Introduction
A visualization in general is a spatial presentation of data or information: the effectiveness of a visualization depends on the human ability to process what is seen and to recognize patterns. The term includes diagrams and drawings of concepts, illustrations, and, of particular interest here, data visualizations, in the sense of Owen 1987.
A data visualization (for the purpose of this paper) is the act of (or the result of) presenting data using an automated algorithm (possibly with manual intervention or tweaking). Vis
A diagram (for the purpose of this paper) is a visualization of information that is explicitly designed by a human: one might think of the distinction between a visualization in general and a diagram in particular as similar to the difference between a graph plotted based on a formula and a drawing.
The object of this paper is to explore ways to create visualizations and diagrams relating to XML documents and their schemas, diagrams that are specific to XMl and the ways that XML is used. The goal of these graphics is that they be in some measure:
|
Elucidatory |
that is, that they form a part of an explanation of the XML in some way; |
|
Pedagogical |
that is, that the viewer may learn from the graphics; |
|
Æsthetic |
that is, pleasing to the eye. |
Where possible, the graphics should also be accessible; that is, interactive features should be available for example to someone using assistive technology such as speech to text or a keyboard with no mouse or pointing device. These graphics are an alternate representation of schemas, DTDs and XML documents, and it does not always make sense to try to make them accessible to blind users where the alternate text description would typically be the DTD or other schema fragment being illustrated, but they should certainly work for people who are colour-blind for example.
The intended audience of the diagrams consists primarily of people creating documents and people trying to understand potentially very large XML schemas; some of the diagrams are also visualizations of collections of XML documents and information within them and may be of more general interest.
Diagramming an XML Document
Before starting to draw pictures we should understand the nature of an XML document. In a later section we will explore Document Type Declarations and various sorts of schema languages and constraint systems, but we should start with something as simple as possible.
The term XML document is defined only indirectly in the XML Specification: A data object is an XML document if it is well-formed, as defined in this specification. In addition, the XML document is valid if it meets certain further constraints. However, we also have, The function of the markup in an XML document is to describe its storage and logical structure and to associate attribute name-value pairs with its logical structures XML 1998. In other words we have a pragmatic test for whether something is an XML Document rather than a clear statement of what the term XML Document might mean. We read also that an XML Document has two aspects (and, lacking a third, cannot be divine): its storage structure, also called physical, and its logicalstructure. The physical aspect is sometimes referred to as an XML file, although in fact a single XML document might be formed from any number of computer files and a computer file much contain data for multiple documents.
An XML Document, then, may exist at several levels. Some of these are as follows:
-
A representation inside computer storage (for example, a sequence of blocks on a hard drive)[1];
-
A stream of data that forms a sequence of binary-encoded numbers, usually each of 8 bits (that is, having a range from 0 to 255), achieved by interpreting the binary numbers as “bytes;”
-
A sequence of Unicode characters, achieved by interpreting the byte stream as being a sequence of encoded characters in which one or more binary numbers are combined to form each Unicode character[2];
-
An in-memory representation of an XML document, perhaps accessible using the methods described in the XDM XDM 3.0 or DOM ; the XML specification does not mandate any particular storage mechanism;
Note that an application is free to build any data structure its designer chooses; this does not have to be complete. A program that extracts colours used by an SVG diagram would obviously not need to store the rest of the input, even temporarily.
This representation is achieved by parsing the sequence of Unicode characters using the grammar rules in the XML specification;
-
An on-screen rendering of the in-memory representation, achieved for example using a CSS-based tree-renderer such as a Web browser, an XML editor’s user interface, an SVG graphics editor, and so on;
-
A printed representation of the XML document, perhaps achieved using XSL-FO, XML or HTML with CSS, proprietary tools such as InDesign, or with some other toolset.
We can start with any of these; which is appropriate depends on our purpose. For example, someone developing a parser may want to see a representation of the input stream as a sequence of characters, to debug the mapping from character encodings to Unicode. Most readers of this paper are probably using existing XML tools so we will start instead with a logical representation.
Logical Representation
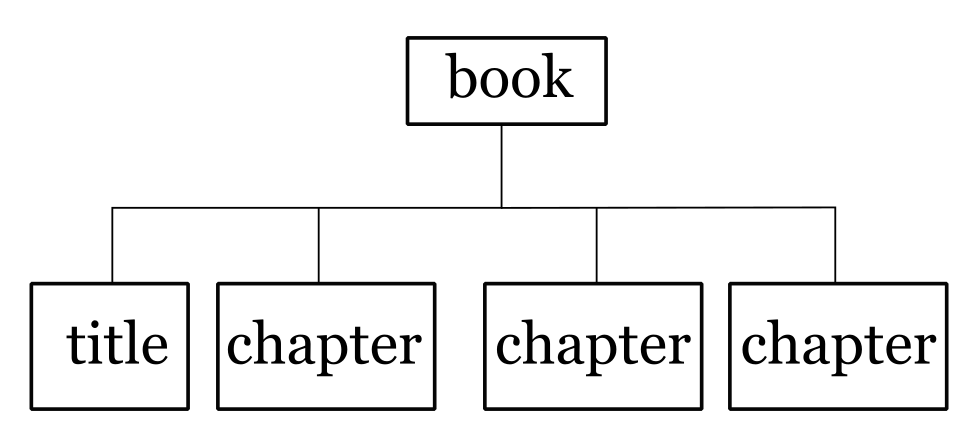
A minimal book diagram.
The diagram in Logical Representation is remarkable partly in its ugliness but chiefly in how little it tells the viewer. It shows a parent-child relationship between a book element and its contained title and chapter elements. The intent of such diagrams is usually two-fold: first, to give an indication of document hierarchy; second, to reassure the newcomer to XML that the logical model differs from the so-called “physical” model of markup characters and text. In fact, such a distinction is not as clear-cut as the beginner might like. A problem with this diagram is that the individual lines are not significant; neither are the boxes. Figure 2 (arguably) conveys the same information more succinctly.
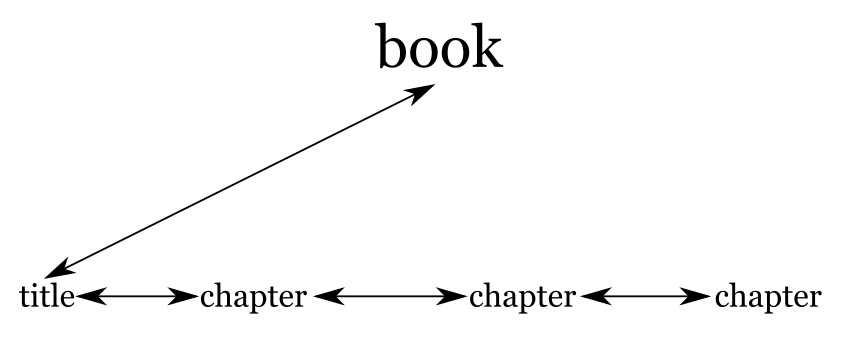
Figure 2

A more minimal illustration of hierarchy in an XML logical document instance.
We draw boxes and lines perhaps because they are familiar from other people who draw boxes and lines, and perhaps influenced by a variety of boxes-and-lines diagrams in computing. But this is the first of a number of examples in this paper where the “traditional” computer science paradigm is not a perfect fit for XML documents. Boxes are used to group things, but we only had one item in each box. Lines are used to indicate explicit parent/child references but in fact XML documents do not have such things. Instead, the parent/child relationship is inferred from containment.
