Introduction
There are many requirements for versioning and customization in a heterogeneous network of Universal Business Language (UBL) [UBL2.0] users. It has long been accepted that the use of XML addresses platform differences and application differences between participants, insulating trading partners from differences in their applications and implementations. Using the identical XML models and constraints, users can interchange information with expected results. However, in three perspectives of UBL there are expected to be differences between users in how the specification is used: over time not all users of UBL can be expected to have kept their systems in step with new releases from the UBL committee; around the world not all communities of users of UBL will have the same requirements for information exchange; and amongst all those engaged with a given community, not all trading partners have the identical business-oriented constraints on the data found in UBL documents.
While using XML does address implementation differences in heterogeneous systems, the definition of UBL illustrates some approaches to addressing the heterogeneous deployment of an adopted specification. This paper reviews guidelines being discussed and adopted by the UBL committee in these areas. Also described are some distinctive aspects about the UBL document constraints that support some automated verification techniques.
The principles described by the UBL committee predate the principles described in the W3C Technical Architecture Group (TAG) finding on strategies for extending and versioning languages [TAG1], but they are in harmony.
The role of schema validity to applications
This paper focuses on a number of versioning issues with respect to schema validity. This recognizes schema validity as a gating factor to many applications being able to inspect the content of an XML instance. While well-formedness is sufficient for processing the content of an XML document with tools such as XSLT, nevertheless there are many approaches to working with XML that oblige an instance to be schema valid before an application is delivered the content found therein. Once the content is delivered, the application can make business and other "higher layer" decisions regarding the instance. By describing approaches addressing schema validity in advance of an application inspecting the content, all applications can be enabled to determine what business to engage in based on the content found.
The UBL committee was presented with a real-world situation involving thousands of Java programmers in Denmark who know nothing about XML but are obliged to write applications that access UBL documents standardized by the Danish government [OIOUBL]. In the general case, consider for example any such programming language with an interface to XML that hides markup from developers. This off-the-shelf interface might load an in-memory data structure based on the W3C Schema post-schema validation information (PSVI) values of a validating processor. The programmer doesn't know anything about XML or about the PSVI, but because the interface delivers all of the document content as a data structure, the application can inspect the XML content and make its business decisions.
If the XML document does not validate against the schema for which the interface was programmed, the data structures do not get loaded, and the application cannot inspect the document contents. Schema validity becomes the gating factor to even look inside of the document, and the document's well-formedness is irrelevant to that programmer. A processing model that coerces an instance to be schema-valid for such an application allows that application to accomplish what it can with the information found therein.
The published processing model for like-versioned UBL systems
The UBL committee published a processing model for a UBL system receiving an XML UBL document, illustrated in Figure 1.
Figure 1: The published processing model for UBL
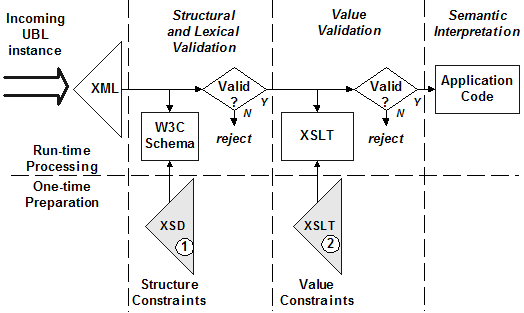
In this model, two distinct steps are engaged to determine the validity of an instance for processing by a receiving application. The structural and lexical constraints are expressed in the W3C Schema XSD file. The value constraints are expressed in an XSLT file. Standardized versions of each of these two files are included in the UBL 2.0 delivery package. Only when an instance has successfully passed structural validation does it make sense to check value validation.
If the application requires schema validity for the loading of data structures, this is assured by the first step. Checking the value constraints in the second step has relieved the application from having to know which constraints apply and can focus on whatever values have been allowed to pass. Thus the application can be quite generic in nature by supporting all possible values. The application does not have to change if the constraints on values change in different business contexts.
Versions of the UBL specification
An innovative concept developed early in the UBL days and now followed by many other committees is the creation of Naming and Design Rules (NDR). These rules govern the (typically automatable) synthesis of formal document models from abstract representations of model information. A set of NDR rules is published for UBL 2.0 [NDR2.0] and governs how the committee can address versions. These rules cannot be violated in determining approaches for versioning.
The NDR makes reference to the abbreviations for Aggregate Business Information Entity (ABIE), Basic Business Information Entity (BBIE) and Associate Business Information Entity (ASBIE), defined by the Core Component Technical Specification [CCTS]. An aggregate element defines a sequence of basic and associated elements, where associated elements are themselves aggregates. The order of the sequence reflects the order as modeled abstractly for the ABIE by the committee, which always orders all constituent BBIE constructs in sequence before all ASBIE constructs.
Three examples of NDR rules that make the UBL vocabulary distinct from other vocabularies are as follows.
-
[CTD2] Every
ccts:ABIExsd:complexTypedefinition content model MUST use thexsd:sequenceelement containing references to the appropriate global element declarations. [Ed. note: i.e. noxsd:choiceconstructs allowed] -
[ELD3] For every class and property identified in the UBL model, a global element bound to the corresponding
xsd:complexTypeMUST be declared. [Ed. note: i.e. the Garden of Eden approach to document modeling] -
[GXS14] The
xsd:anyelement MUST NOT be used except within theExtensionContentTypetype definition, and withxsd:processContents="skip"for non-UBL namespaces.
Considering the last example above, localizing all unknown constructs under a single
point prevents having user-defined customized extensions throughout an instance.
The rule is not in place in order to locate minor version additions to the model.
Adding an <xsd:any> construct within any standardized aggregate for the purpose of versioning would suggest
adding <xsd:any> to every standardized aggregate. After trying to negotiate the importance of which
aggregates would or would not have this construct, it was decided it was simpler that
no aggregate would have this construct.
This section overviews the committee decision to add new documents and augment existing aggregates with minor-version optional additions using the same namespace. Applications can protect themselves from future augmentations by implementing a processing model stripping unexpected elements. The generation of instances must indicate the version of UBL higher than or equal to the highest minor version defining any construct in the instance. Minor version schema expressions are reconstituted from abstract models, not derived from older versions.
Major vs. minor vocabulary versions
As is widely accepted, a major version change for an XML vocabulary is required when instances of the older version no longer validate against a new schema. This implies that applications are obliged to be changed in order to recognize the vocabulary constructs it may already support. From the schema validity perspective, this means an application is unable to inspect the content of an old instance because it cannot validate the instance with the new schema.
To support this, the NDR rules mandate:
-
[VER5] for UBL minor version changes the namespace name must not change.
-
[VER10] UBL Schema and schema module minor version changes MUST not break semantic compatibility with prior versions.
As when defining most XML vocabularies, UBL first defines abstract information items and the granularity, cardinality, order and labeling of their constituent information items. Items are then each assigned a name by which the representation of the item can be identified in an XML document. An application then processes this representation found in an XML instance into information in effecting the desired outcome.
A information item's namespace is merely an extension of its local name. Therefore, XML applications processing UBL documents identify an information item by its namespace-qualified name. The application can then implement whatever semantics are defined for the identified information item. If a UBL minor version introduces a previously existing UBL information item into an augmented aggregate as part of the change, the application will properly identify the item by its established namespace and local name even when found in the newly-permitted location.
