Horn, Franziska, Jörg Hambuch and Sandra Reker. “Hidden Markup — The Digital Work Environment of the "Digital Dictionary of Surnames
in Germany".” Presented at Balisage: The Markup Conference 2016, Washington, DC, August 2 - 5, 2016. In Proceedings of Balisage: The Markup Conference 2016. Balisage Series on Markup Technologies, vol. 17 (2016). https://doi.org/10.4242/BalisageVol17.Horn01.
Balisage: The Markup Conference 2016 August 2 - 5, 2016
Balisage Paper: Hidden Markup – The Digital Work Environment of the Digital Dictionary of Surnames
in Germany
This paper will report on Onodi, the digital work environment developed for the
project Digital
Dictionary of Surnames in Germany (Digitales
Familiennamenwörterbuch Deutschlands, DFD). Onodi combines three major components:
oXygen XML Editor, eXist-db database, and the content management system TYPO3. It
provides a solution that frees editors from direct interaction with the XML code:
the markup is hidden behind an interface. Onodi also has an automatic publication
feature that can be initiated with just two mouse clicks.
In this paper we would like to show the benefits of this modular approach, since
it utilizes the strengths of every single well-developed system and integrates them
as necessary. In this way it makes use of basic features and functions already
implemented and expands them for special requirements of the onomastic dictionary
project.
In the first part of the paper, we present the DFD-project in terms of its aims,
contents, methods and organization. We then present the digital work environment
Onodi in terms of its basic principles and modular construction. We illustrate some
fundamental features for hidden markup supplied by oXygen on the basis of the
implementation in the DFD. Thereafter, we offer a detailed presentation of features
specially developed by the DFD technical team. These comprise a simple way of
inserting identifiers and the linkage of data in the literature database with the
surname database. The paper ends with a presentation of the publication process and
its interaction with the components of Onodi.
Designers are not users – that is one of the main principles one has to
follow regarding project design according to Nielsen 2008. In this paper,
we present the digital work environment Onodi that was designed for the project
Digital
Dictionary of Surnames in Germany (Digitales
Familiennamenwörterbuch Deutschlands, DFD) in close collaboration with its users.
Onodi’s three main components are the oXygen XML Editor, an eXist-db database and
the
content management system TYPO3. We developed a project-specific graphical user
interface that enables the creation of texts with TEI-conformant markup without working
directly with the XML code.
First, we will briefly present the Digital Dictionary of Surnames in
Germany as a long-term project that records the entire inventory of surnames
occurring in Germany. After briefly introducing the general structure of the work
environment, the features that enable XML editing for technologically less-skilled
users
are explained in detail. Based on the work Denzer/Horn 2014 this paper
presents three new features of the digital work environment: 1) integration of a Zotero
literature database, currently with about 1700 entries, 2) copying and pasting of
identifiers and 3) an automatic publication process.
This paper complements other publications on similar software, e.g. ediarum as a
digital work environment for editing manuscripts (Dumont/Fechner 2014) and
dictionary writing systems (e. g. Atkins/Rundell 2008; Abel/Klosa 2012).
New insights into dictionary production presented here may offer connecting factors
for
other text editions as well as dictionary projects.
Project Presentation
The Digital Dictionary of Surnames in Germany is a long-term project
under the auspices of the Academy of Sciences and Literature Mainz and in collaboration
with Technische Universität Darmstadt and the Johannes Gutenberg University (JGU).
It
began in 2012 and has a planned duration of 24 years. The aim of the project is to
prepare the first-ever comprehensive digital dictionary of surnames which exist in
Germany.[1]
In the database of the DFD, all current surnames (roughly 850 000) in Germany
are lexicographically collated. The published articles, in the end about 200 000,
provide information about their etymology and origin. Additionally, the surname entries
provide information, for example, about the geographical distribution of the surname,
the occurrence of the name in countries other than Germany, morphological or semantic
variants and further reading on the topic.
Also available on the DFD website is information about aspects of the history and
development of names in different countries, their (cultural-)historical context and
general linguistic aspects. Furthermore, the dictionary is embedded in a research
portal
namenforschung.net, which
can be seen as a gateway to various projects and information related to the field
of
onomastic studies.
