Making Life Easier for Authors
Publishing organizations have known for years that structured markup languages can facilitate processing of documents into final deliverables. Historically, a big challenge has been making the markup palatable to authors. In two specific browser-based applications that take advantage of the XML format, authors have come to see XML as an ally, and not just a necessary evil.
The applications analyze dependencies among files and topics in potentially large sets of documentation topics, and they deliver relevant information to authors using a web browser. The technologies behind the applications are XQuery [R4], its RESTXQ web API [R2], [R3], JavaScript, and popular JavaScript libraries. The applications described here are used in a 100-person documentation department and are not publicly available. However, the underlying technologies are available to you. This paper shows you enough about possibilities and techniques to inspire you to create your own web applications that combine powerful XML data processing with user-friendly, robust, and potentially dynamic interfaces.
Application 1: Reporting on File Reorganization
The first application helps authors move XML files and associated graphics files within a file system, without breaking dependencies and without violating business rules of the company. It is more cost-effective and less frustrating to make the right set of changes once than to iteratively break and fix things. In 2015, a change in business rules caused the documentation department to move several hundred files that were connected to hundreds of other files through file references. The volume of work and the potential complexity of dependencies meant that having authors manually analyze dependencies would be inefficient and error-prone.
At the other extreme, designing and implementing a push-button tool that analyzed dependencies, moved files, and interacted with the software configuration management system would have required more tool development time than was available. To address the core need within a reasonable time period, we chose the middle ground and developed a web application that analyzes dependencies and provides guidance. One manager said that her group found the guidance helpful: "Quite a few people were a bit concerned about this work but, once they followed the instructions, they got it done very quickly." Over 90% of the file moves were completed in less than a year.
Web Form and Step-by-Step Procedure
To use this application, authors submit a form in a web browser that indicates the file to move, the new location, and which of two computing clusters they use. In the browser, the application displays a report describing a procedure for moving the file and addressing all its dependencies. The following sample report indicates in step 4 that moving the XML file necessitates moving its referenced graphics files to comply with business rules. In step 5, the report indicates which references to the relocated graphics files also need to be updated in other XML source files.

The web interface was more appealing than alternatives for two reasons:
-
Convenience for authors. They do not need to install anything new or look up a command-line syntax.
-
Timing. When we developed this application, the department was planning to switch XML editors. A tool that ran only in the old editor would have become obsolete quickly. By contrast, a web application is independent of the XML editor.
The next three sections discuss the technical details of how RESTXQ turns XQuery functions into web applications, ways to separate analysis code from formatting, and unit testing techniques.
RESTXQ Usage in XQuery Module
The file reorganization application is a simple web application, with a single form that leads to a static report. This application was a good way to start exploring the RESTXQ web API, building on our group's prior experience with XQuery. RESTXQ is a good fit for the technical requirements of this application, providing a way to make a web browser call XQuery code when the author accesses a URL associated with the code. The XQuery code can access XML files in a file system, or in a database compatible with the RESTXQ implementation. In this case, there was already a BaseX database associated with the XML source files.
Using the BaseX [B1] engine for the XQuery language, we developed a single module file that defines a series of XQuery functions. Here are how the functions correspond to the author's actions in the browser:
-
The author points the web browser at a specific URL that ends with
move-xml. A RESTXQ annotation,%rest:path("move-xml"), in the declaration of a particular XQuery function in the module tells BaseX to invoke that function [R1]. The job of that function is to return HTML markup so the browser can render it. As a result, the browser renders the form. -
The author submits the form, causing BaseX to invoke a different XQuery function in the module. This function returns the HTML markup for the report, including text content tailored to the particular file that the author wants to move. In the course of computing the correct HTML markup, the function calls other functions, as described next.
We use the same BaseX database to do bulk reporting on file dependencies, chiefly to help identify files that are shared or unused. Instead of using a web application for the task, the bulk reporting uses cron jobs that create Excel reports. We chose this approach because analyzing the whole file set is time-consuming and because the requirements for bulk reporting do not make a compelling argument for a web application.
Separation of Analysis and Formatting
If you work with XML documents or HTML5, you are familiar with the idea of separating semantics or content from presentation or styling. By design, the XQuery module for this application mostly separates the data analysis, such as looking for file dependencies in the XML documents, from the formation of HTML markup for the browser. Separating these concerns makes it easier to write unit tests for the analysis code and easier to change the appearance or organization of the HTML report.
