Introduction
Hogrefe’s Clinical Handbook of Psychotropic Drugs (CHPD) is a standard reference work that is particularly popular among North American mental health professionals. It is organized by indication groups such as psychosis or depression. It contains many tables with dosing information, trade names, etc.
Supplemented by patient information sheets, the volume comprises about 400 pages (A4 paper size, landscape orientation, spiral binding, see Figure 1).
Figure 1

Print edition
In addition to the main work, which is currently published in its 21st edition, Hogrefe publishes a derivative work that covers psychotropic drugs for children and adolescents. New editions of each volume are published every other year, in an alternating fashion.
The print editions have been published from XML source in a bespoke vocabulary by another typesetter for years when the publisher started exploring the feasibility of an online edition. le-tex was tasked with analyzing the existing XML. It turned out that particularly the table markup was insufficient for reflowable rendering, as it aligned paragraphs in adjacent columns based upon their print line count. In a Web rendering with user-adjustable font sizes and dynamic column widths, paragraphs don’t necessarily keep their print line count. This will lead to misaligned table rows. In order to fix this and other markup issues, le-tex recommended that the vocabulary be switched to something more common and suggested that DocBook 5 with HTML tables be used.
Markup
The markup is DocBook 5 with some conventions and one minor extension. The extension
is that a linkends attribute
may be used in citations, allowing a space separated list of target references to
be cited. This in turn allows for a selective
rendering for print (for example, “[3–5,7]”) and online (linked individual numbers,
“[3,4,5,7]”). The print edition is
typeset with LaTeX that is natively able to group adjacent citation numbers from a
raw list.
A convention has been established for marking up print-only and Web-only content.
This distinction is necessary for
front matter content in that there is a different “about the book” page for print
and Web and the Web rendering of the patient
information sheets (PIS) consists of only the heading and a link to the corresponding
PDF. This is because the PIS are meant
for printing them out. The DocBook attribute condition="web|print" was used to mark up rendering-specific content.
This use is in line with DocBook’s guidelines that don’t make any assumptions on which
values this attribute may assume.
Although the print edition contains a combined index, the different indexterm types
are encoded using the standard
role attribute. Its values are 'indication' and 'tradename', while entries without role
attribute are considered as generic (substance) names. Some of the generic names are
additionally classified (using the
type attribute) as being main entries, that is, the primary location where a substance
is described. These
locations are rendered boldface in the printed index.
The DocBook source data is distributed over 30 files that are consolidated into a wrapper file using XInclude. The XML sources comprise 5 Megabytes.
Web Application
Navigation
In addition to a table-of-contents naviagation, the Web application includes these indexes (Generic Names, Trade Names, Indications, Interacting Agents) as primary navigation widgets. In addition, there is an auto-complete search form that is configured with the list of index terms. When the user enters a search term or clicks on the corresponding index term in the alphabetically grouped indexes, a pre-generated search result list is displayed. If the search terms are generic names, the results are clasified according to the color scheme of the book, as displayed in Figure 2 (green for pharmacology & dosing, red for admonitions, blue for indications, trade names, and other general information, orange for information pertaining to special patient groups such as pregnant women).
