Introduction
Trials in the Late Roman Republic, 149 BC to 50 BC [Alexander 1990] is the title of a database published in book form by the Roman legal historian Michael C. Alexander; it is also the name of a project now underway to produce a new version of the database, reflecting newer scholarship and further research. For brevity, both the database and the project will be referred to simply as TLRR; the first and second editions or versions will be distinguished as TLRR1 and TLRR2.
The book provides a chronological list of trials which are known or thought to have taken place in the century indicated by the subtitle. For each trial, the book gives (I simplify slightly) the date of the trial, the charge or claim, the name of the defendant, the name of the prosecutor or plaintiff, the names of the advocates who spoke on behalf of the defendant or plaintiff, the names of the presiding magistrate(s), jurors, witnesses, and other individuals involved in the trial, and the verdict. Since nothing like modern court records survives from ancient Rome, this information must be pieced together, sometimes tentatively, from sources like records of the speeches given, letters, accounts in historical sources, or chance remarks in works devoted to other topics. For each trial the ancient works which are sources of our information about the trial are listed, as are some salient recent works of secondary literature.
The first edition of TLRR was prepared for print using a batch document formatter (Waterloo Script/GML), but the regularity of the information structure invites the idea of managing the material with database management system. The initial goal of the second edition is to develop precisely such a database; the second edition may or may not appear as a book.
This paper describes three of the technical challenges faced by the project and our experiences using XML technologies to address those challenges:
-
Translating the data used to typeset the first edition into a format suitable for work on the second edition.
This in turn requires that we identify or design the desired target format.
-
Providing secure distributed editing facilities.
-
Providing suitable query interfaces.
This is complicated by the uncertain and fragmentary nature of the information in the database.
The project poses a few organizational challenges, which should perhaps be described because they provide the context for the solution of the technical problems. Like many academic projects, TLRR has rather spotty resources: there is no central grant funding for the project, so each participant is self-funded. There is no money to speak of for infrastructure or technical consulting; the technical work is being done pro bono by the author of this paper, and the project's web presence piggy-backs on an existing contract for shared Web hosting, which means that ideally we want software that can run in a shared hosting environment. (Moving to a virtual private server is not out of the question, but would increase Web hosting costs by about an order of magnitude.)
Because the work is essentially being done on a volunteer basis, resources tend also to be intermittent: each participant will have spells during which they can devote a lot of time to TLRR, alternating with spells during which they must neglect it in order to deal with other demands.
These organizational challenges constrain our technical approach. Our technical solutions must be inexpensive in money, because the project doesn't have any money. Ideally, they will also be inexpensive in time, but this desideratum stands in tension with the requirement that our technical solutions must be interesting, in order to motivate the volunteer technical labor. Since doing new things for the first time is often more interesting than doing again things one has done many times before, and since doing new things tends to expose the work to the danger of surprises and uncertain schedules, the desire that the work be interesting may conflict with the desire for it to be inexpensive in time as well as in money. There is also some potential here for a conflict of interest between the participating historians, who just need technology that will help them do their job, and those providing the technical infrastructure, who want to learn something from the technical work.
The technical problems of TLRR may be of general interest, and TLRR is in some ways an ideal case for exploring different approaches to those technical problems. In the terminology introduced by Lubell 2014, TLRR is a SAND: a small, arcane, non-trivial dataset. The data have intrinsic interest not only for specialists but (because they show interesting causes of conflict and misbehavior in ancient Rome) to others; for specialists in Roman legal history, however, the data are particularly important. Several problems which are peculiarly acute for TLRR (and thus cannot easily be evaded) are also found in many other projects:
-
The data are incomplete.
We do not have court records for this period; the information we have is from letters, collections of legal speeches, remarks by historians, and so on. Sometimes we know the charge and the name of the prosecutor, but not the name of the defendant. Sometimes we know the names of two opposing parties in a civil case, but not who was plaintiff and who was defendant. And so on.
-
The data are often uncertain.
Partly because the records are so incomplete, and partly because the existing evidence can often be interpreted in multiple ways, there are varying degrees of certainty about crucial details. Some dates (for example) can be quite precise: trial 208 took place in
summer of 65
BC. Others are equally precise, though less certain: trial 8 is dated138?
. Others will be less precise: trial 161 is datedbetween 74 and 70
, trial 373between 81 and 43
. Some trials have a bound only at one end:before 63
(trial 219),after 98
(trial 82). Some have more complex dating information:possibly before case #327, certainly just before case #326
(trial 325). Still other trials cannot be dated at all.[1]Sometimes the only thing we (believe we) know about the defendant's advocate is that it was not Cicero (trial 212).
-
In consequence, much of the information in the database needs annotation and qualification. Why do we think this trial took place at this time? And just how certain are we about the identity of the prosecutor or the nature of the charge?
In printed material, this kind of qualification and annotation is handled with footnotes and carefully crafted prose; relational databases don't have a promising history when it comes to attaching footnotes to atomic values.
-
The TLRR database is not (and should not be) an island.
Many of the people, places, and textual sources mentioned in the database are also of concern to other projects; there is a natural desire to be able to link from a trial involving Publius Quinctius (16) to the relevant entry in a digitized form of Pauly/Wissowa, or to the entry in the new Prosopography of the Roman Republic. When the details of a trial are based on the account offered by Tacitus in his Annals, it would be convenient to be able to traverse directly to the relevant passage in a good online edition of Tacitus.
-
Many projects have resources which feel sparse (at least to the project; from outside, of course, things often look rosy).
-
The project team is geographically distributed.
No two participants in the project are in the same city, and few (two pairs of two) are in the same country. Techniques for database management that work with a geographically concentrated team won't work with such a dispersed team.
-
There is already a fully worked out presentation of data of this kind.
The goal of the technical work on TLRR is to support the information gathered by the authors in its full complexity, without forcing simplifications for the sake of the technology. As a rough rule, this has been taken to mean that the representation we choose for the second edition should be able to represent the first edition as well, without requiring any changes in structure or approach. If in the first edition it was found necessary to provide annotation recording the rationale for a given datum, then the second edition should be free to provide similar rationales (or to retain those of the first edition). The design must not force a simplification of the structure, or suppress any relevant information.[2]
Translation into desired format
Before work on the electronic second edition can start, the data used to typeset the first edition must be translated into a format suitable for work on the second edition. This requires that the target format be defined, which in turn requires a careful analysis of the information structure, and a choice of underlying technology (e.g. relational dbms vs XML database). These questions are all deeply intertwingled.
The analysis of information structure might in theory be independent of technology. But in order to specify a target format concretely, it seems in practice to be necessary to have chosen the technology to be used.[3]
Choice of technology
We use XML for reasons which will not surprise attendees at Balisage: device- and application-independence, reusability, longevity of data. Our document grammars will be specified in DTD, Relax NG, and XSD. We use XSLT for the initial translation into XML, XSLT and XQuery for most data-manipulation tasks. We use XForms for our editing interfaces. And we provide public access to TLRR1 and project-only access to the in-progress version of TLRR2 using an XForms-based search interface, an XQuery back end, and XSLT stylesheets to style the results.
Other technologies could (at least in principle) be used. The first edition was done with a batch formatter; batch formatters still exist. Waterloo Script might be hard to run today, but TeX and LaTeX still produce many pages every year. A more modern equivalent to a batch formatter, though, would be to prepare the book in a word processor. Unfortunately, the search possibilities of word-processor data tend to be limited, unless the authors are supernaturally disciplined in the use of stylesheets. Many projects over the years have attempted to use descriptive markup by means of styles in word processors; many more have tried this approach than have succeeded in making it work. (It's possible that the number of successes is greater than zero, but I have no evidence for that proposition.) Also, word processor files don't lend themselves very well to distributed work (although cloud-based systems like Google Docs apparently allow much better distributed authorship than desktop word processors). And neither batch formatters nor more modern word processors have good facilities for the kind of consistency checking needed for a project like this.
All in all, neither batch formatters nor word processors seem to be a good solution for this project.
Some group-authorship projects develop their documents using wikis. Wikis have the advantage that they are built for distributed authorship, and wiki software generally comes with well tested tools for reviewing the history of changes and reverting changes made in error. Many people also believe that wiki markup is less intimidating than XML, easier to learn, and easier to use. (Attendees at Balisage may be inclined to doubt these claims,[4] but that wiki markup is less intimidating to some people can hardly be doubted.)
