Haentjens Dekker, Ronald, and David J. Birnbaum. “It's more than just overlap: Text As Graph.” Presented at Balisage: The Markup Conference 2017, Washington, DC, August 1 - 4, 2017. In Proceedings of Balisage: The Markup Conference 2017. Balisage Series on Markup Technologies, vol. 19 (2017). https://doi.org/10.4242/BalisageVol19.Dekker01.
Balisage: The Markup Conference 2017 August 1 - 4, 2017
Balisage Paper: It’s more than just overlap: Text As Graph[1]
Refining our notion of what text really is—this time for sure!
Ronald Haentjens Dekker
Head of Research and Development and Software Architect
Ronald Haentjens Dekker is a software architect and consultant at the Huygens
Institute for the History of the Netherlands. As a software architect, he is responsible
for translating research questions into technology or algorithms and explaining to
researchers and management how specific technologies will influence their research.
He has
worked on transcription and annotation software, collation software, and repository
software, and he is the lead developer of the CollateX collation tool. He also conducts
workshops to teach researchers how to use scripting languages in combination with
digital
editions to enhance their research.
David J. Birnbaum
Professor and Chair
Department of Slavic Languages and Literatures, University of Pittsburgh
David J. Birnbaum is Professor and Chair of the Department of Slavic Languages and
Literatures at the University of Pittsburgh. He has been involved in the study of
electronic text technology since the mid-1980s, has delivered presentations at a variety
of electronic text technology conferences, and has served on the board of the Association
for Computers and the Humanities, the editorial board of Markup
languages: Theory and practice, and the Text Encoding Initiative Council.
Much of his electronic text work intersects with his research in medieval Slavic
manuscript studies, but he also often writes about issues in the philosophy of
markup.
The XML tree paradigm has several well-known limitations for document modeling and
processing. Some of these have received a lot of attention (especially overlap), and
some
have received less (e.g., discontinuity, simultaneity, transposition, white space
as
crypto-overlap). Many of these have work-arounds, also well known, but—as is implicit
in the
term “work-around”—these work-arounds have disadvantages. Because they get the job
done,
however, and because XML has a large user community with diverse levels of technological
expertise, it is difficult to overcome inertia and move to a technology that might
offer a
more comprehensive fit with the full range of document structures with which researchers
need to interact both intellectually and programmatically. A high-level analysis of
why XML
has the limitations it has can enable us to explore how an alternative model of Text
as
Graph (TAG) might address these types of structures and tasks in a more natural and
idiomatic way than is available within an XML paradigm.
The XML tree paradigm has several well-known limitations for document modeling and
processing, some of which have received a lot of attention (especially overlap; see
the
overviews in Sperberg-McQueen and Huitfeldt 2000 and DeRose 2004) and
some of which have received less (e.g., discontinuity, simultaneity, transposition,
white
space as crypto-overlap). Many of these have work-arounds, also well known, that—as
is
implicit in the term work-around—have disadvantages, but because they get the
job done and because XML has a large user community with diverse levels of technological
expertise, it is difficult to overcome inertia and move to a technology that might
offer a
more comprehensive fit with the full range of document structures with which researchers
need
to interact both intellectually and programmatically. Proceeding from a high-level
view of why
XML has the limitations it has, this presentation explores how an alternative model
of Text as
Graph (TAG) might address these types of structures and tasks in a more natural and
idiomatic
way than is available within an XML paradigm.
From an informatic perspective all documents are structured, including those that
are
traditionally identified as plain text. Some of the structural properties of plain-text
documents are expressed through formatting conventions, such as the use of blank lines
to
separate paragraphs, or of indentation to mark the beginning of a paragraph, or of
centering
to mark a header. The sequence of words in a text, delimited in a complex way that
involves
white space, punctuation, and other symbols, constitutes, on a certain level, an implicit
organizational tier above the sequence of characters.[2] The conventions at work in plain text do not formally, completely, unambiguously,
or in a wholly standardized way differentiate the content of a document from the coded
representation of its structure (or, perhaps more accurately, structures), which problematizes
using plain text for document processing (whether for data mining, publication, or
other
purposes). The challenges this poses have come to be addressed by representing the
structural
properties of a document not through plain-text characters (which might be considered
pseudo-markup), but through formal, standardized markup, such as XML.
The XML data model is an ordered tree, or, more precisely, a rooted and ordered directed
acyclic graph that prohibits multiple parentage, which in the document-processing
community
has come to be understood as representing an Ordered Hierarchy of Content Objects
(OHCO). It
is well known that the OHCO model works reasonably well for describing structures
that consist
of single ordered hierarchies, such as the exhaustive tesselated division of a novel
into
chapters and the chapters into paragraphs, but it is not well suited to modeling structures
that cannot be represented fully by a single tree.[3] The markup community has focused intensively on overlapping hierarchies as a
challenge to the OHCO model,[4] and with good reason, but we argue below that overlap is only one manifestation of
a higher-level problem, and this perspective has implications for deciding how best
to
overcome it. If overlap were the problem, projecting multiple
trees over the content might solve it (e.g., through the SGML CONCUR feature[5]), as might the adoption of a model that permits but does not require hierarchy,
including multiple hierarchies, such as the range model exemplified by LMNL.[6] But if the problem is that a tree is inadequate for higher-level reasons that are
only partially exemplified by overlap, we might have more success if we address the
issue at
that higher level. The Text As Graph model that we introduce below is not intended
to be a
solution to the overlap problem in XML; it is built around a fresh
consideration of the textual structures, both latent and overt, that a data model
will need to
be able to represent. It is nonetheless not accidental that TAG agrees in some respects
with
XML, in others with GODDAG or TexMECS, and in others with LMNL, since all of these
specifications have sought, in partially converging ways, to model text structure.[7]
Below we identify specific situations that pose problems for an OHCO perspective.
With
respect to hierarchy, in addition to overlap, where text may have multiple overlapping
hierarchies, text may not be hierarchical at all. We also identify situations where
text is
not ordered, as well as those where XML creates artifactual content objects that do
not
clearly correspond to what a human would consider a textual content object. In other
words,
TAG seeks to interrogate and address the O, the H, and the CO of OHCO, and not only
the
well-known multiple-hierarchy challenge.
The Text As Graph (TAG) data model consists of a directed property hypergraph for
modeling text, markup (roughly comparable to XML elements), and annotations (roughly
comparable to what XML attributes would be like if they could contain markup, including
attributes on attributes). A hypergraph consists of a set of nodes and a set of edges
and
hyperedges. Nodes and (hyper)edges may have properties, including type (see,
for example, the four types of nodes listed below).
Graph models for text and markup have been proposed before (GODDAG [see, e.g., Sperberg-McQueen and Huitfeldt 2000], GrAF [see, e.g., Ide and Suderman 2007]), but
the model advanced in this paper differs from those because it incorporates a hypergraph [Hypergraph: Wikipedia]. Hypergraphs are
especially valuable for text modeling because they can be implemented using sets,
and
methods for reasoning over and operating on sets are proven and well known [Set: Wikipedia]. Hypergraphs differ from traditional graphs, the edges of which can
connect only two nodes with each other, because the edges in a hypergraph can connect
more
than two nodes with one another, and for that reason they are called hyperedges. Hypergraphs can have directed and undirected hyperedges, and TAG
uses only directed hyperedges, which assert a directed relationship between two non-empty
sets of nodes, one for the source (called the head) and one
for the target (called the tail). As we explain below, in
the TAG model, the directionality of a hyperedge may be used for purposes other than
modeling an order or a hierarchy of the nodes.
Like LMNL and GODDAG, both of which are discussed in more detail below, and unlike
XML,
TAG is defined as a data model, rather than by its syntax. At present TAG does not
have its
own syntactic representation.
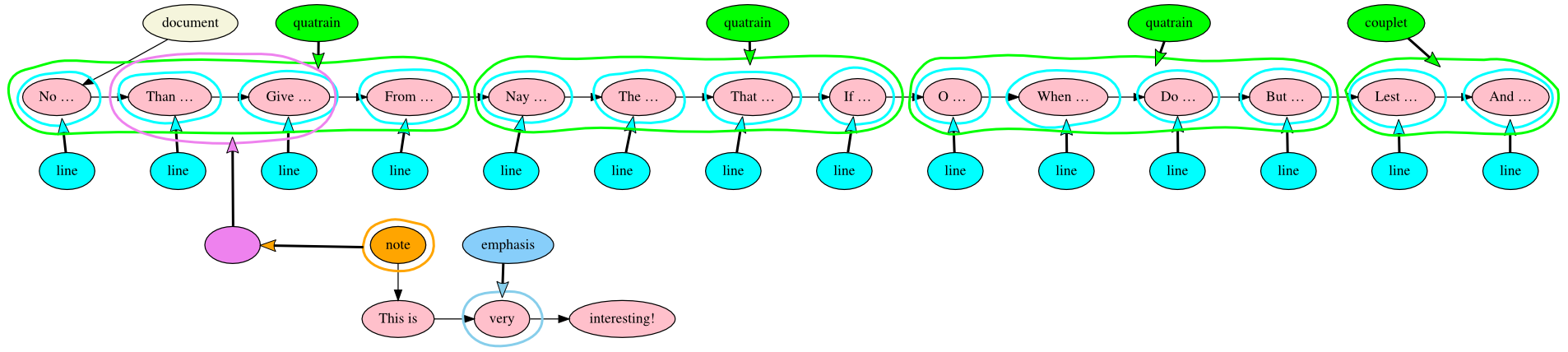
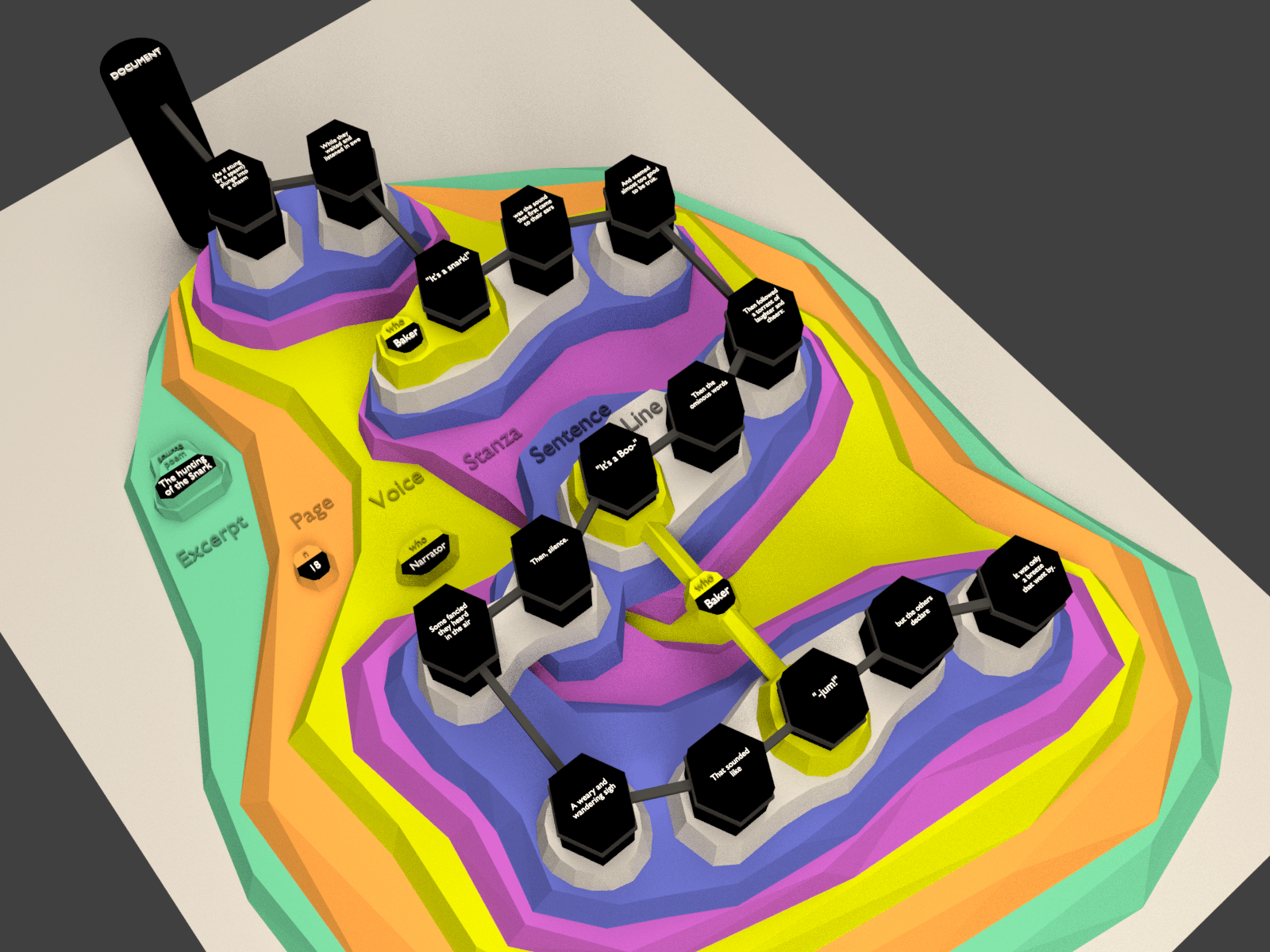
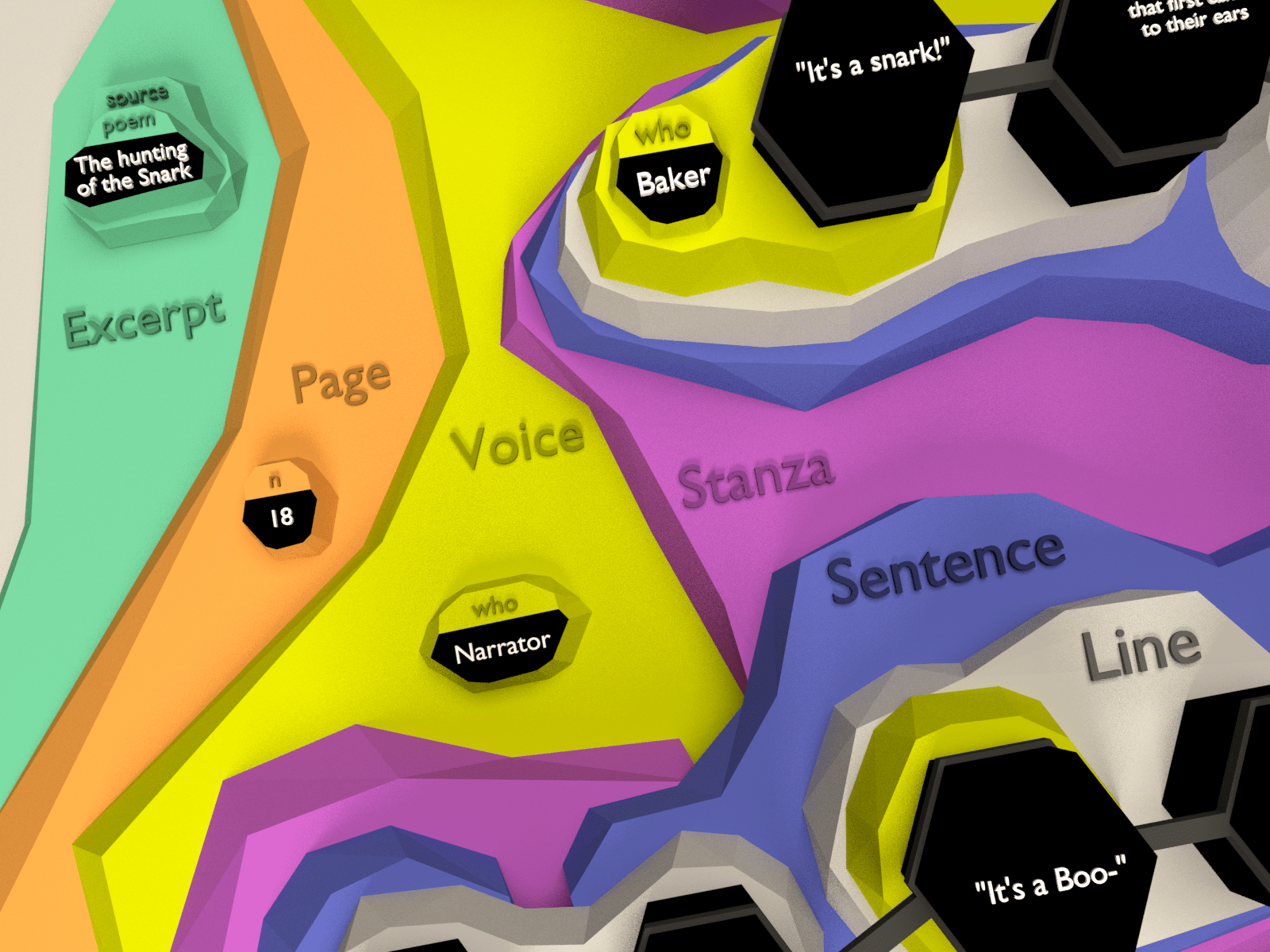
TAG example
Figure 1: William Shakespeare, Sonnet 71
The Document node is beige, the Text nodes are pink, and the Markup nodes are green