Previous surname dictionaries only covered a fraction of existing surnames, and
foreign surnames are for the most part not included. The DFD includes names of foreign
origin as well. By using information about the geographical distribution and
localization of surnames made possible by data mapping, one can provide further support
for the etymological interpretation Schmuck/Dräger 2008; Nübling/Kunze 2006). Thus, contradictory and outdated information from (older)
existing dictionaries can be corrected. The new method of mapping the data concerning
surnames is made possible by a program which has been developed for the forerunner
project, German Surname
Atlas (Deutscher Familiennamenatlas, DFA). The data are based on
the telephone directory of the telecommunication company Deutsche Telekom, with the
records dating from the year 2005. The software uses information about surnames, postal
codes and name frequency to create a map.[2]The benefits of the new method can be illustrated by the plausible
interpretation of names, which were previously uninterpreted. The name Fixemer, for example, is not accounted for in the consulted
German or in the relevant foreign-language dictionaries. Due to its geographical
distribution in the Southern Palatinate and Saarland, it was discovered that the name
is
locational, derived from the French place name Fixem (French commune in the Moselle
department, northeast of Thionville).
The online dictionary registers names for which at least ten different telephone
numbers are listed. In addition to these names, variants are included which have fewer
than ten tokens but similar morphological or semantic features. The modular approach
of
lemma selection by frequency, variation and theme provides a diverse range of recorded
names.
Users of the DFD include the interested general public and academic researchers.
Therefore, we provide a user-friendly website, which is free and accessible to everyone.
An example of support provided for the layperson, is the glossary, with explanations
of
technical terms used in the articles. The advanced search, currently under development,
will provide new search possibilities for a diverse set of research questions. Based
on
the developed classification scheme of names, one can create lists of names with the
same categories. Also one can compile names with common linguistic features (for example
Latin genitive suffix –i) or all annotated variants
belonging to one basic name.
The DFD represents a resource, which can be used by many research disciplines.
Surnames offer a variety of information: They serve as a linguistic source, e.g. for
dialectology, because they preserve historical forms of languages and language
variations. Furthermore, migration researchers can use surnames to track population
movements. One such finding can be mentioned here: In German cities and regions with
a
strong industrial sector – especially automotive industry, such as Munich, Wolfsburg,
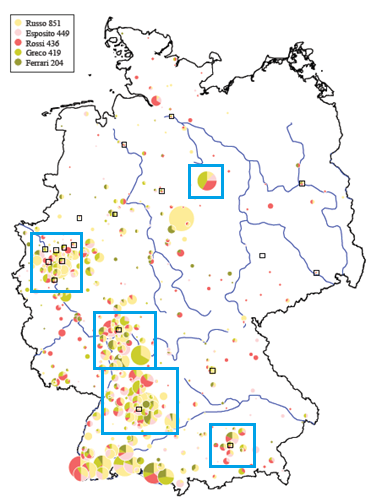
Stuttgart or the Rhine-Main and Ruhr area – one can find many names with a South Italian
origin like Russo, Esposito and Greco. However, surnames
with a North Italian origin, like Ferrari, are rare
(Dräger 2011, p. 143).[3]
Figure 1: Map of Italian surnames in Germany
The map shows the distribution of the Italian surnames Russo, Esposito, Rossi, Greco and
Ferrari within Germany. One can see
clusters around the regions with focus on (automotive) industry – Munich,
Stuttgart, Wolfsburg, the Rhine-Main and Ruhr area.
The information provided by surnames is also interesting for historians, e.g. the
differentiation of occupational groups in the Middle Ages. For instance, determinative
elements of compounds of Müller (English meaning:
miller), such as Freimüller, Bannmüller, Fronmüller and Hofmüller, reflect the different social status in the feudal
system. Frei- in the name Freimüller
indicates that the miller was a free man, while the prefix Fron- in
Fronmüller suggests, that the miller had to pay a
kind of rent to his feudal lord.
General Description of the Work Environment Onodi
The DFD uses an in-house dictionary writing system designed in close interaction with
the users. The main concern is to provide a user-friendly environment which can be
used
to create a richly-annotated and searchable dictionary of surnames that adheres to
modern standards of electronic publishing. This section of the paper will present
the
general structure and basic features of the work environment Onodi. It is based on
a
presentation by Denzer/Horn 2014, but puts more emphasis on designing a tool
for technologically less-skilled users.
