XML-based systems: better than ever but just the same
XML-based data and document-processing solutions have been around long enough now that we can begin to see their outlines and commonalities, despite their vast differences, across domains, between large and small, and down through generations. In some respects, a server farm talking to an XML database back end and producing thousands of arbitrary “views” per minute of dynamically populated content for a range of clients (desktop and mobile) on the Internet, is still just like a 486 processor running Netscape Navigator with a browser plugin on Microsoft Windows 95, with 8MB of RAM. The astonishing differences between then and now can be enumerated using all kinds of metrics. Things now are so much larger, faster, more complex. Perhaps not more cumbersome (the bad old days are hard to forget), but not less so. The similarities may be harder to see; yet it helps to understand the later, more complex form when one considers there has been a straight line of development from the earlier and simpler.[1] We are not doing more than we were doing back then. Much useful work was done by systems built on these principles, even years ago. We are only doing it at ever greater levels of scale, speed and complexity.
Figure 1
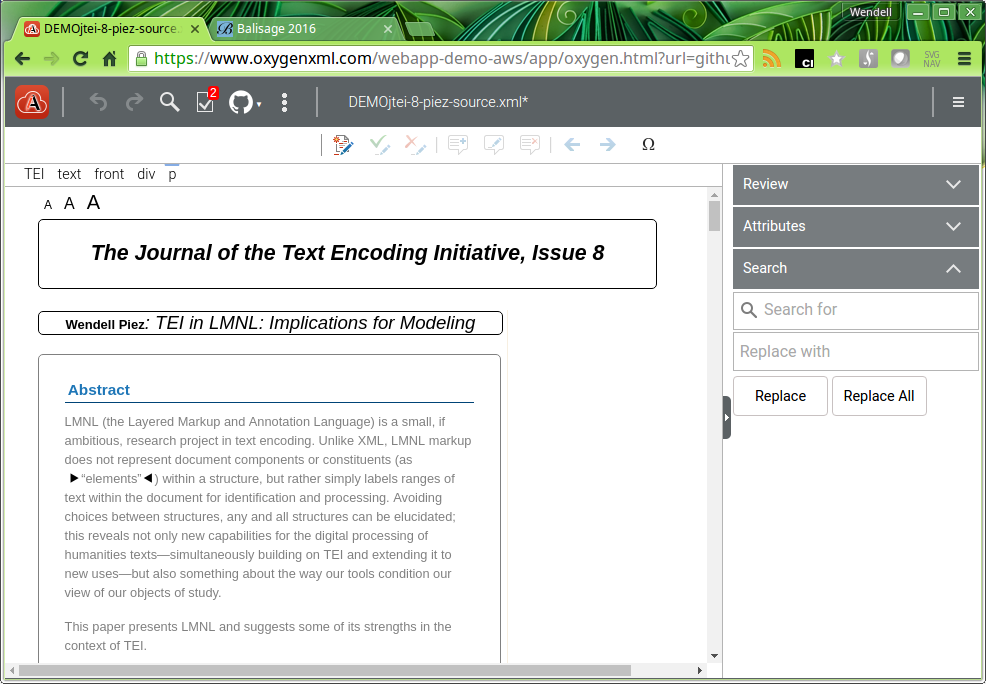
A screenshot of a contemporary online editing interface: this is structured TEI, being edited live in oXygen XML Web author, the presentation configured using stylesheets written by George Bina and others. (What is in view is not styled with XSLT but with CSS+extensions; the application framework can also run XSLT or any other external process.)
This is worth keeping in mind when turning our attention to present opportunities, as experience reinforces our sense of how much we can now do, for example with an ad-hoc (yet strategically chosen) collection of schema(s), XSLT, CSS, Schematron, and glue, whether that be some vendor-specific code, or something patched together, or something very powerful, general and extensible, such as an application coded in XProc (a generalized declarative pipelining language) or a database running XQuery. Even more, we have entire editing environments custom built for purpose, up to and including web-based environments, which purport to make it possible for people who know nothing specifically about text encoding technologies, to use the systems nonetheless, as “experts” (presumably in their own domains ... but then by using it, they also become expert in the system itself). Such frameworks, suites and toolkits are nothing new; but costs for designing, building and supporting these environments and working interfaces have dropped by an order of magnitude every decade since the 1970s – and may (for all we know) continue to do so. This by itself has changed the equations.
Figure 2: XML editors, oldish and newish
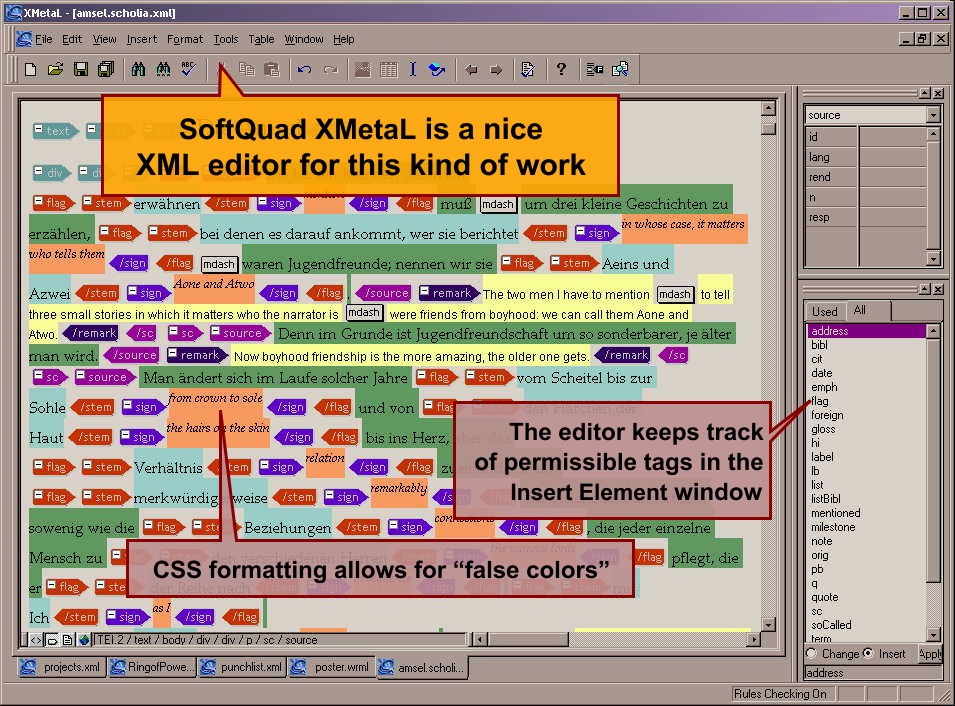
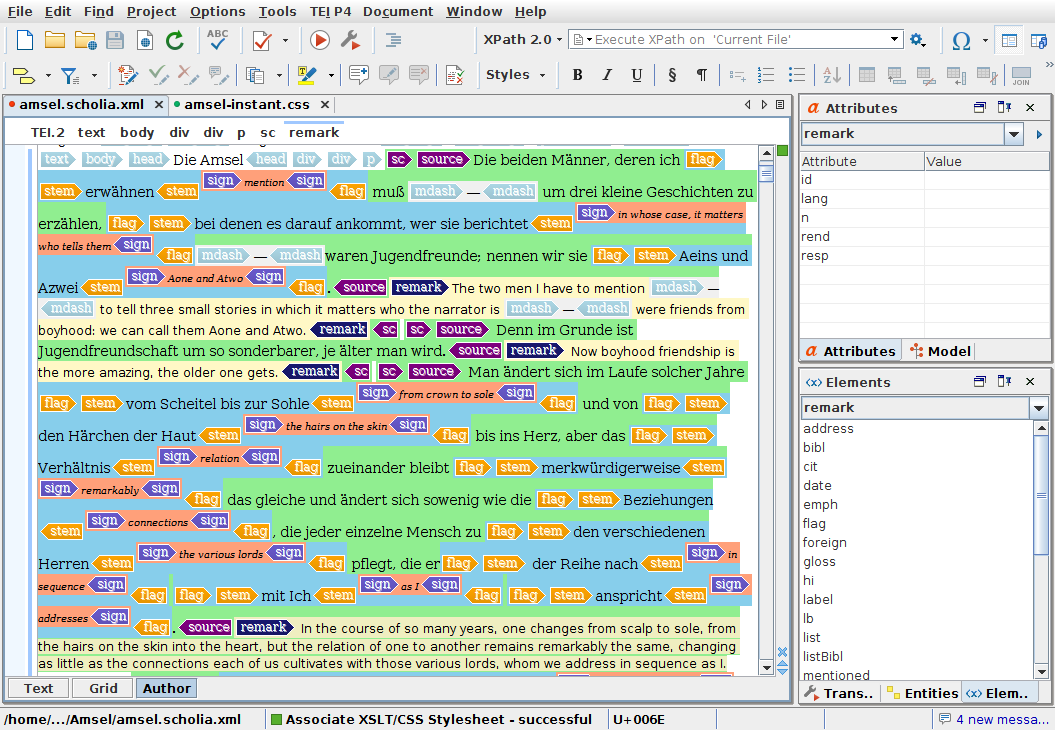
Screenshot of SoftQuad XMetaL (perhaps then BlastRadius), taken in 2002, followed by a view of the same text open in oXygen XML Editor, 2016. Of course, this is a stunt, but it is remarkable how easy it was (twenty minutes of CSS) to emulate the formatting being demonstrated by the old editor, in the new one. (A few more minutes would allow for considerable improvements to the design.)
