Markup provides a means of annotating a text such that its important characteristics are readily apparent. Simplicity of annotation and richness of meaning are often at odds. Through one lens, we can see the evolution of markup as developing along this fault line. TANSTAAFL. SGML provided mechanisms that reduced the complexity of annotation at considerable cost in implementation. XML reduced implementation cost at the expense of simplicity in annotation. HTML attempted to simplify annotation complexity and implementation cost by choosing a single tag set and inventing entirely new extension mechanisms. Online communities like GitHub and Stack Overflow have abandoned angle brackets in favor of Markdown, Common Mark, AsciiDoc, and other markup reminiscent of wiki syntax or SGML SHORTREF.
Explicit markup
Broadly speaking, if additional characters or sequences of characters are added to some content in order to impose an interpretation on it, then we can describe that as explicit markup.
Explicit markup comes in many flavors, a few of which are described here.
XML
If someone mentions markup, most of us think immediately of explicit markup. These days—for this audience—most likely XML. Given a text document, like this one, we embed XML start and end tags, entity references, etc. within it to impose a structure on it.
In fact, XML is a metalanguage: a language for creating languages. This paper is written using DocBook markup, because that’s what the proceedings require. At another conference it might have been marked up in JATS. Or TEI. If some future linguistic research is performed on the corpus of Balisage proceedings, perhaps it will be marked up in some entirely different way.
Consider the first paragraph of this section:
Figure 1: Some text
If someone mentions markup, most of us think immediately of explicit markup. These days-for this audience-most likely XML. Given a text document, like this one, we embed XML start and end tags, entity references, etc. within it to impose a structure on it.
For these proceedings, it could be marked it up thus:
Figure 2: DocBook markup
<para>If someone mentions markup, most of us think immediately of explicit markup. These days&mdash;for this audience&mdash;most likely XML. Given a text document, like <emphasis>this one</emphasis>, we embed XML start and end tags, entity references, etc. within it to impose a structure on it.</para>
In another context, it might be marked up like this:
Figure 3: Some other markup
<g13><s>If someone mentions markup<p>,</p> most of us think immediately of explicit markup<p>.</p></s><s>These days<p>&mdash;</p>for this audience<p>&mdash;</p>most likely XML<p>.</p></s><s>Given a text document<p>,</p> like this one<p>,</p> we embed XML start and end tags<p>,</p> entity references<p>,</p> <q>etc</q><p>.</p> within it to impose a structure on it<p>.</p></s></g13>
In fact, the number of ways that it might be marked up is essentially unbounded. Amongst the strengths of explicit markup is the fact that different structures can be imposed on the same text. (The weakness that different structures cannot, in general, be imposed at the same time with inline markup, is a subject oft discussed at this conference.)
At one level, this makes XML very extensible: new markup elements can be invented at will and used immediately. Namespaces provide a mechanism to ensure that the names one group invents are unlikely to be the same as the names another group invents.
At another level, however, XML is very inflexible and non-extensible. The specification leaves effectively no room for exensibility at the level of parsing:
-
A left angle bracket is always the start of a start- or end-tag.
-
An ampersand is always the start of an entity or numeric character reference.
-
An “
'” is always, literally a U+0027 character. -
The interpretation of an entity reference is always explicitly in terms of the characters used in its definition.
-
etc.
This level of specificity (or brittleness) is part of a trade off between simplicity of parsing and intepretation on one hand and flexibility on the other.
Consider this random document with some markup in it:
Figure 4: Random markup
<f29>"I believe so," <r>Alice</r> replied thoughtfully. "They have their tails in their mouths—and they're all over crumbs."</f29>
While the semantics of the tags may be unknown, the structural
interpretation of the document is wholly defined by the XML
specification: it’s a document with an f29 document
element that has three children: a text node, an r
element, and another text node. The r element in turn
has a single text node child.
SGML
SGML, like XML, is a grammar for creating new grammars. I mention it here for two reasons:
-
SGML is thirty years old this year, so it’s bound to be discussed.
-
SGML provided an “SGML Declaration” and a much richer set of features in its DTDs. Taken together, these gave the document author the ability to make quite profound changes to the way in which the SGML parser behaved.
The SGML Declaration, DTD syntax, and other mechanisms such as notations and SDATA entities made SGML documents much more flexibile than XML documents. It also made the parsers much more difficult to write and the interpretation of documents much more difficult.
In an SGML context, it’s not possible to make definitive assertions about the intepretation of a random document like Figure 4. SGML (before the WebSGML corrigendum anyway) doesn’t attempt to define the intepretation of an SGML document absent its SGML Declaration and DTD.
We shall return to this topic later in section “The road not taken”.
JSON
If the sweet spot for XML and SGML is marking up “prose documents”, the sweet spot for JSON is collections of atomic values. If you are willing to squint and say that the collection of atomic values is analagous to the text document we mark up with XML, then JSON qualifies as explicit markup.
A typical JSON document looks something like this:
Figure 5: JSON data
{
"p": 3,
"q": [
false
],
"r": [
null,
true,
"true"
]
}The two organizational structures in JSON are “objects” (unordered collections of name/value pairs) and “arrays” (strictly ordered collections of arbitrary types). Beyond these two structures, JSON defines only four data types: numbers, strings, booleans, and the literal value “null”. JSON is highly composable. The values in an object can be any JSON type as can the members of an array.
