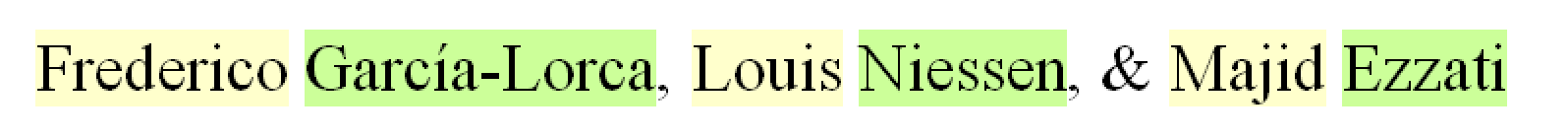BalisageUp-Translation and Up-Transformation: Tasks, Challenges, and Solutions2017
How to cite this paper
Gebhard, Caitlin. “Finding the Tipping Point in Automated Markup During Up-Translation.” Presented at Up-Translation and Up-Transformation: Tasks, Challenges, and Solutions, Washington, DC, July 31, 2017. In Proceedings of Up-Translation and Up-Transformation: Tasks, Challenges, and Solutions. Balisage Series on Markup Technologies, vol. 20 (2017). https://doi.org/10.4242/BalisageVol20.Gebhard01.
Up-Translation and Up-Transformation: Tasks, Challenges, and Solutions July 31, 2017
Balisage Paper: Finding the Tipping Point in Automated Markup During Up-Translation
Caitlin Gebhard is the Customer Support and QA Project Lead at Inera, where she
provides user-focused technical support, documentation, project management, and design
to
the eXtyles and Edifix product teams. Ms. Gebhard uses her love of design and technology
to enhance a variety of user experience and workflows in the scholarly publishing
community. Prior to joining Inera in 2013, she studied technical writing and digital
authorship. She received a BA in English from the University of Massachusetts
Amherst.
Up-translation can be accomplished using both automation and manual techniques. For
most complex content, complete automation can introduce errors or miss content that
requires
tagging, but manual tagging is time consuming and potentially error prone. The best
results
can be obtained by finding a middle ground between automation and manual tagging.
However,
finding that middle ground is, itself, a challenge, and addressing that challenge
requires a
careful balancing act of investing in software development for automation, automatic
flagging of suspect cases for manual review, and designing a tagging and quality-assurance
workflow that is both robust and efficient. This paper discusses the inevitable
inconsistencies, ambiguities, and “gotcha” moments that are encountered when up-translating
scholarly manuscripts to models such as JATS and BITS, and provides recommendations
for
balancing automation with manual review.
While researchers continue to write primarily in Microsoft Word (with the exception
of
some disciplines preferring LaTeX), most systems surrounding the publication of scholarly
manuscripts are driven by XML. Submission systems use XML to capture author and article
metadata. Further, XML drives initiatives such as Crossref for digital object identifiers
(DOIs), ORCID for author identifiers, and FundRef for funding information, not to
mention the
web and e-book platforms on which the content is published.
The scholarly publishing community, particularly in the STEM fields, has adopted the
JATS
(Journal Article Tag Suite) DTD and its sibling, BITS (Book Interchange Tag Suite)
DTD, as the
standard XML formats for published journals and books, respectively. JATS is the most
recent
incarnation of the NLM DTDs, originally released in 2003 by the National Center for
Biotechnology Information (NCBI) of the National Library of Medicine (NLM). The NLM
DTDs
evolved from 2003 to 2008, at which time it was clear that they needed to be formally
standardized. The DTDs were submitted to the National Information Standards Organization
(NISO) in 2008, and in 2012, the ANSI/NISO Z39.96 (informally known as JATS) standard
was
published. The most recent version of this standard is JATS 1.1, revised in 2015 (ANSI/NISO
Z39.96-2015).