If the NDR had allowed or required the namespace to change in a minor version, the established conceptual information item would then have multiple names in different places of a validated instance. If namespace changes were required only for newly defined information items, an application inspecting the namespaces of an instance would not distinguish all information items introduced in the minor version. Therefore, basing minor version distinctions solely on namespaces is insufficient. Thus incurring the overhead of introducing and tracking multiple minor-version-based namespaces would be onerous at worst or misleading at best.
In support of asserting minor version compliance, the UBL NDR mandates an element to be optionally available as part of every UBL instance:
-
[VER15] Every UBL document schema must declare an optional element named "
UBLVersionID" immediately following the optional "UBLExtensions" element.
An instance claiming to satisfy the document constraints for a particular version
of UBL asserts this in the UBLVersionID element. While it is not a mandatory element, applications knowing that an instance
claims to satisfy a particular version can make use of this information.
With this combination of rules and practices, every UBL 2.x document will have the same namespaces used to identify the vocabulary as 2.0. Also, where an instance purports to be an instance of a particular minor version, an application will know where to find this assertion. Note that this element's value is not validated, rather, it is only an assertion that the constructs found in the instance conform to the stated version. An instance with this element absent makes no such assertion, thus an application can only assume the instance is using UBL 2.0. The element cannot be mandatory in a minor version as this would render 2.0 instances invalid where the element is absent.
The UBL common library and new document types
The UBL vocabulary is designed around a common library of business objects expressed as constraints in document structure. Each of the 31 UBL document types import this common specification of business object serialization, thereby reusing the common definitions in all documents.
A UBL naming and design rule mandates that each document type defines only the document element for the document type. The document element children are all references into the common library for both basic and aggregate business objects.
New document types can be added to UBL simply by creating the definitions of new document elements and the children they use. Should there be a need for a new business object, this can simply be added to the library without impacting any of the existing document types. Should there be a need to modify an existing business object, only additions that have optional cardinality can be made in order not to impact the schema validity of an instance of an existing document type.
A minor-versioning approach for backward compatibility
New business requirements for an existing document type may mandate a change to a business object already being used. As when modifying objects to accommodate new documents, such changes can be made in a minor UBL revision provided they are all made with an optional cardinality. Nothing that is mandatory can be added in a minor version specification, as instances of previous minor versions would no longer be schema valid.
In this approach, for example, a system set up to validate version 2.7 instances will also validate a version 2.5 instance. Whether a user wishes to accept the business validity of a version 2.5 instance is an out-of-band business decision. Nevertheless, there is nothing in the system preventing it from being able to inspect the instance.
A processing model for forward compatibility
A receiving application is assumed to have been programmed to be aware of only those constructs of a particular version of UBL. It would therefore be deployed with the schemas for that UBL version and will typically employ validation of received documents in advance of acting on the semantics represented by the information structured and identified in the XML. The application receiving an instance of a later UBL version may find either unrecognized constructs or recognized constructs in unexpected places. For example, a UBL 2.5 application would not recognize constructs introduced by the schema for UBL 2.7.
Shown previously in section “The published processing model for like-versioned UBL systems”, the current UBL 2.0 specification describes a two-step validation processing model. The first of these two steps confirms the structural and lexical constraints (the lexical being, effectively, the structure of the content) of the document. The second step confirms the value constraints being imposed by business requirements beyond the purview of the committee, but within the context of using UBL between trading partners. This second step is described in more detail in section “Trading partner agreements on value constraints”. At either stage of validation, a failure indicates that the message is to be rejected, either because the document structure or value constraints have been violated.
This processing model for like-versioned UBL systems does not serve a UBL 2.5 application receiving a UBL 2.7 instance with unexpected content.
Figure 2 illustrates a processing model being considered by the UBL committee that supports forward compatibility of UBL instances. This augments the processing model described in the UBL 2.0 specification and is being considered for inclusion in the UBL 2.1 specification.
Figure 2: A customized processing model supporting forward compatibility
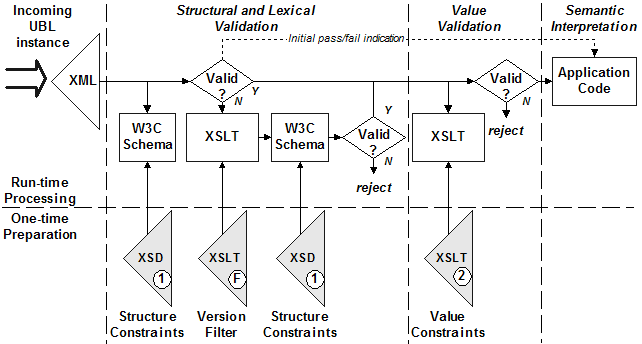
This alternative processing model for the receiving system uses only that version of UBL schema supported by the receiving system, and does not involve any inspection of the XML instance in advance of validation. In this model an initial schema validation failure indication is recognized to possibly have been triggered by an instance using features added in a schema later than the version supported by the system. After such a failure, an instance pruning process takes away unknown constructs from the instance being validated. The resulting pruned instance can then be checked for schema validity. If successful, the pruned instance is passed to the second stage value validation.
As with the standardized model, passing value validation grants delivery of the instance to the application. In this model, a second piece of information accompanies the instance being passed to the application. The application can already assume that value constraints in the document are satisfied. An "initial pass/fail" indication tells the application that the instance it is working with satisfies the structure constraints in either an unmodified ("initial pass") or a modified ("initial fail") state.
An unmodified instance can be acceptable for business processing regardless of the
stated version number found in the UBLVersionID element if all of the business objects found in the instance conform to the constraints
of the application, unused additions in a later version notwithstanding. The application
can use out-of-band decision making, including the UBLVersionID element as input, to accept or reject a modified instance for the purposes of doing
business.
In both cases if the instance is delivered to an application, such an application relying on schema validity for inspecting instance content (as described in section “The role of schema validity to applications”) can successfully extract any information therein.
Considering the example above, a UBL 2.7 instance without constructs unrecognized by the UBL 2.5 schema would validate using the receiving application's schemas. The instance would be passed to the UBL 2.5-aware application untouched and with an "initial pass" indication. In this case that the instance is marked 2.7 is irrelevant. A UBL 2.7 instance with unrecognized constructs would fail to validate with the UBL 2.5 schema and would be passed to the application after being pruned to the UBL 2.5 subset and with an "initial fail" indication. In this case that the instance is marked 2.7 is relevant to the application and user deciding how to proceed.
In support of this processing model, instance pruning processes for UBL 2.0 are already publicly available [Crane Resources]. Such processes are programmatically derived from the UBL specification rather than being hand-coded. This approach gives the pruning process a higher level of assurance of accuracy than coding the filter by hand.
The version high water mark
There was some debate within the committee regarding which value a sending application is obligated to indicate in a UBL document regarding the version of UBL to which the instance conforms.
Consider the example where a sending system supporting features up to UBL 2.7 generates an instance wherein the highest version of UBL represented by any construct used therein was defined in UBL 2.3. No additions defined by UBL 2.4, 2.5, 2.6 or 2.7 are being used within the instance. Though the system supports creating a UBL 2.7 instance, the "high water mark" of the structure is only 2.3.
Should the sending application indicate in UBLVersionID the value "2.3" or the value "2.7"?
A receiving system supporting only UBL 2.2 would accept the instance after the second check of schema validity in Figure 2. The first check of validity would have triggered the instance pruning through the 2.2 filter and the resulting instance would then validate as 2.2. The application would inspect the instance with the knowledge that the instance failed the initial validation. If it found a version of 2.2 or lower, the application could conclude that the instance was improperly structured and only the pruning process cleaned the instance up. In this example, seeing a version higher than 2.2, the application wouldn't know whether the instance was improperly structured or whether the failure was only the presence of additional content. Nevertheless, the application can use an out-of-band decision to continue with the transaction or reject it. This might include human inspection or authorization.