A diagram showing a representation closer to how an XML document might be stored in computer memory is shown in Figure the Third, where the arrows represent direct reachability: an element object might contain a pointer or reference to a linked list of contained elements. Such a diagram is useful for computer programmers implementing XML-based systems but not so useful for authors and schema designers. The programmers may prefer (or need) more complete information, too, and, again, we will return to this with a UML-style example. Note that from a data structure perspective an implementation of a relationship that can be followed in either direction typically involves a pair of pointers, using more memory than unidirectional links and possibly requiring more care on the part of the programmer to maintain both ends of links correctly.
Figure the Third
One way to store a model of an XML document in computer memory is to use a doubly-linked list for the children of each element and to have both a parent and a first-child pointer in each element[3].
In considering how XML documents may be stored we have strayed from logical models of XML documents to physical, where we started this section. The primary audience for this paper is not programmers writing their own XML parsers, since there are already a great many XML parsing libraries.
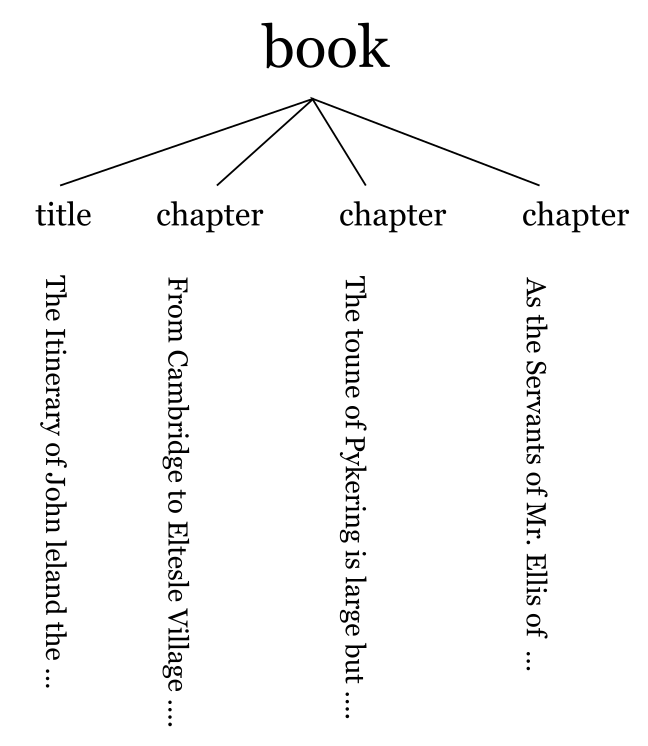
The simple diagrams we have shown so far do not show the textual content of a document, nor do they show XML attributes. One reason for this[4] is that a horizontal tree quickly runs out of room, both in print and on a computer screen. Transposing the tree can make more room. In Figure 4 XML containment has been indicated with nesting. Attributes are still not shown.
Figure 4

Using indenting and type size to show hierarchy and including some of the text from each element.
One of the goals of this paper is to apply some basic principles of graphic design to XML diagrams. We’ll gradually introduce ideas from graphic design in the course of the paper, but let’s start by adding some design flexibility. One way to get more room for the text in our diagram is simply to rotate it, as shown in Figure the Fifth. This does save space but at the expense of readability.
So far we have used only position to show hierarchy. Other ways to indicate hierarchy use size and colour. One way to use colour is to invoke artistic landscape composition and the associated phenomenon of human perception of distance, in which the brain perceives parts of an image coloured red and more highly saturated to be closer to the viewer than objects coloured blue and with less intense colour. The example in Figure the Sixth misuses this in a naïve manner. The problem is that, in a transcription of a printed book or manuscript, element names are generally less important in the hierarchy than the text, but the diagram shows them as large, warm-coloured foreground labels. A similar problem is common in highlighting colour schemes for computer programming languages: the keywords are often shown in bold, with variable and function names in grey or italics. It should if anything be the other way round.
Figure the Fifth
Vertical text might admit more children at the expense of reduced readability. This is an example of the more general design problem of operating with externally-imposed constraints, such as display or paper sizes combined with human vision.
Figure the Sixth

Using colour, size and saturation to indicate foreground and background may emphasize hierarchy in ways that are not appropriate.
In this section we have used some simple diagrams to illustrate an XML document. Our purpose has primarily been to lay foundations for later sections: these diagrams are not XML-specific. In the next section we will contrast generic diagrams with diagrams specific to a specific subject matter or domain.
Schemas and Potential Documents
XML has the distinction of being the only markup system in widespread use today in which documents are commonly constrained in terms of what they can contain. An XML vocabulary can define not only a set of names, such as invoice, payee, total-amount, item, but also a set of rules that limit the content of elements, their placement, the relationships between them, and their quantity. One might want a rule that if you add up all of the individual item prices the total must match. A text-book publisher might insist that documents to be published in a particular series or imprint contain information on author, title and date at the start, together with chapters that each have a title and one or more paragraphs followed by a closing summary and student questions.
Some people come to an XML schema wanting to understand it for the purpose of changing it; others want to write software that processes conforming documents; in most cases (one hopes), the majority of people approaching the schema want to create conforming documents.
A graphical representation of the constraints surrounding an XML vocabulary could be a visualization, intended for exploration, or it could be a diagram, created by a designer for expository purposes. In practice any graphical representation will almost certainly be used for both exploration and storytelling, and so we see the wisdom in Alberto Cairo’s observation that there’s a continuous spectrum rather than two distinct sorts of picture Cairo 2013.
Let’s begin with considering a particular schema. For the purposes of this paper we will use the term schema to mean any set of constraints on documents, whether prescriptive or descriptive. Rather than draw the entire schema we’ll attempt to draw the content rules for a single element.
Elements in XML have associated attributes with values, they have contained elements, and they may also have immediate textual content. It is unusual for vocabularies to constrain the use of processing instructions of XML comments and although it sometimes done we will not consider it in this paper, because when it is done it is usually a special case of constraining elements. So our first attempt at drawing an element surrounds it with its attributes and the child elements it might contain; this is shown in Figure the Seventh.
Figure the Seventh
Minimalistic-style drawing of a single element from a schema.
The vocabulary illustrated is NISO JATS, although that is not of particular concern in this paper. For our purpose what matters is the idea of illustrating a schema. This is not a new idea; a review of older diagrams shows us a wide range, from largely textual depictions of SGML DTDs shipped with SoftQuad Panorama™ in 1994 through Microstar Near and Far Designer diagrams all the way to complete UML and entity-relationship diagrams. A Near and Far Designer style diagram[5] is shown in Figure the Eighth (redrawn by the author using Inkscape).
