Quantitative approaches to the study of Russian verse: The research context
Quantitative metrics, and particularly the statistical study of meter and rhyme, has been a core research methodology in Russian verse theory and scholarship at least since the early twentieth century both among Russian scholars (e.g., Belyj 1910, Taranovski 1953, Gasparov 1984) and abroad (e.g., Scherr 1986, Shaw 1993, Friedberg 2009, Friedberg 2011).[1] Until recently, the methods used in this research have had to rely largely on the laborious human identification and tagging or recording within a corpus of all individual stress and rhyme phenomena, which have then served as input into the (often computer-assisted) statistical analysis of synchronic patterns and diachronic trends in meter and rhyme. Not only is this sort of manual effort at corpus preparation not scalable, and therefore also effectively not reproducible, but more often than not the raw data underlying published scholarship have not been shared, which means that the results cannot be replicated and the conclusions cannot be verified for reasons that transcend labor and scalability. Almost the entire corpus of Russian classical verse is now freely accessible on the Internet in authoritative scholarly digital editions (e.g., at FEB and others), and computational tools could therefore be used to relieve scholars of the human labor previously needed in data collection, preparation, and analysis for studies in quantitative versification. To the extent that the data preparation and analysis proceeds algorithmically, intermediate results can be saved and examined and the entire process can be replicated and verified.
The principal limitation to using available poetic texts for this purpose has been that the place of stress in words, which in Russian is not part of standard orthographic practice and is not predictable without linguistic knowledge, must be determined before an orthographic representation can be converted algorithmically to a useful phonetic representation, which is, in turn, a prerequisite for identifying meter and rhyme automatically. To address this need, the authors have undertaken the development of a network of tools, all freely available, that automate as much as possible this process. The system begins with a full-text dictionary of Russian, consisting of approximately 100,000 headwords with all inflected forms, including information about the place of stress, which can be accessed as a web service to add stress information to Russian-language texts in natural, native orthography. The stressed texts can be used for other purposes (such as in readers for language learners), but our principal goal in developing this module was that they could then serve as input into processes that are capable of producing descriptive statistics and visualizations of metrical and rhyme patterns in individual poetic texts and in corpora. These integrated resources thus serve as a workstation for the formal and quantitative exploration of Russian versification in a way that is consistent with current best practice for research data management. All data and other materials and resources are available under a Creative Commons license.
Assumptions and constraints
We are aided in our research by a combination of fortunate accidental properties of Russian orthography, language, and verse practice, on the one hand, and our application of simplifying assumptions and constraints, on the other. These include the following:
-
There is a one-to-one relationship between vowel letters in Russian orthography and syllables in Russian pronunciation. Unlike in English, for example, there are no silent vowels letters and there is no use of sequences of vowel lettters to represent a single vowel sound. This makes it possible to identify and count vowel letters, an easily identified formal component of written Russian verse, as a proxy for syllables, a phonetic property of spoken Russian verse that is less directly accessible on the basis of written input. This approach would not be practical in English, where not all vowel letters correspond to syllabic nuclei.[2]
-
With the exception of compound words, Russian pronunciation does not have secondary stress. Unlike the situation with English, for example, no matter how long the word form, it cannot have more than one stressed syllable.
-
Russian spelling is closer to Russian pronunciation than is the case with English. Normal Russian writing does not mark the stressed vowel orthographically, but if the place of stress is known (for example, by retrieving it from the full-text lookup dictionary mentioned above), the relationship between orthography and pronunciation is simple enough to be described algorithmically with sufficient precision to identify rhyme and other sound patterning.
-
The predominant form of Russian metrical practice since the Golden Age of Russian poetry (first third of the nineteenth century) and continuing into the present is formally strict and generally regular syllabotonic verse. In addition to syllabotonic verse, Russian does have significant syllabic and tonic traditions, which our system is not designed to process. Instead, we target fairly regular syllabotonic verse for analysis, and use the regularity of the ambient meter and rhyme as a heuristic for making predictions about ambiguities and lacunae that cannot be resolved purely from information available in our full-text lookup dictionary.