Figure 2
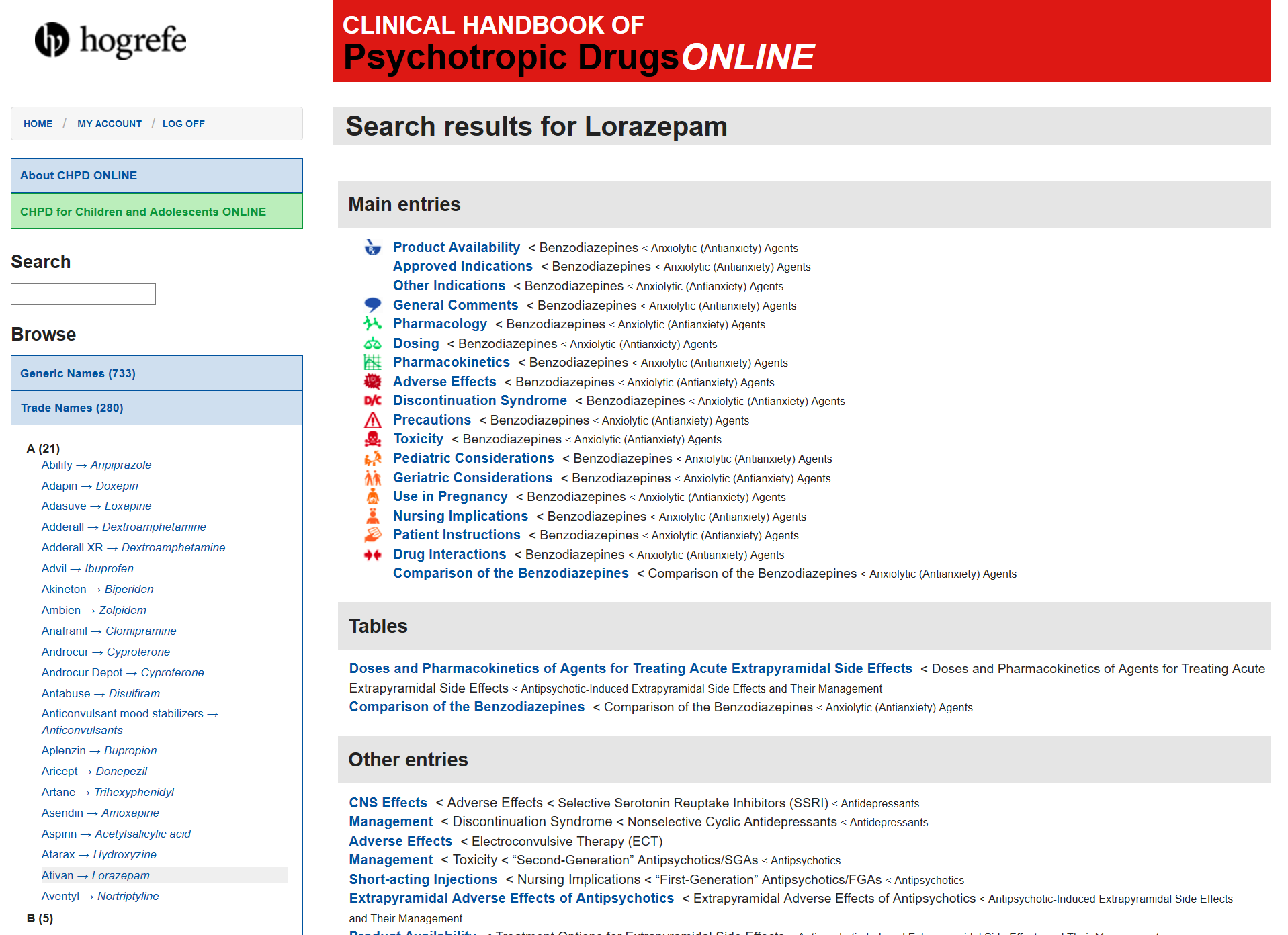
A search result page
Note
The search result lists could be extended to a complete full-text index, excluding stop words, but this was not deemed to add much value.
Search result lists display the main entries in first place. These are often different sections of the same chapter, since the book is organized by substance classes. After that, occurrences in tables are displayed. If Javascript is enabled, the search term is highlighted on the target page when following a link from a search result page (Figure 3).
