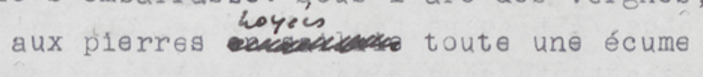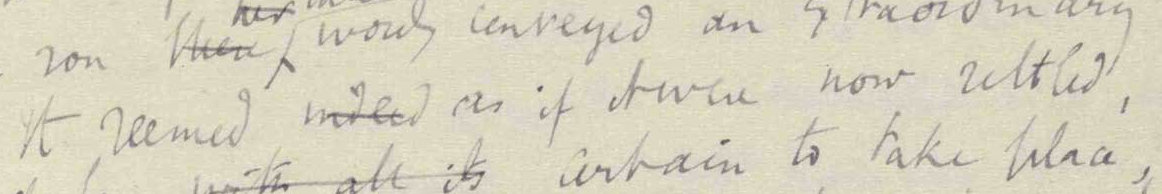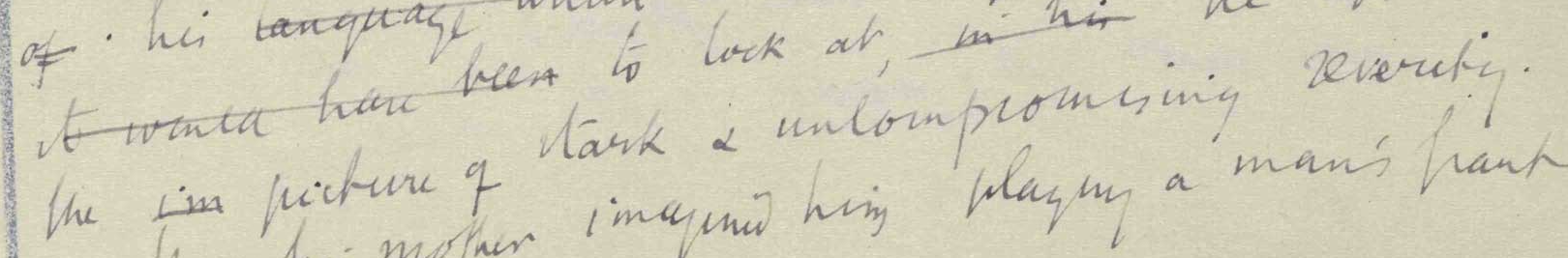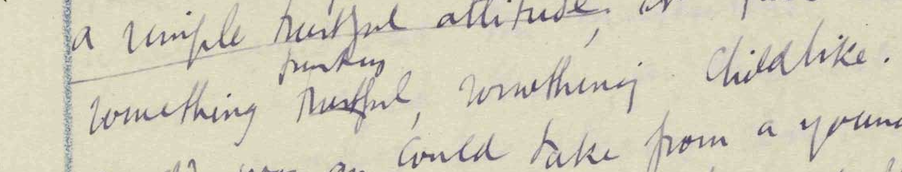Bleeker, Elli, Bram Buitendijk and Ronald Haentjens Dekker. “Marking up microrevisions with major implications: Non-linear text in TAG.” Presented at Balisage: The Markup Conference 2020, Washington, DC, July 27 - 31, 2020. In Proceedings of Balisage: The Markup Conference 2020. Balisage Series on Markup Technologies, vol. 25 (2020). https://doi.org/10.4242/BalisageVol25.Bleeker01.
Balisage: The Markup Conference 2020 July 27 - 31, 2020
Balisage Paper: Marking up microrevisions with major implications: Non-linear text in TAG
Elli Bleeker
Researcher, Research and Development
Research and Development Group, Netherlands Academy for Arts and
Sciences
Elli Bleeker is a postdoctoral researcher in the Research and Development Team
at the Humanities Cluster, part of the Royal Netherlands Academy of Arts and
Sciences. She specializes in digital scholarly editing and computational
philology, with a focus on modern manuscripts and genetic criticism. Elli
completed her PhD at the Centre for Manuscript Genetics (2017) on the role of
the scholarly editor in the digital environment. As a Research Fellow in the
Marie Sklodowska-Curie funded network DiXiT (2013–2017), she received advanced
training in manuscript studies, text modeling, and XML technologies for text
modeling.
Bram Buitendijk
Software Developer, Research and Development
Research and Development Group, Netherlands Academy for Arts and
Sciences
Bram Buitendijk is a software developer in the Research and Development team
at the Humanities Cluster, part of the Royal Netherlands Academy of Arts and
Sciences. He has worked on transcription and annotation software, collation
software, and repository software.
Ronald Haentjens Dekker
Head of Research and Development and Software Architect
Research and Development Group, Netherlands Academy for Arts and
Sciences
Ronald Haentjens Dekker is a software architect and lead engineer of the
Research and Development Team at the Humanities Cluster, part of the Royal
Netherlands Academy of Arts and Sciences. As a software architect, he is
responsible for translating research questions into technology or algorithms and
explaining to researchers and management how specific technologies will
influence their research. He has worked on transcription and annotation
software, collation software, and repository software, and he is the lead
developer of the CollateX collation tool. He also conducts workshops to teach
researchers how to use scripting languages in combination with digital editions
to enhance their research.
The article discusses how micro-level textual variation can be expressed in an
idiomatic manner using markup, and how the markup information is subsequently used
by a digital collation tool for a more refined analysis of the textual variation.
We
take examples from the manuscript materials of Virginia Woolf's To the
Lighthouse (1927), which bear the traces of the author's struggles in
the form of deletions, additions, and rewrites. These in-text revisions typically
constitute non-linear, discontinuous, or multi-hierarchical information structures.
While digital technology has been instrumental in supporting manuscript research,
the current data models for text provide only limited support for co-existing
hierarchies or non-linear text features. The hypergraph data model of TAG is
specifically designed to support and facilitate the study of complex manuscript text
by way of its syntax TAGML and the collation tool HyperCollate. The article
demonstrates how the study of textual variation can be augmented by designated
markup to express the in-text, micro-level revisions, and by computer-assisted
collation that takes into account that information.
When we say that text encoding is a means of making explicit an interpretation of
that
text, we mean that the encoder is compelled to explicitly formulate their underlying
assumptions about the text. We often forget to point out that text encoding also implies
a (subconscious) choice for a certain data model. Needless to say, not all data models
are equally suitable to express and query all kinds of textual information. It is
crucial, then, for encoders to be(come) aware of the consequences of their choices,
not
only on the level of the tagset but also on the level of the data model. As a result,
practising digital textual scholarship – the modeling, encoding, and analysing – can
be
as informative and enlightening as the end product.
Since data models for text are usually developed according to a specific conceptual
idea of text, it is interesting to see what textual features are natively supported
by a
data model. What are, for example, the consequences of expressing text as a consequetive
sequence of characters, with annotations as ranges on the text (LMNL data model)? Or: how will representing textual information as RDF
statements (cf. EARMARK, see Peroni and Vitali 2009) instead of an ordered rooted
tree (cf. XML) change the way we think about text? In each case, the affordances of
the
chosen data model will inevitably affect our encoding practice and the outcomes of
an
analysis.
Ideally, then, the choice for a suitable data model is primarily informed by one's
research questions and the particulars of the textual material, and not by a prevailing
standard. As Michael Sperberg-McQueen noted in his concluding remarks of the Balisage
2009 conference: It is not standards in themselves that are harmful, but mindless
adherence to standards that is harmful (Sperberg-McQueen 2009). Making
an informed choice for a specific data model is accordingly related to the research
needs of a scholar, who needs to be clear about what textual feature(s) they want
to
examine, what result(s) they expect from the text modeling, and how they intend to
get
there.
In this contribution, we investigate how the TAG data model addresses a persistent
challenge for modeling and analysing literary and historical documents. The contribution
builds upon two previous Balisage papers which introduced respectively the TAG model
(Haentjens Dekker and Birnbaum 2017) and the TAGML syntax (Haentjens Dekker et al. 2018). Presently, we will expand on the potential of TAG and
TAGML to model and process complex textual phenomena. We take our examples from
fragments of the authorial manuscripts of Virginia Woolf's To the
Lighthouse (1927). The text on these documents presents quite some
modeling challenges: words are deleted mid-way a sentence, phrases are inserted in
between the lines or in the margin, paragraphs are transposed, changes to the text
structure are indicated with arrows or metamarks, etc. In short: the documents contain
the sort of textual phenomena that tests the limitations of a data model. For this
contribution, we concentrate on one particular phenomena: in-text revisions and similar
non-linear text structures.[2]
After briefly illustrating what we mean with in-text revisions and how they constitute
non-linear information structures (section 2 Non-linear text), we go
on to demonstrate how TAGML allows encoders to markup non-linear text in a
straightforward and idiomatic manner. Using the concept of the computational pipeline,
we show in section 3 (Encoding non-linear text) how a TAGML
transcription of non-linear text is tokenized, parsed, and stored as a single TAG
hypergraph for text. The fourth section, Analysing non-linear text: collation,
discusses the topic of automated collation and outlines how the non-linear information
that is stored in the individual TAG hypergraphs can be used to come to a more refined
collation output via graph-to-graph comparison.
The paper intends to demonstrate how TAG allows scholars to be extremely precise in
expressing their interpretation of textual variance which, in turn, positively affects
the subsequent processing and analysis of the encoded texts. Because work on the TAG
project is under ongoing development, this contribution will not be your average
tool presentation. Rather, we intend to show in some detail how textual
information is stored, interpreted, and processed by our data model. We consider this
essential to understanding the potential of our model for supporting textual analysis.
By providing detailed insights into the design choices and technical implementation
of
TAGML and HyperCollate, we emphasize how the choices made on the level of the storage
and processing of textual information can affect the subsequent analysis.