Onodi consists of three main components: the XML editor oXygen to enter and edit
contents of the dictionary, an eXist-db
database to deploy and maintain the articles, and the content management system (CMS)
TYPO3 with a custom extension for
publishing and searching. Additional modules are a mapping software and the reference
management software Zotero. The
selected software reflects a preference for using established and mostly open-source
software that can be accessed via interfaces for integration.[4] The dictionary writing system Onodi is used successfully to produce and
publish dictionary entries. This can be noted as a mark of effectiveness – a feature
of
usability besides efficiency and satisfaction according to the ISO standard EN ISO
9241.[5]
The digital work environment is designed to be adapted to the needs and skills of
the
lexicographers. This concerns, for instance, data modelling and the user interfaces
for
editing contents in the editor as well as in the CMS. TYPO3 provides a user interface
and granular rights management. Consequently, users can update and edit contents for
the
website, e.g. news or the project description, relatively easily by themselves in
the
backend of the CMS. The interface for XML editing is based on a so-called oXygen
framework which contains CSS files to format the XML files, XML schemas for validation,
templates for new entries and project-specific preferences for editing such as adapted
menu actions and a menu bar. As a result, a WYSIWYG mode is created that hides the
markup.
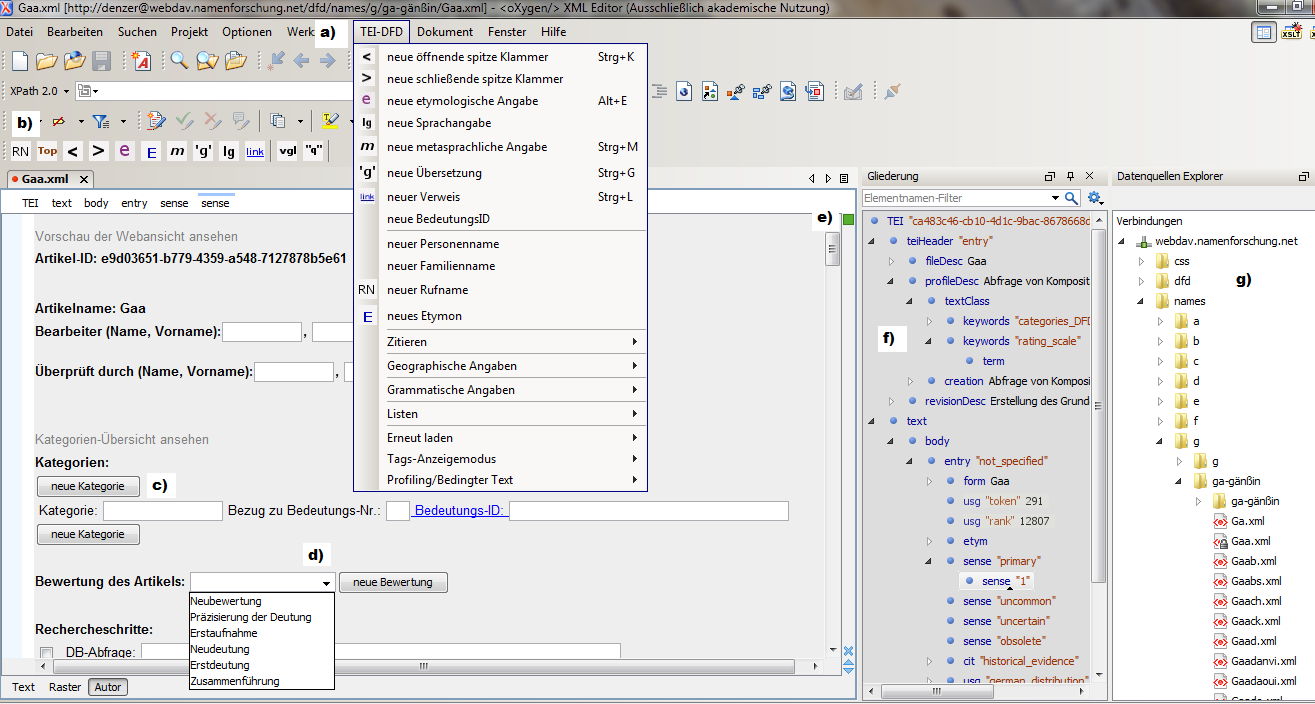
Figure 2: A part of the editing interface in XML editor oXygen
The designations as follows: a) menu for DFD annotations, b) menu bar for DFD
annotations, c) button (here category) to add a new section, d) drop-down menu,
e) real-time validation indicator, f) tree structure view (optional), g) access
to database via WebDAV.
Figure 3: Editing interface: General information such as frequency, rank and language of
origin
Figure 4: XML code: General information such as frequency, rank and language of
origin
The XML is continuously validated against a schema during data input in oXygen. So
the
users receive quick and constant feedback about the well-formedness and validity of
their files. This type of feedback and the emphasis on designing a tailored work
environment for users without extended skills in XML editing are aspects that address
user-satisfaction as one usability feature.