It’s interesting to note that XML has both of the organizational structures as well: attributes are unordered collections of name/value pairs and element content is an ordered collection of nodes. But XML is far less composable.
It’s not difficult to argue this XML document:
<p>This is <em>important</em>.</p>
And this JSON object:
{
"p": [
"This is ",
{
"em": [
"important"
]
},
"."
]
}are equivalent representations of the same underlying data: a “p” that has three “children” including one that is an “em” with one “child”.
As a matter of practicality, JSON documents are not at all constrained to represent data that has an equivalent form in XML. There isn’t any XML document that’s a lossless representation of Figure 5, for example. Consequently, JSON tools don’t lend themselves to efficient processing of the equivalent subset.
Note: Aside
JSON lacks anything that closely resembles XPath. It is possible to define a coherent model for XPath expressions over JSON data, as MarkLogic version 8.x and above do, but it leads to some unexpected consequences. (What, for example, is the node name of the value 3 in an array and is it distinguished from the node name of any other value in the array?)
JSON “in the wild” is subject to considerable variation. The current official definition of the “application/json” media type is RFC 7159 but the format is a subset of the data structures allowed in Javascript. In as much as JSON data structures are often constructed by Javascript, it is not uncommon to find examples of objects and arrays that are putatively JSON but in fact stray outside the boundaries of RFC 7159. (For example, Javascript doesn’t require that property names be quoted.)
SGML and XML are defined with a concept of validity: their metalanguages define new elements (and attributes) in the context of a grammar that divides the universe of documents into valid ones that conform and invalid ones that do not. The definition of JSON includes no notion of validity at the structural level, but several proposals, such as JSON Schema, exist to fill this gap. If widely adopted, they would give JSON a degree of metamodel extensibility not unlike XML.
Syntactically, JSON is as tightly constrained as XML. Attempts to relax the syntactic constraints exist, for example HJSON, but they do so by defining wholly new syntaxes not be extending JSON in any standard way.
CSV
CSV files contain lines of text that are interpreted as “comma separated values” (or sometimes tab separated values, but it comes to the same thing).
In the interest of completeness, it can probably be argued that CSV also qualifies as a kind of explicit markup. In practice, there is tremendous variation in how applications interpret CSV documents.
This variation probably traces back to the notion that it’s “so simple it doesn’t need a specification” combined with implementors’ attempts to be “bugward compatible” with the tools with which they wanted to interoperate.
There is now a specification for the “Model for Tabular Data and Metadata on the Web” (W3C, 17 Dec 2015).
HTML
HTML, despite it’s surface similarity to XML and SGML, is a particular language, a particular set of tags, not a metalanguage. It was originally described using SGML, but never implemented that way. An XML definition was specified, but it was rejected by the browser vendors. Today, when we speak of HTML, we mean HTML5.
HTML uses angle brackets and entity references, and the realization of a document is ultimately a tree, but HTML is maximally Postelian. Where XML imposes both well-formedness and validity constraints, HTML imposes none. Every sequence of characters is an HTML document.
One of the principle goals of the HTML5 effort was to specify the language in such a way that every sequence of characters has exactly one interpretation as an HTML document. In other words, the goal is complete interoperability at the level of constructing a document tree. There is no formal, grammatical definition of HTML; it’s defined in prose in the specification and by running code and a test suite.
In principle, HTML leaves no room for
extensibility. Every sequence of characters already has an interpretation.
In practice, it provides several mechanisms: class attributes,
“data” attributes (that is to say, attributes with names
that begin data-), meta elements, rel
attributes on link elements, script and
embed elements, and Javascript.
HTML can obviously be used in a great many contexts, but for the overwhelming majority of users, the web browser is the only context that matters. On the modern web, Javascript and CSS are effectively required components of that context.
The current HTML maintainers have also asserted that no standard
HTML element name will ever contain a hyphen. Various extensibility
mechanisms have been described that rely on this fact. Cleverly packaging
a hyphenated tag name (such as db-funcsynopsis) with appropriate Javascript
and CSS offers the potential for considerable extensibility in the future.
Unlike namespaces in XML, the hyphenated names described by HTML provide
no mechanism for establishing global uniqueness. This is obviously a problem in theory
as your definition of ex-image and my version of ex-image
are likely to collide in Very Bad™ ways if we attempt to use them together in
the same document. Whether this turns out to be a significant problem in practice
remains to be seen.
Implicit markup
Having surveyed the state of several explicit markup langauges, let’s turn our attention to implicit markup.
There’s no such thing.
While a human being, with the syntax and semantics of a tag set in mind, may be able to look at a document and work out where markup boundaries are implied, computers can’t. At least not unless the current crop of AI systems turn out to be much more successful than previous efforts.
What we mean when we speak of “implicit markup” in this context would be better described as “lightweight markup”: interpreting characters and features of prose documents—as they occur in the prose—as markup.
Lightweight markup languages
On the surface, lightweight markup language appear to make
simple things simple. Presented with a page consisting of several
blocks of text separated by blank lines, we’re all comfortable
assuming that those are, logically, paragraphs of text. Similarly,
lines beginning with “*” or “-” characters
form a bulleted list, and so on.