A receiving system supporting UBL 2.3 would accept the instance structure and the
application would be able to inspect the content. There would be no need to inspect
the asserted UBL version because the "initial pass/fail indication" cites the successful
validation against UBL 2.3 structures. This happens regardless of whether the UBLVersionID states "2.3" or "2.7".
Likewise, a receiving system supporting UBL 2.7 would accept the instance without
needing to inspect the UBLVersionID.
Thus it turns out that there is no obligation for a sending system to ascertain the
high water mark of constructs used in an instance. Indeed, it may be a burden to
quality assurance and testing in application development to test that an application
meets the high water mark requirement. By always populating UBLVersionID with the highest version of UBL supported by the sending application, this statement
will always be true. An instance of UBL 2.3 is, in fact, an instance of UBL 2.7,
so it is safe to say "2.7" in the instance.
Schema synthesis
Note that XSD extension techniques are not suitable for defining later UBL versions based on earlier UBL versions. Accordingly, the document models of each minor version of UBL will be independently expressed from revised abstract models of the information. UBL committee members collaborate on the definitions of minor versions only from UML data diagrams and spreadsheet definitions of information model components. Since the XSD files are synthesized based on the UBL NDR, the original XSD files are not utilized in the expression of subsequent minor versions.
XSD requires redefined elements to be redefinitions in terms of themselves. This requires an extended definition to include the original definition with extensions only after the last of the original items being used.
The UBL NDR requires all atomic information items to be ordered in sequence before all aggregate information items in an element's definition. When new atomic information items are introduced into the model, they need to be positioned in the XML somewhere within or adjacent to the original atomic information items and before the original aggregate information items. Thus a minor version cannot be defined as an extension after the end of its previous version.
Note that minor versions only introduce optional constructs, thus an instance of any version is always a valid instance of any subsequent minor-version.
Customizations of UBL
A UBL Customization is, in the generic sense, the description of XML instances or XML-based applications acting on those instances that are somehow based on or derived from the UBL 2.0 specification. This represents another kind of version of UBL than the versions described by the committee. A community of users adopting UBL can describe a customization as their version of UBL better suited to their business needs than what off-the-shelf UBL can offer.
Two kinds of changes can be distinguished in a UBL customization: the removal of optional standardized constructs that are considered unnecessary, and the addition of new non-standardized constructs not already found in the specification. How a customization is specified impacts on the applications processing UBL information found in XML documents.
Two very distinct interpretations have come to light of how to describe and deploy a customization of UBL. A number of UBL members focus on the business objects described by the UBL information model based on the CCTS information model [CCTS]. Other members focus on the actual elements and attributes in the XML instance and the UBL XSD schemas.
Following current discussions in the UBL TC, the term UBL Compatibility is reserved for a customization focused on the information model, while the term UBL Conformance is reserved for a customization focused on the markup constraints and labels of the document schema.
UBL Compatibility
The Core Component Technical Specification [CCTS] presents a model for standardizing business semantics. It includes a methodology for developing a common set of semantic building blocks that represent business data. Using these building blocks, one can create one's own XML vocabulary. This vocabulary has user-named constructs based on CCTS constructs with the standardized business semantics.
The UBL business objects are built on top of the CCTS building blocks. Therefore, the UBL vocabulary is compatible at an information model level with other XML vocabularies and data representations also based on CCTS. The actual XML vocabularies may be very different, with different namespaces and labels for elements and attributes. However, the semantic basis on which these vocabularies are built promotes compatibility of the information expressed using those semantics.
These UBL business objects can be, in turn, the basis upon which other information models and associated XML vocabularies are built. This promotes compatibility of the information expressed in those vocabularies with the information expressed in UBL instances. Such compatibility is at the application and information model level. However, this does not enforce or predict any document-level instance compatibility in the use of labeled XML information items as defined by UBL.
An instance or a system is said to be UBL-compatible when its information item definitions (not labels) are based on the same UBL and CCTS business objects, thus promoting interoperability at an application and model level between two UBL-compatible systems that understand the underlying business objects.
In a UBL-compatible document, schema validity is irrelevant because the business objects need not express the same granularity or structure or labels as those used in the published UBL schemas. Compatibility is thus viewed from an ontological or semantic perspective, not syntactic.
The granularity, order, cardinality and makeup of constituent information items in a compatible XML document need not have any relationship to UBL documents that validate against the published standardized schemas. Moreover, compatible information items must be distinctly named (labeled in the document tree) from standardized information items so as not to misconstrue what the label of an information item represents. Therefore, an XML application written to support a specific customization must know a priori the namespaces and names of the customized information items, and can only rely on the UBL namespaces and names to represent standardized information items.
UBL Conformance
An instance is said to be UBL-conformant when it uses the granularity, order, cardinality, makeup, names and namespace URI strings of the representation of information items without conflicting with that published in the normative UBL schemas. This promotes interoperability at a document interchange level between two UBL-conformant systems that interpret the so-labeled and structured business objects.
Two aspects of the UBL document models may be unacceptable to a community of users. There may be more business objects defined by UBL than are of interest to the community. Moreover, a community may very well need to express important (to them) business objects not conceived in UBL. The UBL schemas are defined to accommodate these differences.
A UBL conformant customization describes a set of document constraints where all possible instances of the conformant customization are simultaneously schema-valid instances of the published standardized UBL schemas. This allows a community to deprecate (to the point of exclusion) any UBL construct with optional cardinality. Any UBL construct with mandatory cardinality cannot be removed from the conformant customization, as customized instances would not meet the constraints of the original UBL document schemas.
Conformance is thus viewed from a syntactic perspective, presuming equivalence from an ontological or semantic perspective.
An excerpt from an example delivered as part of the UBL 2.0 package shows three fields being used in an Invoice instance, referencing a conformant customization used for a profile of a proposed small business subset:
<in:Invoice ...>
<cbc:UBLVersionID>2.0</cbc:UBLVersionID>
<cbc:CustomizationID>urn:oasis:names:specification:ubl:xpath:Invoice-2.0:
sbs-1.0-draft</cbc:CustomizationID>
<cbc:ProfileID>bpid:urn:oasis:names:draft:bpss:ubl-2-sbs-invoice-
notification-draft</cbc:ProfileID>
As noted in section “Major vs. minor vocabulary versions” an instance may claim to conform to the UBL schemas for the particular minor version
indicated in the UBLVersionID. As well, an instance claiming to satisfy the document constraints for a customization
may assert this in the CustomizationID element. When a community defines variations of a given document model within a
customization, the instance may assert it is a particular variation in the ProfileID element.
An instance may choose not to assert in these elements that it conforms to any particular constraints. A receiving application can then assume it is a UBL 2.0 document but must make its own assessment of the document information or the anticipated use of the document.
Conformant subsets (deprecating existing information)
A major aspect of the success of UBL is the specification of many different business objects that communities of users can utilize when representing their business information. This flexibility found in aggregate information items comes at a cost of defining a granularity of numerous possible constituent items, few of which are mandatory and most of which can be selectively used in an instance.
The community is obliged to use constituent items that are declared as mandatory in a UBL instance, otherwise their instances would not validate against the published standardized schemas. The community can, however, choose to constrain which optional constituent items it will agree to represent the information they use, and which optional constituent items it will agree will never represent any information they find useful or relevant in an interchange.
