State of things
We want to build our resources on json-LD based APIs so that we can use them and others can do the same we do. We want these to be based on the XML TEI data we collaboratively edit. As we build an API we build also clients using it. The construction of APIs and their clients within the same XQuery database (exist-db) may look redundant,[1] but the re-presentation of the data in this way, standardizing access routes and expected results of queries, provides additional information, not directly accessible without the filter of the API, so that the API implementation itself has an heuristic and content-building impact on the data, it is not just another visualization of the same for machines but delivers a representation which benefits from layers of logic and inferences which enrich the data, not only its representation. This paper presents two modules, one serving the IIIF presentation API, the second serving the three Distributed Text Services API specifications (Collection, Document and Navigation), as well as an additional experimental Web annotation and indexes API. These are all based on XML TEI data and implemented with a RESTxq XQuery[2] module within exist-db which also benefits from direct access to a SPARQL Endpoint containing a serialization in RDF of some of the information in the XML. The two modules are - iiif.xql and related modules - dts.xql and related modules.
The setup is not uncommon. We have our data collaboratively edited in GitHub, indexed from there into exist-db and transformed with XSLT to RDF-XML. The RDF-XML is passed on to a Apache Jena Fuseki on the same server and is indexed there as well, as RDF so that the two datasets are parallel and updated synchronously. Both the XSLT transformation and the Reasoner in Apache Jena Fuseki add information by inferencing it from the script or from the ontologies used in the triplestore.
The IIIF and DTS specifications and their importance for Beta maṣāḥǝft
Before getting into the details of some aspects of the modules, let me briefly introduce
for those who may not be familiar with them, the two target API specifications in
question.
The International Image Interoperability Framework Presentation API specification[3] provides a model for describing a set of images giving the minimal necessary
information to retrieve and display them. It uses jsonLD as a syntax and allows images
providers to present their collections of images with a linked-open-data description,
so that
they can be navigated not just in the provider's viewer, but in any viewer which supports
this
specification and can read it. The change this standard and the others in its family
have
brought in the world of manuscript studies and indeed in the provision of images in
general,
for art works, books, etc. is enormous. It is only logical that a project like Beta
maṣāḥǝft: Manuscripts of Ethiopia and Eritrea (Schriftkultur des christlichen Äthiopiens
und
Eritreas: eine multimediale Forschungsumgebung)[4] presenting manuscript descriptions (collaboratively encoded in XML) and the images
of many of these manuscripts, may follow this standard to present the sets of images
of the
manuscripts, since also other major institutions holding manuscripts and offering
them to the
public do the same. Take for example the Digital Vatican Library and the Bibliothèque
nationale de France. In practice, loading the stable URL to a Manifest produced following
the
IIIF specification, like https://betamasaheft.eu/api/iiif/ESum035/manifest into any
IIIF-able
viewer will show the correct sequence of images served from our server with their
metadata.
This Manifest is a URI for a resource described by a label and other properties,
like in the following example
{
"label" : "Bǝḥerāwi Kǝllǝlāwi Mangǝśti Tǝgrāy, ʿUrā Qirqos, UM-035",
"@type" : "sc:Manifest",
"@id" : "https://betamasaheft.eu/api/iiif/ESum035/manifest",
"description" : "An Ethiopian Manuscript.",
"attribution" : "Provided by Ethio-SPaRe project."
}
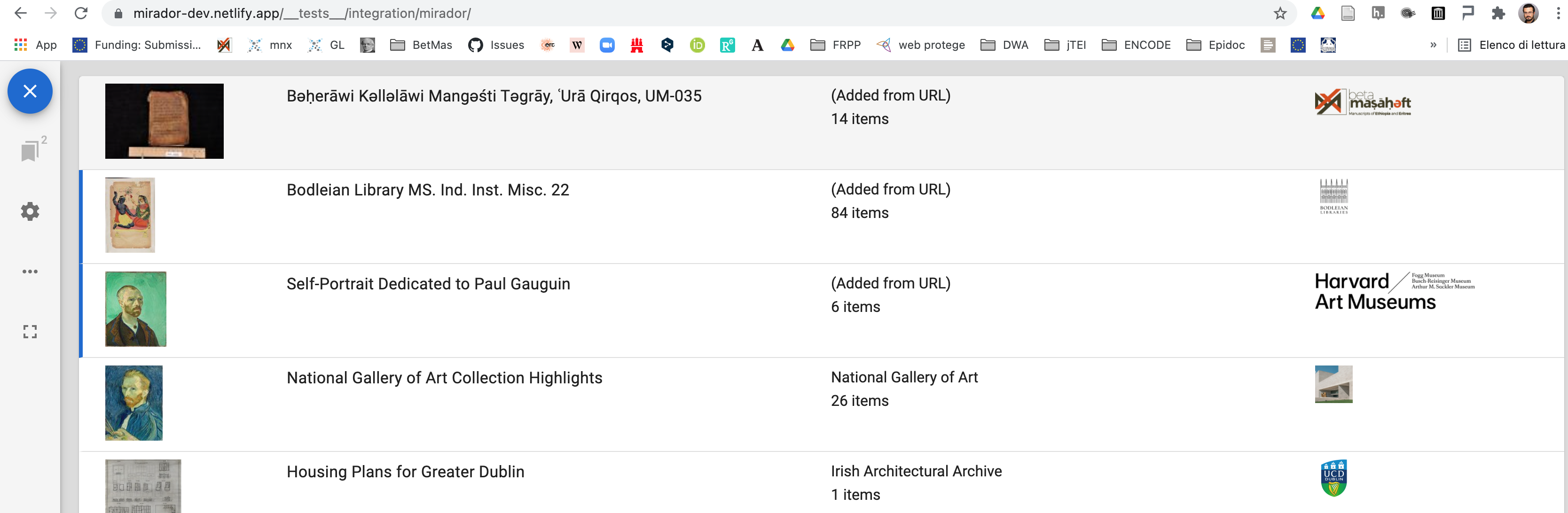
In the following image (Figure 1) I have loaded the above Manifest from its URL into the demo page of the Mirador viewer.
Figure 1: Images of Bǝḥerāwi Kǝllǝlāwi Mangǝśti Tǝgrāy, ʿUrā Qirqos, UM-035 loaded in the demo Mirador viewer (https://projectmirador.org/).
Similarly the Distributed Text Services API Specifications describe ways to present information in jsonLD about collection of texts, which can be literary works, canonical collections of works, inscriptions, letters, papyri or any other type of text.[5] It defines a specification for the presentation of such collections, one for the navigation of the structure of such text (chapters, lines, pages, etc.) and one to retrieve the correct section of a text from a specific reference to a part of it. The Collection API allows a consumer of the API to find out what collections of texts are served by the provider. The navigation API, for a given resource in that collection will tell which possible references are available and how the text is structured. With the Document API, if a client asks for Chapter 1 of the Iliad in a given edition presented by the provider, it will be returned the corresponding text. The three specifications are closely related, but do not need to be all implemented.
If, for example, I ask for the portion of a text in a manuscript running from folio 1 verso, column 2, line 5 to folio 34 recto, column 1 line 15, using references in a format like 1vb5-34ra15, the existence of which I have learned from a request to the navigation API, I will be returned from the document API that portion of the transcription of the text on the manuscript. The navigation API lists possible passages, the document API resolves passages to the actual text. This provides a way to standardise and make usable collections of texts which are not reducible to a hierarchy of authored works and whose structure cannot be adapted always to books, chapters and paragraphs, while exposing in an explicit and standard way, their structure.
The contents of manuscripts are one such type of text, for which the possibility to refer unequivocally and unambiguously to that structure, that is to say, to point to the text, or the feature of the object occurring at folio X and line Y, is paramount to the description of the manuscript as object, as well as to all the philological and historical work which may be carried out using those descriptions, e.g. the critical edition of one of a specific portion of the content. Serving both these kinds of data, text of the transcription of manuscripts, as well as of edited literary works attested from the manuscript tradition, beside the images of the objects, via standard APIs, using linked data formats, is yet another way to give visibility and enhance accessibility of the manuscript culture of Ethiopia and Eritrea, now more then ever put in jeopardy by the current state of war.[6] Both implementations of these API specification, in the context of the Beta maṣāḥǝft collaborative research environment are based on two parallel presentations of the data entered by the community of collaborators, the source in TEI XML and a derived RDF representation.