Many of the conventions used in lightweight markup languages go back as far as text files on computers. They’re clearly inspired by wiki markup (from before the days when the browser was an application platform). There are lots of lightweight markup languages, dozens at least, perhaps hundreds.
The current resurgence in popularity probably derives from the fact that, for many applications, the web browser is the predominant user interface. To the extent that it’s useful to solicit marked-up text from users, the browser presents a significant challenge. Two challenges, in fact: a technical challenge and a usability challenge.
The technical challenge is that the obvious way to solicit input
is with an HTML textarea element into which users type.
Note
Moore’s Law and advances in compiler technology have made the web browser an incredibly powerful application development platform. Much more sophisticated editing applications can be developed for strucured authoring in the browser: Oxygen’s XML Web Author, for example. They are not, however, casually deployed on the web at this time.
The usability challenge will be apparent to anyone who’s tried typing markup into a text area. They will tell you that it’s an unpleasant task. Typing markup without any form of help from an editing tool is tedious and error prone. It’s also a problem for applications. While applications may wish to allow users to type in paragraphs and lists, it’s perhaps undesirable to allow users to type in image or script elements with arbitrary URIs.
Lightweight markup languages are a much better fit for typing into a text box. They require less typing, there are fewer opportunities for markup errors, and the markup elements can easily be limited.
As noted above, many lightweight markup languages have been developed. Often they become associated with a particular community, reStructuredText in the Python community, for example, or Org Mode in the Emacs community.
In this paper, we’ll consider three lightweight markup languages:
-
Markdown, developed to allow authors “to write using an easy-to-read, easy-to-write, plain text format” that could be converted to structurally meaningful HTML, has been adopted by major applications such as Github and Stack Overflow.
-
AsciiDoc, developed with an eye towards making it easier to author DocBook documents, is a natural fit for Balisage.
-
Org Mode, is a feature-rich lightweight markup language that florishes within the Emacs community.
It is not the intent of this paper to declare one of these
languages superior to the others. While we might prefer XML to JSON or
Oxygen to a textarea, lightweight markup languages are
here to stay. Just as AsciiDoc attempts to make a lightweight version
of DocBook, efforts are afoot to make lightweight versions of DITA and
JATS. You’re bound to run into them eventually, if you haven’t yet,
and this paper hopes to provide an overview of the sort of things
you’re going to encounter.
What starts simple, blank lines and asterisks, can quickly descend into an ad hoc sea of punctuation characters, bringing some dubiousness to the adjective “simple”. For the purposes of comparison, this paper presents the same document (to the extent possible) encoded in five ways: DocBook, HTML, the CommonMark flavor of Markdown, AsciiDoc, and Org Mode.
The sample document has been contrived to demonstrate the following features: a document title and additional metadata, inline links, inline emphasis, inline code, inline bold, superscripts, paragraphs, itemized lists, ordered lists, description lists, tables, examples, program listings, footnotes, and a function synopsis.
The DocBook document, Figure 6, and HTML document Figure 7 are presented first.
Figure 6: DocBook markup
<article xmlns="http://docbook.org/ns/docbook"
xmlns:xlink="http://www.w3.org/1999/xlink">
<info>
<title>Document Title</title>
<subtitle>Subtitle</subtitle>
<author>
<personname>Jane Smith</personname>
</author>
<abstract>
<para>The document, abstractly.</para>
</abstract>
<keywordset>
<keyword>alpha</keyword>
<keyword>beta</keyword>
</keywordset>
<publisher><publishername>Yoyodyne Propulsion Systems</publishername></publisher>
<bibliomisc role="john">bigboote</bibliomisc>
</info>
<para>This is a paragraph. See also
<link xlink:href="http://docbook.org/">DocBook</link>.
</para>
<para>This is <emphasis>another</emphasis> paragraph<footnote>
<para>The examples in this document are awful, I know.</para>
</footnote>.</para>
<itemizedlist>
<listitem>
<para>The first item of a bulleted list.</para>
</listitem>
<listitem>
<para>The second item.</para>
<para>The second part of the second item.</para>
</listitem>
<listitem>
<para>The third item.</para>
</listitem>
</itemizedlist>
<para>This is a paragraph.</para>
<orderedlist>
<listitem>
<para>The first item of a numbered list.</para>
</listitem>
<listitem>
<para>The second item.</para>
<para>The second part of the second item.</para>
</listitem>
<listitem>
<para>The third item.</para>
</listitem>
</orderedlist>
<para>This paragraph contains a <code>code</code> word.</para>
<variablelist>
<varlistentry>
<term>Mercury</term>
<listitem>
<para>Burn, baby, burn.</para>
</listitem>
</varlistentry>
<varlistentry>
<term>Venus</term>
<listitem>
<para>Where global warming ran amok.</para>
</listitem>
</varlistentry>
<varlistentry>
<term>Earth</term>
<listitem>
<para>Where global warming is running amok.</para>
</listitem>
</varlistentry>
<varlistentry>
<term>Mars</term>
<listitem>
<para>Future home of Elon Musk.</para>
</listitem>
</varlistentry>
</variablelist>
<para>This is a paragraph.</para>
<table xml:id="table">
<title>A powerful table</title>
<tgroup cols="3">
<thead>
<row>
<entry>x</entry>
<entry>x<superscript>2</superscript></entry>
<entry>x<superscript>3</superscript></entry>
</row>
</thead>
<tbody>
<row>
<entry>1</entry>
<entry>1</entry>
<entry>1</entry>
</row>
<row>
<entry>2</entry>
<entry>4</entry>
<entry>8</entry>
</row>
<row>
<entry>3</entry>
<entry>9</entry>
<entry>27</entry>
</row>
</tbody>
</tgroup>
</table>
<example>
<title>How long since then?</title>
<programlisting language="xquery">xquery version "1.0-ml";
declare variable $startDate external;
let $date := $startDate cast as xs:dateTime
let $diff := current-dateTime() - $date
return
current-dateTime() - $date</programlisting>
</example>
<para>Consider the function synopsis for the “max” function:</para>
<funcsynopsis>
<funcsynopsisinfo>
#include <varargs.h>
</funcsynopsisinfo>
<funcprototype>
<funcdef>int <function>max</function></funcdef>
<varargs/>
</funcprototype>
</funcsynopsis>
<para>Finally, this is the <emphasis role="bold">last</emphasis>
paragraph.</para>
</article>The DocBook document is effectively the highest fidelity source. The “function synopsis” is included specifically because there’s no directly corresponding markup in any of the other flavors.