By paring down the standardized document specification to a conformant subset, the expectations of individuals in the community can be managed. Only those optional constructs allowed within the community need be considered when a sending application represents information. Any optional construct not allowed within the community can be safely ignored by a receiving application should it be present in the instance.
All instances of the conformant subset are schema-valid with the UBL schema version from which the subset is derived.
Conformant extensions (adding new information)
To meet the requirements not perceived by the committee, a community can define their own business objects required for a transaction. These objects are represented as customized information items. These items will have their own granularity, order, cardinality and makeup of constituent information items. Some constituent items may, very well, be appropriately represented by a standardized information item. Moreover, the use of standardized items where possible allows applications to exploit existing support in new contexts.
New basic information items and aggregates defined differently than standardized aggregates must be distinctly named from standardized constructs so as not to ambiguously represent UBL constructs in an XML instance. The names of these non-UBL constructs must use a non-UBL namespace in order to avoid any future name collisions with as-yet-to-be-standardized UBL constructs using the UBL namespaces.
The root of the community's extension definition is an element in a non-UBL namespace
as it both represents and its content is used as a customized semantic not defined
by the UBL committee. The UBL schemas allow the community to position its customized
objects under a reserved element named UBLExtensions found at the beginning of all UBL documents. This element is not described in the
abstract business model of UBL as it is an artefact of document expression, not document
definition.
Meta data available for each UBLExtension child of the UBLExtensions element identifies the nature and source of the extension. The UBLExtension element allows the root of the community extension as its only child element by using
<xsd:any> in its declaration.
Note that extension constructs are not allowed anywhere else in a UBL document outside
of the UBLExtension element, otherwise the UBL schemas will report errors of unexpected content. When
weighing extensibility, the committee considered adding a wild card validation pattern
after all elements, after some elements or in only one location. Adding it after
every element was considered extreme. Agreeing on any selection wasn't possible as
some members felt their choices of selection were warranted while others did not.
Having only one location for extensions manages the expectations of developers and
users for locating additional non-standard constructs.
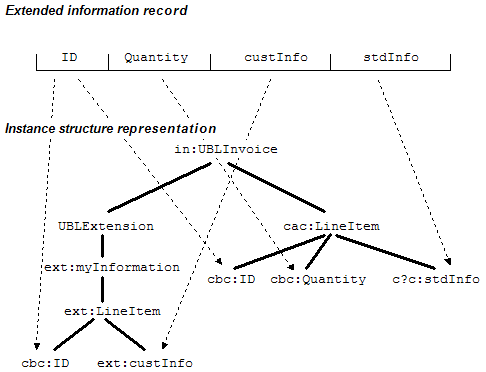
Putting all extensions under one location has its own burden of associating the extension content with the standardized content. Many constructs in UBL, for example line items and parties, are already modeled to have identifiers. Reusing these identifiers in extension content provides a natural association between content found under the extension point and content found in the standardized constructs. Figure 3 illustrates this.
Figure 3: Extension approach without duplication
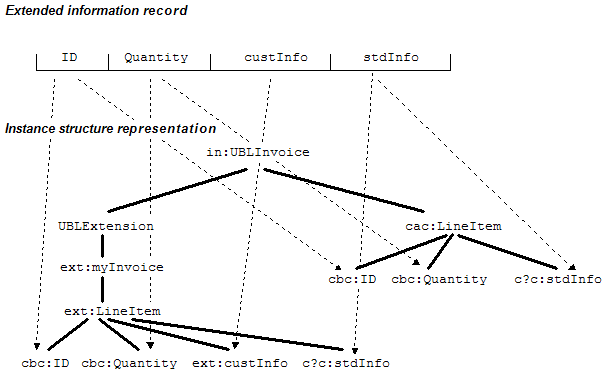
Alternatively, there are committee members contemplating the role of the extension point to be the location of a recipient's customized view of a complete extended UBL instance. In such a document all standardized UBL information items are included under the extension point and their extensions are found in their context. Those items with modified content must necessarily be named differently from the standardized names, but the standardized content can be found therein. The standardized UBL instance with standardized UBL names still exists in the XML in its expected structures.
Those recipients unprepared to process the extension ignore the extension and use
the standardized structure. Meanwhile, those recipients prepared to process the extensions
do so and ignore the standardized structure. This allows the standardized basic objects
to stay in the UBL namespace, but every extended aggregate needs to be named in an
extension namespace. Creating an aggregate with a new name has the "ripple effect"
of requiring containing aggregates to have new names in the extension namespace, stepping
all the way up the document structure to the containing element below UBLExtension. Figure 4 illustrates this.
Figure 4: Extension approach with duplication
No feedback is yet available from users considering either of these two approaches
using UBLExtension.
Conformant instance processing
To support document-order processing of a UBL instance with extensions, the UBLExtensions element is prescribed to be the very first child element of the document element
in every model. Choosing this location was an important decision in support of streaming
interfaces to UBL instances, while being innocuous in support of tree-based interfaces.
A streaming application will encounter all extensions in advance of any standardized
construct. In this way the application is equipped to encounter all standardized
constructs with the information available in extensions already known. No caching
of standardized constructs is necessary to await possible extension information that
would be following if extensions were modeled after every element.
One processing model supporting a customization of UBL is the same processing model depicted in Figure 2. An instance pruning filter recognizing all of the constructs of the customization can reduce any instance not validating successfully against the customization schema. When the resulting pruned instance fails validation, the instance is unacceptable for processing. When the resulting pruned instance succeeds in validation, the application has the same two inputs as in forward compatibility processing: a valid XML instance and an indication of whether or not the instance had to be pruned to be valid.
Another processing model is employed by the Danish conformant customization called OIOUBL [OIOUBL]. This uses a Schematron assertion schema to determine whether an instance satisfies the constraints defined by the customization. This assertion schema confirms both cardinality aspects and value aspects.
Profiles
Another perspective of different versions of UBL can be seen within user communities. A community may decide that different document structure constraints for the same document are necessary for different transaction exchanges involving that document.
The Danish UBL project and at least two other UBL projects in Europe refine community
customization even further with different customizations for different scenarios.
A concept called a profile characterizes a choreography of interchange. Having numerous profiles may requiring
having numerous conformant customizations defined for each UBL schema. A given document
type may have two different sets of constraints in two different profiles of the same
community customization. For example, an invoice instance used in the choreography
of a "Basic procurement" profile may not have as many constructs available to use
as an invoice instance used in the different choreography of an "Advanced procurement"
profile. An instance claiming to satisfy the document constraints for a particular
profile in a customization asserts this in the ProfileID element.
Thus the three dimensions of the version of a set of UBL document structural constraints are defined by the committee version (standard), the community version (customization) and the choreography version (profile).
Conformant schema representation
Figure 5 shows the schema representation fragments and their dependencies. These fragments are produced by the UBL committee with the expectation that a community with a customization would produce their own subset versions of each of the fragments, and would replace the Extension Content Datatype fragment with their extensions.
Figure 5: UBL Schema dependencies
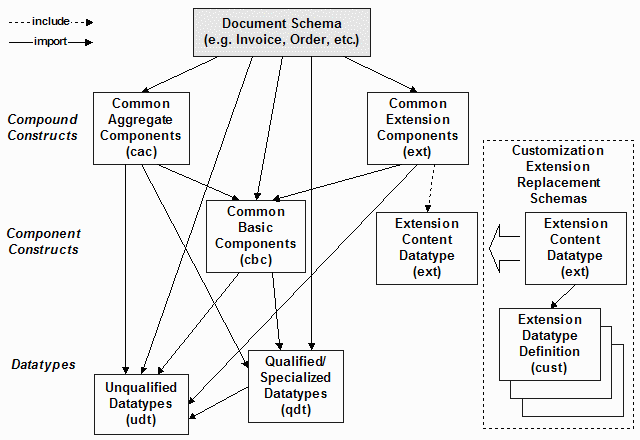
A community defining only extensions, or a UBL user wanting to add information under the extension point for the standard schemas, can leave every OASIS fragment unchanged and read-only. This requires replacing only the one extension module that includes the complete customization definition in the customization namespace.