The challenges and their solutions
Even if the RDF representation is the result of a transformation from the XML TEI
data,
it is already quite different from it and contains not only structures which can provide
different information, it contains in some respects more information. Consider the
following
example (@xml:base = https://betamasaheft.eu/).
<relation name="snap:SonOf" active="PRS10626ZaraY" passive="PRS3429DawitII"/>
When transformed by a rudimentary XSLT, making use of the prefixes defined in
<prefixDef>
(data2rdf.xsl)
in RDF this becomes
<rdf:Description rdf:about="https://betamasaheft.eu/PRS10626ZaraY">
<snap:hasBond rdf:resource="https://betamasaheft.eu/bond/snap:SonOf-PRS3429DawitII"/>
</rdf:Description>
<rdf:Description rdf:about="https://betamasaheft.eu/bond/snap:SonOf-PRS3429DawitII">
<rdf:type rdf:resource="http://data.snapdrgn.net/ontology/snap#SonOf"/>
<snap:bond-with rdf:resource="https://betamasaheft.eu/PRS3429DawitII"/>
</rdf:Description>
The SNAP Bond is inferred and materialised by the XSLT. So, the XSLT makes reasonable assumptions on the XML data and infer triples, necessary for the target specification (in this case the SNAP-DRGN model).[7] When these triples are stored, if a reasoner is active (which it is not yet in our current setting), this may allow to infer even more, for example transitive relations, so that for example "the grandson of" can be queried from a chain of transitive relations like "the son of the son of" without an explicit "GrandsonOf" relation being injected in the data from the XSLT, which would not be possible since the source XML only contains that one statement and does not know if there are others to be related or if the relation itself is a transitive property (which the ontology would know). Here SNAP is also smart in as far as snap:hasBond may be declared as a transitive property thus linking in all possible ways and deferring the type of such relation to the Class to which the bond is assigned. This highlights some abuse of the @name attribute in <relation> and of the Class name instead of the property within it which is only justified by the existence of the XSLT performing the transformation to the above RDF.
Without a reasoner benefiting from the ontology declarations I could access a more complete list of relations with an Xpath like the following.
//t:relation[starts-with(@name, 'snap:')][(@active|@passive)='PRS3429DawitII']
Running this Xpath on my collection of documents would not be different from running on the parallel dataset the following SPARQL query
PREFIX snap: <http://data.snapdrgn.net/ontology/snap#>
PREFIX bm: <https://betamasaheft.eu/>
SELECT DISTINCT ?p2
WHERE {
{bm:PRS3429DawitII snap:hasBond ?b1 .
?b1 snap:bond-with ?p2.}
UNION
{?p2 snap:hasBond ?b2 .
?b2 snap:bond-with bm:PRS3429DawitII}
}
I could then access the type of bond by getting the actual value of @name, in the Xpath or the Class of the Bond in the SPARQL. I get to know all the first level relations, and only those, and only because they are declared. I could similarly do an Xpath on a collection of files to get to know if a text contains another or is contained by another.
//t:relation[@name='saws:contains'][(@active|@passive)='LIT2072NewTes']
This would be able to tell me that the New Testament is contained in the Bible and that it contains the Gospels. I would find this out from the RDF data as well, or generically get to know about all texts which are contained and at the same time contain other texts with a SPARQL query like the following.
PREFIX saws: <http://purl.org/saws/ontology#>
PREFIX bm: <https://betamasaheft.eu/>
SELECT ?text2
WHERE {
?text1 saws:contains ?text2 .
?text2 saws:contains ?text3 .
}
But expanding the Xpath, or an XQuery to look for more than this would be tedious, while, If I had declared in my ontology that for us saws:contains is a transitive property, and told a reasoner about it, I could run a SPARQL query like
PREFIX saws: <http://purl.org/saws/ontology#>
SELECT *
WHERE {
?text1 saws:contains+ ?text2 .
}
This query would know and return in the results, that the Bible contains the Gospels although there is no such statement explicitly made, but the encoders only said that the Bible contains the New Testament and that the New Testament contains the Gospels. The query would also know that the Bible contains the Gospel of Luke, for example, because if a contains b and b contains c than a contains c and so on.
But let's imagine the reality: people do things in different ways. Let us say for example that one of the users said that the Bible contains the Gospel, but another said that the Gospel of Luke forms part of the Gospel, which is the same as saying that the Gospel contains the Gospel of Luke, but in a declarative word, is not the same. In my Xpath I would have to know that this can happen and my query would grow and grow with exceptions and possibilities. In my SPARQL query I would not have to care about the fact that while some of these relations are in the 'contains' directions, others are declared as 'forms-part-of' direction. To do this I would only have to declare the relevant properties as inverse (owl:inverseOf) and I would get the same list.
We do not do this yet, but the implementation already benefits from this setup. The reason why we are not yet exploiting this obvious advantage is on one side individual (I did not know how to set a reasoner) and on the other side is related to the implications of making this statements. Inferences are so easy to declare in an ontology that they are not to be taken lightly, there is a lot that we do not actually want to infer, so we are redesigning our ontology to be sure it infers only what we actually want to infer. Moving the logic into the data (after all, an OWL file for the ontology can be treated just like data using a special vocabulary, and can be written in XML) especially if this logic is part of the knowledge recorded so that it can become explicit when needed is a better idea than relying on the code to know things. On the other side the necessary knowledge of such ontology and of the query language makes the use of standardized APIs better and more usable compared to the provision of an endpoint only.[8]
International Images Interoperability Framework (IIIF) Presentation API
In providing IIIF Manifests based from TEI description of medieval manuscripts from
Ethiopia we are also producing RDF, serialized as json-LD to present a set of images
with
relation to the TEI description of the manuscript depicted in these images. Consider
the
following example from Bǝḥerāwi Kǝllǝlāwi
Mangǝśti Tǝgrāy, ʿUrā Qirqos, UM-035, where the collation of the manuscript,
encoded as a simple list of <item>s child of the TEI element
<collation> is transformed to a IIIF Range
<collation>
<list>
<item xml:id="q1">
<dim unit="leaf">7</dim>
<locus from="1r" to="7v"/>
I(7/fols. 1r-7v; s.l.: 1, no stub)
<note>The structure of quires can not be established with certainty due to the condition of the present Ms.</note>
</item>
<item xml:id="q2">
<dim unit="leaf">4</dim>
<locus from="8r" to="11v"/>
II(4/fols. 8r-11v).
</item>
</list>
</collation>
{
"label" : "Collation",
"ranges" : [ "https://betamasaheft.eu/api/iiif/ESum035/range/q1", "https://betamasaheft.eu/api/iiif/ESum035/range/q2" ],
"@type" : "sc:Range",
"@id" : "https://betamasaheft.eu/api/iiif/ESum035/range/quires"
}
The @xml:ids are used to construct URIs and the @id for the
IIIF Range labelled 'Collation' is made up and is consistent and existent only within
this
context, generated on the fly and not materialized anywhere or stored in a triplestore.
The
same consideration affecting the XSLT above, applies here to a XQuery, which, doing
the
reasoning that maps the TEI to the json-LD infers and injects in the presented data
the URIs
and is in fact their sole guarantee of existence. Here is an example, the bit of the
RESTxq
module which produce the Range above.
declare function iiif:rangetype($iiifroot as xs:string, $name as xs:string, $title as xs:string, $seqran as xs:anyAtomicType+){
map {
"@id":$iiifroot ||"/range/"|| $name,
"@type":"sc:Range",
"label": $title,
"ranges" : if(count($seqran) = 1) then [$seqran] else $seqran
}
};
Overlooking for a second my attempt to work around the serialisation as an array of
a
single value,[9] having this in the code means that if one day I wake up and change that
/range/ string to /r/ all my URIs will have lost persistence,
and yet the IIIF Manifest in the production environment will still be consistent and
usable,
because in that close world all URIs for ranges will change accordingly. Indeed this
is a
great advantage of serving API specifications with linked data built on the fly, compared
to
the almighty SPARQL Endpoint relying on data which stored somewhere.[10] A SPARQL query may have
expectations on the URIs format and may stop to work if this change is made in data
which
can be queried only in that way. Instead, leaving the construction on the fly of the
URIs to
the script makes the responses to a standard API request always consistent and the
client
will not have to care about their persistence either. This is one way in which, making
stable the format of the request instead of the URIs it contains, the vain claims
of
'persistence' of any URI may be abandoned, at least in same respects, in favour of
a more
realistic 'eternal ephemerality'.