Figure 7: HTML markup
<!DOCTYPE html> <html> <head> <title>Document Title</title> <meta charset="utf-8" /> <meta name="subtitle" content="Subtitle" /> <meta name="author" content="Jane Smith" /> <meta name="abstract" content="The document, abstractly." /> <meta name="keywords" content="alpha,beta" /> <meta name="publisher" content="Yoyodine Propulsion Systems" /> <meta name="john" content="bigboote" /> </head> <body> <header> <h1>Document Title</h1> <p class="subtitle">Subtitle</p> </header> <p>This is a paragraph. See also <a href="https://www.w3.org/TR/html5/">HTML 5</a>.</p> <p>This is <em>another</em> paragraph.<sup><a id="fn1m" href="#fn1">1</a></sup>.</p> <ul> <li><p>The first item of a bulleted list.</p></li> <li><p>The second item.</p> <p>The second part of the second item.</p> </li> <li><p>The third item.</p></li> </ul> <p>This is a paragraph.</p> <ol> <li><p>The first item of a numbered list.</p></li> <li><p>The second item.</p> <p>The second part of the second item.</p> </li> <li><p>The third item.</p></li> </ol> <p>This paragraph contains a <code>code</code> word.</p> <dl> <dt>Mercury</dt> <dd>Burn, baby, burn.</dd> <dt>Venus</dt> <dd>Where global warming ran amok.</dd> <dt>Earth</dt> <dd>Where global warming is running amok.</dd> <dt>Mars</dt> <dd>Future home of Elon Musk.</dd> </dl> <p>This is a paragraph.</p> <table id="table"> <caption>A powerful table</caption> <tr> <th>x</th> <th>x<sup>2</sup></th> <th>x<sup>3</sup></th> </tr> <tr> <td>1</td> <td>1</td> <td>1</td> </tr> <tr> <td>2</td> <td>4</td> <td>8</td> </tr> <tr> <td>3</td> <td>9</td> <td>27</td> </tr> </table> <figure> <figcaption>How long since then?</figcaption> <pre>xquery version "1.0-ml"; declare variable $startDate external; let $date := $startDate cast as xs:dateTime let $diff := current-dateTime() - $date return current-dateTime() - $date</pre> </figure> <p>Consider the function synopsis for the “max” function:</p> <pre>#include <varargs.h> int <strong>max</strong>(int n, ...);</pre> <p>This is the <strong>last</strong> paragraph.</p> <p><sup><a id="fn1" href="#fn1m">1</a></sup> The examples in this document are awful, I know.</p> </body> </html>
There are a lot of possible HTML variations. Many authors would add
additional div elements with class attributes. This example is
intentionally somewhat minimal.
HTML doesn’t have anything that corresponds to a footnote or a function synopsis, so those have been coded by hand.
All of the markup formats discussed in this section can be converted to HTML (and often other formats as well). For another kind of comparison, each has been converted to HTML and rendered. No effort has been made to improve the appearance of the output: no special options or CSS applied. This isn’t a question of which is the most attractive, it’s just another way to compare the structure of the output.
The DocBook example, converted with the standard DocBook XSLT 2.0 Stylesheets toolchain is shown in Figure 8. The HTML, simply loaded in a browser, is shown in Figure 9.
{kind=link}
{kind=link}
Figure 8: DocBook rendered

Figure 9: HTML rendered

Many modern editing tools come with language-specific modes to make editing lightweight markup languages easier. As a final point of comparison, the source for each format is shown in Emacs with an appropriate editing mode.
Figure 10: DocBook in Emacs
Figure 11: HTML in Emacs
Markdown / CommonMark
Markdown was explicitly designed to enable authors “to write using an easy-to-read, easy-to-write, plain text format” that could be converted to structurally meaningful HTML. It was somewhat casually specified on John Gruber’s blog.
There are a lot of flavors of Markdown. CommonMark is a recent effort to write a more formal specification for Markdown. That’s the flavor used in this example.
