Lizzi, Vincent M. “Testing Schematron using XSpec.” Presented at Balisage: The Markup Conference 2017, Washington, DC, August 1 - 4, 2017. In Proceedings of Balisage: The Markup Conference 2017. Balisage Series on Markup Technologies, vol. 19 (2017). https://doi.org/10.4242/BalisageVol19.Lizzi01.
Balisage: The Markup Conference 2017 August 1 - 4, 2017
Schematron is a powerful, flexible, and user-friendly tool for validating and reporting
on XML content. Developing a Schematron schema can
involve a lot of testing to ensure that each Schematron rule works as expected. A
robust test suite may contain multiple XML samples for every
Schematron rule in order to test both passing and failing conditions. XSpec — an open
source unit test and behavior-driven development framework
for XSLT and XQuery — now has the ability to test Schematron. Tests for a Schematron
can be described using XSpec test scenarios, and the tests
can be run automatically by XSpec. The end result is a report showing which tests
passed and which tests failed. The new support for Schematron
testing in XSpec enables test-driven development for Schematron and automated regression
testing for Schematron in a continuous integration
environment.
Schematron (ISO/IEC 19757-3:2006) is a rule-based language that uses XPath expressions to test assertions about the
content of XML
documents. Schematron is capable of expressing rules that other XML validation languages
such as DTD and XML Schema are unable to implement
(Usdin, Lapeyre, and Glass 2015). Schematron allows business rules written for a human audience to be included with
XPath that instructs
machines on how to enforce the business rules. This versatility and literate design
make Schematron an attractive tool for implementing business
rules in XML (Lubell 2009). Schematron is often deployed as an important part of quality assurance processes
(Blair 2012; Kraetke and Bühring 2016). It is important to have verification that a Schematron schema functions as intended
because a problem in the schema may allow in errors in XML that should be caught to
slip through quality control. The use of an automated testing
tool can greatly assist with verifying that a Schematron schema functions as intended.
A few tools have been created for testing Schematron schemas. The Schematron Testing
Framework (STF) developed by Tony Graham is one open source tool for testing Schematron. Various
homegrown solutions for testing Schematron, based on tools such as JUnit and others,
have also been created.
XSpec has been enhanced recently to support testing Schematron (XSpec). XSpec is an open source unit test and
behavior-driven development framework for XSLT and XQuery. XSpec was originally developed
by Jeni Tennison and is currently maintained by Sandro
Cirulli and community contributors. XSpec provides a structure in which sample XML
and processing expectations can be organized and executed.
Several features make XSpec an ideal tool for testing Schematron:
Tests are described using a simple and flexible XML format.
XSpec can run multiple test scenarios to encompass both passing and failing conditions.
Sample XML for input to tests can be provided either as fragments of XML or as XML
files.
Execution can be focused on specific tests during development.
XSpec can automatically execute tests and produce a report.
XSpec can run in a variety of environments.
XSLT custom functions can be tested.
XSpec and Schematron have much in common: XSpec and Schematron (the standard Schematron
Skeleton
implementation) are both XSLT applications; both have a literate programming design
that allows natural
language rules to be expressed alongside machine executable code that implements the
rules; both provide
domain specific languages that allow tests to be described easily; and both can execute
a large number of
detailed tests efficiently.
When XSpec is deployed as an automated testing tool for Schematron, it can provide
a number of benefits which include: decreasing the amount of
time needed to write Schematron rules; helping to identify problems early; freeing
time that would otherwise be spent on repetitive testing, which
allows human effort to be directed to activities requiring knowledge and skill; and
reducing the cost of developing and maintaining Schematron
schemas. This paper describes how to use XSpec to test Schematron. Additional information
about how to use XSpec is available in the XSpec wiki
(https://github.com/xspec/xspec/wiki).
Quick Introduction to Schematron
Although much has already been written about Schematron a quick introduction may be
helpful here. Schematron tests XML instance documents using
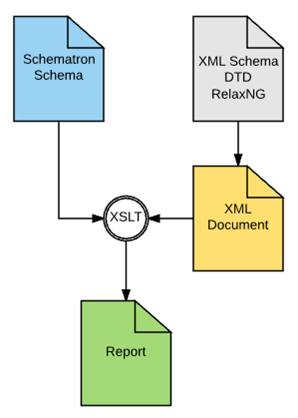
rules, the outcome of which is a report. Figure 1 illustrates the Schematron process flow. Rules in Schematron are written as
assertions, which can be either positive or negative. Schematron is often used for
validating XML to produce a pass/fail or pass/warn/fail report,
although Schematron is also used as a reporting tool to collect information. Schematron
can be used alone or in conjunction with other XML
validation methods.