And wikis are so well established that if a distributed project can agree on conventions for important classes of information (in the case of TLRR, that would include marking the boundaries of fields and so on), using a wiki can reduce training and development costs a great deal.
As it turns out, however, not a single person in the TLRR2 project other than the current author admits to any famiiliarity at all with wikis, or with the use of wiki markup. Wikis remain a fallback to be considered if we cannot get the XML infrastructure to a sufficiently complete state in a reasonable amount of time, but we have chosen to prefer XML over wikis for our work.
The most serious alternative to XML for this project is a relational database. These are ubiquitous and very well tested. They have very good support for consistency checking, for distributed work, and for arbitrarily complex and subtle query and retrieval. But they have poor support for partial and uncertain data (not much worse than anything else, of course, but relational technology is not in itself helpful with these problems) and very poor support for structurally complex (i.e. irregular) data.
A simple sketch of a relational model for TLRR produces
five distinct tables for entities (for trials, persons,
causes of action, ancient sources, and modern secondary
literature).
Figure 1 Figure 2

Other problems arise in designing a format for the data.
-
In display, each field is labeled; usually the label is the name of the field, but sometimes it varies:
prosecutor
when there is one,prosecutors
when there are two or more. The presiding magistrate may be labeledjudge
,praetor
,urban praetor
,peregrine praetor
,iudex quaestionis
, etc., etc. -
Some but not all advocates are known to have spoken for the defendant; others for the plaintiff. Sometimes, we don't know for whom they spoke.
-
The date value (as already illustrated) is not always a year, nor a year range.
-
Every field may have one or more end-notes.
Up-translation and the hermeneutic circle
In the first edition, a sample trial (trial 1) looks like this:
Figure 3
field
, if we allow ourselves to use
the world field a bit loosely)
begins on a line of its own, with a label and a colon.
Footnotes point to supporting evidence for some values.
Each named individual is identified by name, followed by a
number in parentheses, which indicates the number of the
individual's article in Pauly/Wissowa 1894-1980.[6]
The (58)
after the name of Servius Sulpicius Galba,
for example, indicates that his is the fifty-eighth
sub-entry in RE under
Sulpicius; the numbers thus provide
a convenient ways of distinguishing different people with
the same name. In addition, for members of the senatorial class
the date at which they were consul is given (or, if they did not
become consul, the date of the highest office they attained
is given); in addition, if they held office in the year of the trial,
that office is given (as here for Lucius Scribonius Libo, who
was tribune of the people during the year 149).
The first edition of TLRR was prepared using Waterloo Script/GML, a batch formatter widely available on IBM mainframes installed in North American academic settings.[7] In the Waterloo Script source, the first trial looks like this:
.chapter
.sr ZAA = &chapter
.br
.hi +2
date: 149
:EN.On the date see Cic%
:hp1.Att%:ehp1.
12.5b.
:eEN
.br
.ix 1 "&'italic('quaestio extraordinaria')" . &ZAA
charge:
:hp1.quaestio extraordinaria:ehp1.
(proposed)
:EN.See Douglas, :hp1.Brutus:ehp1. p. 77.
:eEN
(misconduct as gov. Lusitania 150)
.br
.ix 2 'Sulpicius (^>58), Ser. Galba' . &ZAA
defendant: Ser. Sulpicius Galba (^>58) cos. 144 spoke
:hp1.pro se:ehp1.
(:hp1.ORF:ehp1. 19.II, III)
.br
.ix 3 'Fulvius (^>95), Q. Nobilior' . &ZAA
advocate: Q. Fulvius Nobilior (^>95) cos. 153, cens. 136
.br
.ix 4 'Cornelius (^>91), L. Cethegus' . &ZAA
prosecutors:
.in +2
L. Cornelius Cethegus (^>91)
.br
.ix 4 'Porcius (^>^>9), M. Cato' . &ZAA
M. Porcius Cato (^>^>9) cos. 195, cens. 184 (:hp1.ORF:ehp1. 8.LI)
.br
.ix 4 'Scribonius (^>18), L. Libo' . &ZAA
L. Scribonius Libo (^>18) tr. pl. 149
(:hp1.promulgator:ehp1.)
.in
outcome: proposal defeated
.hi off
.sk 1
Cic%
:hp1.Div% Caec%:ehp1.
66;
:hp1.Mur%:ehp1.
59;
:hp1.de Orat%:ehp1.
1.40, 227-28; 2.263;
:hp1.Brut%:ehp1.
80, 89;
:hp1.Att%:ehp1.
12.5b;
Liv% 39.40.12;
:hp1.Per%:ehp1.
49;
:hp1.Per. Oxy%:ehp1.
49;
Quint. :hp1.Inst.:ehp1. 2.15.8;
Plut%
:hp1.Cat. Mai%:ehp1.
15.5;
Tac%
:hp1.Ann%:ehp1.
3.66;
App%
:hp1.Hisp%:ehp1.
60;
Fro%
:hp1.Aur%:ehp1.
1. p. 172 (56N);
Gel. 1.12.17, 13.25.15; see also V. Max. 8.1. abs. 2;
[Asc.] 203St;
:hp1.Vir. Ill%:ehp1.
47.7
.br
Ferguson (1921); see also Buckland (1937);
Richardson (1987) 2 n. 12
.sk
:ENDNOTES
For those who have never worked with Waterloo Script or any similar batch formatter, a partial glossary may be in order:
-
.chapter=Start a new chapter
(user-defined command) -
.sr ZAA = &chapter=Set the reference
ZAAto refer to the current chapter number. -
.br=line break
-
.hi +2=start a hanging indent of 2 characters
-
date: 149(actual text) -
:EN.On the date see Cic% :hp1.Att%:ehp1. 12.5b. :eEN=end-note, with the contents indicated
[here%=.
; a literal full stop cannot be used here because it is GML's default tag-close delimiter] -
:hp1.Att%:ehp1.=highlighed phrase
[again%=.
] -
.ix 1 "&'italic('quaestio extraordinaria')" . &ZAA=Add an entry to index number 1, under the heading quaestio extraordinaria, pointing (by number) to trial ZAA
-
.ix 2 'Sulpicius (^>58), Ser. Galba' . &ZAA=Ditto, for index 2 and the entry Sulpicius (58), Ser. Galba
[^= one-en space,>= backspace] -
.hi off=turn hanging indent off
-
.sk 1=skip one line
-
:ENDNOTES=Put the accumulated end-notes here
Finding a suitable representation of this material for database query and retrieval, and for work on TLRR2, requires a more or less standard process of document analysis, in which we try to identify the information present at a level more abstract than what characters are in bold or italic and what strings go into which indexes, the different forms information of each kind can take, and what rules might be able to distinguish correctly entered information from nonsense.
With a view towards the expected uses of the data, the technical work on the TLRR project has devoted particular attention to questions of display (at a minimum, we should be able to recreate the formatting of the first edition in its essentials), query (on which see below), and the connection of the information to other resources (for later hyperlinking).
At this point, however, we encounter a chicken-and-egg problem. To design the target XML format, so that we can create a database, we need to understand the data and know what's actually present, in what form(s). To discover what is present, we need to be able to search it effectively (TLRR provides many illustrations of the principle that one must know the data). String search goes only so far in a format like that of TLRR1. To search the data, we need to translate it into XML so that we can load it into an XML database. To translate the data into XML, we need to design a target XML format.
This chicken-and-egg problem is easily recognized as a computational form of the hermeneutic circle, and we solve it in an analogue of the time-honored way: we make a few assumptions which seem sound, and see where they lead us; based on what we learn, we revise and expand our assumptions and repeat the process. Concretely, the first step towards the XML form of TLRR2 is a direct one-to-one translation of the Waterloo Script input to XML equivalents.
<trial id="ZAA">
<?WScript .sr ZAA = &chapter?>
<br/>
<?WScript .hi +2?>
date: 149<en>On the date see Cic.