For example, one step in the report instructs authors to update XInclude references from the XML file they are moving to other XML files. Behind this step are these XQuery functions:
-
filemove:xincludes-within-file— Finds the XInclude references and returns theirhrefattribute values as a sequence of strings. -
filemove:html-xincludes-within-file— Takes the sequence of strings as an input argument, and returns a sequence of HTML<p>and<ol>elements that the author ultimately sees in the browser. The prefixhtml-in the function name is a naming convention throughout this XQuery module.
The unit test module has these corresponding test functions:
-
test:xincludes-within-file— Tests thatfilemove:xincludes-within-fileidentifies the correct XInclude references and returns the results in the expected data structure. -
test:html-xincludes-within-file— Tests thatfilemove:html-xincludes-within-fileproduces the expected HTML markup for different input patterns, including the case where there are no XInclude references to report.
Alternate Approach Using XSLT
An alternate way to achieve the desired separation would be to make the XQuery module produce not HTML markup, but rather intermediate XML markup that links to an associated XSLT stylesheet. The author's web browser would receive the XML markup, apply the XSLT stylesheet to it, and render the resulting HTML markup. This approach would include additional components in the implementation: a design for the intermediate XML markup, the XSLT stylesheet, and potentially an XSpec unit test file for the XSLT. Analysis functions in the XQuery module would return data as XML markup fragments instead of as sequences or maps.
Unit Testing for Analysis Functions
Multiple unit testing frameworks exist for XQuery, some of which are vendor-specific [W1][X1][V1]. Because we use BaseX to develop and deploy the web application, we use the BaseX unit testing module for testing [U1]. We have unit tests for all the analysis functions and most other functions. The unit tests reside in a separate XQuery module that imports the main XQuery module for the file reorganization application.
For some functions, unit testing is straightforward; you call the function with
representative but simple input arguments, and use unit:assert() or
unit:assert-equals() to check that the function returns an expected
result.
For other functions, we use a set of XML files with known dependencies on other XML files to be able to check that the analysis functions find the correct set of dependencies. Basing tests on production XML documents would make the tests unstable because the XML documents change over time. Instead, we use a small set of test documents. The test module includes a setup function that creates an XQuery database with the test documents. In the declaration of this setup function:
After the setup function executes, unit tests can use the testing database when calling the functions under test.
Application 2: Visualizing a Network of Linked Topics
The second application for XML authors helps them visualize the topic network in their DocBook documentation sets. A topic network is a collection of HTML topics and the hyperlinks that interconnect those topics. Inter-topic links make it easy for customers to consume a collection of related HTML topics. In B2 Mark Baker uses the phrase link richly to describe one of seven fundamental characteristics of effective web topics [B2].
Given the importance of links, we wanted a way to visualize the links among topics in a way that would help authors gain insight into the topic network they have created. We already have ways to create links, modify links, and navigate via links, but nothing visual. This diagram uses boxes to represent topics and arrows to represent the links. Solid arrows link among the topics shown, while dashed arrows link to topics that are not shown.
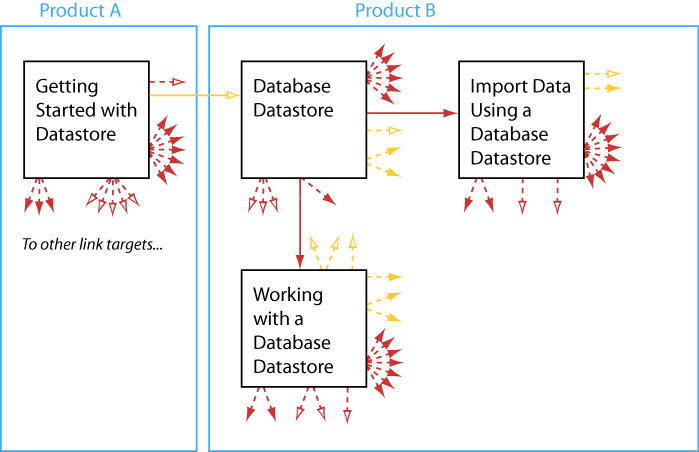
One challenge is that links and topics in realistic topic networks are too numerous to represent using typical directed-graph diagrams. We are only in the early stages of designing effective, readable visualizations of topic networks. At the same time, we have learned useful technical points that are worth sharing here. We describe a way to combine XQuery with JavaScript in a web application that graphically depicts characteristics of XML documents and supports iterative exploration.
