Gross, Mark, Ari Gross and Yunhao Shi. “A System to Identify Plagiarized Images in STM Journal Submissions.” Presented at Balisage: The Markup Conference 2017, Washington, DC, August 1 - 4, 2017. In Proceedings of Balisage: The Markup Conference 2017. Balisage Series on Markup Technologies, vol. 19 (2017). https://doi.org/10.4242/BalisageVol19.Gross01.
Balisage: The Markup Conference 2017 August 1 - 4, 2017
Balisage Paper: A System to Identify Plagiarized Images in STM Journal Submissions
Mark Gross
President
Data Conversion Laboratory
Mark Gross, President of Data Conversion Laboratory, is a recognized authority on
XML implementation, document conversion, and data mining. Prior to founding DCL in
1981, he was with the consulting practice of Arthur Young & Co. Mark has a BS in Engineering
from Columbia University and an MBA from New York University, and has taught at the
New York University Graduate School of Business, the New School, and Pace University.
Ari Gross
CEO
CVISION Technologies, Inc.
Dr. Ari Gross, Ph.D., serves as Chief Executive Officer at CVISION Technologies, Inc.
Dr. Gross has been involved in digital imaging for the past 20 years. His achievements
include over 40 published papers and several patents in areas related to digital imaging
and document understanding. Dr. Gross received a BS degree in Mathematics from Johns
Hopkins University and a PhD in Computer Science from Columbia University.
Yunhao Shi
Senior Software Engineer
CVISION Technologies, Inc.
Yunhao Shi is a senior software engineer at CVISION Technologies, Inc. He has been
involved in digital imaging, OCR and automation for the past 13 years and has a patent
in super accurate OCR. Shi received a BS degree in computer science from Queens college.
Plagiarism in the scientific community is not new, but has garnered greater attention
in the past few years due to higher publication volumes, greater pressure to publish,
increased access and the resultant increased readership, and computers that can do
the analysis on the fly. To counter the embarrassment, and economic harm, of publishing
plagiarized research, testing for text-based plagiarism in journal articles has become
a regular practice; for many journals and societies all incoming articles are tested
against massive publication databases to avoid future problems.
While text analysis has become common, identifying image-based plagiarism is more
complex with significant technical difficulties to overcome, and to our knowledge
is not done. This paper describes work we recently completed on a pilot system to
compare images in a submitted article against an image publication database, identifying
likely matches that warrant further investigation. We also discuss the issues surrounding
altered images, including the need to identify likely candidates while minimizing
false positives.
Plagiarism in the scientific community is not new, but has garnered greater attention
in the past few years due to higher publication volumes, greater pressure to publish,
increased access and the resultant increased readership, and computers that can do
the analysis on the fly. To counter the embarrassment, and economic harm, of publishing
plagiarized research, testing for text-based plagiarism in journal articles has become
a regular practice; for many journals and societies all incoming articles are tested
against massive publication databases to avoid future problems.
While text analysis has become common, identifying image-based plagiarism is more
complex with significant technical difficulties to overcome, and to our knowledge
is not done. This paper describes work we recently completed on a pilot system to
compare images in a submitted article against an image publication database, identifying
likely matches that warrant further investigation. We also discuss the issues surrounding
altered images, including the need to identify likely candidates while minimizing
false positives.
Doesn’t Google Already Do All This With Facial Recognition?
While what Google, Facebook, and others do in recognizing faces, landmarks, etc. is
truly amazing, recognizing plagiarized images turns out to be much more complex. With
facial recognition, you can appropriately model what you are looking for – faces have
common features, which can be mapped, and are recognizable when searching an image
collection. In addition, solving the facial recognition problem does not necessarily
require comparing the image to the facial universe. Facebook, for example, knows who
your friends are, simplifying the matching process to the nearest neighbors in the
graph. In other words, friends in the social network are given precedence over non-friends
and friends of friends. Likewise, with facial recognition security applications at
airports and other sensitive locations, you have reasonable knowledge of what you
are looking for; the database of “persons of interest” is relatively small (10,000’s,
not millions).