Our system is not designed, then, to analyze poetry that is not syllabotonic in organization (e.g., free verse, purely syllabic verse, purely tonic verse). It is also not designed to analyze poetry that has a heterometrical structure, that is, syllabotonic poems that do not have the same general metrical type for all lines (such as poems that mix binary and ternary meters, or that mix types of binary or types of ternary meter).[3]
-
We assume that the predominant or ambient meter in a poem must be one of the following: iamb (O X, where “O” represents a weak, or metrically unstressed, syllable and “X” represents a strong, or metrically stressed, one), trochee (X O), anapest (O O X), amphibrach (O X O), or dactyl (X O O). We use the terms predominant and ambient equivalently to refer to the general metrical cadence of the poem, but, crucially, not every strong position will be stressed linguistically in recitation and not every weak position will be unstressed.[4] We identify pyrrhic (O O) and spondee (X X) as possible idiosyncractic variants within generally iambic or trochaic poems, but we exclude them a priori as a predominant type. We make no attempt to identify the rarer ternary feet (those that do not have exactly one strong syllable) or any feet that are neither binary nor ternary.
-
We can deal effectively with lines of different length where the differences result from variation at the end of the line, such as catalexis (the omission of unstressed syllables after the final stress) and hypermetricality (the incorporation of additional unstressed syllables beyond the end of the final foot), including hypermetrical syllables not only in the clausula (end of the line), but also at the caesura (regular correspondence of a word boundary and a foot boundary in the middle of the line). We can also recognize and deal with irregularity at the beginning of the line, that is, with irregular anacrusis (the inclusion of additional unstressed syllables before the initial foot).
-
There is no principled way to distinguish whether, for example, a nine-syllable line with stress on the even-numbered syllables should be considered trochaic tetrameter with a regular anacrusis or iambic tetrameter with a regular hypermetrical syllable in the clausula. In recognition of the stronger general preference for iambic binary verse in Russian, we make that our arbitrary identification when confronted with this sort of ambiguity in situations where it cannot be resolved otherwise (e.g, on the basis of other lines of the same poem that may have only eight syllables).
In Russian verse, as in English, the position of stress is not marked orthographically and is not predictable from the orthography, which means that both the ambient meter and deviations from it cannot be identified purely from orthography (without additional linguistic knowledge). The same is true of rhyme, which requires information about both the position of stress and the phonetic shape of the text, because the orthographic system of the language is not purely phonetic. The first challenge, then, is to use XML tools to make explicit the stress and phonetic information that is only implicit in poetic texts in natural orthography. Beyond that, as is illustrated below, if stress and pronunciation are to be made explicit within an XML model, the most natural representations will involve mixed content. Mixed content poses special challenges for subsequent XML processing because although XSLT and XQuery (and the XPath function library on which they depend) are well equipped to process sequences of nodes, individual atomic values, and sequences of characters within strings, they were not designed with core functions that support the processing of mixed content in a way that corresponds to a human reader’s understanding of continuous poetic text.
Research context
Our project design was developed partially to provide functionality that was not prioritized in other existing computational treatments of verse, which were developed with different goals. Two such examples involve the treatment of verse in the Text Encoding Initiative (TEI P5) guidelines and in the poetry subcorpus of the Russian National corpus (RNC poetry).
Text Encoding Initiative
The Text Encoding Initiative (TEI P5) recommendations concerning metrical and rhyme information in verse texts are limited to using standoff metadata to record analytic conclusions about the poetry. The TEI recommendations are not designed to support tagging the actual textual material so as to assist a computer in identifying metrical and rhyme patterns. TEI verse markup features include:
-
<div type="book" n="1" met="-+|-+|-+|-+|-+/" rhyme="aa">
(TEI P5, Section 6.4.1, cited 19 July 2015) Here the@metand@rhymeattributes record the meter and rhyme scheme in a summary, standoff way, but only after the researcher has already determined them. There is nothing elsewhere in the recommended TEI markup that explicitly associates the individual minus, plus, and pipe characters in the@metattribute value with specific moments in the text itself, and there is no markup within the lines of the poem that would allow the automated computation of those attribute values. This markup is intended not to support the machine-assisted discovery of meter and rhyme in XML-encoded poetic text files, but to record those properties only as user-supplied metadata about the text. -
The TEI recommendations suggest using the
@metattribute for the dominant, or ambient, meter in the poem and a@realattribute on the level of individual lines to represent deviations from that norm. Here, too, the TEI records only information the researcher has already discovered, and provides no support for conducting machine-assisted analysis that would identify and compute these properties on the basis of an input corpus where they have not previously been determined. -
The TEI provides a rich
<metDecl>element for representing complex metrical patterns (TEI P5, Section 6.4.3, cited 19 July 2015), but here, too, what the markup records is the researchers’ conclusions after analyzing the text. The<metDecl>element is not used to mark up the text itself in a way that would allow those patterns to be discovered with machine assistance.
Representing known metrical and rhyme schemes in a consistent way has obvious
benefits over a lack of consistency within or across projects, but the TEI
recommendations do not seek to address the scalability challenges described above.