Tagging Complex Content
The JATS and BITS models are quite rich and complex, befitting the varied and
complicated content scholarly organizations publish every day. While this complexity
allows
publishers to be more flexible and quite granular with their content, it makes automated
up-translation challenging. At the 2017 Journal Article Tag Suite Conference (JATS-Con
2017), a member of the International Standards Organization (ISO) discussed his experience
in finding a vendor to convert ISO’s back-catalogue content to ISOSTS XML, a standards
DTD
based on JATS:
During the RFP process, we heard statements such as “we can provide 100% accuracy
and 100% automation”. This is simply impossible, and Innodata were one of the more
open
providers initially offering 98% accuracy and being quite upfront this would be a
semi-automated process, ie, a large part of the operation would require manual tagging.
(Galichet 2017)
ISO sought an XML conversion process that would guarantee at least 99.95%
accuracy, but found that this was impossible to accomplish with automation alone.
Likewise, the complexity of the content, the richness of the models, and what can
only
be called the human factor make it extremely difficult to
perform high-quality, accurate up-translation through manual processes alone. Completely
manual tagging is prone to headache-inducing inconsistencies and one-off errors that
do not
occur in an automated process For example, this author has seen instances where the
publication-type attribute “journal” was misspelled:
<mixed-citation publication-type="jornal".../>
Because the publication-type attribute allows any value, the misspelled “jornal” type
is
valid according to the DTD, but it would throw a wrench in any system trying to access
journal references tagged correctly:
<mixed-citation publication-type="journal".../>
Rather than attempt the herculean feat of high-quality up-translation through either
fully automated or fully manual processes, scholarly content requires a careful balance
of
both. However, finding the tipping point between the two processes can be a challenge.
In
this author’s experience, a semiautomated process is is most effective for capturing
certain
types of metadata. In particular, publishers are often sensitive about the metadata
located
in the front matter. It is important for such metadata to be accurate so that citations
to
that record are (hopefully) correct. Bibliographic citation data are likewise important
because they drive the statistics around the scholarly record, the journal, and the
publisher.
Contributor Metadata
The accurate tagging of contributor metadata is not just a courtesy to the authors;
it
also drives many of the systems surrounding and influencing the scholarly community.
An
incorrectly tagged author name can result in overlooked credit or misattribution of
credit, incorrect bibliographic references to the author that appear in subsequent
papers,
and confusion at funding organizations. As part of their Science
Editor series on international naming conventions, the Council of Science
Editors published several articles with guidelines for editing (and, therefore, parsing)
author names from around the world. In one article on Spanish and Portuguese naming
conventions, Bill Black highlights the importance of editing and parsing contributor
names
correctly: “It can help to ensure that other researchers and bibliographic database
services that cite the articles give the credit due to the authors and to the editors’
journals and that other researchers who see the piece cited can easily locate abstracts
of
the articles or their full text” (Black 2003). Contributor metadata fuels many
different aspects of the research and publishing ecosystem, and it is important to
get it
right.
Bibliographic Citation Metadata
Accurate, granular tagging of the manuscript’s references is just as important as
tagging the manuscript’s author information. As Carol Anne Meyer explains in her article,
“Reference Accuracy: Best Practices for Making the Links,” reference data accuracy
is the
key to providing better experiences for readers and for authors. She writes:
Reference citations in scholarly publishing have never been more important than in
the age of electronic distribution. Not only do references cite relevant previous
work, they also provide one of the most valuable functions in electronic publishing:
an actionable, clickable link to more information about the citation. (Meyer 2008)
Reference linking impacts a publication’s measurability and discoverability,
criteria that benefit both the author as well as the publisher. As Meyer 2008
explains, “any problems with reference accuracy can underestimate the impact of an
author’s work or of a journal.” Editors can spend hours copy editing and correcting
bibliographies, but errors introduced during the conversion to XML can undo all of
that
work in seconds.
Idiosyncrasies: Limitations of Automation
When we (human readers) look at this byline:
D Carol Bird MD, editor
we can identify patterns that inform how we would tag this paragraph according to
the JATS XML model:
We use white space to parse the individual parts of the byline and context to recognize
what those parts are. For example, we know that when “MD” appears at the end of the
author
name, it is likely a degree and not an abbreviated given name. In theory, smart software
could
do all of this tagging automatically.