Indeed, in this last observation is a point that is easy to allow to slip by. Up until fairly recently, there were two very distinct sorts of “framework development”, as one might call it, related to XML and XML-based publishing and data processing systems. One was the creation of customized structured editing environments – systems that attracted significant investments over what is now decades (publishing systems stretching back as far as computers do), and which by the late 1990s had evolved into an entire market for software and services. Typically these applications, albeit nominally standards-conformant (generally some flavor of SGML was the starting point), were implemented on proprietary stacks of one form or another, and set out to support processes end-to-end, typically by combining user interfaces (for creation and management) with production capabilities, usually by way of integration with a publishing application.[2] To build such an application meant cultivating expertise not only in applicable standards (where they existed) but also the software application itself and its formats and interfaces (which were typically proprietary, if only to fill the gap where standards did not exist – because they were being tried for the first time). Notwithstanding the challenges, this was something that was done successfully, and more than once.
Yet while – at least in some vertical markets (where factors of scale and automatability are especially favorable) – applications have been built and sustained on these principles, there has also developed a healthy counter market (one might call it) in free and low-cost tools for document and data processing. The web itself is of course the main difference between now and the 1990s – two decades proving to be long enough for several revolutions in publishing. Indeed one of the most profound revolutions has been in the (relative) universalization of access to information on how to operate and build on the web. In other words, the web itself has been the means for its own dissemination of expertise, and other forms of data processing (off as well as on the web) have benefited from being "transmissable" on the web (as a platform for knowledge transfer). So for the mere cost of a data connection, one has access to libraries and indeed executables that have required years (albeit often by do-it-yourselfers like yourself) to develop, encapsulate and publish. We work now in a kind of ecosystem of software development activity, which changes everything about how we work and how are work can combine with and magnify the work of others. And this is true not only for technologies of web development as such, but of much that goes with it.
Consequently there have appeared alternatives to the high-end editing environments for supporting XML-based processing workflows, approaches that assume a much more do-it-yourself attitude. From the early days, it became possible to build and operate systems by stitching together whatever markup and text processing utilities you could get to work, perhaps Perl or Python, or perhaps DSSSL (when we had that) or next XSLT. These components would then be bolted together using whatever pipelining architecture was available to you. (Maybe it was shell scripting over the file system or through editor buffers.) Typically this meant writing batch or shell scripts that managed files according to custom-made logic over the file system, invoking open-source or otherwise-accessible executables in order to get the actual job done. But sometimes you would have other interfaces to query and even edit your data.
Solutions patched together in this way tended not to be end-to-end document processing or publishing systems, but instead focussed on problems that need to be solved, or that they could usefully or neatly address. While there might have been some front-end component to these systems, that generally wasn't their strength; instead they tended to provide services on the back end or downstream of the editing process. Their operators, in contrast to the first kind of (customized) editing environment, tended to be technologists, at least to the point that they could troubleshoot when problems arose. When orchestration of processes became complex (as they soon enough did), simple interfaces would be contrived using build languages (or other methods). While such systems require considerable expertise in relevant standards and technologies (including libraries and APIs) to build and sometimes to operate, unlike the top-down editors, they have tended to be unencumbered by proprietary barriers to development and reuse, while arguably, in comparison to proprietary alternatives, providing even more open-ended functionality. It turns out that all by themselves, XSLT, Apache Ant, and file utilities can take you a very long way.
Indeed it should be kept in mind that at some point it becomes difficult to draw a boundary between a “customized editing environment” and the kinds of support for processing in general that such an editing environment routinely offers as well. In other words, what makes these systems distinguishable at all is not that they offer any particular sort of user interface – there may be no GUI in sight – but rather that they bundle front and back end services and processes in a way that makes them accessible and controllable by users. Indeed, users should be at the heart of it, and the focus needs to be on providing users, within available means, with something both neat and effective for them, something that produces more value in its outputs than it demands in inputs (of time, resources, attention). The term “workflow” can help us keep things in mind as well: it's not just about where data comes from and how it starts, but what happens to it.
So on the open source side as well, two decades have seen real development. Thirty years after the standardization of SGML and nearly twenty after XML's formal release, developers have a range of choices that (back then) only the most audacious were able to envision. These include not only tooling in support of XML and related standards in all the major languages and platforms, and not only proprietary and semi-proprietary stacks, but open source solutions and specifications as well. In particular (in the context of this discussion), XProc should be mentioned, inasmuch as we now have a pipelining language even apart from our transformation language, something that is indeed useful. As tools and technologies have matured (built, tested, deployed, shaken down, shaken out) and public resources such as the standards themselves (or: public specifications) have stabilized, open source and free-for-use tools have continued to offer a low-cost-of-entry alternative to the big, top-down systems. In turn, this has proven to be an opportunity for companies who offer software and services based on the availability of such tools in addition to its primary beneficaries, the projects and organizations that can use them to solve problems.
Consequently, one might consider XProc running in XML Calabash inside oXygen XML Editor (one product which has played an important role in this evolution[3]) to be a culmination of both strands of development – structured editors that offer all the functionality of environments that used to cost ten (or a hundred) times as much to build and deploy, yet emerging out of (and taking advantage of) the community-standards-based tagging initiatives and the tools that go with them (these include DITA, TEI, NISO JATS etc.) rather than only from top-down imperatives.