The code however, although in this case it does not produce any new statement and it simply reorganizes existing data, cannot be said to be zero-impact, it constructs the data and if that single point fails or breaks in any way, even where the data is entirely safe and correct, it will impact access on all sides, an issue which is multiplied by the extensive usability of the produced presentations demonstrated above. But this is no news, it is a statement of the obvious affecting all code and all data in any context. It is in fact not only one or two identifiable lines which build the logic and inferences, it is the structure of the code itself which makes assumptions and works with them for a result.
Needless to say, this IIIF representation is an entirely different matter from that
of
the declaration of <surface>s and <zone>s within the
TEI. This is a declarative list of areas on a specific set of images, while the IIIF
Manifest is a presentation of that set of images. The content of attributes of a zone
may be
used to compute the URI pattern for a request to an IIIF Image API, which must be
present to
serve images.
Each TEI description of a manuscript and encoding of its text in our project is itself a highly collaborative effort. The example above, to date, involved at least seven persons, only counting the contributors to that single file and not those who edited related entities, bibliographic entries, etc. The file containing the manuscript description is edited by several contributors, and refers to several other entities in the database edited each by many contributors. Any presentation of that data will include some of that related information and thus exponentially increase the number or involved edits and contributors which are involved in the data presented in any given output.
This challenge is augmented in those cases where we may wish to link to an external
set
of images. We may match a collaborative description with a set of images which is
potentially elsewhere not bound to this description, so practically writing metadata
for a
resource out there. Consider for example Vatican City, Biblioteca Apostolica Vaticana, Aeth. 1. The images of this
manuscript are hosted and served via IIIF with a Manifest by the Digital Vatican Library
at
https://digi.vatlib.it/iiif/MSS_Vat.et.1/manifest.json. All we do is pre-load this
known
manuscript's Manifest into the Mirador viewer for the user of our description of the
manuscript. This Manifest cannot include any information which we have encoded in
our TEI
description. We know that a particular quire is at a particular position within the
manuscript, but the viewer
does not allow to navigate to that location, because the Manifest does not have a
range for
that, since it is not created starting from our description, which has been enriched
with that information. We could potentially build
another Manifest which points to the images at the Vatican library but is directly
based on our TEI description of the manuscript, but we do
not. One reason is, that we cannot make assumptions on the image set and its actual
structure. We
cannot do this even on the images and Manifests which we serve ourselves, actually,
because
curating the images in the first place is not an easy task, but in that case we take
our
chances. It would need regular human checking to be sure we keep being aligned to
an
externally served resource, so we gave up the enriched alternative Manifest. Still,
using a
@facs we can directly point to the relevant image or area of it from the
manuscript description.
Adding those attributes is, to say the least, tedious for any editor who does not want to give up the freedom of encoding directly, without any form-like interface.
Fortunately, the king of elements for manuscript description,
<locus> can be made to reason in terms of what is available in the TEI
file. A simple placement information like
<locus target="#27v1">
will have to be parsed and resolved to point to the correct <lb>
<pb n='27v'/>
...
<lb facs='#facs_15_line_1606762008880_11923' n='1'/>
This is achieved by regulating the content of the @target in the encoding
guidelines (referencing) as well as that of @from and @to so that
they match a referencing system, and parsing that consequently (locus.xqm).
The @facs in the corresponding placement reference will point to a
<zone> and from there all necessary bits of information to retrieve the
relevant part of the image will be available.
<surface xml:id="f27v" ulx="0" uly="0" lrx="2464" lry="1641">
<graphic url="https://betamasaheft.eu/iiif/Ham/1993/Eri_1993_025.tif/full/full/0/default.jpg" width="2464px" height="1641px"/>
<zone ulx='434' uly='186' lrx='1185' lry='1640' rendition='TextRegion' xml:id='facs_15_r1'>
<zone ulx='476' uly='191' lrx='1041' lry='301' rendition='Line' xml:id='facs_15_line_1606762008880_11923'/>
</zone>
</surface>
I have not even tried to convince anyone, my self in the first place, to type this down. We get it instead from Transkribus after running a Layout Analysis and fixing it with human input.[11]
To be able to offer a 'simple' functionality, namely, clicking on a placement information and seeing the relevant image, eventually moving to a viewer where this is in its context, requires not only curated data but also curated and controlled scripts which make assumptions which cannot be ignored by the users. Programming that in XQuery or XSLT may be one way to make it more readable to the same users of the data and its visualization.[12] XQuery (and indeed also XSLT and XPath, and X-languages in general) are readable enough and familiar enough to large communities of practice in the humanities, if not explicitly designed for these users.[13]
Rarely we only want to see the images. We want to navigate a set of images coming from a description of an artefact or get from that description straight at an image of interest without having to page through in the viewer until we reach it. To do this we need the XML, we need the IIIF Images and Presentation API and the XQuery producing these presentations and making the connection, we need a client application supporting this, like Mirador. Alone, neither the data or the Manifest, or the API, or the application achieve the task.
It may be more obviously useful to implement and use an API for images than it is for texts. After all, we have HTTP protocol and eventually XML and HTML just for that... but there is a lot more to be gained by applying the same models of implementation to the presentation of features of the structure of texts. And that may be part of what a TEI encoded text has to say for the structure of a text, but not for the structure of a collection of texts, which remains often a matter of organization of the system where the TEI files are organized, stored, and indexed.
The Distributed Text Services API specifications (DTS)
Architecture: not all is in one TEI file
What 'texts' to serve? The 'diplomatic' transcription of the manuscript? The edition? Of which version? Some relations among textual units in a corpus of ancient literature cut across several languages, periods and interests making the organization efforts of a 'library' clash with reality. Ancient translations, versions of the same 'work' which had their own independent history, collections of smaller units varying in size and scope, summaries, etc. The ancient idea of text was just very different from our own. It is not possible to order ancient texts by title or by author. It is not possible to organise them in a fixed hierarchies without forcing them. What is available instead is a network of relations. Establishing explicit and individual relationships between variously identified units allows to organise ancient literature the way we know it without adding on it the hierarchies which are instead more typical of printed literature. And if we do not know and cannot say anything, we can just do so and let an unidentified text be such without needing to enter a group of other 'similar' items.
For example, a textual unit, that is to say a work, in a more generic sense,[14] may form
part of several other textual units, like in the following example, retrieved searching
for records with two <relation> elements with a
@name='saws:formsPartOf'
<listRelation>
<relation name="saws:formsPartOf" active="LIT4615Salam" passive="LIT1968Mashaf"/>
<relation name="saws:formsPartOf" active="LIT4615Salam" passive="LIT3575Mashaf"/>
</listRelation>
In an HTML view as well as in another type of output, we can play with this and
present the information, relying on the accessibility for our scripts of the information
linked. The script will know what to do with 'LIT1968Mashaf'. Also the TEI consumer
will
be able to resolve with @xml:base to https://betamasaheft.eu/LIT1968Mashaf
and will be redirected to the landing page for that item. But the script knows more
and
given knowledge of what to expect in that context, namely the identifier of a textual
unit
may be able to fetch its canonical title for example.
Figure 2: Forms part of...