The encoding scheme used within the dictionary writing system follows the TEI guidelines, especially the
module Dictionaries. Following these proposals means providing
possibilities for data exchange and further exploration (Ide/Sperberg-McQueen 1995). The
annotation of relevant information is a key step to realizing basic and advanced
searches on online entries. The dictionary contains not only linguistic but also
extra-linguistic information such as frequency and geographical distribution.
Furthermore, the editor encodes basic working steps he or she has undertaken for
research and production of an entry. These steps are documented quickly and easily
in
the user interface by ticking check boxes which are implemented via oXygen’s check
box
form controls. Some relatively indirect denotations and the usage of numerous attributes
adversely affect the readability for human lexicographers working on the XML. These
are
additional reasons for the development of a work environment that uses oXygen’s author
view of instead of its source view. The use of TEI markup for the entries and SVG
for
the maps reflect the adherence to standards in terms of data modeling.
The user interface is flexible and customizable to adapt a set of requirements:
different kinds of names, e.g. Spanish and Turkish names[6], and different entry types, e.g. glossary entries and entries with
additional thematic information besides dictionary articles. Furthermore, offering
various menu actions provides flexibility and customizability. For instance, if a
user
inserts a reference via the respective button or menu action, a basic code template
is
inserted in the entry. If he or she needs additional elements, e.g. for a second author
or to refer to a column instead of a page, the user can add single elements via the
menu.
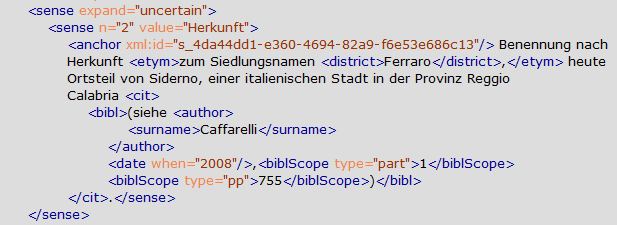
Figure 5: Encoding references in sense (1)
Filled-in code template for a reference.
Figure 6: Encoding references in sense (1) – XML code
Figure 7: Encoding references in sense (2)
Selection of menu actions to customize a reference: new author,
new volume, new page and new
column.
Onodi uses several of oXygen’s custom CSS functions to ensure consistency regarding
data input: Via built-in form controls, the interface provides drop down menus to
select
a language for example, and date pickers, e.g. to choose the date on which an external
online resource was last accessed.
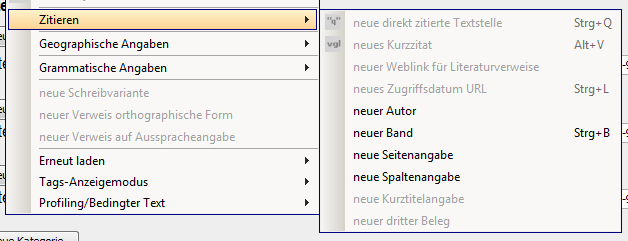
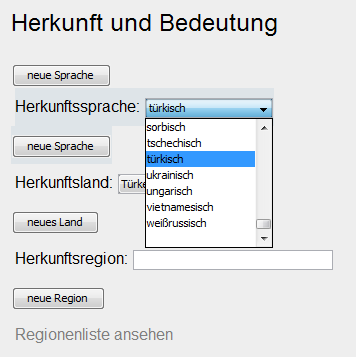
Figure 8: Example for drop-down menu
Based on oxy_combobox built-in form control to select the language of origin.
After selection the correct BCP language tag is inserted in the source code,
e.g. tr for Turkish.
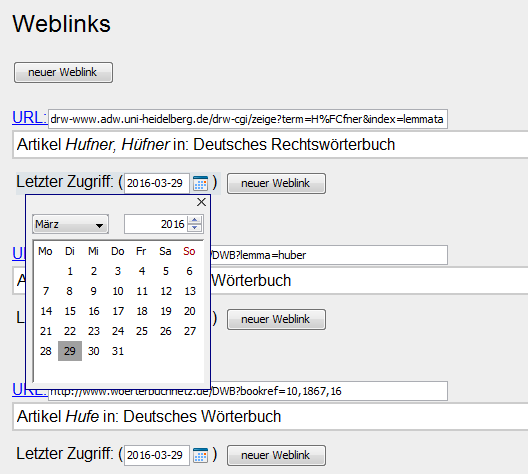
Figure 9: Example for date picker
Based on oxy_datePicker built-in form control to select the date on which an
external online resource was last accessed. After selection the data is inserted
in machine readable form in the source code, e.g. <date
when="2016-03-29"/>.