Non-linear text
Challenges for text-encoding
Briefly put, non-linear text means that the text does not form a linear stream of
characters. As we explained in Bleeker et al. 2018 and Haentjens Dekker et al. 2018, textual content is normally fully ordered information: the text characters form a stream of
characters and their order is inherent to their meaning. Fully ordered text is
parsed and processed as it is read: in Western scripts that means from left to
right, from top to bottom.
In many cases, however, text is not always or consistently a linear structure.
Textual variation, for example, may constitute partially
ordered information. Take the in-text revision in Figure 1:
The original text of this fragment reads aux pierres en saillie toute une
écume. The words en saillie are crossed out and the word
noyées is added above the line, changing the phrase into
aux pierres noyées toute une écume. The words en
saillie and noyées are on the same location in the text
and thus mutually exclusive.
Text encoding implies the interpretation, transcription, and encoding of textual
inscriptions on the document page. In case of documents with in-text revisions,
markup can be used to identify the subsequent stages in the writing and revision
process or to label the different types of revisions. To illustrate the trickiness
of encoding non-linear text, let's take a look at how it can be done in TEI/XML. The
TEI Guidelines, the de facto standard for text encoding (TEI P5), are currently based on the XML data model, which means
that literary texts are usually modeled as an ordered, monohierarchical tree. So,
as
text encoders set out to encode the various stages of writing and revision as
thoroughly as possible, they face the tricky task of encoding partially ordered
information in a fully ordered data structure. The example above can be encoded in
TEI/XML with del and add elements, and – if needed – a
subst element to group the two elements together as a single
intervention:
aux pierres <subst><del>en saillie</del><add>noyées</add></subst> toute une écume .
Here, the opening tag <subst> indicates where the textual
information becomes temporarily non-linear. We can say that the two readings
en saillie and noyées constitute two paths through
the text. The tags del and add identify the two separate
paths. Within the individual paths, the text is fully ordered again: the words
en saillie would have a different meaning (if any) if the text
characters lost their order. At the closing tag </subst> the two
branches rejoin and the text becomes fully linear again.
Similar examples of non-linear or partially ordered information that is expressed
in markup are the choice or app elements. Both are used to
group a number of alternative encodings for the same point in the
text.[3]
Because XML cannot natively express non-linear text structures at the level of the
model or the syntax (Haentjens Dekker and Birnbaum 2017), the TEI Guidelines provide
several dedicated elements and schemata. As a result, the temporary non-linearity
as
expressed with the TEI/XML element subst can be licensed by and
validated against a schema.[4] In theory, a query processor that has access to and understands this schema
will be able to recognize the non-linear information expressed by the markup.
Following our example above, the processor will understand that the words en
saillie and noyées are located on the same place in the
text stream and that they are mutually exclusive alternatives to each other.
Unfortunately, this scenario does not apply to the majority of the XML query
processors. In most cases, processing queries remains limited to a linear level. Put
differently: the TEI/XML file may conceptually represent the
encoder's idea of non-linear text, but that concept is typically not shared with a
processor. This has significant consequences for searching, querying, and analysis.
Desmond Schmidt found for instance that only 10% of digital editions using inline
markup could find literal expressions that span inline substitutions
(Schmidt 2019, note 3). The section below illustrates other
complications that arise when collating texts with in-text variations.
Challenges for text analysis
In this contribution, we focus on one form of text analysis that would
particularly benefit from having access to non-linear information: collation.
Collation can be defined as the comparison of two or more versions
(witnesses) of a literary text in order to establish a record of
the textual variance. To this end, a scholar can use designated collation tools like
CollateX (CollateX) or Juxta (Juxta). However,
since these automated collation tools operate on character strings, the non-linear
information about revisions within individual witnesses is not used to come to an
alignment of the texts.
The first option implies that relevant information about an author's writing and
revision process is ignored by the collation tool. This may have a negative impact
on the analysis of the textual variance. With the second option – passing on markup
tags (in flattened form) – editors can at least use the retained information to
visualize the deleted words in the collation
output,[5] or to raise the flattened transcription again (see the
Variorum Frankenstein project, Birnbaum et al. 2018,
discussed in more detail in section 4.1.2 Passing along markup).
However, this option requires a considerable set of technical skills that may not
be
available to most scholarly editors. Furthermore, the collation tool would still
operate on the character stream and the non-linear information is
not part of the alignment process.
This brings us to three important requirements for the way TAG should handle
non-linear information. First, editors need to be able to markup this kind of
partially ordered information in a straightforward manner. Secondly, a processor
needs to recognize non-linear information as such so that the texts can be queried
and searched more effectively. And finally, we need a collation program that
recognizes non-linear text as two or more mutually exclusive paths through the text,
from which it then chooses the best match.
Our Balisage 2018 paper already demonstrated how to represent non-linear
information in TAGML (Haentjens Dekker et al. 2018); section 3.2 TAGML will therefore focus on how this information is
interpreted by the TAGML parser and stored as a hypergraph. Section 4.2 HyperCollate then describes how the individual TAG
hypergraphs can be collated by the hypergraph-based collation tool HyperCollate
(https://huygensing.github.io/hyper-collate/) that recognizes
non-linear information and thus produces a more refined collation output. Both
sections are proceeded by an overview of the related work done in these
areas.
Encoding non-linear text
Related work
In addressing the need to model overlapping, non-linear, or discontinuous text
structures, TAG shares the objectives of several existing markup systems.
Accordingly, there are aspects of TAG's approach that correspond closely to other
syntaxes or data models, most notably TexMECS, LMNL, and TEI/XML. This section
should therefore not be read as a critique on existing markup approaches, but rather
as an illustration of how TAG complements or relates to these approaches.
Embedded markup approaches
As the table in Figure 2 illustrates, there
are various embedded markup approaches to expressing complex textual structures.
Some are more effective than others, but theoretically text encoders can use any
data model to express any kind of text, no matter how complex, as long as they
are willing to use some workarounds, do some extra coding, and hand over certain
tasks to other data formats (Vitali 2016). But the more
additional coding, customized solutions, or handovers are necessary, the more
complicated it will be to process, query, interchange, or reuse the encoded
files (Haentjens Dekker et al. 2018, Schmidt 2019).
From the outset, the main objective behind the development of TAG has been to
both simplify and advance the work of text encoders worldwide. In our ideal
scenario, editors can work with a data model that natively supports the modeling
of complex text features, with as few handovers or customized technical
solutions as possible. The table below therefore represents to what extent
markup systems support complex textual features like non-linearity,
discontinuity, and overlap in a native way.[6]
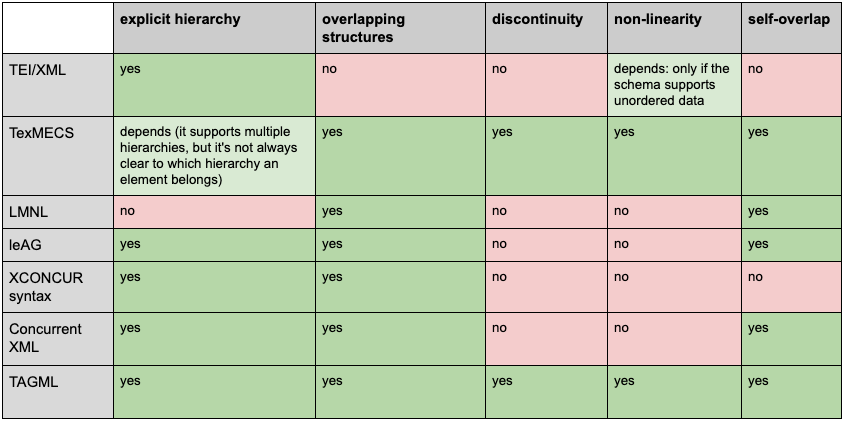
Figure 2: Overview feature-support in embedded markup languages
Overview of complex textual features supported by embedded markup
languages. The overview is partly inspired by the map drawn by
Wendell Piez (Piez 2008), by the MLCD Overlap
Corpus (Marcoux et al. 2012), by the tables of Fabio
Vitali (Vitali 2016), and by the inventory of
Pierre-Édouard Portier et al. (Portier et al. 2012).
As the table shows, TexMECS is able to natively represent non-linearity. By
default, all contents of a TexMECS document are ordered, and it is possible to
indicate the start and end of an unordered element. For example, the children of
a subst element can be marked as unordered in the following TexMECS
notation:
This is a <|subst||<del|useful|del> <add|clear|add>||subst|> example
.
Here, the deleted word and the added word are on the same position in the text
stream and mutually exclusive (Huitfeldt and Sperberg-McQueen 2003).
XCONCUR (Schonefeld 2007), Concurrent XML (Dekhtyar and Iacob 2005), LMNL (Piez 2008), and linear
extended Annotation Graphs (LeAG, Barrellon et al. 2017) are designed
primarily to deal with overlapping structures and do not natively support
non-linear structures.[7] The case of TEI/XML is slightly more complicated. We mentioned above
that the TEI Guidelines identify a number of elements (notably the
subst, choice and app) whose children
are understood to be unordered. We also noted that this requires the use of a
schema language like XML Schema that supports unorderedness, as well as a
schema-aware processor. In reality, most generic XML processors will not be
aware of these exceptions and process the XML document as a fully ordered tree.
In that case, all alternative paths through the text will be considered as being
part of one and the same text stream.