Figure the Eighth
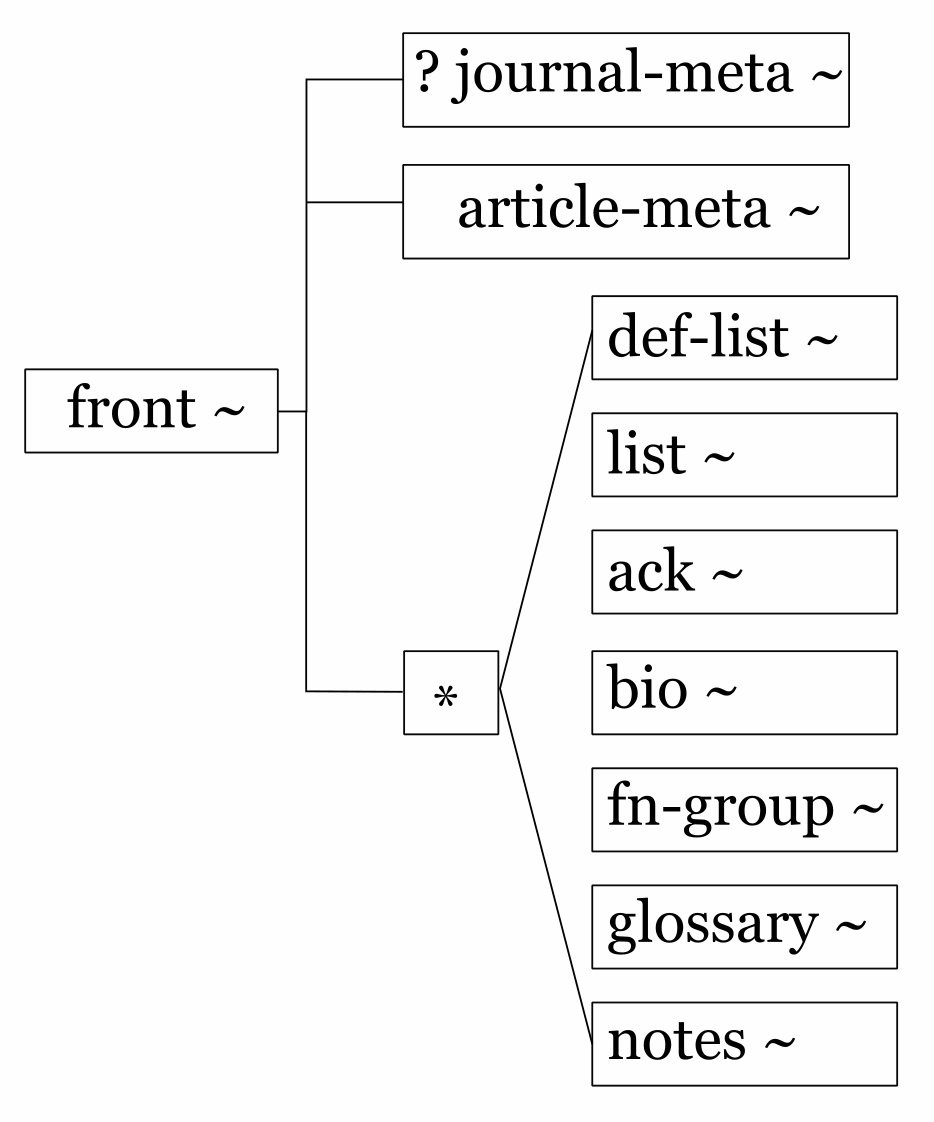
A diagram in the style of the old Near and Far Designer tool, showing possible contained elements for the front element.
The Near and Far Designer diagram shows several things at the same time: the front element has a tilde after its name to show that an instance of that element in a document can accept attributes; a question mark at the start of a name indicates optionality; an asterisk indicates a group of elements of which any number (including zero) can appear in any order in a sequence. There is no explicit indication of sequence (it is implied by vertical juxtaposition) and no immediate indication of what any of the sub-elements might contain (in the application this could be obtained by actuating the represenation of an element, wherupon the application would insert the diagram for the element concerned, expanding the tree. This diagram format was marketed primarily for use by people working directly with an SGML or (later) XML document type definition and doing document analysis rather than for people editing a document, even though many people working with documents also found it useful.
Figure the Ninth

A “Village” diagram of potential containment. The term “village diagram” is used by the author because these diagrams often resemble maps of small settlements of people and houses. Their primary characteristcs are that the children at each level are arranged relatively far from their parent but with their owm immediate children clumped closely around them; a danger for items to overlap is mitigated by having the children branch off at angles resulting in the child-clumps being arranged in a loose circle around their common parent. A more formal term is “multi-directional tree diagram” as used for example by Lima 2013 Chapter 04 but that conflates the widely-spaced clumping layout with the various angles.
The principle of progressive disclosure suggests that a diagram intended for authors should not go beyond immediate needs and should not show grand-child elements. But this would fail to take into account the goal that an author might have to insert an element that is not shown. In addition, in many XML vocabularies, most elements can be given attributes such as xml:lang or id so the indication of attributes is not very useful. Figure the Ninth shows an initial attempt by the author to produce an alternative design. Here, the hierarchy of potential containment is shown with text size as well as colour, and the lines are in colour to exploit a foreground/background visual illusion, in that they can be seen as primary (with a reddish tint) or as background (thin, not saturated, actually purplish). The names of potentially-contained elements have been rotated in a rough spiral around the names of their putative parents. From a design perspective this makes them secondary: the goal is to give indication of the elements beyond the current focus. This could be combined in an interactive application, for example by highlighting the elements that can directly contain text; Figure the Tenth does this using colour, but now something non-obvious has been introduced that requires a secondary explanation. In addition, neither sequence nor the presence of attributes is represented in these village diagrams; only the fact of possible containment.
The goal of Village diagrams is to give a quick indication of potential containment. The diagrams make little attempt to show the ordering of potential child elements, leaving that task to authoring software: in a content model of the form (a, b, c, (d | e | f)*, g, h, c) the initial elements are placed in required order but all other potential children are sorted alphabetically; the diagrams are to be read clockwise starting at the top of each cluster. These diagrams may appear “friendlier” or less intimidating than full UML-style diagrams, or even than the Near and Far Designer pictures, to people less accustomed to thinking in terms of complex abstract containment, athough this hypothesis has not been tested in usability studies.
Figure the Tenth

The village Diagram re-imagined to highlight elements that can contain text.
We will return to Village Diagrams when we discuss interactivity, and we will return to the relationship between a document and its schema when we go beyond two dimensions. This section has illustrated a distinction between a tree constructed from a particular XML document instance (an actual tree) and a (possibly unbounded) set of possible trees implied by a schema. The difference means that representing a schema as a tree can be misleading: any given element might be allowed to appear in multiple points in a hierarchy in an instance document so that the grammar implied is not a strict tree: an element may have more than one potential parent. None the less, trees have been used for representing information for hundreds of years and their familiarity should not be underestimated.
Domain-Based Visualizations
The Extensible Markup Language, taken with the entire “XML Stack” of specifications and technologies, is really a complex system for defining domain-specific markup languages. These are sometimes called a vocabulary or, using an older term from SGML days, a tag set. The term vocabulary is used in this paper to mean a set of element names, together with attribute names, used in a particular way for any particular sort of document. A vocabulary often has constraints, such as requiring that an invoice has a total amount. Languages for expressing these constraints will be discussed in a later section under the generic name of schemas.
Consider the situation in which one is given a set of XML documents and assigned the task of understanding them in some way. You might need to know which element names were used, or which attributes appear on which elements, or what is the longest single line of text, or whether any 8-bit characters occur. But more likely is that your task is to understand some things about the information represented by the documents.
