BalisageUp-Translation and Up-Transformation: Tasks, Challenges, and Solutions2017
How to cite this paper
Piez, Wendell. “Uphill to XML with XSLT, XProc … and HTML.” Presented at Up-Translation and Up-Transformation: Tasks, Challenges, and Solutions, Washington, DC, July 31, 2017. In Proceedings of Up-Translation and Up-Transformation: Tasks, Challenges, and Solutions. Balisage Series on Markup Technologies, vol. 20 (2017). https://doi.org/10.4242/BalisageVol20.Piez02.
Up-Translation and Up-Transformation: Tasks, Challenges, and Solutions July 31, 2017
Balisage Paper: Uphill to XML with XSLT, XProc … and HTML
Wendell Piez
Wendell Piez is an independent consultant specializing in XML and XSLT, based in
Rockville MD.
HTML is a widely familiar vernacular for ad-hoc representation of documents, and
can be useful as a staging ground for decomposing and breaking down the more complex
operations in uphill data transformation. HTML, syntactically well-formed and maintained
within XML pipelines with well-defined interfaces, can usefully join XSLT and XProc
to
provide for a complete up-conversion or data-enhancement pipeline – especially when
the
ultimate target is semantically richer than HTML. In a project based on this approach,
lessons learned include: “Many steps may be easier than one”; “If it doesn't work,
try it
the other way around”; and “Validation is in the eye of the beholder”.
Facing a specific interface (internal or external)
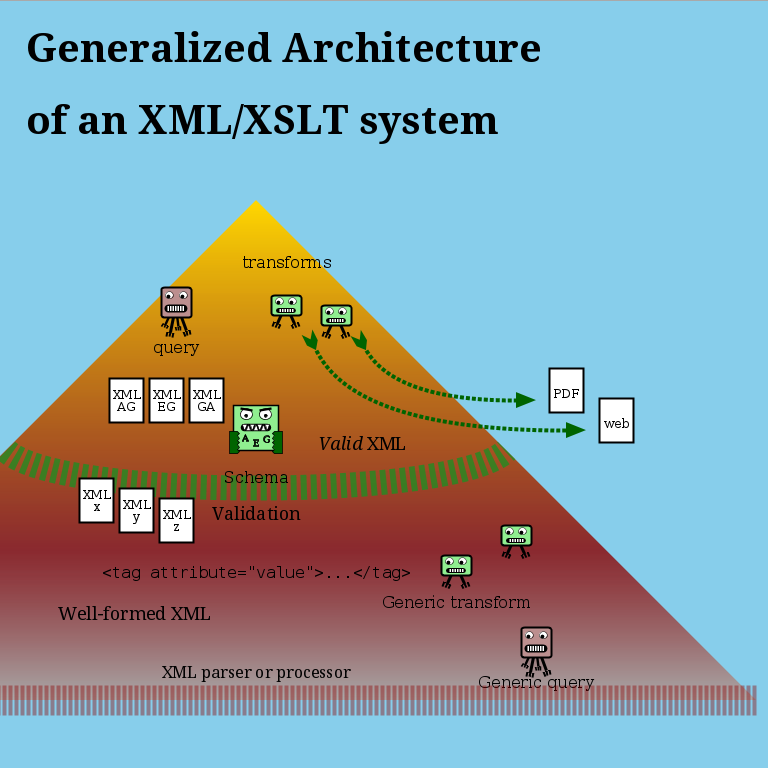
Four uses for data formats
Figure 4
Distinguishing among these four different uses for a data format, may be helpful.
Application format
System hub format
(Abstracted from processes; generalized)
Control format
(Further generalized and externalized)
Carrier format
(Commonly a form of an application or hub format, i.e. an application of an
application)
Note
Application
A data format may provide for functionalities in processing, either directly or
via indirect bindings or programming. "Display on the web" broadly is an application
of HTML. But HTML archived for long-term storage (and hence tomorrow's processor)
is
not aiming (or not aiming only) at this use.
The great attraction of electronic data formats is in their fungibility, which can
permit them (in principle and often actually) to be represented and re-represented
in
and for other applications. Thus even hard-core "application profile" formats such
as
SVG or XSL FO (formatting objects), must maintain a balance between supported
functionalities, and abstract specifications.
Hub
The design, specification, application and use of a hub format is different from
an application format. In theory and practice, hub formats have enabled data reuse
and
re-publication by providing for "downhill conversion" into one or more application
formats.