The problem is that the pattern-recognition algorithms used in smart software can
only get
you so far. What happens when smart software encounters a pattern that it is not programmed
to
recognize? Even worse, what happens when it encounters a pattern that looks exactly
like
something it can recognize but is actually something
completely different?
Multicultural Contributions
Due to the variety of human naming conventions around the world, it is nearly impossible
for a machine to correctly parse every author name it encounters. It is also fair
to say
that a human reader will not accurately parse every name she or he encounters, but
humans
have the added benefit of common sense, flexibility, and the Internet. When in doubt,
a
human reviewer can check her or his understanding of a name against reference sources
(or
ask the author). It is difficult to program a piece of software to question itself
in the
same way.
Here are some examples of cases that cannot be handled by automation alone.
Example 1: Multipart Names
A machine can easily be trained to parse names that have multiple given names and/or
surnames, but without understanding the author’s background, the results will never
be
100% correct. For example, a smart machine can use white space and a bias toward Western
naming conventions to automatically parse and tag the multipart name “Jonathan Taylor
Thomas” without error:
If the same algorithm is applied to names from other cultural contexts, it will likely
mis-parse the name. For example, if the machine uses the same white space identification
and Western name bias as in the previous example, it will mis-parse the Spanish name
“Federico García
Lorca”:
In Science Editor’s article on editing author names
from Spanish- and Portuguese-speaking countries, Black 2003 explains that names
of Spanish origin often use two family names, “the first being the father’s and the
second
the mother’s.” He continues:
When a woman marries, she drops her mother’s name but keeps her father’s name, to
which she appends the preposition de (“of”) followed by her husband’s father’s
surname. For example, if María Esquivel López marries Juan Sánchez Mendoza, she drops
her mother’s surname (López), keeps her father’s surname (Esquivel), and adds “de
Sánchez,” becoming María Esquivel de Sánchez. (Black 2003)
There are also variations in how the parts of the compound surname are
presented; “some women omit the de when adding the
husband’s surname, such as using María Esquivel Sánchez instead of María Esquivel
de
Sánchez ” (Black 2003). On top of this, Hispanic given
names may contain multiple parts, such as “María Cristina” or “José Fernando”
(Black 2003).
Using the same automated parsing rules as illustrated earlier, and if the software
is
programmed to identify “de” as a surname prefix, the name “María Esquivel de Sánchez”
would be incorrectly parsed
as:
<contrib contrib-type="author">
<name><surname>Esquivel de Sánchez</surname>
<given-names>María Cristina</given-names></name>
</contrib>
Black 2003 summarizes that “for persons unfamiliar with Spanish names, the
use of compound given names can make it difficult to decide whether a word that falls
in
the middle of a name is the second part of the given name or is the paternal surname.”
It
is part of an editor’s job to know this kind of information and get the metadata right.
However, low-skilled manual taggers and semi-smart software may not have the nuances
of
international naming conventions incorporated into their workflows, and errors can
easily
be introduced in the author metadata.
Example 2: Surname or Suffix
Inappropriate translations can also introduce errors. In the name “Edward Araujo
Júnior,” the author’s full surname is “Araujo Júnior,” but we can imagine software—or
low-skilled manual taggers—incorrectly parsing “Júnior” as the English generational
suffix
“Junior”:
Left
uncorrected, such an error would inevitably cause subsequent errors in citations to
Mr.
Araujo Júnior’s work.
Example 3: Eastern Order of Names
In some Eastern and East European cultures, the family name and the given name are
presented in the opposite order in which Western cultures present the names. In Science Editor’s article, “English Versions of Chinese Authors’
Names in Biomedical Journals: Observations and Recommendations,” Sun et al. 2002
explain that “in Chinese the surname precedes the given name. Thus, for example, in
the
Chinese name Zhou De-An, Zhou is the surname and De-An is the given name.” Automation
tools whose algorithms are configured to parse primarily Western-style names will
inevitably mis-tag such names. Unfortunately, the author Zhou De-An is easily mis-tagged
as:
While it is possible to switch the order of elements in the algorithm, what happens
when it encounters a group of contributors that consists of both Western- and
Eastern-style names? If Han Solo (given name “Han”) and Han Sunghee (given name “Sungee”)
were to publish a paper together, how would a single algorithm tag these names correctly?