For sighted people, an efficient way to understand a lot of data is often to have the computer draw a picture of the data. Pictures and diagrams that are used to explore possible relationsips in data rather than being used to explain already-understood relationships to other people are called data visualizations.
Peter Robinson wrote, a concentration on digital methods, for themselves, may neglect the base questions facing any editor: why is the editor making this edition; for whom is the editor making this edition? Robinson 1997 A similar question faces anyone creating visualizations: it is all to easy to get lost in the awesome and limitless beauty of artificial trees and to forget one’s true sense of purpose. Peter Robinson concluded, The great promise of electronic editions, to me, is not that we will find new ways of storing vast amounts of information. It is that we will find new ways of presenting this to readers, so that they may be better readers. To do this, we will have to teach our editions to swim to the readers.
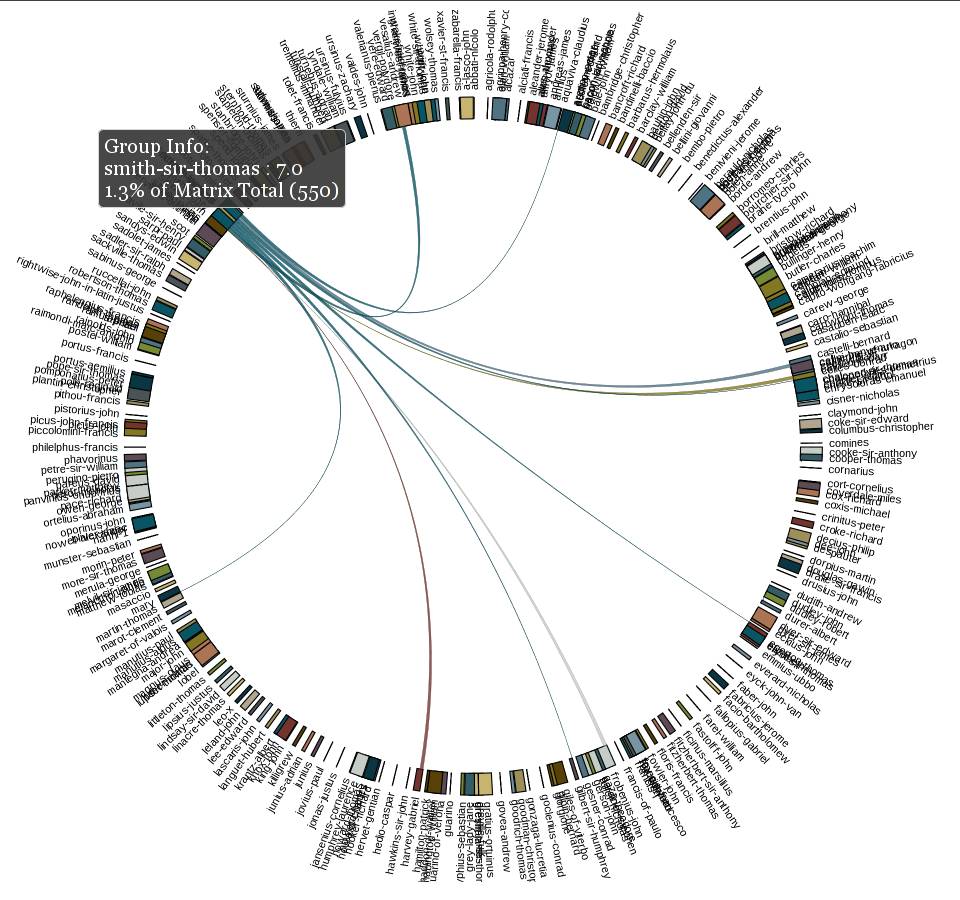
Figure the Eleventh is a chord diagram generated by extracting cross-references from a dictionary of biography; the arcs represent entries that mention other entries. This sort of diagram is excellent for quickly finding “clusters,” or groups of related data—in this case people referred to often or people who refer to many others. The entry for Raphael in this diagram, for example, is connected to the entry for Peruguino and also to that for Duerer. A link from the article for Peruguino makes a connection that is here easily visible but might otherwise, in a dictionary with approximately 10,000 entries, be overlooked. A similar diagram showing places mentioned could be overlaid to give an idea of the likelihood that people worked together or knew one another.
Figure the Eleventh
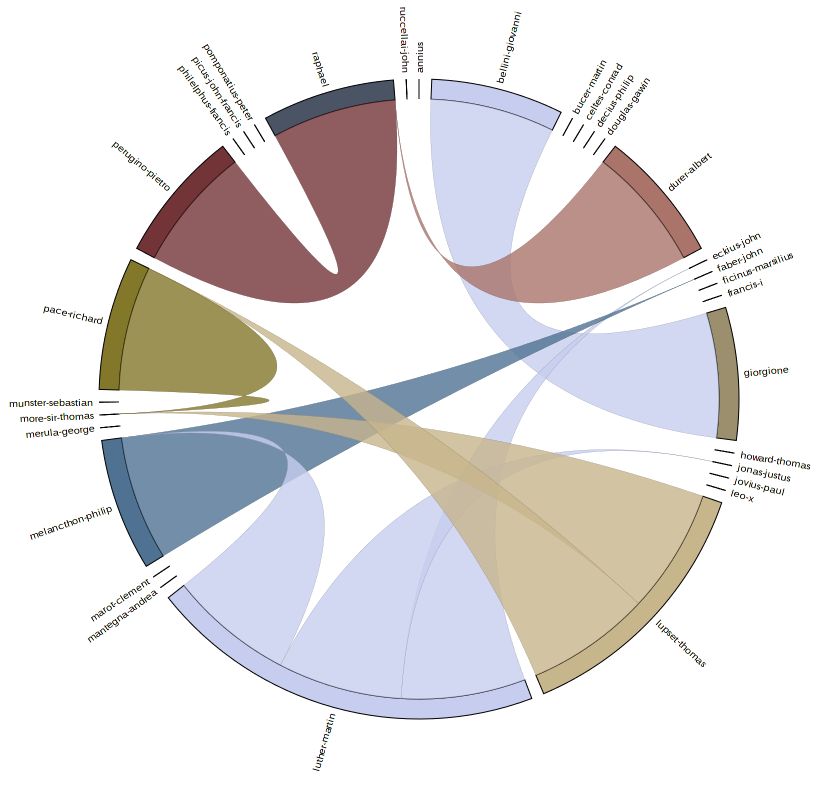
A Chord Diagram shows relationships between entries (in this case) or sometimes groups of entries. This particular diagram illustrates cross-references in a biographical dictionary, in this case restricted to cross-reference to or from entries for people alive at the same time as Erasmus. The size of each segment is proportional to the number of cross-references in the given entry. The colours are arbitrary here and do not convey information, but help the viewer to track the different groups of lines. Arranging the names around the circle by country of birth, or by date of birth, can make evident relationships that are not obvious from a casual reading of a single entry of the dictionary.
A chord diagram can be a useful adjunct to other navigation systems for a large corpus, especially when generated automatically. It can also be made interactive; we will explore this in the section on interactivity later in this paper. Important for our purpose here is that we can exploit a mixture of XML markup, domain knowledge about the document to find which element represent a person’s biography, and schema awareness to find ID values.