However, when identifying images for potential plagiarism, there is no a priori model to recognize or compare to – the image (or subimage) might be anything, and
has likely been altered from the original.
“Identity” vs. “Similarity”
Identifying two objects as identical is relatively easy, for either text or images.
Identifying variations is more interesting. Remember in sixth grade when kids would
copy a paragraph from an encyclopedia (or now Wikipedia), try to change a few words,
and assume no one would notice? That’s essentially what we’re trying to catch. Of
course, determining that two similar instances are copies vs. happenstance can be
quite subjective.
It’s a recurring problem in text, images, and even music.
Text-based Similarity
Gathering text similarity metrics are relatively easy. We can normalize compared documents
by eliminating punctuation and noise words, pairing synonyms, building word wheels,
and other such normalization tactics, allowing a computer to compare a document against
a large text repository to “count” differences, identifying candidate sections that
require further attention.
A typical example of the type of analysis that we perform, though not for plagiarism,
is the analysis of document collections to recognize similar sections in order to
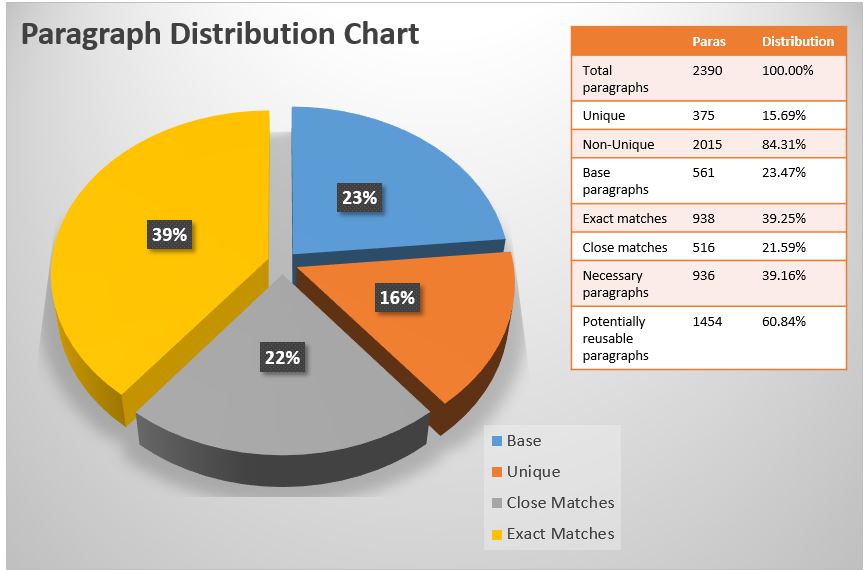
identify common reusable components. The pie graph of findings for an example document
collection is shown in Figure 1. This collection consists of 2,390 paragraphs, and we found that 938 (39.25%) were
identical to a version of the paragraph found earlier in the collection, and that
another 516 (21.59%) were close matches.
Figure 1: Paragraph Distribution Chart
The close matches are of greatest interest here. Figure 2 shows an example of the variations that were found in a set of documents, with the
identified variations redlined to make clear where the variations occurred. The first
instance (line 1773) is the base paragraph to which we compare the variations. The
next line shows a composite of all the variations, many of which are minor. Most of
these paragraphs are candidates for standardization in order to streamline the document
set.
Figure 2: Redline Example
Image-based similarity
As we do for text, we want to identify more than just identical images, but rather
also those that have been somewhat transformed. Typical image transformations likely
in a publishing scenario include the following:
Rescaling
Occlusion (a portion of the image is blocked or covered)
Color remapping
Cropping
Translation
Rotation or mirror Image
The following sections describe approaches to account for some of these image transformations,
including normalizing for color and scale, and constructing tiled image descriptors
to deal with translation and occlusion. While rotation was outside the scope of this
pilot project, we do discuss techniques that would be used to detect 90-degree rotations
for image similarity matching. We’ll see that a strong, robust image similarity detection
system needs to rely on multiple techniques.