Users do not have to create new entries from scratch. The production is efficient
because each entry in the database has a basic XML structure. Furthermore, important
fields are already filled automatically, e.g. name, frequency, rank and a UUID
(Universally Unique Identifier) as identifier. The collaborative database can be
accessed by users independent of their location via WebDAV protocol in the editor
oXygen. The protocol locks entries that are opened by a user to avoid conflicts
and unintended overwrites (Dumont/Fechner 2014). For our technical
team, a native XML database such as eXist-db provides another advantage: data can
be
manipulated via X-technologies and there is no need for switching to a particular
database query language, e.g. SQL.
To sum up, Onodi uses various built-in functions provided by oXygen to hide XML
markup. They are a key feature of a user-friendly work environment for users without
extended XML skills. An automatic publication process and menu actions to easily insert
identifiers and to integrate bibliographical data are other useful functions which
extend oXygen’s and TYPO3’s built-in functions and which are presented in detail in
the
next section.
New Onodi Features in Detail
This chapter presents three examples of new Onodi functionalities which go beyond
the
deployment of built-in features of oXygen and TYPO3. They extend the work environment
described by Denzer/Horn 2014.
Copying of UUIDs
As mentioned before, there are three kinds of documents in the dictionary:
articles, glossary entries and so-called thematic information. Each document is
identified by a UUID. These UUIDs are used for linking documents to each other. An
example: To link the article of the Turkish name Aydin to the
thematic information Turkish surnames, the user copies the UUID of
Turkish surnames and pastes it into the appropriate input field
of the article. Furthermore, users are able to link from an article to another
article or to a single meaning inside an article. To be able to do the latter, each
meaning of a name is identified by its own UUID.
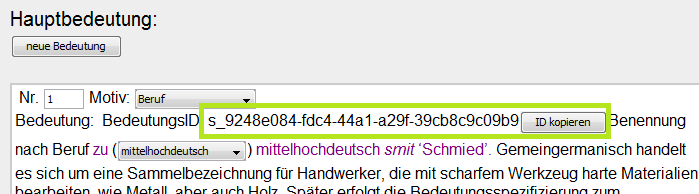
The UUID is stored in an xml:id attribute. We display the UUID as
static text using the CSS selector :before. In author view, it is not
possible to select and copy attribute and element values shown as static text. A
simple solution is to switch to text mode where one has full access to the XML
source code. However, for users without extended XML skills, this carries the risk
of invalidating the document by mistake. Additionally, selecting a UUID like
bd5b4622-81d0-4520-8cdc-8e0d9b680bb0 with the mouse is
error-prone and therefore not user-friendly. If a user accidentally selects only a
partial string, thus omitting characters at the beginning or end of the string, a
broken link is created.
oXygen’s author mode functionalities are extensible. To support customization,
oXygen provides an SDK (Software Development Kit) and an API (Application
Programming Interface). To offer a convenient way of copying the UUID in author
mode, we developed a custom operation in Java.[7] It contains a class called copyAttributeValueOperation which implements
oXygen's AuthorOperation interface.[8] Its doOperation method is customized for our use case. It copies the
value of xml:id to the clipboard. Depending on the context, it uses
either the xml:id from the root element or from an anchor element
contained in a sense element. With CSS we display buttons next to any UUID in the
document, so that a user is able to copy the UUID with a simple click. The user
receives visual feedback by a popup message showing which UUID was copied.
Figure 10: Button to copy a UUID
The UUID shown in Figure 10 illustrates a customization of oXygen’s
auto-generated UUIDs which can begin either with a letter or a number. As valid
values for xml:id, UUIDs have to begin with a letter. As a first
solution, a prefix s_ is added. This temporary solution will soon be
replaced: We developed an oXygen plugin that ensures that UUIDs start with a letter.[9]
To include the custom operation into Onodi, we placed its jar file in the
framework directory and configured the classpath in the framework settings. After
that, the new copyAttributeValueOperation can be configured as an action in the
framework settings. In general, there are three ways to make the action available
for users: As a menu entry, a toolbar button or as CSS button in the document
itself. When using a menu entry or a toolbar button, the user has to place the
cursor at the appropriate node in the document. For now, CSS buttons are used, since
they offer the most convenient way for our users to have a button directly where it
is necessary.
Managing Bibliographical References
Literature plays an important role during creation of the DFD. When interpreting
the meanings of a name, much specialized literature has to be consulted and the
available interpretations have to be assessed. Bibliographical references provide
academic evidence for the interpretation. In published articles, they offer further
information for the interested reader. Not only in articles, but also in thematic
information and glossary entries, bibliographical references are necessary.
We manage our literature with the open-source reference management tool Zotero.