Representing Paper
Figure the Twelfth shows a visualization made by overprinting successive pages of a book. The top of the figure is fairly regular, with shadows caused be ascenders and descenders; towards the foot of the page one can see the double-column shadows of footnotes. The faint line at the very bottom is where a double-page spread was set longer, probably to avoid an awkward heading placement on the next page.
Figure the Twelfth

Overlaying multiple pages of a book.
The example of overlaid printed pages shows how a visualization might be of use to different people. If you show a printed book to an experienced printer or publisher you’ll see them lift the book up to the light and peer through the paper. They are testing the quality of “back up,” the alignment of lines of type on both sides of the paper, because care taken in this affects the amount of “show-through,” distracting and unsightly shadows from the past and future appearing between the lines of the text.
Beyond Two Dimensions
We have seen examples of diagrams in which text is rotated, either as a partial circle or, as in the village diagrams, at other angles. In this section we will examine some visualizations that use three spatial dimensions. A three-dimensional diagram can be used to provide extra space, or to show increased detail in the centre of a picture without entirely losing the information at the edges. This sort of diagram is a simulated three-dimensional projection. Figure the Thirteenth shows a village diagram projected onto the surface of a three-dimensional surface, giving an egg-like effect. This turns out to have more visual appeal than practical application, but similar “hyper-focal” elliptical projections have been used in commercial product, including SoftQuad’s HoTMetaL Pro™, with some success. What makes these projections useful is that you can move the “lens”, or rather, move the “paper” beneath a fixed lens, to magnify different parts of the diagram at pleasure.
Figure the Thirteenth

A village diagram projected onto the surface of an egg is useful only if you can move the canvas (or move the egg) easily. User experience is central to the success of applications that use 3D techniques because skills and knowledge demanded of the user tend to be specialized.
Another approach to a third dimension is to construct virtual three-dimensional models which a user can then manipulate, examine, rotate and explode. Figure the Fourteenth shows a deconstructed view of a single page of a printed book. In the figure, the page apparatus, annotations and cross-references, the central Biblical text and the commentary are each represented as a separate layer. This is a three-dimensional model created using the libre software package Blender. A Web-based object renderer can show this object and allow a user to rotate it, to zoom in and view it from different angles, and, like the present writer, to become lost and confused. The figure uses a background gradient in order to help orient the viewer; this is especially helpful if the view becomes accidentally inverted.
Until such time as user interfaces for Web based model viewers are designed with user experience in mind, three dimensional work seems to be of limited utility. In addition there is today difficulty in software portability, although Web browser support for 3D object rendering is improving and, at the time of writing, becoming portable.
Figure the Fourteenth
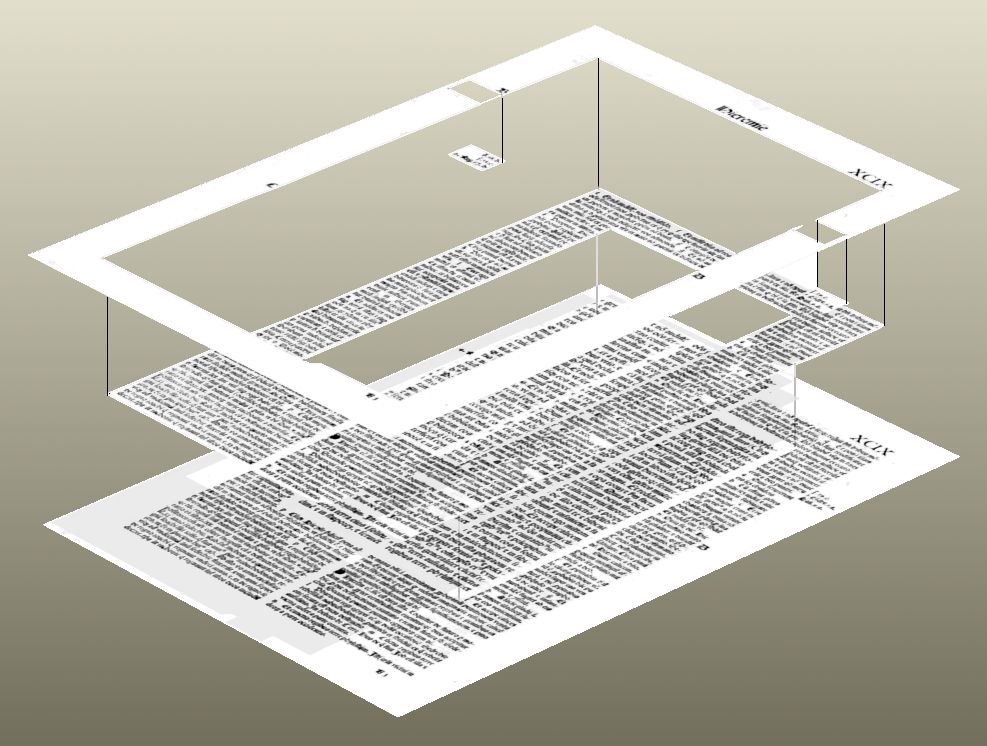
A three-dimensional “exploded view” of a printed page makes apparent the various parts.
Interactivity and Animation
The Chord diagram in Figure the Eleventh was generated using XQuery (with the BaseX implementation) to generate a JSON document read by a JavaScript that uses the D3 library. The layout mechanism used is a parametrized force directed layout Meirelles 2013 pp. 64ff. Thomas 2015 contains a worked example that may be instructive.
It is possible to generate a D3 diagram from XML rather than from JSON, and even to use D3 to animate or lay out an existing SVG document. However, almost all of the easily-available examples use JSON, at least in part because of the simplicity of loading JSON in JavaScript.