One approach producing the subset schemas available on Crane's web site is to work with the OASIS artefacts as input and use the XML comment construct to elide all of the information items not used by the community customization. A human reader of the end result can see all of the OASIS standardized constructs, easily distinguishing those that are in the customization and those that are not. The model modifications are expressed using spreadsheets available from the OASIS web site. This straightforward approach was developed from pragmatism and wanting to avoid writing a schema synthesis application from scratch.
The other approach producing the subset schemas is to work at an abstract model level and to synthesize the schema fragments from scratch from the subset model. Interestingly, when this was done for one customization, anecdotal reports of "distrust" in the schemas surfaced. This surprised the community developers and became a real barrier of acceptance for the users. How would users be assured that the schemas synthesized from scratch would not violate the constraints standardized by OASIS?
Regardless of the approach taken, this reassurance turns out to be very important to candidate users. How can one categorically prove all instances of a posited customization are simultaneously valid against the standardized document constraints? Doing so would validate the modified UBL model's conformance against the original UBL document model.
Using XPath files for validating model conformance
When researching techniques for validating a modified UBL model's conformance against the original UBL document model, it was observed that the NDR rules ensure such is satisfied by confirming each modified ABIE conforms with each standardized ABIE. However, some early users of modified UBL models broke NDR constraints by defining contextual differences for ABIE definitions, while still positing their instances validated against the standard UBL models. A mechanical means by which model conformance can be tested was needed. To accommodate both those who respect the NDR and those who do not, a methodology was developed to exploit some UBL resources that were created years before for an entirely different purpose of presentation rather than validation.
The XPath recommendation [XPath 1.0] defines a data model for the information found in XML instances. This model is agnostic to any constraints that may have been imposed on the creation or use of the instance. XPath 1.0 is based only on XML syntax and XML Namespaces. The data model describes well-formed instances (which may or may not be valid). The model focuses on the information found in the instance and not in any way the syntax used in the instance to express the information.
The UBL Human Interface Subcommittee [HISC] project created an XML vocabulary for enumerating information items in a catalogue of available XPath addresses from the document element to all items allowed by a given document model described by a schema or to all items found a particular XML instance. The normative instance of an XPath file for a given document model is an XML instance of the XPath file vocabulary [XPath File]. This instance can be machine-processed by any XML-aware application and can also be used to create human legible reports and diagnostic materials.
XPath files for UBL 2 schemas are publicly available [UBL-XPath]. There happens to be sufficient information in a UBL schema expression to derive the complete suite of information items. The combination of UBL NDRs happen to make it straightforward to create XPath files from the published XSD expressions. For example, the use of the "Garden of Eden" (all elements and types defined globally) approach to declarations, and only sequence groups (no choice groups), makes XPath files unambiguous for UBL, whereas XPath files might be quite insufficient for other document models and modeling conventions. This tool, therefore, is not a general purpose tool to use for all XML vocabularies.
More research is required to come up with more information in the XPath normative files to accommodate different schema expression conventions and NDRs. Initial discussions with vendors indicates that XPath files are not sufficiently rich to express XML document structures for arbitrary constraints, only those constraints limited by the UBL NDRs.
Note that XPath files need not be generated from XSD schemas or XML instances. The UBL spreadsheets used to determine the contents of the XSD schemas (or any spreadsheets describing content nesting and definition) can be used as a source for creating XPath files. However created, the XPath files express in a programmatically processable form all of the possible combinations of XML non-recursive hierarchy for the information items described by a document model, schema or instance.
XPath file vocabulary
The document element of an XPath file is <XPath>. Document-wide namespace prefix/URI associations are expressed in <Namespace> elements. XML element information structure is expressed in an XPath file as <Element> element children of parent <Element> elements. Similarly, attributes of elements are expressed as <Attribute> element children. Each construct indicates its allowed cardinality. This is sufficient
to express models described using UBL NDR.
An XPath file can be processed by an application to internalize all of the structures
expressed. The application can then compare structures or do other processing with
the information. The following is an excerpt from the beginning of the XPath file
generated for the AttachedDocument document type:
<XPath xmlns="urn:oasis:names:tc:ubl:schema:XPath-1.0"
xml:id="urn:oasis:names:tc:ubl:XPath:AttachedDocument-2.0">
<Namespace prefix="ad" uri="urn:...:AttachedDocument-2"/>
<Namespace prefix="cac" uri="urn:..:CommonAggregateComponents-2"/>
<Namespace prefix="cbc" uri="urn:..:CommonBasicComponents-2"/>
...
<Element name="AttachedDocument" type="AttachedDocumentType"
prefix="ad" minOccurs="1" maxOccurs="1">
<Element name="UBLExtensions" type="UBLExtensionsType"
prefix="ext" minOccurs="0" maxOccurs="1">
<Element name="UBLExtension" type="UBLExtensionType"
prefix="ext" minOccurs="1" maxOccurs="unbounded">
<Element name="ID" type="IDType"
extends="udt:IdentifierType" prefix="cbc"
minOccurs="0" maxOccurs="1" text="">
<Attribute name="schemeAgencyID" use="optional"
type="xsd:normalizedString"/>
<Attribute name="schemeAgencyName" use="optional"
type="xsd:string"/>
...
</Element>
<Element name="Name" type="NameType"
extends="udt:NameType" prefix="cbc"
minOccurs="0" maxOccurs="1" text="">
<Attribute name="languageID" use="optional"
type="xsd:language"/>
</Element>
<Element name="ExtensionAgencyID"
type="ExtensionAgencyIDType"
extends="udt:IdentifierType" prefix="ext"
minOccurs="0" maxOccurs="1" text="">
<Attribute name="schemeAgencyID" use="optional"
type="xsd:normalizedString"/>
...
</Element>
...
</Element>
</Element>
<Element name="UBLVersionID" type="UBLVersionIDType"
extends="udt:IdentifierType" prefix="cbc"
minOccurs="0" maxOccurs="1" text="">
<Attribute name="schemeAgencyID" use="optional"
type="xsd:normalizedString"/>
<Attribute name="schemeAgencyName" use="optional"
type="xsd:string"/>
...
</Element>
...
<Element name="CustomizationID" type="CustomizationIDType"
extends="udt:IdentifierType" prefix="cbc"
minOccurs="0" maxOccurs="1" text="">
...
</Element>
<Element name="ProfileID" type="ProfileIDType"
extends="udt:IdentifierType" prefix="cbc"
minOccurs="0" maxOccurs="1" text="">
<Attribute name="schemeAgencyID" use="optional"
type="xsd:normalizedString"/>
...
</Element>
...
</Element>
</XPath>
This is an exhaustive serialization of all document contexts. Each element and attribute indicated is a possible element and attribute in the hierarchy found in instances conforming to the model's structural constraints.
XPath reports
Two XPath reports are made available: a simple text report of absolute XPath addresses (that is, an XPath address that begins from the root node and document element) and a mockup XML instance, both of which have one of every information item described by an XPath file.