Since all bibliographical information is stored online, it is available independent
of location to all members of our project group. To enter new literature or edit
existing entries, the Zotero website or Zotero standalone software can be used. The
online database is access protected and available to project members only.
The bibliographic data are retrieved regularly in order to make them available
within oXygen. To do so, we use the scheduler provided by eXist-db. It calls an
XQuery script on a daily basis. This XQuery script uses the Zotero API to collect
all bibliographical entries from our Zotero group library and stores them in a
TEI-conformant XML document within the eXist-db database. Currently, our library
contains about 1700 bibliographical entries.
When writing an article in oXygen, users can link to an existing bibliographical
reference by choosing it from a list. To display this list, our framework provides
some custom actions. These actions are located in the main menu, item
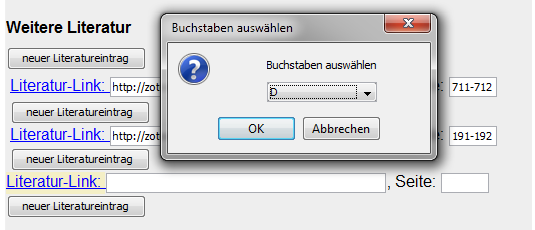
TEI-DFD, sub item Cite. Clicking on New
literature link first opens a select box where the user has to choose a
letter. This is the first letter of the name of the author of the work. After
choosing a letter, the list of relevant bibliographical entries is displayed. The
entries are ordered by author name and year of publication. Above the list, there
is
an input field to jump to an author. When an entry is selected, a click on
OK inserts a URI into the article. This URI leads to the relevant
bibliographical entry in our Zotero online library. By opening the URI, users can
easily check the bibliographical data. Any necessary modifications of the data can
be entered immediately.
We use an index function of ediarum (Dumont 2013) to display the
list of bibliographical entries. First, we tried to display the whole list of about
1700 bibliographical entries at once. For performance reasons we decided to
implement the two-stage workflow as described above.
Figure 11: Creating a link to a bibliographical reference (1)
Drop-down menu to select the first letter of the author’s name.
Figure 12: Creating a link to a bibliographical reference (2)
List box to select a bibliographical reference.
There are no bibliographical data stored in the article. The markup just contains
the URI of the entry in the Zotero library. The URI contains the ID of the entry and
the ID of the Zotero group. So, the link identifies the bibliographical entry
unambiguously. Users have to open the link in order to check if it is correct. To
simplify this, we display a clickable text next to the link using CSS.
Another way to check the bibliographical data is using the web preview we
implemented. The web preview is an instrument for editors to inspect an article on
the DFD website before it is published. In oXygen, CSS is used to display a link in
the article. This link opens the DFD website and displays the whole article.
We use XSLT to transform the article markup to HTML. For each literature entry in
an article, the XSLT script displays the bibliographical data stored in the document
that is regularly fetched from Zotero.
Publication of Articles
An editor can initiate the publication of an article with two mouse clicks. The
further process of publication runs automatically.
Figure 13: Check boxes documenting the working steps before publication
Figure 14: Check boxes documenting the working steps before publication – XML
code
The metadata section of each article contains several check boxes to document the
steps of the working process. When an article is ready for publication, the editor
activates the check box Approval for publication and saves the
document. Technically, this saving is an update of the article in the eXist-db
database. On every update, a trigger fires. It runs an XQuery script which checks
if
the article has the Approval for publication set. If this is the
case, the article is added to a publication list. This list is an XML document which
is stored in eXist-db and contains the UUIDs of all articles waiting to be
published.
Figure 15: An excerpt of the list of articles which are approved for publication
This publication list is used to fetch the articles from eXist-db and publish them
on the TYPO3-driven dictionary website. We developed a custom TYPO3 extension called
dfd which is used to display the dictionary-related content.
Besides this, it contains a task for the TYPO3 built-in scheduler. This scheduler
task calls the URI of the publication list. For each UUID found in the list, TYPO3
looks up the URI of the respective article. It then fetches the article from
eXist-db by sending a GET request to the URI. The XML source code of the article is
stored in TYPO3's MySQL database. This kind of redundant storage makes the online
dictionary independent of the availability of the eXist-db database.
Like articles, the other kinds of XML documents also include a check box to mark
them as ready for publication. Different from the articles, there is no publication
list for thematic information or glossary entries. Since their quantity is much
lower, they are respectively stored in single collections. Thus, the scheduler task
only has to call the URI of the collection. As a response, eXist-db sends a listing
of all documents and their URIs in the collection. The task fetches their XML and
determines by XPath if the check box Approval for publication is set.