Figure 1: Schematron processing an XML instance document
The essential Schematron elements that are used to create Schematron schemas are described
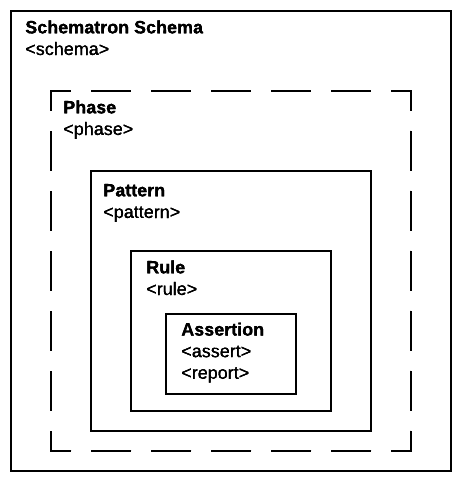
below. Figure 2 shows the basic structure
of a Schematron schema.
Figure 2: Basic structure of a Schematron schema
A Schematron schema (which will henceforth be referred to as just Schematron) is written
in XML and begins with the root element
<schema>.
If any namespaces are needed each namespace should be declared using a <ns> element.
Namespace prefixes that are declared in <ns> elements
can be used in XPath expressions in the Schematron. The <ns> element is placed inside
the <schema> element.
The <schema> element contains one or more <pattern> elements. The <pattern> element
performs a pass through an XML instance document
during which the assertions contained in the <pattern> are evaluated. The <pattern>
element can be used to group related assertions.
<sch:pattern>
Each <pattern> contains one or more <rule> elements. The <rule> element provides the
context in which XPath tests will be evaluated for
assertions contained in the <rule>. The context is defined in the @context attribute
using an element name or XPath expression that identifies
nodes that should be tested by the assertions within the <rule>. For example, <rule
context="foo"> matches all <foo> elements and the XPath
tests for assertions in this rule are relative to the <foo> element.
<sch:rule context="xpath">
Each <rule> element contains one or more assertions. Assertions are written using
<assert> and <report> elements.<assert> and
<report> hold a natural-language description and have an attribute @test which holds
an XPath expression that will be evaluated. <assert> and
<report> also have optional attributes: @id holds an identifier, and @role describes
function (e.g. "error" or "warn"). When a Schematron is run,
an <assert> or <report> can be thrown if the input XML instance matches the criteria
that is specified by the XPath expression in the @test
attribute. An <assert> will be thrown if the XPath test evaluates to false. A <report>
will be thrown if the XPath test evaluates to true.
<sch:assert test="xpath">message to be output if the xpath test is false</sch:assert>
<sch:report test="xpath">message to be output if the xpath test is true</sch:report>
The <phase> element allows a set of patterns to be named so that Schematron can run
a particular set of patterns (instead of all patterns,
which is the default if no phase is selected or defined). <pattern> has an optional
@id attribute which can be used in conjunction with the
<phase> element to identify a group of patterns. In this example if a user selects
to run Schematron using the phase named "phase1", patterns A
and B will run and pattern C will not
run.
When Schematron is run, an XML instance (a document) is given as input and the Schematron
uses the following process to evaluate the XML instance.
Each <pattern> performs a pass through the XML instance. When a <rule> context matches
a node in the XML instance the XPath tests for
assertions in that <rule> are evaluated. Schematron then produces a report that contains
the messages for each assertion that was thrown during
evaluation of the XML instance. The report can be output as XML in the Schematron
Validation Report Language (SVRL) format.
The following example shows a simple Schematron that checks XHTML <div> elements to
ensure the @class attribute is present. This Schematron has
one <pattern> element to perform a single pass through a given XHTML document. The
<rule> with context "html:div" locates all <div>
elements in the XHTML namespace. The assertion is defied using an <assert> element
with an XPath test that evaluates to true if the @class
attribute is present on the context node (all <div> elements), a message that should
be generated in a report if the @class attribute is not
present, and specifies the role of this assertion as error.
<?xml version="1.0" encoding="UTF-8"?>
<sch:schema xmlns:sch="http://purl.oclc.org/dsdl/schematron" queryBinding="xslt2">
<sch:ns uri="http://www.w3.org/1999/xhtml" prefix="html"/>
<sch:pattern>
<sch:rule context="html:div">
<sch:assert test="@class" role="error">div must have a class attribute</sch:assert>
</sch:rule>
</sch:pattern>
</sch:schema>
When this Schematron is run on the following XHTML, the <rule> locates the <div> element,
and the <assert> tests for the presence of the
@class attribute. The @class attribute is not present, so the test on the <assert>
evaluates to false and the assertion is thrown. The report
that is produced by the Schematron will contain the message "div must have a class
attribute" with a status "error" as defined in the
<assert>.