Ironically, part of the value offering of a tool such as oXygen XML Editor is the extent to which – precisely by incorporating directly the “best in category” open source toolkits – it actually insulates its developers from proprietary entanglements, allowing us to work independently to provide whatever local user base we have, with something they need, without having to go further upstream to get the support we need in doing so. Not incidentally, this also lowers the cost of oXygen, since its own "proprietary footprint" over the functionality set, is smaller; due to this lower cost, and especially given its component-based assembly, it also becomes thinkable to use a tool like oXygen not just "end to end" but also for much smaller and discrete sorts of operations. In short: at its lower cost it can serve much more flexibly in the “big mix” (of processes and formats) that characterizes information management today.
What else has changed? The market environment. No longer is this (as it seemed to be 20 years ago) a seemingly Quixotic struggle against the blind and casual use of proprietary word processors and desktop publishing applications to produce, manage and archive information. The alternative today to XML and structured data seems to be, not word-processing-and-unstructured-data, but HTML-and-the-web. Personally I am of the belief that appearances are deceptive, and this is really only the old foe in a new form, albeit not really a foe at all! – and yet paradoxically that an XML mindset – and even an XML toolkit – can still flourish in this environment. In other words, the problem is the same as it was, and XML/XSLT still offers the solution (or at least, a means to provide a solution), and so the key is to continue to use them even while adapting. Even today, and even and indeed especially on the web, XML/XSLT can be a kind of secret super-power.
The problem is knowing when this is. That is, recognizing opportunities: where can applications of transformations, and processing pipelines built out of them, achieve meaningful goals, whether for a project, organization or business? Where can we apply the power of transformations? becomes the key question. And – if they do not always save energy – then how might we use XML-based technologies to produce things (useful or beautiful) that would be impossible or unthinkable without them?
Transformations: Lower and higher-order organization
What hasn't changed is the basic three-cornered transformation architecture: source / transformation / result[4], a triad that immediately refracts and multiplies once we engage “meta-processes” or control processes, by exerting controls over our components (first, our nominal “source” but soon enough over the transformation itself or components of it, and finally over results as well) using the same methods – transformation – as we use for core processes. Only the simplest of systems reduces to a single source/specification/view (not even an HTML page with a CSS stylesheet in a browser these days typically constitutes a single source with a single display specification); what is much more common is some kind of series or cascade of processes and applications, many of which have, if not active dependencies, then at least implicit dependencies on further processes “up stream” (i.e. at presumed earlier points in a document's lifecycle or processing history). Indeed the real power of these systems is when you become able to manage their complexity by putting different transformations of various kinds and purposes together. So XML's power comes not from the simple or single fact of descriptive encoding (the separation of concerns that comes with any model/view/controller especially one as cleanly separated as this), but also from the fact that XML data can be handled – frequently but not always by design – in aggregate and that XML is itself composable. We can not only display documents, but also process, edit and amend them in any way imaginable, in groups and in groups of groups.
So it becomes possible to apply logical operations to data sets in sequences of steps, between (the details vary) authoring or acquisition, assembly, aggregation, normalization and integration, production and publication. Indeed it should not be hard to see in these steps, analogues and “recapitulations” of activities that publishers already perform and indeed that is their purpose, to perform them – if electronic means and media offer a chance to do anything truly “new” (which is a separate discussion), that is generally as a complement and offshoot of doing something that has already been shown to need doing. Nonetheless it has been demonstrated repeatedly that when it comes to things like formatting and reformatting documents with consistency; marshalling and managing metadata and adjunct resources (such as images or sample data sets belonging to published items or articles); normalizing, regularizing and integrating cross-references and citation data; the creation of indexes and ancillary resources with their descriptions; and numerous other of the typical “chores” that come with publishing, XML-based systems can provide means to lighten the load consistently. The theory and practice of all this is fairly well understood.
Importantly, while these “meta-transformations” include validation,[5] they may also include other operations that might (within a purely “functional” universe) be considered as side effects or as externally dependent (that is, as reflecting arbitrary state external to the system), such as utilities for reading from file systems, compressing and decompressing sets of resources, copying files in a file system or via FTP over the Internet, and other sorts of tasks. Join these capabilities to the intrinsic capability of XML (which is typically used, when working inside such an architecture, to represent file structures etc.) for querying using the same tools (XPath, XSLT, XQuery) as you use for document handling, and the system has yet more leverage (as has not gone unremarked at Balisage, for example see Rennau 2016). A utility or set of utilities can produce formatted output from controlled source data (that much we accept) but it can also do much more than that, providing services in exposing and editing that data; providing for customized quality checking; providing for help with mundane tasks associated with file management (to a local set of requirements), and so on.
When XSLT is the technology of choice, it becomes natural to describe or characterize these operations as “transformations”, although that term also then comes (by analogy) to indicate any “before/after” relation of applying a logical process, algorithm or filter to a source document, thereby achieving (and perhaps persisting, as an artifact) a result, whether by XSLT or other means. Synonyms for “transformation” in this sense might include “view”, “rendition” or “filter”.
Of course nothing is consumed nor even “transformed” in a transformation. What happens instead is that a new artifact is created next to the old one, sometimes a copy or simulacrum, presumably always some sort of (intended) representation or reading of it. It is as if the butterfly were sitting next to its pupa, which is still alive and able to transform again. Transformation is, really, is not about changing anything but more like “bottling” it, in a different form or package, or as an extract or permuted version of itself in some way. Indeed it is the same as a query, albeit with a different goal (an entirely altered view of a whole, not just an extracted bit) and we can certainly describe our triad as a model-controller-view (source-query-result) if we like – the differences being rather in emphasis.
Considered as abstract operations, transformations are also composable. Chain two or more transformations together as a pipeline, setting aside any intermediate results between them, and you have what can be regarded as a single transformation. (You also need another layer, i.e. a way to represent this multiples-in-one relation. You could do this with a shell, or an XProc, or a wrapper XSLT, etc. Meta-process!) Considered as a black box, any system-level component can be regarded as a transformation – with certain specified inputs and certain expected results therefrom – even if internally, in its implementation, it is quite complex. It doesn't help that as XSLT developers know, transformations are sometimes (frequently) pipelines themselves internally (in whole or in part), as indeed XSLT can be seen as a language for pipelining function calls. (And the same will be true of other transformation technologies in their ways.) So the actual line between “transformation” and “pipeline” is very blurry.
Nonetheless it is convenient to think of transformations as being the atomic units (either because elemental and rudimentary, or because designed to be logical/recomposable, or simply because they are opaque, “black boxes”); “pipelines” are more generally transformations when considered as aggregates not as processes. Additionally, we may wish to stipulate that the model does not insist that a transformation be an automated or automatable process. Manual intervention may be the best or only way to produce it. (What makes a data manipulation or management task a transformation is not whether it is automatable or how difficult it is, but whether it can be described adequately to be performed and assessed.)