The XQuery doing this knows a great deal about the database structure, its indexes, the desired output. What about the poor client who does not have all these modules and does not want to scrap the HTML to rebuild this information? We could enrich our RDFa support, that is one thing. However, passing on this type of information in the response to a standard request to an API, allows the machine as well as the human to follow those links and allow them to structure the navigation of the collection. This is what the DTS Collection Specification also supports. We have rather some code to expose that in the same way in which the above HTML view is produced, to serve those clients.
Because these XML tags are passed on to the RDF as described above, the graph of relations can be queried from the XQuery building the response to the API request specified by the DTS API, and they can be included in the output json-LD. A function (here) will loop through a list of relations and query for them the triplestore.
declare function dts:sparqls($id, $property){
let $querytext := $config:sparqlPrefixes || "SELECT ?x
WHERE {bm:" || $id || ' '|| $property||" ?x }"
let $query := dts:callfuseki($querytext)
return
$query//sr:binding[@*:name='x']/sr:*/text()
};
The dts:callfuseki() function here will simply send an HTTP request to
the port where Apache Jena Fuseki is running with the SPARQL query constructed, and
iteratively populate a map, for example:
"dts:extensions" : {
"saws:formsPartOf" : "https://betamasaheft.eu/LIT2384Taamme"
}
If this extension is exposed by the client of the API, The browsing of the relations between textual units, which are listed by the collection API as a flat list, becomes an actual way to pass from one to the other textual unit without any additional organizational filters. We stick to a plain list and this relations to give it depth and structure, so that the machine client may have at least the same ways to distinguish a link from another link as the human has.
Multiple hierarchies of citation
As well as multiple relations and hierarchies of texts, there are also multiple
'canonical' citations, multiple editions, and multiple citations structure which,
depending on the type of context will be resolved by a human reader to a portion of
a
given text. The example above, of a transcription of a manuscript involves only one
such
structure, articulated with <pb>, <cb>, and
<lb>, but consider the following example.
<div type="edition" xml:lang="gr" resp="#frisk">
<head>
<surplus>ΑΡΡΙΑΝΟΥ</surplus>
ΠΕΡΙΠΛΟΥΣ ΤΗΣ ΕΡΥΘΡΑΣ ΘΑΛΑΣΣΗΣ
</head>
<div type="textpart" subtype="chapter" n="1" xml:id="chapter1">
<ab>
<pb n="1" corresp="#frisk"/>
<pb n="51" corresp="#casson"/>
<pb n="257" corresp="#mueller"/>
<pb n="9r" corresp="#L"/>
<pb n="40v" corresp="#P" facs="https://digi.ub.uni-heidelberg.de/diglit/iiif/cpgraec398/canvas/0084.json"/>
Τῶν ἀποδεδειγμένων ὅρμων τῆς
<placeName ref="pleiades:39290">Ἐρυθρᾶς θαλάσσης</placeName>
καὶ τῶν περὶ αὐτὴν ἐμπορίων πρῶτός ἐστιν λιμὴν
...
</ab>
</div>
Here I have encoded several page breaks of editions (the @corresp points
at the @xml:id of a <bibl>). I may certainly refer to this
as 'chapter 1' or '1', but I may also refer to page 51 of Casson's edition of page
257 of
Muller's to refer to the same passage. Another similar issue is that of the way in
which a
given part of a work is referred to. The first paragraphs of a liturgical text may
contain
a commemoration for a certain Saint to be done on a given day of a month. I may refer
to
this as the commemoration for that Saint, that for the Day or as the first paragraph,
depending on the audience or simply on convenience.
<div type="textpart" subtype="chapter" n="1" xml:id="Maskaram">
...
<div type="textpart" subtype="chapter" xml:id="MaskIntroduction">
...
</div>
<div type="textpart" subtype="chapter" xml:id="Mask1">
<div type="textpart" xml:id="Mask1Beginning">
...
</div>
<div type="textpart" subtype="commemoration" xml:id="Mask1Job">
...
</div>
<div type="textpart" subtype="commemoration" xml:id="Mask1Bartolomewos" corresp="NAR0017SBartalomewos">
...
</div>
...
</div>
...
</div>
a reference to 'chapter 1', should resolve to an XPath like div[@n='1']
a reference to 'the second commermoration of the first day of Maskaram' should also
resolve to
div[@type='commemoration'][2]/parent::div[@xml:id="Mask1"]/ancestor::div[xml:id="Maskaram"]
in the same way as an hypothetical reference. The resolver of this reference needs
to be
able to map it to the correct piece with as few assumptions as possible about what
the
editor will have decided to be the relevant structures and names for its text and
what the
client will have picked among those to provide a pointer. Here we have again a place
where
the code needs to be savvier then we would like it to be if we assume code needs to
be as
generic as possible. A regex is stored (could be actually kept within the TEI with the existing
appropriate elements)[15] and a function does its best to match, given a priority order what
it could refer to piece by piece, building XPaths which are able to match any potential
structures. The following is an example from the module of such constructor for a
part of
an XPath
"/(t:div|t:cb|t:pb|t:lb|t:l)[(@xml:id|@n)='"|| $r/text()||"' or contains(@corresp,'"||$r/text()||"')]"
The reference used could be the @corresp to the Narrative Unit
identifying the commemoration of Bartolomewos without identifying a specific text,
as this may occur within differnt types of texts, in different forms, sometimes as
edited text, sometimes only as transcription.
This is indeed a legitimate, if not the most common reference used, as will also be
shown
below in the Collatex example Figure 8.[16]
The XQuery is able, within the exist-db setup for the redirection and parsing of the
requested URI, to get a variety of possibly encoded structures and return the correct
text. If we had a <citeStructure> in our TEI data, we could achieve the same from
an
explicit declaration (Cayless et al. 2021), but it is still often the case that we only have parts of text and that the encoding
is in slow but constant progress so that such a declaration is not yet possible.
The DTS Navigation API, will however only at the moment present
one of them. The Collection API request for a textual unit like the one identified
by LIT4032SenkessarS,[17] can be retrieved starting from the HTML view at
https://betamasaheft.eu/works/LIT4032SenkessarS/main clicking on the VoID (Vocabulary of
Interconnected Datasets) and then selecting the value of
void:uriLookupEndpoint, that is
https://betamasaheft.eu/api/dts/collections?id=https://betamasaheft.eu/LIT4032SenkessarS.
Here the DTS Collection API tells us of the structure of the text, namely that there
are
textparts, which contain chapters which can contain subscriptio, commemoration and
supplication. also this names are given by the encoder and selected by the script
according to a series of alternative priorities for each element used in the
encoding.
