Pipelines: an Introduction
It has been known for a long time [see for example Thompson2001, McGrath2002, McGrath2004] that processing of XML documents can conveniently be organized in the form of a pipeline. In such a pipeline, the work is divided into a sequence of steps, each of which takes an XML document as input, and produces another XML document as output. Constructing an application in the form of a pipeline has many advantages, the main ones being (a) that the code of each step in the pipeline is kept very simple; (b) that it is very easy to assemble an application from a set of components, thus maximizing the potential for component reuse, and (c) there is no requirement that each step in a pipeline should use the same technology; it's easy to mix XSLT, XQuery, Java and so on in different stages.
A number of products are available to assist with the development and management of pipeline-based applications, examples being Orbeon [Orbeon] and Apache Cocoon [Cocoon]. More recently W3C has developed a standard language, XProc [W3C XProc], for the definition of pipelines.
One of the benefits of structuring an application using pipelines is that different technologies can be used to implement each step within a pipeline. This maximizes component reusability, since the ability to make use of an existing component is not dependent on the choice of technology used to implement the component. This only works, of course, if there are some kind of standards for plugging heterogeneous components together.
Ideally, components will be able to pass information to each other without the overhead
of
serializing the data as lexical XML and then reparsing it. Equally, they will be able
to pass information
without buffering the entire document in memory. This suggests that in an optimal
interface, the
data will be passed between components as a stream of events (for example, startElement,
endElement, etc).
The question then arises, how should the components of a pipeline be written? One can envisage three styles:
-
Each component is written as a complete program that reads XML from its input and writes XML to its output. We will call this a main-loop component, because in general it contains a program loop containing read and write instructions.
-
A component may be written to be called repeatedly by the component that supplies its input, once for each item of input. This is an event-driven style of programming, and we will call this a push component.
-
A component may be written to be called repeatedly by the component that consumes its output. That is, the component is called whenever some more data is required. We will call this a pull component.
These three styles of component are illustrated in Figure 1.
Figure 1
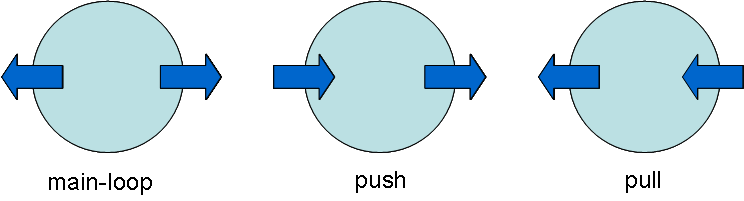
Fig 1. Three styles of pipeline component. The arrows indicate the direction of control flow; the direction of data flow is in all cases from left to right.
A push filter is a component of a pipeline that is invoked repeatedly by its upstream neighbour (the supplier of its input), and that in turn makes multiple calls to its downstream neighbour (the consumer of its output). Similarly, a pull filter is a component that is invoked repeatedly by its downstream neighbour (the consumer of its output), and that in turn makes repeated requests for data from its upstream neighbour (the supplier of its input).
Each of these styles has advantages and disadvantages, from the points of view of the developer of the component and the user of the component. When it comes to constructing a pipeline, however, we probably have to face the fact that we will sooner or later want to integrate components that have been written in different styles: main-loop components, push components, and pull components; one aim of this paper is to address the integration challenges this poses.
Pipelines within a Query or Stylesheet
The concepts described in this paper can be applied at various levels of the system. One can consider a pipeline in which each component is a complete XSLT or XQuery transformation. Or one can consider a pipeline of operations contained within a single stylesheet or query: this often manifests itself as a multi-phase transformation whose logic looks something like this:
<xsl:variable name="x">
<temp>
<xsl:apply-templates select="/" mode="phase-1"/>
</temp>
</xsl:variable>
<xsl:variable name="y">
<tump>
<xsl:apply-templates select="$x" mode="phase-2"/>
</tump>
</xsl:variable>
<xsl:template name="entry">
<xsl:apply-templates select="$y" mode="phase-3"/>
</xsl:template>
We can think of this as a sequence of three “push” components if we adopt the XSLT
1.0 paradigm
which describes literal result elements, xsl:apply-templates, and other instructions that
create new nodes as “writing to the result tree”. The terminology has changed in XSLT
2.0; such
instructions are now described as constructing a node and returning it to its caller.
That is, the language
has changed between the two releases from talking about a push model to talking about
a pull model.
By and large this is only a matter of presentation. But the 1.0
model is probably closer to the way many implementations are likely to work internally.
An internal pipeline within a single XQuery has a more pull-like feel to it. The equivalent might be:
declare function f:phase-1($d as document-node()) {
<temp>{f:process($d)}</temp>
}
declare function f:phase-2($x as element(temp)) {
<tump>{f:manipulate($x)}</tump>
}
declare function f:phase-3($y as element(tump)) {
<html>{f:render($y)}</html>
}
f:phase-3(f:phase-2(f:phase-1(/)))
The “pull” nature of this pipeline arises from the use of function calls as the composition mechanism; the control logic starts from the last stage in the pipeline, and each stage invokes its predecessor by means of a function call.
However, because XSLT and XQuery are both declarative languages, this user view (or
specification view)
of how the languages work might not always match the internal reality. The underlying
XSLT engine
might compile “pull” code from an xsl:apply-templates instruction, or might compile
“push” code from a function call. This flexibility, which we shall examine in more
detail later,
turns out to be one of the major benefits of writing in a declarative language.