In the following XHTML the <div> element has a @class attribute. When the Schematron
is run on this XHTML the test for a @class attribute
evaluates to true so the assertion is not thrown, and the message is not output in
the report.
This quick introduction has described the parts of Schematron that are used most frequently.
Schematron has more features which include abilities
to: reuse abstract patterns and abstract rules, import patterns and rules from separate
files, use XPath to generate messages, reuse diagnostic
messages, include documentation in the Schematron, and link to external documentation.
At its core Schematron is simple and easy to use, yet
Schematron can contain thousands of assertions and the XPath expressions can be complex.
When a Schematron grows in size or complexity it becomes
increasingly important to have a reliable and efficient means to verify that the Schematron
works correctly as intended.
Writing Tests for Schematron
Developing a Schematron typically involves testing the Schematron using a set of sample
XML. The sample set should include both XML that is valid
— which the Schematron should pass, and XML that contains errors — which the Schematron
should catch. This sample set must be maintained in addition
to the Schematron itself. When changes are made to the Schematron, new sample XML
should be added to test the changes, and the entire sample set
should be used again to test the Schematron to verify that no regression defects have
been introduced. The curation of a set of sample XML for a
Schematron is well described by Schwarzman (2017). XSpec can assist with developing and maintaining a
Schematron by providing a structure for organizing the sample XML associated with
a Schematron and automatically executing the Schematron on the set
of sample XML.
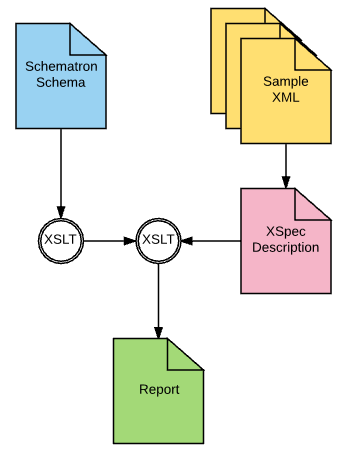
When XSpec is run it first compiles the Schematron, then executes the test scenarios
that are described in the XSpec test description, and then
produces a report, as illustrated in Figure 3.
Figure 3: XSpec processing Schematron tests
The first step in creating an XSpec test for a Schematron schema is to create an XML
file that adheres to the XSpec RelaxNG schema. The root
element <x:description> should have an attribute @schematron that specifies the file
path to the Schematron schema. For example,
Next, <x:scenario> elements are added for each test case. The <x:scenario> element
is used both to organize tests and to describe
individual tests. A scenario is required to have a label, which is placed in an attribute
@label, to describe what the scenario is testing. An
<x:scenario> element can contain nested <x:scenario> elements, a convenience which
provides a way to organize tests, as in this case:
An <x:scenario> that describes an individual test contains sample XML and declares
one or more expectations about the desired result of running
the Schematron on the sample XML. An <x:context> element is used to hold the sample
XML. The sample XML can be placed directly in the
<x:context> element:
Alternatively, sample XML in a separate file can be referenced by the <x:context>
element using a @href attribute. For example,
<x:context href="sample.xml"/>
The results that are desired when the Schematron is run on the sample XML can be declared
using expect elements. The expect elements are as
follows:
<x:expect-assert> verifies that an <assert> is thrown.
<x:expect-report> verifies that a <report> is thrown.
<x:expect-not-assert> verifies that an <assert> is not thrown.
<x:expect-not-report> verifies that a <report> is not thrown.
<x:expect-rule> verifies that a <rule> is fired (i.e. thrown).
<x:expect-valid> verifies that the Schematron is executed and that it passes validation for the sample
XML (i.e. no
<assert> or <report> is thrown). If the Schematron throws any warning or informational
messages (i.e. <assert> or <report> with
a @role attribute specifying “warn” or “info”) these are allowed for a passing validation.
<x:expect> can be used to specify custom expectations to directly test the SVRL XML that is
generated when a Schematron
schema is run on a sample XML.
The <x:expect-assert>, <x:expect-report>, <x:expect-not-assert>, and <x:expect-not-report>
elements will normally match any
<assert> or <report> that is in the Schematron. These expect elements have optional
attributes, @id, @role, and @location, which can be used
in any combination to make an expectation more specific.
id identifies a specific <assert>, <report>, <rule>, or <pattern> in the Schematron
with a matching @id attribute
value.
role matches the @role attribute value of an <assert>, <report>, or <rule> in the Schematron.