(those with the name property value of quatrain or
couplet) and cyan (those with the name property value of
line). A chain of regular (one-to-one) edges, represented by solid
black arrowheads, begins at the Document node and connects the Text nodes in order.
Text
nodes in this case are entire lines of text, but they could also be smaller units;
see
the discussion of Overlap, below. There are additional whitespace-only Text nodes
between the lines, but these have been omitted here to reduce the complexity of the
diagram.
The illustration of a TAG hypergraph of William Shakespearea’s Sonnet 71 (Appendix A), above, includes a Document node, fourteen Text nodes (as
noted above, there are also white-space-only Text nodes between the lines, but these
have
been omitted here to reduce the complexity of the diagram), and eighteen Markup nodes
(fourteen with their name property value equal to line, three to
quatrain, and one to couplet). Regular (one-to-one) edges
start at the Document node and chain all Text nodes in textual order. Hyperedges point
from
the Markup nodes into sets of Text nodes. In this case, hyperedges that start in Markup
nodes with the name property of line happen to point to a set
that consists of a single Text node, and those with name property values of
quatrain and couplet happen to point to sets of four and two
Text nodes, respectively. Note that in TAG, in contrast to XML, a Markup node corresponding
to the XML root element, although permitted, is not required, and we’ve omitted it
here.
Also in contrast to XML, the quatrain and couplet Markup nodes
point directly to the Text nodes, and not to line Markup nodes (although
that, too, is possible; see the discussion of hierarchy below).
How TAG represents selected structural properties of text
This section describes in an introductory way how TAG represents order, textual content,
markup, overlap, and discontinuity. Some of these issues are taken up in more detail
later,
after we introduce the types of nodes, edges, and hyperedges that make up the TAG
model of
text.
Order
A distinctive feature of the TAG model is that textual content is an ordered set of
Text nodes, but Markup and Annotation nodes are not ordered. Because Markup nodes
all
point directly or through intermediaries to Text nodes, to the extent that Markup
nodes
might be said to have order, their order is only a derived property of the order of
the
Text nodes to which the markup applies.[9] This bottom-up perspective on order within a document distinguishes TAG from
the top-down, ordered-tree perspective of XML and GODDAG, where, contrary to TAG,
the
order of nodes (including Text nodes) is derived, through depth-first traversal, from
the
order of their parent nodes.[10] In this respect TAG is closer to LMNL, where order in the document also
inheres at the lowest level, which in LMNL is start position of a range in the sequence
of
atoms that make up the content.[11]
Textual content
Textual content in TAG is expressed by nodes with a type value of text, each of which represents a segment of
textual content (Text nodes may also be empty). The order of the text is stored as
directed regular (one-to-one) edges between pairs of Text nodes; this chain begins
at the
Document node, which points to the first Text node, and a single, unbroken chain connects
all Text nodes in the document except those in annotations.[12] Annotations (see below), which typically encode metadata, can be understood as
ancillary documents, and their textual content is modeled as separate chains that
begin at
the Annotation node.
Markup
Markup in XML serves four purposes simultaneously: containment, dominance (hierarchy), datatyping, and
order. In XML, an ancestor element both contains (starts before and ends after) its descendants and
dominates them (is connected to them by a path that
travels only downward in the tree). An XML element specifies a type (through the generic identifier), and it instantiates order because XML is defined as an ordered tree of nodes,
including element nodes.
TAG separates these four functions. As described above, order in TAG is a property only of Text nodes. Containment is modeled by subset relations that are independent of any
hierarchy; it is axiomatic that a superset (of Text nodes) contains all of its proper subsets. Datatyping is implemented through Markup-to-Text hyperedges that point from
a Markup node to a set of Text nodes, where the Markup node has a name
property, the value of which is comparable to the generic identifier (name) of an
XML
element. Unlike in XML, however, Markup-to-Text hyperedges do not model hierarchy;
their
only function is datatyping (and, through subset relations of their tails, containment).
Because Text nodes can have multiple incoming hyperedges on them, textual content
can have
multiple markup on it, and because Markup-to-Text hyperedges do not form a tree, that
situation does not engender overlap concerns. Annotations on Markup nodes provide
supplementary information (metadata) about the node, similarly to attributes in XML,
except that in TAG, as in LMNL, annotations can have rich content, and are not limited
to
just a name and an atomic value. As in XML and unlike in LMNL, annotations on a Markup
or
Annotation node in TAG are unordered.
In TAG, as in LMNL, a document is not required to express a hierarchy. Where dominance
relations must be modeled, TAG uses Markup-to-Markup hyperedges to implement a hierarchy.
The fact that hierarchy is optional is an important distinction from XML (single
hierarchy) and GODDAG (one or more hierarchies).
Markup nodes do not contain other Markup nodes; Markup nodes identify (point to) sets
of Text nodes, and the Text nodes may participate in subset relationships with one
another. This means that in TAG it is not meaningful to ask whether a single set of
Text
nodes identified with one Markup node as a paragraph and with a different Markup node
as a
quotation represents a paragraph that consists of a quotation or a quotation that
consists
of a paragraph. Where the hierarchy of coextensive paragraphs and quotations matters,
the
relationship may be modeled, but as one of dominance (hierarchy), rather than of
containment.
The separation of these four functions means that a Markup node provides datatyping
through its name property, although this property is optional (see the
discussion of Scope of reference, below). Because the tail of a Markup-to-Text hyperedge
is a non-empty set of Text nodes, and Text nodes are ordered and have intrinsic subset
and
other interrelationships, markup may also specify order and containment, but only
indirectly. The specification of dominance is optional, and is entirely a property
of
Markup nodes.
Overlap and self-overlap
Overlap between the Text node tails of two or more Markup-to-Text hyperedges does
not
require a special construction in TAG. Each Markup-to-Text hyperedge points to a set
of
Text nodes, and those Text node tails may or may not overlap with one another. In
the
set-based terminology of TAG, overlap describes a relationship between sets where
there is
a non-empty intersection and neither set is a subset of the other. In this respect,
overlap of sets of Text nodes in TAG is similar to the LMNL overlap of ranges of atoms
(but see immediately below about discontinuity). Self-overlap (in XML terms, overlap
that
involves two elements with the same generic identifier) is not a special case in TAG
because two Markup nodes with the same name property (datatype) each is the
head of its own hyperedge. Overlap in TAG, as in LMNL, is a matter of containment,
rather
than of dominance. The GODDAG developers have identified the importance of the difference
between containment and dominance [Sperberg-McQueen and Huitfeldt 2000, Sperberg-McQueen and Huitfeldt 2008a, Sperberg-McQueen and Huitfeldt 2008b], while
in XML the two are not distinct.
Discontinuity
In XML, GODDAG, and LMNL, discontinuity is expressed with more than one element
(XML/GODDAG) or more than one range (LMNL), and the fact that the discontinuous parts
(with respect to hierarchical or linear structure) form a whole must be encoded
separately. That would then require subsequent reunification, higher in the hierarchy
in
GODDAG, and in the limen and with coindexed annotation values in LMNL.[13] In TAG, discontinuity in the Text nodes that constitute the tail of a
Markup-to-Text hyperedge is modeled exactly the same way as continuity because the
Text
nodes are not required to be continuous. This means there is only one Markup node
for all
the Text nodes in an instance of discontinuous markup, and no obligatory partitioning
into
segments is needed. TexMECS syntax is capable of modeling discontinuity directly with
suspend-tags and resume-tags [Huitfeldt and Sperberg-McQueen 2003 §2.2.4], but if a TexMECS
document is to be parsed into GODDAG, the fragments are modeled as separate structural
components, and the difference between GODDAG and XML in this respect is that because
GODDAG permits multiple parentage, it is possible to create an additional parent node
for
the fragments. TAG, then, views fragmentation that must be reunited as an undesirable
side-effect of the XML, GODDAG, and LMNL models, and regards linearly discontinuous
content as a single item that may be separated when necessary, such as for serialization
in LMNL sawtooth syntax, rather than as two objects that may be united when necessary.[14]
TAG components
Nodes
The following types of nodes are supported by TAG:
Document nodes. Each Document node represents a
single document.[15] It is connected by a regular edge to the first Text node in the
document. Document nodes have no properties other than the type
property value of document.
Text nodes. The textual content of a TAG
document is stored in one or more Text nodes, roughly comparable to XML Text nodes.