"dts:citeStructure" : [ {
"dts:citeStructure" : [ {
"dts:citeStructure" : null,
"dts:citeType" : "chapter"
}, {
"dts:citeType" : "subscriptio"
}, {
"dts:citeType" : "commemoration"
}, {
"dts:citeType" : "supplication"
} ],
"dts:citeType" : "textpart"
} ]
Here we learn of what we may expect, not yet of the actual stuff available. Moving on to the DTS Navigation API with https://betamasaheft.eu/api/dts/navigation?id=https://betamasaheft.eu/LIT4032SenkessarS I am told what is available to begin with, as top structure
{
"dts:citeType" : "unit",
"dts:dublincore" : {
"dc:source" : [ {
"@type" : "sc:Range",
"@id" : "https://betamasaheft.eu/api/iiif/BNFabb66A/manifest"
}, {
"@type" : "sc:Range",
"@id" : "https://betamasaheft.eu/api/iiif/BNFabb66B/manifest"
}, {
"@type" : "sc:Range",
"@id" : "https://betamasaheft.eu/api/iiif/BNFet677/manifest"
} ],
"dc:title" : "First half of the year"
},
"dts:ref" : "FirstHalf"
}
Here, where you can see how the IIIF manifests are also related to the reference (also
in the next example, with reference to the correct Ranges), I can then use levels,
and I know from dts:citeDepth how many are available, to navigate different levels of structure or I can point
to one of the available dts:ref to see what it contains. Since I know already that the commemorations are the fourth
level, I can request https://betamasaheft.eu/api/dts/navigation?id=https://betamasaheft.eu/LIT4032SenkessarS&level=4
and get the following among the members of this level of citation
{
"dts:citeType" : "commemoration",
"dts:dublincore" : {
"dc:source" : [ {
"@type" : "sc:Range",
"@id" : "https://betamasaheft.eu/api/iiif/BNFabb66A/range/ms_i1.1.1.3"
}, {
"@type" : "sc:Range",
"@id" : "https://betamasaheft.eu/api/iiif/BNFabb66A/range/ms_i1.1.1.4"
}, {
"@type" : "sc:Range",
"@id" : "https://betamasaheft.eu/api/iiif/BNFabb66B/manifest"
}, {
"@type" : "sc:Range",
"@id" : "https://betamasaheft.eu/api/iiif/BNFet677/manifest"
} ],
"dc:title" : "Sǝnkǝssār commemoration of Bartalomewos"
},
"dts:ref" : "FirstHalf.1.Mask1.Mask1Bartolomewos"
}
Using the dts:ref I can then request the passage with https://betamasaheft.eu/api/dts/navigation?id=https://betamasaheft.eu/LIT4032SenkessarS&ref=FirstHalf.1.Mask1.Mask1Bartolomewos
and its text from the DTS Document API, which, if nothing different is stated and
supported, should default to return the above XML in a <dts:fragment>. Eventually, other formats of reference known and inferable by the encoder, or user,
e.g. https://betamasaheft.eu/api/dts/navigation?id=https://betamasaheft.eu/LIT4032SenkessarS&ref=NAR0017SBartalomewos
using the @corresp instead of the @xml:id, would have worked just the same, but the API does not need to declare all the available,
it tells its favourite as one option among many valid ones, while the code need to
be gentle in accepting any format of request.
This is all very experimental and new, it works only to an extent in this implementation and makes far too many assumptions in the code, some of which may just be plain wrong, but I hope that the features and usefulness of this to match the actual encoding of texts in a varied and complex collection, still allowing yet a higher level of interoperability, passing on to the consumer of the API as much complexity as possible. Paradoxically, the presence of multiple texts and translation of a single identified unit is in this context the simplest bit. The result is needless to say, shaky. Too many uncertainties, too many assumptions in the code. As we prefer mindless scribes because less prone to make changes, also mindless code should be a nicer acquaintance for the codicologist and philologist.
Joining in one dataset the information which can only queried from the XML
As already seen in the example above, one example where this data exposes connections to machines requesting it in a readily available way, is the list of witnesses of a given textual unit. In our TEI the declaration that a given content is into a manuscript is made within the TEI-based catalogue description of that manuscript. Therefore the list of the manuscripts which contain a text is the result of an XQuery in the database for those entries, it is not encoded in the TEI file describing the textual unit.[18]
<msItem xmlns="http://www.tei-c.org/ns/1.0" xml:id="ms_i1">
<locus from="2r"/>
<title type="complete" ref="LIT1957Mashaf" xml:lang="gez">ቀሌምንጦስ፡</title>
<textLang mainLang="gez"/>
</msItem>
For a given textual unit LIT1957Mashaf I will go query all TEI files which have a
<msItem> with a @ref pointing to it as in the example
above. Because of what we said above, this is not quite it. If my LIT1957Mashaf is
a part of
another textual unit, and that is attested in the <msItem> I also want
those manuscripts. The HTML presents these results with text to read
the list of possible witnesses computed for a textual unit. The DTS API implementation
instead presents that as part of the data, querying it similarly behind the scenes.
"dc:source" : [ {
"fabio:isManifestationOf" : "https://betamasaheft.eu/BLorient751",
"@type" : "lawd:AssembledWork",
"@id" : "https://betamasaheft.eu/BLorient751",
"dc:title" : "London, British Library, BLorient 751"
}, {
"fabio:isManifestationOf" : "https://betamasaheft.eu/BLorient772",
"@type" : "lawd:AssembledWork",
"@id" : "https://betamasaheft.eu/BLorient772",
"dc:title" : "London, British Library, BLorient 772"
}, {
"fabio:isManifestationOf" : "https://betamasaheft.eu/BLorient753",
"@type" : "lawd:AssembledWork",
"@id" : "https://betamasaheft.eu/BLorient753",
"dc:title" : "London, British Library, BLorient 753"
}, {
"fabio:isManifestationOf" : "https://betamasaheft.eu/BLorient752",
"@type" : "lawd:AssembledWork",
"@id" : "https://betamasaheft.eu/BLorient752",
"dc:title" : "London, British Library, BLorient 752"
} ]
Indexes and clients
But without concrete use cases, it would be useless to develop APIs. While the viewer above demonstrates in one of the possible uses of the IIIF Presentation API, I will provide here three examples of currently-under-development or proposed uses of the DTS APIs in our project.
Beta maṣāḥǝft text navigation
Needless to say, we use the DTS API to navigate the transcriptions of manuscripts and the editions of texts which we have. Even if they are partial, as in most cases. Let me say, especially if they are partial or incomplete, we know is a bit of generously encoded structure of the text, e.g. an incipit. This is the norm and not the exception for us, although the collaborative set up as allowed many contributors to share what they have with the rest of the interested parties. Let me first discuss the navigation of a manuscript, which is more standard, as it is defined by the object itself and not by the structure of the intellectual content. We extract transcriptions using Transkribus, as noted above. The following example thus does not contain a guaranteed correct transcription in Ethiopic. The structure of the text, between folia, columns and lines should instead be correct and has been double checked before exporting the results of the Hand-written Text Recognition step. In the sequence of images we see the navigation from folio, to side, to column, to line in the column for the first line of the second folio, recto of Bǝḥerāwi Kǝllǝlāwi Mangǝśti Tǝgrāy, ʿUrā Qirqos, UM-035.[19]
Figure 3: All text of the transcription of the manuscript

Figure 4: Navigating to Folio 2, https://betamasaheft.eu/ESum035.2

Figure 5: Folio 2, recto, https://betamasaheft.eu/ESum035.2r

Figure 6: Folio 2, recto, column a, https://betamasaheft.eu/ESum035.2ra

Figure 7: Folio 2, recto, column a, line 1, https://betamasaheft.eu/ESum035.2ra1

The navigation is relative to the first available upper level and should allow to navigate within the text. This is rather expensive and time consuming but as a prototype allows us for example to point to exact pieces of text with a simply URL structure and return the correct text. This is also helpful to discover relevant passages. This is useful for example when comparing different manuscript witnesses of a same text. As seen above we can reach the correct places in the description of the content, these will contain the placement of the information and that we can use to resolve to the exact piece of text requested. If a given passage where the text in question occurs is known, then it can be pointed to using this same syntax, even if the description of the manuscript is not complete yet with that information. Alternatively a user could propose a change for the entry, clicking the EDIT button which redirects to GitHub, and add that bit of XML.