The @role attribute is
often used to specify outcomes such as “error”, ”fatal”, ”warn”, or ”info.”
location identifies a specific location, using an XPath pointer, in the context XML that the
Schematron <assert> or
<report> is expected to find. Namespace prefixes that are defined in Schematron using
<ns> elements can be used in the XPath. An XPath
pointer can, for example, be easily obtained by using the "Copy XPath" function in
oXygen and pasted into the @location attribute.
The <x:expect-assert>, <x:expect-report>, and <x:expect-rule> elements have an optional
attribute @count which verifies that an
<assert>, <report> or <rule>, respectively, is thrown a certain number of times. Without
the @count attribute, the <x:expect-assert>,
<x:expect-report>, and <x:expect-rule> elements verify an <assert>, <report> or <rule>
is thrown at least once. With the @count
attribute, the <x:expect-assert>, <x:expect-report>, and <x:expect-rule> elements
verify an <assert>, <report> or <rule> is thrown
the same number of times as specified by the @count attribute (e.g. count="1" specifies exactly once).
For instance, if you expect that when a Schematron is run on a particular sample XML
an <assert> with id “a1” and role “error” will be thrown
at XPath location /article/front/article-meta/fpage, this expectation could be written
in a scenario as:
Custom XSLT functions that are embedded in a Schematron schema can be tested in an
<x:scenario> by using an <x:call> element to call the
function and an <x:expect> element to describe the expected result of the function.
Parameter values that should be used in the test can be
specified in the <x:call> element using <x:param> elements, as the following illustrates:
If a Schematron has multiple phases separate XSpec files are needed to test each phase.
The phase that is to be tested can be specified in the
<x:description> element by adding an <x:param name="phase"> element containing the
name of the phase. (<x:param> can also be used to
provide parameters to the Schematron compilation.) For example:
It is often helpful to organize test scenarios into separate files to make the maintenance
of large test suites easier or to enable reuse of test
scenarios. Test scenarios that are in a separate file can be imported using the <x:import>
element, which can be placed in the <x:description>
element. An attribute @href is required to specify the path to the XSpec file that
is to be imported. For instance,
<x:import href="common-scenarios.xspec"/>
During development it can be helpful to run a single test scenario in isolation instead
of running an entire test suite. The @focus attribute can
be added to any <x:scenario> to instruct XSpec to run only that scenario. After finishing
work on a focused scenario, it is a good idea to remove
the @focus attribute and run XSpec to check that no problems have been introduced
into other scenarios. For example,
<x:scenario focus="working on new test" label="article title should not be in all caps">
It can sometimes be necessary to prevent certain test scenarios from executing. For
example, if a test scenario is known to fail for a particular
reason that cannot be easily resolved, it might not be desirable to have this scenario
executed. Any <x:scenario> can be marked as pending, which
will prevent the <x:scenario> from being executed. There are two ways to mark an <x:scenario>
as pending: the <x:scenario> can be wrapped
in an <x:pending> element, or an attribute @pending can be added to the <x:scenario>
element. For example,
<x:pending label="not yet implemented">
<x:scenario label="language code should use ISO 639">
<x:context>
<article xml:lang="xx"/>
</x:context>
<x:expect-assert/>
</x:scenario>
</x:pending>
or
<x:scenario pending="not yet implemented" label="language code should use ISO 639">
<x:context>
<article xml:lang="xx"/>
</x:context>
<x:expect-assert/>
</x:scenario>
XSpec incorporates the standard XSLT implementation of ISO Schematron. When XSpec
executes a Schematron test, before the test is actually run, the
Schematron is first compiled by a series of three XSLT transforms. The process for
compiling Schematron into XSLT is described in documentation for
Schematron (Jelliffe). XSpec can be configured to use custom XSLTs for compiling Schematron by providing
the file path to the
custom XSLTs in environment variables SCHEMATRON_XSLT_INCLUDE, SCHEMATRON_XSLT_EXPAND,
and SCHEMATRON_XSLT_COMPILE.
XSpec might not be able to test every Schematron schema. There are limits to what
XSpec is able to test in XSLT which may also apply to
Schematron. For example, XPath that begins at document root (i.e., begins with “/”)
may not work as intended when executed within XSpec. The
limitations of using XSpec to test Schematron are not yet known because this is a
new feature. Users may report problems that they encounter to the
issue log on the XSpec GitHub project (https://github.com/xspec/xspec/issues).