The problem can become even more complicated, because some East Asian authors will
attempt to westernize their names and change, for example, “Lee Choon Shil” to “Choon
Shil
Lee” when submitting a paper to a Western (or English-language) journal. Worse, sometimes
publishers do not realize when an author has converted their Eastern name to Western
order, and the name is further mangled as the editor tries to Westernize an Eastern
name
that is already in Western order.
For editors without access to proper training—or a solid understanding of proper
tagging—East Asian names may be left completely unparsed; the full name is tagged
as the
<surname> without any effort to disambiguate the given name and family name. For
example, the Korean authors of a conference paper deposited with Crossref
(doi:10.1109/RFIC.2003.1213947) are incorrectly tagged as:
Some research into Korean naming conventions and other publications by the same
authors indicate that the authors submitted their paper using Western naming order;
the
correct tagging should be:
Subsequent editors—or reference-linking software—trying to properly parse or link
to
this paper will be unable to use the DOI metadata of this publication to disambiguate
the
names.
Problem References
Automated parsing algorithms can encounter even more variety when parsing bibliographic
references. Hundreds of different editorial styles are used throughout the publishing
community, and when you take into account typos and inconsistencies introduced by
authors
and the reference management software that authors use, developing software that can
correctly identify each piece of a reference 100% of the time is a herculean feat.
Even the
most sophisticated algorithms will undoubtedly encounter references that can confuse
even
the brightest human editor.
Example 4: Immunoglobulin A
This particular reference follows an author’s unique (perhaps accidental) editorial
style. Semicolons are used to separate each author as well as to separate the author
list
from the article title.
Watanabe A; Kitamura M; Shimizu M; Immunoglobulin A (IgA) with properties of both
cryoglobulin and pyroglobulin. Clinica Chimica Acta. 1974;52(2):231–237.
Although the article title begins at “Immunoglobulin,” someone unfamiliar with biology
or an automated tagging algorithm could easily misidentify this as the last
author—“Immunoglobulin A”:
<ref id="b1"><mixed-citation publication-type="journal"><person-group person-group-type="author"><string-name><surname>Watanabe</surname> <given-names>A</given-names></string-name>, <string-name><surname>Kitamura</surname> <given-names>M</given-names></string-name>, <string-name><surname>Shimizu</surname> <given-names>M</given-names></string-name>, <string-name><surname>Immunoglobulin</surname> <given-names>A</given-names></string-name></person-group>. <article-title>(IgA) with properties of both cryoglobulin and pyroglobulin.</article-title> <source><italic>Clin Chim Acta</italic></source>. <year>1974</year>;<volume>52</volume>(<issue>2</issue>):<fpage>231</fpage>-<lpage>237</lpage>.</mixed-citation></ref>
The correct XML is:
<ref id="b1"><mixed-citation publication-type="journal"><person-group person-group-type="author"><string-name><surname>Watanabe</surname> <given-names>A</given-names></string-name>, <string-name><surname>Kitamura</surname> <given-names>M</given-names></string-name>, <string-name><surname>Shimizu</surname> <given-names>M</given-names></string-name></person-group>. <article-title>Immunoglobulin A (IgA) with properties of both cryoglobulin and pyroglobulin.</article-title> <source><italic>Clin Chim Acta</italic></source>. <year>1974</year>;<volume>52</volume>(<issue>2</issue>):<fpage>231</fpage>-<lpage>237</lpage>.</mixed-citation></ref>
Example 5: False Duplicates
When algorithms that parse out complex content are created, it can be difficult to
account for what appears to be duplicate information. Take this reference:
Morcos MW, Al-Jallad H, Hamdy R. Comprehensive review of adipose stem cells and
their implication in distraction osteogenesis and bone regeneration. BioMed research
international. 2015 Sep 13;2015.