Stand-off approaches
Several stand-off approaches to markup also allow for the expression of
non-linear structures. The Multi-Version Document (MVD) system developed by
Desmond Schmidt et al. (Schmidt 2008, Schmidt and Colomb 2009,
Schmidt and Fiormonte 2010) implements a variant graph which is a
suitable data structure for representing non-linearity. In the case of a draft
manuscript featuring multiple revision stages, the MVD-approach suggests the
editor creates separate transcriptions (layers) for each in-text
revision stage. The transcription files can be in plain text, HTML, XML or LMNL format.[8] Creating layers implies interpretative work from the editor who needs to
differentiate between revision stages on the manuscript text based on cancelled,
added, and transposed (units of) text. Layers are thus artificial constructs
that represent a collection of in-text variations. The separate files are merged
into one MVD, so that all versions of a text – both the in-text variation and
the variation across documents – are stored in one variant graph.
EARMARK (Extremely Annotated RDF Markup; (Peroni and Vitali 2009)) is
another standoff system and well-known to the Balisage-community. EARMARK
implements a collection of RDF statements about text fragments that describe
properties of that fragment. Technically, the underlying RDF data model is
flexible enough to express partially-ordered information, but according to the
EARMARK specification (Peroni and Vitali 2009), this feature is not
supported.
EARMARK does support the option to represent multi-orderedness: via the
e-GODDAG extension, RDF statements about the same text node can be repeated in
different contexts. This way, users can express multiple text orders (Peroni and Vitali 2009, section 4.1; Di Iorio et al. 2009; Peroni et al. 2014). However, multi-orderedness is not identical to
partially-orderedness. To our knowledge, expressing diverging and converging
paths through the text stream (our definition of partially-ordered information)
is currently not parsable in EARMARK.
TAGML
We have defined non-linear text as partially ordered information, and we have
emphasized that it is desirable for a markup system to natively represent
partially-ordered information. Now let's move on to the approach of TAG. This
section first describes the pipeline of the TAGML parser. It subsequently
illustrates the operations of the parser with three examples of textual variation
within a manuscript fragment: a single deletion, an immediate deletion, and a
grouped revision. For each example, we show the TAGML transcription and the Abstract
Syntax Tree (AST) that is created by the TAGML parser.
Note that a draft manuscript can present a huge number of complex textual
variations (substitutions within substitutions within substitutions, transpositions
of multiple segments, revisions within a word, etc). For this paper, we selected
three short examples, lest the visualisations of the ASTs becomes too large and
uninformative.
TAGML Pipeline
Figure 3 presents a schematic
representation of the TAGML processing pipeline.
Figure 3: TAGML pipeline
The TAGML processing pipeline. The input is a TAGML document, the
output is an Abstract Semantic Graph.
The input of the pipeline is a TAGML document that contains a combination of
text and markup. Markup tags indicate whether the text is fully ordered,
partially ordered, or unordered.[9] The TAGML document is first tokenized by the TAGML lexer which produces
a stream of TAGML tokens; each token contains information about its position in
the TAGML document, its type, and its length. We will discuss the lexer in more
detail below. The stream of TAGML tokens is subsequently parsed with an
ANTLR-generated parser that uses TAGML grammar, resulting in an AST of the input
TAGML document. The most up-to-date version of the TAGML grammar can be found on
Github. From the AST, an Abstract Semantic Graph (ASG) can be
generated. In the TAG data model, the ASG is implemented either as a
Multi-Colored Tree (MCT) or a hypergraph.[10] In a tree model the markup elements start at the top level and are
(almost) all above the text elements, which are at the bottom in leaf nodes. In
contrast, the TAG hypergraph model has the text elements at the centre of the
model. The relationship between Text nodes and Markup nodes is expressed by
hyperedges.
Examples
The examples in this section come from the authorial notebooks of Virginia
Woolf's To the Lighthouse, written between 1926
and 1927 (Woolf 1927). Digital facsimiles of the notebook
pages are available via the digital archive Woolf Online.[11] Of each example we show four representations: the manuscript fragment,
the TAGML transcription, its AST as produced by the parser, and its hypergraph
representation. Again, we'd like to point out that these examples are selected
for their simplicity; more complex examples would result in an exceptionally
large AST visualisation that won't fit into this paper.
Single deletion
Figure 4: Manuscript fragment with a single deletion
A deleted word on a fragment of Virginia Woolf's manuscript of
To the Lighthouse, Fol. 9;
SD. p. 4.
If we follow the tag suggestions of the TEI Guidelines for
transcription of primary sources and map them to TAGML,[12] a textual fragment with the deletion can be represented as follows:
[TEI>[s>it seemed [?del>indeed<?del] as if it were now settled<s]<TEI]
The
question mark prefix in the [?del> tag indicates that the
element and its textual content are optional, thus two ways of reading the
text. When processed by the TAGML parser, the following AST is produced:
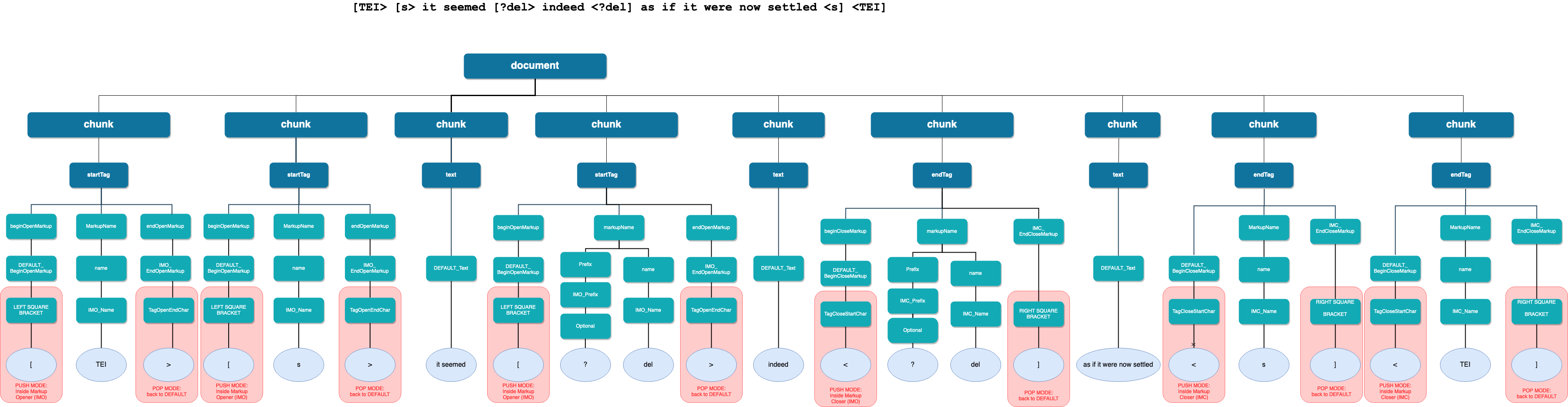
Figure 5: AST of a single deletion
Visualisation of the AST of a single deletion.
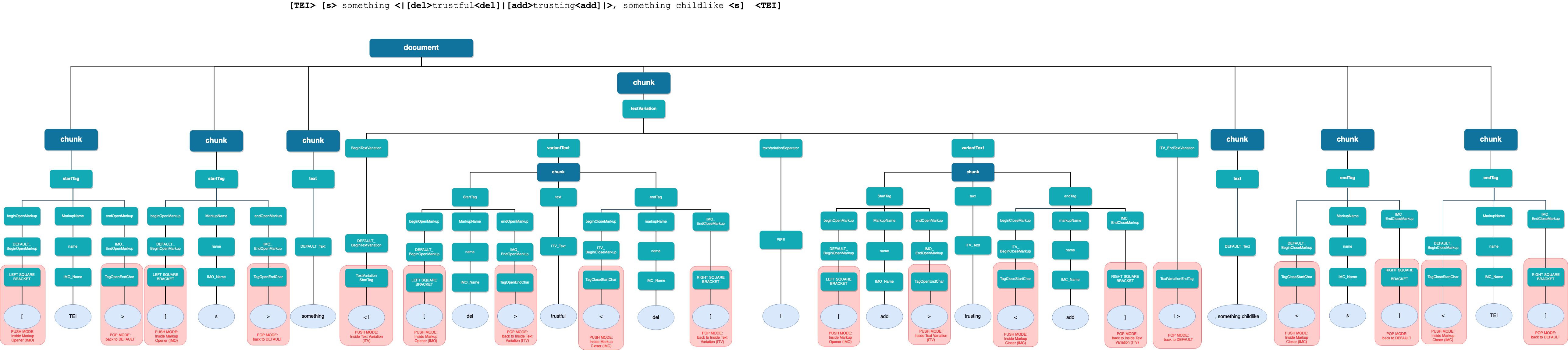
The TAGML grammar is context-sensitive,[13] and a TAGML document consists of one or more chunks. Each chunk can
contain either a start tag, an end tag, text, or text variation. In this
diagram, the TAGML tokens are visualized in the blue leaf nodes. The fact
that the lexer has different modes enables us to reuse a (sequence of)
character(s). Based on their position in the TAGML document, the same
characters may get a different function. For example, if the lexer is in the
'Default'-mode, a left square bracket [ is identified as the
start of a markup opener, so the lexer switches to the 'Inside Markup
Opener'-modus. The lexer remains in this modus until it encounters a token
that prompts it to switch to another modus, in this case that could be the
> token, which triggers the lexer to switch back to the
'Default'-modus ('pop mode // back to default'). The diagram shows how a
TAGML token can trigger the shift to a different modus: the modes of the
lexer are visualized in red and connected to the tokens that trigger
them.
From the resulting AST a Multi-Colored Tree or a hypergraph can be
generated. Because hypergraphs are more suitable to represent non-linear
information, we will show the hypergraph for each TAGML document. Note that
the AST only expresses the syntactic structure of the TAGML document, which
means the start tags and end tags are not linked. Going from an AST to a
hypergraph, then, means that the start and end tags will need to be
reconnected in order to form Markup nodes in the hypergraph.