Because transformation to HTML is explicitly the design goal of Markdown, there is a straightfoward extension mechanism: just insert HTML markup. We see that in Figure 12 for footnotes, description lists, tables, and figures.
Table I
| Feature | Markup |
|---|---|
| Document title | # title |
| Additional metadata | Not available |
| Inline links | [title](uri) |
| Inline emphasis | _emphasis_ |
| Inline code | `code` |
| Inline bold | *bold* |
| Superscripts | HTML |
| Paragraphs | Blank line |
| Itemized lists | + |
| Ordered lists | 1. |
| Description lists | HTML |
| Tables | HTML |
| Examples | HTML |
| Program listings | ``` or indent four spaces
|
| Footnotes | HTML |
| Function synopsis | HTML |
Figure 12: CommonMark markup
# Document Title
<!-- There are proposed extensions for document metadata -->
This is a paragraph. See also [CommonMark](http://commonmark.org)
This is _another_ paragraph<sup><a id="fn1m" href="#fn1">1</a></sup>.
+ The first item of a bulleted list.
+ The second item.
The second part of the second item.
+ The third item.
This is a paragraph.
1. The first item of a numbered list.
2. The second item.
The second part of the second item.
3. The third item.
This paragraph contains a `code` word.
<!-- There are proposed extensions for DLs -->
<dl>
<dt>Mercury</dt>
<dd>Burn, baby, burn.</dd>
<dt>Venus</dt>
<dd>Where global warming ran amok.</dd>
<dt>Earth</dt>
<dd>Where global warming is running amok.</dd>
<dt>Mars</dt>
<dd>Future home of Elon Musk.</dd>
</dl>
This is a paragraph.
<table id="table">
<caption>A powerful table</caption>
<tr>
<th>x</th>
<th>x<sup>2</sup></th>
<th>x<sup>3</sup></th>
</tr>
<tr>
<td>1</td>
<td>1</td>
<td>1</td>
</tr>
<tr>
<td>2</td>
<td>4</td>
<td>8</td>
</tr>
<tr>
<td>3</td>
<td>9</td>
<td>27</td>
</tr>
</table>
<figure>
<figcaption>How long since then?</figcaption>
```xquery
xquery version "1.0-ml";
declare variable $startDate external;
let $date := $startDate cast as xs:dateTime
let $diff := current-dateTime() - $date
return
current-dateTime() - $date
```
</figure>
Consider the function synopsis for the “max” function:
#include <varargs.h>
int max(int n, ...);
Finally, this is the *last* paragraph.
<sup><a id="fn1" href="#fn1m">1</a></sup> The examples in this document are awful, I know.
The focus of the CommonMark specification is the core language. Several extensions have been proposed: extensions for document metadata and a simpler, text syntax for description lists, for example.
The CommonMark example, converted to HTML with cmark
is shown in Figure 13.
{kind=link}
Figure 13: CommonMark rendered

Figure 14: CommonMark in Emacs
AsciiDoc
AsciiDoc was designed to be an alternate syntax for DocBook. It supports a fairly large, though not wholly complete, set of DocBook constructs. It can also be transformed into HTML and other XML vocabularies.
The common tools for transforming AsciiDoc into XML or HTML provide language-specific extension mechanisms. The AsciiDoc markup includes facilities for attribute annotations on blocks.
AsciiDoc also supports advanced features such as variable substitution (a mechanism for doing text substutition not unlike general entities in XML).
Table II
| Feature | Markup |
|---|---|
| Document title | = title |
| Additional metadata | :property: |
| Inline links | link:uri[title] |
| Inline emphasis | _emphasis_ |
| Inline code | `code` |
| Inline bold | *bold* |
| Superscripts | ^superscript^ |
| Paragraphs | Blank lines |
| Itemized lists | * with explicit continuations
|
| Ordered lists | 1. with explicit continuations
|
| Description lists | term :: description |
| Tables | Visual with preamble |
| Examples | . title before block
|
| Program listings | ---- with [source,language] preamble
|
| Footnotes | footnoteref:[id,Footnote text] |
| Function synopsis | Approximate with program listing |
Figure 15: AsciiDoc markup
= Document Title :SUBTITLE: Subtitle :AUTHOR: Jane Smith :ABSTRACT: The document, abstractly. :KEYWORDS: alpha, beta :PUBLISHER: Yoyodyne Propulsion Systems :JOHN: bigboote This is a paragraph. See also link:http://asciidoctor.org/[Asciidoctor]. This is _another_ paragraphfootnoteref:[fn1,The examples in this document are awful, I know.]. * The first item of a bulleted list. * The second item. + The second part of the second item. * The third item. This is a paragraph. 1. The first item of a numbered list. 2. The second item. + The second part of the second item. 3. The third item. This paragraph contains a `code` word. Mercury :: Burn, baby, burn. Venus :: Where global warming ran amok. Earth :: Where global warming is running amok. Mars :: Future home of Elon Musk. This is a paragraph. [[table]] .A powerful table |====================== | x | x^2^ | x^3^ | 1 | 1 | 1 | 2 | 4 | 8 | 3 | 9 | 27 |====================== .How long since then? [source,xquery] ---- xquery version "1.0-ml"; declare variable $startDate external; let $date := $startDate cast as xs:dateTime let $diff := current-dateTime() - $date return current-dateTime() - $date ---- Consider the function synopsis for the “max” function: [source,c] ---- #include <varargs.h> int max(int n, ...); ---- Finally, this is the *last* paragraph.