At first glance, an editor might question which “2015” is the print date. An
automated up-translation might try its
best:
<ref id="b1"><mixed-citation publication-type="journal"><person-group person-group-type="author"><string-name><surname>Morcos</surname> <given-names>MW</given-names></string-name>, <string-name><surname>Al-Jallad</surname> <given-names>H</given-names></string-name>, <string-name><surname>Hamdy</surname> <given-names>R</given-names></string-name></person-group>. <article-title>Comprehensive review of adipose stem cells and their implication in distraction osteogenesis and bone regeneration.</article-title> <source>BioMed research international<source>. 2015 Sep 13;<year>2015</year>.</mixed-citation></ref>
But
it will stumble on untangling the dates, and it might incorrectly tag the second instance
of “2015” as the <year>, when in this reference, in fact, it is the volume number.
The correct tagging for this reference is:
<ref id="b1"><mixed-citation publication-type="journal"><person-group person-group-type="author"><string-name><surname>Morcos</surname> <given-names>MW</given-names></string-name>, <string-name><surname>Al-Jallad</surname> <given-names>H</given-names></string-name>, <string-name><surname>Hamdy</surname> <given-names>R</given-names></string-name></person-group>. <article-title>Comprehensive review of adipose stem cells and their implication in distraction osteogenesis and bone regeneration</article-title>. <source>BioMed research international.</source> <year>2015</year> <month>Sep</month> <day>13</day>;<volume>2015</volume>.</mixed-citation></ref>
Example 6: Name Segmentation
As previously discussed in author bylines, name segmentation differs in different
cultures, and without guidance from knowledgeable editors, errors can be easily introduced
into the tagging of contributor names. This problem is more common in bibliographic
references, because the editors cannot simply query the contributors to the reference
as
easily as they can contact the author of the paper. Furthermore, errors introduced
at
other publishers can be reinforced and transmitted to other publications if the erroneous
record is deposited at a metadata service such as Crossref. When an editor or automated
reference linking tool uses such a service to validate the accuracy of their references,
they may be verifying their references against incorrectly tagged data.
Name segmentation errors are one such error category that propagates throughout the
publishing world. The following reference was published in an article in Trace Elements and Electrolytes:
Saiki M, Alves ER, Jaluul O, Sumita NM, Filho Jacob W. Determination of trace
elements in scalp hair of an elderly population by neutron activation analysis. J
Rad
Nucl Chem. 2008; 276: 53-57.
The last author, “Filho Jacob W,” was mis-parsed at some point during the editorial
process. The correct name is “W. Jacob Filho.” Represented in JATS XML, the contributor
is
incorrectly tagged as:
For this reference author, the name may be easily parsed by either a manual tagger
or
machine into the given name “W. Jacob” and surname “Filho” instead.. However, further
research into this particular author found that the surname is actually “Jacob Filho”
(sometimes represented as “Jacob-Filho”), and the given name is “W” (or, “Wilson”).
So,
while the publisher’s reference parsing tools segmented the name correctly, the order
of
surname elements was incorrect. The correct tagging is:
This and other reference errors were examined in a series of Letters to the Editor
in
Trace Elements and Electrolytes, in which one
researcher identified errors in references and Inera responded with explanations of
the
possible causes. Inera summarizes the most common errors:
The most systematic error occurred in author name segmentation (the separation of
name elements into given name(s) and surname(s)). Publishers and their vendors may
need
to review and improve their processes for capturing correct author name information
in
the publication workflow and verifying that all metadata is correct, including not
just
the spelling but the order and segmentation of author names. (Dunford et al. 2017)
Example 6: Vital Health Stat 10
There are also references that automated conversion software can do a better job of
tagging than a human editor. Take the following reference:
Benson V, Marano MA. Current estimates from the National Health Interview Survey,
1992. Vital Health Stat 10 1994 Jan;(189):1-269.
In this case, “10” is part of the journal title Vital Health
Stat 10 (the full name is Vital and Health Statistics.