Figure 6: Hypergraph visualisation of a single deletion
A visualisation of the hypergraph of the single deletion, with
the markup information in labeled hyperedges. Here, the Text
nodes form a directed graph and the text can be read from left
to right, following the arrows. The visualisation shows the two
paths through the text that imply that the text can be read in
two different ways: one version of the text includes the deleted
word indeed, and one version excludes it. The
Markup nodes connected to the Text nodes are visualized as
coloured spheres. For example, the Markup node labeled
del is connected to the Text node
indeed.
Immediate deletion
Figure 7: Manuscript fragment of an immediate deletion
An immediate deletion (currente
calamo) on a fragment of Virginia Woolf's
manuscript of To the
Lighthouse, Fol. 9; SD. p. 4.
In TAGML, the immediate deletion is expressed as follows:
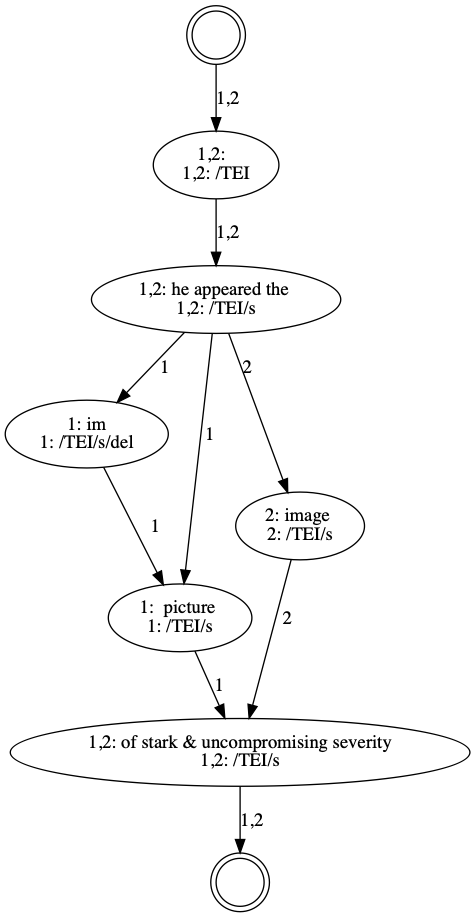
[TEI>[s>The [del>im<del] picture of stark & compromising severity.<s]<TEI]
Note that the [del> does not have an optional prefix
? because we interpret an immediate revision as part of the
same writing stage as the rest of the text. This means there is just one
reading of the text and that reading includes two deleted text characters
im.
Figure 8: AST of an immediate deletion
An AST of the immediate deletion encoded in TAGML. The
different modes of the lexer are visualized in red. Note, for
instance, how the lexer interprets text characters either as
Text or as a markupName depending on its current modus
(respectively 'Default'-modus or
'InsideMarkupOpener'-modus).
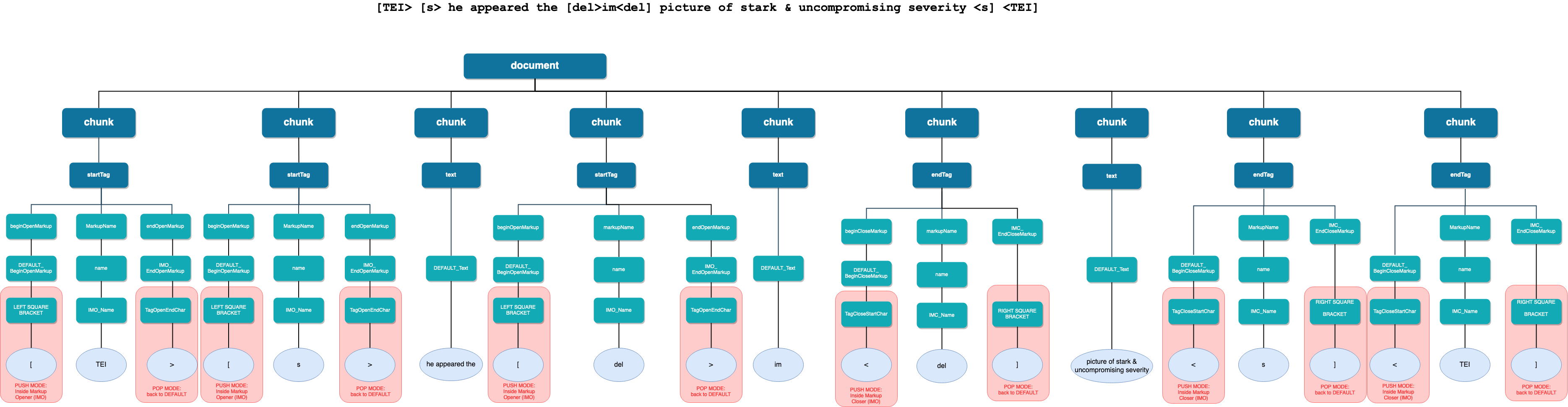
Figure 9: Hypergraph of an immediate deletion
Visualisation of the hypergraph as generated from the AST
above. Because the immediate deletion is taken as part of the
running text, the text in the hypergraph has no branches: there
is only one way of reading the text. The fact that the text
characters im are deleted is represented by
associating the Text node with a Markup node labeled
del.
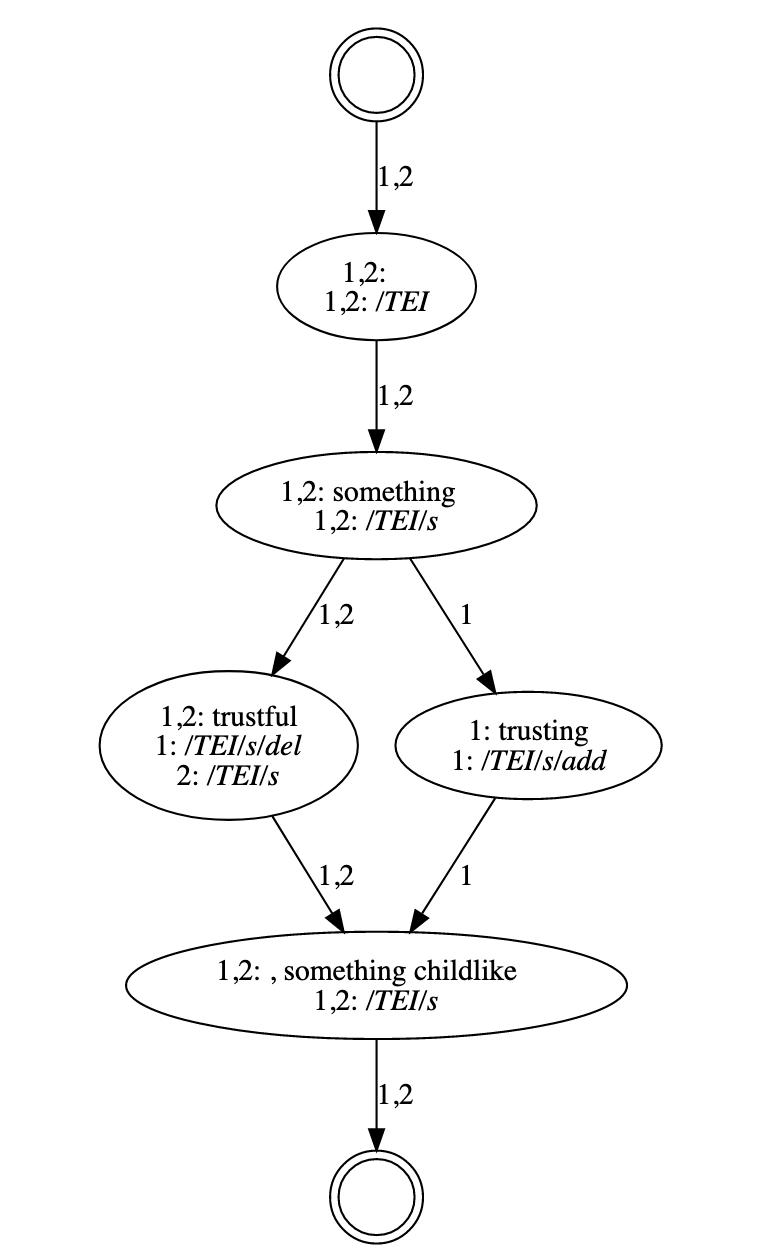
Grouped revision
Figure 10: Manuscript fragment of a grouped revision
A grouped revision on a fragment of Virginia Woolf's
manuscript of To the
Lighthouse, Fol. 15; SD p. 7.
A grouped revision is a clear example of non-linear, partially
ordered information: alternative readings for the same point in the text. In
the TAGML syntax, the branching of the text stream is indicated with
<|, the individual branches are separated with a
vertical bar | and the converging of the branches is indicated
with a |>. Individual branches contain markup and text. The
present example can thus be encoded like this:
As
we will see in the visualization of the AST below, the TAGML parser will
recognize and interpret the divergence and convergence signs, so that the
content of the branches is considered variant text ('ITV_text').
Figure 11: AST of a grouped revision
This visualization of the AST of the grouped revision example
shows how the lexer switches constantly between modes. This
ensures that the parser has the right information and can
interpret non-linear, partially ordered information as it was
intended by the human encoder: as an indication of two readings
of the same point in the text.