The order of the Text nodes is represented by directed edges that connect them in
textual order.[16] The first Text node can be recognized because there is a link to it from
the Document node. The value of a Text node is the text it represents,
comparable to the string value of an XML Text node. Text nodes in TAG may be empty;
pointing from a Markup node to an empty Text node provides functionality comparable
to that of empty elements in XML.[17]
The simplest TAG document has only a Document node and a single Text node. The
text of the document is subdivided into Text nodes to support their association with
different Markup nodes. As in the XML tree, TAG Text nodes are made up of
characters, but the characters are not types in the TAG data model, and TAG has no
counterpart to LMNL atoms.[18]
Markup nodes. Markup nodes correspond roughly
to element nodes in XML, and each instance of markup is represented by its own node.
The only property of a Markup node is a name, which is analogous to the
XML generic identifier, but TAG also permits anonymous Markup nodes, much as LMNL
permits anonymous annotations (see below, under Scope of reference, for an example
of how these might be used). Markup nodes are connected to one or more Text nodes
by
a hyperedge, where the Markup node is the head and a set of Text nodes is the tail.
There is no requirement that the Text nodes in the tail of a Markup-to-Text
hyperedge be contiguous.
Annotation nodes. Annotation nodes represent
metadata about the targets of Markup nodes, and are thus similar to the way
attributes represent properties of elements in XML. The name property
of an Annotation node is analogous to the name of an XML attribute. As with LMNL
annotations and unlike XML attributes, Annotation nodes may have content that
includes markup, there may be annotations on annotations, and there may be multiple
annotations with the same name on a single Markup or Annotation node. Unlike LMNL
but like XML attributes, annotations are unordered (but if they contain Text nodes,
those are connected by regular, one-to-one edges that form them into a chain,
beginning at the Annotation node). The Shakespearean sonnet example above does not
contain any Annotation nodes.
Edges and hyperedges
Overview
The following edge relationships are supported by the model. All edges are directed;
some are regular (one-to-one) edges and others are hyperedges. By definition, a directed
hyperedge points from one non-empty set of nodes (the head) to another non-empty set
of
nodes (the tail). In TAG, all hyperedges have exactly one node in the head and one
or
more nodes in the tail except for Annotation-to-Markup hyperedges, which have one
or
more nodes in the head and exactly one node in the tail. Edges and hyperedges in a
hypergraph may have properties, although TAG does not at present make use of them.[19]
Edges that express order
Text nodes are ordered with the following regular (one-to-one) edge relationships,
and constitute the only ordered sets in TAG:
Text-to-Text directed edges. Text nodes are
connected with directed edges, which chain and therefore order them, so that the
linear order of the text is preserved. In the Shakespearean sonnet example above,
Text-to-Text directed edges point from the first Text node to the second, from the
second and third, etc., until the end of the text.
Document-to-Text directed edges. A
Document-to-Text directed edge points from the Document node to the first Text
node contained in that document. In the Shakespearean sonnet example above, a
single Document-to-Text directed edge points from the Document node to the first
Text node, which in this case represents the first line of the poem.
Annotation-to-Text directed edges.
Annotations can be conceptualized as ancillary documents, and, like documents,
they may contain text, which is represented as a chain of Text nodes. Analogously
to the use of a Document-to-Text directed edge to point to the first Text node in
the main document, an Annotation-to-Text directed edge points from an Annotation
node to the first Text node contained in that annotation. This Text node is part
of the Text of the annotation, and not of the Text being annotated. Separating the
Text nodes in the document from those in the annotations is comparable to the fact
that the values of attributes in XML are not part of the string value of the
document. Text in an annotation, like the main document text, may be marked up
with Markup nodes, which is to say that the Text nodes of an annotation may serve
as the tail of the Markup-to-Text hyperedges described below.
Hyperedges that specify and type sets of Text nodes
Markup-to-Text directed hyperedges.
Markup-to-Text hyperedges connect a single Markup node (head) to a set of Text
nodes (tail). In the Shakespearean sonnet example above, fourteen Markup-to-Text
hyperedges each point from a single Markup node with a name property
value of line to a set of one Text node, three Markup-to-Text
hyperedges with a name property value of quatrain each
point to a set of four Text nodes, and one Markup-to-Text hyperedge with a
name property value of couplet points to a set of
two Text nodes. Note that the quatrain and couplet
Markup nodes point to Text nodes, and not to the line Markup nodes
(although Markup-to-Markup hyperedges can be added if that is needed). This is an
important difference from the XML tree structure, where Text nodes would be the
children of <line> elements, but not of the
<quatrain> and <couplet> elements.
Hyperedges that express targets of annotation
Annotation-to-Markup directed hyperedges.
Annotation-to-Markup directed hyperedges point from a set of Annotation nodes to
the Markup node that they are annotating.
Annotation-to-Annotation directed hyperedges.
These make it possible to add annotations to annotations, that is, to represent
metadata about annotations. This feature is borrowed from LMNL. As with
Annotation-to-Markup hyperedges, the head is the set of annotations being added,
and in this case the tail is the Annotation node (rather than Markup node) to
which they are being added.
Hyperedges that express dominance
Markup-to-Markup directed hyperedges.
Markup-to-Markup hyperedges connect a single Markup node (head) to a set of Markup
nodes (tail). The Shakespearean sonnet example above does not include any
Markup-to-Markup hyperedges, but if we wished to encode, for example, that a
quatrain dominates its lines hierarchically, and does not merely contain their
Text nodes, we could express that with a Markup-to-Markup hyperedge between a
quatrain Markup node (head) and its four line
Markup nodes (tail).
Constraints
Only the following types of edges are permitted:
Table I
Head
Document
Text
Markup
Annotation
Tail
Document
-
-
-
-
Text
edge
edge
hyperedge
edge
Markup
-
-
hyperedge
hyperedge
Annotation
-
-
-
hyperedge
An implementation must raise an error if:
a document contains any type of node, regular (one-to-one) edge, or hyperedge
not included in the preceding table
a document does not have a single Document node, which points to a single Text
node
a document does not have at least one Text node
a Document node points to anything other than a single Text node
a Text node points to anything other than another single Text node
there is not exactly one Text node in the main text and in the text of every
annotation that does not point to another Text node, except that an Annotation is
not required to have text.
two contiguous Text nodes are in the tail of all of the same Markup-to-Text hyperedges[20]
a regular (one-to-one) edge from an Annotation node points to anything other
than a single Text node
a Text node is not part of a continuous chain that begins at a Document node or
Annotation node
a Markup node is the head of more than one Markup-to-Text hyperedge or more than
one Markup-to-Markup hyperedge[21]
a Markup-to-Text hyperedge has anything other than a single Markup node in its
head and anything other than a non-empty set of Text nodes that are in the same
chain (but not necessarily contiguously) in its tail
a Markup-to-Markup hyperedge has anything other than a single Markup node in its
head and anything other than a non-empty set of Markup nodes in its tail
the head of a hyperedge contains anything other than a single Markup node
(Markup-to-Text or Markup-to-Markup hyperedge) or a non-empty set of Annotation
nodes (Annotation-to-Markup hyperedge)
the tail of a hyperedge contains anything except a non-empty set of Text nodes
(Markup-to-Text hyperedge), a non-empty set of Markup nodes (Markup-to-Markup
hyperedge), or a single Markup or Annotation node (Annotation-to-Markup and
Annotation-to-Annotation hyperedge)
the head of a regular edge is anything other than a Document node, Annotation
node, or Text node
the tail of a regular edge is anything other than a Text node
the head or tail of a hyperedge is empty or contains nodes that are not all of
the same type
any two edges or hyperedges have the same type, the same head, and the same
tail
an Annotation node does not have a name
Challenges for text modeling
In this section we illustrate several types of textual structures that have proven
awkward
for XML because they contradict or otherwise are not part of the OHCO tree model.
For each we
provide an abstract description of the problem, of one or more XML workarounds, and
their
GODDAG, TexMECS, and LMNL counterparts (as appropriate), illustrated with examples
drawn from
use cases in Digital Humanities research projects.
Overlap
The challenge to text modeling in XML that has attracted the most attention is overlap.
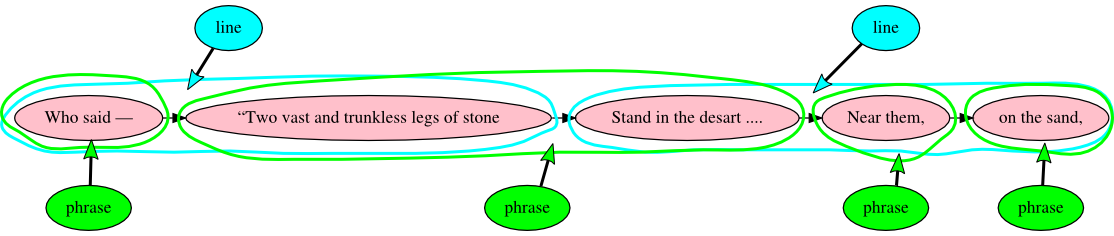
For example, notice in the image below how the phrase Two vast and trunkless legs of
stone Stand in the desart begins in the middle of line 2 and ends in the middle of
line 3, an absence of synchronicity between verse lines and sentences that is called
enjambment.[22] :
Piez’s illustration is actually of LMNL ranges, rather than of XML element trees.
The
same structure might be visualized as independent overlapping trees as follows, where
cyan
represents the tree of metrical lines and green represents the tree of linguistic
phrases:
Figure 3: Percy Bysshe Shelley, Ozymandias
Projecting two independent trees over a common set of words. In XML the individual
words would not be children of <line> and <phrase>
elements, and would instead be grouped inside Text node children of those
elements.
Because it is not possible to represent the preceding structure in XML markup, the
following pseudo-XML is not well-formed:
<line><phrase>Who said —</phrase> <phrase>“Two vast and trunkless legs of stone</line>
<line>Stand in the desart….</phrase> <phrase>Near them,</phrase> <phrase>on the sand</phrase></line>
New XML users often misunderstand the prohibition against overlap as a prohibition
against overlapping tags, but if that were the entire
issue, it could be remedied by simply removing the syntactic prohibition. But the
rule about
tags exists because tags must represent a tree, hierarchy in a tree prohibits multiple
parentage, and overlap would permit a node to have more than one parent. Overlap is
possible
in GODDAG only incidentally because TexMECS permits overlapping tags; at a higher
level it
is because GODDAG permits Text nodes to have multiple parents and TexMECS serializes
the
GODDAG model. LMNL sawtooth syntax may look like XML syntax with the prohibition against
overlapping tags removed, but the real difference is at the level of the data model:
LMNL
ranges can overlap and XML elements cannot because the content between XML start and end tags is a
sequence of descendant nodes in a tree, and not a range of textual atoms.
TAG represents overlap naturally because the TAG counterpart to an XML element is
a
directed hyperedge that associates a head Markup node with a set of tail Text nodes.
To tag
a line of poetry in the example above, TAG would create a hyperedge from a Markup
node with
the name property value of line (comparable to a
<line> element in XML) to a set of Text nodes (comparable to Text nodes
in XML). Sets are unordered, but because the TAG model requires sequence
edges between Text nodes, which record the continuous order of the text stream (comparable
to the sequence of atoms in the LMNL model), the textual content of the line is fully
specified by (= can be retrieved by examining) the membership of the set of tail Text
nodes
and the sequence edges between them. In the illustration below, the black arrows represent
regular edges that connect Text nodes in order, the irregular colored bounding lines
demarcate the sets of tail Text nodes, and a similarly colored arrow points into them
from
their Markup node heads:
Figure 4: Percy Bysshe Shelley, Ozymandias
A hypergraph representing overlap of phrases and metrical lines.
Additional use cases involving overlap challenges in XML include pages vs paragraphs
in
publications of novels, folios vs texts in medieval manuscripts, and speeches vs metrical
lines in drama. Overlap in poetic structures has been explored in detail in Piez 2014, which also discusses an unusual structural paradox involving
Chapter 24 of Mary Shelley’s Frankenstein. Overlap
involving word and metrical foot boundaries in poetry is discussed below.