Pipelines within an XSLT or XQuery processor
We can also look at pipelines as implemented internally within an XSLT or XQuery processor, or within other components such as XML parsers, validators, and serializers. The serializer is the component responsible for converting a tree representation of an XML document into lexical XML markup; it is controlled by a number of user-settable properties as described in [W3C Serialization]. The serializer in Saxon, for example [see Saxon] and [Kay2001] is implemented internally as a pipeline containing one or more of the following components:
-
An
UncommittedEmitter, which decides dynamically whether the output method is XML, XHTML, or HTML, and constructs the rest of the pipeline accordingly -
A
CharacterMapExpander, which handles anyxsl:character-mapdeclarations in the stylesheet -
A
UnicodeNormalizer, which converts character sequences into composed or decomposed Unicode Normal Form -
A
URIEscaperwhich performs percent-encoding of HTML URI-valued attributes such ashref -
A
MetaTagAdjusterwhich adds, deletes, or modifies<meta>elements appearing within the<head>element of an HTML or XHTML document -
A
CDATAFilter, which wraps selected text nodes in CDATA sections -
An
XML10ContentCheckerwhich checks that the output contains only characters allowed by XML 1.0 (used only in the case where XML 1.1 input is permitted but XML 1.0 output is required) -
An
Indenter, customized to XML, HTML, or XHTML, which adds newlines and indentation -
An
Emitter, customized to XML, HTML, XHTML, or text, which acts as the final stage of the pipeline, emitting a sequence of characters.
Note that for a given task, the actual serialization pipeline will often contain very
few
of these components: if the cdata-section-elements attribute of the xsl:output
declaration is absent, for example, there will be no CDATAFilter on the pipeline.
Moreover, the pipeline may contain components not in the above list: Saxon provides
an interface
allowing the serialization pipeline to be customized with additional user-defined
components.
Does this design perform well? In some respects, it is not optimized; for example
it would be
possible to implement character map expansion and Unicode normalization in a single
“for each character” loop
with fewer instructions than when they are done in separate loops. However, for most
workloads this
is more than compensated by the fact that there are no “per event” or “per character”
tests for
optional operations that are not actually needed. Much of the logic is carried out
at pipeline
configuration time; if the CDATAFilter is not included in the pipeline, then there
will be no once-per-node test to say “should this text node be formatted as a CDATA
section?” So
the net effect is that the user pays no price for facilities that are not used.
In Saxon, the serializer is implemented as a push pipeline: each component uses a SAX-like interface to pass XML events to the next stage in the pipeline. This seems a natural design given that the serializer is writing output, and is thus providing a “write” service to its ultimate client (which might be the XSLT transformation engine, or a user application).
Another internal pipeline within Saxon is the schema validation pipeline, used to
validate
instance documents against the rules defined in an XSD Schema [W3C XML Schema]. This again consists
of a number of components, which in this case are assembled even more dynamically;
every time a
start tag is encountered, a new component is added to the pipeline to validate the
contents of that
element, and this component is then removed from the pipeline when the matching end
tag is found.
Also, if an element defines one or more identity constraints (xs:unique, xs:key,
and xs:keyref), then a “watch” component is added to the pipeline to watch for elements
that match the select expression of the constraint; when such an element is encountered,
a further
“watch” is added to detect and act on elements and attributes that match one of the
field expressions
of the constraint. This illustrates one of the benefits of using a push pipeline:
it is very easy
for such a pipeline to branch, so that one component pushes a single event to many
listeners. In this
case the multiple listeners represent, for example, the multiple fields that can appear
in a single
identity constraint, or the multiple identity constraints that can exist for a single
element declaration
in a schema. Such branching is not possible in a pull pipeline, for obvious reasons.
Push vs. pull parsing
For some people, the terms “push” and “pull” are associated primarily with styles of XML parsing. In particular, with a push parser API like SAX, the main control loop is in the parser, and the user application is invoked to notify significant events such as start and end tags. With a pull parser API like StAX, the main control loop is in the user application, which repeatedly requests the next event by calling the parser.
This usage of the terms “push” and “pull” is simply a special case of the way we use the terms in this paper, for the case of a pipeline that has two stages only, the XML parser and the user application.
It is probably true that both the SAX and StAX APIs have been designed rather too closely for this particular use case (the interface between parsers and user-written applications) rather than for the more general requirement of communication between arbitrary steps in a pipeline. In this paper, however, we are concerned with general principles and not with the specific design of these two APIs. (StAX, in fact, offers two different pull APIs with different trade-offs between functionality and speed, and indeed, it also bundles in two complementary push APIs as well.)
At the parsing level, the debate between advocates of push and pull parsing APIs hinges primarily on usability, not performance. There are some performance differences, but they are fairly marginal. For example, with a pull API it is easier for the consumer of the data to skip parts of the document (for example, when a start tag has been notified it can skip to the matching end tag), which has the potential to reduce the cost of processing the unwanted data. Many of the performance issues relate to how many times character strings are moved from one buffer to another, and such factors depend on the fine detail of the API design rather than on whether it is a push or pull interface.
As regards usability, pull parsing does appear to be more attractive to many users. I believe this is primarily because programmers like to be in control: writing the code that owns the main control loop is easier than writing event-driven code. It means, for example, that much of the current state is maintained on the stack provided automatically by the programming language, rather than needing to be maintained manually on a stack implemented by the user application.
Unfortunately, in a multi-stage pipeline this advantage tends to disappear. Typically only one component in the pipeline can own the main control loop: the others will either be push filters or pull filters.
A difference between pull and push parsing becomes noticeable when the correspondence between input and output events is not one-to-one. A push filter can easily generate zero, one, or more output events in response to each input event. The same effect can be achieved in a pull filter, but it requires more intricate management of state information between calls. For this reason, my experience is that while a pull parser API is attractive when the application can then be written as a single control loop, writing a pipeline consisting entirely of pull filters is trickier than writing an equivalent push pipeline.
Branching and Merging
A significant difference between pull and push pipelines is this: a push component can readily send its output to more than one destination, whereas a pull component can readily read data from more than one source. This is illustrated in Figures 2 and 3. By its nature, a push pipeline cannot handle multiple streamed inputs, nor can a pull pipeline handle multiple streamed outputs.
Figure 2
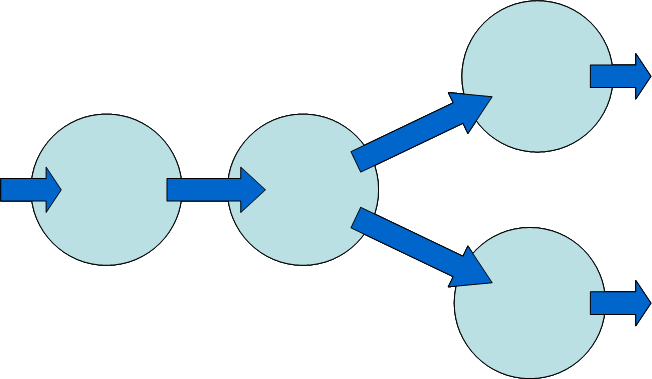
Fig 2. Branching in a push pipeline. A component can write to several destinations.