Our approach to identifying meter and rhyme in a poetic corpus might be compared to
the methods researchers would employ in building an index of first lines, a common
interface feature of poetic corpora. The TEI does not need to advise users about
building this type of index because the procedure is obvious on the basis of the TEI
markup: the first <l> descendant element of the poem in formal
structural terms corresponds to the first line of the poem in human terms. Our goal
is to implement similar functionality for formal verse features that do not lie as
close to the surface as identifying the first line of a poem; for example, if a line
of verse is in iambic tetrameter, we should be able to learn that through processing
the data itself. The results of our analysis might then be recorded with TEI markup,
since we can translate our identifications algorithmically into the sorts of string
values expected for the TEI @met and @real and
@rhyme attributes. One of our goals, then, is to make metrical and
rhyme information accessible in a way that is closer to the actual textual content
than what the TEI provides through metadata attributes.
As noted above, our method is effective with Russian verse of a particular type, but it is not easily transferred and applied to other national poetic traditions, nor to Russian poetry that is not syllabotonic in nature. Insofar as the TEI guidelines are intended to be of broad, general use, they are not the place to look for instructions about, for example, identifying meter or rhyme differently in Russian and in English. Even given that constraint, though, it would nonetheless be desirable to see guidelines from the TEI about how to make information about meter and rhyme accessible in a digital text not merely by assertion at the level of line or stanza or canto or poem, but through computation at a lower textual level. The TEI’s exclusive attention to standoff representations of meter and rhyme obscures the fact that those emergent properties are derived substantially (if not entirely) from phonetic (including stress) properties of the text. Our system therefore prioritizes using those lower-level phonetic properties to derive the higher-level poetic ones, which may then the recorded according to the TEI recommendations or otherwise.
Russian National Corpus
The Russian National Corpus poetry subcorpus (RNC poetry) supports the rendering of verse with accent marks, as in the following screen capture:
Figure 1: RNC stress example: Russian National Corpus output
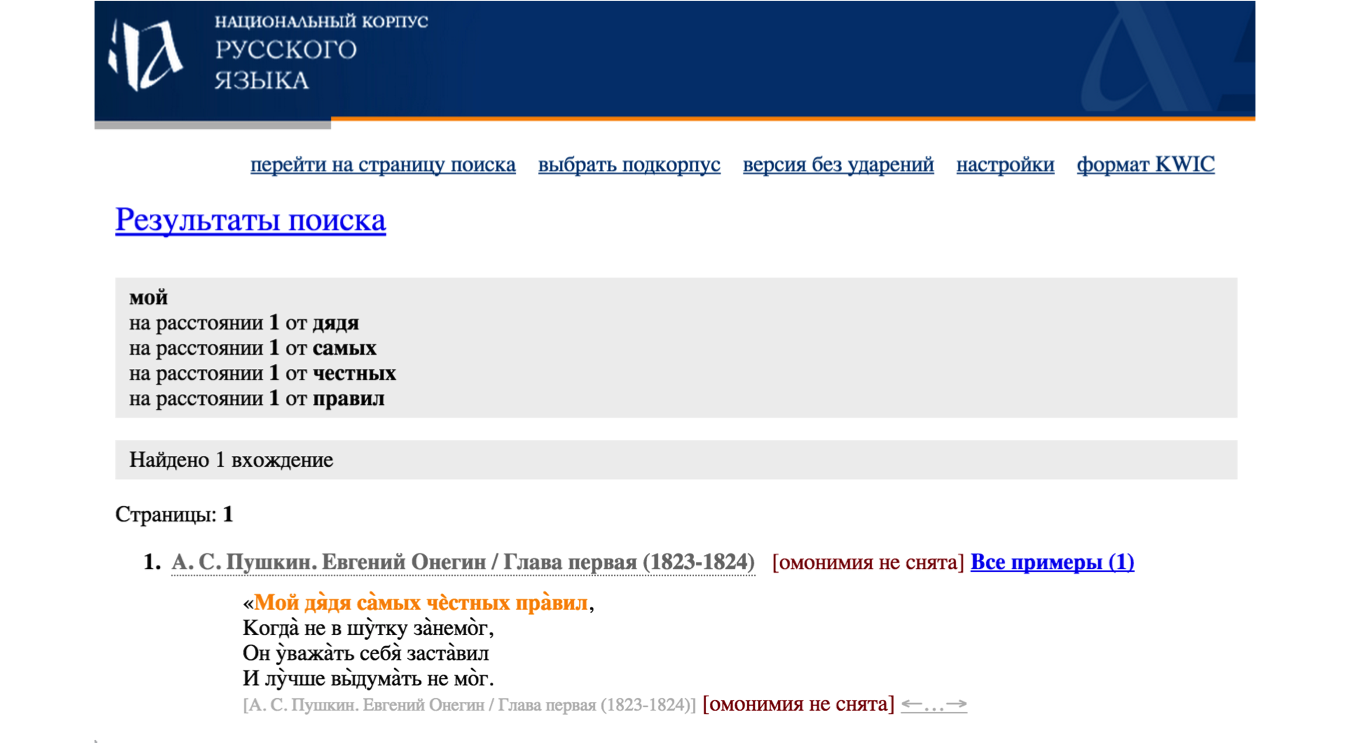
Note the multiple stress marks on the last word of line 2, the second word of line 3, and the middle word of line 4. In fact, these Russian words have only a single stress.