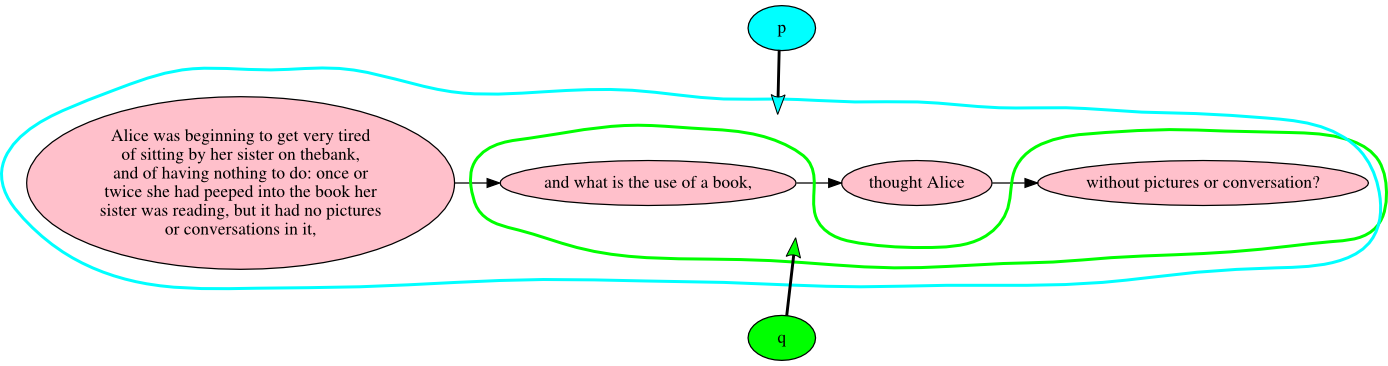
Alice was beginning to get very tired of sitting by her sister on the bank, and of
having nothing to do: once or twice she had peeped into the book her sister was reading,
but it had no pictures or conversations in it, and what is the use of a
book, thought Alice without pictures or conversation?
There is no way to mark up this passage in XML without fragmenting the quotation into
two elements (and relying on semantics to stitch together the pieces in the application
layer), yet our human intuition is that there is a single quotation, and that the
model,
therefore, should represent it as a single object.[23] As Sperberg-McQueen and Huitfeldt 2008b also observe, there is a sense in
which book and without are adjacent and a different sense in
which book and thought are adjacent. XML syntax and the XML
tree cannot represent both of these realities simultaneously, which means that at
least one
of them must be handed off to the application layer.
Sperberg-McQueen and Huitfeldt 2008b situate this type of structure in a GODDAG
context, where it intersects with the distinction between containment and dominance. Concerning LMNL,
they write that
[With respect to] the unity of discontinuous elements: such a unity may be asserted
by
the application layer (that is, by the definition of a LMNL vocabulary), but it is
not
visible on the LMNL level, and thus need not be accounted for at the level of LMNL
itself.
The design of LMNL thus seems to require that any account of dominance (as distinct
from containment), and any account of discontinuous elements, be handled in the
application layer. LMNL itself achieves a degree of simplicity and regularity as a
result,
at the expense of complexity in the application.
Piez 2008 describes discontinuity in LMNL as modeled by the limen, where the example provided
(http://piez.org/wendell/LMNL/Amsterdam2008/presentation-slides.html#page23)
records it through coindexed annotations. That dependency seems to locate discontinuity
in
an application layer, since whether coindexed annotations represent discontinuity
is not an
inherent property of the coindexing. As was noted earlier, TexMECS is capable of modeling
discontinuity directly with suspend-tags and resume-tags, but if a TexMECS document
is to be
parsed into GODDAG, the fragments are then modeled as separate structural components
TAG prioritizes the representation of text structures, including discontinuity, in
the
model, without dependency on application-layer semantics. The example from Alice in Wonderland described above would have the following form
in TAG:
Figure 5: Lewis Carroll, Alice in Wonderland
Each hyperedge points from a Markup node head (identifying the type of text
structure) to a tail set of Text nodes. Normal edges connect the Text nodes in order.
In
the TAG model, then, a discontinuous textual object is represented the same way as
a
continuous one, as an ordered set of Text nodes that form the tail of a Markup-to-Text
hyperedge.[24]
Other examples of discontinuity involve stage directions in dramatic text, such as
the
following example from George Bernard Shaw’s Mrs. Warren’s
profession:
VIVIE. Sit down: I’m not ready to go back to work yet. [Praed sits]. You both think
I
have an attack of nerves. Not a bit of it. But there are two subjects I want dropped,
if
you don’t mind.
One of them [to Frank] is love’s young dream in any shape or form: the other [to
Praed] is the romance and beauty of life, especially Ostend and the gaiety of Brussels.
You are welcome to any illusions you may have left on these subjects: I have none.
If we
three are to remain friends, I must be treated as a woman of business, permanently
single
[to Frank] and permanently unromantic [to Praed].
Here the last four stage directions interrupt not just the speech, but the sentences
in
which they occur.
Hierarchy, containment and dominance
The challenges that have emerged from our experience of XML as a model of text involve
not only the limitations of OHCO, but also its tyranny. If text is understood as an Ordered Hierarchy of Content
Objects, are there aspects of text that are not ordered (O), are there aspects that
are not
hierarchical (H, by which we mean not just that they are not mono-hierarchical, but
that
they are not hierarchical at all), and does the model create content objects artifactually,
that is, where they are not perceived as inherent properties of the text being modeled
(CO)?
XML requires us to model all content as both ordered and hierarchical, and it represents
content objects as elements (at least as content objects are described in DeRose et al. 1990). GODDAG and LMNL both grew out of a recognition that not all
properties of text can be modeled effectively as a single hierarchy, and their focus
is not
limited to that issue, but they differ in the extent to which they interrogate features
of
text that may not be hierarchical at all, that may not be ordered, and that may not
involve
what a human would consider a content object.
As was mentioned earlier, the XML data model does not distinguish containment from
dominance, which Tennison explains and illustrates in LMNL terms as follows:
Containment is a happenstance relationship between ranges while dominance is one
that has a meaningful semantic. A page may happen to contain a stanza, but a poem dominates
the stanzas that it contains.[25][Tennison 2008]
In XML, an ancestor element both contains (starts
before and ends after in the serialization) its descendants and dominates them (is connected to them by a path that travels only downward in
the tree). In the XML view below of the Shakespearean sonnet the we used as a TAG
example
above, the <poem> element both contains and dominates three
<quatrain> elements and one <couplet> element, and
the <quatrain> and <couplet> elements both contain and
dominate <line> elements:
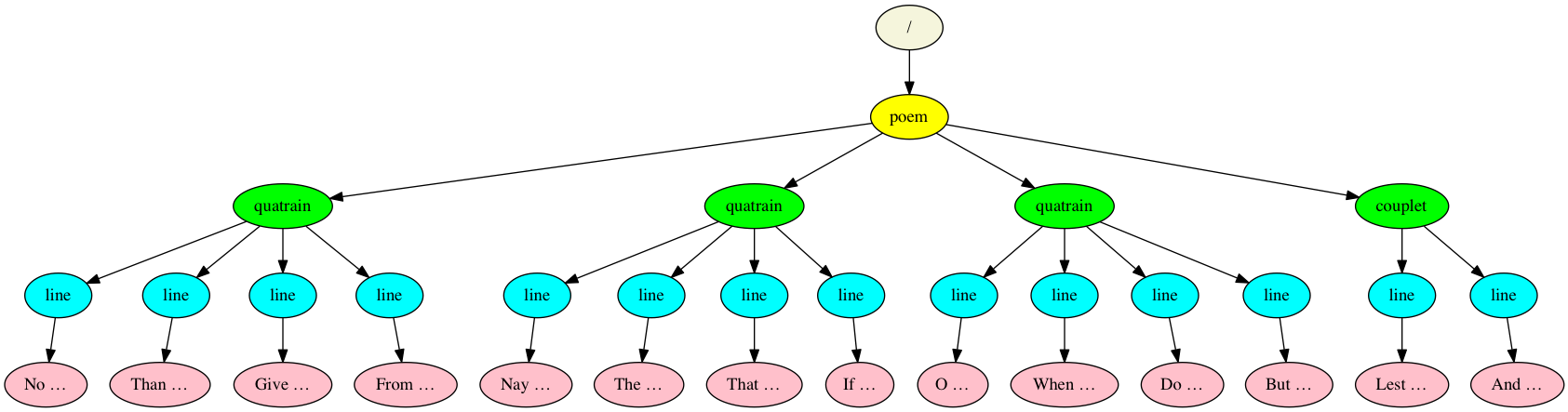
<poem>
<quatrain>
<line>No longer mourn for me when I am dead</line>
<line>Than you shall hear the surly sullen bell</line>
<line>Give warning to the world that I am fled</line>
<line>From this vile world with vilest worms to dwell:</line>
</quatrain>
<quatrain>
<line>Nay, if you read this line, remember not</line>
<line>The hand that writ it, for I love you so,</line>
<line>That I in your sweet thoughts would be forgot,</line>
<line>If thinking on me then should make you woe.</line>
</quatrain>
<quatrain>
<line>O! if,—I say you look upon this verse,</line>
<line>When I perhaps compounded am with clay,</line>
<line>Do not so much as my poor name rehearse;</line>
<line>But let your love even with my life decay;</line>
</quatrain>
<couplet>
<line>Lest the wise world should look into your moan,</line>
<line>And mock you with me after I am gone.</line>
</couplet>
</poem>
Figure 6: William Shakespeare, Sonnet 71
The XML tree encodes containment and dominance in the same way.
In the earlier TAG example of this sonnet, a Markup-to-Text hyperedge defines the
tail
as a set of Text nodes and labels (datatypes) it. In the TAG version of this example,
all
quatrain, couplet, and line Markup-to-Text hyperedges point to sets of Text nodes,
and
containment is modeled by subset relations among the Text-node tails of those hyperedges.
Where the Text nodes that constitute the tail of a Markup-to-Text hyperedge with the
name property (on the Markup node) of line form a proper
subset of the Text nodes that constitute the tail of a Markup-to-Text hyperedge with
the
name property (on the Markup node) of quatrain, the quatrain
contains the line, and the same is true of the relationship between couplets and lines.[26] In this emphasis on containment, rather than dominance, TAG is similar to flat
LMNL, except that LMNL ranges must be continuous (LMNL handles discontinuity separately),
while contiguity is not relevant in defining the set of Text nodes that may serve
as the
tail of a hyperedge in TAG (see the discussion of Discontinuity, above). In the TAG
version
we have chosen not to make the three quatrains and the couplet what in XML terms would
be
children of a root <poem> element, but we could, should we wish, create a
Markup-to-Text hyperedge with a name property value (on the Markup node) of
poem. This could point, through a hyperedge, to the set of all Text nodes
in the poem, which would let us model containment. It could also serve as the head
of a
Markup-to-Markup hyperedge from it to the Markup nodes with quatrain and
coupletname property values, which would let us model dominance.[27] In other words, Markup-to-Text nodes model containment, rather than dominance
(indirectly, through subset properties of the Text nodes to which they point), and
where it
is important to distinguish dominance from containment, the TAG model supports this
through
Markup-to-Markup hyperedges.
One final consequence of the XML conflation of containment and dominance is that when
exactly the same text must be tagged in two ways simultaneously, XML requires one
of the
elements to contain the other. But, as was noted above, if a Markup node with the
name property value of paragraph and a Markup node with the
name property value of quotation both point to exactly the
same set of Text nodes, in TAG it does not make sense to ask whether the paragraph
contains
the quotation or the quotation contains the paragraph because containment in TAG is
defined
as a proper subset relationship among sets of Text nodes. Whether a paragraph consists
of a
quotation or a quotation consists of a paragraph is a reasonable question, but in
TAG it is
a question of dominance, expressed through Markup-to-Markup hyperedges, and not of
containment, expressed (indirectly) through Markup-to-Text hyperedges.
Artifactual hierarchy
As we described above, markup in XML is (among other things) a form of datatyping,
and
the XML spec uses the word type explicitly in this meaning:
Each element has a type, identified by name, sometimes called its generic
identifier (GI) [W3C XML §3]
This means that when XML assigns a type to part of a document by making it an
element, it simultaneously creates an element node, which pushes the textual content
down a
level in the document hierarchy. Consider the following XML structure, represented
here in
markup and as hierarchy:
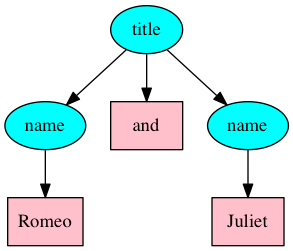
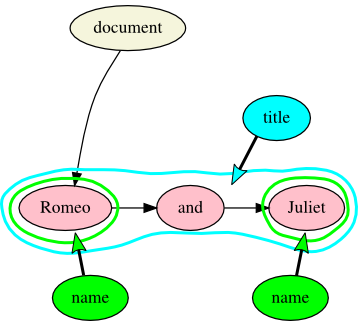
<title><name>Romeo</name> and <name>Juliet</name></title>
Figure 7: Romeo and Juliet (XML)
In XML, the three words of the title are spread over two levels of the hierarchy.
Cyan ellipses are element nodes and pink rectangles are Text nodes.
If we wish to specify in XML that the first and third words of the title are of type
name, we can tag them as elements of that type, with the result that the
Text nodes they contain wind up on a different level of the hierarchy than the conjunction
between them.[28] This contradicts our intuition that the title contains three words, two of which
have the type name, replacing it with a model in which the title contains two
objects of type name with a word between them, and it is the
name objects that contain the first and third words.