The entire reason we conceive of "uphill conversion" at all is because we envision
a hub format in which encoded information is "high value" – both "clean" and "dense",
meaning both more expressive and more efficient, parsimonious, integral and
communicative. If such a format is identified with an application, then so must our
data be. When this becomes a problem (as it inevitably does sooner or later), the
way
to insulate and protect data from "application rot", likewise, is to take care that
the representations (in and of its encoding) be abstracted away from application
requirements. A hub format provides a safe home, as it were.
Historically, the broadly descriptive formats including TEI, JATS, DITA and
Docbook were all developed to serve this role, in information systems of various sizes
and scales of complexity.
But plenty of systems exist that have their own private hub format of one form or
another. Indeed, XML itself is only one of many ways a hub format can be defined and
managed.
Carrier
However, just because we have a hub format, doesn't mean we have to use it for
every purpose: on the contrary, the opposite must necessarily be the case. Just as
we
expect to translate data "out of" or "down from" our hub into application formats,
we
might suppose that data on the way "in" or "up into", might require something that
doesn't impose (or, at any one stage, doesn't yet
impose) all the rigors of the hub.
Similarly we may have formats or data encoding regimens that serve for nothing but
a communicative purpose (for example, between two systems that have their own hub
format). That's a carrier format.
It isn't difficult to produce an artificial carrier format or indeed to adapt a
hub format (typically by relaxing it) to this purpose. It is also possible (and
frequently easier) to adapt something.
Note that, somewhat confusing, someone's carrier format, may be someone else's
application format. That is, what is a carrier for you (internally) becomes for them,
an interface that they have to target (externally).
Thus it's typical to try and cheat, using an application format as a carrier
format and vice versa. That is what we are doing here.
Control
Finally, it should be noted that actual control over a data set may be exerted,
even without a fully specified hub format – inasmuch as control mechanisms may take
other forms than the classic constraints over markup languages (which focuses
validation on element type names, containment as represented syntactically, and
attribute flags. Sometimes the hub format or essential aspects or elements of the
hub
are better regarded as a projections of other, further abstracted models or
taxonomies.
It is frequently difficult, when considering a system especially that has grown
over time, to determine exactly where the control points actually are. Especially
since where they are actually controlled (operationally) and where they are nominally
dictated, are often two different things. Documentation, it is sad to say, is more
often than not out of date.
These entanglements are all reasons, it may be, not to rely on a hub format to do
every job in the world. Imposing a requirement that a process artifact (even a
temporary one) conform to a hub format (designed for another purpose) may be an
arbitrary imposition as often as it's a neat trick. Better to keep the hub format
for
the good data, the controls in place – and with the data that is not so good or not
yet so good, don't make such demands.
History of these projects
Figure 5
TEI transcription of translated tract
Figure 6
Started with editorial work from plain text sources
HTML did not start this way – but it has evolved in the direction of this
capability
(HTML is a hub format that was broken on the wheels of its applications.)
HTML Typescript
Figure 11
Sir James Cantlie (1851-1926), Lecture on Hong Kong. Typescript with holograph
corrections, etc., London, 1898. Page 19: a more or less random typescript page from
Wikimedia Commons
HTML can present rough-but-capable representation of "what an author wrote"
Analogous to a "typescript" in print-oriented production
Represents a work in progress, not a finished work
Its lack of (final) production values is part of the point
Offers a site of analysis, negotiation and preparation for the next stage of
production
By analogy - a downstream consumer is apt to be happier to consume HTML than most
any
other format even a "better" one ...
Sulphur Mountain Resort (interior), Banff. By Tony Hisgett. Wikimedia Commons.