Perceptual Hashing
A powerful group of techniques that we focused on for this pilot is Perceptual Hashing.
Hashing is a general technique that maps data of arbitrary size to data of fixed size,
which is called the hash value. Different types of hashing perform different purposes.
For example, with cryptographic hashing, even small differences in the input data
results in a vastly different hash value. If a file has the same hash value, it means
it almost certainly wasn’t altered. That would be a good approach to identify identical
images, but won’t help with similar images.
Perceptual hashing has the opposite goal, which is that similar images have similar
hash values. It is designed so that even somewhat large differences in the input data
will have only minimal effect on the hash value. That means someone may alter an image
without changing its perceptual hash value very much.
Perceptual Hashing has several properties that make it ideal to be part of an image
similarity detection system. It is very fast – once the hash value is calculated,
it can be compared to the hash values of stored images at a rate of several million
images per second. It is completely scale invariant – changing the height, width,
or DPI of an image makes it no harder to detect. It is resistant to occlusion – a
large portion of an image would need to be covered for it to affect the similarity
results, and is not affected by most color re-mappings.
The various Perceptual Hashing algorithms convert an entire image into a hash value
and then compare this value to the hash values of other images. The closer the two
hash values are to each other, the closer the images should be perceptually. When
two images are very similar to each other, most of the bits in their respective hash
values will be identical. The more bits they differ on, the more different the images
will appear. Calculating the hash value itself can be done fairly quickly, with the
first step being the slowest.
The following outlines the steps of the Average Hash, a simple form of Perceptual
Hash which uses a 64-bit hash value:
Rescale an image so that it has a height of 8 pixels and width of 8 pixels;
Convert each of those 64 low resolution pixels to grayscale;
Calculate the average value of the 64 grayscale pixels;
Compare each of the 64 grayscale pixels to their average;
If they’re equal/above average, set them to 1; If they’re below average, set them
to 0;
Bitpack the 64 bits into a 64-bit integer that serves as the hash value;
Compare this 64-bit hash value to the 64-bit hash value of other images;
Comparison is determined by XORing them – counting the number of bits that differ;
The lower the number, the more likely it is that these images are similar.
There is no one ideal Perceptual Hashing function; the various hashing algorithms
make different assumptions about the nature of the image and the transformations that
were done to permute the image. One algorithm that we’ve found to be very effective
is the Difference Hash. Rather than compare each of the 64 low resolution pixels to
the average value, it compares each of them to a neighbor. This captures the gradient
difference between the neighboring values and ignores any changes that may have affected
the average. Another algorithm that we’ve found to be effective is DCT Hash, which
uses the DCT (Discrete Cosine Transform) coefficients of a low resolution image. DCT
is used for JPEG image compression because it models color images very well. That
same modeling can be used to capture high level information about an image that can
be used for Perceptual Hashing. While it runs a bit slower than other Perceptual Hashing
algorithms, and it performs poorly on Black and White images, it does an excellent
job on most color images. By combining and weighting multiple Perceptual Hashes, we
can quickly and effectively find the closest perceptual matches across a range of
images and transformations. Fortunately, Perceptual Hashing is fast, allowing you
to use several of them, thereby getting more robust results.
There are certain image transformations that Perceptual Hashes have difficulty with.
For example, a rotated or mirror image file will not score well when compared to its
original. A possible approach would be to process eight 64-bit integers for each image
(the original, rotated 90 degrees to the right, rotated 90 degrees to the left, and
upside down, and then the mirror image, which is also then rotated three different
ways). Each of these values can be found by simply rearranging the order of the bits
in the hash value. This method won’t help with smaller rotations, such as 10 or 20
degrees. That is why the production-level system would also need other, rotationally
invariant methods that can detect small rotations, in combination with Perceptual
Hashing algorithms.
The Pilot System
To demonstrate the effectiveness of Perceptual Hashing, we developed a pilot program
using image data provided by IEEE (Institute of Electrical and Electronics Engineers).
We used a collection of 10,000 images coming from 1,400 technical papers. Our test
system allows a user to upload a batch of images and runs the comparison software
against the database, returning candidate matches, along with thumbnails and scores.