Figure 3
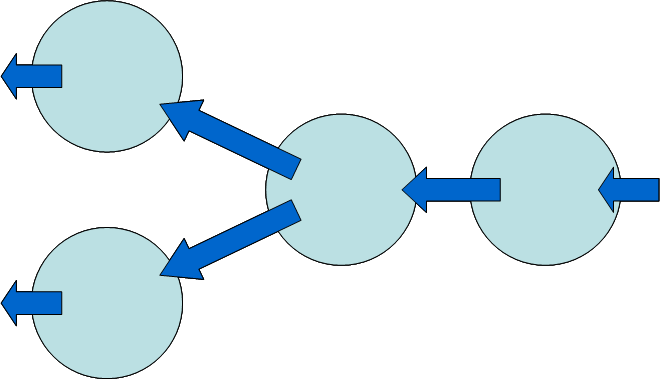
Fig 3. Merging in a pull pipeline. A component can read from several sources.
As already mentioned, a situation where branching is useful is in evaluating uniqueness constraints during schema validation. At any given point during a streamed validation of an instance document, any number of uniqueness constraints can be active. These might have the same scope (employee number and social security number must both be unique over all employees) or they might have different scope (promotion date must be unique within an employee history). In Saxon's schema validator, every time a new uniqueness constraint comes into scope, a uniqueness monitor for that constraint is activated; all parsing events are distributed to all active uniqueness monitors. This design is only possible with a push pipeline.
A situation where merging might be useful is in implementing the XPath 2.0 deep-equal()
function. One can envisage implementing this by means of a streaming pass over both
inputs (especially, say, in the
case where both operands are calls to the doc() function, the intent being to compare two
complete XML documents).
Any significant difference between the two event streams would then cause the function
to return false. This
is only possible with a pull pipeline. Because Saxon's architecture is predominantly
push-based, it does not
offer a streaming implementation of the deep-equal() function — instead it requires both operands to
exist as trees in memory.
Pipeline Granularity
In the serialization and validation pipelines discussed above, the calls from
one component to the next are at the level of an “event”. This is similar to a SAX
event (start element,
end element, text node, comment node) and so on, except that in Saxon, the internal
push interface treats
each attribute as a separate event notified after the start tag; namespaces are also
notified as events,
representing a namespace declaration or undeclaration. A pull pipeline can also operate
at the same
granularity: in the StAX XMLEventReader interface, a call on nextEvent()
returns an XMLEvent object, which again represents a parsing event such as StartElement,
EndElement, Characters, or Comment. As with SAX, the attributes are delivered as part
of the
StartElement event.
Saxon's XPath engine, by contrast, makes extensive use of pipelines in which the unit
of
data transfer is not a parsing event, but an XPath item (that is, a node or atomic
value).
Many XPath operations, especially in XPath 2.0, take sequences of items as
their input and deliver sequences of items as their result. An obvious example is
a filter
expression SEQ[PRED], where the output sequence is that subset of the input items that satisfy some
predicate. This kind of list processing is well established in functional programming
languages,
and to deliver acceptable performance it is always implemented using pipelines, to
avoid
allocating memory to intermediate results. Pipelining also benefits execution through
“early exit”:
an operator only needs to read as much of its input as is needed to deliver a result.
Typically each expression in the expression tree is
represented at run-time by an iterator which delivers the results an item at a time
in response to
a call (such as next()) from the consumer of the data; the implementation of this iterator
in turn makes calls on next() to get data from the iterators representing its subexpressions.
A pull pipeline works well here because in general, an XPath expression takes input sequences from several subexpressions but delivers a single sequence as its result. For example, the union operator (assuming its inputs are do not need to be sorted into document order, which is usually the case) can be implemented by an iterator that switches between reading from its two input streams, never looking ahead more than one item for either.
Push processing can also be useful at the item level, however. An example is a recursive function that operates over a sequence:
<xsl:function name="f:compute-running-total" as="element(transaction-with-balance)*">
<xsl:param name="input" as="element(transaction)*"/>
<xsl:param name="current-balance" as="xs:decimal"/>
<xsl:if test="exists($input)">
<transaction-with-balance amount="{$input[1]/@amount}" balance="{$current-balance + $amount}"/>
<xsl:sequence select="f:compute-running-total(remove($input, 1), $current-balance + $amount}"/>
</xsl:if>
</xsl:function>
A push implementation of this function will typically write each computed element to the output destination as soon as it is constructed. A pull implementation, unless optimized, is likely to construct successive sequences of length 1, 2, 3,,, n, with a great deal of copying of intermediate results. Furthermore, a push implementation can benefit more easily from tail call optimization, whereby on a recursive call the stackframe of the calling function is reused for the called function, avoiding stack overflow when processing a lengthy input sequence.
Saxon is capable of evaluating this function in either push or pull polarity. As a
general rule in Saxon,
tree construction operations (such as xsl:element) work in push polarity; XPath operations that navigate through
an input document work in pull polarity; and flow of control constructs such as function
calls or conditional expressions
can work in either direction, generally choosing the polarity of their parent instruction
by preference.
As well as pipelines that operate at the event level or the item level, XQuery in
particular can take
advantage of pipelines in which the unit of data is a tuple. This underpins the semantics
of XQuery FLWOR
expressions. Currently in Saxon there is only one instance of a pipeline involving
tuples, which is needed
to support certain unusual cases of the order by clause in a FLWOR expression. In future, however,
tuples will need to be implemented more deeply in the infrastructure as they are essential
to the support
of new facilities in XQuery 1.1 such as grouping and windowing.