"Mountain chalet" theory of upconversion
("When climbing a tall peak it's nice to have a mountain chalet halfway up")
The shortest distance between two points is not always a straight line
"Many steps are sometimes easier than one"
Pipelines and processing
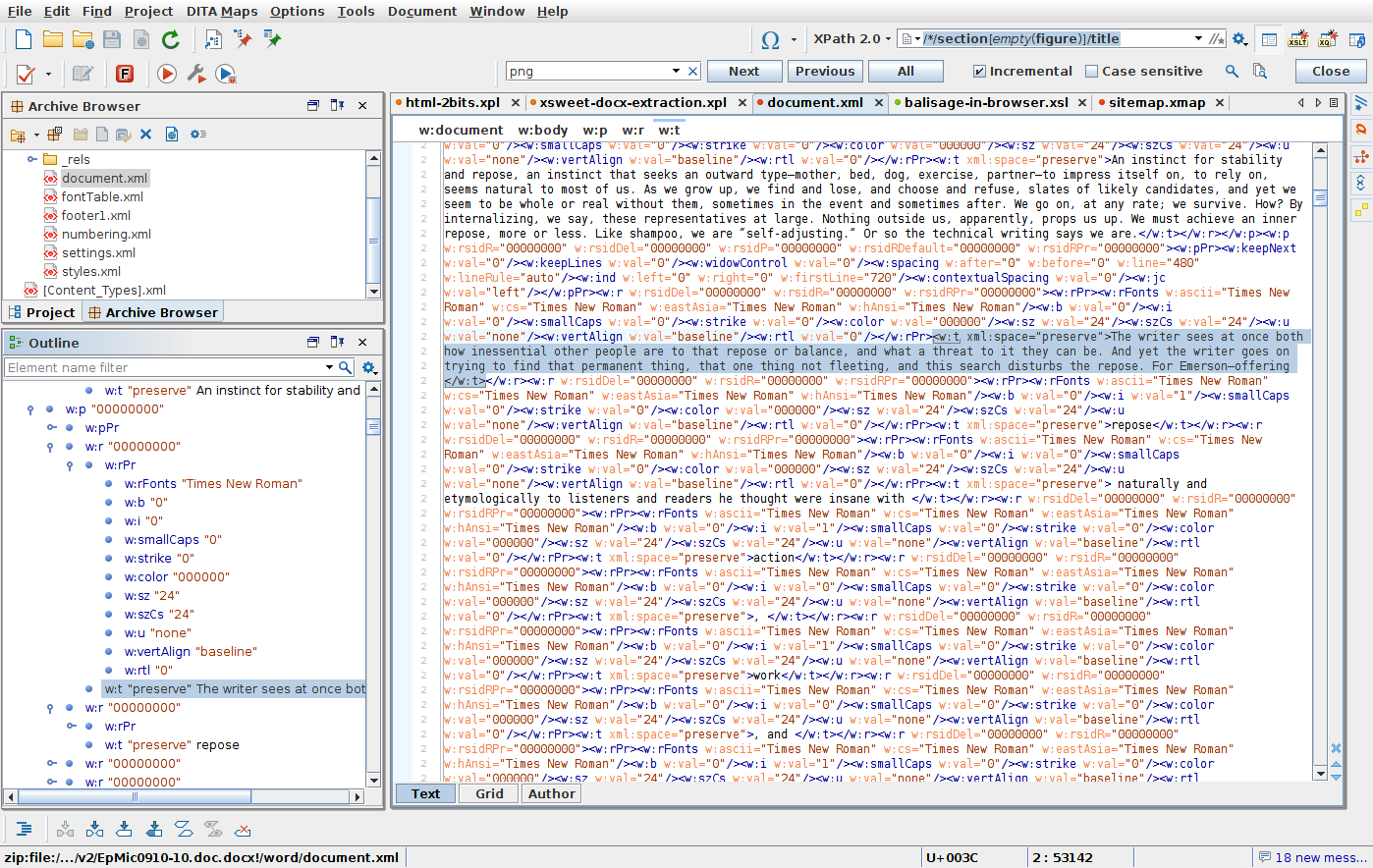
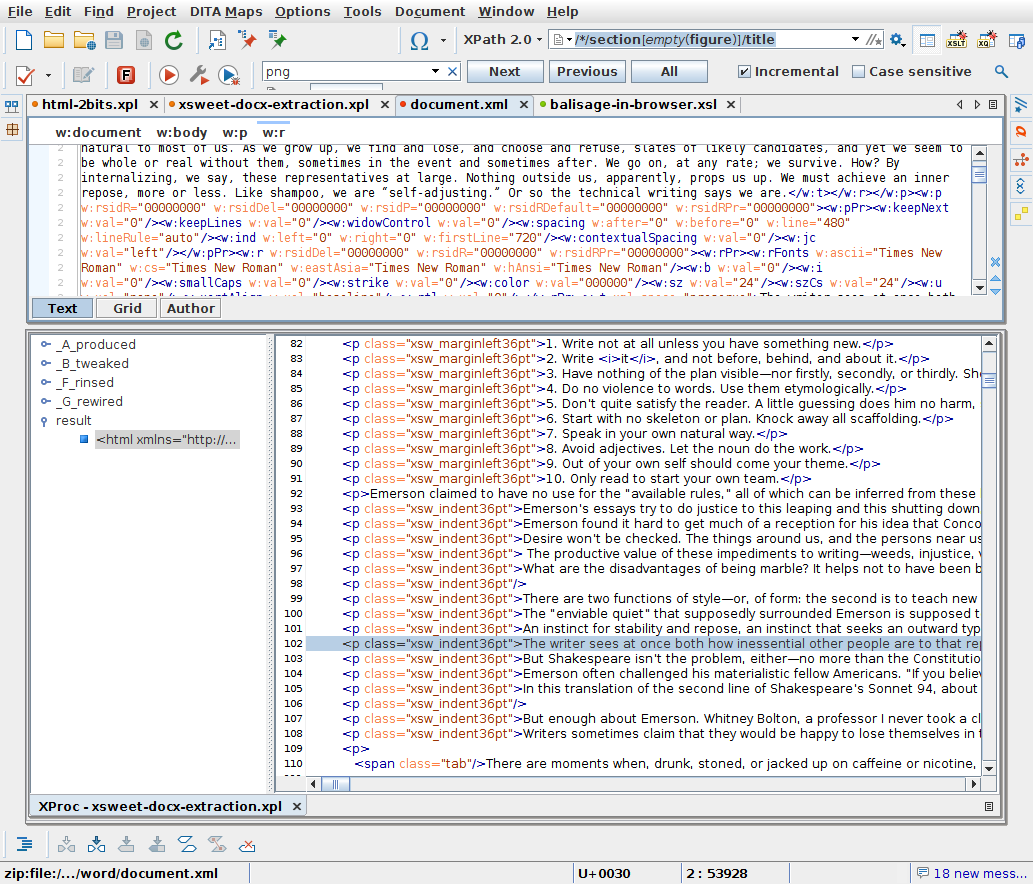
Figure 13
"Before" - Word (OOXML) source
Figure 14
"After" - pulled into (reasonably clean) HTML
Having a carrier format in place early is helpful
At least data transmission is possible even while other aspects are tbd
Pipelines permit handling complex problems!
By breaking down into simpler problems
Freeing up order of development priorities
"Try it the other way around"
Early HTML production is an example of this
Or, performing header promotion, and only then structural induction
A system is no longer all-or-nothing
Note
Many of the more challenging problems in data conversion are much more tractable when
broken into parts or phases, than they are when conceived as single operations. Having
an
nominal carrier format already designed – even before other parts of a system are
yet fully
mature – is really helpful when we turn to building tools and processing, since one
aspect
of that problem at least (namely, what sorts of tags to use to express things), has
been
reduced, making it possible to focus on the more essential parts (what is the information
being represented and processed).
Thus, even when HTML solves no problems for a conversion pipeline, it can expose them.
This is itself is really useful.
So for example, a huge problem in data conversion is structural inferencing – how
to