If so, the XML is stored in TYPO3's MySQL database. Most of the articles contain a
map which shows the distribution of the respective name in Germany. The scheduler
task fetches each map which is referenced in an article.
The scheduler task terminates when it has fetched and stored all approved
articles, thematic information, glossary entries and maps. The documents are then
available in TYPO3's MySQL database. On the website, the TYPO3 extension dfd
displays lists of articles, thematic information and glossary entries. A website
visitor can read an article by selecting it from the list or by finding it using a
simple search form. To display the article, its XML code is transformed to HTML by
an XSLT script. For thematic information and glossary entries, there are similar
XSLT scripts in use.
Conclusion
With Onodi we developed a digital work environment which makes it possible also for
technologically less-skilled users to produce richly annotated texts, especially
dictionary articles, in an effective and efficient way. As a result, highly structured
entries in media-neutral format are produced using standards such as TEI and
UUIDs.
The user-friendly interface which is similar to well-known text production software
ensures that the editors can concentrate on their research. The linkage by UUIDs of
glossary articles or further thematic information to the name article, for instance,
is
made easier by the feature of copying the ID via a button. Editors do not have to
worry
whether they forgot a number or letter because of this feature. Furthermore, they
do not
have to be concerned about details of the publication process because the process
is
automated.
Because of the modular approach we can profit from the strength of every single
system. One of the benefits of the use of Zotero, for example, and its integration
within the work environment is that within the XML editor, no sophisticated reference
management has to be developed. By linking the citation, it is also relatively resistant
to failure. Data are changed centrally and so they are updated and corrected in each
linked article.
In summary, we hope to have shown that Onodi is a flexible, extensible and
customizable tool that can be adapted to other dictionary projects, especially with
an
onomastic focus.
References
[Abel/Klosa 2012] Abel, Andrea/Klosa, Annette (2012):
Der lexikographische Arbeitsplatz – Theorie und Praxis. In: Fjeld, Ruth
Vatvedt/Torjusen, Julie Matilde (ed.): Proceedings of the 15th EURALEX International
Congress, 7-11 August 2012. Oslo, p. 13-421.
[Atkins/Rundell 2008] Atkins, B. T. Sue/Rundell,
Michael (2008): The Oxford Guide to Practical Lexicography. Oxford.
[Bank 2012] Bank, Christina (2012): Die Usability von
Online-Wörterbüchern und elektronischen Sprachportalen. Information – Wissenschaft
&
Praxis. Volume 63, issue 6, p. 345-360. doi:https://doi.org/10.1515/iwp-2012-0069.
[Denzer/Horn 2014] Denzer, Sandra/Horn, Franziska
(2014): Die Arbeitsumgebung des Digitalen Familiennamenwörterbuch Deutschlands. Ein
XML-basiertes Redaktionssystem. In: Mann, Michael (ed.): Digitale Lexikographie. Ein-
und mehrsprachige elektronische Wörterbücher mit Deutsch: Aktuelle Entwicklungen und
Analysen. Hildesheim/Zürich/New York, p. 67-96.
[Dräger 2011] Dräger, Kathrin (2011): Italienische
Familiennamen in Deutschland. In: Hengst, Karlheinz/Krüger, Dietlind (ed.):
Familiennamen im Deutschen. Erforschung und Nachschlagewerke. Familiennamen aus fremden
Sprachen im deutschen Sprachraum. Leipzig, p. 333-347.
[Fahlbusch/Heuser 2014] Fahlbusch, Fabian/Rita
Heuser (2014): Das Digitale Familiennamenwörterbuch Deutschlands.
Möglichkeiten und Ziele am Beispiel regionaler Namen. In: Gilles, Peter/Kollmann,
Cristian/Muller, Claire (ed.): Familiennamen zwischen Maas und Rhein. Frankfurt am
Main
[et al.], p. 209-226.
[Heid/Zimmermann 2012] Heid, Ulrich/Zimmermann, Jan
Timo (2012): Usability testing as a tool for e-dictionary design: collocations as
a case
in point. In: Fjeld, Ruth Vatvedt/Torjusen, Julie Matilde (ed.): Proceedings of the
15th
EURALEX International Congress. 7-11 August 2012. Oslo, p. 661-671.
[Nübling/Kunze 2006] Nübling, Damaris/Kunze,
Konrad (2006): New Perspectives on Müller, Meyer, Schmidt: Computer-based Surname
Geography and the German Surname Atlas Project. In: Studia Anthroponymica Scandinavica.