XPath text reports
An XPath text report is targeted to a human reader and can be a handy tool to overview
the information found in an XPath file. Each XPath address is preceded by a reference
ordinal (one ordinal for elements and a pair of ordinals for attributes), and the
cardinality of the information item. An excerpt of the XPath text report of the above
AttachedDocument XPath file is as follows (lines are wrapped to fit on this page, there is no line
wrapping in the actual file):
1 1..1 /ad:AttachedDocument/
2 0..1 /ad:AttachedDocument/ext:UBLExtensions/
3 1..n /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
4 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
cbc:ID
4.1 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
cbc:ID/@schemeAgencyID
4.2 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
cbc:ID/@schemeAgencyName
4.3 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
cbc:ID/@schemeDataURI
4.4 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
cbc:ID/@schemeID
4.5 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
cbc:ID/@schemeName
4.6 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
cbc:ID/@schemeURI
4.7 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
cbc:ID/@schemeVersionID
5 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
cbc:Name
5.1 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
cbc:Name/@languageID
6 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
ext:ExtensionAgencyID
6.1 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
ext:ExtensionAgencyID/@schemeAgencyID
6.2 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
ext:ExtensionAgencyID/@schemeAgencyName
6.3 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
ext:ExtensionAgencyID/@schemeDataURI
6.4 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
ext:ExtensionAgencyID/@schemeID
6.5 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
ext:ExtensionAgencyID/@schemeName
6.6 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
ext:ExtensionAgencyID/@schemeURI
6.7 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
ext:ExtensionAgencyID/@schemeVersionID
7 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
ext:ExtensionAgencyName
7.1 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
ext:ExtensionAgencyName/@languageID
8 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
ext:ExtensionVersionID
8.1 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
ext:ExtensionVersionID/@schemeAgencyID
8.2 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
ext:ExtensionVersionID/@schemeAgencyName
8.3 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
ext:ExtensionVersionID/@schemeDataURI
8.4 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
ext:ExtensionVersionID/@schemeID
8.5 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
ext:ExtensionVersionID/@schemeName
8.6 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
ext:ExtensionVersionID/@schemeURI
8.7 0..1 /ad:AttachedDocument/ext:UBLExtensions/ext:UBLExtension/
ext:ExtensionVersionID/@schemeVersionID
...
XPath instance report
The mockup XML instance created from an XPath file is called an XPath instance report.
This can be used to compare structures of XML documents (but not their values) containing
the information items described by an XPath file. An excerpt of the XPath instance
report of the above AttachedDocument XPath file is as follows; note how the corresponding reference ordinals are captured
in the information items between exclamation marks, and because of this the instance
cannot be validated by the UBL schemata (nevertheless the reference ordinals are valuable
diagnostic tools in non-schema-aware systems such as XSLT 1.0 stylesheets):
<ad:AttachedDocument
xmlns:ad="urn:...:AttachedDocument-2"
xmlns:cac="urn:...:CommonAggregateComponents-2"
xmlns:cbc="urn:...:CommonBasicComponents-2"
...
<ext:UBLExtensions>
<ext:UBLExtension>
<cbc:ID schemeAgencyID="!4.1!" schemeAgencyName="!4.2!"
schemeDataURI="!4.3!" schemeID="!4.4!" schemeName="!4.5!"
schemeURI="!4.6!" schemeVersionID="!4.7!">!4!</cbc:ID>
<cbc:Name languageID="!5.1!">!5!</cbc:Name>
<ext:ExtensionAgencyID schemeAgencyID="!6.1!"
schemeAgencyName="!6.2!" schemeDataURI="!6.3!" schemeID="!6.4!"
schemeName="!6.5!" schemeURI="!6.6!" schemeVersionID="!6.7!"
>!6!</ext:ExtensionAgencyID>
<ext:ExtensionAgencyName languageID="!7.1!"
>!7!</ext:ExtensionAgencyName>
<ext:ExtensionVersionID schemeAgencyID="!8.1!"
schemeAgencyName="!8.2!" schemeDataURI="!8.3!" schemeID="!8.4!"
schemeName="!8.5!" schemeURI="!8.6!" schemeVersionID="!8.7!"
>!8!</ext:ExtensionVersionID>
<ext:ExtensionAgencyURI schemeAgencyID="!9.1!"
schemeAgencyName="!9.2!" schemeDataURI="!9.3!" schemeID="!9.4!"
schemeName="!9.5!" schemeURI="!9.6!" schemeVersionID="!9.7!"
>!9!</ext:ExtensionAgencyURI>
<ext:ExtensionURI schemeAgencyID="!10.1!"
schemeAgencyName="!10.2!" schemeDataURI="!10.3!" schemeID="!10.4!"
schemeName="!10.5!" schemeURI="!10.6!" schemeVersionID="!10.7!"
>!10!</ext:ExtensionURI>
<ext:ExtensionReasonCode languageID="!11.1!" l
istAgencyID="!11.2!" listAgencyName="!11.3!" listID="!11.4!"
listName="!11.5!" listSchemeURI="!11.6!" listURI="!11.7!"
listVersionID="!11.8!" name="!11.9!">!11!</ext:ExtensionReasonCode>
<ext:ExtensionReason languageID="!12.1!"
>!12!</ext:ExtensionReason>
<ext:ExtensionContent>
</ext:ExtensionContent>
</ext:UBLExtension>
</ext:UBLExtensions>
<cbc:UBLVersionID schemeAgencyID="!14.1!"
schemeAgencyName="!14.2!" schemeDataURI="!14.3!"
schemeID="!14.4!" schemeName="!14.5!" schemeURI="!14.6!"
schemeVersionID="!14.7!">!14!</cbc:UBLVersionID>
...
Confirming UBL conformance of a customization
Using XPath files, both the customization definition and the customization pruning filter can be validated against their requirements. Figure 6 illustrates the process flow where XPath files play a role.
Figure 6: Customization schema and filter validation
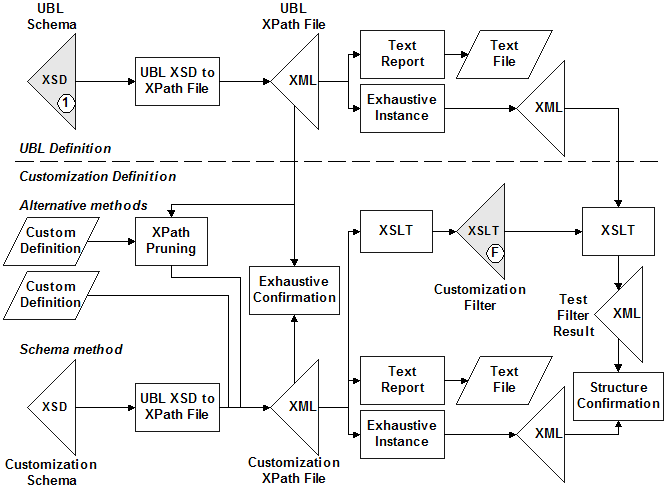
At the top left the UBL Schema is translated into an XPath file. This has already been made publicly available on the OASIS web site [UBL-XPath]. Included with the files are the text reports and the instance reports for each document type. An instance report is an exhaustive instance in that each and every element and attribute is instantiated (limited only by recursive references). When such an instance is passed through a customization filter, it should produce in the filtered result a structure with one of every element and attribute of the customization document model.
At the bottom left are three ways of expressing the document constraints of a customization document model. The top of the three shows a declarative approach that prunes the UBL XPath file into a subset XPath file. This necessarily produces an XPath file where each and every element and attribute item listed and its cardinality satisfies the cardinality of the UBL XPath file for the same document type.