Example
The following is an example of an XSpec test for a simple Schematron schema. This
Schematron schema implements two rules based on JATS (Z39.96-2015), an XML format for journal articles:
Identifier
Business Rule
Result
am-0001
An article should have one DOI tagged in <article-id> with pub-id-type="doi"
creates an error which should cause a stop
am-0002
A book review article should have details of the book(s) being reviewed tagged in
<product> element(s)
creates a warning message
The Schematron schema that implements these rules is as follows (filename demo.sch).
<?xml version="1.0" encoding="UTF-8"?>
<sch:schema xmlns:sch="http://purl.oclc.org/dsdl/schematron" queryBinding="xslt2">
<sch:pattern>
<sch:rule context="article-meta">
<sch:assert id="am-0001" role="error"
test="count(article-id[@pub-id-type='doi']) = 1"
>An article should have one DOI tagged in <article-id> with
pub-id-type="doi"</sch:assert>
<sch:report id="am-0002" role="warn"
test="ancestor::article[@article-type='book-review'] and not(product)"
>A book review article should have details of the book(s) being
reviewed tagged in <product> element(s)</sch:report>
</sch:rule>
</sch:pattern>
</sch:schema>
Sample XML is created to test each business rule. The rule am-0001 states that an
article should have one DOI tagged. Three sample XMLs are
needed to test this rule: a sample with one DOI tagged, which should pass the requirement;
a sample with no DOI tagged, which should fail by having
less than one DOI; and a sample with two DOIs tagged, which should fail by having
more than one DOI. These sample XMLs are added to the XSpec test.
First, a scenario element is added for rule am-0001. Inside this scenario element,
three scenario elements are added for the three sample XMLs. The
sample XML is placed in context elements, and expect elements are added to specify
the result that is desired when the Schematron is run on the
sample XML.
Rule am-0002 states that a book review article should have details of the reviewed
book(s) tagged in product element(s). Two sample XMLs are used
to test this rule: a sample with a book review article that has the product element,
which should pass the requirement, and a sample with a book
review that does not have the product element, which should generate the warning message.
First, a scenario element is added for rule am-0002.
Inside this scenario element, two scenario elements are added for the two sample XMLs.
Again, the sample XML is placed in context elements, and
expect elements are added to specify the desired result of the Schematron running
on the sample XML.
In addition, a sample is created as an example of XML that correctly follows all of
these rules. This sample is an XML file and it is referenced
using a context element (filename book-review.xml).
The test is executed by running XSpec with the -s option, which indicates a Schematron test.
xspec\bin\xspec.bat -s test\demo.xspec
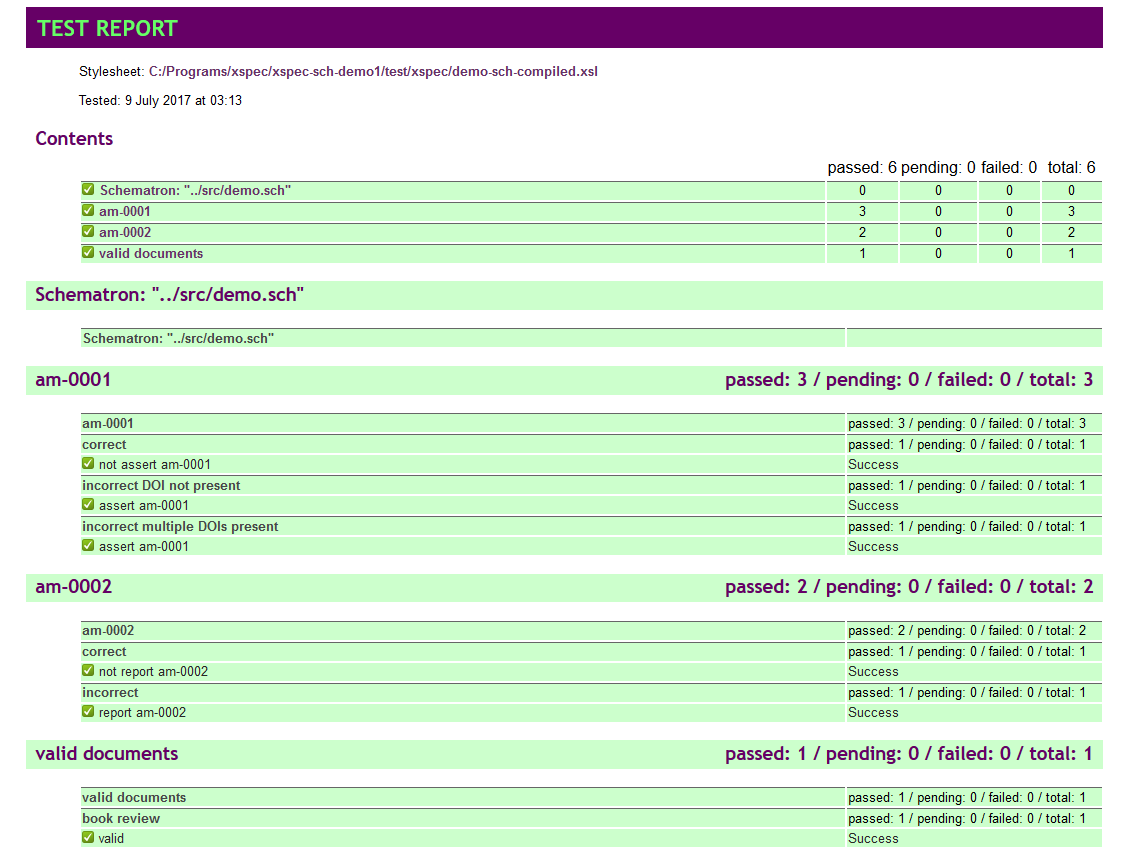
XSpec runs the tests and produces a report that shows the result of each test. The
report can be output in HTML format presented in a display
similar to the example shown in Figure 4.
Figure 4: Example of an XSpec Schematron test report
Behavior-Driven (or Test-Driven) Development
Behavior-Driven Development (BDD) — also known as Test-Driven Development (TDD) —
is a methodology for
software development that involves writing tests to ensure that code works correctly
before, or at the same
time as, the code itself is written. The use of specialized tools to automate software
testing helps to
enable a BDD workflow (Fox 2016). BDD can be introduced at any point in a project. If a