<hp1>Att.</hp1> 12.5b.</en>
<br/>
<ix n="1" target="ZAA"><ital>quaestio extraordinaria</ital></ix>
charge: <hp1>quaestio extraordinaria</hp1>
(proposed)<en>See Douglas, <hp1>Brutus</hp1> p. 77.</en>
(misconduct as gov. Lusitania 150)
<br/>
<ix n="2" target="ZAA">Sulpicius (+58), Ser. Galba</ix>
defendant: Ser. Sulpicius Galba (58) cos. 144 spoke
<hp1>pro se</hp1> (<hp1>ORF</hp1> 19.II, III)
<br/>
<ix n="3" target="ZAA">Fulvius (+95), Q. Nobilior</ix>
advocate: Q. Fulvius Nobilior (95) cos. 153, cens. 136
<br/>
<ix n="4" target="ZAA">Cornelius (+91), L. Cethegus</ix>
prosecutors:
<?WScript .in +2?>
L. Cornelius Cethegus (91)
<br/>
<ix n="4" target="ZAA">Porcius (++9), M. Cato</ix>
M. Porcius Cato (9) cos. 195, cens. 184 (<hp1>ORF</hp1> 8.LI)
<br/>
<ix n="4" target="ZAA">Scribonius (+18), L. Libo</ix>
L. Scribonius Libo (18) tr. pl. 149
(<hp1>promulgator</hp1>)
<?WScript .in?>
<br/>
outcome: proposal defeated
<?WScript .hi off?>
<?WScript .sk 1?>
<p>
Cic. <hp1>Div. Caec.</hp1> 66;
<hp1>Mur.</hp1> 59;
<hp1>de Orat.</hp1> 1.40, 227-28; 2.263;
<hp1>Brut.</hp1> 80, 89;
<hp1>Att.</hp1> 12.5b;
Liv. 39.40.12;
<hp1>Per.</hp1> 49;
<hp1>Per. Oxy.</hp1> 49;
Quint. <hp1>Inst.</hp1> 2.15.8;
Plut. <hp1>Cat. Mai.</hp1> 15.5;
Tac. <hp1>Ann.</hp1> 3.66;
App. <hp1>Hisp.</hp1> 60;
Fro. <hp1>Aur.</hp1> 1. p. 172 (56N);
Gel. 1.12.17, 13.25.15;
see also V. Max. 8.1. abs. 2;
[Asc.] 203St;
<hp1>Vir. Ill.</hp1> 47.7
<br/>
Ferguson (1921); see also Buckland (1937);
Richardson (1987) 2 n. 12
</p>
<?WScript .sk?>
</trial>
In this XML form, each GML tag from the Waterlook Script GML gdoc
vocabulary has been translated into an equivalent XML tag. The simplest and most common
Script instructions (.br for a forced line break and .ix for an
index entry) have been represented by new XML elements named br and
ix, respectively. The formatting function &'italic() has
been translated into an ital element. Other Waterloo Script instructions have
been represented by processing instructions labeled WScript. (In the ideal case, the
processing instructions should not be needed and can be filtered out, but until it
has been
established that all the important information has been captured in XML elements and
attributes, they should be kept around, in case they turn out to convey critical
information, e.g. about element boundaries.)
This print-oriented XML format is not in itself very useful, but it allows XML tools to be applied: in particular, XPath, XQuery, and XSLT. Using a simple XSLT stylesheet it's possible to replicate the basic formatting of the printed TLRR1; the success of this effort helps to make plausible the proposition that the translation into XML has not lost any essential information. And using an interactive XQuery interface it's possible to query the data to find patterns and check our understanding of the patterns.
On the basis of that understanding, we can begin the design of an XML vocabulary.
The vocabulary design(s)
The development of the TLRR vocabulary is an iterative process. Starting from a given XML form, we examine the data looking for useful patterns visible in the data but not well captured by the markup. Given a potential pattern, we look for instantiations of the pattern and for counter-examples. Once a pattern is reasonably well understood, an XML representation for the pattern is designed and an XSLT stylesheet is written to translate from the previous XML form to the new XML representation.
Concretely, there have been several XML forms so far; we believe we are nearing an acceptable form, but at the time this paper was written, we had not yet arrived at that destination. The stages of stepwise refinement thus far visited are:
-
The
, that is the direct translation from Waterloo Script + GML into XML shown above.gdocXML form -
A
fielded XML form
, in which each labeled field in the input is enclosed in an XML element, as are the lists of ancient sources and of modern secondary literature.This format (shown below) already makes possible more interesting query interfaces and displays.
-
A
named-entity form
, in which all people and causes of action (charges, claims, legal proceedings) in the database are identified and represented in stand-alone XML documents with unique identifiers, and all references to them from trials are recognized and tagged as such. Since the references retain their full content in this form, this form has a good deal of redundancy. In fact it has even more redundancy than the original, since we have added the additional stand-alone representations of people and procedures. -
A
normalized form
, in which references to people and causes of action are reduced to their essential information, normally the unique identifier of the entity. In cases where the reference differs from the usual form, the historians in the project will need to decide whether the reference is an error or a context-dependent variation that is not an error.Context-dependent variation can be handled by making the reference be either empty (in which case the form of reference is to be taken from the stand-alone document) or non-empty (in which case the content of the reference is taken to be a context-dependent variant of the usual form).[8]
-
A form in which the fields which can contain lists of names are given markup that reflects the list structure.
Still to come at this writing, but expected to be in the past by the time of Balisage, are two further forms:
-
A form in which the date field is more highly structured than at present.
In TLRR1, any field whose information takes an unusual form can and does resort to English prose to describe the situation. This complicates both the editing of fields and the construction of a query interface. The goal of this form will be to represent the usual case with relatively structured XML elements, while still allowing unusual cases, which will be tagged differently, to allow special treatment in editors and queries.
The fielded form
The first step past the gdoc version of the data
in XML form is to recognize all field labels; because labels
vary a good deal (singular, plural; different Latin terms
for the role played, case-specific descriptions), this took
several passes to get right. In the simple case, a simple
regular-expression search in a text node will find the
label. The first version of the stylesheet recognized all
field labels spelled with a single word in Roman type, the
most common italicized labels of a single word, and the most
common multi-word labels; later versions added one by one to
the collection of labels recognized.
Labels containing a mixture of roman and italic type
required particular attention. In the end, it proved
possible to look for yet-unrecognized labels by searching
for text nodes which contained colons and which were not
descendants of the en (end-note) element. This
search uncovered the use of the labels witnesses (in
first actio)
and witnesses (to be heard
in second actio)
in trial 177.
In the course of this work, it became clear that in many
trials, the sequence of fields given did not agree with the
sequence described in the introduction to TLRR1. There, the
list of fields gives the order date, charge or claim,
defendant, advocates, prosecutor or plaintiff, presiding
magistrate, jurors, witnesses, ... But in some trials, an
advocate may be listed after, not before, the plaintiff; in
some, a witness may be listed before the plaintiff. Upon
inspection, it proved that TLRR1 places closely related
fields together, to create larger (implicit) groups of
fields. In particular,
advocates and
witnesses who appear specifically for the defendant
are grouped with the
defendant; if the plaintiff also has an advocate, it will be
listed after the plaintiff, not before. (Prosecutors in
criminal cases apparently never have advocates in this
material, only plaintiffs in civil cases.)
The implicit groupings of TLRR1 have been made
explicit in the fielded XML by introducing the elements
defGrp,
ppGrp, and analogous grouping
elements for other fields.
Since fields are marked in the input only at the
beginning of the field and end when the next field begins,
the XSLT 2.0 for-each-group construct proved very
helpful here. In a first step, milestone elements were
injected into the trial record to mark the beginnings of
fields; in a second step, the material in a trial was
grouped by milestone elements and the groups were tagged as
fields. In a third step, sequences of related fields were
grouped at a higher level; elements defGrp and
ppGrp (defendant's group and plaintiff or
prosecutor's group) were introduced to group all the members
of an identifiable party
in the case.
The indexing instructions (retained until the tagging has been further refined) proved to be a remarkable complication, since they often but not always precede rather than follow the label for the field to which they logically belong, and they clutter the XML.
The stylesheet is available for inspection on the
project's web site; the fielded data
which
is the output of this pass on trial 1 is as follows.