Figure 8: Collatex used to collate passages of text retrieved from DTS script, jumping the API
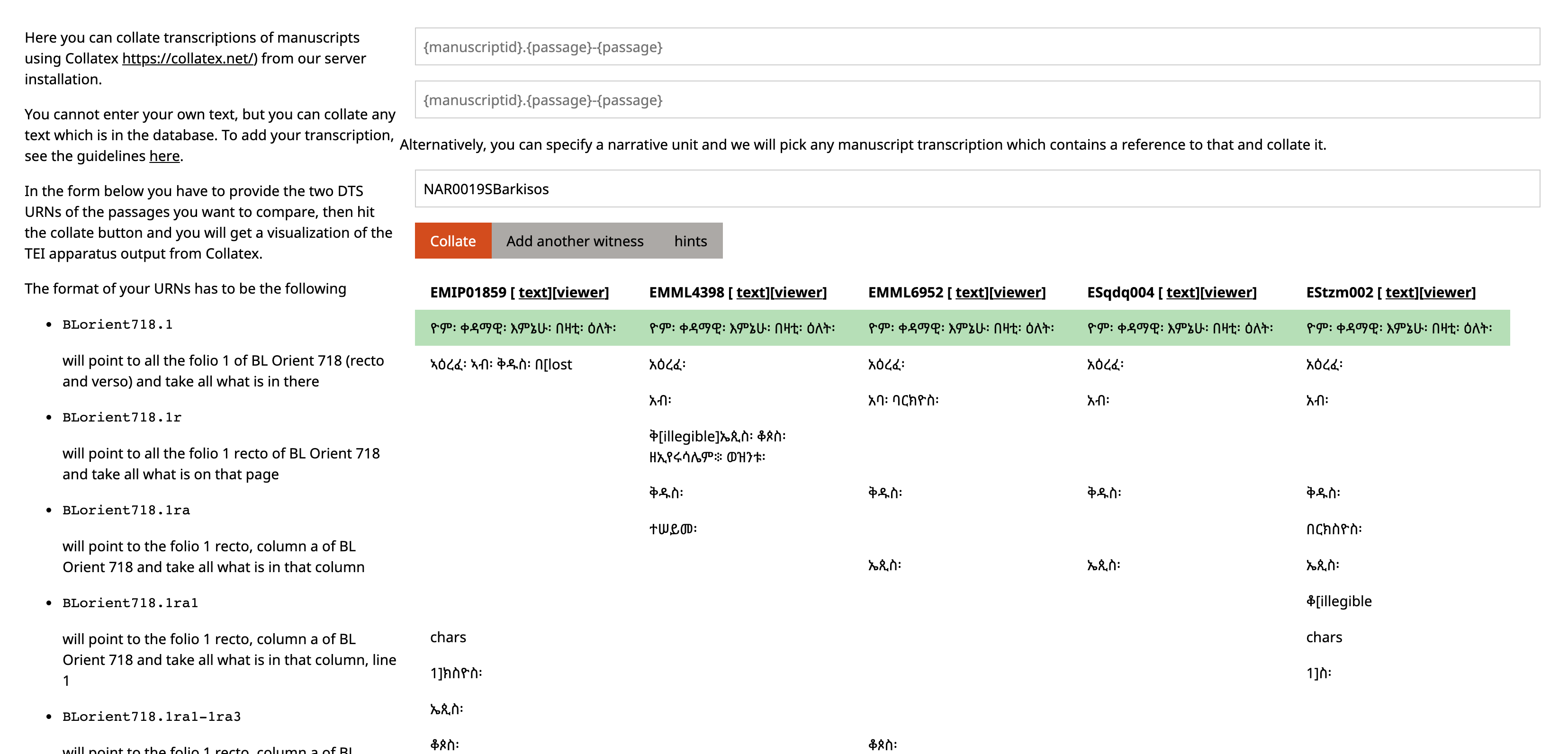
In this case the application does not consume the DTS API, it jumps directly to the XQuery functions fetching the correct portions of text from the parsing of the reference, transforms them into comparable strings, strips of some punctuation and then presents the results provided by passing those normalised strings to Collatex.[20]
How nice, if that could be done starting from a DTS endpoint so that one could collate passages from data stored in different source databases, eventually in different ways and formats. A functionality similar to that implemented for Alpheios, described below, would allow to collate transcriptions of manuscripts hosted by diverse institutions in the same way in which the Mirador viewer allows its users to see side by side sets of images coming from different providers. And if that collation and the linked IIIF parts could go hand in hand, we could have a generic editor for images and texts, based on solid jsonLD-based standards. But both in this case and the previous actually our application has no reasons to consume its own API, it uses instead the same XQuery functions which are used by the API directly.
Web Annotation indexes
What is an entry into an index of places or persons if not a list of occurrences formatted as a, possibly resolvable, reference to the main structure of the text? Annotations exist in the text for personal names and toponyms marked up in TEI, and querying them together with their context is a fairly easy job for an XQuery script. So, if we can fetch from DTS our table of contents, the contents in the correct order with correct references flexibly adjusted according to the text itself and its author and encoder, we may in the same way fetch a list of marked terms of a given kind, e.g. toponym and produce our indexes by providing an ordered list of these and the corresponding pointer to their context in terms of navigation. Eventually, a script-based index allows us to alter the context and produce indexes from the same annotations for outputs or views which are different. The Distributed Text Services does not have a specification for this,[21] but I suggested that this would complete, with IIIF, the resources needed to be able to produce API based book products for example, dynamically generated from the collaboratively edited data. Similarly a citation of a passage in another text, encoded like in the following example,
<ref cRef="betmas:LIT2000Mazmur.101.7">
ተመሰልኩ፡
<app>
<lem wit="#D #E #F">ጰልቃን፡</lem>
<rdg wit="#M #V">ጳልቃን፡</rdg>
</app>
ዘገዳም።
</ref>
could be unpacked into a series of meaningful informations for a client which is navigating the index, using the Web Annotation standards, like in the example below, which is extracted from the GitHub issue linked above.
{
"body": [
{
"text": "ተመሰልኩ፡ ጰልቃን፡ ጳልቃን፡ ዘገዳም።",
"@lang": "gez",
"role": "ref",
"id": "https://betamasaheft.eu/LIT2000Mazmur.101.7"
}
],
"@context": "http://www.w3.org/ns/anno.jsonld",
"target": {
"source": {
"dts:citeType": "sentence",
"dts:level": "1",
"dts:citeDepth": 2,
"dts:passage": "/api/dts/document?id=https://betamasaheft.eu/LIT4916PhysB&ref=4.2",
"type": "Resource",
"link": "https://betamasaheft.eu/LIT4916PhysB.4.2",
"id": "https://betamasaheft.eu/LIT4916PhysB",
"dts:ref": "4.2",
"dts:references": "/api/dts/navigation?id=https://betamasaheft.eu/LIT4916PhysB&ref=4.2"
},
"selector": {
"@value": "TEI/text/body/div[2]/div/div[2]/ab/ref",
"type": "XPath"
}
},
"type": "Annotation"
}
In the body of the annotation, I can count on the ability of the server to unpack
the
@id, from https://betamasaheft.eu/LIT2000Mazmur.101.7 to
https://betamasaheft.eu/works/LIT2000Mazmur/text?ref=101.7 which uses the same parameter
of the DTS specification to pass on to the client requests related to the passage
and the
collection. Also the target of the annotation is enriched with a series of information
which provide navigation assistance, including the XPath selector, with one among
the many
possible Xpath to the node which constitutes the annotation (<ref> in
this case). Both if I am looking at a wider collection of texts or I am focusing on
a
portion of an identified text, I can produce on the fly indexes of declared features.