Then too, pipelines (considered as transformations) can also be arranged into higher level assemblages, suites of utilities and operations and declaration sets (including declarations of constraints) that work together to achieve specific ends in information processing (both for “publishing” and any others you might think of). These are indeed more difficult to talk about, since while the XSLT at the center hasn't changed all that much (allowances between made for the vast differences in XPath 1.0 and 2.0 data models), the languages in which these assemblages were composed and made available to users, have changed a great deal over time. So a set of tasks that might have been accomplished, in a very rudimentary yet not inelegant way in, say, 1998, with a compiler-build utility such as GNU make – creating a static HTML web site, for example, or generating an index -- these same operations (as noted), we might today be doing using an XProc pipeline and processor invoked from inside an editing application.
Despite not exactly having a name – we might call them frameworks or assemblies or toolkits or any number of things, while remaining somewhat confused as to the boundaries exactly – these things can be distinguished from other productions. Indeed every year at Balisage, a considerable number of them are demonstrated – for example in 2016 we have Caton and Vieira 2016, Clark and Connel 2016, Cuellar and Aiken 2016, Galtman 2016, Graham 2016, Horn, Denzer and Hambuch 2016, Kraetke and Imsieke 2016, Lubell 2016 Sperberg-McQueen 2016. These are “applications” in only a stricter sense than the commonest sense today (“applications” as commoditized piece of software); as meaningful assemblies and configurations (“meaningful” in their contexts of use) of available and handmade parts, they are not software or standards, schemas or libraries, even though all these are greatly mixed up in and with all of these things and typically make use of one or several of them.
Whatever the best term to designate them, first we have to see them for what they are. Typically they are built or deployed on top of some third-party software or architecture, presenting them with wrappers, customizations and extensions that suit them for particular tasks in the project of interest. And once again there is this fractal aspect whereby these creatures resemble, in form, the things out of which they are composed: frameworks (as considered as more or less tightly integrated sets of processes, available to an operator who accomplishes some task) are much like pipelines in their basic outlines, which are much like transformations. They have multiple inputs and outputs, including stylesheets and configurations as well as (so-called) source data;[6] they can be regarded as black boxes and sometimes (but not always) executed with the push of a button or click of an icon. They typically entail achieving and applying, more or less explicitly, a logical mapping from source format(s) to target(s), in service of some more or less complex information processing objective, such as populating or querying a data store, acquiring or editing documentary information, publishing in multiple formats, integrating with external resources. Each one is unique although they are frequently offered as models to be emulated. Sometimes libraries, applications or languages spin off from them.
|
examples of transformation |
A CSS stylesheet applied to an XML document for display in a web browser. An XSLT stylesheet that converts tagging in an XML document into a normalized form. A translation from English into French. |
|
examples of pipelines |
A sequence of XSLTs that produce structured (XML) output from (implicitly structured) plain text input (more or less groomed or regular) A macro composed of several search/replace operations in sequence, to manage special characters (transcoding) A procedure that is executed monthly, which requires packaging some files (collected over the course of the month) and FTPing them to a vendor |
|
examples of ??? (third-order organization) |
An editing environment consisting of a combination of display stylesheets (CSS, XSLT) referencing (and including) a publicly-available standard schema. Schematron is bolted in to provide checking tag usage against local rules. A metadata crosswalking system, supporting queries to a web service, bundling the results in a (nominally standards-based) XML wrapper for consumption in another channel. The production of a conference proceedings on a shoestring, in which papers are submitted in an XML format, thereby offloading a great deal of editorial work to authors. The results are not always the prettiest but they are streamlined, and costs (in time and effort) are manageable – enabling the conference to produce a proceedings while spending its money on more important things. A Schematron-documentation system, in which Schematrons can be composed via literate programming, and their specifications coded and indexed for external management and governance (i.e., linking error messages to policies). Projects demonstrated at Balisage as cited above, for example Caton and Vieira 2016, which describes the Kiln publishing framework, a set of stylesheets and configurable components used by an academic department on a routine basis (multiple times per annum) to produce project web sites. |
|
workflow (higher-order organizations) |
The third-order assemblies presumably combine at still higher organizational levels. So, for example, the publication of a journal involves one or more workflows, each of which might avail themselves of one or more (assemblies of) transformation architectures – including (notably) organizational black boxes (wherein can be hand work, outsourcing or anything). |
However fuzzy the terminology, these system-level assemblages have been maturing; functionalities are tried, tested and demonstrated, and platforms, software and methods all improve. No longer are they always such duct-tape and baling-wire assemblages as they were in the old days. Indeed, even the most peculiar customized local processes over XML can now, often, be sufficiently integrated into interfaces (whether editing and content and workflow management environments) that operators can use them without having to see angle brackets at all, or more generally, without having particularly to care for or about encoding issues in the least.
That someone should able to edit structured text “friction free” (whatever this means for formats behind the scenes) is something of a Holy Grail. My own feeling is that whether and how intricacies of tagging are best hidden away, very much depends on the circumstance. However, one implication of what follows (as I hope the reader agrees) is that the prospect of “tagless” XML (or HTML) editing is ultimately less promising than the way framework architectures can reduce the complexity and tedium, not of encoding as such, but of all else that goes with it. If tagging were the only thing a “content expert” had to think about, in other words, I think she would swiftly learn it. How to tag things is today one of the lesser problems in getting stuff up and out. The more daunting challenges are the ones at the level of deployment architectures and environments. What are you asking users to learn?
Then too, smart framework development can be one way to help bridge the expertise gap. An actual, functioning XML document processing environment can be a learning platform as well as a means of production.
A transformation cost model
One intriguing thing about this progression is the fractal nature of the relation (blurry boundaries between categories, self-similarity across scale) from one level to the next. Another is that structurally, they are isomorphic: any component can (and at some level must) be defined in terms of its putative input(s) and output(s) however complex each of these may be (since there might be aggregation as well as filtering at any point). Thus there is always this tripartite pattern, source/transformation/result, where the middle term is regarded as a black box capable of achieving the mapping from source(s) to result(s), however specified.
In turn this suggests we can apply a single analytic framework to all levels of scale and complexity, whether looking from “far away” or “up close”. Such an analytic framework is offered here. It seeks to interpret any problem of transformation or of document processing, equivalently, as a problem of managing costs of investment (in time but also in expertise)[7] in view of risks and opportunities of return over time. Note that it is only “pseudo” quantitative, in that its usefulness should be less in whether and how it can be applied to result in some sort of number, but because it may elicit a better understanding between relative factors when considering what makes transformations valuable, when they are valuable. That is, the intent here is to offer not only a way of assessing when and where there may be opportunities, but also some (perhaps counter-intuitive) observations about when these systems work well and why they are sustainable.
The formula is based on the stipulation that any document, instance or occasion of transformation must be considered as a member of a set. This is reasonable to do and indeed inevitable given how we typically and ordinarily develop transformations as rules of implication between types and classes. (We can consider one-offs – transformations that are run once on a single instance of a source document, then thrown away – as singleton sets, so there is no real problem here.)
Viewed as a member of its set, any given transformation will incur the cost of development of that transformation, plus setup for running it (at all, that is the first time, but also in general, for all runs), plus the operations costs (after setup, including marginal costs per item), all divided by the count of successful instances (runs).
Equation (a)
Or equivalently (splitting operations cost into an average):
Equation (b)
Or (abbreviated)
Equation (c)
These all say the same thing. Extracting operations costs for the set and averaging it across members of the set is helpful for weighing the significance of this addend directly against the “development” (more properly D+S) side. This assymetry of factors is the most important thing about this model. The direct implication is that as long as operations overhead is relatively high and in particular if it increases relative to count (most especially, increases linearly – i.e. there are significant marginal costs per item), it will continue to burden transformation costs, even while costs of Development and Setup are amortized (distributed) across the entire set. If instead, operations costs can be brought to zero - then it is possible to achieve very low costs for the transformation as a whole, as Development+Setup costs are distributed, even when the count of documents is relatively low.