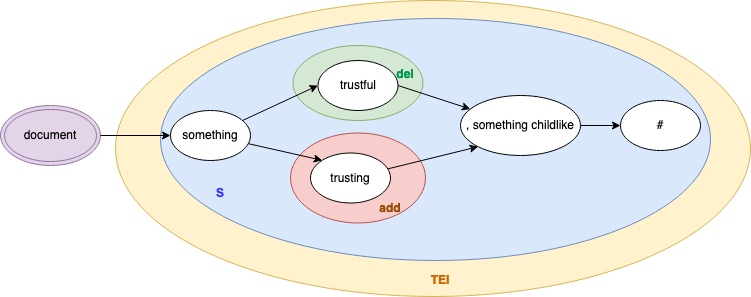
Figure 12: Hypergraph of a grouped revision
This hypergraph visualization demonstrates the concept of
branches by showing how the text diverges into two branches
after the word something. Each branch contains
both text and markup. The information in the branches is
mutually exclusive: when read from left to right, the text in
the hypergraph either reads something trustful, something
childlike or something trusting, something
childlike. The branches converge again after the
text variation ends.
Taken together, the different visualizations of in-text revisions
illustrate how TAG and TAGML allow for a natural and idiomatic digital
representation of in-text variation, one that we think comes as close as
possible to how a human encoder understands it. The next section will look
at ways to transfer this understanding to a collation tool.
Analysing non-linear text: collation
Related work
We defined collation at its most basic level as the comparison of two or more
versions (witnesses) of a text to find (dis)similarities between or
among them. As mentioned above, collation software typically does not excel at
handling markup within individiual witnesses: they collate the witnesses looking at
the plain text – either ignoring all tags and attributes or requiring users to
remove them in a pre-processing phase – or transform the markup to plain text
characters so that the tags are collated but their meaning ignored. In either case,
any partially ordered information is overlooked. Still, because the requirement of
including (certain) markup elements in the collation process continues to exist,
scholars have invented some nifty ways to work around the limitations of prevalent
collation software. We distinguish three main approaches, which are briefly
discussed in the following paragraphs:
Creating additional witnesses for each in-text revision;
Passing along markup for postprocessing;
Comparing structured (data-centric) XML files.
Creating additional witnesses for each in-text revision
Section 3.1.2 (Stand-off approaches) described how users of the MVD
technology can create separate layers for each occurrence of in-text variation.
These layers can subsequently be used as temporary witnesses for the plain text
collation. Using the MVD collation functionality 'Compare', the temporary
witnesses and the base texts are compared to one another. Both the official text
versions and their temporary layers are merged into one MVD, which stores the
text shared by each version and layer only once, similar to a variant graph.
'Compare' does not recognize markup elements and consequently does not
differentiate between text and markup. In fact, it is not quite correct to say
that the collation program ignores the markup information about non-linearity:
the markup was never there in the first place.[14] The result of the collation is an MVD variant graph containing in-text
revisions as well as between-document variation. In the variant graph, in-text
non-linear structures (i.e., within one witness) are distinguished from external
variation (i.e., between witnesses) by sigla.
Passing along markup
Some collation tools allow for markup elements to be passed on through their
pipeline. The markup elements are ignored during the alignment process, but they
are present in the output and can then be used for further analysis or
visualisation purposes.
Juxta Commons accepts TEI/XML encoded files for collation. The tool offers an
interface that lists all TEI/XML elements contained by the input witness; the
user can select which elements should be part of the collation and which can be
filtered out. The TEI/XML elements are not part of the alignment process proper:
they are saved as stand-off annotations to the text tokens and passed-on through
the collation pipeline. The elements can be visualized in the heat map
representation of the collation result, which shows deletions in red and
additions in green. In other output formats of Juxta, the <add>
and <del> tags are no longer there.
Another method to pass along markup through the collation pipeline requires
coding on the side of the editor who interacts with the underlying code of the
collation tool. We illustrate this approach by looking at the software CollateX.[15] The JSON input format for CollateX allows for extra properties to be
added to words. In a preprocessing step, the text is tokenized and transformed
into JSON word tokens. Editors can make a selection of markup elements that they
wish to attach to the JSON token as a t property (the
t standing for token). The collation is
executed using the value of the token's n property
(n for normalized), but the selected
markup is included in the JSON alignment table output via the
t property, and can be processed in the visualisation
of the alignment table. This approach does approximate the goal of having
in-text revisions marked as non-linear text in both in- and output, but at the
point of alignment, the collation algorithm is unaware of any non-linearity in
the witness' text and treats the partially ordered information as a linear
structure.
Comparing data-centric XML
Finally, there are several approaches to comparing XML trees (Barabucci et al. 2016, Ciancarini et al. 2016). Some XML editors, like
oXygen, have a built-in XML comparison function. In theory, this approach would
allow for the comparison of TEI/XML transcriptions containing non-linear
information encoded with subst or app elements. The
comparison functionality is primarily developed for structured, record-based XML
documents – e.g., XML documents containing address information such as person
name, address, age – and the documents are compared on the level of the XML
elements.
Comparing two record-based XML documents results in an overview of the
difference in markup. For example, an add element in witness A
would be aligned with an add element that is on the same relative
location in witness B. Note that these matches are made on the element level and
not on level of the textual content.
Textual scholars studying the revisions in literary texts, however, would
typically give preference to the textual content.
The DeltaXML software does detect and display changes between two XML
documents, either on the level of the XML elements or on the level of the text
content. (Delta XML) Their Document comparator tool compares two XML documents and merges them
into a new XML document that contains additional attributes representing the
variation. What is more, DeltaXML provides the option to identify
orderless containers: XML elements whose children can
be arranged in an order that is not considered significant.
Orderless containers are marked by placing the
deltaxml:ordered="false" attribute on the element so that all
its children will be considered to occur in any order. It's a description that
seems to apply to our interpretation of the subst, the
app and the choice elements. Comparing XML
documents that contain a combination of ordered and orderless data (i.e., the
children of some XML elements are ordered, but others are orderless) remains,
according to the DeltaXML developers, a challenge. They propose
to solve it by preprocessing the input XML documents.[16]
That data-centric XML comparison methods usually do not work for text-centric
encoded documents has already been pointed out by Di Iorio et al., who wrote
that although XML is used to encode both literary documents and database
dumps, there is something different from diff-ing an
XML-encoded literary document and an XML-encoded database (Di Iorio et al. 2009, emphasis in original). In the case of comparing an
encoded literary document, the authors state, the output of a diff should be
evaluated on its naturalness, that is: for an algorithm to identify the changes
that would be identified by a manual, human approach. To this end, Di Iorio et
al. developed the implementation JNDiff.[17] Di Iorio et al. were right to point out that the comparison of encoded
literary documents is quite unique. In the majority of cases, the collation of
such documents needs to take place on the level of the text. Rather than being
compared, the markup indicating in-text revision needs to be
interpreted as it was indented by the encoder:
identifying the start and end of textual variation.
HyperCollate
In developing HyperCollate, we assumed the need for a collation tool that, first,
recognizes the multiple writing stages within each witness text and, secondly,
chooses the best match from these different stages. This implies that the non-linear
structures in an encoded text need to be recognized by the collation program, and
that the program needs to take this information into account during the alignment
process. The technical implications are, first, that the input witnesses are not
treated as a linear string of characters, but as hypergraphs consisting of partially
ordered information. Secondly, that the collation program recognizes this partially
ordered information and processes it accordingly.
As a result, a multidimensional text containing multiple revision stages would no
longer have to be flattened before collation. More importantly, we
estimate that the collation result would approximate the way a human editor would
collate the texts. Accordingly, the collation tool would effectively support and
advance scholarship.
HyperCollate's approach
HyperCollate takes as input two TAG hypergraphs of the individual witnesses.
Note that each hypergraph may contain a combination of ordered, partially
ordered and unordered information. The partially ordered information is
represented as two or more branches in the hypergraph, with the text nodes in
these branches having the same position in the text vis-à-vis the document root
node (see the hypergraph visualisations in section 3.2.2 Examples).
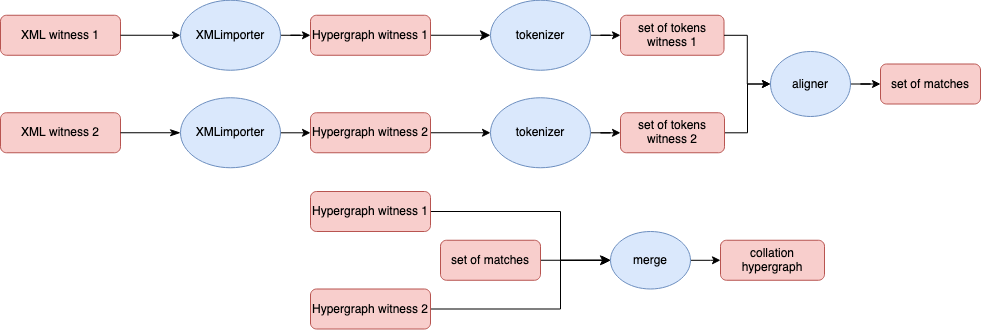
The computational pipeline of HyperCollate can be visualized as follows:
Figure 13: The HyperCollate pipeline
A visualisation of HyperCollate's approach, to be read from the
upper left to the upper right corner; then from the lower left to
the lower right corner.
For each hypergraph witness, the textual content is first tokenized into text tokens. By default, the text
nodes are segmented on whitespace and punctuation. Note that the output of the
tokenizer is not a linear stream of tokens: the tokens contain information about
their distance vis-à-vis the root note (their depth), and in the
case of non-linearity there may be more than one text token at the same
position. The two witnesses are subsequently aligned. Alignment here means that HyperCollate calculates the
smallest possible number of changes needed to change one set into the other.
The output of that alignment is a set of matching tokens. Again, the tokens in
this set contain information about their depth, and there may be more than one
text token on the same position. Based on the information from this set of
matches, the two witness hypergraphs are merged
into a new collation hypergraph that contains all information about the Text
nodes and the Markup nodes of the input witnesses. All the nodes that are not
aligned are unique to one of the two witnesses; all the nodes that are aligned
can be reduced from two to one node, with labels on the edges indicating which
node is part of which witness.