Hybrid Granularity
The Saxon push interface allows both parsing events and complete items to be sent down the pipeline. This arises naturally from an XSLT instruction such as:
<xsl:element name="x">
<xsl:attribute name="a" select="1"/>
<xsl:sequence select="doc('abc.xml')"/>
</xsl:element>
The values passed down the pipeline by this instruction are a start-element event, an attribute event, a document node, and an end-element event. This is a hybrid sequence containing both “composed” nodes (the document node), and “decomposed” events representing nodes (the start and end element events); the attribute node fits into both categories.
Saxon provides two pipeline filters called compose and decompose. When added
to a push pipeline, the compose filter acts as a tree builder: a sequence of start-element and
end-element events is converted into a tree, which is then passed on down the pipeline
as a single composed node.
The decompose filter does the reverse: if it receives a document or element node, it decomposes
this
into a sequence of parse events. The decision whether to compose a sequence or decompose
it is delayed until
it is known what the recipient of the data intends to do with it: if the eventual
recipient is a serializer, then
decomposed form is preferred, while if it is a tree builder, on an operation that
requires a “real tree” as input,
then composed form is needed.
When push meets pull
Or: When pull comes to shove...
The preceding discussion establishes that there are places where it makes more sense to do pull processing, and places where push is more sensible. But we have also seen that changing polarity can cause a noticeable performance cost. So what happens when a push pipeline meets a pull pipeline?
To make this more concrete, a simple design approach for an XSLT 1.0 processor is as follows:
-
The source document is built as a tree in memory, typically by a two-stage pipeline consisting of a push parser and a tree-builder, perhaps with intermediate filters to perform operations such as DTD or schema validation, or XInclude processing.
-
Path expressions in the XSLT stylesheet are evaluated using a pull pipeline in which the values passed down the pipeline are (references to) nodes in the source tree.
-
Instructions in the XSLT stylesheet that construct nodes in the result tree are evaluated by sending decomposed events (start-element, end-element, etc). If the result tree is serialized, these events can pass directly to the serializer, which itself is implemented as a push component, eliminating the need to construct the result tree physically in memory.
So we have a push stage, then a pull stage, then another push stage, as illustrated in Figure 4.
Figure 4
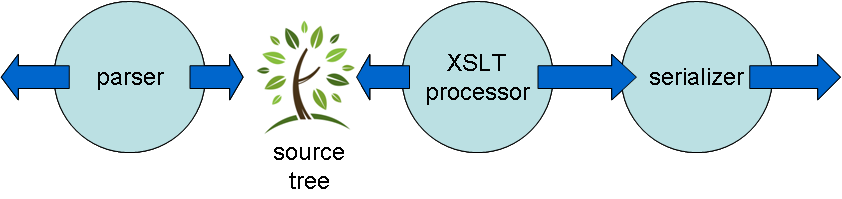
Fig 4. Typical structure of an XSLT 1.0 processor.
Between the parsing pipeline that processes the source tree and the XPath evaluation pipeline that reads it, there is a polarity change from push to pull, and this is typically handled by allocating memory to hold the complete tree. That is, the pipeline is interrupted; there is a need for a reservoir of memory with sufficient capacity to hold the entire source tree. At the same time, there is a latency impact, because the second pipeline stage typically cannot start operation until the first has finished.
A similar conflict typically arises in a straightforward implementation of intra-stylesheet
pipelines
based on temporary trees in XSLT 2.0 (or in XSLT 1.0 with the node-set() extension). The chances
are that a variable holding a temporary tree will actually be materialized in memory
— constructed as the final
destination of a push pipeline — to be read by a pull pipeline that only starts operation
once the tree writing
has finished. Contrast this with a variable that simply holds a sequence of existing
nodes or atomic values,
where the process that creates the sequence and the process that reads it can often
be pipelined together,
avoiding the need to physically materialize the variable's value.
By contrast, passing data from a pull pipeline to a push pipeline is no problem. In between there is a component that owns the control loop, reading data from the pull side, and writing it to the push side.
Once pipelines become more complex, the turbulence caused by push/pull conflicts can have a significant effect on performance. The flow is interrupted every time such buffering occurs, and this does affect both memory usage and latency. A recent paper [Kay2008] explores the effect of changing certain pull/push decisions within the Saxon XQuery processor. This examines the behaviour of a particular query in the XMark benchmark:
-
Using default execution with push polarity, the query takes 1926ms
-
Forcing the query to run with pull polarity, execution time increases to 3496ms, because of the need to buffer the result tree before serialization.
-
Running the query as a whole with push polarity, but using pull polarity for the FLWOR expression that computes the content of the main result element gives a run-time of 2720ms
The conclusion to be drawn from these results is not that push is better than pull or vice versa, but that changes in polarity as the data passes down the pipeline are expensive and need to be avoided.
The problem is probably worse in XQuery than in XSLT. XSLT has two sublanguages: the XSLT instruction set, and the XPath expression language. It makes sense for XPath expressions to pull, and for XSLT instructions to push. Because the two sublanguages are independent and don't compose very well, this generates relatively few conflicts. By contrast, XQuery is a single language where these constructs are fully composable, and using the same evaluation strategy is therefore likely to lead to more turbulence.
There is an alternative way to graft a push pipeline to a pull pipeline. Rather than allocating memory to hold the accumulated data, it is possible to operate the two in separate threads. With two threads there can be two control loops. Data written by the push thread can be placed in a cyclic buffer, from which the pull thread can read it, as illustrated in Figure 5.
Figure 5
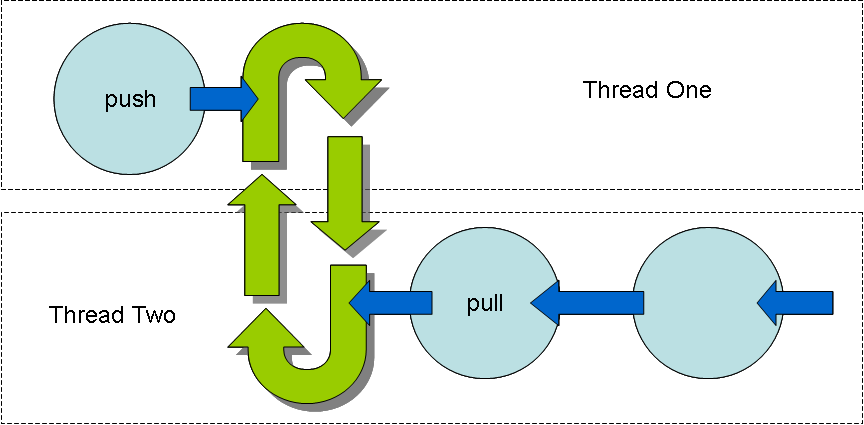
Fig 5. Using a cyclic buffer to resolve a push-pull conflict.