Series 10. Data from the National Health Survey). Using a well-curated
database of possible journal title names, automation can solve this particular problem,
but it is almost impossible to hand-tag correctly without previous knowledge of this
unusual journal title.
Balancing Automation with Human Review
In order to mitigate the errors that may be introduced by a fully automated process
and
create a workflow that ensures accuracy, publishers must find a way to incorporate
manual
human review without sacrificing the time saved by automation. This might be addressed
in two
ways.: proof the middle steps and flag suspect cases.
Proof the Middle-Steps
In cases where there is no room for error, automated conversion to XML can happen
“under
the hood.” For example, the parsing of submission history dates from
can
happen silently without human review. However, when processing more complex content,
such as
author lists or references, it is prudent to include an intermediary human-review
step. For
example, in the Word document color-coded character styles could be applied to identify
individual components before the document is converted to XML. For example, after
the
initial parsing stage, each element of the author paragraph is marked with yellow
“au_fname”
and green “au_surname” character styles:
Figure 1
By using color-coding and intuitive character style names, the editor can quickly
scan
the byline and confirm or correct the parsed names.
This step is even more important for references, where the nuances of an editorial
style
may render errors in the machine’s results invisible. For example, for the following
reference:
2. Kuck D, Caulfield T, Lyko F, Medina-Franco JL, Nanaomycin A Selectively Inhibits
DNMT3B and Reactivates Silenced Tumor Suppressor Genes in Human Cancer Cells. Mol
Cancer
Ther 2010;9:3015–23.
automation might incorrectly parse “Nanaomycin A” as an author name (similar to
the error that we see in Example 3: Immunoglobulin A). If the resulting XML for this
reference is rendered according to the same editorial style, it would appear as:
2. Kuck D, Caulfield T, Lyko F, Medina-Franco JL, Nanaomycin A. Selectively Inhibits
DNMT3B and Reactivates Silenced Tumor Suppressor Genes in Human Cancer Cells. Mol
Cancer
Ther 2010;9:3015–23.
The only evidence that the XML is incorrect are the comma preceding and period following
the false author, “Nanaomycin A.” With color-coded character styles in the Word document,
the editor can identify and correct the error before the manuscript is converted to
XML:
Figure 2
In this case, the editor would manually correct the character styles applied to the
article title before submitting the manuscript to the final stage of XML conversion.
Flag Suspect Cases
In addition to displaying the results of automated parsing using color-coded character
styles, publishing tools can add an additional piece of communication between the
automation
and the human editor. In cases where it is known that algorithms may introduce errors
when
parsing content, the software can insert Word comments informing the editor that manual
review is necessary. In other words, software developers can take steps to help algorithms
recognize when they are unsure of the results rather than silently introduce errors.
For example, when the software detects that there is a lot of unstyled text between
what
it recognized as the author list and what it recognized as the article title, the
software
is “aware” that it was unsuccessful in automatically parsing the author list. In addition
to
providing color-coded character styles, the software inserts a Word comment alerting
the
editor, or tagger, that there is a problem. The error message may read: “The process
was
unable to fully identify and edit the author list, most likely because of incorrect
punctuation in the original text. Please correct the entire author list by hand.”
Figure 3
Fully self-aware XML conversion software is a long, long way down the road. However,
we
can mitigate errors introduced by automation if we program software to be somewhat aware of its limitations. When software communicates to
the human user whenever it has encountered a hurdle, it is then much easier for the
user to
perform a targeted review of the machine’s work.
Post-Conversion Quality Assurance
In addition to proofing the initial parsing stages of a semiautomated Word-to-XML
workflow, it is often recommended that production teams proof the final XML output.
In the
2011 JATS-Con paper, “Reality Check: What to Expect from Automated Conversion to NLM
XML,”
Bloom et al. 2011 explain the ways in which their team employs XSLT stylesheets to
display a WYSIWYG version of the tagged content . By using a variety of colors, fonts,
and
point sizes, the visual representation makes it easier for editorial and production
teams to
review the tagging of complex elements. This visual scan ensures that the “XML is
not just
valid but correctly represents the data” (Bloom et al. 2011). They conclude:
Pre- and post-conversion effort pays off in the end. No conversion to XML can be a
totally hands-off/lights-out silver bullet. The analysis performed up-front will lead
to a
better result in the end. The final XML will still inevitably need some adjustments
but
the effort put in before and after conversion will minimize the amount of tweaking
necessary.