<trial id="ZAA" tlrr1="1" sortdate="">
<date>149<en>On the date see Cic. <i>Att.</i> 12.5b.</en>
<ix n="1" target="ZAA"><i>quaestio extraordinaria</i></ix>
</date>
<ccGrp>
<charge><i>quaestio extraordinaria</i>
(proposed)<en>See Douglas, <i>Brutus</i> p. 77.</en>
(misconduct as gov. Lusitania 150)
<ix n="2" target="ZAA">Sulpicius (+58), Ser. Galba</ix>
</charge>
</ccGrp>
<defGrp>
<defendant>Ser. Sulpicius Galba (58) cos. 144 spoke
<i>pro se</i> (<i>ORF</i> 19.II, III)
<ix n="3" target="ZAA">Fulvius (+95), Q. Nobilior</ix>
</defendant>
</defGrp>
<advGrp>
<advocate>Q. Fulvius Nobilior (95) cos. 153, cens. 136
<ix n="4" target="ZAA">Cornelius (+91), L. Cethegus</ix>
</advocate>
</advGrp>
<ppGrp>
<prosecutor label="prosecutors">L. Cornelius Cethegus (91)
<br/><ix n="4" target="ZAA">Porcius (++9), M. Cato</ix>
M. Porcius Cato (9) cos. 195, cens. 184 (<i>ORF</i> 8.LI)
<br/><ix n="4" target="ZAA">Scribonius (+18), L. Libo</ix>
L. Scribonius Libo (18) tr. pl. 149
(<i>promulgator</i>)
</prosecutor>
</ppGrp>
<outcome>proposal defeated</outcome>
<sources>
<ancient>
Cic. <i>Div. Caec.</i> 66;
<i>Mur.</i> 59;
<i>de Orat.</i> 1.40, 227-28; 2.263;
<i>Brut.</i> 80, 89;
<i>Att.</i> 12.5b;
Liv. 39.40.12;
<i>Per.</i> 49;
<i>Per. Oxy.</i> 49;
Quint. <i>Inst.</i> 2.15.8;
Plut. <i>Cat. Mai.</i> 15.5;
Tac. <i>Ann.</i> 3.66;
App. <i>Hisp.</i> 60;
Fro. <i>Aur.</i> 1. p. 172 (56N);
Gel. 1.12.17, 13.25.15;
see also V. Max. 8.1. abs. 2;
[Asc.] 203St;
<i>Vir. Ill.</i> 47.7
</ancient>
<modern>
Ferguson (1921); see also Buckland (1937);
Richardson (1987) 2 n. 12
</modern>
</sources>
</trial>
The presence of explicitly marked fields in this
form makes possible simple field-limited searches like
Figure 4find Sulpicius Galba as a defendant
. It
also makes it possible for a query interface to
accept multiple search words and give priority to
results in which all search words are found within
the same field, over records in which one search
term is found in one field, and another in a different
field. In the query interface shown below, the
fields are also color-coded; this may help experienced
users focus more quickly on the part of the record
they are most interested in at the moment, but its
initial motivation was just making it easier to check
whether the field boundaries produced by the
XSLT transformation described above had produced
the correct results or not.
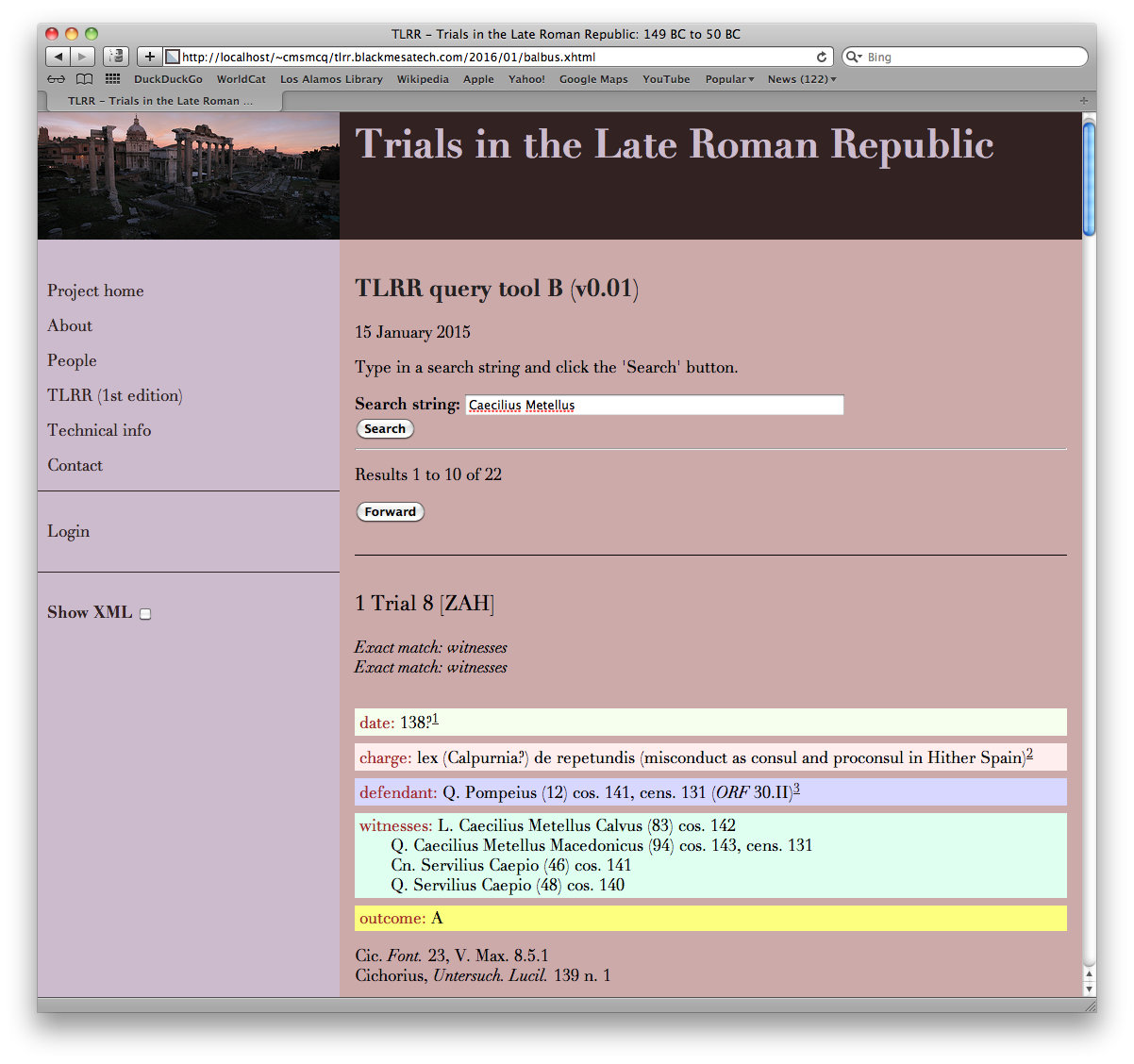
Recognizing people and procedures
The next step is to prepare for normalizing the data by
recognizing and tagging all references to persons and all
references to legal charges, claims, laws, particular
courts, or special legal procedures (all given, depending
on the case, in the field normally labeled charge
or claim
, and grouped togther by the index in TLRR1
under the umbrella term
procedures).
In unrestricted prose text (or even in prose with
highly conventional idioms like Wall-Street-Journal stories),
named-entity recognition is a very challenging undertaking.
It should be less daunting here,
since the input contains indexing instructions
for persons and procedures. The ix elements
tell us what named entities have already been registered
here; all we have to do is find them in a the text.
We can search the relevant fields
for occurrences of the character string in question and
tag it as a person or a procedure.
The first wrinkle here is that the text uses
the conventional order for the parts of a name:
praenomen, nomen,
cognomen (e.g. Q. Fulvius Nobilior (95)
),
but the index uses an inverted order
nomen,
praenomen,
cognomen
(Fulvius (+95), Q. Nobilior
)
in order to obtain the desired alphabetical sequence of names.
But it is straightforward to read the index instruction,
identify the parts of the name, reorder them, and
look for the resulting character string in the data.
At least, that is, for men of the upper classes, with
conventional names. There prove to be a number of
exceptions to the rule that every Roman has
a nomen and praenomen
and that almost every Roman has a cognomen,
and the name parsing routines must be adjusted to account
for them.