Small Multiples and Iterative Behavior
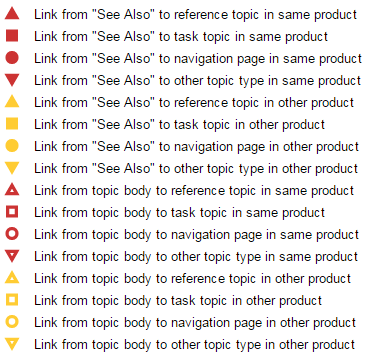
The current prototype of this application uses the concept of small multiples [T1] to depict author-coded links among topics as geometric icons. Icons in the application vary in their characteristics: shape, color, and fill. The icon characteristics depend on:
-
The information type of the link target
-
Whether the link goes from one set of product documentation to another
-
Whether the link is located in the topic body or a designated XML link container, typically labeled
See Also
in our HTML deliverables
The following legend shows the combinations of icon characteristics that can occur and what they mean.
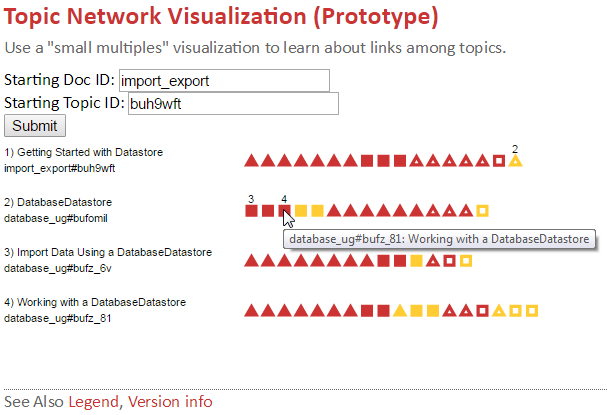
For example, the following row of icons shows that authors coded 25 links in a certain topic.

The fill, shape, and color of the icons indicate that, of those 25 links:
-
Seven are located in the See Also section and point to reference topics in the same product.
-
Two are located in the See Also section and point to task topics in the same product.
-
Twelve are located in the topic body and point to reference topics in the same product.
-
One is located in the topic body and points to a task topic in the same product.
-
Three are located in the topic body and point to reference topics in other products.
The idea is that in the web application, authors can start with a topic of interest, click Submit to display the set of icons that depict topic links, and use the depiction to learn about topic connectivity in the network of topics. They can hover over any icon to see a tooltip that indicates which topic the icon represents. They can click an icon to display the corresponding set of icons for that topic, as a new row at the bottom. By iterating, they can follow an end user's possible clickstream in the HTML deliverables or cover a desired subset of their topics. Using their knowledge of the subject matter and relative importance of each topic, they can assess whether the connectivity characteristics of a given topic are appropriate. After iterating a few times, the results might look like this:
This application traverses a large set of XML documents at the back end, while supporting graphics and dynamic behavior at the front end. Using a web-based front end lets us take advantage of third-party JavaScript libraries.
Boundaries Between XQuery and JavaScript
The application relies on XQuery to find links in the XML documentation and identify their characteristics. We integrated the D3 library, a popular JavaScript library for visualizing data and manipulating documents based on data [B3], with XQuery in a single web application. We also simplified the code using the jQuery JavaScript library [J1]. In this application, JavaScript is the main driver, and it interacts with XQuery at these discrete points:
-
When the author submits a form to indicate a starting topic of interest, the jQuery-based callback function calls XQuery to gather data about links to that topic.
-
After XQuery gathers data from the XML documents, JavaScript depicts the data graphically using the capabilities of D3.
-
When the author clicks an icon that has a JavaScript callback function, XQuery gathers new data about links. The callback for the clickable icons is similar to the callback for the submission button in the form.
This diagram summarizes how JavaScript, XQuery, and the author's mouse operations transfer control back and forth in this application.
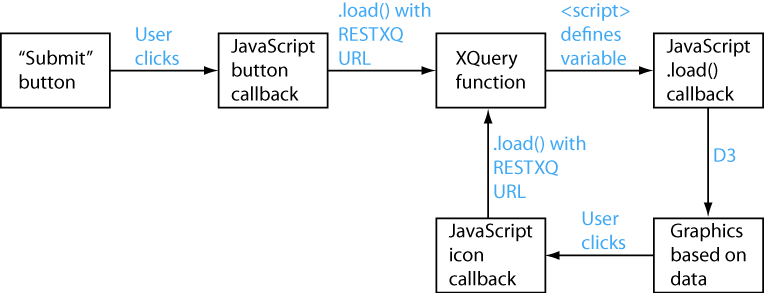
Calling from JavaScript to XQuery
One way to call XQuery from JavaScript is to use the AJAX .load() method in
jQuery [J2]. When this method accesses a URL associated with a RESTXQ
path, the XQuery engine invokes the XQuery function that maps to that URL. The XQuery
function returns markup. The .load() method regains control and inserts the
returned markup into the page.