The AsciiDoc example, converted to HTML5 with asciidoctor
is shown in Figure 16.
{kind=link}
Figure 16: AsciiDoc rendered

Unlike the other conversions, the “default” conversion for AsciiDoc includes CSS to improve the appearance.
Figure 17: AsciiDoc in Emacs
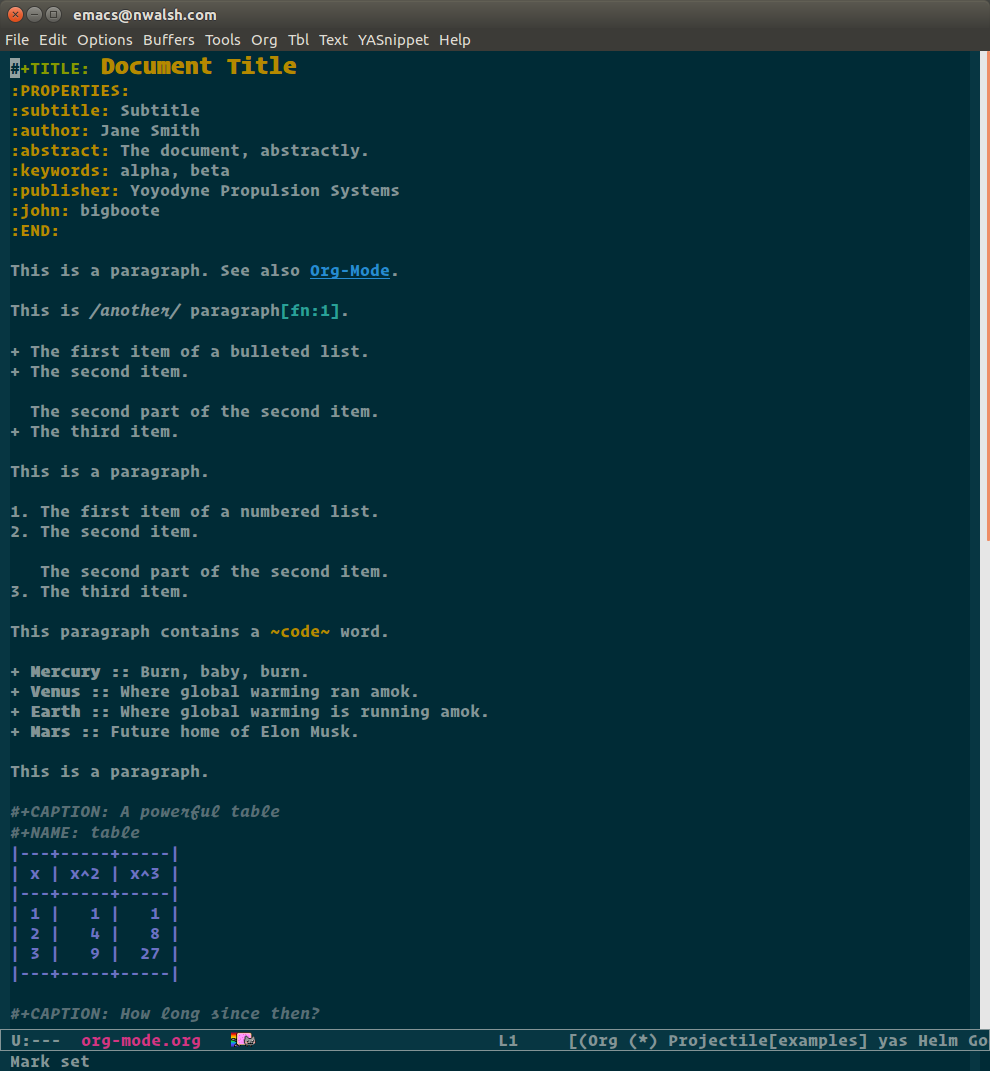
Org Mode
Org Mode grew organically out of an earlier outline mode on Emacs. It boasts a very rich integration with Emacs including features like inline execution of code samples and a literate programming facility. Like AsciiDoc, it supports many different back ends.