“Setup” here includes setting up and running the transformation, that is the costs of running the transformation over and above the costs of handling items in the set (the overhead). With good tooling and/or expertise available, this can drop very low. However (when not) it can also be a prohibitive factor, a barrier to entry.
“Development” is the cost of development of the transformation to the point where it gives acceptable (and/or presumably correct) results. Note that in order for a transformation to run at all, Development costs must typically be incurred early. Yet this is not always the case – while maintenance, similarly, might be considered a type of deferred development. It should also be kept in mind that Development costs are relative to available skills. Not all developers provide the same D “energy” for the same time invested and sometimes the difference will be many multiples (where a skilled developer writes robust functioning code more simply and rapidly than an inexperienced developer facing a problem for the first time). Indeed the relative availability of expertise making D affordable is currently the most important gating factor.
It is useful to consider Development and Setup as independent. An organization may be able to pay for Development (or maybe it can be discounted by acquiring a "stock" solution), but if setup costs are prohibitive, this doesn't matter. In a contrasting case, maybe Setup is low (in the event) but since Development is high, a transformation is not viable. (Perhaps an unskilled operator has access to tools he does not know how to exploit, or perhaps a transformation is underspecified and thus impossible to “get right” even with the best code.)
The average operations costs is where the real problems are hidden. Only when operations costs go down (and especially if they can go down appreciably as count goes up), do transformations have a chance of paying for themselves quickly. Operations costs will include, primarily, all the costs of managing and transmitting files and data resources, including any copying, “grooming”, renaming, editing, marshalling of resources, cross-checking and confirmation. Assume that any time a resource is touched, some minor cost can be associated. This attention may be expended at the level of each individual document, or of the set as a whole. It will be highly variable across operational contexts - sometimes the additional marginal cost per document is extremely low (maybe it can be shared among a large documents at once); at other times, it is not.
A further complication hidden in this value (operations costs) is that in circumstances where not every transformation is successful, the successful ones may have to pay for the unsuccessful ones as well as for themselves. Costs of detection of problems and of their remediation have to be included in operations. And this may also entail new costs associated with overhead, for example if further tasks in file management, project management or task tracking are required when errors or lapses occur. In other words, operations costs will explode in situations where actual throughput is low (count goes down) because transformations are fallible – this is the dark side and the worst problem of automation technologies gone awry: bad transformations (which require corrections or workarounds) may eat up all the benefits of good ones. The viability of any transformation over the scope of actual inputs, and the assurance of a high rate of success (most especially, before all inputs are seen), remain critical determinants in whether a pipeline is actually worth the cost of building and running it.
Several things are suggested by this model:
-
For lower costs, there are really two distinct points of control, both of which must be favorable (or at least not unfavorable): total count for the set (the higher the better), and associated cost of operations (the lower the better).
This is the “no-brainer” hypothetical case: total count going high enough to justify the necessary investment both up front and per item. The idea that a single stylesheet can save costs on processing large quantities of (valid) input files is the premise on which XML is usually built and sold.
And this principle does work, assuming inputs are adequate in quality to the purposes of processing; that is, when they are capable of supporting clean “down hill” subordinate and spinoff applications. (Of course to say as much is simply to make the circular point that if things are effectively able pay for themselves, they do so. The key is in being able to see when and how this can happen in a markup workflow.)
-
Ways of bringing operations costs and overhead down can be critical. In particular, a appropriately constrained editing environment (such as many XML environments) pays for itself because it helps reduce average overhead for processing per document, in all downstream processes – ideally to nearly zero (by virtue of controlling inputs to a strongly validated model).) In conditions like this, an organization such as an academic department or small project (again, see Caton and Vieira 2016, Horn, Denzer and Hambuch 2016 or Sperberg-McQueen 2016) is able to take advantage of the technology to good effect, despite a (relatively) modest document throughput per month and from year to year: in these cases a relatively low document count is counter balanced by the fact that once data content is in the system with sufficiently strong semantics, subsequent production costs can reduce to effectively nothing, since operations costs are so low – while D/S costs (having been incurred in the past, now we are in a reuse phase) can increasingly be discounted. Consider also how this advantage is compounded with the accessibility advantage when any of these projects is on the web (as so many of them are); authors can be much more engaged than in prior systems in the active publication of their documents. So a manageable investment (in time, effort, expertise) results in a significant resource that pays out its value over time despite the fact that count (overall throughput) never gets very high.
This peculiarity of standards-based XML technologies, that despite its being built for what might be called “industrial grade” operations, it is also well suited for much smaller scale enterprises – including projects that are not distinguished by their size or scale, but because the information itself is of such high value. The results of a single run of a single stylesheet on a single document can sometimes be very valuable – enough to pay even for a high D, if other costs are controlled.
Finally it is worth noting that the classical solution to this problem – managing operations costs as distinct from development costs - is to separate it out. A developer's time is expensive. If the developer can produce an environment or mechanism whereby someone else, whose time is less expensive, can meaningfully contribute to the process – there are opportunities there.
-
Conversely, a significant strategic risk to the system is if operations are commandeered or locked down in some form that makes operations difficult to manage. Where this is the case (reflected in the model in high operations costs), even an effective tradeoff between (low) D+S and (high) utility and efficacy, can be difficult to motivate. How much energy does it take to turn the crank and push stuff through can be a determining factor.
The model suggests that this risk should be considered as comparable to the risks of setting out to build transformations that are not viable, because they cannot be fully specified or scoped in a way that is practically useful (not just theoretically). They are design failures of similar levels of seriousness. In addition to imagining the conceptual viability of a transformation architecture, you must consider your environment. Having a workflow that is sustainable remains a sine qua non, however elegantly a transformation is conceived or a pipeline is designed.
-
Likewise, if we can also control Development and Setup, while keeping average operations low, we can envision how even a very simple application might give real benefits over time – even if it run only infrequently (count is not especially high) and it requires some effort to run (i.e. operations is not zero).
For example, as an independent contractor I have internal systems for time logging and for tracking bank and credit card accounts. The logging application is indispensible for billing among other things (and now I have time logs going over fifteen years). The bank and credit card accounting enables me to coordinate expense tracking in my accounting software, with my bank accounts, in a form optimized for archiving and future reference. Formally independent of both the systems it aligns with (for robustness and portability), as a side effect of the record-keeping it creates a paper trail (and my accountant appreciates my tidy records). Any self-employed person must, in order to stay in business, have some sort of analogous system (as indeed I was instructed to use a spreadsheet). But it isn't always in XML, while it is … more painstaking and error prone.
These are “toy” systems in that they are very lightweight and in some ways improvised; yet they have paid for the time invested in them many times over.
-
The case of a one-off transformation is easy to see, as it consists simply of the operational overhead, plus the cost of setup and development of the transformation. It pays for itself if the transformation itself is valuable enough to account for this expense. (It can sometimes be compared to the cost of doing the same task by other means.)
-
Similarly, work done entirely by hand (i.e. no transformation reducing costs across a set) simply sets S and D to zero. The conversion is essentially the cost of the “operations” (which may be considerable). This is the trivial “null” case.