Because TAG separates the use of markup in hierarchy and its use for datatyping, it
is
possible to assign a type to text without distorting the hierarchy. Here is the TAG
representation of the same content:
Figure 8: Romeo and Juliet (TAG)
In this TAG example, the markup on names specifies their type and content without
imposing a hierarchy. The title contains three text nodes, represented by pink ellipses.
Markup nodes are green (for names) and cyan (for titles), and the document node is
beige.
As illustrated in the example above, markup of Text nodes in the TAG model, unlike
in
XML, does not create a hierarchical layer as a side effect of datatyping. As we have
seen
earlier, it is possible to represent hierarchy in TAG, but it is not an inescapable
consequence of all markup, as it is in XML.
White space as crypto-overlap
In natural language processing, tokenization is the process of breaking up a string
of
plain text characters into substrings (typically words and punctuation, which may
be
adjacent or separated by white space), often while removing token separators in the
process.
Tokenization of plain text when processing XML is commonly performed using regular
expressions and the tokenize() function, but tokenize() atomizes
its first argument, which means that it cannot be used on tagged text without losing
the
markup in the process. Even tokenization that would not create overlap-based well-formedness
violations, such as splitting and tagging the words of a line of poetry in which the
stressed vowels are tagged as <stress> (see the illustration below),
requires intermediary temporary manipulations, such as converting the markup to text,
tokenizing with tokenize(), and then converting the temporary text back into
markup, or adding additional markup, tokenizing with
<xsl:for-each-group>, and then removing the temporary markup.
The reason tokenizing tagged text is awkward in XML even where overlap is not a risk
has
one explanation in terms of the syntax and another in terms of the data model. In
terms of
the syntax, the markup and text are intertwined in a way that makes it impossible
to ignore
markup during tokenization while retaining access to it after the process is complete.
In
terms of the data model, as noted above, tagging the stressed vowels in a line of
verse
pushes their textual content down a level in the hierarchy, so the line no longer
forms a
string. Furthermore, although it is not usually described this way, the use of white
space
to separate words may be understood as pseudo-markup, which means that the words in
tagged
text potentially represent overlapping hierarchies in plain-text disguise.[29]
In TAG, however, Markup nodes on one layer point to Text nodes on another layer, one
that contains nothing but Text nodes, which makes it possible to tokenize the text
without
interference from the markup. The tokenization splits larger Text nodes into smaller
ones,
but they remain in the tail of their old Markup-to-Text hyperedges, while new Markup-to-Text
hyperedges are added to tag the new individual words. In the simplified illustrations
below,
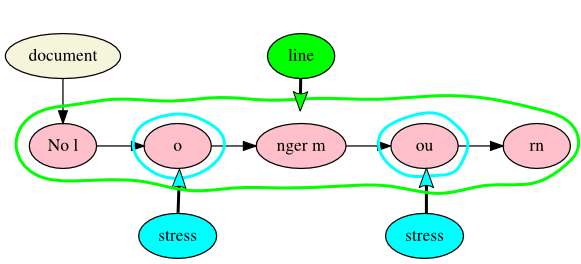
we have created a poem that consists entirely of a single three-word line
(No longer mourn). In the first of these illustrations, the stressed vowels
are tagged but the words are not:
Figure 9: A simplified poem without word tokenization
Without word tokenization, there are five Text nodes, three of which are not marked
up individually and two of which form the tails of Markup-to-Text hyperedges with
a
name property of stress on the Markup node, indicating
that these are stressed vowels.
Because stress is marked on a single vowel sound, XML would be capable of tagging
the
individual words while retaining the stress markup, since no overlap would result.
For that
reason, the following XML representation, which tags both words and stressed vowels,
is well
formed:
Yet if we try to use tokenize() in a transformation to add the
<word> markup to a line that already contains the
<stress> markup, the <stress> markup will be lost
during atomization.
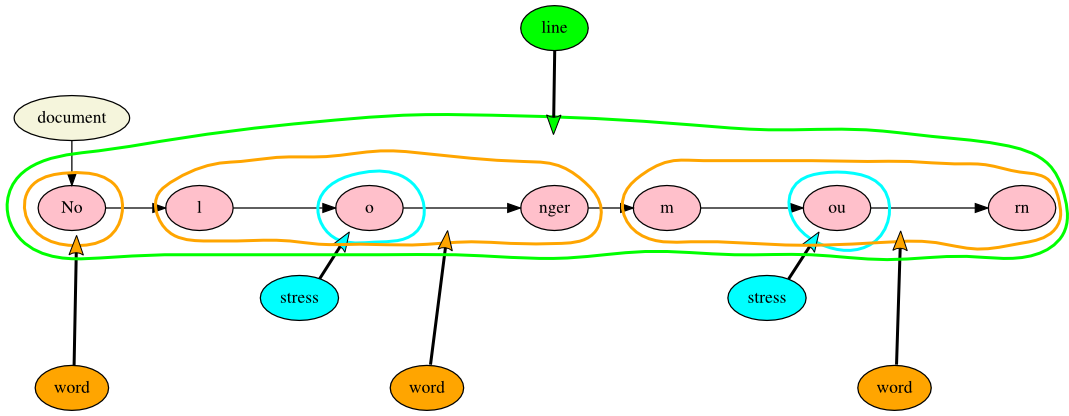
This situation is not a challenge for TAG. In the example below, we have added
Markup-to-Text nodes to tag the words, which can be determined by tokenizing the text
on
white space. Tokenization is possible because the Text nodes are not interrupted by
the
markup, which points to them without being inserted between them (syntactically) and
without
pushing them to different levels of the hierarchy (in the tree structure):
Figure 10: A simplified poem with word tokenization
With word tokenization, there are now seven Text nodes. Two of them still form the
tails of Markup-to-Text hyperedges with a name property of
stress on the Markup node, indicating that these are stressed vowels.
There are now also three Markup-to-Text hyperedges with a name property of
word on the Markup node (in orange); the first points to a single Text
node, and the others each point to three Text nodes.
The additional markup requires additional division of Text nodes, but all modifications
are local, and the only part of the graph that has to be updated is the part to which
the
markup is being added.[30]
The preceding example does not create overlap because the Text nodes that are marked
up
for stress are subsets of those that are marked up as words. But if we also want to
tag
poetic feet, which are needed to identify caesura (a regular coincidence of word and
foot
boundaries in the lines of a poem), overlap would become an issue in XML. One work-around
in
an XML environment has turned out to involve, surprisingly, tagging neither the feet
nor the
words (see Birnbaum and Thorsen 2015), deriving both from other properties of the line
during processing, but the fact that we can use white-space pseudo-markup to escape
the
consequences of syntactic overlap doesn’t mean that the the overlap isn’t there. A
data
model that can represent both feet and words explicitly, and that could identify caesura
as
a relationship between those two types of structural components, would represent explicitly
the human understanding of caesura, and the explicit representation of structure is
much of
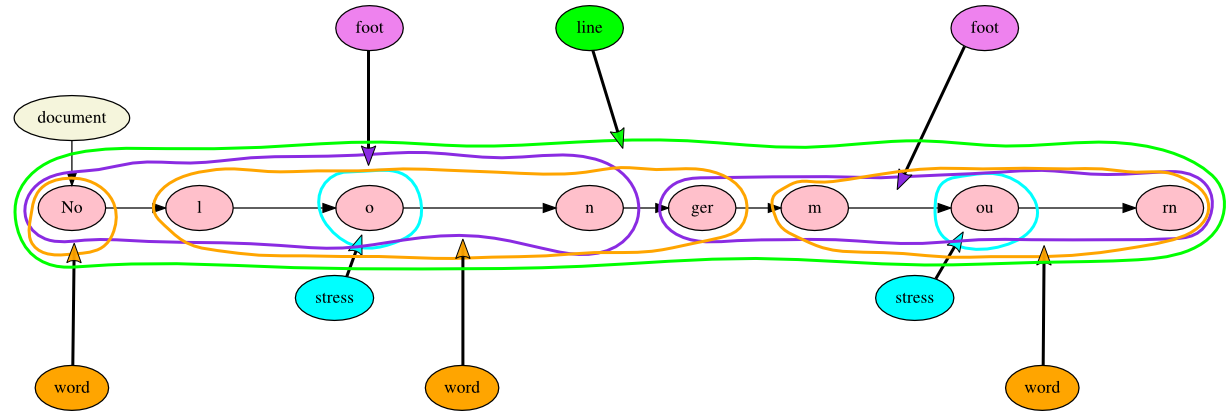
what markup is all about. In the illustration below, we have added foot markup to
the
previous example:
Figure 11: A simplified poem with word and foot markup
When we tag the feet by adding Markup-to-Text hyperedges with a name
property value of foot on the Markup node (in violet), we create overlap
between feet and words, since the word longer is split between the ictic
second syllable of the first iamb and the non-ictic first syllable of the second.
A corresponding XML-like structure that tags words and feet would not be well formed
because the <foot> elements would overlap with the
<word> elements:
In XML, [t]he identification of caesura requires the identification of both feet
and words, which are not coextensive and which frequently overlap. The challenge,
then, is
to locate where foot and line boundaries coincide without employing markup in a way
that
would violate well-formedness overlap constraints. [Birnbaum and Thorsen 2015] In TAG, where overlap is not an issue, caesura is possible when two adjacent Text
nodes
are in the tails of different Markup-to-Text word hyperedges and different
Markup-to-Text foot hyperedges. Caesura is typically 1) at or near the middle
of the line, and 2) implemented consistently, so not every coincidence of word and
foot
boundaries proclaims a caesura; that coincidence is necessary, but not sufficient.
Scope of reference
Footnotes can be understood as annotations on text, but in XML they are typically
represented by elements at the location where the note reference should occur in a
reading
text, as with the <footnote> element in DocBook or the
<note> element in TEI. Anchoring a footnote at a point in the text
stream, instead of as an annotation on a string of (possibly tagged) text with a beginning
and an end, is problematic because it does not mark explicitly the scope of the note,
such
as whether a footnote reference at the end of a paragraph points to the preceding
sentence
or the preceding two sentences or more, or to the entire paragraph. The TEI
<note> element avoids this limitation because it can point to an
arbitrary target with XPointer, but this stand-off strategy is an indirect way of
specifying
what might have been represented more immediately as an attribute if XML attributes
were
able 1) to model rich content, and 2) to annotate something without being forced to
give it
a generic identifier that specifies its type.[31]
TAG avoids the XML prohibition against markup in attribute values because in TAG the
Text nodes of an annotation can be a target of markup, just like those of the main
text. TAG
avoids the scope of reference problem because the annotation can point to a Markup
node with
a name if an appropriate one exists (such as paragraph in a document that marks up
paragraphs). In the example below, because TAG permits anonymous Markup nodes (that
is,
because the name property of Markup nodes is optional), we annotate arbitrary
text without giving it the equivalent of an XML generic identifier, although in a
revision
currently under development, we are exploring pointing directly from the annotation
to the
Text nodes, which would obviate the need for the anonymous Markup node. With either
of these
approaches, footnote-like relationships can be modeled in TAG as what they are: rich-text
annotations on text regardless of whether the target of the annotation corresponds
to a
Content Object with an identifiable type. TAG is similar to LMNL in this respect,
except
that in TAG text being footnoted that is discontinuous is no different from continuous
text;
it is a set of Text nodes that constitute the tail of a Markup-to-Text hyperedge.
In the simplified example below, we add a footnote to the second and third lines of
a
poem by using an Annotation node (orange) to point to a Markup node (violet) that
is the
head of an anonymous Markup-to-Text hyperedge, and the text of the annotation also
has
markup (a sky blue Markup node with a name property of emphasis
points to a single Text node). Neither of these features is available with attribute
markup
in XML because elements must have generic identifiers (= cannot be anonymous) and
attribute
values cannot contain markup. And if the footnote target happens to be something that
would
create overlap in XML (e.g., if it runs from the middle of one line to the middle
of another
and the lines have been tagged explicitly), XML is further encumbered by the prohibition
against overlap.
Figure 12: A poem with an annotation (footnote) on lines 2 and 3
The violet ellipse is an anonymous Markup node that serves as the head of a
Markup-to-Text hyperedge and points to the Text nodes for lines 2 and 3 of the poem.
The
orange ellipse is an annotation on the anonymous Markup node. Annotations have their
own
textual content, which is represented by a chain of Text nodes that begins with the
Annotation node, much as the main text is represented by a chain of Text nodes that
begins with the Document node. The text of an annotation may be the target of markup,
and in this example a Markup-to-Text hyperedge with a name property of
emphasis on the Markup node points to a single Text node.