For example, suppose the HTML page contains the following markup.
<div class="xmlcontainer"> <!–- XQuery will populate this part of the page. --> </div>
The following JavaScript code selects the <div> element using a jQuery
selector, and loads a URL.
$(".xmlcontainer")
.load("my-restxq-path/mydocID/mytargetID");Through the RESTXQ path, "my-restxq-path/mydocID/mytargetID", the
.load() method calls the XQuery function associated with that path. The
XQuery module contains a function similar to the next excerpt, receiving two function
arguments via the {$docID} and {$targetID} path templates in the
%rest:path annotation.
declare
%rest:path("my-restxq-path/{$docID}/{$targetID}")
function linkvis:linkinfo(
$docID as xs:string,
$targetID as xs:string)
as element()
{
(: Body of XQuery function goes here :)
};When JavaScript regains control, it inserts the return value of the XQuery function
into
the HTML <div> element.
If further JavaScript processing is necessary after the XQuery function has finished,
the extra JavaScript code can go in a callback function that becomes the third argument
of
.load(). The callback executes when the AJAX request completes.
$(".xmlcontainer")
.load("my-restxq-path/mydocID/mytargetID", {}, function() {
// JavaScript code to execute after XQuery function finishes
});Passing Data from XQuery to JavaScript
In this case, the return value of the XQuery function is not the HTML markup for the graphics we want the application to display. It is the job of D3 to create that HTML markup. XQuery gathers data about links in documents and passes the data back to JavaScript, enabling D3 to create HTML markup based on the data.
Script as an XQuery Return Value
The JavaScript portion of the application needs variables that contain data computed
by XQuery. To define these variables, the XQuery function invoked from JavaScript
returns
a <script> element. This element contains inline JavaScript code that
defines the desired variables as shown here. (The application uses additional properties,
but for simplicity, this code shows only three properties per array object.)
<script>
var mydata =
[
{
"docID":"import_export",
"targetID":"buh9wft",
"topictitle":"Getting Started with Datastore"
},
{
"docID":"import_export",
"targetID":"bhg4l7w-1",
"topictitle":"Getting Started with MapReduce"
}
];
</script>XQuery code to produce this return value takes this form:
<script>{
"var mydata = " ||
serialize(arguments for serializing data...)
|| ";"
}</script>The following larger XQuery fragment puts <script> in the context of
the XQuery function that the JavaScript .load() method invokes.
declare
%rest:path("my-restxq-path/{$docID}/{$targetID}")
function linkvis:linkinfo(
$docID as xs:string,
$targetID as xs:string)
as element()
{
(: XQuery computations go here. :)
return
<script>{
"var mydata = " ||
serialize(arguments for serializing data...)
|| ";"
}</script>
};Constructing JavaScript code by concatenating XQuery strings can be inconvenient and error-prone. We minimized the amount of code we constructed in this way.
JSON Serialization
We used serialize(...) in the last program listing. JSON is a convenient
notation for JavaScript to receive, and XQuery can produce data in JSON format. The
W3C XPath and XQuery Functions and Operators 3.1 candidate
recommendation outlines how to serialize data as JSON [K1].
Although this recommendation is not final, some XQuery engine vendors support JSON
as the
candidate recommendation describes. In BaseX, XQuery code such as the following produces
a
JSON array like the earlier sample.
serialize(
<json type="array">{
for $thislink in $linkseq (: Define $linkseq elsewhere :)
return
<_ type="object">
<docID>{ (: Query logic, such as $thislink/@docID :) }</docID>
<targetID>{ (: Query logic... :) }</targetID>
<topictitle>{ (: Query logic... :) }</topictitle>
</_>
}</json>,
<output:serialization-parameters
xmlns:output="http://www.w3.org/2010/xslt-xquery-serialization">
<output:method value="json"/>
</output:serialization-parameters>
)Data Processing After JavaScript Regains Control
The processing described so far works as follows:
-
The JavaScript
.load()method loads a RESTXQ URL, which transfers control to an XQuery function. -
The XQuery function computes data and returns a
<script>element whose inline JavaScript code defines a variable that stores the data. -
JavaScript regains control and executes the code inside
<script>. -
JavaScript invokes the callback function specified as the third argument in
.load(). The callback function has access to the variable,mydata.