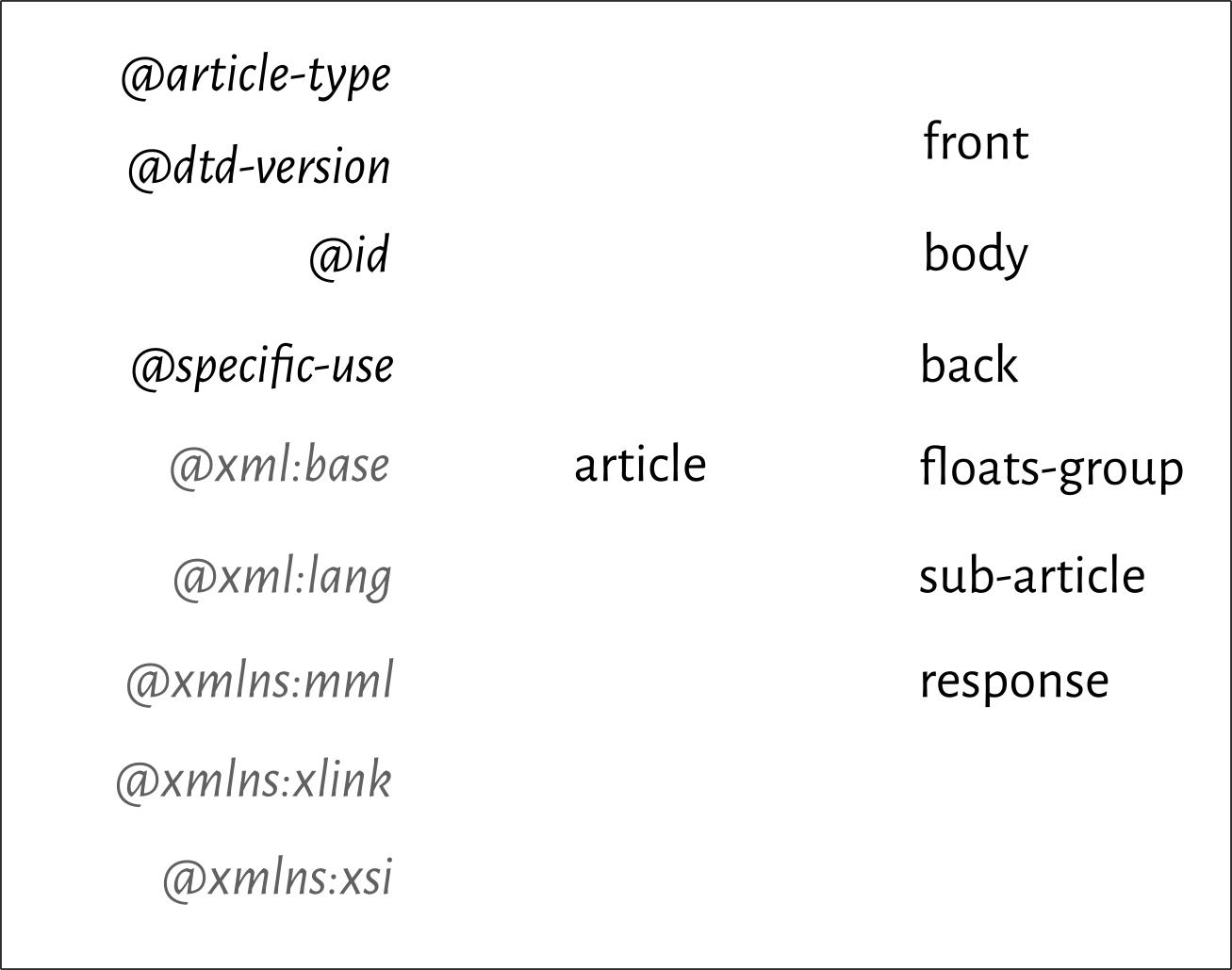
Using JavaScript in the Web browser brings an added dimension to the diagrams. We can animate them and make them respond to the mouse pointer. Figure the Fifteenth is drawn and laid out using the D3.js JavaScript library; it shows that an article element can contain sub-article, front, body and floats-group sub-elements and gives indication of what each of those elements may in turn contain. in this version the text labels are all horizontal, but the final layer of potential containment are again drawn in a spiral. They use an italic typeface because italic is economical of space and has relatively high readability when displayed at an angle.
If you drag a mouse pointer over one of the element groups in the diagram, nothing will happen, because this paper uses static reproductions of the diagrams. However, in a live version the sub-elements are brought to the “foreground” by becoming darker, as shown in Figure the Sixteenth
Figure the Fifteenth
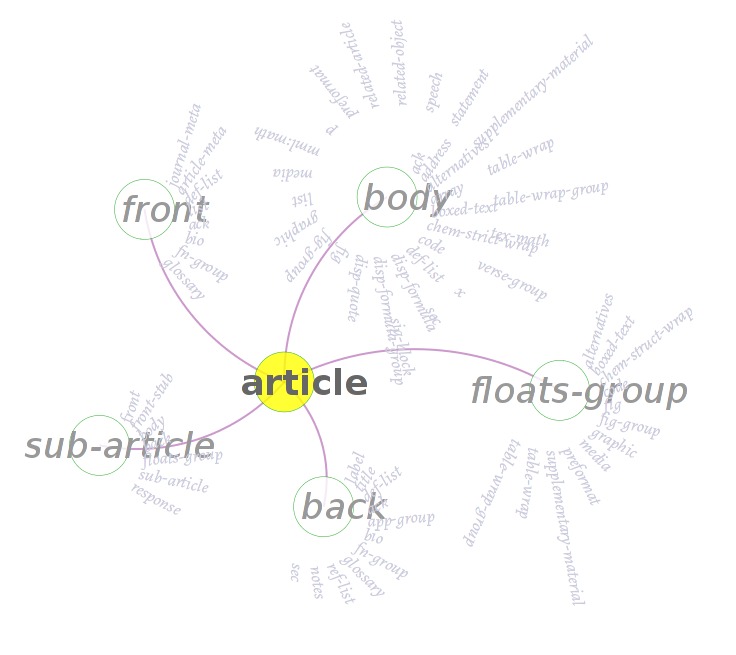
A “spiral” village diagram implemented in a Web browser using the D3.js JavaScript library. The circles behind each main label were added to show the user that the individual groups can be dragged around with a mouse (or finger); such visual indications of possible interactions are known as affordances.
Figure the Sixteenth

The active element group is shown with darker sub-elements, bringing them (in an artistic compositional sense) to the foreground.
A combination of interactivity and animation can be effective in encouraging users to explore a diagram. An alternate way to present a tree is to use nested circles to indicate containment, and Figure the Seventeenth shows a circular treemap illustrating DTD-based potential containment. This diagram also includes attributes (prefixed with an @-sign), and marks optionality and cardinality with *, ? and + as in a DTD. Circular treemaps use a lot of space, unfortunately, but they may be helpful in teaching people about element containment.
Figure the Seventeenth
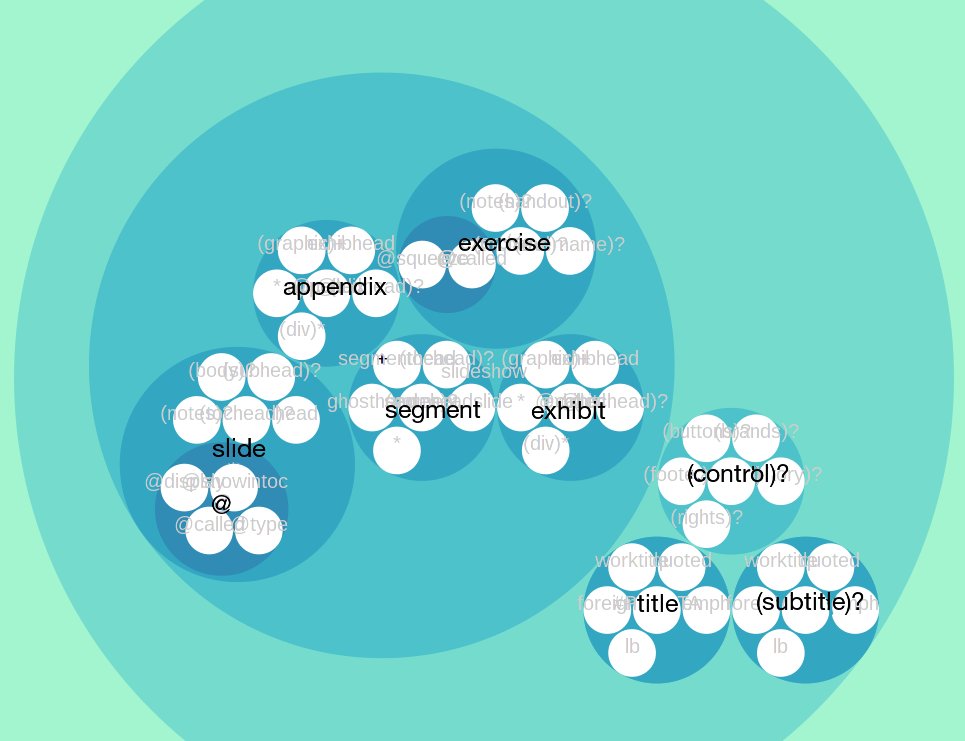
A circular treemap (as described by Lima 2013). Different labels become more or less readable at different levels of zoom, initiated by clicking on a circle.