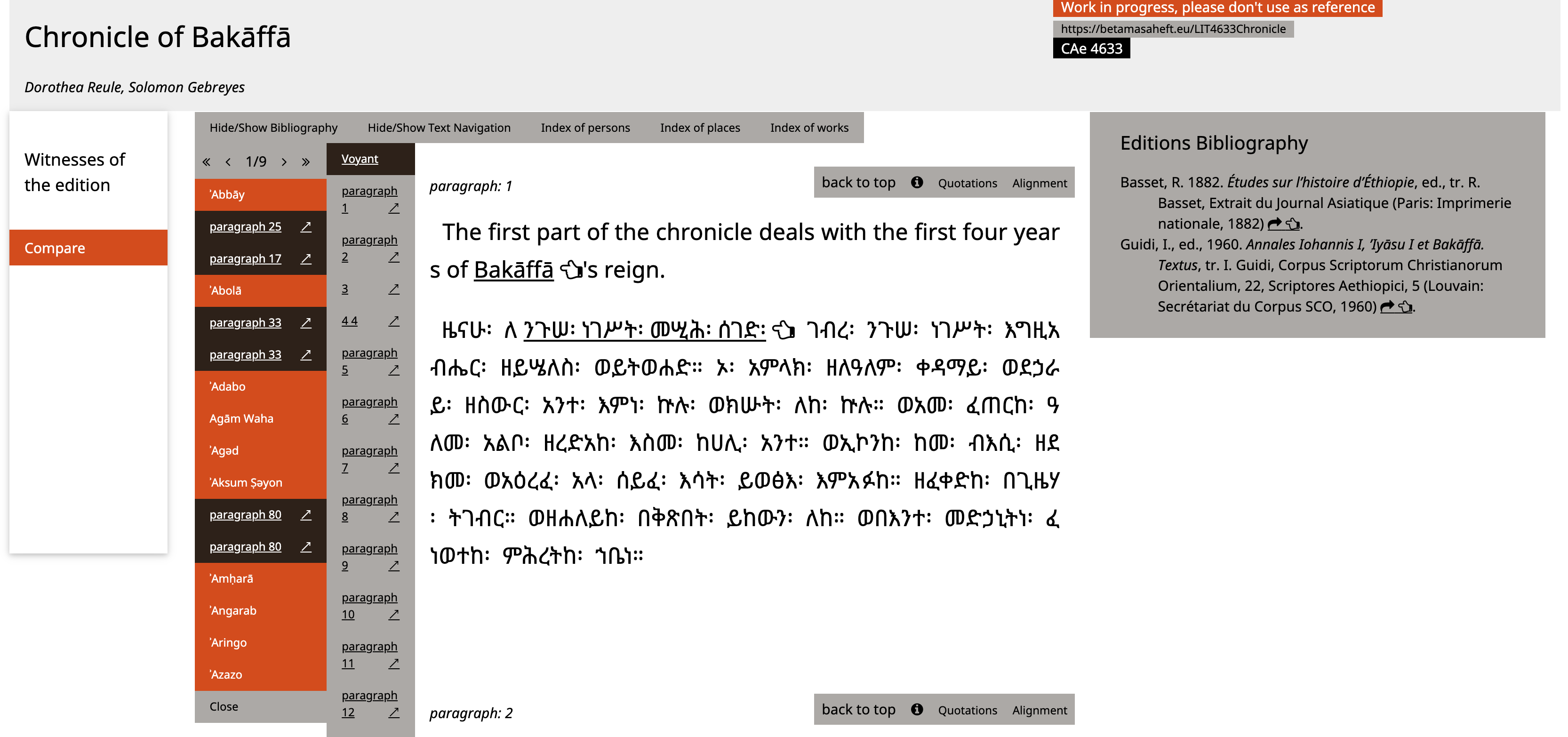
For
example in the image below, the index of places is loaded besides the navigation bar
for
the Chronicle of Bakāffā[22]
Figure 9: The index of places beside the navigation of the text structure in the Chronicle of Bakāffā.
Alpheios Alignment
I would like to conclude with an example of an external client for the DTS services, the Alpheios Alignment tool (Version 2), which has just been developed by The Alpheios Project.[23] The first version of the Alpheios tool for the alignment of texts in different languages was improved so that texts may be uploaded from source, with copy paste or from DTS API. Available implementations include Alpheios' own collection of Greek and Latin texts and the Beta maṣāḥǝft implementation. In the following images you can see how the interface leads through different requests to the API to select the text which is then loaded and prepared for alignment.
Figure 10: Loading a text in Alpheios from a DTS API.
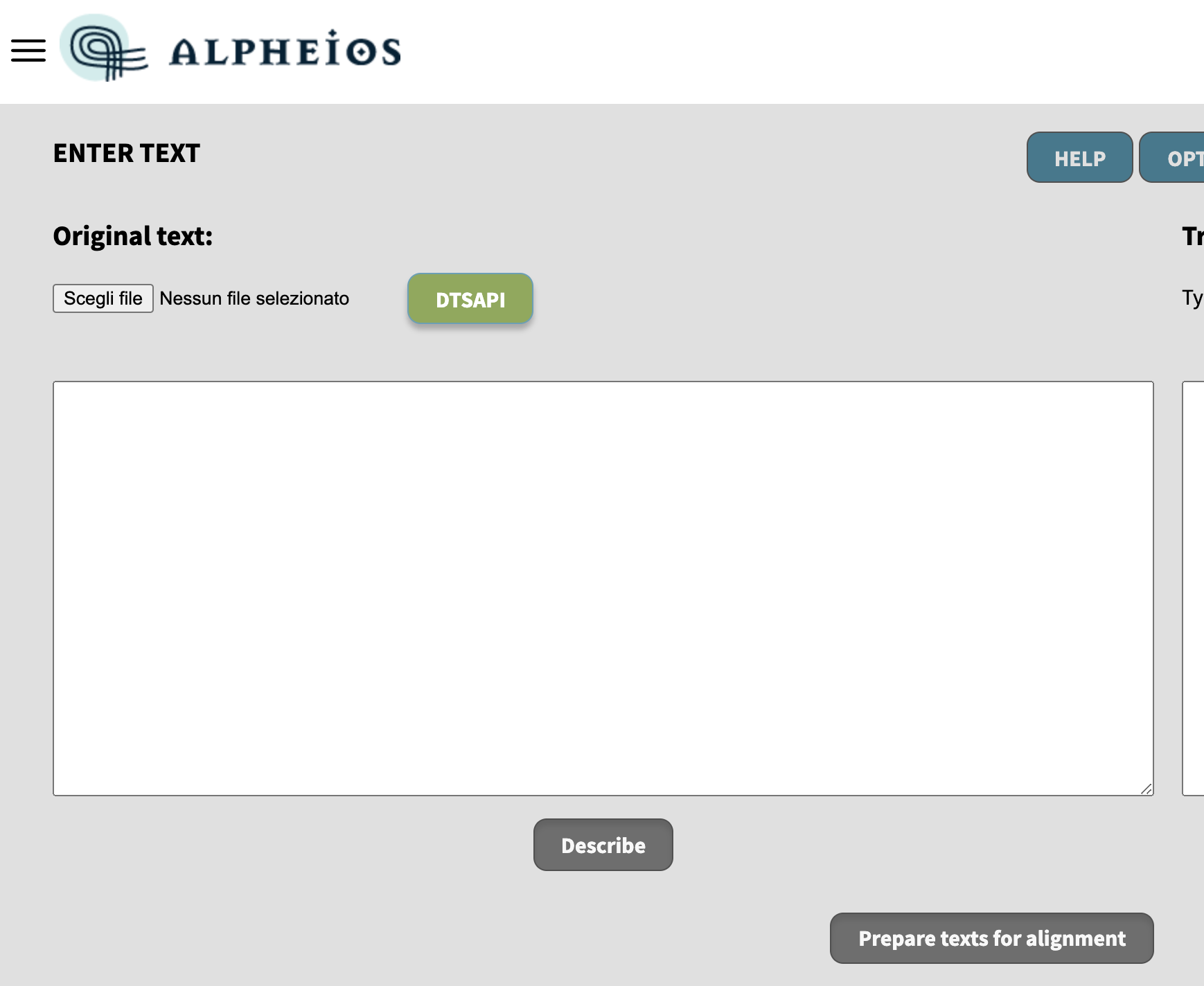
Figure 11: Navigating the Collection API
Figure 12: Available passages (folia) from the Navigation API
Eventually a DTS 'Search' functionality could be added to load a collection which is a subset of entries coming from a query, so not all resources with some text, but all resources with some text and a match for a given string query. This would need a parameter for this query string to be added to the specification, which has not yet been proposed.
The json export of alignment will be then transformed to TEI for inclusion in the BM data repository and eventually the annotation thus created fed into a set of existing morphological annotations and texts.
Conclusion
I hope I have demonstrated in practice some of the aspects of the XQuery implementation serving the DTS and IIIF API specification for the Beta maṣāḥǝft project. While I think the DTS API specification are the most innovative and promising development, they are still very much a 'Baustelle' but I think that their potential is self evident and I look forward to more and more implementations and texts. These can be added also to Matteo Romanello's DTS Aggregator (https://github.com/mromanello/aggregator) and become immediately available also in the experimental DTS Browser (https://dts-browser.herokuapp.com/).
References
[Almas et al. 2021] Almas, Bridget, Thibault Clérice, Hugh Cayless, Vincent Jolivet, Pietro Maria Liuzzo, Matteo Romanello, Jonathan Robie, and Ian W. Scott. 2021. ‘Distributed Text Services (DTS): A Community-Built API to Publish and Consume Text Collections as Linked Data’. https://hal.archives-ouvertes.fr/hal-03183886.