The lower the score, the more likely the match, with zero being an almost certain
match. We can set a score threshold to limit the number of matches provided.
As a first test, we matched these 10,000 files against each other, to see how often
they found matches. The code ran very quickly. On average it took less than 0.25 seconds
to generate the 64-bit integers for the three perceptual hashes we used, and we were
able to compare the image to the stored values at a rate of 8 million images/second.
As expected, there were papers that contained images that were similar to each other.
In fact, in our relatively limited test set, whenever an image found a matching image,
it almost always was from the same paper. For example, Figure 3 shows two images from the same paper that are nearly identical. They had a score
of 2, where 0 would be identical.
Figure 4 shows two files from the same paper that were a bit further apart, with a score of
12.
Figure 4: Very similar images (variance score = 12)
Images reprinted with permission of IEEE
And lastly, Figure 5 and Figure 6 show two sets of files that differed even more. They both had a score of 20, which
was low enough to be a possible match.
Figure 5: Somewhat dissimilar images, but with similar color schemes (variance score = 20)
Images reprinted with permission of IEEE
Figure 6: Somewhat dissimilar images, but with similar color schemes (variance score = 20)
Images reprinted with permission of IEEE
The above images help illustrate an important point about image similarity metrics.
There is no single score that measures the full perceptual difference between two
files. When Perceptual Hashing gives a very low score to two images, there is a very
high likelihood that they are similar. As the score increases, the likelihood of similarity
declines, and when it is above a certain score the risk of a match becomes minimal.
There will always be cases, though, where people disagree on how similar the images
are, and no algorithm can give an authoritative answer. Perceptual Hashing gave these
images a low enough score that a human would want to investigate them, even if they
ultimately feel the images differ.
On-line Portal
In order to facilitate user testing, we provided a user interface allowing a user
to upload a batch of images; these image batches are processed against the entire
database and the resulting “candidate matches” returned to the user. The computed
match scores are provided; the lower the number, the more likely the match.
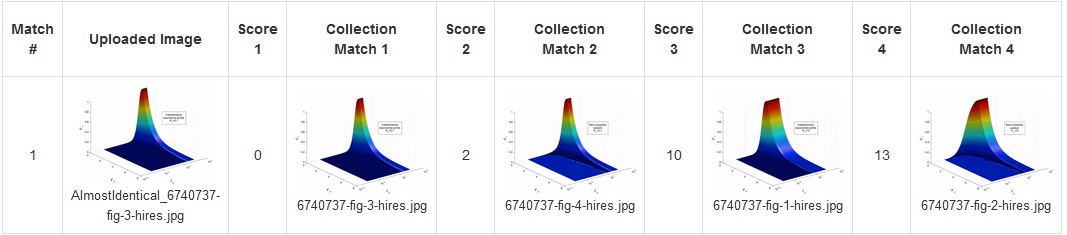
Figure 7 shows an instance of example output. The first image is the uploaded image, and the
system identified the four most likely matches. The first matched image, with a score
of zero, is the identical image; the next three images have minor variations, with
progressively higher scores of 2, 10, and 13.
Figure 7: Sample Output Instance
Next Steps
The purpose of this pilot was to investigate the feasibility of identifying “similar
images” against an image database in order identify plagiarized images, and to determine
if there is broad interest in such a capability. The pilot project has shown feasibility,
and we are looking into the possibility of building the scaled-up, production level
system. The next steps would be to:
Enhance the matching process by layering additional algorithms to overcome the limitations
discussed above
Tuning the algorithms to more clearly differentiate false positives and streamline
the review process
Scale up the infrastructure to accommodate multi-million image production databases.
The capabilities shown in this pilot project can have broad implication not just in
identifying plagiarized images, the focus of this study, but also in other applications
where there exists a need to find matching images in large databases and in the big
data world. We foresee that further expansion of the capabilities investigated here
can lead to sophisticated image search tools paralleling the very sophisticated tools
now available for text search and analytics.