The middle of the three shows some other customization definition that is arbitrarily created by a community by whatever means. When the community produces an XPath file expressing all of the possible element and attribute items for their model, this can be input to a process called Exhaustive Confirmation.
Likewise, when the community uses a schema to express the document constraints, and that schema follows the UBL NDR, then the same UBL XSD to XPath File process can produce the XPath file for the customization. This XPath file can be input to the Exhaustive Confirmation process.
Exhaustive confirmation is a comparison of each and every entry in customization XPath file with the entries in the UBL XPath file. When the cardinality of each customization item doesn't violate the cardinality of the corresponding UBL item, then it is proven that all instances of the customization definition or schema are instances of UBL. This means that any system supporting UBL schemas will validate all instances of the customization document model without fail.
Note that the UBL NDR requiring global declarations of the types of all elements implies the mechanics of exhaustive confirmation can be reduced to a only a confirmation of all parent/child relationships. The complete XPath files are merely repetitions and recursive applications of unchanging parent/child relationships. If, however, it were true for another project's NDR that types were not global and contextual differences were introduced by a customization, then exhaustive confirmation would need to use the complete XPath file and would successfully produce a correct result.
There is enough information in the customization XPath file that the customization filter can be synthesized without human intervention. XPath files are thus used to methodically confirm both the definition of a customization and the filter stylesheet labeled "F" in the flow described in Figure 2. Again, the UBL NDR requiring global declarations of the types of all elements implies the mechanics of this filter can be reduced. In the case for UBL only a filter of allowed parent/child relationships is sufficient, whereas a more general filter would need to calculate more elaborate contextualization of allowed constructs.
The customization XPath file can be used to produce the text report which is useful for developers and users of the customization.
The customization XPath file can also produce an exhaustive instance. The structure of this exhaustive instance can then be compared against the structure of the filtered UBL exhaustive instance. This confirms the correct behavior of the customization filter.
Trading partner agreements on value constraints
Any given business entity may have many different relationships or changing relationships with different trading partners. This represents yet another perspective of different versions of UBL, one where the business is using different value constraints in UBL documents in different business scenarios.
By using UBL trading partners are agreeing to use the same document structures in which to place the information being exchanged. But the constraints on the values used within the information itself could not possibly be mandated by the UBL committee or by the community of users defining a customization. Therefore, the business entity needs different versions of value constraints for use in different and very subjective business situations.
Consider the controlled vocabulary of datum values used for codes and identifiers
in an XML document. For example, ISO has standardized mnemonic abbreviations as codes
in a number of code lists. For example, USD, CAD and GBP represent, respectively, the currency values for the US dollar, the Canadian dollar
and the British pound. Another list with mnemonic abbreviations is the list of country
codes. For example, FR, DE and ES represent, respectively, the country codes for France, Germany and Spain. The UN/ECE
has standardized non-mnemonic values for payment means such as 10, 42 and 51 for, respectively, "cash", "payment to bank account" and "norme 6 97-Telereglement CFONB (French Organisation for Banking Standards) - Option
A" (illustrating the compactness benefit of using abbreviated codes rather than long
titles).
Historically, the constraints on item values have been codified in schemas along side constraints on document structures and lexical value structures. In contrast, the UBL specification mandates only where information is found in an XML document (the document structures and the lexical structures), without constraining the values themselves. As illustrated in both Figure 1 and Figure 2, a pass on the instance validates the values used therein separately from the passes needed to confirm structural and lexical constraints. This allows a standard UBL schema, or a customized schema created by a community of users, to be used by individuals in the community without any changes when different code and identifier values are needed for subjective business reasons.
Each business may have a number of versions of differing value constraints. The versions may be distinguished by the practices or policies in place for different trading partners. The versions may be distinguished by changes within the business itself over time. Throughout all these differences, the structures mandated by the UBL committee or the community customization are not affected, only the values found within those structures.
Moreover, it may be necessary to use different versions of value constraints for the same information item found in different contexts of a single XML document. As the UBL schemas are defined using global names and global types according to the NDR, it would not be possible in the schema to express different value constraints on two different items of the same name.
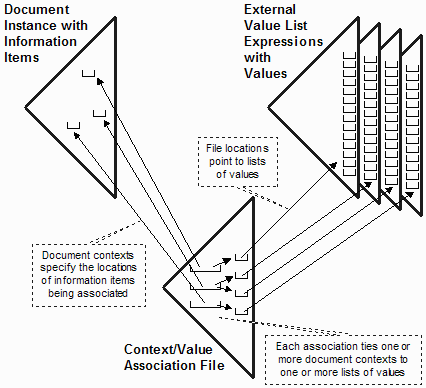
Figure 7 illustrates the expression of codes in context using an external file called a Context/Value Association (CVA) file.
Figure 7: Associating values with document contexts
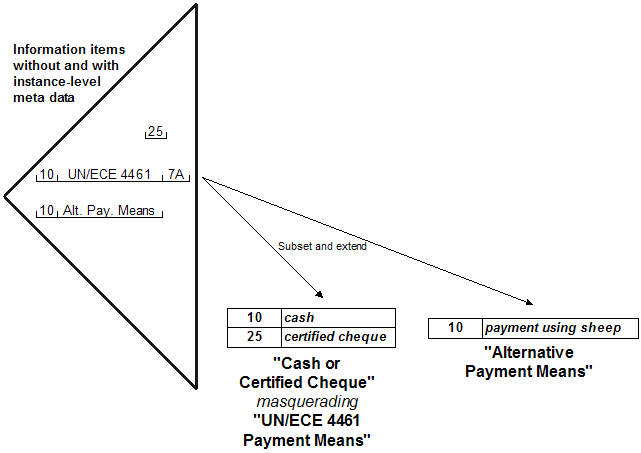
Consider, for example, that there are 75 different payment means represented by codes
defined by the UN/ECE 4461 specification. A business may wish to constrain payments
for one trading partner to only cash (10) and to all other trading partner either cash or certified cheque (25). The business is not interested in accepting instances from any trading partner
claiming to pay by any of the other 73 means such as a payment into a bank account
(42).
UBL has codified all code lists using the OASIS Genericode 1.0 specification [genericode]. The published payment means code list has 75 entries and is labeled "UN/ECE 4461". Other list-level meta data identifies the list from which the values are taken, thus indicating the standardized semantics of the codes to be implemented by applications. Figure 8 illustrates items in three contexts of a single document where the first context uses values from the entire standardized list, the second context uses the subset of standardized values, and the third context uses a combination of a subset of standardized values extended by a custom value.
Figure 8: Contextual uses of different versions of code lists
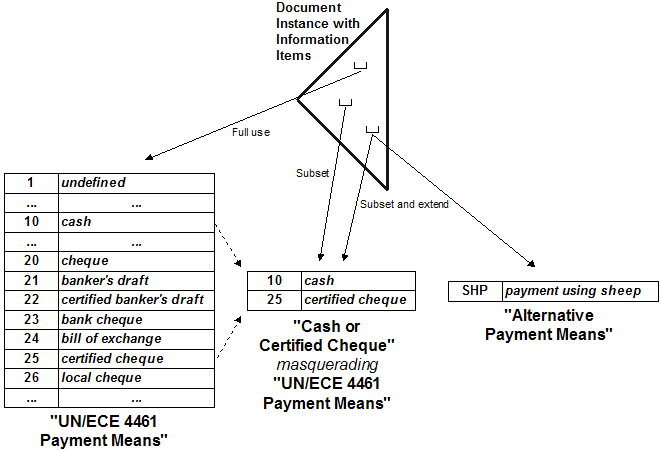
Necessarily, the subset list cannot be labeled "UN/ECE 4461" because it is, in fact, not the UN/ECE list. In this example it is labeled "Cash or Certified Cheque", but this may not be a name recognized by an application, and it could be an arbitrary name indicating use with a particular trading partner. However, the values in that list have the same semantic meaning as the values in the standardized list. An application knows the standardized values and would not recognize values from an ad hoc subset list if the list used arbitrary meta data. To address this, a subset list is said to masquerade the list from which its values are taken. For the purposes of application interpretation, the standardized semantics associated with the masqueraded list are implied by the values used from the masquerading list. The application then can understand what is represented by the codes, regardless of which version of a subset list is in use.