Insofar as a footnote can be considered metadata about text, the structure illustrated
above represents it as an annotation, but it does not require us to assign a type
to the
target of the annotation as a side effect of referring to it, and it allows us to
add markup
to the footnote text itself.
Data model versus syntax
Syntax is not necessarily the same as a data model. A data model could, at least in
principle, be serialized in multiple ways, and syntax developed to represent one data
model
could be coopted to represent a different one. TAG does not at present have its own
serialization syntax, and the Alexandria Markup implementation described below can
read and
write LMNL sawtooth syntax and TexMECS (parsing the results as a representation of
the TAG
data model, rather than of LMNL or GODDAG), and it is intended to be able to do the
same
with XML syntax.
One challenge of comparing TAG to XML, LMNL, GODDAG, and TexMECS is that TAG, like
LMNL
and GODDAG, is a data model, while XML and TexMECS are defined by their syntax. Perhaps
a
bit surprisingly in the context of Balisage, which describes itself as the markup conference, our focus here is not on markup (that
is, on syntax and serialization), but on the data models that may be expressed through
markup, which means that for comparative purposes we may sometimes need to infer a
data
model from a syntactic specification.
The situation is especially complicated in the case of XML because although it does
not
have a data model, it also has three almost-data-models: XML DOM [W3C DOM], which is an object model and API; the XML InfoSet [W3C XML InfoSet],
which is an information model; and XDM [W3C XDM], which is a data model
for processing XML. Our inferred data model for XML for comparative purposes here
includes
the seven node types specified in XDM (not the twelve of XML DOM or the eleven types
of
information items of the XML InfoSet), along with the structural properties of the
ordered
tree that are relevant for understanding (but not necessarily adequate for processing)
well-formed XML (e.g., attribute nodes on an element are unordered). Our aim is not
to
create a data model for XML, which lies far outside the scope of this paper, but to
identify
features of the way XML models text that can be used comparatively to help elucidate
features of TAG.
The fact that some of our objects of comparison are serializations and others are
data
models matters because, as the etymology of the term implies, serialization is an
ordered
linear expression, which is not a requirement of data models. If, for example, a paragraph
is exactly coextensive with a quotation, in XML syntax, LMNL sawtooth syntax, and
TexMECS
syntax, the start tag of either the paragraph or the quotation must come first in
linear
order. But in LMNL the relative order of the ranges defined by the tags is not an
obligatory
part of the model, which permits two ranges to begin at the same location in the text,
and
the same is true of TAG. In XML, however, one element must be the parent of the other,
and
the order of the start tags reflects both containment and hierarchy. TexMECS negotiates
this
issue by using different start- and end-tag delimiters to distinguish when the relative
order of the tags is informational and when it is not.[32]
Semantics versus application level
Another challenge for text modeling involves distinguishing properties that inhere
in
the structure of the text being modeled from those that depend on semantics that must
be
interpreted at a higher (application) level. A failure to make this distinction may
have two
types of consequences (which are really aspects of the same thing, the delegation
of
information that should be part of the model to the application layer): either the
application must know that some properties of the model are not informational and
are to be
ignored, or the application must know that there is information that is not represented
entirely by the model and must therefore be added during processing. If, however,
the model
explicitly represents the structural properties of the text and nothing else, the
application level is freed from having to supplement the model, and can concentrate
on
features that are truly application-specific.
Moving structural information out of the application layer and into the model is a
priority in the design of TAG, and here are two illustrations of the issue:
The pairing of start and end tags in XML markup is inherent in the markup itself,
and is available during parsing with no reference to semantics. In contrast, the
pairing of XML milestones that are used to simulate container tags as a work-around
for overlap (see the discussion of Trojan markup in DeRose 2004)
depends on semantics. XML applications do not need to know that regular start and
end
tags delimit an element because that information is an inalienable feature of all
XML
documents that is fully specified by the syntax, but they do need to know when empty
tags are being used to simulate the beginning and end of a content object and when
they are not, or which pseudo-start-tags are to be associated with which
pseudo-end-tags. A robust and efficient strategy would represent all structural
features as parts of the model itself, instead of requiring that some of them be
handled through semantic information that is available only at the application
level.
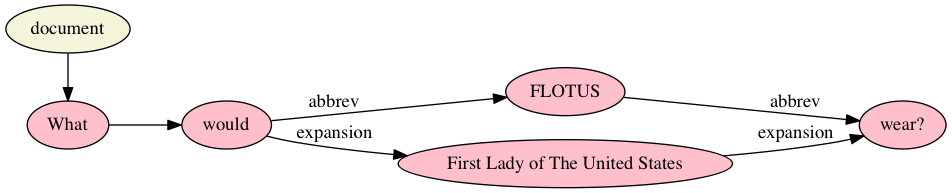
Because XML models an ordered hierarchy, elements always have order, which
requires the application layer to distinguish situations where order is semantically
meaningful from situations where it isn’t. For example, the TEI
<choice> element has the semantics of associating content objects
that do not have a natural order with respect to one another, such as an abbreviation
and its expansion or an error and its correction. How those should be rendered is
the
proper business of the application layer, but the XML model requires that one option
proceed or follow the other even when the order does not represent an inherent,
informational property of the text being modeled. This has the undesirable consequence
that, incorrectly (from the perspective of what the marked-up text means), an XML
processor will regard two TEI documents as different if they differ only in the order
of the children of their <choice> elements unless the processor is
given access to TEI markup semantics. Imposing an arbitrary order as a schema
enhancement (for example, requiring that an abbreviation always precede its expansion
inside a TEI <choice> element) will avoid the problem of
distinguishing when two documents should be considered the same or different, but
at
the cost of making order informational in some situations and arbitrary in others,
that is, of imposing order on something that is not inherently ordered. A more robust
and efficient model would not specify order when it must then be ignored, so that
a
processor will know when order is informational and when it is not from the model,
without recourse to semantics.
Concerning the first of these issues, matching up pseudo-start-tags with pseudo-end-tags
during processing does not arise in TAG not only because TAG does not at present have
its
own syntactic expression (although we can represent some features of TAG by borrowing
LMNL
sawtooth syntax or TexMECS), but also because the fact that TAG permits overlap makes
such
workarounds unnecessary. The second issue is more challenging, and because TAG currently
models text as a single chain of Text nodes, it does not yet distinguish situations
where
order is not informational. But because that is a feature of what text is (that is,
because
the first O of OHCO is as much an issue as the H that follows it), it is a design
requirement that we intend to address as development continues (see Appendix B).
TAG in the Alexandria Markup text repository
The Alexandria Markup text repository system is an open-source read/write implementation
of the TAG model currently under development by the Huygens Institute for the History
of the
Netherlands at https://github.com/HuygensING/alexandria-markup. As was
noted above, at present TAG does not have its own syntax, although strategies for
import and
export are under active development. Alexandria Markup is able to parse and import
flat LMNL
sawtooth syntax, but it treats the syntax as an expression of TAG properties, rather
than LMNL
ones. This means, for example, that although annotations on the same object in LMNL
are
ordered, because those in TAG are not, this order is not treated as informational
during
import or export, or internally. It also means that TAG structures that are not naturally
represented in flat LMNL syntax, such as the Document node or discontinuous sets of
Text
nodes, require special handling. Alexandria Markup is not intended to be an implementation
of
LMNL, and the use of LMNL sawtooth syntax in TAG should not be misunderstood as representing
the LMNL data model. Alexandria Markup is also able to import and parse TexMECS syntax,
which
it also interprets as a representation of the TAG data model, rather than of GODDAG.
The
implementation in the current system loads the TAG model into memory, but persistence
of the
nodes and hyperedges in a key-value store on disk is under development.
Importing documents into Alexandria
Importing plain text into Alexandria Markup
As an example of importing into Alexandria Markup, consider a document that consists
of just the plain text Hello, World. When we import this plain-text
document into Alexandria Markup, a very simple graph is created, consisting of two
nodes
and one regular edge. One node is the TAG Document node; the other is a TAG Text node
that
contains all of the text. A regular edge is created from the Document node to the
Text
node, which associates the text with the document.
Importing LMNL into Alexandria Markup
The lexer uses a grammar to tokenize the LMNL text, setting the type of the token
according to the current context (e.g., annotations inside annotations, inside range
start
or end tags, etc.). The stream of tokens is then parsed in the importer, which is
also
sensitive to the context.
At the start of the import, we create a new Document node, which serves as the head
of
the chain of Text nodes for the main text layer. We deal with parser events in the
following ways:
For each range start tag we create a new Markup node, which we add to a list of
open Markup contexts.
For each string of text we create a new Text node, which we add to the tail of the
Markup-to-Text hyperedges for all open Markup contexts. We also add the Text node
to
the chain of Text nodes.
After each range end tag we remove the corresponding Markup node from the list of
open Markup contexts.
For each annotation start tag we create a new Annotation node, which we add to an
annotation list for the current Markup node. Unless the annotation is empty, we now
set this Annotation as the current text layer, which means that until we come to the
annotation close tag for this annotation, all new Text nodes and Markup nodes will
be
added to this annotation. When we encounter the corresponding annotation end tag,
we
close this Annotation and return to the previous text layer.
Importing TexMECS into Alexandria Markup
We use a lexer and parser to interpret TexMECS syntax. At the start of the import,
we
create a new Document node. We deal with parser events in the following ways:
After each start tag, we create a new Markup node and add it to the list of open
Markup nodes, and to the Document.
For each string of text we create a new Text node, which we add to the tail of the
Markup-to-Text hyperedges for all open Markup contexts. We also add the Text node
to
the chain of Text nodes.
After each end tag we remove the corresponding Markup node from the list of open
Markup contextss.
After each suspend tag we remove the corresponding Markup node from the list of
open Markup contexts, and add it to the list of suspended Markup contexts.
After each resume tag we remove the corresponding Markup node from the list of
suspended Markup contexts, and add it to the list of open Markup contexts.
Exporting from Alexandria Markup in sawtooth syntax
As an example of exporting a simple document from Alexandria Markup, a serialization
of
the TAG data model into LMNL sawtooth syntax involves traversal over an instance.
The
traversal begins with the Document node, which must have a single directed regular
edge that
points to the first Text node. We then follow the Markup-to-Text hyperedges that are
connected to this Text node.[33] There can be zero or more Markup-to-Text hyperedges on a Text node, each of
which is headed by one Markup node. The traversal collects all the Markup nodes that
point
to the Text node, and for each of them it writes a start tag, where the order of multiple
start tags is not part of the TAG model, and is therefore at the discretion of the
implementation. We then proceed to the next Text node by following the outgoing regular
Text-to-Text edge, which connects all Text nodes (except those on annotations) in
a single
chain. As before, we collect all Markup nodes connected to the new Text node, and
we then
calculate the differences between the sets of Markup nodes that point to the two Text
nodes
under consideration. For the intersection we do nothing; for the set of Markup nodes
that
are only on the previous Text node we write end tags; and for the set of Markup nodes
that
are only on the new Text node we write start tags. At the conclusion of the traversal
(which
can be recognized because only the final Text node does not have an outgoing regular
edge),
we write end tags for all associated Markup-to-Text hyperedges.
TAGQL: A query language for TAG in Alexandria Markup
The Alexandria Markup query language for TAG, which is currently in an early stage
of
design and implementation, uses an SQL-like syntax. For example:
select text from markup where name='a'
returns the content of the Text nodes marked up with a.
select annotationText('encoding:resp') from markup where name='sonneteer'
return the values of all Annotation nodes with a name property value of
resp where the annotation is on another Annotation node, which has a
name property value of encoding, and the
encoding annotation is on a Markup node with the name
property value of sonneteer.
The query language operates on sets of nodes and edges. Below are some concise examples
of how such queries might operate in terms of the model, which at that level involves
a
traversal of the Text nodes, since those are the only ordered part of the model. This
naïve
approach would not be performative and would not be implemented directly; a TAG application,
like any database of any type, would employ indices, alternative data structures,
caching,
and other features that are not part of the model, but that can be used to maximalize
performance.[34]
Sample query: Find all lines in the second quatrain of a sonnet
Quatrains are stanzas that consist of four poetic lines, and an Elizabethan sonnet
consists of three quatrains followed by a couplet, for a total of fourteen lines.
Assume a
document where lines and quatrains are Markup nodes that point to sets of Text nodes.
Start at the Document node and navigate to the first Text node, which is part of the
first
quatrain. Follow that Text node up to its associated Markup node that has a
name property value of quatrain; it points to the set of all
of the Text nodes in the quatrain. Follow the chain of Text nodes until the first
one not
in that set, which will be at the beginning of the second quatrain. Follow its hyperedge
up to the associated quatrain Markup node, which points to the set of all
of the Text nodes in its tail, that is, all of the text of the second quatrain. If
you
need the line markup, and not just the text of the lines, return the Text nodes with
their
associated Markup-to-Text hyperedges that originate in Markup nodes with a
name property value of line, that is, with their line
markup.