For every witness, then, there is always a fully connected path of Text nodes
through the collation hypergraph: from the start node to the end node, following
the sigla on the edges. Labeled hyperedges are used to associate the Markup
node(s) with the Text nodes. The collation hypergraph can be visualized as an
ASCII table or a collation graph (in .dot, SVG or PNG format). In the case of >2
witnesses, the collation output could also be used as the basis for a new
collation following the progressive alignment-method (Spencer and Howe 2004).
Examples
In the paragraphs below, we return to the examples from section 3.2.2 Examples. Each example text fragment is collated with
HyperCollate against another version of the same text that can be found in the
print proofs of To the LighthouseWoolf 1927.[18] The HyperCollate output, a collation hypergraph, can be visualized in
multiple ways, from an ASCII alignment table to an SVG graph. Each format has
its own level of information density. Here, we provide an alignment table
visualisation and an SVG collation graph visualisation to illustrate what
differences this density makes: a simpler visualization may be clearer, but it
may lack relevant information about the textual variance and/or the markup.
Single deletion
Input witness 1:
[TEI>[s>it seemed [?del>indeed<?del] as if it were now settled<s]<TEI]
Input witness 2:
[TEI>[s>as if it were settled<s]<TEI]
Figure 14: Alignment table visualisation of the collation output
The [-] in front of the text token 'indeed' is
how HyperCollate visualizes that this token is marked as a
deletion in the input. However, this simple alignment table
visualisation does not show that there are two different paths
through the text of witness 1.
Figure 15: Collation graph visualisation of the collation output
A collation hypergraph visualisation of the output of
HyperCollate. As with a standard variant graph, the matching
Text tokens are merged; only the variant Text tokens are made
explicit. The witness sigla, represented on the edges as well as
in the vertices of the collation hypergraph, indicate which
tokens belong to which witness. Furthermore, vertices include a
path to the markup associated with each Text node. In this
visualisation, the two paths through the text of witness 1 are
visible.
Immediate deletion
Input witness 1:
[TEI>[s>he appeared the [del>im<del] picture of stark & compromising severity.<s]<TEI]
Input witness 2:
[TEI>[s>he appeared the image of stark & compromising severity.<s]<TEI]
Figure 16: Alignment table visualisation of the collation output
This alignment table visualisation shows that the text
characters 'im' (an immediate deletion in witness 1) align with
the word 'image' in witness 2. Note that aligned
is not the same as match: two tokens may be
placed above each other because they are at the same relative
position between two matches, even though they do not constitute
a match. Still, by including the deletion in the collation we
see that Woolf deleted the word 'image' and opted for 'picture'
in her draft manuscript, but that based on the print proofs she
went with 'image' after all.
Figure 17: Collation graph visualisation of the collation output
Visualisation of the collation hypergraph. The variant graph
visualisation can include more information than an alignment
table, which makes it a useful visualisation to analyse the
collation outcome in more detail. Note, for instance, that this
visualisation shows that the Text tokens 'im' (witness 1) and
'image' (witness 2) are indeed not considered matches by
HyperCollate.
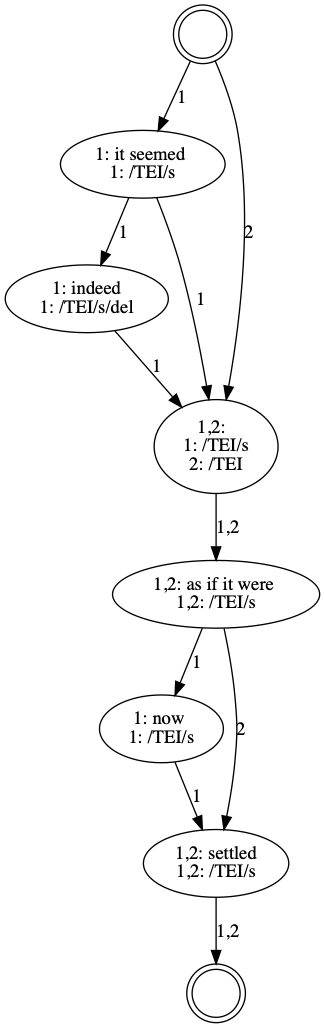
Figure 18: Alignment table visualisation of the collation output
The alignment table visualisation of HyperCollate presents
grouped revisions in a single cell, to indicate that there are
two optional readings for the same position in the text.
Figure 19: Collation graph visualisation of the collation output
Looking at the markup information in the vertices of this
collation hypergraph, we see that the Text token 'trustful' has
different markup in witness 1 compared to witness 2. Still,
because HyperCollate takes the text as leading, the Text tokens
are merged into one vertex.
Discussion
The contribution concentrated on representing in-text variation in TAGML and
subsequently collating that information with HyperCollate. We described how the TAG
model understands textual variation within one text version as non-linear, partially
ordered information. The TAGML syntax allows encoders to express partially ordered
information in a straightforward manner.
Partially ordered information is recognized and processed as such by the TAGML parser,
and stored as multiple branches in a hypergraph for text. The Text tokens within each
branch are mutually exclusive and have the same depth, meaning that they are both
at the
same distance from the root document node of the hypergraph.
HyperCollate is a hypergraph-based collation program that implements the TAG model.
HyperCollate aligns Text tokens based on their relative position in the text as well
as
their depth in the hypergraph. The program recognizes the branches in the input
hypergraphs: if two Text tokens have the same position number, the program finds the
best match between them. The output of HyperCollate is a collation hypergraph that
can
be visualized in different ways; in this paper we showed an alignment table and a
variant graph visualization.
Presently, the TAG approach to transcription and collation takes the text as leading,
using the markup as basis to recognize in-text variation as partially ordered
information. Nevertheless, future work could look into aligning hypergraphs while
looking at other types of markup, e.g., paragraph or sentence breaks. This would be
a
drastic adjustment to the collation algorithm, though, because it would require
HyperCollate to prioritize not only the text, but also the markup. Another topic of
further work is the TAG query language (TAGQL) in order to query the information of
both
individual TAGML documents and the collation hypergraph.[19]
Finally, we continue working on the different output formats of the collation.
Currently, the collation output can be visualized as an ASCII table or a collation
graph
(in .dot, SVG, or PNG format). The examples used in this contribution were small text
fragments and simplified TAGML transcriptions for a reason: representing and collating
two larger TAGML transcriptions, each containing several stages of revisions, would
result in an AST and a collation hypergraph that, in their entirety, cannot be
visualized in any meaningful way for the reader. In fact, the TAGML input and
HyperCollate output contain a much larger variety of textual information than the
visualization of a collation hypergraph. Since this information can be of instrumental
value to a deeper study of the text, a future aim of HyperCollate is to provide an
output in a TAGML-format. This could be similar to the TEI critical apparatus, and
would
allow scholars to continue their textual analysis on the collation output.
Conclusion
So far, all of our contributions to Balisage are characterized by an aspect of
'ongoing research' and the same applies to this contribution. Among other things,
HyperCollate is not yet operating optimally and TAGML does not have a fully functioning
query language yet. Nevertheless, we hope to have shown the value of looking beyond
the
prevalent standard and continuing to question how we think about, represent, and analyse
texts digitally.
As more processes are automated and new methods spring from using digital
technologies, we have more and better digital instruments to map the writing process.
But we need to pay equal attention to the thoughts that go into making these
instruments: how are scholarly activities automated? And how does that affect our
understanding of and interaction with text? In short: it is important that textual
scholars continue to explore different options and to critically evaluate to what
extent
a data model addresses their research needs.
The underlying goal of our contribution was therefore to provide transparency about
the way a TAGML document is parsed and subsequently collated. We illustrated how we
transferred our human understanding of in-text variation to the computer and how this
intelligence is used to improve the alignment of textual witnesses. In testing, we
have
found that HyperCollate's more refined collation technology allows scholars to closely
examine different forms of textual variation and to discover patterns in the writing
processes of literary authors. We can see this even with the small examples of Woolf's
text used in this contribution: in two of the three cases a word that was deleted
in the
draft version reoccurred in the print proofs.
We consider HyperCollate as an inclusive approach to collation: scholars are no longer
required to 'flatten' the manuscript text, to dive deep into the code of the collation
software, or to create additional transcriptions solely for collation purposes. Instead,
they can preserve and use the information about an author's creative revision process
and arrive at a collation result that may reveal information previously hidden.
[Barabucci et al. 2016] Barabucci, Gioele, Paolo
Ciancarini, Angelo Di Iorio, and Fabio Vitali. Measuring the quality of diff
algorithms: a formalization. In Computer Standards
& Interfaces, vol. 46 (2016), pp. 52-65. doi:https://doi.org/10.1016/j.csi.2015.12.005.
[Barrellon et al. 2017] Barrellon, Vincent,
Pierre-Edouard Portier, Sylvie Calabretto, and Olivier Ferret. Linear extended
annotation graphs. In Proceedings of ACM Document
Engineering, Malta, September 2017 (2017). doi:https://doi.org/10.1145/3103010.3103011. Online available.
[Beshero-Bondar 2017] Beshero-Bondar, Elisa
Eileen. Rebuilding a Digital Frankenstein by 2018: Reflections toward a Theory of
Losses and Gains in Up-Translation. Presented at Symposium on Up-Translation
and Up-Transformation: Tasks, Challenges, and Solutions, Washington, DC, July 31,
2017.