[Clifford and Wicentowski 2020] Anderson, Clifford B., and Joseph C. Wicentowski. 2020. XQuery for Humanists. College Station, Texas: Texas A & M Univ Pr.
[Bodard 2021] Bodard, Gabriel. 2021. ‘Linked Open Data for Ancient Names and People’. In Linked Open Data for the Ancient Mediterranean: Structures, Practices, Prospects, edited by Sarah E. Bond, Paul Dilley, and Ryan Horne. Vol. 20. ISAW Papers. http://hdl.handle.net/2333.1/zs7h4fs8.
[Cayless et al. 2021] Cayless, Hugh, Thibault Clérice, and Jonathan Robie. 2021. ‘Introducing Citation Structures’. Presented at Balisage: The Markup Conference 2021, Washington, DC, August 2 - 6, 2021. In Proceedings of Balisage: The Markup Conference 2021. Balisage Series on Markup Technologies, vol. 26. doi:https://doi.org/10.4242/BalisageVol26.Cayless01.
[DTS] ‘Distributed Text Services API Specification’. 2018. https://w3id.org/dts/.
[The Guardian 24 January 2021] ‘Fabled Ark Could Be among Ancient Treasures in Danger in Ethiopia’s Deadly War’. 2021. The Guardian. 24 January 2021. http://www.theguardian.com/world/2021/jan/24/fabled-ark-could-be-among-ancient-treasures-in-danger-in-ethiopias-deadly-war.
[Liuzzo 2017] Liuzzo, Pietro Maria. 2017. ‘Encoding the Ethiopic Manuscript Tradition: Encoding and representation challenges of the project Beta maṣāḥǝft: Manuscripts of Ethiopia and Eritrea’. Presented at Balisage: The Markup Conference 2017, Washington, DC, August 1 - 4, 2017. In Proceedings of Balisage: The Markup Conference 2017. Balisage Series on Markup Technologies, vol. 19. doi:https://doi.org/10.4242/balisagevol19.liuzzo01.
[Liuzzo 2019] Liuzzo, Pietro Maria. 2019. Digital Approaches to Ethiopian and Eritrean Studies. Supplement to Aethiopica 8.
[Beta Maṣāḥǝft Data] Liuzzo, Pietro Maria, Solomon Gebreyes, and Dorothea Reule. 2020. ‘Beta Maṣāḥǝft TEI-XML Data’. UHH Data Notes 1. doi:https://doi.org/10.25592/DANO-01-001.
[Beta Maṣāḥǝft Guidelines] Liuzzo, Pietro, Dorothea Reule, Eugenia Sokolinski, Solomon Gebreyes, Daria Elagina, Denis Nosnistin, Eliana Dal Sasso, and Jacopo Gnisci. 2018. ‘Beta Maṣāḥǝft Guidelines’. 2018. https://betamasaheft.eu/Guidelines/. http://dx.doi.org/10.25592/BetaMasaheft.Guidelines
[Retter 2012] Retter, Adam. 2012. ‘RESTful XQuery: Standardized XQuery 3.0 Annotations for REST’. In XML Prague 2012: Conference Proceedings, University of Economics, Prague, Czech Republic, February 10–12, 2012, 91–123.
[Reule 2018] Reule, Dorothea. 2018. ‘Beta Maṣāḥǝft: Manuscripts of Ethiopia and Eritrea’. In COMSt Bulletin, edited by Alessandro Bausi, Paola Buzi, Pietro Maria Liuzzo, and Eugenia Sokolinski, 4/1:13–27.
[Siegel and Retter 2015] Siegel, Erik, and Adam Retter. 2015. EXist: A NoSQL Document Database and Application Platform. Sebastopol, CA: O’Reilly.
[Waal 2021] Waal, Alex de. 2021. ‘Steal, Burn, Rape, Kill’. London Review of Books, 17 June 2021. https://www.lrb.co.uk/the-paper/v43/n12/alex-de-waal/steal-burn-rape-kill.
[1] The TEI-Publisher (https://teipublisher.com/) has, among many other features, its own support for a DTS Collection API out of the box.
[2] For RESTxq see Retter 2012 and Siegel and Retter 2015.
[3] https://iiif.io/api/presentation/2.1/#status-of-this-document
[4] https://betamasaheft.eu/ See also Liuzzo 2017 and more recently Liuzzo 2019, and a brief description of the underlying data in Beta Maṣāḥǝft Data. This is a long-term project funded within the framework of the Academies' Programme (coordinated by the Union of the German Academies of Sciences and Humanities) under survey of the Akademie der Wissenschaften in Hamburg. The funding will be provided for 25 years, from 2016–2040. The project is hosted by the Hiob Ludolf Centre for Ethiopian Studies at the Universität Hamburg. It aims at creating a virtual research environment that shall manage complex data related to the predominantly Christian manuscript tradition of the Ethiopian and Eritrean Highlands. My participation to the conference, the writing of the code discussed and of this article are supported by this project, which I would like to acknowledge here.
[5] https://distributed-text-services.github.io/specifications/ DTS. See also Almas et al. 2021.
[6] See Waal 2021 and The Guardian 24 January 2021.
[8] We do that as well in Beta maṣāḥǝft especially to give the possibility to directly link to a compiled query for use in other tools and environments. The RDF has the disadvantage of being as such extremely hard to version, let alone cite as such, which makes the priority of the XML over this other format a fundamental requirement. I would like to thank Elisa Beshero-Bondar for her question during the conference, which triggered the write up of the above paragraphs and examples.
[9] I could have probably used the array{} constructor instead, but that is
how the code is at the moment.
[10] The same script could be used to produce the triples, store and index the RDF and serve it instead from a the triplestore, implementing the RESTxq module or any other implementation to query only the triplestore with an appropriate CONSTRUCT or DESCRIBE queries serialized as json-LD. This would remove further necessity of data-formatting logic from the script leaving it where it belongs, that is, in the data. The intermediate layer is one way to preserve the integrity of the data provided with all necessary information to avoid misuse and ensure credit is given, if required.
[11] https://readcoop.eu/transkribus/
[12] We have this in a piece of XSLT.
[15] See, The Reference System Declaration in the TEI Guidelines.
[16] See the page on references of the project's Guidelines for more on this.
[17] Dorothea Reule, Alessandro Bausi, ʻSǝnkǝssār (Group A)ʼ, in Alessandro Bausi, ed., Die Schriftkultur des christlichen Äthiopiens und Eritreas: Eine multimediale Forschungsumgebung / Beta maṣāḥǝft (Last Modified: 28.3.2017) https://betamasaheft.eu/works/LIT4032SenkessarS [Accessed: 2021-06-16+02:00]
[18] There may be a list of witnesses, which is however a different thing.
[19] Denis Nosnitsin, Pietro Maria Liuzzo, Alessandro Bausi, Nafisa Valieva, Massimo Villa, Eugenia Sokolinski, ʻBǝḥerāwi Kǝllǝlāwi Mangǝśti Tǝgrāy, ʿUrā Qirqos, UM-035ʼ, in Alessandro Bausi, ed., Die Schriftkultur des christlichen Äthiopiens und Eritreas: Eine multimediale Forschungsumgebung / Beta maṣāḥǝft (Last Modified: 27.5.2021) https://betamasaheft.eu/manuscripts/ESum035/main [Accessed: 2021-06-14+02:00]
[20] https://collatex.net/
[21] https://github.com/distributed-text-services/specifications/issues/167
[22] Dorothea Reule, Solomon Gebreyes, Jonas Karlsson, Antonella Brita, Alessandro Bausi, Simone Seyboldt, ʻChronicle of Bakāffāʼ, in Alessandro Bausi, ed., Die Schriftkultur des christlichen Äthiopiens und Eritreas: Eine multimediale Forschungsumgebung / Beta maṣāḥǝft (Last Modified: 23.7.2019) https://betamasaheft.eu/works/LIT4633Chronicle/main [Accessed: 2021-06-14+02:00]
[23] https://alignment.alpheios.net/