Figure 3
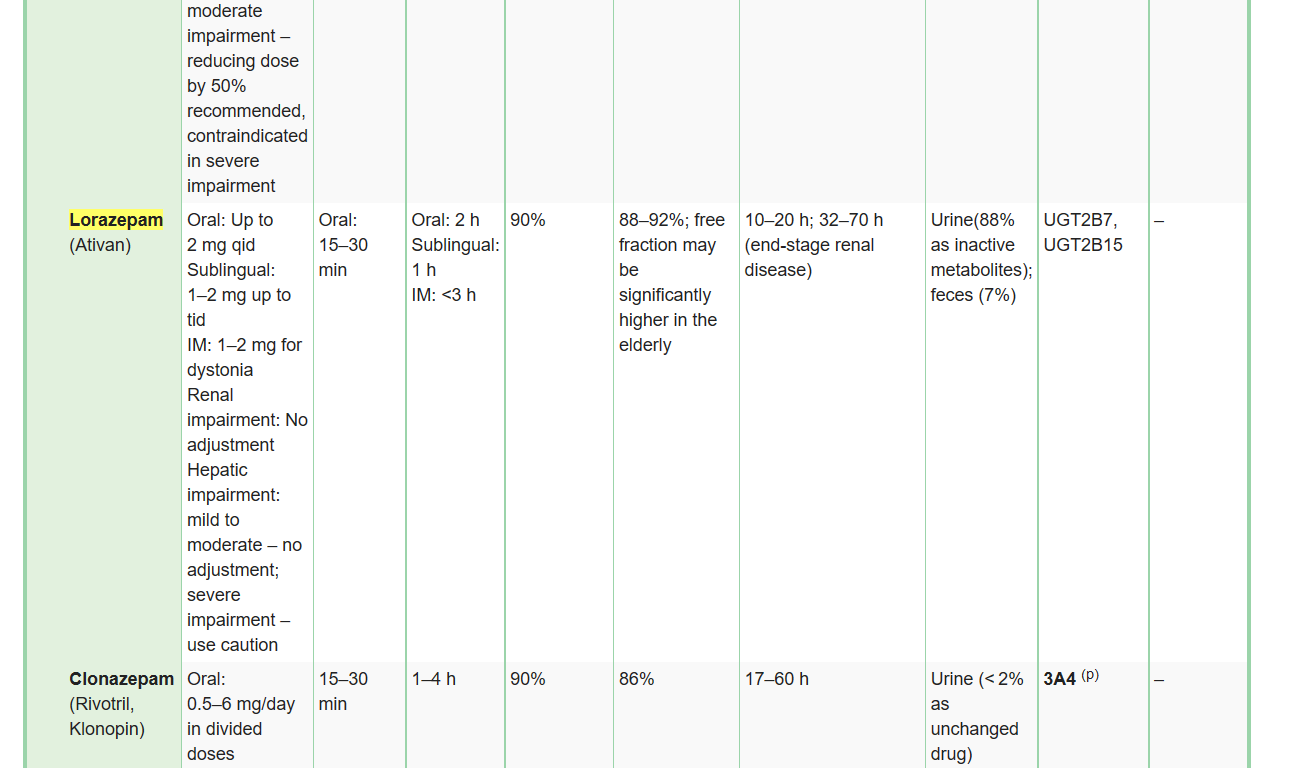
A search result page
If one follows a link to a subsection, the relevant subsection will unfold. The displayed
URL will be modified
accordingly, using the Javascript pushState() method [ref_pushState]. When the user
manually unfolds additional subsections, the URL will be modified accordingly (Figure 4). This allows pages with their section expansion state and highlighting to be
bookmarked and to passed on as links. This way, the drawback of many single-page apps,
which is insufficient
bookmarkability, can be avoided.
Note
Both the expansion state and the search terms to be highlighted are encoded in the
query string of the URL, by
means of said pushState() Javascript method. When such a URL, for example
benzodiazepines.html?sections=d2e99762,d2e101505&term=Lorazepam, is accessed later, the HTML page
loads with all subsections initially collapsed. A client-side Javascript routine then
looks for headings with the
corresponding IDs (d2e99762 and d2e101505 in this example) and toggles the visibility of the
HTML content that is in the same <div> as the heading.
Another client-side Javascript routine analyzes the term part of the query string (for example, …&term=Lorazepam)
searches the text for occurrences of the search term and injects HTML <span>s with a CSS
class that effects the yellow highlighting.
It should be noted that in the absence of Javascript, users can still bookmark whole sections (read: HTML pages) according to their plain URLs. It won’t be possible to save the expansion state though. This provides graceful degradation for when client-side scripting is unavailable.