Tidskrift för nordisk personnamnsforskning 24, p. 53-85.
[Schmuck/Dräger 2008] Schmuck, Mirjam/Dräger,
Kathrin (2008): The German Surname Atlas Project. Computer-Based Surname Geography.
In
Proceedings of the 23rd International Congress of Onomastic Sciences. Toronto, p.
319-336.
[2] For reasons of data protection a map is only provided if a name has more than
five telephone connections.
[3] For further information and explanation about Italian surnames in Germany, see
Dräger 2011.
[4] As a non-open-source tool oXygen provides several decisive advantages: e.g.
it’s a powerful tool with numerous functionalities and a helpful support team.
For further information about how the components were selected, see Denzer/Horn 2014.
[5] The term usability and its features are
explained in more detail by Heid/Zimmermann 2012 and Bank 2012. They also present studies investigating the usability of dictionaries. Dumont/Fechner 2014 give an example for discussing the usability of a work
environment for editing manuscripts. Nielsen 2012 provides
another introduction on usability with further features and with an emphasis on
usability for websites.
[6] Names are structured and have developed differently in different languages.
For instance, in Spain a person’s name comprises two surnames. Another example
are Turkish names. In comparison with German surnames (and most other European
ones), Turkish names differ in motivation in naming because of their special
historical background. Rather than evolving over several centuries, Turkish
surnames were introduced in the early 20th century by law, obligating every
family to choose and register a surname within a relatively short period of
time. Further information and explanation (in German) about Turkish surnames are
provided here: http://www.namenforschung.net/id/thema/3/1 (June 14,
2016).
Abel, Andrea/Klosa, Annette (2012):
Der lexikographische Arbeitsplatz – Theorie und Praxis. In: Fjeld, Ruth
Vatvedt/Torjusen, Julie Matilde (ed.): Proceedings of the 15th EURALEX International
Congress, 7-11 August 2012. Oslo, p. 13-421.
Bank, Christina (2012): Die Usability von
Online-Wörterbüchern und elektronischen Sprachportalen. Information – Wissenschaft
&
Praxis. Volume 63, issue 6, p. 345-360. doi:https://doi.org/10.1515/iwp-2012-0069.
Denzer, Sandra/Horn, Franziska
(2014): Die Arbeitsumgebung des Digitalen Familiennamenwörterbuch Deutschlands. Ein
XML-basiertes Redaktionssystem. In: Mann, Michael (ed.): Digitale Lexikographie. Ein-
und mehrsprachige elektronische Wörterbücher mit Deutsch: Aktuelle Entwicklungen und
Analysen. Hildesheim/Zürich/New York, p. 67-96.
Dräger, Kathrin (2011): Italienische
Familiennamen in Deutschland. In: Hengst, Karlheinz/Krüger, Dietlind (ed.):
Familiennamen im Deutschen. Erforschung und Nachschlagewerke. Familiennamen aus fremden
Sprachen im deutschen Sprachraum. Leipzig, p. 333-347.
Fahlbusch, Fabian/Rita
Heuser (2014): Das Digitale Familiennamenwörterbuch Deutschlands.
Möglichkeiten und Ziele am Beispiel regionaler Namen. In: Gilles, Peter/Kollmann,
Cristian/Muller, Claire (ed.): Familiennamen zwischen Maas und Rhein. Frankfurt am
Main
[et al.], p. 209-226.
Heid, Ulrich/Zimmermann, Jan
Timo (2012): Usability testing as a tool for e-dictionary design: collocations as
a case
in point. In: Fjeld, Ruth Vatvedt/Torjusen, Julie Matilde (ed.): Proceedings of the
15th
EURALEX International Congress. 7-11 August 2012. Oslo, p. 661-671.
Ide, Nancy
M./Sperberg-McQueen, Michael (1995): The TEI. History, Goals, and Future. In: Computers
and the Humanities 29, p. 5-15. doi:https://doi.org/10.1007/BF01830313.
Nübling, Damaris/Kunze,
Konrad (2006): New Perspectives on Müller, Meyer, Schmidt: Computer-based Surname
Geography and the German Surname Atlas Project. In: Studia Anthroponymica Scandinavica.
Tidskrift för nordisk personnamnsforskning 24, p. 53-85.
Schmuck, Mirjam/Dräger,
Kathrin (2008): The German Surname Atlas Project. Computer-Based Surname Geography.
In
Proceedings of the 23rd International Congress of Onomastic Sciences. Toronto, p.
319-336.
Author's keywords for this paper:
electronic dictionaries; digital work environment; XML; usability; hidden markup; graphical user interface