In Proceedings of the Symposium on Up-Translation and
Up-Transformation: Tasks, Challenges, and Solutions. Balisage Series on Markup
Technologies, vol. 20 (2017). doi:https://doi.org/10.4242/BalisageVol20.Beshero-Bondar01.
[Beshero-Bondar and Viglianti 2018] Beshero-Bondar, Elisa E., and Raffaele Viglianti. Stand-off Bridges in the
Frankenstein Variorum Project: Interchange and Interoperability within TEI Markup
Ecosystems. Presented at Balisage: The Markup Conference 2018, Washington,
DC, July 31 - August 3, 2018. In Proceedings of Balisage: The
Markup Conference 2018. Balisage Series on Markup Technologies, vol. 21
(2018). doi:https://doi.org/10.4242/BalisageVol21.Beshero-Bondar01.
[Birnbaum et al. 2018] Birnbaum, David J., Elisa
E. Beshero-Bondar and C. M. Sperberg-McQueen. Flattening and unflattening XML
markup: a Zen garden of XSLT and other tools. Presented at Balisage: The
Markup Conference 2018, Washington, DC, July 31 - August 3, 2018. In Proceedings of Balisage: The Markup Conference 2018. Balisage Series on
Markup Technologies, vol. 21 (2018). doi:https://doi.org/10.4242/BalisageVol21.Birnbaum01.
[Bleeker et al. 2018] Bleeker, Elli, Bram
Buitendijk, Ronald Haentjens Dekker, and Astrid Kulsdom. Including XML markup in
the automated collation of literary texts. Presented at XML Prague 2018,
Prague, Czech Republic, February 8–10, 2018. In XML Prague 2018 -
Conference Proceedings (2018), pp. 77–95. Available via
http://archive.xmlprague.cz/2018/files/xmlprague-2018-proceedings.pdf.
[Bleeker et al. 2019] Bleeker, Elli, Bram
Buitendijk and Ronald Haentjens Dekker. Between Freedom and Formalisation: a
Hypergraph Model for Representing the Nature of Text. Long paper presented
at the TEI Conference and Members meeting 2019, September 16-20 2019, Graz, Austria.
Slides available from: https://zenodo.org/record/3929350. doi:https://doi.org/10.5281/zenodo.3929350.
[Ciancarini et al. 2016] Ciancarini, Paolo, Angelo
Di Iorio, Carlo Marchetti, Michelle Schririnzi, and Fabio Vitali. Bridging the gap
between tracking and detecting changes in XML. In Software: Practice and Experience, vol. 46, no. 2 (2016), pp.
227-250. doi:https://doi.org/10.1002/spe.2305.
[Di Iorio et al. 2009] Di Iorio, Angelo,
Michele Schirinzi, Fabio Vitali, and Carlo Marchetti. A natural and multi-layered
approach to detect changes in tree-based textual documents. In International Conference on Enterprise Information Systems,
pp. 90-101. Springer: Berlin, Heidelberg (2009). doi:https://doi.org/10.1007/978-3-642-01347-8_8.
[Haentjens Dekker and Birnbaum 2017] Haentjens Dekker, Ronald and David J. Birnbaum. It’s more than just overlap:
Text As Graph. Presented at Balisage: The Markup Conference 2017,
Washington, DC, August 1–4, 2017. In Proceedings of Balisage: The
Markup Conference 2017. Balisage Series on Markup Technologies, vol. 19
(2017). doi:https://doi.org/10.4242/BalisageVol19.Dekker01.
[Haentjens Dekker et al. 2018] Haentjens
Dekker, Ronald, Elli Bleeker, Bram Buitendijk, Astrid Kulsdom and David J. Birnbaum.
TAGML: A markup language of many dimensions. Presented at Balisage:
The Markup Conference 2018, Washington, DC, July 31 - August 3, 2018. In Proceedings of Balisage: The Markup Conference 2018. Balisage Series on
Markup Technologies, vol. 21 (2018). doi:https://doi.org/10.4242/BalisageVol21.HaentjensDekker01.
[Huitfeldt and Sperberg-McQueen 2003] Huitfeldt,
Claus, and C. M. Sperberg-McQueen. TexMECS: An experimental markup meta-language
for complex documents. Last revised on October 5, 2003. Available online.
[Marcoux et al. 2012] Marcoux, Yves, Claus
Huitfeldt and C. M. Sperberg-McQueen. The MLCD Overlap Corpus (MOC): Project
report. Presented at Balisage: The Markup Conference 2012, Montréal, Canada,
August 7 - 10, 2012. In Proceedings of Balisage: The Markup
Conference 2012. Balisage Series on Markup Technologies, vol. 8 (2012).
doi:https://doi.org/10.4242/BalisageVol8.Huitfeldt02.
[Peroni and Vitali 2009] Peroni, Silvio and
Fabio Vitali. Annotation with EARMARK for Arbitrary, Overlapping and Out-of-Order
Markup. Presented at the DocEng’09 conference, September 16-18, 2009. In
Proceedings of the 2009 ACM Symposium on Document Engineering
(2009), pp. 171-180. ACM: New York. doi:https://doi.org/10.1145/1600193.1600232.
[Portier et al. 2012] Portier, Pierre-Édouard,
Noureddine Chatti, Sylvie Calabretto, Elöd Egyed-Zsigmond and Jean-Marie Pinon.
Modeling, Encoding And Querying Multi-structured Documents. In
Information Processing & Management, vol. 48,
no. 5 (2012), pp. 931-955. doi:https://doi.org/10.1016/j.ipm.2011.11.004.
[Schmidt and Fiormonte 2010] Schmidt, Desmond,
and Domenico Fiormonte. Multi-Version Documents: A digitisation solution for
textual cultural heritage artefacts. In Intelligenza
Artificiale, vol. 4, no. 1 (2010), pp. 56-61.
[Schonefeld 2007] Schonefeld, Oliver.
XCONCUR and XCONCUR-CL: A constraint-based approach for the validation of
concurrent markup. In Data Structures for Linguistic
Resources and Applications. Proceedings of the Biennial GLDV Conference
(2007).
[Sperberg-McQueen 2009] Sperberg-McQueen, C. M.
Sometimes a question of scale. Presented at Balisage: The Markup
Conference 2009, Montréal, Canada, August 11 - 14, 2009. In Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup
Technologies, vol. 3 (2009). doi:https://doi.org/10.4242/BalisageVol3.Sperberg-McQueen02.
[Woolf 1927] Woolf, Virginia. 1927. To the Lighthouse. Holograph ms. Berg Collection, New York
Public Library; Proofs, Smith College Libraries. Pamela L. Caughie, Nick Hayward,
Mark
Hussey, Peter Shillingsburg, and George K. Thiruvathukal, editors. Woolf Online.
[1] The authors express their gratitude to the reviewers for their extensive and insightful
comments.
[2]Overlap is evidently a recurring favorite of the markup
community and the past decades have witnessed a significant number of
alternative markup languages and/or data models to represent overlapping
structures. However, we argued elsewhere that there is much more to modeling
complex texts than overlapping hierarchies alone (Haentjens Dekker and Birnbaum 2017). In the context of in-text revisions, Desmond Schmidt noted that
solving the overlap problem does not necessarily solve the
challenges of modeling textual variation: not all cases of textual
variation are cases of overlapping hierarchies, and hence solutions to
overlapping hierarchies cannot adequately represent textual
variation (Schmidt and Colomb 2009, p. 499). Indeed, as the
table in Figure 2 shows, data models developed to represent overlapping
structures do not necessarily provide for expressing non-linear
information.
[6] For some examples of discontinuity and overlap in literary text, see
Bleeker et al. 2019.
[7] Note that while the extended Annotation Graphs-model is a stand-off
annotation model, its syntax LeAG is an inline markup syntax.
[8] The practice of splitting individual files into multiple layers is
also promoted by Witt et al 2007. This transforms different
sets of linguistic corpora into a set of separate XML documents that
have identical text, but different annotations.
[9] An example of unordered information is metadata.
[10] Technically, an ASG is a Directed Acyclic Graph (DAG) and the
hypergraph is a rooted mixed property hypergraph. But conceptually they
can be considered as similar, so in this context we will take the TAG
hypergraph also as an implementation of the ASG.
[11] We are grateful to and acknowledge the Society of Authors as the
literary representative of the Estate of Virginia Woolf. The Woolf
material may not be used for commercial purposes. Please credit the
copyright holder when reusing Woolf's work.
[12] It is currently not an official part of our research to map the
TEI semantics to TAGML, but we intend to work towards TAGML being an
alternative expression of TEI.
[13] Because TAGML allows markup ranges to overlap, the markup does not
have to be closed in the exact reverse order in which it was opened,
like with XML. This makes the TAGML grammar context sensitive. The
ANTLR4 grammar used in the TAGML library, however, is context-free, because ANTLR4 does not
provide a way to encode context-sensitive grammars. The current
parser that is generated from the grammar cannot check whether every
open tag (eg. [tag>) is eventually followed by a
corresponding close tag (<tag]). This and other
validity checks are done in post-processing. We are currently
examining how to build a context-sensitive parser that does not
require post-processing.
[14]Bleeker 2017, pp. 106-114, elaborates on the MVD
"Compare" technology and why it will not always produce the desired
results for the study of textual variation.
[15] A number of projects make use of CollateX' option to pass along
information about relevant markup elements through the collation
pipeline, e.g., the Beckett Digital Manuscript Project (Van Hulle et al. (editors) 2019), the critical edition of the Primary Chronicles of David J. Birnbaum
(Ostrowski et al.; Birnbaum 2015) and the
Frankenstein Variorium Project (Beshero-Bondar and Viglianti 2018).
[17] Unfortunately we have not been able to test JNDiff as it has not been
updated since 2014 and it is not clear whether it is still
maintained.