Table III
| Feature | Markup |
|---|---|
| Document title | #+TITLE: title |
| Additional metadata | #+PROPERTY: or :PROPERTIES: “drawer”
|
| Inline links | [[uri]][title] |
| Inline emphasis | /emphasis/ |
| Inline code | ~code~ |
| Inline bold | *bold* |
| Superscripts | ^superscript |
| Paragraphs | Blank lines |
| Itemized lists | *, +, or - |
| Ordered lists | 1. |
| Description lists | + term :: description |
| Tables | Visual with property preamble
|
| Examples | #+BEGIN_EXAMPLE with property preamble
|
| Program listings | #+BEGIN_SRC with arguments
|
| Footnotes | [fn:1] |
| Function synopsis | Approximate with program listing |
Figure 18: Org Mode markup
#+TITLE: Document Title :PROPERTIES: :subtitle: Subtitle :author: Jane Smith :abstract: The document, abstractly. :keywords: alpha, beta :publisher: Yoyodyne Propulsion Systems :john: bigboote :END: This is a paragraph. See also [[http://orgmode.org/][Org-Mode]]. This is /another/ paragraph[fn:1]. + The first item of a bulleted list. + The second item. The second part of the second item. + The third item. This is a paragraph. 1. The first item of a numbered list. 2. The second item. The second part of the second item. 3. The third item. This paragraph contains a ~code~ word. + Mercury :: Burn, baby, burn. + Venus :: Where global warming ran amok. + Earth :: Where global warming is running amok. + Mars :: Future home of Elon Musk. This is a paragraph. #+CAPTION: A powerful table #+NAME: table |---+-----+-----| | x | x^2 | x^3 | |---+-----+-----| | 1 | 1 | 1 | | 2 | 4 | 8 | | 3 | 9 | 27 | |---+-----+-----| #+CAPTION: How long since then? #+BEGIN_EXAMPLE #+BEGIN_SRC ml-xquery :var startDate="1967-06-16T18:24:00-07:00" xquery version "1.0-ml"; declare variable $startDate external; let $date := $startDate cast as xs:dateTime let $diff := current-dateTime() - $date return current-dateTime() - $date #+END_SRC #+END_EXAMPLE Consider the function synopsis for the “max” function: #+BEGIN_SRC c #include <varargs.h> int max(int n, ...); #+END_SRC Finally, this is the *last* paragraph. [fn:1] The examples in this document are awful, I know.
The Org Mode example, converted to HTML within Emacs is shown in Figure 19.
{kind=link}
Figure 19: Org Mode rendered

Figure 20: Org Mode in Emacs
The road not taken
Or, stupid SGML tricks
Unique among the approaches described in this paper, SGML included a standard mechanism for making quite substantial changes to the behavior of the parser. SGML documents require both an SGML Declaration and a DTD. Let’s return to the earlier example, Figure 4, and provide an SGML DTD for it.
Figure 21: SGML document
<!DOCTYPE f29 [ <!ELEMENT f29 - - (r|#PCDATA)*> <!ELEMENT r - - (#PCDATA)> ]> <f29>"I believe so," <r>Alice</r> replied thoughtfully. "They have their tails in their mouths-and they're all over crumbs."</f29>
We also need an SGML Declaration. XML was designed so that it was possible to process XML documents using an SGML parser, with the appropriate XML SGML Declaration. We’ll just use that one. If you run Figure 21 through an SGML parser and look at the ESIS output, you’ll get something like Figure 22. What’s an ESIS, you ask? ESIS stands for Element Structure Information Set. It’s a standard way to represent the output from an SGML parser.
Figure 22: ESIS for SGML document
(F29 -"I believe so," (R -Alice )R - replied thoughtfully. "They have\ntheir tails in their mouths-and they're all over\ncrumbs." )F29 C
It’s a line-oriented format. For our purposes, it’s sufficient to note that “(tag” represents a start tag, “)tag” represents an end tag, “-” represents text and a terminal “C” indicates that parsing was successful.
Now let’s have a little bit of fun. SGML dates back, as we’ve observed, thirty years to 1986. It’s antecedants, including GML, go back even further. If you go back that far, you return to an era where input was often done with 80 column punched cards (or, at least, virtual ones in the case of IBM) and memory was at a premium. It was also an era when data entry was a specialized task. Operators could be expected to follow detailed data entry instructions.
SGML developed features like tag minimization, SHORTTAG, and SHORTREF to encode markup text in fewer characters. The DTD could define a state machine to define how these characters were to be interpreted. For instance:
Figure 23: SGML document with SHORTREF
<!DOCTYPE f29 [ <!ENTITY q-start "<q>"> <!ENTITY q-end "</q>"> <!SHORTREF start-q '"' q-start> <!SHORTREF end-q '"' q-end> <!USEMAP start-q f29> <!USEMAP end-q q> <!ELEMENT f29 - - (r|q|#PCDATA)*> <!ELEMENT r - - (#PCDATA)> <!ELEMENT q - - (#PCDATA)> ]> <f29>"I believe so," <r>Alice</r> replied thoughtfully. "They have their tails in their mouths-and they're all over crumbs."</f29>
The ESIS for this document reveals something dramatically different.
Figure 24: ESIS for SGML document with SHORTREF
(F29 (Q -I believe so, )Q - (R -Alice )R - replied thoughtfully. (Q -They have\ntheir tails in their mouths-and they're all over\ncrumbs. )Q )F29 C
Using that DTD, our document is equivalent to this document:
Figure 25: SGML document with quotes
<!DOCTYPE f29 [ <!ELEMENT f29 - - (r|q|#PCDATA)*> <!ELEMENT r - - (#PCDATA)> <!ELEMENT q - - (#PCDATA)> ]> <f29><q>I believe so,</q> <r>Alice</r> replied thoughtfully. <q>They have their tails in their mouths-and they're all over crumbs.</q></f29>
A fact that we can demonstrate by comparing the ESIS output, if we wish.
So what is going on?