Saxon uses this technique to support the limited kind of streamed processing available
in Saxon-SA 9.1
and earlier releases [see Saxon Streaming]. Although this offers limited functionality, it has proved a boon to those users
who
need to handle source documents in the gigabyte range, stretching the capacity of
available real memory.
The idea here is that the result of an expression such as doc('big.xml')//unit can be
delivered (piped) as a sequence of unit elements, each of which is a small subtree
of the original large document. Many transformations (as noted by [McGrath2004] have the
characteristic that the transformation can be effected by dividing the source documents
into a sequence of
small trees rooted at what McGrath calls a fulcrum element, applying a transformation to each of these subtrees,
and then combining the results back into a single result tree; this construct is explicitly
geared to
this kind of transformation. To satisfy the semantics of the language, it is only
possible to do this
if the expression appears in a context where the subtree is copied, for example
<xsl:copy-of select="doc('big.xml')//unit"/>. This is because without the copying,
the recipient of the data would be allowed to navigate away from the unit element using
XPath axes such as parent or following-sibling. With a copy, the unit
element becomes a standalone (parentless) element, so any attempt at such navigation
returns nothing.
Of course there is no real copying going on here: it's just that the system behaves
as if it built a large
tree containing the whole source document, and then copied small parts of it to be
processed one at a time.
The subset of XPath that Saxon allows to be used in this streaming mode is quite restrictive. It is based originally on the subset defined in the XML Schema specification for the definition of uniqueness and referential integrity constraints. It only allows downward selection. Unlike Saxon's usual strategy for XPath evaluation, this streaming subset of XPath is evaluated in push polarity: a SAX parser is used to parse the source document, and the resulting events are then passed through a series of push filters whose effect is to reduce the document to a sequence of elements representing the parts selected by the path expression (the fulcrum elements). The remaining events then go to a tree builder which builds each element subtree in turn as a real tree in memory; the sequence of nodes representing the fulcrum elements are then pushed into a cyclic buffer where they are read by the pull pipeline (in a separate thread) that consumes the data and transforms it using further XSLT instructions.
It would be possible to avoid this two-thread approach by reimplementing the first stage as a pull pipeline, starting with a pull parser (StAX), and then filtering the parsing events in pull polarity. There are several reasons this has not been done. Firstly, the code was originally written to work within Saxon's schema validator (which works in push polarity), and it would be costly to rewrite it. Secondly, as already discussed, writing pull-based filters is probably more difficult than writing push-based filters. Finally, all other processes that can take place on the parsing pipeline, for example schema validation, would also need to be rewritten to operate in pull polarity, and this is simply not a practical proposition. Nevertheless, it needs to be recognized that the current design is an engineering compromise. But as such it is convenient to the purpose of this paper, because it exemplifies the fact that when you want to reuse streaming components, you will sometimes find that some of them have the wrong polarity.
Coroutines
Handling the push-pull conflict using multiple threads, as discussed in the previous section, is actually overkill. Threads offer two significant features: each thread has its own execution stack to maintain state, and each thread can be independently scheduled. We need the first feature, we don't need the second. Or to put it another way, we don't really need threads at all: we need coroutines. (In fact, we can probably make do with the restricted kind of coroutine sometimes called a generator; but the terminology in this area varies).
The key idea here is that two components can each be written as a loop, maintaining
whatever
data they wish in local variables within the loop. One component issues write calls
within its loop to push data out; the other issues read calls within its loop to pull data in.
When the writer issues its write request, control passes to the reader at the point
where it issued its read
request; and when the reader issues its read request, control passes back to the writer
so that it can
compute its next output and write it.
Of course, this extends to a pipeline with more than two components. It also extends to a branching pipeline in which one component writes several output streams for consumption by different readers. And to a merging pipeline, in which one component reads from several input streams supplied by different writers. Essentially it means that as far as the programmer is concerned, there are no push or pull components any more: every component owns its own control loop. This, as we have seen, should simplify the programming of the component, and it should also improve reusability, since components are no longer restricted to operate in either a push or pull pipeline: they can work in both.
How come this doesn't lead to deadlocks? The answer is that you can't have a general graph of coroutines reading and writing to each other, as you can with threads. The coroutines are not true peers; there has to be a hierarchic control relationship represented by the way in which they are originally invoked.
Unfortunately this concept, to be usable in practice, requires support from the programming
language
and compiler, which is rarely forthcoming in modern programming languages, though
the yield
construct found in Javascript and C# comes close.
However, XSLT is a programming language, and we are in control of its compiler, so this raises the question of whether user-level intra-stylesheet pipelines can indeed be implemented as coroutines. Specifically, can we generate code from XSLT templates such that the XSLT code that writes data to a temporary tree runs as a coroutine alongside the XSLT code that reads data from the temporary tree? In principle, one of the major benefits of having a stateless declarative language like XSLT is that the implemented execution model can diverge dramatically from the structure of the code as seen by its author.
Clearly this is only going to work if the temporary tree is processed in a sequential manner. This caveat eliminates many cases: it reflects the fact that a push-pull conflict is not the only reason that pipelines break down; they also break because of ordering conflicts (data needs to be sorted), or because, in the case of a pull pipeline, data cannot be supplied to more than one client in a streamed manner. But if we work on the assumption, for the moment, that we can identify an XSLT process that reads a temporary tree in a sequential manner (we'll come back to this later), then in principle we should be able to run this as a coroutine alongside the process that writes the tree, without buffering the tree in memory.
At this point, it will be useful to rediscover the concept of program inversion, an idea from the days of sequential data processing using magnetic tape, that was designed specifically to tackle this problem.