BDD workflow is used from the start, the project may have a complete corpus of automated
tests that helps to
ensure reliability of the software. If a BDD workflow is introduced to an existing
project, new development
work can begin to use BDD, and over time tasks can be performed to create automated
tests for older code.
Whether to use a BDD workflow is not an all-or-nothing decision; it is possible to
use a BDD workflow only
in those parts of a project where it is feasible.
The following is an outline of a BDD workflow for Schematron development using XSpec.
The first three
steps (writing the business rule, collecting sample XML, and assigning an identifier),
can be done with the
participation of stakeholders. The subsequent three steps require knowledge of Schematron
and XSpec.
Write the business rule.
Collect samples of XML that are valid according to the business rule and samples of
XML that
should cause a validation failure or message according to the business rule. The sample
set should
be selected to include examples that test boundary limits and edge cases.
Assign the business rule an identifier (a valid xs:NCName)
Create an XSpec <x:scenario> for the business rule.
Inside the <x:scenario> for the business rule, create an <x:scenario> for each
sample XML.
Provide the sample XML using <x:context>
Describe the expectation using expect elements.
Include the identifier in the @id attribute of the expect elements.
Write the Schematron assertion for the business rule. Include the identifier in the
@id attribute
of the <assert> or <report>.
Run the XSpec test to verify that the Schematron works as expected.
When writing a Schematron schema, a developer may choose to organize assertions into
rules and patterns
for reasons of efficiency, and the chosen organization may differ from the way the
business rules are
organized or the way the XSpec tests are organized. Assigning an identifier to each
<assert> and
<report> (using the @id attribute) and using these identifiers to relate the corresponding
business rule
and XSpec tests can help with maintenance of the Schematron. If a complex business
rule is implemented using
more than one <assert> or <report> the identifier can be extended by adding a unique
suffix in the @id
attribute of each <assert> or <report>.
Continuous Integration
Use of a continuous integration server can further improve a Schematron development
workflow. Continuous
integration offers a variety of options for task automation, such as executing tests
when changes are pushed
to a code repository, sending email alerts when tests succeed or fail, and triggering
downstream actions
after successful tests. XSpec is able to produce its reports in the JUnit XML format,
which is understood by
Jenkins, a popular continuous integration server (Jenkins).
The following is an example of how an XSpec Schematron test can be configured to run
in a continuous integration server. It is worth noting that
while this example illustrates using Jenkins as a continuous integration server, using
GitLab to host a code repository, using a git submodule to
import XSpec, and using a Windows server environment, other tools and methods can
be used to achieve the same goal. This example also makes use of
the File Operations Plugin for Jenkins. In addition, the server on which Jenkins is
running has Java and git installed. By using a git submodule as
shown here it is possible to use the latest version of XSpec from the git repository,
although in practice it may be preferable to use a release
version of XSpec (at the time of this writing the first release version with support
for Schematron is expected to be available on GitHub
soon).