determine appropriate structures latent in unstructured data: in transformation terms,
allocating contents to structures properly in a result, even when the input is "soup".
It is
convenient, though not essential, that HTML can be used easily to represent data in
both
forms, before ("soupy") and after ("structured"), using HTML div or
section elements to represent the structure.
It's getting from one form, to the other, that is the problem. Producing the soup
from
the structure is easy: that's why we call it "down". But to get structure from the
soup is
comparatively difficult, and solutions tend to be accordingly brittle, partial and
limited.
The process requires two distinct operations, not just one. First, the "signaling
elements"
that are taken to represent structural boundaries (in this case, section titles or
other
section demarcators), must be recognized. (For most purposes in structured documentary
data,
section titles serve as effective signals regarding at least some salient document
structures. But this is not always the case.) Only once this has occurred (logically
or
temporally) does it become possible to render the structure itself. And rendering
the
structure is only possible if the signals line up.
This two-phase approach plays out easily in HTML: in the first phase, paragraphs that
are "actually headers" can be promoted to h1-h6. In the second phase, the section
structure
is built up from the headers. Each of these is significantly easier, when it can be
isolated
from the other.
What's more, we can explain it this way, and anyone familiar with HTML can understand
it. We don't need to educate them in a new data representation to make our methods
explicable.