-
Note that this algebra also helps shed light on the developer's perennial question, when is it worth automating something. To do so: Consider the cost of Development + Setup with honest counts (both optimistic and pessimistic) and estimates of per-item overhead. Then compare this cost with the cost of doing the task by hand.
Finally, it is interesting that this accounting also makes it possible to begin thinking about one of the more vexing distinctions to developers of transformation pipelines, namely the difference between transformations that go “up hill” and those that go “down”. The metaphor invokes gravity: the idea is, it's harder to go up hill. Since our model already seeks to represent “cost” in terms of energy inputs (D, S, operations), it is possible to consider what higher cost (up) vs lower cost (down) should mean in closer detail.
Up and down transformation
The distinction between “up hill” and “down” is fairly well understood at least by practitioners, and it can even be described and categorized. In the abstract, it is possible to conceive of an uphill conversion is one that adds information or that makes explicit, in the result, information that is only implicit in the source data. What we need is a metric that considers “energy” to be potential in document structural and markup semantics, inasmuch as (and to the extent that) its (encoded) representation is economical, terse, comprehensive within its scope, consistent and transparent – all of which traits help to make subsequent processing easier. (If the super-ordinate semantics of element types and attributes in the model are known in advance, as they frequently should be when using a standard vocabulary, we can further rejoice.) However, the sad reality is that data usually starts life in forms that are the opposite of consistent and regular, at any rate to the high degree necessary. Uphill conversion often requires augmenting the data with information that is not already there. Not only that, but of course the same transformation may go up with respect to some features (adding information that it induces) while at the same time, it goes down in others (leveling other forms of information for purposes of representation).
Nonetheless it is possible to generalize. First, a transformation will be more difficult to develop (high D) when the scope or range of its inputs is very wide. This makes specification of a transformation that will work effectively more difficult (if not impossible in the general case). “Work effectively” is of course subject to definition, but that is, exactly, the crux of it. If count (or throughput or availability) goes down due to ineffectiveness, costs of (successful transformations) go up. For a transformation to work effectively typically means that its results are predictable, rules-bound and confirmatory of (consistent with) policies and designs that have been put in place with forethought. When the range of inputs is very wide, it is (tautologically) harder to enforce rules across the set. Less consistency and quality across the information set means less predictability.
This is why the oldest trick in the book is to manage both development costs (D) and, implicitly, also setup (S) and Operations, by relying on predefined rule sets (schemas), if not industry and community standards to constrain sets of documents in ways that make specification (and thus implementation) of “down hill” mappings feasible. (In a way, the system is optimized early for everything by not being optimized for anything.) There is a subtle tradeoff here: while this method does indeed provide more robust handling through processing pipelines, it also solves the problem (i.e., the problem of accommodating arbitrary semantics in inputs) by setting it aside – with the effect, ironically, that the potential count of the set (of successful transformations) will be accordingly lower. The key to making this work is to see that this latter set – semantic features in the data you wish you could have handled, described and exploited, but were not able to (due to constraints on either resources or means) – is as small as possible - in a manner of speaking, if you never want what you decide you can't have. Yet the opportunity costs of what you are not doing with your data and data descriptions, must always lurk as a not-fully-knowable.
This in turn suggests exactly what we know from experience, namely that these systems work best when inputs can be both (a) appropriately constrained (so the scope of the transformation is manageable) and (b) expressive of the necessary relations in the data (i.e. more or less well tagged for the purpose, whatever the markup language or dialect). The costs of Development – for any subsequent transformation defined over this data set – will simply be lower, sometimes dramatically lower, when this is done correctly. Moreover, this is the case whether the data description is standard, or bespoke, or some combination.
Whenever we have a transformation that is simple and explicit enough to be highly reliable, and average overhead goes to zero - that is a sign that a transformation is going in the “correct” direction. Indeed when we look at the code that underlies such systems we are likely to see things much simpler than in the uphill case.
Development on the next level up
Note that to a degree D (development cost of the transformation) and average operations may be linked, inasmuch as when carefully applied, a modest investment of D can also significantly lower operations (and thus average operations) for a document set – and this is also an effective way to make many transformations viable that would not be otherwise. In effect, this means that developers can be tasked with helping make a transformation profitable not only be implementing the transformation itself, but by reframing or refactoring its context and requirements (with the result that operations costs come down.) Look to your operations and your average operations costs per run; these are where great potentials for improvement are.
Of course, the last fact - the susceptibility of operations' value being affected directly by processing environment – is a consequence of the composability of transformations. If every transformation occurs within a pipeline, it stands to reason that addressing costs of running that pipeline or architecture is crucial to ensure the success of the transformation within it. Invest D (development) in the pipeline as a whole, and the costs of running every transformation in it, will come down.
This relationship also explains the paradox of why a well designed pipeline of steps can be cheaper to build and easier to maintain than a single transformation doing the same thing (and by the same token why micropipelining within a transformation is also a useful thing). Not infrequently, a complex problem can be addressed by refactoring it into into phases, each phase of which can be simpler and easier (even together) to build and operate than a one-pass solution – even one that by some measures is more efficient.
Further implications of the model
In addition to suggesting such a unified view of transformations and the contexts in which they operate, this model also provokes other considerations. In particular, while it can readily be observed that the out-of-pocket costs and commitments in building an XML-based toolkit (whether standards- and community-based or entirely homemade) are much lower than ever before, nonetheless the practical challenges may still be somewhat daunting.
The abstract to this paper suggests some of the practical questions one must ask. Notably, those include specific questions of architecture and environment, which the general model proposed here, deliberately avoids – and they are questions that have always faced developers of systems of this sort, and will presumably always do so. Nonetheless the cost model does offer some perspective, suggesting a few interesting points:
-
Planning ahead (with regard to technology commitments, standards alignment and conformance, policy development, development of governance mechanisms), etc. etc. – all of these are important as ever – but – what characterizes these questions at present is their complexity, which may present us with something of a “Hamlet” problem. At a certain point, plans must be executed. One of the strengths of a toy is, it shows what can be done, before building it out. Sometimes it is better to start small, to adapt, build and learn, than to try and answer everything all at once.
Accordingly, when thinking about tools building, look for real needs that those tools might help to address, and be willing to start small.
-
Similarly, agility is going to count. One reason the tools of today are so powerful is that they are configurable. So configure them!
-
Standards and the resources that go with them have proven to be an invaluable resource and a common asset to be protected. This reinforces the common sense and conventional wisdom that we should use them to every extent possible – even while we should be clear not to compromise business or project goals to them. This is usually possible.
-
Because of the contribution to costs of operations for running transformations, bringing these down (where they can be reduced) should be a priority; this is where the friction in the system tends to be. This means when possible automating or semi-automating routines that are time consuming but predictable, or that consume energy cross-checking what was done manually since automated means were not available.
Important to note however that these stress points are not necessarily in the center; much more they happen at the front (intake) or back ends (post-production and delivery). As noted, addressing these issues can have dramatic effects on costs of running pipelines even when they are not at the core.
Nonetheless, these improvements are worth nothing if the core does not work. A reasonable development strategy might be, first, to demonstrate the viability of a transformation at all without worrying about operations costs; then, when it is working, address issues there.