[18] Digital facsimiles of the page proofs are also available via the
digital archive Woolf Online. The same copyright notice applies.
[19] In recognition of the crucial role TEI/XML plays in the text encoding
community, we already provide a TAGML-to-XML export function. A TAGML file
uploaded in the Alexandria database can be
exported to XML with the alexandria export-xml [filename] -o
[filename].xml command. This will export the specified TAGML document
as XML. Of course, the conversion from hypergraph to tree implies information
loss. Overlapping hierarchies are represented in the XML output as Trojan Horse
markup. See for more information the Alexandria
documentation. (Alexandria)
Barabucci, Gioele, Paolo
Ciancarini, Angelo Di Iorio, and Fabio Vitali. Measuring the quality of diff
algorithms: a formalization. In Computer Standards
& Interfaces, vol. 46 (2016), pp. 52-65. doi:https://doi.org/10.1016/j.csi.2015.12.005.
Barrellon, Vincent,
Pierre-Edouard Portier, Sylvie Calabretto, and Olivier Ferret. Linear extended
annotation graphs. In Proceedings of ACM Document
Engineering, Malta, September 2017 (2017). doi:https://doi.org/10.1145/3103010.3103011. Online available.
Beshero-Bondar, Elisa
Eileen. Rebuilding a Digital Frankenstein by 2018: Reflections toward a Theory of
Losses and Gains in Up-Translation. Presented at Symposium on Up-Translation
and Up-Transformation: Tasks, Challenges, and Solutions, Washington, DC, July 31,
2017.
In Proceedings of the Symposium on Up-Translation and
Up-Transformation: Tasks, Challenges, and Solutions. Balisage Series on Markup
Technologies, vol. 20 (2017). doi:https://doi.org/10.4242/BalisageVol20.Beshero-Bondar01.
Beshero-Bondar, Elisa E., and Raffaele Viglianti. Stand-off Bridges in the
Frankenstein Variorum Project: Interchange and Interoperability within TEI Markup
Ecosystems. Presented at Balisage: The Markup Conference 2018, Washington,
DC, July 31 - August 3, 2018. In Proceedings of Balisage: The
Markup Conference 2018. Balisage Series on Markup Technologies, vol. 21
(2018). doi:https://doi.org/10.4242/BalisageVol21.Beshero-Bondar01.
Birnbaum, David J. Using
CollateX with XML: Recognizing and Tracking Markup Information During
Collation. Blogpost, published on June 28, 2015 under Computer-supported collation with CollateX. Available on
http://collatex.obdurodon.org/xml-json-conversion.xhtml.
Birnbaum, David J., Elisa
E. Beshero-Bondar and C. M. Sperberg-McQueen. Flattening and unflattening XML
markup: a Zen garden of XSLT and other tools. Presented at Balisage: The
Markup Conference 2018, Washington, DC, July 31 - August 3, 2018. In Proceedings of Balisage: The Markup Conference 2018. Balisage Series on
Markup Technologies, vol. 21 (2018). doi:https://doi.org/10.4242/BalisageVol21.Birnbaum01.
Bleeker, Elli, Bram
Buitendijk, Ronald Haentjens Dekker, and Astrid Kulsdom. Including XML markup in
the automated collation of literary texts. Presented at XML Prague 2018,
Prague, Czech Republic, February 8–10, 2018. In XML Prague 2018 -
Conference Proceedings (2018), pp. 77–95. Available via
http://archive.xmlprague.cz/2018/files/xmlprague-2018-proceedings.pdf.
Bleeker, Elli, Bram
Buitendijk and Ronald Haentjens Dekker. Between Freedom and Formalisation: a
Hypergraph Model for Representing the Nature of Text. Long paper presented
at the TEI Conference and Members meeting 2019, September 16-20 2019, Graz, Austria.
Slides available from: https://zenodo.org/record/3929350. doi:https://doi.org/10.5281/zenodo.3929350.
Ciancarini, Paolo, Angelo
Di Iorio, Carlo Marchetti, Michelle Schririnzi, and Fabio Vitali. Bridging the gap
between tracking and detecting changes in XML. In Software: Practice and Experience, vol. 46, no. 2 (2016), pp.
227-250. doi:https://doi.org/10.1002/spe.2305.
Dekhtyar, Alex, and
Ionut Emil Iacob. A Framework for Management of Concurrent XML Markup. In
Data and Knowledge Engineering, vol. 52, no.2, pp.
185-215 (2005). doi:https://doi.org/10.1016/j.datak.2004.05.005.
Di Iorio, Angelo,
Michele Schirinzi, Fabio Vitali, and Carlo Marchetti. A natural and multi-layered
approach to detect changes in tree-based textual documents. In International Conference on Enterprise Information Systems,
pp. 90-101. Springer: Berlin, Heidelberg (2009). doi:https://doi.org/10.1007/978-3-642-01347-8_8.
Haentjens Dekker, Ronald and David J. Birnbaum. It’s more than just overlap:
Text As Graph. Presented at Balisage: The Markup Conference 2017,
Washington, DC, August 1–4, 2017. In Proceedings of Balisage: The
Markup Conference 2017. Balisage Series on Markup Technologies, vol. 19
(2017). doi:https://doi.org/10.4242/BalisageVol19.Dekker01.
Haentjens
Dekker, Ronald, Elli Bleeker, Bram Buitendijk, Astrid Kulsdom and David J. Birnbaum.
TAGML: A markup language of many dimensions. Presented at Balisage:
The Markup Conference 2018, Washington, DC, July 31 - August 3, 2018. In Proceedings of Balisage: The Markup Conference 2018. Balisage Series on
Markup Technologies, vol. 21 (2018). doi:https://doi.org/10.4242/BalisageVol21.HaentjensDekker01.
Huitfeldt,
Claus, and C. M. Sperberg-McQueen. TexMECS: An experimental markup meta-language
for complex documents. Last revised on October 5, 2003. Available online.
Van Hulle,
Dirk, Mark Nixon, And Vincent Neyt, editors. Samuel Beckett's Digital
Manuscript Project. Antwerp: University Press Antwerp.
http://www.beckettarchive.org, last updated in 2019.
Marcoux, Yves, Claus
Huitfeldt and C. M. Sperberg-McQueen. The MLCD Overlap Corpus (MOC): Project
report. Presented at Balisage: The Markup Conference 2012, Montréal, Canada,
August 7 - 10, 2012. In Proceedings of Balisage: The Markup
Conference 2012. Balisage Series on Markup Technologies, vol. 8 (2012).
doi:https://doi.org/10.4242/BalisageVol8.Huitfeldt02.
Ostrowski, Donald, David J.
Birnbaum, and Horace G. Lunt. The e-PVL: An electronic edition of the Rus'
primary chronicle. Via http://pvl.obdurodon.org/.
Peroni, Silvio and
Fabio Vitali. Annotation with EARMARK for Arbitrary, Overlapping and Out-of-Order
Markup. Presented at the DocEng’09 conference, September 16-18, 2009. In
Proceedings of the 2009 ACM Symposium on Document Engineering
(2009), pp. 171-180. ACM: New York. doi:https://doi.org/10.1145/1600193.1600232.
Portier, Pierre-Édouard,
Noureddine Chatti, Sylvie Calabretto, Elöd Egyed-Zsigmond and Jean-Marie Pinon.
Modeling, Encoding And Querying Multi-structured Documents. In
Information Processing & Management, vol. 48,
no. 5 (2012), pp. 931-955. doi:https://doi.org/10.1016/j.ipm.2011.11.004.
Schmidt, Desmond,
and Robert Colomb. A data structure for representing multi-version texts
online. In International Journal of Human-Computer
Studies, vol. 67, no.6 (2009), pp. 497-514. doi:https://doi.org/10.1016/j.ijhcs.2009.02.001.
Schmidt, Desmond,
and Domenico Fiormonte. Multi-Version Documents: A digitisation solution for
textual cultural heritage artefacts. In Intelligenza
Artificiale, vol. 4, no. 1 (2010), pp. 56-61.
Schonefeld, Oliver.
XCONCUR and XCONCUR-CL: A constraint-based approach for the validation of
concurrent markup. In Data Structures for Linguistic
Resources and Applications. Proceedings of the Biennial GLDV Conference
(2007).
Spencer, Matthew and
Christopher Howe. Collating Texts Using Progressive Multiple Alignment.
In Computers and the Humanities, vol. 38 (2004), pp. 253-270.
doi:https://doi.org/10.1007/s10579-004-8682-1.
Sperberg-McQueen, C. M.
Sometimes a question of scale. Presented at Balisage: The Markup
Conference 2009, Montréal, Canada, August 11 - 14, 2009. In Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup
Technologies, vol. 3 (2009). doi:https://doi.org/10.4242/BalisageVol3.Sperberg-McQueen02.
Witt, Andreas, Oliver
Schonefeld, Georg Rehm, Jonathan Khoo, and Kilian Evang. On the Lossless
Transformation of Single-File, Multi-Layer Annotations in Multi-Rooted
Trees. In Proceedings of Extreme Markup Languages
2007, Montréal, Canada, 2007. Available from:
http://conferences.idealliance.org/extreme/html/2007/Witt01/EML2007Witt01.xml.
Woolf, Virginia. 1927. To the Lighthouse. Holograph ms. Berg Collection, New York
Public Library; Proofs, Smith College Libraries. Pamela L. Caughie, Nick Hayward,
Mark
Hussey, Peter Shillingsburg, and George K. Thiruvathukal, editors. Woolf Online.
Author's keywords for this paper:
textual genetic research; automated collation; data model; nonlinearity; graph database; multiple hierarchies; overlap; hypergraph; simultaneity; TAG; text as graph; TAGML; HyperCollate