Figure 4
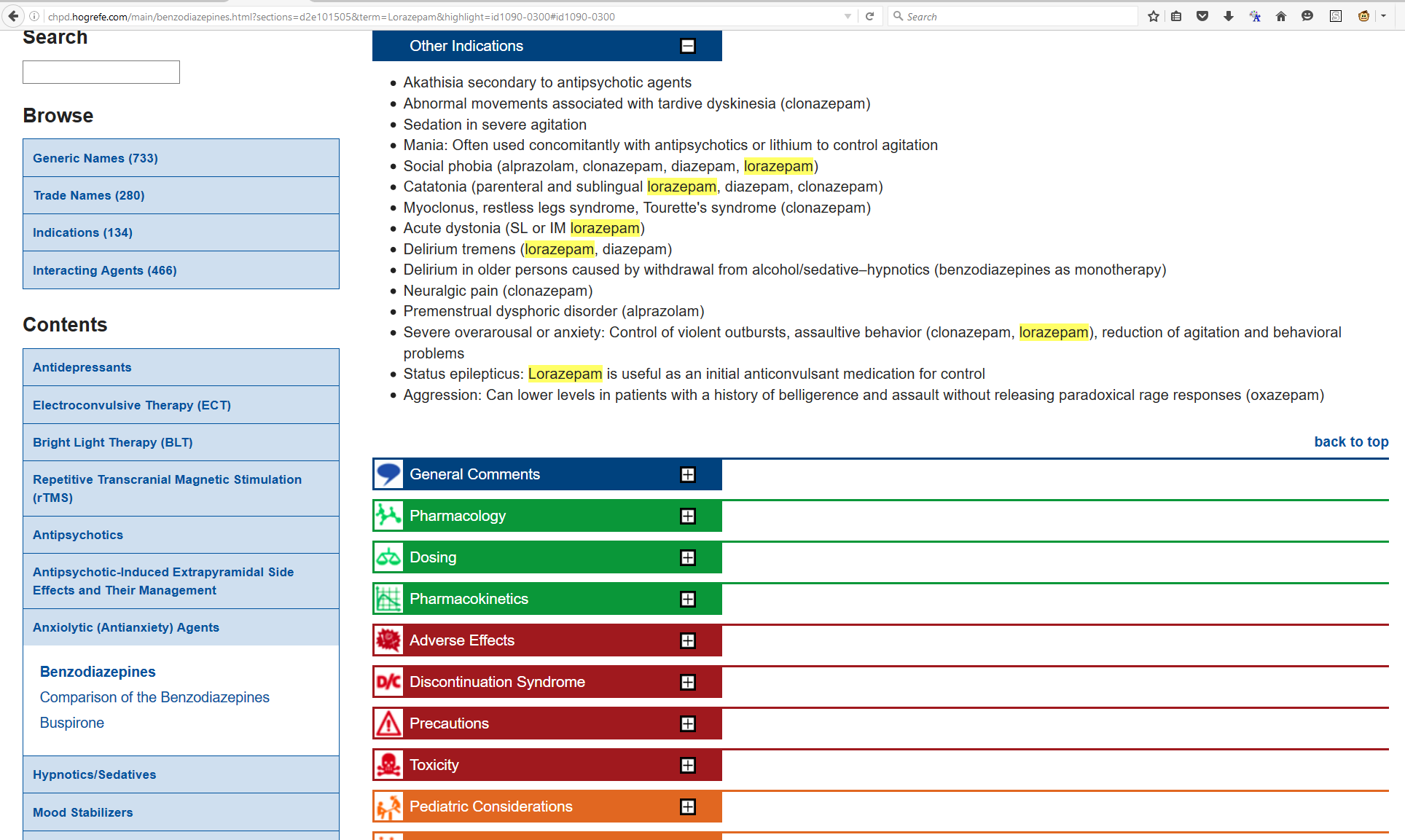
Following a link will unfold its HTML section and modify the displayed URL
Mobile First
Since Hogrefe found out that many healthcare professionals wanted to use the site on their mobile devices, a responsive layout using media queries was established shortly after launching the Web app. However, there were still many large tables that were too wide for mobile displays. Several solutions have been evaluated, among them also CSS-only solutions that switched to a list view for mobile. However, it was decided that a tabular view was still preferable on mobile. In addition, some tables were even too wide for desktop screens. Hogrefe then commissioned development of a Javascript-based table widget that allows users to selectively collapse columns and rows [ref_tableWidget]. The resulting user experience can be seen in Figure 5.