A more traditional presentation of a DTD uses a tree; Figure the Eighteenth shows such a tree, drawn using D3.js and software to parse a DTD and generate JSON; it would be possible to write that software in JavaScript and have the Web browser read the DTD directly, or to transform an XML Schema using XSLT. Figure the Nineteenth shows the same diagram after a user has interacted with it by pressing some of the boxes to the right of the labels. Pressing once expands, and pressing again hides the sub-tree. A space-saving tree layout is used, creating a relatively compact view despite the apparently wide spacing. The expansion actually occurs over approximately one-fifth of a second, so that there is a strong sense of expansion and collapse. The motion turns out to be quite rewarding and strongly encourages exploration.
Figure the Eighteenth
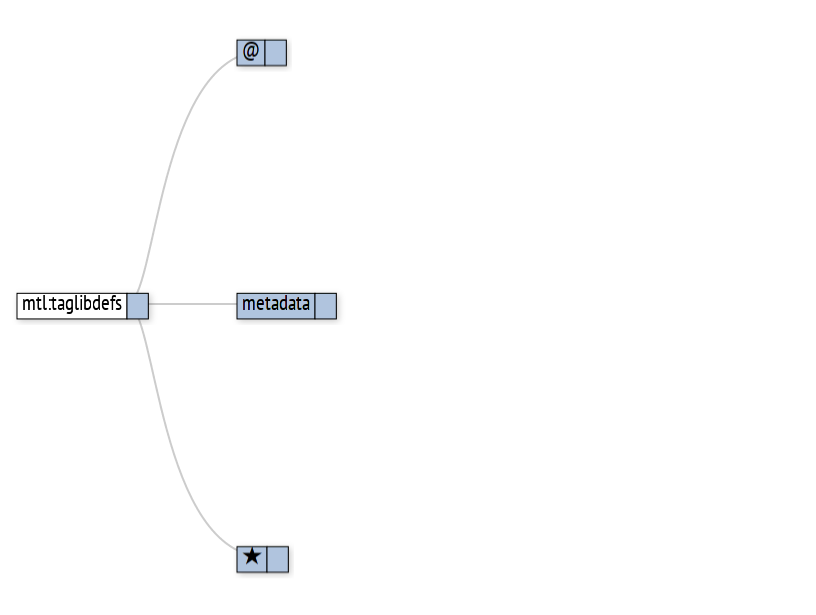
The initial view of the DTD shows the root element and the top-level elements that it might contain. In this case there are XML attributes, a required metadata element and an or-group suggested by a star (★).
Figure the Nineteenth
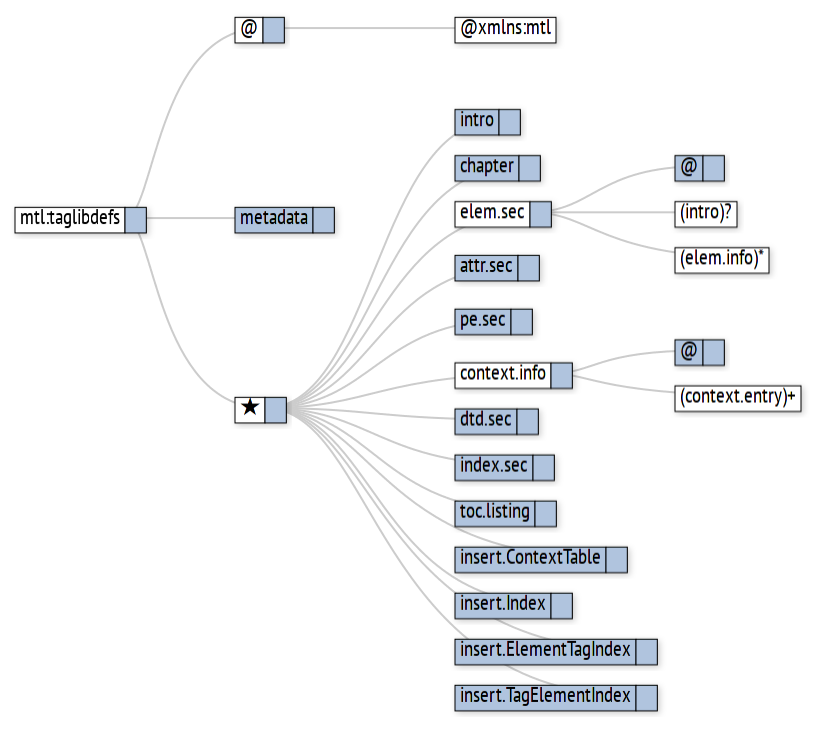
This figure shows the same diagram as the previous figure, after the user has clicked on some of the “expansion” boxes to the right of the labels.
The interactive nature of a Web browser with JavaScript can blur the distinction between document and application. The power this gives must be balanced by the responsibility to create Web pages and applications that people can actually use.
Figure the Twentieth
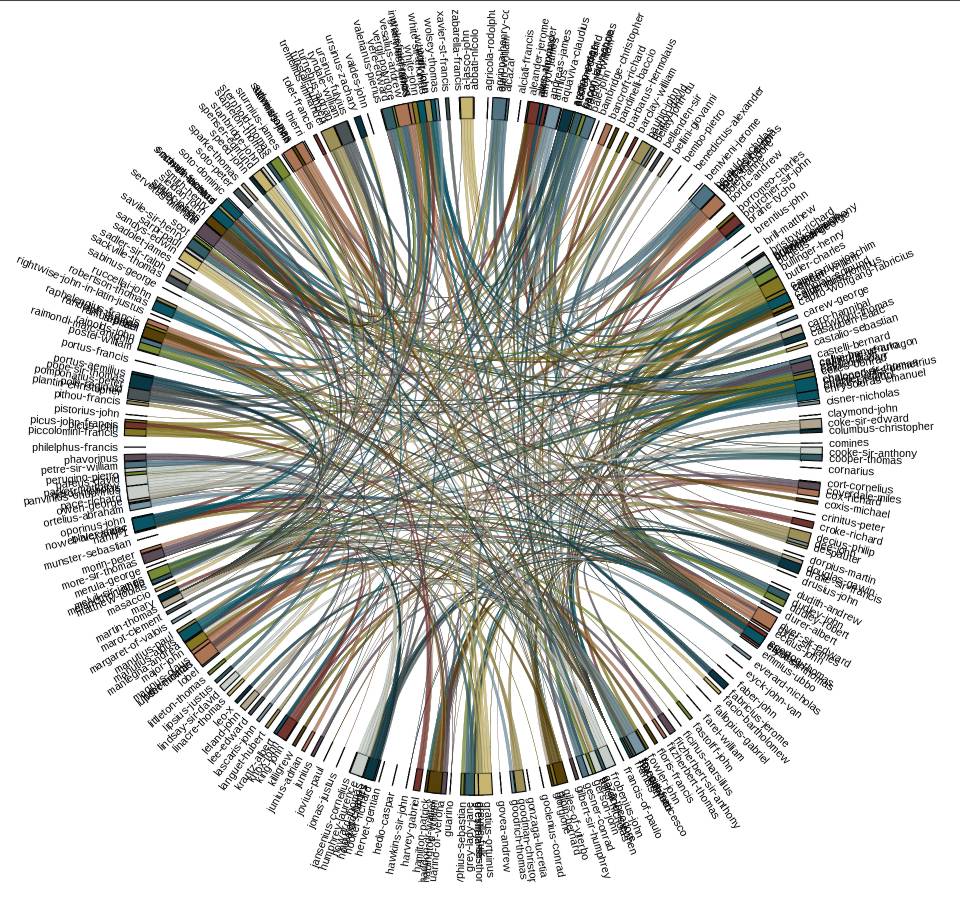
A more complex chord diagram; when there are more then 360 labels some overlap starts to occur at the periphery. This could be mitigated using similar grey/black foreground/background techniques to those used in some of the other diagrams.