After a first round of named-entity recognition, trial 1 is marked up as follows:
<trial id="ZAA" tlrr1="1" sortdate="-0149">
<date>149<en>On the date see Cic. <i>Att.</i> 12.5b.</en>
<ix n="1" target="ZAA"><i>quaestio extraordinaria</i></ix>
</date>
<ccGrp>
<charge>
<i><procedure pid="c-quaestio_extraordinaria" lang="lat"
>quaestio extraordinaria</procedure></i>
(proposed)<en>See Douglas, <i>Brutus</i> p. 77.</en>
(misconduct as gov. Lusitania 150)
<ix n="2" target="ZAA">Sulpicius (+58), Ser. Galba</ix>
</charge>
</ccGrp>
<defGrp>
<defendant>
<person pid="pSulpicius58Ser.Galba"
ix="Sulpicius (+58), Ser. Galba"
>Ser. Sulpicius Galba (58)</person> cos. 144
spoke <i>pro se</i> (<i>ORF</i> 19.II, III)
<ix n="3" target="ZAA">Fulvius (+95), Q. Nobilior</ix>
</defendant>
</defGrp>
<advGrp>
<advocate>
<person pid="pFulvius95Q.Nobilior"
ix="Fulvius (+95), Q. Nobilior"
>Q. Fulvius Nobilior (95)</person> cos. 153, cens. 136
<ix n="4" target="ZAA">Cornelius (+91), L. Cethegus</ix>
</advocate>
</advGrp>
<ppGrp>
<prosecutor label="prosecutors">
<person pid="pCornelius91L.Cethegus"
ix="Cornelius (+91), L. Cethegus"
>L. Cornelius Cethegus (91)</person>
<br/>
<ix n="4" target="ZAA">Porcius (++9), M. Cato</ix>
<person pid="pPorcius9M.Cato" ix="Porcius (++9), M. Cato"
>M. Porcius Cato (9)</person> cos. 195, cens. 184
(<i>ORF</i> 8.LI)
<br/>
<ix n="4" target="ZAA">Scribonius (+18), L. Libo</ix>
<person pid="pScribonius18L.Libo" ix="Scribonius (+18), L. Libo"
>L. Scribonius Libo (18)</person> tr. pl. 149
(<i>promulgator</i>)
</prosecutor>
</ppGrp>
<outcome>proposal defeated</outcome>
<sources>
<ancient>
Cic. <i>Div. Caec.</i> 66;
<i>Mur.</i> 59;
<i>de Orat.</i> 1.40, 227-28; 2.263;
<i>Brut.</i> 80, 89;
<i>Att.</i> 12.5b;
Liv. 39.40.12;
<i>Per.</i> 49;
<i>Per. Oxy.</i> 49;
Quint. <i>Inst.</i> 2.15.8;
Plut. <i>Cat. Mai.</i> 15.5;
Tac. <i>Ann.</i> 3.66;
App. <i>Hisp.</i> 60;
Fro. <i>Aur.</i> 1. p. 172 (56N);
Gel. 1.12.17, 13.25.15;
see also V. Max. 8.1. abs. 2;
[Asc.] 203St;
<i>Vir. Ill.</i> 47.7
</ancient>
<modern>
Ferguson (1921);
see also Buckland (1937);
Richardson (1987) 2 n. 12
</modern>
</sources>
<revisionHistory>
<change date="2016-02-13T19:18:15.929-07:00"
who="CMSMcQ"
>extract this entry from entity-tagged version of TLRR1</change>
</revisionHistory>
</trial>
The second wrinkle (not visible in the example shown)
is that in a surprising number of cases (surprising to the
programmer, at least) the string search fails to locate
the appearance in the text of the person or procedure
named in the index entry. Analysis of some cases (aided
by a simple search for all records containing an
unmatched-index-entries element) shows
a variety of causes.
-
Trials may involve individuals not mentioned in RE. In trial 372, for example, the index entry whose string value is
Octavius (not in RE)
is not found in any single text node, because the name is marked up asOctavius (not in <i>RE</i>). -
In many criminal cases, it's clear that the charge was electoral corruption (ambitus), but there may be some uncertainty as to whether the charge was laid under the lex Cornelia de ambitu, the lex Servilia de ambitu, the lex Calpurnia de ambitu, etc. In other cases, the specific law is known. When the specific law under which the charge was brought is identifiable from the sources, TLRR1 provides index entries both for the specific law and for the general concept of ambitus. The nominative form ambitus found in the index entry does not occur in the names of laws (where it is inflected as the object of the preposition de), so the string search fails.
The same issue arises for several other common charges.
-
When the precise law appealed to is uncertain, the text often indicates it with a question mark; the index entry
lex Cornelia de aleatoribus
, for example, corresponds to the textual entrylex Cornelia? de aleatoribus
; the question mark in the text defeats a straightforward string search. -
Sometimes the textual entry gives two RE numbers, not just one. In Trial 369, the person indexed as
Cornelius (194), L. Lentulus
is referred to in the text asL. Cornelius Lentulus (194, cf. 195)
. -
The relation between the text form of a name and the index form is sometimes complicated, and the algorithm generates the wrong form to search for. In trial 150, the person indexed as
Staienus (1), C. Aelius Paetus
is not named in the text asC. Staienus (1) Aelius Paetus
(as the normal parsing algorithm would expect) but asC. Aelius Paetus Staienus (Staienus [1])
. It is currently unclear whether this reflects a more subtle but still algorithmic pattern or whether this and other cases are simply exceptions that need to be handled individually. -
When ancient sources identify a person using two name forms, TLRR1 typically indexes both; in trial 376, the text refers to
Cn. Decidius (or Decius?), Samnis (1)
, who is indexed under both possible forms of name (Decidius (1), Cn. Samnis
,Decius (1), Cn. Samnis
); neither index form appears literally in the text. -
In a few cases, the index form does appear literally in the text, but is interrupted by a footnote. In trial 318, for example, Titus Fadius is indexed as
Fadius (9), T.
and the text's reference to him reads:<defGrp> <defendant>T. Fadius<en>His <i>cognomen</i> is probably not ‘Gallus’; see Shackleton Bailey (1962) and <i>Studies</i> 38, and <i>MRR</i> Suppl. 89. </en> (9) tr. pl. 57<en>Shackleton Bailey, <i>CLF</i> 1.350 suggests that he became aedile and/or praetor 55-53.</en> </defendant> </defGrp>
At the current writing, names and procedures presenting the problems just listed have not yet been successfully recognized and tagged. (In the case of generic procedures like ambitus, it's not yet clear whether they should be, or whether the additional index entry for ambitus should be handled by information in the procedure records for the individual laws in question.) It should be possible to recognize them by moving beyond a string search in a single text node to a more complicated but also more powerful matching method loosely based on Brzozowski derivatives, which uses a recursive function which keeps track of what has been matched and what remains to be matched and which can skip over footnotes, question marks, and start- and end-tags for italics. That should handle many, though not all, of the cases thus far identified.
Normalization
The next step foreseen (not yet performed) is to normalize the data further. As can be seen in the examples given so far, references to persons normally are accompanied by information about the offices they held (either at the peak of their political career or at the time of the trial). Specifying twice that Servius Sulpicius Galba served as consul in 144 is an unnecessary redundancy; normal database design would seek to reduce that redundancy by recording it just once, in a record devoted to the individual, and then referring to that record from both trials (1 and 10) in which he appears.
In the current design of the database, the
person record for Ser. Sulpicius Galba
should look like this:
<person id="pSulpicius58Ser.Galba">
<nomen>Sulpicius</nomen>
<RE>58</RE>
<praenomen>Ser.</praenomen>
<cognomen>Galba</cognomen>
<rs/>
<indexform>Sulpicius (+58), Ser. Galba</indexform>
<textform>Ser. Sulpicius Galba (58)</textform>
<offices>cos. 144</offices>
<revisionHistory>
<change date="2016-02-13T18:48:41.296-07:00"
who="CMSMcQ"
>extract this entry from entity-tagged version of TLRR1</change>
<change date="2016-02-13T17:12:06.567-07:00"
who="CMSMcQ"
>analyse name parts using pattern re-person in tlrr.ner.xsl</change>
</revisionHistory>
</person>
(In the current state of the database, it should be noted,
the offices element is empty, because the
redundancies have not yet been successfully removed.)
Similarly simple stand-alone records will be provided for procedures (charges, claims, and laws), courts (e.g. the quaestio extraordinaria shown in the examples above)[9], ancient sources, and modern (secondary) sources.
The result is that the overall design of the XML database will resemble that shown in the figure used above to illustrate a potential relational model for the material. It does not currently appear that the six-way join made necessary by this normalization will pose performance issues on so small a database; it remains to be seen how badly it will complicate the construction of queries.