Begin by creating a git repository. Add a git submodule to import XSpec. Create a
Schematron schema and
XSpec test. Commit these changes to git. Then, push the repository to a project that
has been created on
GitLab. These tasks can be accomplished through the following git commands:
Next, configure a job to run the XSpec test by following these steps in Jenkins:
Create a new item (i.e. job, project)
Select Freestyle project. Enter a name for the item and avoid using spaces in the
name.
In the “Source Code Management” section, enter the URL and credentials for the Git
repository.
Then, under “Additional Behaviours” select “Advanced sub-module behaviours” and enable
the option
“Recursively update submodules”.
In the “Build” section, add an action “File Operations” and select “File Download”.
Enter the URL
http://central.maven.org/maven2/net/sf/saxon/Saxon-HE/9.7.0-18/Saxon-HE-9.7.0-18.jar
and enter the target file name “saxon.jar”
Next, in the “Build” section, add an action "Execute Windows Batch Command". Enter
this script which sets the SAXON_CP environment
variable and then executes XSpec.
set SAXON_CP="%WORKSPACE%\saxon.jar"
xspec\bin\xspec.bat -s -j test\demo.xspec
In the “Post-build Actions” section, add an action “Publish Junit test result report”.
Enter the
Test report XMLs location as “test/xspec/*-junit.xml”.
Save the configuration
Click “Build Now” to have Jenkins run the XSpec test. A progress bar will appear to
indicate that the test is running. After the process is done
click the “Latest Test Result” link to see the report. Jenkins displays XSpec test
results as a summary which can be clicked to view the results of
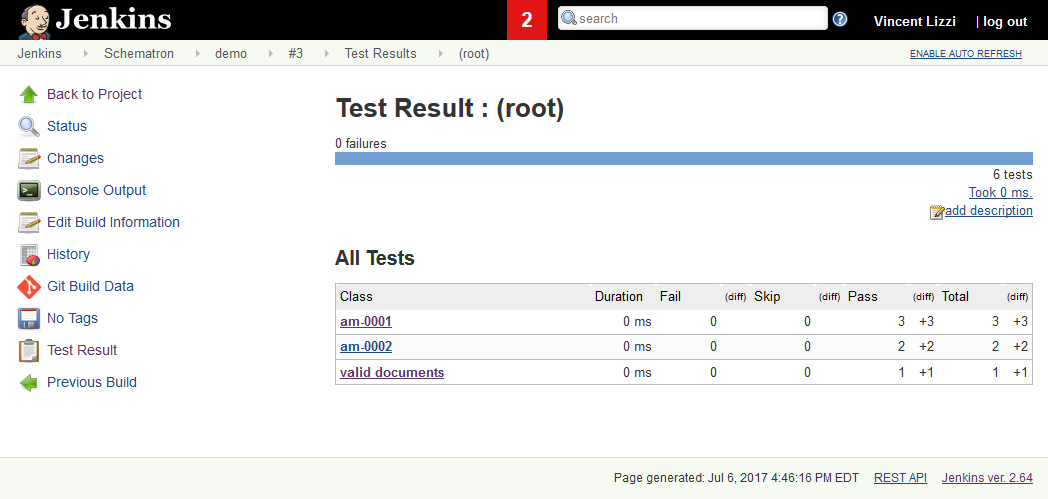
individual tests, as shown in Figure 5.
Figure 5: Example of XSpec test results in Jenkins
Configuring XSpec to run automatically in a continuous integration server may provide
the highest level of
convenience for testing Schematron. There are a great many options available when
considering how to
incorporate XSpec in a project, and decisions can be driven by the unique needs of
a project.
Conclusion
In this paper, XSpec was introduced as a testing automation tool to assist with developing
and maintaining Schematron schemas. A tutorial on how
to use XSpec for testing Schematron was provided, followed by an example of an XSpec
test for a Schematron schema. A possible workflow for
incorporating XSpec into a Schematron development project was suggested using the
Behavior-Driven Development methodology. An example was used to
illustrate how XSpec tests for a Schematron schema can be configured to run automatically
in a continuous integration server.
The use of automated testing tools has become popular due to the many benefits that
automated testing can
provide. XSpec now offers Schematron users a new tool for automated testing of Schematron.
Support for
testing Schematron is a new feature in XSpec, and users may report feedback through
the XSpec
project on GitHub.