Moreover, we can now see what effects it is likely to have if the costs of S+D have been dropping for everyone due to market externalities. Largely because experts in XML transformation (or for that matter, of document processing technologies) are fairly rare, D in particular is still not exactly low. Yet nevertheless given available tools, for someone who does have facility (or who can learn!), costs of D can be very low over time. In principle, this should bring the technologies within the capabilities of a great many organizations who were formerly, simply, unable to enter this market – if they can cultivate the talent.
Standards as commons
Why have costs of development and setup been plummeting? The single most important reason is the success of standards, technologies and community efforts in XML space. As a random example, consider TEI. Focusing on academic research and publishing especially in the humanities, TEI helps publishing and scholarship in general for all its participants by sharing not only specifications, but tools. In doing this, the TEI indeed threatens to “encroach”, to some extent, on work traditionally done by publishers or their vendors; yet by doing so, it makes the potentials (or at least, many of the potentials) of XML technologies accessible to a user base, which would not be able to afford the vendors in any case. And the work that they do ends up – if only because TEI provides a place to start, and its users have a role to play – benefiting the supposed competitors, the very publishers and their vendors who would be trying to do the work, in any case, without them. The entire industry and marketplace moves forward more quickly because underlying assets (including not only the TEI Guidelines but the tools, demonstrations and indeed expertise that go with them) are shared, not held apart.
This is only to choose one community more or less at random, while just the same might be said in different ways about public resources like DITA, NISO JATS, XSLT, XQuery or indeed the web itself. Indeed much can be said of any interchange standard, technology standard or publicly specified, community supported initiative. With respect to the individual developer or organization, they are resources, assets we haven't had to pay for. As such, they create wealth indirectly, by helping to keep the (S+D) addend in the formula low (insofar as X amount of it has already been paid for) and thereby helping making the “transformation strategy” more broadly effective.
This used to be theory but in the development of generalized data transformation technologies on the XML stack, we have actually seen this happen. A “technology commons” has emerged that underwrites the development of creative, effective solutions by anyone.
The small organization or operator faces a dilemma here. One is very keenly aware of one's debts to other developers (indeed one's best contributions may seem to be nothing but derivative), yet not in a position – these organizations more than any are strapped for resources – to make much of it. The approved compensation (to contribute one's own efforts) isn't available. So what do you do?
Relax. There is nothing wrong with using a public resource: that is what it is for.
On the other hand, be aware that by using a standard you come to have an interest in it. Ultimately, to help take care of the community is only to help take care of your own.
Paradoxes of real data sets
In addition to the one just mentioned (“standards initiatives seem to undermine markets but can also provide their long-term foundations”), there are other paradoxes we face as we examine the task of building and deploying customized working environments.
Most of these stem from the fact that development of these frameworks has one critical advantage over the development of libraries, standard or community-based tag sets or interfaces, or more generalized frameworks: they can be tuned and developed to actual, not just putative or hypothetical, data sets, and to problems and challenges associated with using them. At least, representative samples of data will be easier to obtain, and it may also be possible to scope requirements with reference to actual not just hypothetical data. (That is, an element usage that never occurs can reasonably be judged out of scope. Why have a rule for something you will never see.) This has all kinds of benefits for constraining the problem set and limiting Development (as an expense), since you avoid developing solutions to problems you do not have.
Then too, the advantage of having an actual system to care about, is that you get to care about that. If your actual users are happy, you don't have to think about your hypothetical users (or not much). Similarly, you have access to feedback that is unavailable, for the most part, to developers who are concerned with the more general case. (This fact alone is why most generalized libraries start as spin-off projects from projects meeting more local needs.) You can always ask your users, what works, what doesn't, and what are the actual not hypothetical needs and opportunities.
What you need to know
You need to know the difference between transformations that go “up hill” vs those that go down. Being able to make this distinction early, before D has been invested, is critical to understanding how tractable a problem is at all. This distinction is best learned by example and by experience: even if certain kinds of transformations (that induce structure or infer metadata from content, for example), are known to be harder in the general case, for practitioners there is frequently an element of knowing it when you see it. When a transformation goes down, or across, there is always clear relation between the distinctions among elements and values given in the source data, and a set of “corresponding distinctions” among element types and controlled values in the result format. Accordingly, going down hill it is always clear how you get from here to there – whereas in the contrary case, the specification of an uphill conversion, there is often a tip-off in the form of hand-waving or a “magic happens here” step. This is something one can potentially learn to recognize even if one does not know exactly how one accomplishes the transformation itself. (Indeed, being able to construct and validate such an actionable mapping from one data description to another, is an invaluable skill in and of itself, and one without which the subtlest programming prowess is useless.)
To be sure, knowing something technically about the processing model of different transformation technologies doesn't hurt, including both W3C-XDM-based transformations such as XSLT/XQuery, and other available options, as this experience helps to inform what sorts of operations (in document processing) are difficult and costly, vs what sorts of operations can be expected to be routine and subject to automation, refinement, and control by tooling.
The general distinction between “up” and “down” is more important than whether a process is (to be) entirely automated, entirely “by hand” (defined in relative terms, but considered generally as “requiring human attention”), or something in between. Even at the same time as it should be obvious that a straight-down transformation should rarely if ever be done by hand (except possibly as an instructive exercise for school children) – better to learn how to implement and execute a transformation – it is also fair to expect that at least certain kinds of “uphill transformation” will always evade automatability even with AI. Looked at from one end, this is actually a good thing: there will always be work for (what we now call) “content experts”. (Indeed we should do our best to create and cultivate a market for such experts.) Looked at from the other, automatability must be a primary consideration inasmuch as it indicates the degree to which development (D) can be applied to lower operational costs (overall or per piece) – where the latter includes the costs of giving attention to work as it goes through.
However, assuming that a system can be sufficiently well controlled (“disciplined”) that it can depend reliably on being able to transform in either direction at all, the promises of twenty years ago still hold up; customized frameworks using standard or even bespoke formats (when appropriately applied!) can demonstrate a number of significant advantages, even at the (so-called) low end where document count will be relatively low:
-
There may be some cost savings in comparison to other means of doing the work – while not necessarily dramatic.
-
Yet, data will come through with better quality and consistency.
-
There will be unanticipated opportunities for information enhancement, application, reinvention - especially to the extent that the data is part of an ongoing living system and not simply an artifact.
-
Despite these developments the information itself is stabilized and protected from further obsolescence.
Stabilized, in this case, means:
-
Information is accessible long-term (formats are insulated from obsolescence) not because we expect the technology of the future to be the same, but despite our expectation that it will not be.
-
Data sets and indeed operations (processing) code are much more likely to migrate off this particular platform and implementation and onto another - something not necessarily valuable today, but whose value can be suddenly substantial. In other words, to the extent we can continue to take advantage successfully of externalities such as the availability of (standards-conforming) software and platforms (even at low cost when necessary), we are also protected from loss of value in those data sets due to "application rot" or degraded access over time (as may happen with proprietary formats).
-
Likewise, because we are using not only formats but also technologies (including code) in externally-specified, standard languages with multiple implementations in the market, we are able ipso facto to take advantage of continuing improvement and evolution in those technologies, from which we all benefit – even without making further investments ourselves.