It might prove more convenient to embrace the redundancy
shown (subject to some revision of the markup structures, as
described below) and control it by making it easy, when
consulting the record for an individual person, law, court,
etc., to see exactly the terms in which it is referred to
from records for trials; this should make it easier to keep
all references consistent, while still allowing queries for
trials to return trial elements without having to
transform them by expanding the references to persons,
courts, etc.
Editing interface(s)
One of TLRR's key points of interest for practitioners of XML technology is that it allows the direct comparison of several different approaches to the distributed collaborative editing of XML documents. The consistent structure of trial records in the database make a forms-based approach to editing (not at all unusual for relational databases) an obvious choice. An obvious candidate for the implementation of that interface (particularly given the requirement for distributed editing, which in practice means Web-based editing) is XForms.
The current plan for TLRR is to use XForms to make it
possible for the historians in the project to edit records in
the database. The shared hosting environment within which we
operate offers Subversion repositories as a standard feature
and allows Subversion to be configured to accept requests
using a WebDAV (Web distributed authoring and versioning)
interface, notably including PUT requests, which
are straightforward to make from XForms. (The situation varies
from server to server, of course, but software which supports
WebDAV appears to be one of the most straightforward ways of
making a Web server accept PUT requests.)
The current form of the editor for trials shows all
of the existing data in the trial in read-only form, with
buttons for editing an existing field or for adding a
field not yet present.[10]
Figure 5: XForm for trials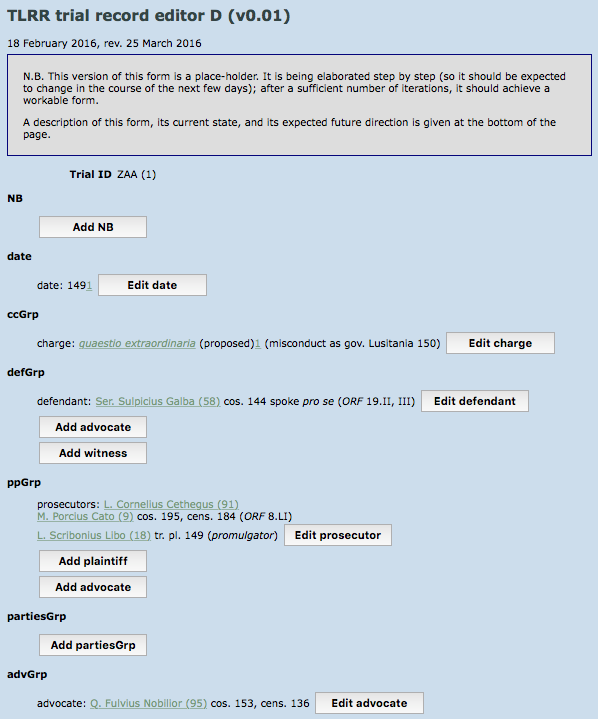
XForms can readily handle many of the obvious constraints in the normalized design of the database. At a first approximation, these include:
-
The
dateelement can take any of several forms: a simple date, a terminus ante quem (before X), a terminus a quo (after Y), a date range. Dates may be uncertain (e.g. marked with a?
), and about one date in four will have a footnote. -
The
chargeorclaimelement should contain a reference to aprocedurerecord, possibly accompanied by an end-note. -
The
defendant,prosecutor/plaintiff,advocate,judge,juror, andwitnesselements should contain one or more references to persons. -
The lists of ancient sources and modern scholarly literature should consist of a series of references to known sources.
XForms can easily allow selection from controlled
lists of values (e.g. names of courts for which the database
has a court record, names of persons for which
we have a person record, ...). This reduces
the need to retype names and references, and helps
reduce the incidence of typographic error. XForms can
also exploit various inter-element dependencies (in
a criminal case, with a prosecutor, any
advocate will have spoken for the defense; the prosecutor
serves as his own advocate).
But there are of course complications. Dates can take a
bewildering variety of forms. As the examples above show,
references to individuals may have additional case-specific
information. (Trial 1 has simple unadorned references to the
advocate Quintus Fulvius Nobilior and the prosecutor Lucius
Cornelius Cethegus. But the reference to the defendant is
accompanied by the notation spoke pro se
(ORF 19.II, III)
, which tells us that
Sulpicius spoke on his own behalf and that at least parts of
his speech are preserved and have been published in the
collection Oratorum Romanorum Fragmenta
(Fragments of Roman orators
); the prosecutor M.
Porcius Cato has a similar notation. And the prosecutor L.
Scribonius Libo is noted to have served in a specific legal role
(promulgator) in this case.
So a simple pull-down menu from which the user can choose the name of a known person will not suffice for TLRR2. And in any case, a simple pull-down menu with 700 entries may not be as helpful as one would wish.
And as has been mentioned, any field in the database may need annotation; in markup
terms,
the element en can appear pretty much anywhere, sometimes multiple times in a
field, when it is clearly attached to a particular portion of the value for the field
and not
necessarily to the value as a whole.
The presence of additional information and notes is not a
problem from the XML point of view. We can say simply that the
values of TLRR fields are prose, and prose is easily represented
by mixed content in XML. Retrieval will be aided by allowing
specialized markup like person and procedure
in the mixed content, but not much more need be done, surely.
The major complication here is that there is no simple, obvious, and completely satisfactory way of dealing with mixed content in XForms. Content models of elements allowed in mixed content are often recursive; XForms provides no standard recursive structures. Conventional editing interfaces for mixed content make sub-elements flow with the character data; XForms generally treats any text-entry widget as a block for layout purposes. The structure of mixed content tends to vary a great deal from element instance to element instance; XForms (like relational database tables) is easiest to use when structures are simple and regular.
We are experimenting with several ways of addressing these issues.
First, while XForms does not have standard recursive
patterns for dealing with recursive data, it does support
iteration over a node set specified using XPath. And the XPath
Figure 6descendant axis is essentially the transitive
closure over the (recursive) child axis. So while
we cannot conveniently say in standard XForms display the
children of the
,
we can say something that comes close to the same
thing, namely defendant element, and for children
of defendant apply this same pattern recursivelydisplay all descendants of the
. If we
prefix each node with a label indicating its depth in the tree
(the count of its ancestors), we can make the tree structure
of the field visible. Within limits, that is: as the reader
can perceive,
in the current implementation
the varying length of the labels does not
produce varying indentation of the actual text widgets, and
the document-order presentation of all descendants gives us no
hook for marking the ends of elements. So while
the beginnings of the defendant element, using this patterni, procedure, and
en elements are clearly marked, it is not visually
obvious where they end.
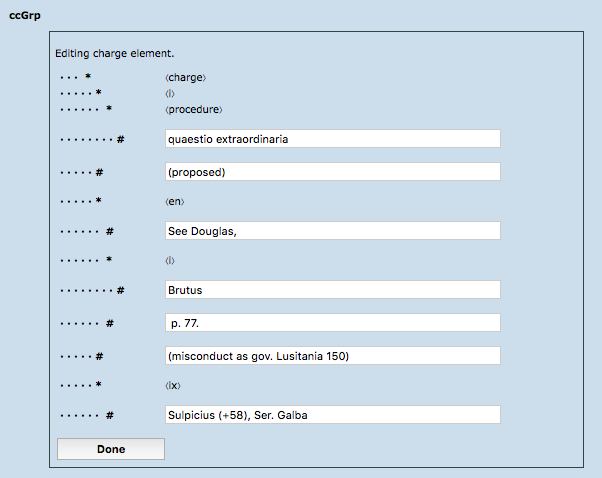
In this form, the XForms label for a text node is calculated as shown below; this illustrates the method used for varying the label with the element's depth in the tree.
<xf:input ref=".">
<xf:label>
<xf:output value="concat(substring(
concat('· · · · ',
'· · · · ',
'· · · · ',
'· · · · '),
1,
2 * count(ancestor-or-self::*)),
' # ',
name())"/>
</xf:label>
</xf:input>
A different approach to the absence of recursion in standard XForms would be to use the (not yet standard) subforms mechanism for recursion. Subforms are common in existing browser-based XForms implementations, because they help keep the forms lighter-weight and improve response time and memory usage. Since they are loaded dynamically, and may be loaded at more than one location in the parent form at the same time, the IDs on elements in the subform must be adjusted at load time.