Figure the Twentyfirst
When the user “hovers” over a name or the corresponding circle segment, only the arcs corresponding to that name are shown. Additional text is also shown; the text in this figure is in “debugging mode” rather than user mode. Note that popping up text can have accessibility problems even for sighted users, so the actual application displays the text elsewhere along with other domain-specific information.
Interactivity, Foreground and background
The chord diagram from the previous section is already complex enough that it becomes difficult to use on smaller screens. An interesting application of chord diagrams might be an interface to allow users to explore containment in a schema, showing the might-contain and might-be-within relationships. But in a large schema the circle would be too large.
One way to mitigate visual complexity is to use the human vision system’s ability to discriminate between foreground and background. The use of colour has already been mentioned in the discussion of Village Diagrams, with warm colours (red, orange) being perceived as closer to the viewer than cold colours (blue, green). The use of focus can also help the vision system to “pre-process” an image and draw attention to pats perceived as foreground: blurring the edge of items as a function of distance leaves the sharp-edged foreground items prominent.
Complex three-dimensional diagrams benefit greatly from simple artistic techniques such as systematic colour choice and blurring to simulate distance. Although the three-dimensional diagrams are too complex to achieve with D3 and JavaScript in the scope of a short paper, the techniques also apply to simpler diagrams. Blurring and fading in particular can be an effective alternative to “progressive disclosure,” indicating where further information is available but without distracting the user. A sharpening technique with colour value is used in the interactive Village Diagrams to bring an element’s potential children to the foreground when the user indicates interest.
Related Work
People have been writing programs to draw diagrams based on SGML and XML documents. Wendell Piez, David Birnbaum, David Dubin, Michael Sperberg-McQueen and others have presented diagrams at Balisage and the preceding series of conferences, Extreme Markup.
The use of tools such as D3 with XQuery is not new, although using the D3 library to draw XML-specific relationships appears at best uncommon.
The primary contributions in this paper (the author hopes) are the use of the Web browser and JavaScript to make interactive diagrams and visualizations; systematic use of principles and technique from the fields of graphic design and representational art; an emphasis on some XML-specific sorts of relationships such as potential containment coupled with a minimalist reductionism to try to make the diagrams simple and clear.
Conclusions
XML Documents exist as part of a rich ecosystem of schemas, constraints, potential documents and actual documents, transformations and relationships. Data visualization and diagramming techniques can help people to perceive and understand relationships in new ways.
The Open Web Platform has matured to the point where Web browsers can display SVG and can perform sophisticated visualizations that can be created, modified and even animated with JavaScript; JavaScript libraries such as jQuery and D3.js simplify the work of doing this considerably.
This paper has shown examples of visualizing: information in XML documents; XML documents and their structure; XML documents and their relationships with XML Schema constraints; and also the universe of potential XML documents that an XML Schema defines. Some of these visualizations are unique to constrained markup languages such as XML with a Schema, and perhaps also help to illustrate some of the value of using a Schema even if that Schema is not prescriptive.
Finally, some discussion of graphic design and artistic composition has been applied to visualization and diagram techniques; this is a subject for which there are many examples and few tutorials.
The author hopes this paper will encourage readers to explore visual representations for themselves, and also that the paper will help readers to explain some of the benefits of using XML to other people.
References
[XML 1998] Bray, Tim, Paoli, Jean, Sperberg-McQueen, C. M., Maler, Eve and Yergeau, François, Extensible Markup Language (XML) 1.0 (Fifth Edition), W3C, 1998; the latest version is always online at http://www.w3.org/TR/REC-xml/
[Cairo 2013] Cairo, Alberto, The Functional Art: An introduction to information graphics and visualization, New Riders, 2013. A useful book with significant amounts of discussion and examples used to illustrate points rather than being chosen primarily (or only) for aesthetic reasons.
[DOM] Le Hors, Arnaud, et al., Document Object Model (DOM) Level 3 Core Specification, W3C, 2004; available online at http://www.w3.org/TR/DOM-Level-3-Core/.
[Lima 2013] Lima, Manuel, The Book of Trees: Visualizing Branches of Knowledge, Princeton Architectural Press, New York, 2013. Includes both an historical perspective and clear descriptions of a number of ways of displaying trees based on a simple category system.
[Meirelles 2013] Meirelles, Isabel, Design for Information, Rockport, 2013. Many examples and some principles,such as figure/ground, influenced by graphic design.
[Owen 1987] Owen, Scott, ed.
HyperViz - Teaching Scientific Visualization Using
Hypermedia (A project of the ACM SIGGRAPH Education Committee,
the National Science Foundation (DUE-9752398), (DUE 9816443) and the
Hypermedia and Visualization Laboratory, Georgia State University); see
article Definitions and Rationale for Visualization
, last
updated October 1999.
http://www.siggraph.org/education/materials/HyperVis/hypervis.htm.
[Robinson 1997] Robinson, Peter. What text really is not, and why
editors have to learn to swim
, in Literary and Linguistic Computing,
Vol 24, No. 1 (2009). doi:https://doi.org/10.1093/llc/fqn030. Originally written in 1997.
[Thomas 2015] Thomas, Stephen A., Data Visualization with JavaScript, No Starch Press, 2015. Although the coverate of trees and tree-like structures is limited, this book makes few assumptions about the background of the reader and is particularly helpful for those people less confident with the JavaScript language.
[XDM 3.0] Walsh, Norman, Burglund, Anders, and Snelson, John, XQuery and XPath Data Model 3.0, W3C, 014; available online at http://www.w3.org/TR/xpath-datamodel-30/.
[1] We will for the purpose of this paper ignore details of file system block allocation, mainframe fixed record padding, cross-system byte size variations, and many other technical details, and will consider a computer file to be a sequence of bytes, each of which has a numeric value in the range 0..255 inclusive, while recognizing that this is itself an abstraction.
[2] Strictly speaking the sequence can use a non-Unicode encoding, but the resulting XML document, at least conceptually, is made from a sequence of Unicode characters.
[3] A more efficient approach (in both space and time) is to use a finger-tree, but that is wandering outside the scope of this paper.
[4] apart from the fact the author didn’t include them in the pictures!
[5] Version 3 of MicroStar Inc.’s Near and Far Designer included both SGML and XML DTD support.