Sample query: Find enjambment
Enjambment is a poetic phenomenon where a sentence (or sometimes a phrase) crosses
a
line boundary. Assume a document where lines and sentences are Markup nodes that point
to
sets of Text nodes. Traverse the Text nodes starting at the Document node. Any adjacent
Text nodes in the tail of the same Markup-to-Text hyperedge with a Markup node
name property value of sentence, but in the tails of
different Markup-to-Text hyperedges with a Markup node name property value of
line, represents an enjambment.
The Alexandria Markup server API
The Alexandria Markup server has a REST API, which includes the following:
Table II
Method
I/O format
Response
GET /documents
out: json
return a list of the urls of the stored documents
POST /documents/lmnl
in: lmnl text
add a document using a lmnl text, return the id of the document in the Location header
POST /documents/texmecs
in: texmecs text
add a document using a TexMECS text, return the id of the document in the Location
header
GET /documents/{uuid}
out: json
return information about the document
GET /documents/{uuid}/lmnl
out: text
return a representation of the document in sawtooth syntax
POST /documents/{uuid}/query
in: text, out: json
execute a query on the document, return results as json
Java/Python clients
There are clients in Java and Python that, given the URL of an Alexandria Markup server,
can connect to it in a way that hides the details of the REST protocol. The client
code
handles the setting of the required HTTP headers, the formatting of the input and
the
interpreting of the results.
Conclusions
TAG is a graph-based model that consists of a set of nodes and edges (both regular,
one-to-one edges and hyperedges). Only Text nodes are ordered, and the order of Markup
nodes
is derived from the order of the Text nodes to which they point. TAG models containment
through subset relations, and overlap through intersection where neither set is a
subset of
the other, and it deals naturally with discontinuity because there is no requirement
that sets
of nodes be contiguous. TAG is capable of modeling hierarchy, but it is not required
to do so,
and it is possible to have multiple hierarchies. TAG separates the datatyping role
of tagging
from issues of hierarchy, so it is possible to label a set of Text nodes with a Markup-to-Text
hyperedge without affecting hierarchical relations, and it also possible to annotate
a set of
Text nodes with naming them, that is, without the equivalent of an XML generic identifier.
A
root node is optional. At the moment there is a single text order, but TAG recognizes
the need
for greater nuance in this area, about which see Appendix B, which also
identifies other issues that TAG does not (yet) address.
Appendix A. William Shakespeare, Sonnet 71
No longer mourn for me when I am dead
Than you shall hear the surly sullen bell
Give warning to the world that I am fled
From this vile world with vilest worms to dwell:
Nay, if you read this line, remember not
The hand that writ it, for I love you so,
That I in your sweet thoughts would be forgot,
If thinking on me then should make you woe.
O! if,—I say you look upon this verse,
When I perhaps compounded am with clay,
Do not so much as my poor name rehearse;
But let your love even with my life decay;
Lest the wise world should look into your moan,
And mock you with me after I am gone.
Appendix B. Features of text not currently represented in TAG or in Alexandria Markup
The following features are not currently part of the TAG model, but they are recognized
as
necessary components of a textual data model, and under development.
Order
TAG, like XML, is currently fully ordered, but some textual meaning is either unordered
(simultaneity) or multiordered (transposition). The fully ordered set of Text nodes
in the
current TAG model and its implementation in Alexandria Markup is easily traversed,
but
simultaneity and transposition present challenges to traversal that we are still evaluating.
TAG intends to support the representation of both simultaneity and transposition in
the
model, in distinction from XML, where the model is an ordered tree and deviations
from a
single order must be handled at the application layer.
Simultaneity
All Text nodes in TAG are ordered, but modeling text as a partially ordered set,
rather than as an ordered set, would reflect the nature of text more correctly. For
example, the TEI XML <choice> element wraps child elements that do not
have a logical mutual order, such as an abbreviation and its expansion or an error
and its
correction. In XML, artifactual order of this sort cannot be excluded from the model,
and
must therefore be ignored at the application level, and TAG, as described above, currently
has the same limitation. Ideally, sets of Text nodes that are not mutually ordered
logically would not be represented as ordered in the model.
Not only does XML order the children of <choice> even though they
have no logical order,[35] but the <choice> element itself is an artifactual Content
Object, as it represents as an element in the hierarchy a property that is fundamentally
an issue of traversal. The same is true of the TEI <app> element in the
parallel segmentation representation of textual variation. Both the artifactual order
and
the artifactual wrapper must be interpreted at the application layer, and the information
they add is not about the document content as much as it is about the markup, viz.,
that
although XML is an ordered tree, the order of the children of these particular elements
is
not informational.
One possible way to an alternative model is suggested by the Variant Graph that is
used to represent textual variation in the open-source CollateX collation tool [CollateX]. The variant graph represents alternative readings (from different
manuscript witnesses) without wrapper constructions, and could be used to model
simultaneous alternatives in TAG without either artifactual order or artifactual wrappers.
For example, an abbreviation and its expansion might be represented through a directed
acyclic multigraph as:
Figure 13: Abbreviation and expansion
From What would Michelle do?, New York Times,
2016-11-02. There is no artifactual wrapper element, like TEI
<choice>.
Because currently Text nodes in TAG are fully ordered, it is not now possible to model
simultaneity through multiple, differently labeled ordering edges between Text nodes.
We
are exploring strategies for remedying this limitation.
Transposition
Representing alternative orders of the same content, as may be needed in critical
editions in which the textual witnesses may contain some of the same words, but with
reordering, poses a challenge for data models based on a single linear textual order,
including, at the moment, TAG. Insofar as a critical text may be instantiated as a
single
document, and two witnesses may differ through transposition, the representation of
transposition is a requirement for a satisfactory text model. The representation of
transposition is also part of the Variant Graph structure used to model textual variation
in the open-source CollateX collation tool [CollateX], and suggests a
way to incorporate transposition into TAG, but because currently Text nodes in TAG
are
fully ordered, it is not now possible to model transpositions in TAG as alternative
orders. In the following hypothetical transposition scenario, each set of labeled
edges
forms a single complete order with no cycles:
Figure 14: Transposition
Witness A (black and blue edges) reads It was a dark and stormy
night and witness B (black and red edges) reads It was a stormy and
dark night. The edges for witness A (labeled either only A or
A,B) describe an acyclic directed graph, as do those for witness B
(labeled only B or A,B).
The multigraph above uses labeled edges to permit traversal without cycles over edges
that share a label, and suggests a possibility for supporting transpositions, which
is a
necessary part of modeling multi-witness critical texts.
Intradocumentary variation
Intradocumentary variation (see TEI Genetic editions), such as additions, deletions,
and rearrangements, pose a special challenge for at least two reasons:
An edition may include multiple witnesses, each of which may have intradocumentary
variation. For example, the same or different persons may have created additions and
deletions and then layered additions and deletions onto those additions and deletions
in each of the witnesses to a tradition. This is challenging not only from a modeling
perspective, but also from a philological one. A intuitive and widely-used strategy
involves selecting one revision layer per witness for the purpose of comparison with
other witnesses, with the undesirable result that the other layers are ignored,
perhaps without clear philological justification. Another approach is to create
pseudo-witnesses, such as an Additions witness and a
Deletions witness. However, the pseudo-witness approach falls short
because intradocumentary variation is local: an addition in one place is likely to
be
independent of an addition in another.
Intradocumentary variation may affect not only the Text nodes, but also the markup
hierarchy. For example, one paragraph may be divided into two, or a section may be
demoted to a subsection, without any change to the values of the Text nodes
themselves. The same may apply to interdocumentary
variation: when one paragraph in witness A becomes two paragraphs in witness B. For
an
experimental investigation of these issues in an XML context see Bleeker 2017.
Constraint language
Constraints in this paper are expressed in prose. They should be expressed formally
in a
more complete specification.
Markup language
TAG does not define a markup language, that is, a syntactic form that can be used
to tag
text and for import and export serialization. As was noted above, Alexandria Markup
can
parse LMNL syntax (into the TAG data model, not the LMNL one, so it is not so much
parsing
LMNL as borrowing LMNL syntax to express TAG relationships), the same is true of TexMECS,
and similar support is planned for XML syntax. None of these three grammars is capable
of
representing all of the features of TAG. We leave open the question of how to provide
a
character-string serialization of a TAG document.
Appendix C. Hypergraph visualizations
The image below visualizes hypergraph properties of part of Lewis Carroll’s Hunting
of the Snark.
Figure 15: Lewis Carroll, The hunting of the Snark (excerpt)
This hypergraph models the containment and order of the text, with no statement of
hierarchy (dominance).
Text nodes are black hexagons with white text, and they are connected in a single
chain
(which starts at the Document node) by black bars. Markup nodes of type Line,
Voice, Stanza, Sentence, Page,
and Excerpt are represented by irregular backgrounds of white, chartreuse
yellow, magenta, blue, orange, and green, respectively. Annotation nodes on
Excerpt, Page, and Voice Markup nodes have
names and properties. The image models containment with no statement of dominance,
although
dominance could be asserted by adding Markup-to-Markup hyperedges.
The following images emphasize different aspects of the model:
Figure 16: Lewis Carroll, The hunting of the Snark (excerpt)
The image shows how discontinuous parts of the same unit are combined and annotated
in
the model.
Figure 17: Lewis Carroll, The hunting of the Snark (excerpt)
The image shows the layering of different types of Markup on the same Text
nodes.
Figure 18: Lewis Carroll, The hunting of the Snark (excerpt)
The image provides a closer look at the layering. The higher voice levels contain
text
spoken by the Baker but reported by the narrator, which is why they are the targets
of
more than one Markup node of with a name property value of
voice.
Figure 19: Lewis Carroll, The hunting of the Snark (excerpt)
The image illustrates how annotations may have their own Text nodes.
Appendix D. Requirements
An improved text model should have the following properties. In all instances where
we
write that the model should be able to X, we mean that it should be able to X
without requiring access to semantic information at the application level. In other
words, the
components of the model should fully represent the properties of the text being modeled,
with
no extraneous artifactual properties that an application must then know to ignore.
XML uses
the term markup to identify both elements and attributes, while in the list
below we use the TAG terminology, where the term markup refers to the
counterpart of XML elements and annotation to the counterpart of XML
attributes.
The following are characteristics we might ask of an improved text model:
It should support both textual (character data) content and markup and annotations
(of the sort expressed in XML through element and attribute markup).
It should support multiple layers of markup and annotation.
It should be able to represent overlapping markup.
It should be able to represent discontinuous markup.
It should be able to represent components that are not logically ordered without
imposing an arbitrary order that must then be ignored.
It should be able to represent transpositions, or reorderings, e.g., in a critical
text with variants that differ only in order.
It should support annotations on annotations, that is, metadata about
metadata.
It should support but not require the representation of hierarchy, including
multiple, partial, or overlapping hierarchies.
With respect to reading, it should support queries for text, markup, annotations,
or
a combination of those components.
With respect to writing, it should support creating, inserting, deleting, or
otherwise modifying both textual content and markup and annotations.
With respect to workflow, it should be possible to defer decisions about relations
among layers. For example, it should be possible to create markup and annotations
without hierarchy and apply a hierarchy only later. This deferral might be compared
to
the way XML documents may be validated against schemas that may be created and
associated only after a fully functional well-formed document has been created.
With respect to scalability, it should enable, in a computationally efficient way,
the types of documents and processing likely to be required by the digital text
community.
With respect to I/O, a system that implements the model should support serialization
as plain text on export and the parsing of such serializations on import. TAG does
not
currently have its own syntax. Our Alexandria Markup implementation can read and write
LMNL sawtooth syntax and can read TexMECS, and it is intended to be able to read and
write XML.[36]
With respect to user interaction, a system that implements the model should provide
a legible interface that enables reading and writing by human users.[37]
[Bleeker 2017] Bleeker, Elli. Mapping
invention in writing: digital infrastructure and the role of the genetic editor. PhD
dissertation, University of Antwerp, 2017.
[Coombs et al. 1987] Coombs, James H., Allen H.
Renear, and Steven J. DeRose. Markup systems and the future of scholarly text
processing.Communications of the association for computing machinery,
30.11 (Nov. 1987): 933–47. doi:https://doi.org/10.1145/32206.32209.