A subform for an element which displays editable widgets for the element's text-node children, and provides buttons for each child element which cause the same subform to be loaded again, recursively, for the child element, may produce a more plausible indentation-based display of the XML document's tree structure. On the negative side, it may require more clicking to open subforms than users will be happy with.
A third approach, again non-standard but widely supported
by existing implementations, is to use a rich-text
editor
as an XForms widget, to provide an interface
for editing mixed content. All of the existing widgets for
this purpose known to the author started life as in-browser
HTML editors, and it is in most cases not immediately obvious
from the documentation how to adjust them so that instead of
allowing children named b, i, ul,
and ol they should allow children named
procedure, title, en, and so on.
A fourth option would be to use a simple text widget,
with wiki-style markup for sub-elements. An early prototype
of this approach shows the basic idea.
Figure 7
[[ ... ]]
marks end-notes,
(^ ... ^)
marks references to secondary literature,
(* ... *)
marks all italics (both book titles and Latin
legal terms),
(+ ... +)
marks references to persons, and so on.
One advantage of such a wiki-style text widget over
a real
wiki is that the markup it
uses is not tied to that of any existing wiki product
and can be project-specific (and documented in the
XForms interface itself). One drawback is that there
is no obvious way to support pull-down menus for
references to persons, ancient sources, or modern
secondary literature in a wiki context. The cost of
developing translations from the XML form used by the
project to a wiki-style markup and back has not yet
been estimated; in XSLT 2.0, the grouping constructs
and the xsl:analyze-string instruction
would make it easy, but the only XSLT readily available
in an XForm today is XSLT 1.0; recursive template calls
will be more cumbersome than XSLT 2.0 grouping.
Fortunately, the strings to be parsed will never be
very long.
Yet another approach would be to use an alternative to XForms and exploit the customization frameworks available for some XML editors, such as Oxygen's Author mode.
In the interests of allowing head-to-head comparison, we expect to develop several of these approaches. In the short term, however, the priority is on getting one of these working sufficiently well that the historians are willing to use it.
Query interfaces
The query infrastructure used by TLRR is based on a sharp
boundary between the front end, which handles the user
interface, and the back end, which handles queries and returns
XML elements. The idea of such a sharp boundary has a long
history (see Borenstein 1991 for a well formulated
case) and was recently reiterated by the digital humanist
Peter Robinson
in the context of reuse of
data by others, using the
memorable slogan Always remember that your user interface
is everyone else's enemy.
[11] A sharp boundary is not the only way to
proceed; a great deal of interesting recent
work on the RESTXQ interface relies on close integration
of front end and back end.
In TLRR, the sharp boundary between front and back end is
enforced by having them written in different languages and
running on different machines. The front end is an XForm
(concretely a mixture of standard XHTML, CSS, and XForms
elements). The back end is written in XQuery. The front end
communicates with the back end by sending HTTP requests, or
would do so if browsers did not forbid this by enforcing the
so-called same-origin
rule. In our case
the effect of the same-origin rule is that an XForm loaded
from the TLRR web site cannot make an HTTP request from the
different server where the XQuery engine is running. So we use
a relatively thin PHP shim on the TLRR server; it accepts
requests from the front end, sanity checks them, and passes an
HTTP request to the back end using the REST interface defined
by the BaseX XQuery engine. (Nothing essential depends on the
choice of the REST interface; the same effect could be
achieved by using the RESTXQ interface, or doubtless other
interfaces specified by other XQuery engines.) The XQuery
engine responds to requests by running the indicated
predefined query with the parameters supplied by the front
end; all queries return XML documents, which are displayed by
the XForms front end with the help of an XSLT stylesheet
(using the transform() function, an as-yet
unstandardized extension to XForms supported by XSLTForms).
Making XQuery run successfully in a shared hosting environment proved more challenging than had originally been hoped. One complication is commercial: low-end shared Web hosting providers like the one used by the TLRR project don't allow users to run Java servers, or indeed any servers other than those like MySQL run by the provider itself. For that, it is necessary to seek a Java hosting provider, in a distinct (and somewhat more expensive) market. Such Java hosts may provide a choice of servlet containers such as Tomcat, Glassfish, or JBoss; it proves possible to configure a Java-based XQuery engine like BaseX to run in Tomcat, though the experience is far from painless for the user who has no aspirations to be a Java developer and no great interest in Java as a technology.
The more interesting challenges of the query interfaces to TLRR lie not in the infrastructure but in the complexities of TLRR's data.
As an example, let us consider the date of a trial. If a user asks to see all the trials from the 80s BC (i.e. between 89 BC and 80 BC, inclusive), what should the results be?
The date element may, as noted above, take several
forms. The most common forms include these:
-
In simple cases, the
dateelement may contain a date in the database's coverage range (149 to 50). For example, trial 235, dated62
. -
In some cases, the date is more precise (e.g. trial 116
late 87
or trial 351Sept. 50
). -
In another common case, it may contain a date range (e.g. trial 372
between 81 and 43
). -
A date range can be full (both a start- and an end-date) or partial (a terminus ad quem or a terminus a quo). For example, trial 362 (
by 91
), trial 122 (83 or after
). -
The end-points of a full or partial date range may be either dates in the range (e.g. trial 373, dated
between 81 and 43
) or references to other trials (e.g. trial 288, datedbefore case #289
).Sometimes the end-point is explained tersely (e.g. trial 249
before Cicero’s exile in 58
, trial 146before 74 (the date of Cotta’s command)
). -
The date range may be qualified (e.g. trial 370,
long before 69
; trial 125,fifteen years before case #166
). -
Any date or date-range end-point can be uncertain (e.g. trial 47,
112?
; trial 160between 74? and 70
). -
A partial date range may be given for the time of year (e.g. trial 221
63, after trial #220
; trial 15374, end of year, before Dec. 10
). -
Sometimes specific milestones in the trial are given, as well as or instead of a general date (e.g. trial 284,
54, verdict reached on July 4
, or trial 34650, charge laid by Aug. 8
). -
Sometimes more than one possible date or range may be given (e.g. trial 371,
80s? 60s?
).
When the trial is assigned a single date, not marked as uncertain, then it's fairly clear that the trial should be included in the results for a search for trials in the 80s if and only if the date of the trial lies between 1 January 89 and 31 December 80. That takes care of the first two cases.
When the trial has a date range, and the date range lies entirely with the range 89-80, then again the trial should clearly be included. If the date range lies completely outside the range 89-80, it should clearly be excluded. When the range of dates given for the trial overlap with the range given in the search, then we know that the trial could have occurred in the queried time span, but also that it may have occurred outside it. Perhaps the best thing to do is to adopt a kind of fuzzy logic and assign to such trials a real number between zero and one, indicating the degree to which they fall into the class of trials described in the query. Or, assuming (without any evidence for or against) that all dates within the date span assigned to the trial are equally likely, we can measure the probability that the trial occured within the time span in the query. Trial 372, dated between 81 and 43, would have on this account a 5.26% probability (2 chances out of 36) of falling within the 80s. A trial dated to between 91 and 76 would have a 62.5% probability (10 chances out of 16) of falling in that range. Conceptually, fuzzy logic and probability are rather different, but in this application the arithmetic turns out to be largely the same.
In cases with only a half-closed range (terminus a quo or ad quem), we can use the same logic as for closed ranges if we can supply a default starting date and a default ending date for trials. For trials believed to have taken place under the Roman republic, the traditional end date of the republic (27 BC) can serve a a terminus ad quem; a plausible terminus a quo is harder to find, but if we find nothing else we can always use the traditional starting date for the republic (509 BC). For trials of completely unknown date, we can use both the default and the default end to define their date range.
One consequence of this approach is that we can then return results sorted by probability (in descending order). Trials known to have occurred in the 80s have probability 1.0 and come first; trials with a high likelihood but no certainty of falling in the range come next; trials with a semi-closed range will tend to have a very low probability, but those whose fixed point is closest to the 80s will score highest. Trials of completely uncertain date will have the largest range of possible dates and so the lowest probability of having occurred in any given span of years.
Trials whose date is uncertain (e.g. 80?
for trial
130) must be assumed to have less than 100% probability of
occurring in the year indicated, and a correspondingly
non-zero probability of having occurred in some other year. It
is not clear what probability should be assigned to the given
year, nor how to allocate that probability among other years.