Acknowledgements
The author would like to thank Sandro Ciruli, AirQuick, Amanda Galtman and Robert
Stuart for providing encouragement, testing and suggestions. The
author also thanks Jeni Tennison for creating XSpec, and Florent Georges for helping
to sustain the XSpec project.
References
[Blair 2012] Blair, Julie. “Developing a Schematron–Owning Your Content Markup: A Case Study.”
Presented at
Journal Article Tag Suite Conference (JATS-Con) 2012, Bethesda, MD, October 16 - 17,
2012. In Journal Article Tag Suite
Conference (JATS-Con) Proceedings 2012. National Center for Biotechnology Information (US). https://www.ncbi.nlm.nih.gov/books/NBK100373/
[Kraetke and Bühring 2016] Kraetke, Martin, and Franziska Bühring. “A Quality Assurance Tool for JATS/BITS
with Schematron and HTML Reporting.” Presented at Journal Article Tag Suite Conference
(JATS-Con) 2016, Bethesda, MD, April 12 - 13, 2016. In
Journal Article Tag Suite Conference (JATS-Con) Proceedings 2016. National Center for Biotechnology Information
(US). https://www.ncbi.nlm.nih.gov/books/NBK350149/
[Lubell 2009] Lubell, Joshua. “Documenting and Implementing Guidelines with Schematron.”
Presented at Balisage: The Markup Conference 2009, Montréal, Canada, August 11 - 14,
2009. In Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup
Technologies, vol. 3 (2009). doi:https://doi.org/10.4242/BalisageVol3.Lubell01
[Schwarzman 2017] Schwarzman, Alexander B. “JATS Subset and Schematron: Achieving the Right Balance.”
Presented at Journal Article Tag Suite Conference (JATS-Con) 2017, Bethesda, MD, April
25 - 26, 2017. In Journal Article Tag
Suite Conference (JATS-Con) Proceedings 2017. National Center for Biotechnology Information (US). https://www.ncbi.nlm.nih.gov/books/NBK425543/
[Usdin, Lapeyre, and Glass 2015] Usdin, Tommie, Deborah Aleyne Lapeyre, and Carter M. Glass. “Superimposing
Business Rules on JATS.” Presented at Journal Article Tag Suite Conference (JATS-Con)
2015, Bethesda, MD, April 21 - 22, 2015. In Journal Article Tag Suite Conference (JATS-Con) Proceedings 2015. National Center for Biotechnology Information (US).
https://www.ncbi.nlm.nih.gov/books/NBK279902/
Blair, Julie. “Developing a Schematron–Owning Your Content Markup: A Case Study.”
Presented at
Journal Article Tag Suite Conference (JATS-Con) 2012, Bethesda, MD, October 16 - 17,
2012. In Journal Article Tag Suite
Conference (JATS-Con) Proceedings 2012. National Center for Biotechnology Information (US). https://www.ncbi.nlm.nih.gov/books/NBK100373/
Kraetke, Martin, and Franziska Bühring. “A Quality Assurance Tool for JATS/BITS
with Schematron and HTML Reporting.” Presented at Journal Article Tag Suite Conference
(JATS-Con) 2016, Bethesda, MD, April 12 - 13, 2016. In
Journal Article Tag Suite Conference (JATS-Con) Proceedings 2016. National Center for Biotechnology Information
(US). https://www.ncbi.nlm.nih.gov/books/NBK350149/
Lubell, Joshua. “Documenting and Implementing Guidelines with Schematron.”
Presented at Balisage: The Markup Conference 2009, Montréal, Canada, August 11 - 14,
2009. In Proceedings of Balisage: The Markup Conference 2009. Balisage Series on Markup
Technologies, vol. 3 (2009). doi:https://doi.org/10.4242/BalisageVol3.Lubell01
Schwarzman, Alexander B. “JATS Subset and Schematron: Achieving the Right Balance.”
Presented at Journal Article Tag Suite Conference (JATS-Con) 2017, Bethesda, MD, April
25 - 26, 2017. In Journal Article Tag
Suite Conference (JATS-Con) Proceedings 2017. National Center for Biotechnology Information (US). https://www.ncbi.nlm.nih.gov/books/NBK425543/
Usdin, Tommie, Deborah Aleyne Lapeyre, and Carter M. Glass. “Superimposing
Business Rules on JATS.” Presented at Journal Article Tag Suite Conference (JATS-Con)
2015, Bethesda, MD, April 21 - 22, 2015. In Journal Article Tag Suite Conference (JATS-Con) Proceedings 2015. National Center for Biotechnology Information (US).
https://www.ncbi.nlm.nih.gov/books/NBK279902/