Figure 5
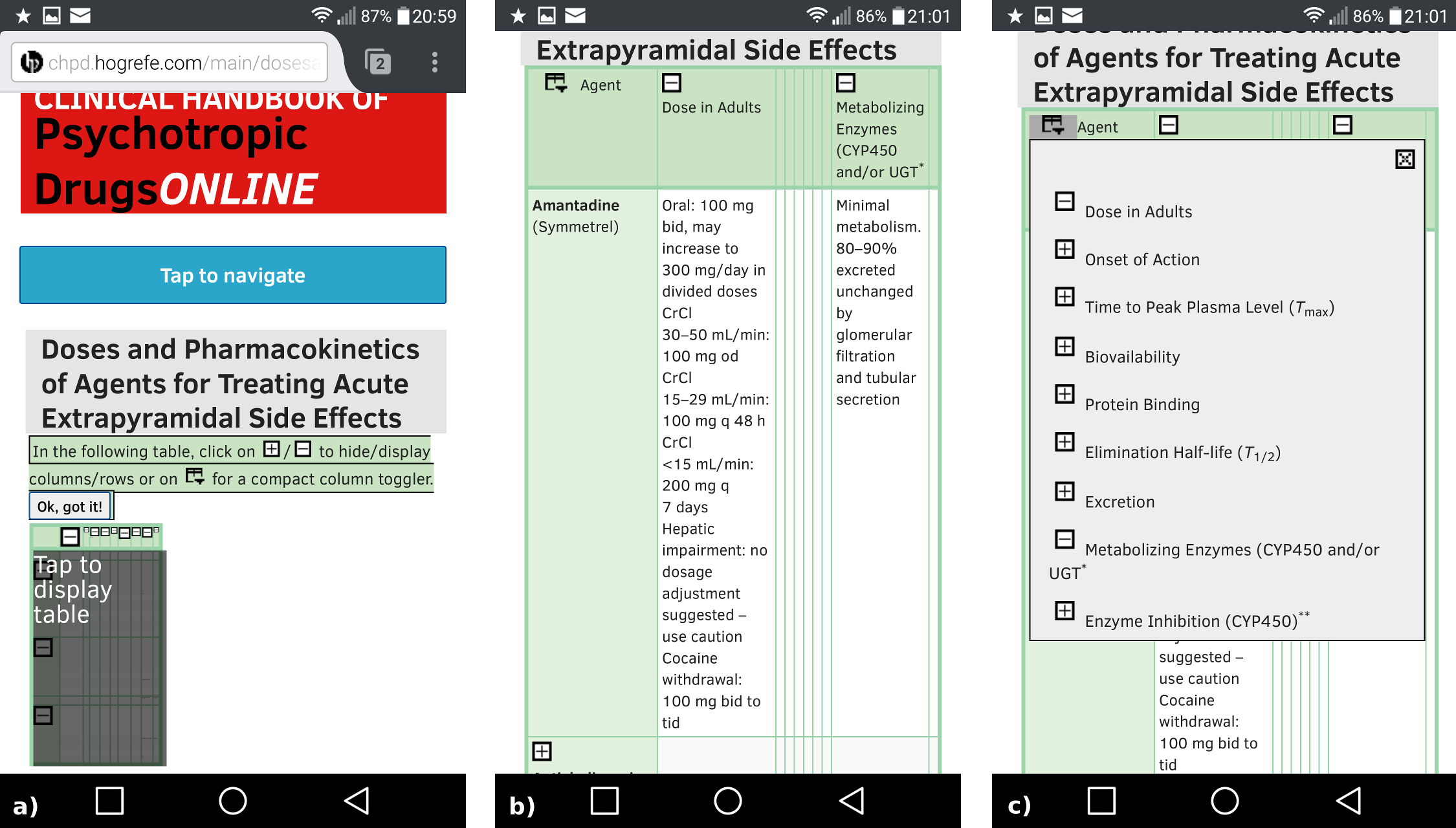
Table widget on mobile devices. a) Initial view. b) View with some columns and a row in collapsed state. c) A flyout menu allows toggling for columns that are outside the viewport
Offline First
The Web application may be run either standalone or within a web application server that primarily is responsible for enforcing access control. It should be noted that even the autocomplete search runs offline since it is Javascript-based, as do other features such as URI rewriting for bookmarking the expansion state of subsections. The Web application may be distributed on a USB stick and run from there.
Page Generation
As stated above, the application runs on static pages. Everything, including a JSON list of search terms and the search result pages, is generated by a static site generator. Static site generators have become a hot topic particularly for powering large, content-driven, high-traffic Web properties [ref_static]. The article discusses that the number of static site generators on Github has more than doubled during 2015. Technology-wise, most of the generators seem to be written in procedural languages such as Ruby or Javascript. Often they operate on Markdown, YAML or HTML content and use more or less established templating languages.[1]
CHPD’s static site generator is XSLT 2.0 which is not only a standardized templating
language but also a very powerful
one (see Figure 6). It renders the DocBook input to HTML, chunking at appropriate locations. In
addition to this, it may easily create the index navigation. In contrast to text-based
input that needs to be parsed and
queried by custom program logic, the XML input may be easily queried using XPath.