Jackson Structured Programming and the Concept of Inversion
Michael Jackson (not the singer) developed the method of program construction known as JSP (Jackson Structured Programming) initially as a way of designing the batch processing systems of the 1960s and early 1970s, characterised by their use of sequential data files stored on open-reel magnetic tapes. The method is fully described in a 1975 book [Jackson1975], but most readers will find it easier to consult a retrospective analysis written by Jackson in 2001 [Jackson2001]
The files used in these systems were generally organized as a hierarchy (for example, customers, orders, then order lines) and were processed sequentially. There was insufficient main memory to hold more than a fraction of the file contents: a reel of magnetic tape held typically 20Mb, while 128Kb of main memory was considered generous. So processing consisted of reading one or more tapes sequentially, typically a master file and a transaction file containing details of changes, merging the data from the multiple inputs, and then writing the output to another tape.
The essential principle of JSP was the idea that the structure of the program should mirror the structure of the data. JSP used a graphical notation to represent hierarchic structure embodying the basic elements of sequence, choice, and iteration, and this same notation was used to represent the structure both of the data and of the resulting program. The notation is illustrated in Figure 6. In his retrospective, Jackson acknowledges that the ideas he was advocating had a great deal in common with parallel developments in compiler-writing; his graphical notation was essentially a BNF schema for data files, and his program structure similar to that of a recursive descent parser derived from that grammar. But of course no-one saw it that way at the time: compiler technology was still in its infancy.
Figure 6
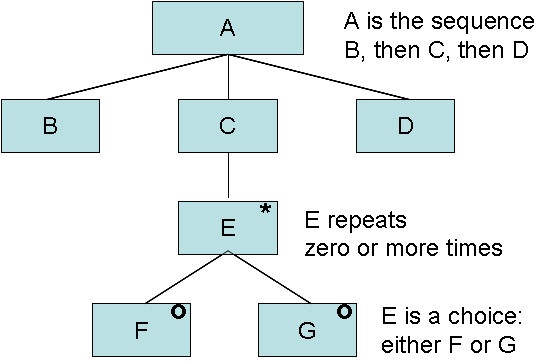
Fig 6. Jackson notation for sequence, iteration, and choice.
So, what happens when the structure of the output file does not correspond in a simple way to the structure of the input? This is known as a structure clash. Jackson identified three kinds of structure clash:
-
An interleaving clash, typically involving transformation of a single input sequence (all employees, say) into multiple output sequences (employees by department)
-
An ordering clash, involving sorting the data into a different order
-
A boundary clash, involving constructing a new hierarchy for the existing records without changing their order (in the language of the markup world, this is the problem of parallel hierarchies running through the same data, with one hierarchy being primary in the input and a different hierarchy being primary in the output).
Of these, the one that caused most problems in program design was the boundary clash, and Jackson's approach to solving it was to split the process into two phases, a flattening phase that eliminates the first hierarchy, followed by a grouping phase that imposes the second hierarchy. So we see that the notion of the pipeline as a mechanism for breaking down the processing of hierarchic data has a long pedigree.
In the world of magnetic tape, the problem was that the output of one phase of processing was typically written to tape, to be read again by the next phase. Since writing 20Mb of data to a tape could take an hour, this clearly created a problem, and this is where the idea of inversion comes into the picture.
Jackson recognized that the intermediate file could be eliminated if, instead of the second phase of processing owning its own control loop, it were rearranged to be called by the first program every time another record became available. JSP refers to this rearrangement as an inversion. Crucially, Jackson recognized that this did not necessarily mean that the second phase had to be written in what we would now call a “push” style: inversion was a mechanical transformation of a program text that could be performed by a compiler. Jackson went on to produce a COBOL preprocessor that automated this task.
Again there is a similarity with compiler technology. A bottom-up parser is an inversion of the top-down parser for the same grammar; whereas the top-down parser has the structure Jackson would advocate, mirroring the structure of the input file, the bottom-up equivalent is event-driven. The challenge in writing a correct bottom-up (push) parser for a complex grammar is considerable, because of the difficulty of maintaining state between calls; but the task can be automated given a high-level description of the grammar to be processed.
The relationship between a conversational application and a transactional one is another example of an inversion. A conversational application owns the control loop and issues write requests to talk to the user, and read requests to get their replies. This relies on the application retaining state in main memory (or paged out to secondary store) while waiting for user responses, which severely limits concurrency. A transactional application, whether written according to the conventions of a traditional mainframe TP monitor or according to the more modern architecture of the web, is event-based: a message from the user activates the application, which has to retrieve the state of the conversation from some holding place, process the message, and then save the state again before replying to the user.
The UK mainframe manufacturer ICL developed a very successful fourth-generation application development environment under the name RADS (it was subsequently marketed as QuickBuild) [Brown1981, Cosh1981]. QuickBuild was designed according to JSP principles. Interactive applications were written in a conversational style (as if they owned the control loop), and were then automatically compiled into transactional code - again, an automated inversion. A similar idea can also be seen in the scripting language used by the Cocoon framework [Cocoon Flow].
In all these examples, the user achieves the benefits that come from writing the application as a controlling application (maintainability, readability, reusability) combining these with the improvements in system performance that come from using a push-based control model.
How does inversion actually work? Essentially, whereever the application issues a
read request
for more data, this needs to be translated into instructions that save the state (including
the reentry point),
and exit. Then a new entry point needs to be created for the module, to be invoked
when data becomes available,
which restores the state and resumes execution at the correct entry point. Typically
the state here means
the data on the stack, together with the reentry point (or program counter).
This state is sometimes known as a continuation;
some modern programming languages, even if they do not compile inverted code automatically,
offer continuations
as a way of achieving a similar effect by hand. The yield construct in C# is an example.
Inversion does not depend on a program being written in a declarative language like XSLT with no immutable variables. But it becomes a lot easier to analyze the language to determine what parts of the state are significant, and to avoid saving and restoring unnecessary parts of the state, if the language is sufficiently high level. The essential requirement is not that variables are immutable, but that it is clear from static analysis which variables need to be preserved as part of the state. In the case of XSLT, the term “variables” here includes the dynamic execution context: that is, the context item, position, and size, as well as more obscure context variables such as the current grouping key and current mode. The next section explores inversion of XSLT programs in more detail.