[Sperberg-McQueen and Huitfeldt 2000] Sperberg-McQueen, C. M. and Claus Huitfeldt. GODDAG: a data structure for overlapping
hierarchies.Digital documents: systems and principles: 8th international conference
on digital documents and electronic publishing, DDEP 2000, 5th international workshop
on the
principles of digital document processing, PODDP 2000, Munich, Germany, September
13–15,
2000, revised papers, ed. Peter King and Ethan V. Munson. NY: Springer, 2004,
139–60. doi:https://doi.org/10.1007/978-3-540-39916-2_12. A revised version is available at
http://cmsmcq.com/2000/poddp2000.html
[Sperberg-McQueen and Huitfeldt 2008a] Sperberg-McQueen, C. M., and Claus Huitfeldt. Containment and dominance in Goddag
structures Presented at Processing text-technological resources, Bielefeld, March
13-15, 2008, organized by the Zentrum für interdisziplinäre Forschung der Universität
Bielefeld. Slides (but not full text) available on the Web at
http://www.w3.org/People/cmsmcq/2008/bielefeld/slides.html
[1] The authors are grateful to Elisa Beshero-Bondar, Elli Bleeker, Gijsjan Brouwer, Bram
Buitendijk, and Astrid Kulsdom for their valuable contributions and support.
[2] Others properties, often more lexical than structural, may depend on contextual
information that is not always expressed explicitly. For example, a capitalized reference
to London is formally marked as a proper noun by capitalization, but
whether it is a placename in England (or Ohio or Ontario or elsewhere) or the personal
surname of a US writer is not represented formally.
[3] The OHCO literature is already familiar to the Balisage audience, and it is not our
goal to provide an exhaustive bibliography. The seminal papers that advocated for
OHCO as
a document model are Coombs et al. 1987 and DeRose et al. 1990; the
seminal examination of the limitations of OHCO, by some of the same authors, is Renear, Mylonas, and Durand 1996 (first introduced as a conference presentation in 1992). Wendell
Piez discusses issues pertaining to overlap and OHCO, and the alternative range model
implemented in LMNL, in Piez 2014.
[7] The desiderata TAG seeks to satisfy are described in a requirements document in Appendix D.
[8] We have created https://github.com/HuygensING/TAG as a portal where we
intend to maintain links to all of our work on TAG as a model and on the Alexandria
Markup
implementation that we discuss below.
[9] The same applies to Annotation nodes, which are not ordered, but which are
attached to either Markup or other Annotation nodes. Two Markup nodes that point to
the same Text nodes are not ordered with respect to each other, since the inferred
order of a Markup node is a derived property of the set of Text nodes to which it
is
attached, and in this example the markup is attached to the same Text nodes. The order
of Markup nodes that point to overlapping or discontinuous sets of Text nodes is
similarly undefined, since the relative order of the sets of Text nodes in the tails
is not strictly defined. See also below about markup dominance.
[10] The XML InfoSet specification defines a children property on element
information items, the value of which is [a]n ordered list of child information
items, in document order. [W3C XML InfoSet, §2.2] This
means that parents know the order of their children, but children do not know their
place in that order. The restricted version of GODDAG, like TAG, has a single order
for all Text nodes, while generalized GODDAG allows different orders in the case of
multiple parentage. As far as we know, there is currently no implementation of
generalized GODDAG other than the stand-off version implemented in EARMARK, which
does
not store the Text nodes in memory. [Peroni et al. 2014]
[11] LMNL ranges may be said to have relative start
order, but not relative order. Unlike the tails of TAG Markup nodes, LMNL
ranges cannot be discontinuous, which simplifies the inventory of positional
relationships that can obtain between ranges.[LMNL range relations]
[12] See also the discussion of unordered content and transpositions in Appendix B.
[13] LMNL ranges must be continuous because they have single start and
end properties [LMNL data model], and a value
comprising a single string (a sequence of contiguous characters). [Piez 2014] This means that a continuous set of atoms may serve as the
content of a single range, but discontinuous components must be stitched together
through coindexing, as illustrated in An example limen: relating discontinuous
ranges in Piez 2008.
[14] This is not meant to imply that fragmented speech must always be regarded as
unitary. The decision is a philological one, and TAG can point to the parts of a
divided quotation from separate Markup nodes when the developer considers that
appropriate. In the following excerpt from Virginia Woolf’s Kew
gardens, editors might reach different conclusions about whether this is one
utterance or two:
He talked almost incessantly; he smiled to himself and again began to talk, as
if the smile had been an answer. He was talking about spirits–the spirits of the
dead, who, according to him, were even now telling him all sorts of odd things
about their experiences in Heaven.
Heaven was known to the ancients as Thessaly, William, and now, with
this war, the spirit matter is rolling between the hills like thunder.
He paused, seemed to listen, smiled, jerked his head and continued:–
You have a small electric battery and a piece of rubber to insulate the
wire–isolate?–insulate?–well, we’ll skip the details, no good going into details
that wouldn’t be understood–and in short the little machine stands in any
convenient position by the head of the bed, we will say, on a neat mahogany
stand. All arrangements being properly fixed by workmen under my direction, the
widow applies her ear and summons the spirit by sign as agreed. Women! Widows!
Women in black–
[15] What constitutes a document is a hermeneutic question that TAG does not seek
to answer.
[16] All main text in the document forms a single chain of Text nodes, and the
same is true of the Text in an annotation. See also Appendix B for
a discussion of simultaneous text and contradictory order.
[17] Empty elements play a smaller role in TAG than in XML because TAG does not
problematize overlap. This means that it does not need to create empty elements
to simulate the start and end tags of a subordinate hierarchy, as is the case in
some XML markup strategies.
[18] The XML DOM and XDM include Text nodes in the model. The XML InfoSet has no
Text nodes, but regards the individual character as an information item:
Each character is a logically separate information item, but XML
applications are free to chunk characters into larger groups as necessary or
desirable.W3C XML InfoSet
[19] Annotation hyperedges point from the Annotations to the thing being annotated
because we think of adding annotations to markup similarly to adding markup to
text.
[20] In this case, they should be merged into a single Text node. This is
comparable to the XML prohibition against Text nodes that are nearest siblings
of other Text nodes. One difference is that in TAG, nearest-sibling Text nodes
are permitted in the tail of a Markup-to-Text hyperedge as long as they are not
all in the tail of all of the same Markup-to-Text hyperedges.
[21] A Markup node may be the head of both a single Markup-to-Text hyperedge and
a single Markup-to-Markup hyperedge. For example, in the Shakespeaerean sonnet
example above, we could add a Markup node with a name value of
poem that is the head of two hyperedges. One is a
Markup-to-Text hyperedge that points to all Text nodes in the poem. The other is
a Markup-to-Markup hyperedge that points to the three quatrain Markup nodes and
the single couplet one. TAG permits us to assert either or both of these
hyperedges.
[22] In this example we have tagged phrases, rather than sentences, but since phrases are
constituents of sentences, a phrase break that crosses a metrical line boundary normally
also entails a sentence break, and therefore an enjambment.
[23] It is possible to interpret the content of the <quotation>
element as three child nodes: a Text node, an intervening element that holds the
narrative interjection, and then another Text node, and in that sense the quotation
is
one object, although that object incorporates something that is not part of what a
human
understands as the quotation. Sperberg-McQueen and Huitfeldt 2008b explains why
this is unsatisfactory (see especially their footnote 2).
[24] The comma in the second Text node might more properly be regarded as part of the
narrative interpolation, and not of Alice’s quoted speech.
[25] This wording (dominates the stanzas it contains) means that
dominance presupposes containment, but the reverse is not the case.
[26] The quatrain Markup node does not contain or have any other direct relationship to
the line Markup node. It is the set of Text nodes of the quatrain that contains the
set
of Text nodes of the line.
[27] Because, as the Tennison quote above illustrates, dominance presupposes containment,
it is not strictly necessary to create a Markup-to-Text hyperedge for the
<poem> element if it is the head of a Markup-to-Markup hyperedge.
[28] It is possible to tag the conjunction, as well, so as to push the word
and down to the same hierarchical level as the names, but we have not
observed that in practice. If the markup process involves tagging what the user
considers informational, it should be possible to say that some text in this title
is of
a particular type that we care about sufficiently to specify it in
our markup, and other text is not, and to tag the former, but not the
latter.
[30] What tokenization on white space should do with the white space is a processing
issue, and not part of the model. The white space could form its own Text nodes, which
would be members of the tails of the line Markup-to-Text hyperedges, but
not of the tails of any of the word Markup-to-Text hyperedges. Or
trailing white space could be regarded as part of the word it follows, and therefore
included inside the Tails of the word Markup-to-Text hyperedges. In this
example, the white space would not form separate Text nodes; e.g., the first Text
node
would consist of three characters, No followed by a space.
[31] Concerning this last point, when a footnote applies to a paragraph, the paragraph
is
already a structural unit independently of the footnote reference. But when a footnote
applies to the last two sentences of a longer paragraph, the two sentences become
a unit
only because they are the target of the footnote. That does make them a structural
component, but assigning a generic identifier like <footnote_target>
to them is a concession to the XML prohibition against anonymous elements, that is,
to
the fact that XML elements always require a generic identifier that provides explicit
datatyping. The generic identifier is redundant because it repeats, in a different
way,
information that is already present by virtue of pointing at or referring to the
sentences from a footnote.
[33] Although Markup-to-Text hyperedges are directed from the Markup node to the Text
nodes, graph traversal may follow incoming edges back to their heads as easily as
it
follows outgoing edges to their tails.
[34] Indices achieve their optimization during querying partially at the expense of
increasing the cost of updating, since parts of the index must be rebuilt when the
content is edited. However, not only can index updates be deferred, but, more
importantly, modifications to a TAG document are local because, among other things,
they
do not depend on character offsets, and therefore are not propagated across the entire
document. This obviates much of the expense of updating in a character-offset-based
standoff model.
[35] As was noted above, this is problematic because it means that two TEI documents
that differ only in the order of the children of their <choice>
elements are not deep-equal. This means that the XML data model imposes a property
that not only is not present in the meaning of the document, but also leads to an
erroneous representation of that meaning that can be corrected only through special
handling at the application layer.
[36] This list item refers to syntactic representations that were developed for data
models other than TAG: XML syntax and the XML data model, LMNL sawtooth syntax and
the LMNL data model, and TexMECS and GODDAG data model. When we speak about parsing
XML or LMNL or TexMECS syntax into Alexandria
Markup, we mean that it is parsed into the TAG data model, and not into XML or LMNL
or GODDAG data models.
XML angle-bracketed markup, LMNL sawtooth markup, and TexMECS all are capable of
representing some but not all features of TAG. For example, LMNL supports
annotations on annotations, while TexMECS doesn’t. More subtly, because annotations
on the same object are ordered in LMNL but not in TAG, when Alexandria Markup parses
LMNL syntax, it is not parsing it into the LMNL data model because, among other
things, it creates unordered annotations. TexMECS supports hierarchy, while LMNL
sawtooth syntax does not. LMNL can represent hierarchy through the limen, but the limen currently has no defined
representation in the syntax. [Piez 2008] We leave unresolved for
now the question of how to serialize fully all information in a TAG document.
[37] We leave unresolved for now the design and implementation of such an interface,
except to say that it might not require a specialized, TAG-aware editor. One
approach might involve the selective export of TAG information for manipulation in
a
third-party editor, followed by its reimport and reintegration into the TAG
document.
Coombs, James H., Allen H.
Renear, and Steven J. DeRose. Markup systems and the future of scholarly text
processing.Communications of the association for computing machinery,
30.11 (Nov. 1987): 933–47. doi:https://doi.org/10.1145/32206.32209.
Ide, Nancy and Keith Suderman.
GrAF: a graph-based format for linguistic annotations. Proceedings of the
Linguistic Annotation Workshop, held in conjunction with ACL 2007, Prague, June 28–29,
1–8.
https://www.cs.vassar.edu/~ide/papers/LAW.pdf
Renear, Allen H.,
Elli Mylonas, and David G. Durand. Refining our notion of what text really is: the
problem of overlapping hierarchies.Research in humanities computing, ed. Nancy Ide and Susan
Hockey. Oxford: Oxford University Press. 1996.
http://cds.library.brown.edu/resources/stg/monographs/ohco.html
Sperberg-McQueen, C. M. and Claus Huitfeldt. GODDAG: a data structure for overlapping
hierarchies.Digital documents: systems and principles: 8th international conference
on digital documents and electronic publishing, DDEP 2000, 5th international workshop
on the
principles of digital document processing, PODDP 2000, Munich, Germany, September
13–15,
2000, revised papers, ed. Peter King and Ethan V. Munson. NY: Springer, 2004,
139–60. doi:https://doi.org/10.1007/978-3-540-39916-2_12. A revised version is available at
http://cmsmcq.com/2000/poddp2000.html
Sperberg-McQueen, C. M., and Claus Huitfeldt. Containment and dominance in Goddag
structures Presented at Processing text-technological resources, Bielefeld, March
13-15, 2008, organized by the Zentrum für interdisziplinäre Forschung der Universität
Bielefeld. Slides (but not full text) available on the Web at
http://www.w3.org/People/cmsmcq/2008/bielefeld/slides.html