This allows for a really straightforward
processing step that first selects the indexterms of a certain role, then calculates custom sort keys (e.g.,
β is sorted as “beta”) and then groups the items according to their initial letters.
In total, more than 1400 pages are being generated, of which approx. 1100 are search result pages.
Figure 6

An XSLT snippet that is responsible for search result page generation
It should be noted that the same expressive power and elegance was not available with XSLT 1 for at least four reasons:
-
XSLT 1 did not provide a standard chunking (result document) mechanism;
-
The XSLT 2 conversion stylesheet provides and uses 20 custom XPath functions that encapsulate calculations and help cut down the complexity of XPath expressions, thereby greatly improving maintainability. Custom
xsl:functions are not available in XSLT 1; -
XSLT 2 provides native grouping instructions;
-
The conversion stylesheet heavily uses regular expression functions that are not available in XSLT 1. This is a bit counterintuitive as one would not expect many regex-based text manipulations when rendering DocBook to HTML. Analysis shows that they are primarily used for file path manipulations and in sort key normalizations, for example replacing α with
alphaor the space character class\p{Zs}with a plain space.
There are workarounds for these operations in XSLT 1. However, they tend to be verbose and less maintainable.
Outlook
Hogrefe plans to migrate all content to a BITS-based XML dialect called HoBoTS [ref_bits, ref_hobots] that they selected for encoding all of the books they publish.[2] For CHPD, this means that there has to be an XSLT that converts from DocBook to BITS/HoBoTS.
Hogrefe intends to deliver all of their book content on the Atypon Literatum [ref_literatum] platform. The major advantage is that they don’t have to run a separate access control application for CHPD. It remains to be seen, however, whether Literatum offers the same set of features that the current Web app provides, particularly with respect to custom indexes and table rendering, but also with respect to the color coding scheme that CHPD users have become used to and that is uniform across the print and the current Web editions.
Conclusion
XSLT 2.0 provides a powerful and standardized way to generate HTML from XML and to create additional navigational structures. The advantage of XSLT was particularly obvious when the responsive layout necessitated structural changes within the generated HTML. Adapting the generating XSLT was a matter of an hour; generating all 1400 pages afresh was a matter of a minute. With HTML5 serialization support introduced in version 3.0, XSLT/XPath is still the processing tool of choice for creating modern Web pages or E-Books from a common XML source.
References
[ref_pushState] “Manipulating the browser history – Adding and modifying history entries”. Mozilla Developer Network. [accessed 2016-04-20]. https://developer.mozilla.org/en-US/docs/Web/API/History_API#Adding_and_modifying_history_entries
[ref_tableWidget] Vonende, Mathias; Imsieke, Gerrit: “jquery-tablemanager plugin”. [accessed 2016-04-20]. https://github.com/maze-le/jquery-tablemanager
[ref_static] Biilmann Christensen, Mathias: “Why Static Website Generators Are The Next Big Thing”. Smashing Magazine. [accessed 2016-04-20]. https://www.smashingmagazine.com/2015/11/modern-static-website-generators-next-big-thing/
[ref_bits] “Book Interchange Tag Set: JATS Extension”. [accessed 2016-04-20]. http://jats.nlm.nih.gov/extensions/bits/
[ref_hobots] Imsieke, Gerrit: “Hogrefe Book Tag Set (HoBoTS)”. [accessed 2016-04-20]. https://hobots.hogrefe.com/schema/hobots.rng
[ref_literatum] Atypon Systems, Inc.: “Literatum”. [accessed 2016-04-20]. https://www.atypon.com/products/literatum/
[1] It should be noted that neither Markdown/CommonMark, YAML, or HTML support index terms which are a concept that was fundamental to providing a multi-faceted navigational and search access. These markup deficiencies, combined with the lack of a standardized query language in the text-based formats, makes processing these formats with these procedural languages significantly harder, compared to an XML/XSLT approach.
[2] They decided for a JATS-based vocabulary over DocBook because it shares much of its vocabulary with Hogrefe’s journals. The journal XML has always been NLM/JATS based. However, when the CHPD XML was converted to DocBook, BITS was not available yet and there was no canonical way to encode book chapters or index terms in the NLM/JATS family of XML vocabularies. Therefore, DocBook seemed like a good fit at that time.