Inversion in XSLT
Let's look at inversion in XSLT. Specifically, let's take a simple stylesheet and see how it can be compiled in such a way that it is driven by push events coming from the XML parser, and in turn drives the serializer by issuing similar push events. Such a stylesheet would be fully streamable, allowing execution without building either the source tree or the result tree in memory.
Clearly not all stylesheets are fully streamable in this way, and it's not the intent in this paper to try to define exactly what conditions a stylesheet must satisfy in order to be streamable. The XSL Working Group in W3C is currently working on this problem, and hopefully will publish its first results soon after the Balisage 2009 conference. The focus here is on a different problem: having determined the code is streamable in principle, how do we actually arrange the execution to perform streaming?
Inverting a single-phase stylesheet
We'll start with a single-phase stylesheet, one that is self-evidently streamable in that the push events needed to construct the result tree are a subsequence of the push events representing the source tree. Hopefully if we can establish that a single-phase streamable stylesheet can be inverted, it should then be possible to see how multiple streamable phases can be pipelined together without allocating memory for buffering intermediate results.
Here is a simple stylesheet that deletes all the NOTE elements from a source
document, wherever they appear.
<xsl:stylesheet version="2.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="*">
<xsl:copy>
<xsl:copy-of select="@*"/>
<xsl:apply-templates/>
</xsl:copy>
</xsl:template>
<xsl:template match="NOTE"/>
</xsl:stylesheet>XSLT 2.0 describes the semantics of this code in terms of functional composition:
xsl:apply-templates is an expression that returns a result (which in this case will
always be a sequence of elements); this sequence is then used as an operand of the
containing
instruction (xsl:copy), which copies these elements, adding a new parent element to
construct a larger tree at each stage of processing.
In practice, however, the execution model is likely to be closer to the way XSLT 1.0
describes the semantics. The 1.0 specification talks of instructions writing nodes
to the result tree:
that is, of data being pushed to the next stage in the pipeline. It's easy to visualize
the start
and end tags of the xsl:copy instruction as if they were separate sub-instructions, one
pushing a startElement event to the result, the other pushing a matching
endElement event.
One can see this effect at work in Saxon's XQuery compiler. Saxon-SA has the capability to compile XQuery to Java source code, which makes the execution strategy rather visible. Given this query:
<e>
<date>{current-dateTime()}</date>
</e> the resulting Java code (simplified only very slightly for comprehension) is:
public void process(final XPathContext context) throws XPathException {
SequenceReceiver out = context.getReceiver();
out.startElement(name_e, type_untyped);
out.startElement(name_date, type_untyped);
out.append(context.getCurrentDateTime());
out.endElement();
out.endElement();
}This query, of course, reads no data: it was chosen deliberately to show how the construction of the result tree is optimized away. Although Saxon's XSLT processor does not have the ability to generate Java code, the execution model of the interpreter follows the same pattern. If it did generate code, the code for the identity template in our example stylesheet would look something like this (this is idealized code; it leaves out messy details such as maintaining the context position):
public void template1234(final XPathContext context) throws XPathException {
SequenceReceiver out = context.getReceiver();
NodeInfo current = context.getCurrentNode();
out.startElement(current.getNodeName(), type_untyped);
Iterator attributes = current.iterateAxis(Axis.ATTRIBUTE);
while (attributes.hasNext()) {
NodeInfo attr = attributes.next();
out.attribute(attr.getNodeName(), attr.getStringValue());
}
XPathContext context2 = context.newContext();
Iterator children = current.iterateAxis(Axis.ATTRIBUTE);
while (children.hasNext()) {
NodeInfo child = children.next();
applyTemplates(child, context2);
}
out.endElement();
}
We can see that this code is written in the form of a control loop. It reads its input
using
imperatives such as children.next() (and, indirectly, via applyTemplate()),
and it writes its output using imperatives such as startElement() and endElement().
To make this code streamable with respect to the input from the parser, we need to
invert it. It will
end up looking something like the code for the Saxon schema validator. This maintains
a stack of
element handlers, one for each currently open element; if an element is being processed
by a template
rule, then the element handler would be a class with methods startElement() and
endElement() which for the identity template would look something like this:
public State startElement(final XPathContext context) throws XPathException {
SequenceReceiver out = context.getReceiver();
NodeInfo current = context.getCurrentNode();
out.startElement(current.getNodeName(), type_untyped);
return applyTemplatesState ;
}
public void endElement(final XPathContext context) throws XPathException {
SequenceReceiver out = context.getReceiver();
out.endElement();
}
The object applyTemplatesState is the continuation,
the data that tells the despatcher what to do next: in this case, to select template
rules to process
the events representing children of this element, adding those templates to the stack
of state information.
The inversion of a template will not always be as simple as this, of course. In general
on exit from
the startElement() call, all information about current variables and the current context
needs to be saved on a stack, and restored from the stack when endElement() is called.
If the template contains an xsl:choose instruction, the retained state information will need
to remember which branch of the choice is active, and so on.
If the template uses xsl:for-each to process the children of the context node,
the simplest way to handle this is probably by rewriting the xsl:for-each as a call
on xsl:apply-templates in some singular mode, passing all the in-scope variables as parameters.
This reduces the number of cases that need to be handled by the inversion logic. Other
more complex constructs
such as xsl:for-each-group, however, still need individual treatment if they are to be made
amenable to streaming.
Inverting a multi-phase stylesheet
A multi-phase stylesheet typically uses a temporary tree (or sequence) in a variable to hold the intermediate results that form the output of one phase and the input to the next. Ideally each phase will use a different mode:
<xsl:variable name="phase1output">
<xsl:apply-template select="/" mode="m1"/>
</xsl:variable>
<xsl:variable name="phase2output">
<xsl:apply-templates select="$phase1output" mode="m2"/>
</xsl:variable>
<xsl:template match="/">
<xsl:apply-templates select="$phase2output" mode="m3"/>
</xsl:template>
Provided it can be established that the processing of a temporary tree such as
phase1output is streamable (which, as we have said, is beyond the scope of this
paper), there is essentially no additional difficulty in pipelining the different
phases
together in such a way that the intermediate results are not buffered in memory. Phase
1 writes
to phase1output by pushing events; the inverted code for phase 2 is immediately activated
to process these events as they occur.