Arbitrary tweak of HTML @class / @style - add/remove
Configured for runtime w/ XML driver
Header promotion by induction
Filter paragraphs by formatting properties, reduce, count and sort them
Assign header level categories based on combinations of properties
Produce an XSLT from this (result of analysis) for this particular instance (or
family member)
Apply this XSLT to original document to match and produce headers
Note
A so-called "meta-pipeline" or "meta-transformation", loosely, might be any application
of a transformation technology that is anything but the simple three-part
source/transformation/result arrangement. Yet even within a simple architecture, pipelines
will typically be made of pipelines, and transformations will include multiple "logical"
and
even "temporal" steps or stages, within both their specification(s) and their execution.
More complex arrangements are possible and sometimes useful. These include not only
pipelines of transformations in sequence (each one consuming the results of the precedent
one) but also pipelines with extra inputs, spin-off results, or loops, wherein (for
example)
logic is produced in one branch that is then used to transform the results of another
branch.
Because XSLT is syntactically homoiconic (canonically expressed in the same notation
that it reads and produces, i.e. XML), it is a straightforward exercise to construct
a
pipeline whose transformation is itself generated dynamically. This is useful if we
don't
know what XSLT we will want, until runtime. If we can specify inputs to produce a
transformation programmatically, we can delay its actual production until we have
the
data.
An example is the header promotion transformation as described above – a transformation
of HTML data in which paragraphs (p elements) can be mapped into h1-h6 based on properties
either assigned to them (in the data) or accessible and measurable. This is not a
trivial
operation, but it can be achieved using pipelines in and with XSLT.
The difficulty is that such a transformation depends on an assessment of which
properties assigned to which paragraphs, separately and together, warrant promotion
for that
(type) of paragraph. The particulars of this assessment may only be fully discovered
in view
of the data itself. So a pipeline has to "inspect" and "assess" the data itself before
it
can produce its set of rules for handling it.
Thus, in a pipeline, header promotion can proceed in three steps: in the first step,
and
analysis of the data is conducted in which candidate (types of) block-level or
p elements are selected and bound to (different levels of) header elements.
In a second step, this analysis (result) is fed to a generic "meta-transformation"
XSLT that
produces a one-time use XSLT specifically for the data set. The third step is the
application of this one-time custom-fit XSLT to the data, matching elements appropriately
to
produce headers from the p elements as directed.
As noted, HTML's lack of any kind of structural enforcement over its element set,
is
very advantageous here. A header promotion transformation can litter the result file
with h1
- h6 elements, all without (much) concern either for formal validation or for predictable
behavior in tools.
To be sure, such raw data may not be ready to bring into a structured environment,
which
will not permit such a free representation: but then, that is the point. The inference
of
div or section boundaries, once headers are in place, is another fairly
straightforward operation – when the data warrants it.
Other similar examples of pipelines, metapipelines and multi-stage pipelines can be
mentioned, including pipelines
Producing diagnostic outputs (document maps, error reports etc. etc.)
Referencing external (exposed) configurations or "drivers" to simplify
operation
Enriching data sets (e.g. content type inferencing) by reference to rule sets,
external authority files, or other criteria
Murky worlds
Figure 16
From The Life and Opinions of Tristram
Shandy
Laurence Sterne, 1759.
Notice we leave aside issues having to do with (for example) fine points of HTML
alignment
List structures, lists inside paragraphs ...
This is because we aren't validating!
"Valid is in the eye of the beholder" and formal HTML validation buys us
nothing
Instead, we promiscuously mix tag sets
Regression testing as we proceed permits this to occur as a "shaping"
End point is when our target data is strong not when process is (ever) finished
We may well introduce other data enhancements along the way
This is upconversion, the task is endless
Note
One interesting and unexpected consequence of distinguishing our temporary carrier
format from our long-term hub format, is that it becomes possible to mix them on the
way
from one to the other. This may be regarded as cheating - certainly it feels a little
different to write XSLTs that expect tagged inputs to be mixed, and to behave accordingly.
Yet since the entire purpose of such XSLT is to clean up
such tagging (i.e. to reduce the use of the uphill carrier format in favor of the
hub
format), this isn't actually a problem. It's something we can get used to.