What will that be? That is very hard to say, except that to point out again that the formula, cost = (D+S)/count + ave, will apply to any transformation undertaken by any means. The same questions apply for an XML/XSLT-based publishing system, a web-based editing and production platform, or an outsourcing vendor. But they will also differentiate the good systems from the bad, no matter what the technology stack, due not to that choice alone but to exigencies of their design:
-
How their cost (to build, setup and run) compares to short- and long-term value (of transformation results);
-
How these costs compare to costs of alternative means to the same or comparable goals;
-
Where smart investments (for example, in infrastructure and training) can help to mitigate and control both Setup and Development costs for any/all your processes;
-
How (and where) Development can also be an investment in future Development;
-
Where environmental factors trump everything (by affecting operations / overhead)
All these must be considered in light of local facts and contingencies. And where they are most interesting, and problematic, is at the edges.
In the meantime, costs of designing and building such contraptions, whether on top of oXygen XML Editor, Apache Cocoon or a freeware XML/XQuery database or any of a myriad other possibilities – as demonstrated every year at Balisage – is now dropping low enough, that even small and medium-size organizations can use them to get real work done. This makes a difference because if the capital and expertise requirements are too great, transformation architectures just will not be built in the commons, only within proprietary stacks. And while this in itself may not be a bad thing (the model worked for some companies for years), it is vulnerable, inasmuch as any proprietary solution risks being exposed to a lower-cost (or open source) competitor that is "good enough" – a final paradox being that the health of customized, proprietary and differentiating applications – including yours – depends on the strength of the commons.
References
[Caton and Vieira 2016] Caton, Paul, and Miguel Vieira. “The Kiln XML Publishing Framework.” Presented at XML In, Web Out: International Symposium on sub rosa XML, Washington, DC, August 1, 2016. In Proceedings of XML In, Web Out: International Symposium on sub rosa XML. Balisage Series on Markup Technologies, vol. 18 (2016). doi:https://doi.org/10.4242/BalisageVol18.Caton01.
[Clark and Connel 2016] Clark, Ashley M., and Sarah Connell. “Meta(data)morphosis.” Presented at XML In, Web Out: International Symposium on sub rosa XML, Washington, DC, August 1, 2016. In Proceedings of XML In, Web Out: International Symposium on sub rosa XML. Balisage Series on Markup Technologies, vol. 18 (2016). doi:https://doi.org/10.4242/BalisageVol18.Clark01.
[Cuellar and Aiken 2016] Cuellar, Autumn, and Jason Aiken. “The Ugly Duckling No More: Using Page Layout Software to Format DITA Outputs.” Presented at Balisage: The Markup Conference 2016, Washington, DC, August 2 - 5, 2016. In Proceedings of Balisage: The Markup Conference 2016. Balisage Series on Markup Technologies, vol. 17 (2016). doi:https://doi.org/10.4242/BalisageVol17.Cuellar01.
[Galtman 2016] Galtman, Amanda. “Web-Based Job Aids Using RESTXQ and JavaScript for Authors of XML Documents.” Presented at Balisage: The Markup Conference 2016, Washington, DC, August 2 - 5, 2016. In Proceedings of Balisage: The Markup Conference 2016. Balisage Series on Markup Technologies, vol. 17 (2016). doi:https://doi.org/10.4242/BalisageVol17.Galtman01.
[Graham 2016] Graham, Tony. “focheck XSL-FO Validation Framework.” Presented at Balisage: The Markup Conference 2016, Washington, DC, August 2 - 5, 2016. In Proceedings of Balisage: The Markup Conference 2016. Balisage Series on Markup Technologies, vol. 17 (2016). doi:https://doi.org/10.4242/BalisageVol17.Graham01.
[Kraetke and Imsieke 2016] Kraetke, Martin, and Gerrit Imsieke. “XSLT as a Modern, Powerful Static Website Generator: Publishing Hogrefe's Clinical Handbook of Psychotropic Drugs as a Web App.” Presented at XML In, Web Out: International Symposium on sub rosa XML, Washington, DC, August 1, 2016. In Proceedings of XML In, Web Out: International Symposium on sub rosa XML. Balisage Series on Markup Technologies, vol. 18 (2016). doi:https://doi.org/10.4242/BalisageVol18.Kraetke02.
[Horn, Denzer and Hambuch 2016] Horn, Franziska, Sandra Denzer and Jörg Hambuch. “Hidden Markup — The Digital Work Environment of the ‘Digital Dictionary of Surnames in Germany’.” Presented at Balisage: The Markup Conference 2016, Washington, DC, August 2 - 5, 2016. In Proceedings of Balisage: The Markup Conference 2016. Balisage Series on Markup Technologies, vol. 17 (2016). doi:https://doi.org/10.4242/BalisageVol17.Horn01.
[Lubell 2016] Lubell, Joshua. “Integrating Top-down and Bottom-up Cybersecurity Guidance using XML.” Presented at Balisage: The Markup Conference 2016, Washington, DC, August 2 - 5, 2016. In Proceedings of Balisage: The Markup Conference 2016. Balisage Series on Markup Technologies, vol. 17 (2016). doi:https://doi.org/10.4242/BalisageVol17.Lubell01.
[Rennau 2016] Rennau, Hans-Jürgen. “FOXpath - an expression language for selecting files and folders.” Presented at Balisage: The Markup Conference 2016, Washington, DC, August 2 - 5, 2016. In Proceedings of Balisage: The Markup Conference 2016. Balisage Series on Markup Technologies, vol. 17 (2016). doi:https://doi.org/10.4242/BalisageVol17.Rennau01
[Sperberg-McQueen 2016] Sperberg-McQueen, C. M. “Trials of the Late Roman Republic: Providing XML infrastructure on a shoe-string for a distributed academic project.” Presented at Balisage: The Markup Conference 2016, Washington, DC, August 2 - 5, 2016. In Proceedings of Balisage: The Markup Conference 2016. Balisage Series on Markup Technologies, vol. 17 (2016). doi:https://doi.org/10.4242/BalisageVol17.Sperberg-McQueen01.
[1] I am aware as I write the final version that the paper tries, for all its broad sweeps across the XML landscape, to avoid any question regarding what might be called the parallel stack (and the elephant in the room), that is, the web stack in all its forms but especially its latest ones. However, the paper implicitly also tries to justify this tactic by declaring its generalizations to apply to any application of technology, even broadly, if or as that application is considered as an information process (or transformation or workflow, in/out) – which it might be. Be that as may be, this note also serves to qualify that I am fully aware that XML's development has very much occurred also within and qualified other parallel and embracing developments, as well.
[2] Needless to say this development and distribution model was faithful to the outlines of commercial software vendors of the time: that a code base should be proprietary was an assumption.
[4] Of course this architecture is as old as publishing inasmuch as it is found in the triad author/editor/printer, but that is another story (and a longer one).
[5] As has been remarked (by Eric Van der Vlist among others), a simple validation is a transformation that returns a Boolean “heads / tails” answer; it gets its power or what might be called leverage (as an application of energy) when its result imputed with a semantics such as “valid” and “invalid”. Because validations can be designed to be systematically discriminating, this becomes a useful gateway function – since one sure way to control costs of transformation is to control the scope or range of inputs.
[6] And note that source and target (result) will be very much relative to the framework. For example, in Tony Graham's framework for the validation of XSL-FO (see Graham 2016), the "source" is the XSL stylesheet or XML-FO instance to be validated – an artifact that in another context, would be a stylesheet or processing spec.
[7] “Cost” could be considered as a form of energy or even as a measure of a scarce resource, namely available and applicable skills.