Coupling manual review and analysis before and after conversion helps ensure that
the
final XML is valid and accurate.
Conclusion
When working with human-created content, it is important to realize that it is impossible
to get completely accurate results from a fully automated up-translation process.
The nuances
of and complexities inherent in such content can never be fully appreciated by a machine.
Alternatively, attempting to perform this up-translation manually is prone to inconsistencies
and one-off errors, not to mention the expense of labor.
For publishers of complex content, up-translation should be accomplished with a careful
balance of automated software and manual review. Finding the tipping point between
what a
machine can do well and what a human can do well is a challenge. In most cases, this
tipping
point is triggered by content that requires a more sophisticated and flexible approach.
In
this author’s experience, the scholarly content that requires a more sophisticated
eye, and
therefore a “cyborg” approach, is the metadata. There is simply too much variation
in this
data—differences in naming conventions, inconsistent styles, and human error—for a
machine to
parse and tag this content accurately.
To address this, we recommend combining the efficiency of smart software with the
flexibility and knowledgeable application of manual review. One way to do this is
to include
an intermediary step between parsing and XML tagging to present the results of automated
parsing to the user for a quick review and possible correction. User-friendly warnings
to
alert the user that the software has encountered content that requires manual review
and
possible hand tagging can also help. The human editor can review the machine’s parsing
results
(and correct them) before finally translating the document to XML. Sophisticated algorithms
can save time and provide granular tagging, but nothing beats the flexibility of a
human
reviewer.
[Bloom et al. 2011] Bloom, D., Friedman, B., &
Kupferstein, G. (2011). Reality Check: What to Expect from Automated Conversion to
NLM XML.
In: Journal Article Tag Suite Conference (JATS-Con) Proceedings 2011.
Bethesda, MD: National Center for Biotechnology Information. Available from
https://www.ncbi.nlm.nih.gov/books/NBK61837/
[Dunford et al. 2017] Dunford, R., Izzo Hunter, S., &
Rosenblum, B. (2017). RE: Seifert M. How Accurate Are References in Trace Elements
and
Electrolytes? Trace Elements and Electrolytes, 34, 139–140. doi:https://doi.org/10.5414/TEX01495
[Galichet 2017] Galichet, L. (2017). Beware of the Laughing
Horse: Managing a Back-catalogue Conversion. In: Journal Article Tag Suite
Conference (JATS-Con) Proceedings 2017. Bethesda, MD: National Center for
Biotechnology Information. Available from
https://www.ncbi.nlm.nih.gov/books/NBK425542/
Bloom, D., Friedman, B., &
Kupferstein, G. (2011). Reality Check: What to Expect from Automated Conversion to
NLM XML.
In: Journal Article Tag Suite Conference (JATS-Con) Proceedings 2011.
Bethesda, MD: National Center for Biotechnology Information. Available from
https://www.ncbi.nlm.nih.gov/books/NBK61837/
Dunford, R., Izzo Hunter, S., &
Rosenblum, B. (2017). RE: Seifert M. How Accurate Are References in Trace Elements
and
Electrolytes? Trace Elements and Electrolytes, 34, 139–140. doi:https://doi.org/10.5414/TEX01495
Galichet, L. (2017). Beware of the Laughing
Horse: Managing a Back-catalogue Conversion. In: Journal Article Tag Suite
Conference (JATS-Con) Proceedings 2017. Bethesda, MD: National Center for
Biotechnology Information. Available from
https://www.ncbi.nlm.nih.gov/books/NBK425542/
Meyer, C. A. (2008). Reference Accuracy: Best
Practices for Making the Links. The Journal of Electronic Publishing,
11(2). doi:https://doi.org/10.3998/3336451.0011.206