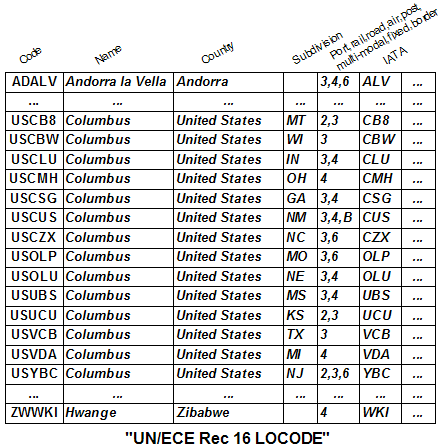
It is important for a list maintainer to describe the values in the code list such that a user of the code list best understands the semantics of codes. Values from each code list or identifier list may have value-level meta data. The typical ISO or UN/CEFACT code list has only the code itself and its name to be used as a description. Figure 9 illustrates the need for additional value-level meta data to disambiguate the simple name. This example shows some of the meta data associated with values in the UN/ECE Recommendation 16 location code list "LOCODE".
Figure 9: Value-level meta data
Instance-level meta data is used by the author of the XML instance to disambiguate two codes that have the same value but different meanings. In UBL, instance-level meta data is expressed in attributes of the element containing the code. Figure 10 illustrates three items using codes.
Figure 10: Instance-level meta data
The first code does not have instance-level meta data because it is unambiguous.
The second code indicates the semantics of "10" are defined in the "UN/ECE 4461" list version "7A", even though the actual list
being used is titled "Cash or Certified Cheque". The third code indicates the semantics
of the same value "10" are defined in the alternative list. The application thus can infer the document's
intent of the use of the code.
It should be noted that the UN/CEFACT organization publishes their code lists on a
semi-annual basis. Code "10" in the early 2007 ("7A") list might have its meaning changed in the late 2007 ("7B")
list. If it is important to the document that the semantics be distinguished, then
it is important to indicate the version in the instance-level meta data.
Figure 11 illustrates the Schematron-based creation of the XSLT stylesheet labeled "2" used in Figure 1.
Figure 11: Validation artefact generation
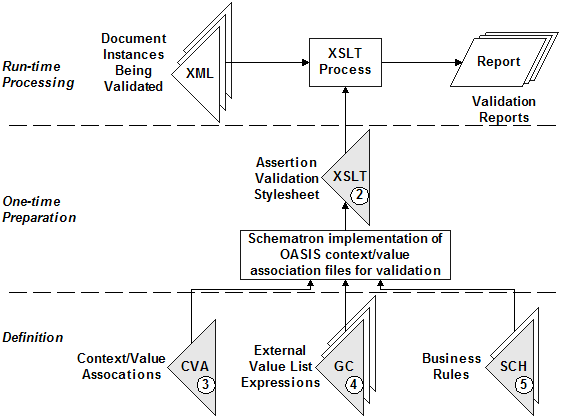
The context/value association (CVA) file labeled "3" associates XML document contexts with the codes in the genericode files labeled "4". Since Schematron allows for the specification of arbitrary business rules, these can be folded into the process in the generation of the single assertion validation stylesheet "2".
The versions of value validations when using UBL are, therefore, specified by different combinations of CVA files, genericode files and business rules. When engaging in business with different trading partners or in different business situations, the user can decide which version of value validation constraints to apply to the document.
Conclusion
Figure 12 illustrates there are three areas when using the OASIS Universal Business Language where versions of document constraints come into play in the validation of UBL XML documents: the base schema published by the UBL committee, any customization schema published by a user community for use in a particular business scenario called profile, and the values used within instances of those schemas in particular business relationships.
Figure 12: Different versions of UBL document constraints
An instance can assert it satisfies a particular set of structural and lexical constraints
through the three optional elements UBLVersionID, CustomizationID and ProfileID. The committee's backwards compatible minor-versioning strategy ensures a validating
application can access this information in instances of older versions by the committee
policy of introducing only optional constructs. The committee's proposed forward
compatible processing model ensures a validating application can access this information
in instances of newer versions by removing from an instance any constructs that are
not defined by the supported older version.
A user community can create a conformant customized subset and/or extended version of the UBL schemas by removing optional standardized constructs and by adding non-standardized constructs only underneath the document's extension point.
A individual in that community can choose from different versions of value constraints to layer on top of the community's structural and lexical constraints based on arbitrary trading partner requirements. These versions are expressed as code and identifier lists combined with business rules placed on the values.
This illustrates how a single XML vocabulary can be deployed into a heterogeneous network of differing implementation levels and different business contexts, while still promoting interoperability and standardized committee structures. The proposed processing model supports applications relying on schema-validity for instance inspection. Using this model, any individual will be able to access an instance from any other individual in any UBL community. Combining the document constraints with the out-of-band business constraints any two parties can successfully interchange information without schema validity being a barrier to access.
References
[CCTS] Core Components Technical Specification - Part 8 of the ebXML Framework http://www.unece.org/cefact/ebxml/CCTS_V2-01_Final.pdf Version 2.01 2003-11-15
[Crane Resources] Crane Softwrights Ltd.; Free developer resources http://www.CraneSoftwrights.com/links/res-ublo.htm
[genericode] OASIS Genericode 1.0 http://docs.oasis-open.org/codelist/genericode
[HISC] UBL Human Interface Subcommittee http://www.oasis-open.org/committees/ubl/hisc
[NDR2.0] UBL Naming and Design Rules 2.0; Editors: Mavis Cournane, Michael Grimley (draft) http://www.oasis-open.org/committees/document.php?document_id=22992
[OIOUBL] OIOUBL - Offentlig Information Online - Universal Business Language http://www.oioubl.info/classes/en/index.html
[TAG1] Extending and Versioning Languages: Strategies; Editor: David Orchard (draft) http://www.w3.org/2001/tag/doc/versioning-strategies
[UBL2.0] UBL 2.0; Editors: Jon Bosak, Tim McGrath, G. Ken Holman http://docs.oasis-open.org/ubl/os-UBL-2.0/UBL-2.0.html
[UBL-XPath] UBL 2.0 XPath files http://docs.oasis-open.org/ubl/submissions/XPath-files/
[XPath 1.0] James Clark, Steve DeRose XML Path Language (XPath) Version 1.0 http://www.w3.org/TR/1999/REC-xpath-19991116 1999-11-16
[XPath File] G. Ken Holman XPath file models http://www.oasis-open.org/committees/document.php?document_id=23525 2007-04-14
[XSD] Henry S. Thomson, et al.; XML Schema Part 1: Structures Second Edition http://www.w3.org/TR/2004/PER-xmlschema-1-20040318 2004-03-18
[XSLT 1.0] James Clark; XSL Transformations (XSLT) Version 1.0 http://www.w3.org/TR/1999/REC-xslt-19991116 1999-11-16