As a starting point, to keep things simple (and mindful of the
inherent imprecision of any estimates of probability for such
cases), we assume for now that any date marked ?
has a
50% chance of being right and a 50% chance of being wrong, and
that the latter is spread unevenly among the five nearest
years on each side (9%, 7%, 5%, 3%, 1%). If this leads to
results that repeatedly strike historians as odd or
unexpected, we will try to produce other estimates.
Trials with multiple possible date ranges (e.g. trial
254 66? 65? 58?
, or 371 80s? 60s?
)
will be treated as having a discontinuous range; the
probability calculation is essentially the same.
Trials dated solely with respect to other trials will
need to have their date ranges calculated by reference
to those of the other trials in question. So trial 287
(before cases #288 and #289
) and
299 (before case #289
) will be assigned a
terminus ad quem from trial 289
(summer 54, in progress on July 27
). Trial
125 fifteen years before case #166
will have a date range calculated on the basis of
that for trial 166 (between 76 and 68
,
making the range for 125 be between 91 and 83).
It will be evident both that calculating an effective date
range for trials whose date range is given only implicitly or
indirectly would complicate queries quite a bit; all of the
calculations for the effective date range can be performed in
advance and stored in the database. Some mechanism will be
needed to invalidate the calculations when the content of the
date element is changed, so that they can be
refreshed. (Fortunately, this is not a real-time system,
and field values are not expected to change multiple times
per second.)
The attentive reader may have been saying for some time now
that this appears to be basically the same idea as relevance
ranking in information retrieval; the attentive reader is of
course right. At the crucial level of abstraction, both
relevance ranking in information retrieval and the search
procedures for dates outlined above shift from Boolean logic
to fuzzy logic. Instead of assigning to every record in the
database a Boolean value for the proposition This record is
in the class described by the search
, these approaches
assign a real number between 0 and 1 to each record, with
higher numbers indicating greater likelihood of being of
interest to the user. The specific mechanisms used in IR for
calculating relevance results, on the other hand, appear not
to be very helpful for TLRR's data. (And the term
relevance does not seem at all a good
description of what is being calculated, unless it is taken to
denote the property of being of interest to the user, rather
than being relevant to a particular subject or topic assumed
to be the target of the query.)
Future work
The participants in TLRR have (at least) two distinct goals. For the historians, the key goal is to develop an updated version of the database and to publish it. The participants have expressed a strong preference for print publication if at all possible. For the technical partner, the first goal of TLRR is to assist the historians in achieving their goals; in the short term, that means providing usable editing and query interfaces, and in the longer term seeing to print formatting and for the eventual migration of the data from the TLRR server to a digital archive capable of caring for it long term. A secondary goal is to investigate different ways of solving the challenges posed by the project. For that reason, we expect to implement multiple XForms front ends (and, time permitting, eventually probably also an Oxygen front end, and possibly others) for editing the data. We may implement a SQL version of the database (just to show how unmanageable it will be, if the data are reduced to third normal form, or possibly to be surprised by the discovery that it is manageable after all). We expect to implement multiple query interfaces, varying both in the user interface and in the target database. Each of the various XML forms described above should be made searchable, in order to illustrate on one concrete example how better markup makes it easier to do more useful queries, and how poor markup makes useful queries harder to formulate. And when the time comes to produce printed output, it may be feasible to make head-to-head comparisons among different tools for the job: TeX, XSL formatting objects, XHTML plus CSS, or other XML-capable layout tools.
If the secondary goal is well achieved, the TLRR database may be of interest to other XML practitioners as a way of showing clients and potential users the kinds of difference markup choices can make.
References
[Alexander 1990] Alexander, Michael C. Trials in the Late Roman Republic 149 BC to 50 BC. Toronto: University of Toronto Press, 1990. (= Phoenix, Journal of the Classical Association of Canada / Revuew de la Société canadienne des études classiques, Supplementary volus / Tome supplementaire XXVI)
[Borenstein 1991] Borenstein, Nathaniel S. Programming as if People Mattered: Friendly Programs, Software Engineering, and Other Noble Delusions. Princeton, N.J.: Princeton University Press, 1991.
[Lubell 2014]
Lubell, Josh.
XForms User Interfaces for
Small Arcane Nontrivial Datasets
.
Presented at Balisage: The Markup Conference 2014,
Washington, DC, August 5 - 8, 2014.
In
Proceedings of Balisage:
The Markup Conference 2014.
Balisage Series on Markup Technologies, vol. 13 (2014).
doi:https://doi.org/10.4242/BalisageVol13.Lubell01.
On the Web at
http://www.balisage.net/Proceedings/vol13/html/Lubell01/BalisageVol13-Lubell01.html.
[Pauly/Wissowa 1894-1980] Pauly, August Friedrich von, Georg Wissowa, et al. Real-Encyclopädie der classischen Altertumswissenschaft. Stuttgart: Metzler, 1894-1980.
[1] Trial numbers are given so that readers interested in inspecting the data in context can consult either the PDF of TLRR1 or the current form of the database, both available from the project's web site at http://tlrr.blackmesatech.com/.
[2] In the words of the classicist Jocelyn Penny Small, It is not the job of
the classicist to clean up our messy information in order to put it into a
database; it is the job of the database to preserve the
mess.
As this is written, it remains to be seen whether we will satisfy this requirement completely.
[3] The specification of a format for a relational database will take the form of an entity-relationship diagram or something similar; a format for an XML database will be specified in the form of sample documents and/or notes for a document type definition or other XML schema. Trying to express the crucial information without any commitment to an underlying technology will only result in descriptions so vague and abstract that they prove unhelpful. Experience in many projects suggests that even then, the highly abstract descriptions risk turning out to involve a lot of commitments to particular technology, which have been carefully disguised and thus not exposed to discussion, which not been systematically checked for mutual consistency, and which make it difficult to implement the design in a natural way in any technology.
[4] Those with sufficiently long memories may regard wiki markup as nothing but the resurrection of the SGML SHORTREF feature, only with less documentation and freed of any requirement for interoperability. But the existence of SHORTREF as a feature does establish that the basic features of wiki markup are not incompatible with SGML or XML.
[5] There may be other ways to avoid the inconveniences described here. Some SQL users appear resigned to working with data that are not in fact in third (or even first) normal form. But since that destroys the consistency-checking apparatus of the relational model, working with non-normalized data also seems unattractive.
[6] The Real-Encyclopädie der
klassischen Althertumswissenschaft by August
Friedrich von Pauly, Georg Wissowa, and others is
frequenty referred to as Pauly/Wissowa
or just
RE
. Pauly's first edition began to
appear in 1839 and was completed in 1852 (after Pauly's
death). A second edition was begun by Georg Wissowa in
1890; the first volume appeared in 1894, the final volume
in 1978, and the index volume in 1980.
[7] Waterloo Script was similar in style and behavior to IBM's Document Composition Facility (DCF) Script, and Waterloo GML was an independent implementation of GML, using Waterloo Script as the implementation language.
[8] I acknowledge the influence here of the technical-term mechanism used in some XML-encoded W3C specifications, in which local content can be used to override the standard spelling of a technical term, which simplifies the use of technical terms at the beginnings of sentences and their use in plural or other inflected forms.
[9] Unlike TLRR1, TLRR2 will distinguish between laws or charges like ambitus and courts or venues like the quaestio extraordinaria in the example. Alexander puts them all into the same field, perhaps because when one is known, the other is often not known.
[10] At the moment, two editing interfaces are available on the public web site; others will be made available as time permits (including false starts that did not work out, as a way of helping other people avoid similar false starts). The public versions will not, of course, be able to save data to the database. The interfaces available now differ slightly from those shown below, partly because the images here show earlier versions and partly because the images here show the project-internal page styling, not the public page styling.
At this point it should also be noted that the
NB, not yet seen in any examples, holds
information sometimes given at the head of a trial
display, such as trial only threatened
(trials 13, 103, and others) or
= ? case #133
(trial 132).
[11] By this I understand Robinson to mean that many re-users of our data will have goals different from those assumed by any user interface we may have developed, and that having to get at data through a user interface instead of an application programming interface is guaranteed to make reuse harder. (He also meant, I believe, that user interfaces age much faster than data or even than good APIs.)