Must it be pushed, or can it be pulled?
The previous sections describe how XSLT code, considered as a control loop, can be inverted with respect to its input, so that it acts as a push filter, processing events originating from the previous phase of processing.
It's reasonable to ask whether one could not equally well invert the code with respect to its output, so that it acts as a pull filter, responding to requests for more data originating from the subsequent phase of processing, that is, from the consumer of its output.
The answer is that this is also possible, though I have not explored this avenue in as much detail: because the Saxon serializer and schema validators work only in push polarity, there is a strong tendency to use push polarity for everything else as well.
We have already seen that the key difference between push and polarity is that a push
component can send data to multiple recipients, whereas a pull component can read
data from multiple
sources. XSLT in its current form has few constructs that requires the ability to
stream input from multiple sources in parallel (the example of the deep-equal() function
was a little contrived). An xsl:merge instruction is under consideration
for XSLT 2.1, and one can see how this would benefit from streamed processing in pull
polarity.
Meanwhile it should be evident how the ability of push pipelines to branch to multiple
destinations could be
exploited in cases where one component in a pipeline writes temporary data to a variable,
and
two separate components both read from this variable. If both these components are
streamable, there
is no reason why the fact that the variable has more than one reader should result
in it being
buffered in memory; the events generated by the component that writes to the variable
can be broadcast
to all the readers of the variable, provided that each of them is streamable with
respect to that
variable.
So, inversion into pull polarity is possible, but inversion to push code seems to have more practical utility at present.
Conclusions
Pipelines have been recognized for many years as a good way to structure XML applications, and the emergence of XProc as a standard language for describing pipelines can only encourage this. For performance, the stages of a pipeline should communicate by means of streams of events. Traditionally, this can be done either by writing components with pull polarity (the consumer calls the supplier when data is required), or by components with push polarity (the supplier calls the consumer when data is available). Performance problems arise when components with different polarity are mixed within the same pipeline.
This is seen within the internal pipelining of an XSLT processor. The scaleability of XSLT is limited because most processors build the source tree in memory. This is sometimes needed because the transformation accesses the data not in its original order; but in many cases the tree is built only because of the polarity clash that exists between the push operation used by the XML parser and validator, and the pull operation used by the XPath processor when navigating the tree. Many XSLT processors avoid building the result tree in memory, and this is because there is no polarity clash: the XSLT instruction evaluation and the result tree serialization both operate with push polarity.
This problem is not new. Jackson tackled it when designing batch processing systems using magnetic tape. He formalized the concepts of structure clashes that prevent streamed operation, and he developed the idea of program inversion as a way of automatically transforming a pull program to a push program or vice versa. What this paper has attempted to do is to demonstrate that the same ideas can be applied to the XML-based pipeline systems of today. As the usage of XML increases and more and more users find themselves applying languages like XSLT and XQuery to multi-gigabyte datasets, a technology that can remove the problems caused by pipeline polarity clashes has great potential.
References
[Cocoon] Apache Cocoon. http://cocoon.apache.org/
[Cocoon Flow] Advanced Control Flow: Cocoon and continuations. http://cocoon.apache.org/2.1/userdocs/flow/how-does-it-work.html
[Brown1981] A. P. G. Brown, H. G. Cosh, and D. J. L Gradwell. Database Processing in RADS - Rapid Application Development System. In Proc 1st British National Conf. on Databases (BNCOD-1), Cambridge, 1981
[Cosh1981] H. G. Cosh, A. P. G. Brown, and D. J. L Gradwell. RADS - ICL's Rapid Application Development System. In Proc 3rd Conf of European Cooperation in Informatics, Munich, 1981. Springer, ISBN 3-540-10855-8
[Jackson1975] Michael A Jackson. Principles of Program Design. Academic Press, 1975
[Jackson2001] Michael A. Jackson. JSP in Perspective. sd&m Pioneers' Conference, Bonn, June 2001. http://mcs.open.ac.uk/mj665/JSPPers1.pdf
[Kay2001] Michael Kay. Saxon: Anatomy of an XSLT Processor. IBM DeveloperWorks, Feb 2001. http://www.ibm.com/developerworks/library/x-xslt2/
[Kay2008] Michael Kay. Ten Reasons why Saxon XQuery is Fast. IEEE Data Engineering Bulletin, 31(4):65-, Dec 2008. http://sites.computer.org/debull/A08dec/saxonica.pdf
[McGrath2002] Sean McGrath. XPipe — A Pipeline Based Approach To XML Processing, Proc. XML Europe 2002, Barcelona, Spain, May 2002.
[McGrath2004] Sean McGrath. Performing impossible feats of XML processing with pipelining, Proc XML Open 2004, http://seanmcgrath.blogspot.com/pipelines.ppt (Microsoft Powerpoint)
[Orbeon] http://www.orbeon.com/
[Saxon] http://www.saxonica.com/
[Saxon Streaming] Streaming of Large Documents (in the Saxon documentation). http://www.saxonica.com/documentation/sourcedocs/serial.html
[W3C Serialization] Scott Boag et al, eds. XSLT 2.0 and XQuery 1.0 Serialization. W3C Recommendation, 23 January 2007. http://www.w3.org/TR/xslt-xquery-serialization/
[Thompson2001] Henry S. Thompson. The XML Meta-Architecture. Presented at XML DevCon, London, Feb 2001. http://www.ltg.ed.ac.uk/~ht/XML_MetaArchitecture.html
[W3C XProc] Norman Walsh, Alex Milowski, and Henry S. Thompson, eds. XProc: An XML Pipeline Language. W3C Candidate Recommendation, 26 November 2008. http://www.w3.org/TR/xproc/
[W3C XML Schema] Henry S. Thompson et al, eds. XML Schema Part1: Structures. 2nd Edition. W3C Recommendation, 28 October 2004. http://www.w3.org/TR/xproc/