Going one step further, the callback function can use the D3 .data()
method to bind the data in the mydata variable to graphical objects. Here is
a JavaScript code fragment that creates an SVG section of the page and inserts an
array of
<g> grouping elements, each of which is associated with an array element
in the mydata variable.
// Start a new row of data.
var svg = d3.select(".new").append("svg")
.attr("height",rowHeight)
.attr("width","100%");
var symdiv = svg.append("g").attr("class","symdiv");
// Insert <g> elements with data bound to them.
var symbolgroups = symdiv.selectAll("g").data(mydata).enter()
.append("g")
.attr("transform","translate(" + labelWidth + ",0)")
.attr("class","gsymbols")
.on("click",symbolclick);
// Further code inserts symbols, labels, and tooltips.Challenges
While web APIs for XQuery are not that new, it took the tools group a while to be able to use them. We needed to wait until the company's IT infrastructure supported Java servlets. The alternative — running XQuery applications from an individual's local Tomcat server environment — was not appealing because of the dependency on that person's machine.
An additional challenge has to do with individual skill sets. The documentation tool developers in the group who use XQuery are not web technology experts, while the web technology experts in the larger organization do not use XQuery. We are working on this challenge through collaboration and learning.
Conclusion
Over the past several years, XQuery without the web interface has proven its usefulness to documentation tool developers. We are just beginning to explore the benefits of its web interface, and we have found it useful for applications such as the ones described in this paper. We are considering the use of the XQuery Update Facility [S1] within web applications to modify XML documents, instead of just reading and analyzing them.
At the same time, modern authoring tools for XML documents let authors execute XQuery code directly within the authoring environment. Depending on requirements, that capability could be more convenient than a browser-based application. We would do a case-by-case evaluation of functional designs for a given project, and we appreciate having XQuery web applications as a viable option.
References
[B1] BaseX. The XML Database. http://basex.org
[B2] Baker, Mark. Every Page Is Page One.
Laguna Hills, California: XML Press, 2013.
[B3] Bostock, Mike. D3.js - Data-Driven Documents. http://d3js.org
[D1] Database Module - BaseX Documentation. http://docs.basex.org/wiki/Database_Module
[J1] The jQuery Team. jQuery. http://jquery.com
[J2] The jQuery Team. .load() | jQuery API Documentation. http://api.jquery.com/load
[K1] Kay, Michael, ed. XPath and XQuery Functions
and Operators 3.1. W3C Candidate Recommendation 18 December 2014.
http://www.w3.org/TR/xpath-functions-31/
[R1] RESTXQ - BaseX Documentation. http://docs.basex.org/wiki/RESTXQ.
[R2] Retter, Adam. RESTful XQuery.
XML
Prague 2012, Conference Proceedings, p. 91-124.
http://archive.xmlprague.cz/2012/files/xmlprague-2012-proceedings.pdf.
[R3] Retter, Adam and Christian Grün. RESTXQ
1.0: RESTful Annotations for XQuery.
Unofficial Draft 23 February 2015. http://exquery.github.io/exquery/exquery-restxq-specification/restxq-1.0-specification.html
[R4] Robie, Jonathan et al, eds. XQuery 3.0:
An XML Query Language. W3C Recommendation 8 April 2014.
http://www.w3.org/TR/xquery-30/
[S1] Snelson, John and Jim Melton. XQuery Update Facility 3.0. W3C Last Call Working Draft 19 February 2015.
http://www.w3.org/TR/xquery-update-30/
[T1] Tufte, Edward. Envisioning
Information.
Cheshire, Connecticut: Graphics Press, 1990.
[U1] Unit Module - BaseX Documentation. http://docs.basex.org/wiki/Unit_Module.
[V1] Vatsendvik, Knut. Unit Testing
Framework for XQuery.
https://blogs.oracle.com/knutvatsendvik/entry/unit_testing_framework_for_xquery
[W1] Whitby, Rob. xray. https://github.com/robwhitby/xray
[X1] xquery-unit. https://developer.marklogic.com/code/xquery-unit