-
<!USEMAP start-q f29>says that in the context of thef29element, thestart-qSHORTREF is in effect. -
<!SHORTREF start-q '"' q-start>says that a single double quote character should be replaced by the value of theq-startentity. (In SGML, markup in entities is emphatically not required to be well-formed within the entity replacement text). -
<!ENTITY q-start "<q>">defines theq-startentity such that it inserts aqstart tag. -
As soon as a
qstart tag has been inserted, we’re in a different context.<!USEMAP end-q q>says that in the context of aqelement, theend-qSHORTREF is in effect.Which, by the same general steps as above, will cause a single double quote character to insert a
qend tag, which will change the context back, etc.
This DTD effectively makes properly paired occurrences of double quotes into start- and end-q tags. It is possible to take this mechanism quite a bit further than may at first be obvious. Consider this document:
Figure 26: Another SHORTREF document
<!DOCTYPE doc [
<!ENTITY object-open "<object>">
<!ENTITY object-close "</object>">
<!ENTITY key-open "<pair><key>">
<!ENTITY key-close "</key>">
<!ENTITY value-open "<value>">
<!ENTITY value-close "</value></pair>">
<!ENTITY array-open "<array>">
<!ENTITY array-close "</array>">
<!ENTITY entry-open "<entry>">
<!ENTITY entry-close "</entry>">
<!ENTITY string-open "<string>">
<!ENTITY string-close "</string>">
<!SHORTREF start-map '{' object-open
'[' array-open
'"' string-open>
<!SHORTREF object-map '"' key-open
'}' object-close
':' value-open>
<!SHORTREF value-map '"' string-open
',' value-close
'{' object-open
'[' array-open
']' array-close
'}' object-close>
<!SHORTREF array-map '"' string-open
'{' object-open
',' entry-open
'[' array-open
']' array-close
'}' object-close>
<!SHORTREF key-map '"' key-close>
<!SHORTREF string-map '"' string-close>
<!USEMAP start-map doc>
<!USEMAP object-map object>
<!USEMAP key-map key>
<!USEMAP value-map value>
<!USEMAP string-map string>
<!USEMAP array-map array>
<!ELEMENT doc - - (object|array)+>
<!ELEMENT pair O O (key,value)>
<!ELEMENT object - - (pair)+>
<!ELEMENT key - - (#PCDATA)*>
<!ELEMENT value - O (object|array|string)*>
<!ELEMENT string - - (#PCDATA)*>
<!ELEMENT array - - (entry)+>
<!ELEMENT entry O O (object|string)>
]>
<doc>
{
"object": {
"key": "value",
"key2": "value2",
"array": [
"a",
"b",
"c"
]
}
}
</doc>
It produces a quite long and complicated ESIS:
Figure 27: ESIS for another SHORTREF document
(DOC (OBJECT (PAIR (KEY -object )KEY (VALUE (OBJECT (PAIR (KEY -key )KEY (VALUE (STRING -value )STRING )VALUE )PAIR (PAIR (KEY -key2 )KEY (VALUE (STRING -value2 )STRING )VALUE )PAIR (PAIR (KEY -array )KEY (VALUE (ARRAY (ENTRY (STRING -a )STRING )ENTRY (ENTRY (STRING -b )STRING )ENTRY (ENTRY (STRING -c )STRING )ENTRY )ARRAY )VALUE )PAIR )OBJECT )VALUE )PAIR )OBJECT )DOC C
Which, with some effort, you can work out means that it is equivalent to this document:
Figure 28: Another document with markup
<!DOCTYPE doc <!ELEMENT doc - - (object|array)+> <!ELEMENT pair O O (key,value)> <!ELEMENT object - - (pair)+> <!ELEMENT key - - (#PCDATA)*> <!ELEMENT value - O (object|array|string)*> <!ELEMENT string - - (#PCDATA)*> <!ELEMENT array - - (entry)+> <!ELEMENT entry O O (object|string)> ]> <doc> <object> <key>object</key> <value> <object> <key>key</key> <value> <string>value</string> </value> <pair> <key>key2</key> <value> <string>value2</string> </value> </pair> <pair> <key>array</key> <value> <array> <entry> <string>a</string> </entry> <entry> <string>b</string> </entry> <entry> <string>c</string> </entry> </array> </value> </pair> </object> </value> </object> </doc>
Or, with whitespace for legibility, this one:
Figure 29: Prettyprinted markup
<doc>
<object>
<key>object</key>
<value>
<object>
<key>key</key>
<value>
<string>value</string>
</value>
<pair>
<key>key2</key>
<value>
<string>value2</string>
</value>
</pair>
<pair>
<key>array</key>
<value>
<array>
<entry>
<string>a</string>
</entry>
<entry>
<string>b</string>
</entry>
<entry>
<string>c</string>
</entry>
</array>
</value>
</pair>
</object>
</value>
</object>
</doc>Concluding remarks
The tension between richness and simplicity isn’t going to go away. It’s easy to dismiss lightweight markup languages as lacking the sophistication necessary to capture the full richness of a text. But each offers mechanisms for capturing some of the richness. Some is often better than none.
Whether efforts to develop lightweight markup formats capable of usefully capturing the semantics of DITA or JATS will succeed remains to be seen, but widespread adoption of Markdown and other lightweight markup formats on websites demonstrates that they are sufficient for many applications.
Have you considered where they might be appropriate in your workflow?