In such murky worlds, the introduction of ad-hoc validation steps for even intermediate
results, is sometimes useful. For example, a Schematron can tell whether an HTML file's
headers (h1-h6 elements) are in "regular order", thus susceptible to serving as markers
of a
regularly-nested div or section structure. (One implementation of a rule enforcing
regular
order is that each header be either an h1, or not more than one level below the immediately
preceding header. So an h4 can directly follow an h5 or h3, but not an h2.) Naturally,
much
emphasis is placed on assigning and managing values to @class and thereby abstracting
semantic categories away from the literal code.
Work on validating profiles of HTML is critical to this. Schematron is one option.
So is
Gerrit Imsieke's Epischema https://www.xml.com/articles/2017/04/29/epischemas/. In any case, when the goal
remains clear – both valid and optimal expression in the target language – much remains
forgiveable along the way. The relevant principle here is "Validation is in the eye
of the
beholder".
Another consequence of the "murky worlds" is that it becomes possible to implement
features such as "passive upconversion". For example, a system that produces JATS
from
arbitrary HTML can easily be "sensitized" to produce certain JATS elements as soon
as their
names are found on HTML inputs, assigned via @class. This makes the implementation
of
mappings from any HTML into these JATS elements, as easy as seeing to it that the
appropriate class value is provided in an HTML → HTML transformation – something relatively
easy to configure and implement. (Especially using another meta-XSLT.)
Sometimes it turns out if we reverse the order of operations (assumptions), things
can
be easier
Operative principle is "try it the other way around"
For example, if we have prior knowledge as to document structure, a
pull can be (much) easier to execute than an induction
HTML early is another example of this
Refactor, break the problem apart and "conquer in detail"
The last mile problem
Figure 18
A search on a popular search engine for "last mile problem" yields among other things
this photo of the Esopus Meadows Lighthouse (Esopus New York). By John Hirth,
CC-BY-SA.
Of course we are not interested in HTML (even clean) but (say) JATS, TEI or DITA
But many problems of going to SADF (standard average document format P
Flynn) can be addressed in an HTML target, making subsequent conversion easy
E.g. header promotion, list induction
When this is not the case – we'd have had a problem anyway
Can this be scaled up? Perhaps not without process controls up front
(When is it better than a screen scrape: tipping point at ca. 30 MS pp?)
The case against HTML on the way up hill
Figure 19
Balloons over Cologne, 2010. Photo by the author.
Scaling problem?
XSweet is designed on the assumption that the problem splits into tractable and
irreducible aspects
So XSweet addresses tractable problems
creating clean/vernacular HTML-something from Word
While setting irreducible aspects aside
mapping arbitrary, implicit, local semantics into controlled content objects
Is this analysis correct?
The flip side is that HTML-first offers a pipeline that is transparent and
traceable throughout
Semantic inadequacy of HTML?
A carrier format can afford to be embarrassed about its syntax and even its semantics,
if the job gets done
In practice, extending CSS (slightly) has proven to be all that is ever needed
Haupt, Stefanie, and Maik Stührenberg. “Automatic upconversion using XSLT 2.0 and
XProc: A real world example.” Presented at Balisage: The Markup Conference 2010, Montréal,
Canada, August 3 - 6, 2010. In Proceedings of Balisage: The Markup Conference 2010. Balisage
Series on Markup Technologies, vol. 5 (2010). doi:https://doi.org/10.4242/BalisageVol5.Haupt01.
Piez, Wendell. “Framing the Problem: Building customized editing environments and
workflows.“ Presented at Balisage: The Markup Conference 2016, Washington, DC, August
2 - 5,
2016. In Proceedings of Balisage: The Markup Conference 2016.
Balisage Series on Markup Technologies, vol. 17 (2016). doi:https://doi.org/10.4242/BalisageVol17.Piez01.
Haupt, Stefanie, and Maik Stührenberg. “Automatic upconversion using XSLT 2.0 and
XProc: A real world example.” Presented at Balisage: The Markup Conference 2010, Montréal,
Canada, August 3 - 6, 2010. In Proceedings of Balisage: The Markup Conference 2010. Balisage
Series on Markup Technologies, vol. 5 (2010). doi:https://doi.org/10.4242/BalisageVol5.Haupt01.
Piez, Wendell. “Framing the Problem: Building customized editing environments and
workflows.“ Presented at Balisage: The Markup Conference 2016, Washington, DC, August
2 - 5,
2016. In Proceedings of Balisage: The Markup Conference 2016.
Balisage Series on Markup Technologies, vol. 17 (2016). doi:https://doi.org/10.4242/BalisageVol17.Piez01.