What the Russian National Corpus represents with grave accent marks is not the place of stress during recitation, but the location of strong metrical positions, that is, places where stress might be expected according to to the ambient iambic meter of this poem. This is useful information, although the online presentation may be confusing because it uses a stress mark to identify not stressed syllables, but strong metrical positions, only some of which correspond to linguistic stress. This representation, which essentially just lays a general iambic tetrameter metrical template on top of the words without regard to which syllables are or are not pronounced with stress, makes it impossible to identify deviations from the ambient meter. These deviations lie at the core of, for example, Kiril Taranovski’s (Taranovski 1953) law of regressive accentual dissimilation, discussed below, and it is important for our research to be able to identify them.
Making stress explicit
The machine-assisted identification of meter and rhyme on the basis of plain-text
input documents in standard Russian orthography begins by tokenizing the text at white
space, normalizing it (stripping punctuation and folding case), and looking up each
word
form in a full-text dictionary. The dictionary is an XML database stored in eXist-db, with records that have the following form (in this example,
карий = brown (eye color)
):
<item>
<unstressed>карий</unstressed>
<stressed>к<stress>а</stress>рий</stressed>
<pos>п</pos>
<form>
<categories>
<category case="N" gender="m" number="sg"/>
<category case="A" gender="m" animacy="i" number="sg"/>
</categories>
<content>к<stress>а</stress>рий</content>
</form>
<!-- other <form> elements -->
</item>Each lexeme is an <item> element and every inflected form of the
lexeme is an item/form/content descendant, which encodes the place of
stress by wrapping the stressed vowel in <stress> tags. The only
content of the dictionary we use at present is the <content>
elements; for every word token in the input document (represented in the following
example as a $currentToken variable) we query the dictionary for
//content[. eq $currentToken]which atomizes the
<content> element, effectively stripping any internal
<stress> markup and and comparing the string value to the plain
text input token. We retrieve the entire <content> elements that
match, including the internal <stress> elements, and transform them
with XSLT to wrap each match in <str> (= stressed form) tags and to tag all vowel letters as
<vowel> elements
with a @stress attribute that has three possible values: 1=
stressed,
-1=
unstressed, and
0=
stress status unknown.
In most cases the wordform is in the dictionary and there is a single match, which gives us the unambiguous stress position for that token. If the word is not in the dictionary or if there is an ambiguity (there are Russian wordforms that differ only in the place of stress, and that therefore are indistinguishable from one another in plain text), the dictionary returns all possible values. In the example above, the dictionary will return
<str>к<vowel stress="1">а</vowel>р<vowel stress="-1">и</vowel>й</str>reflecting that there is only one match in the dictionary, and that the first of the two vowels in the wordform is stressed and the second is unstressed. A wordform not in the dictionary will be returned with
@stress values of 0for all vowels. An ambiguity, such as города (an inflected form of the lexeme город
city) will return two results:
<str>г<vowel stress="1">о</vowel>р<vowel stress="-1">о</vowel>д<vowel stress="-1">а</vowel></str>with stress on the first vowel in the genitive singular and
<str>г<vowel stress="-1">о</vowel>р<vowel stress="-1">о</vowel>д<vowel stress="1">а</vowel></str>with stress on the last vowel in the nominative and accusative plural). These results are merged in postprocessing to return a single composite result:
<str>г<vowel stress="0">о</vowel>р<vowel stress="-1">о</vowel>д<vowel stress="0">а</vowel></str>reflecting that the stress properties of the first and third vowels are uncertain, but the middle vowel is unambiguously unstressed. Once the stress possibilities for each token have been determined, it is reunited with its original orthographic representation in the poem (before case-folding and the stripping of punctuation) and the text of the poem is returned with the following structure:
<poem>
<stanza>
<line>
<word>
<orth>карий</orth>
<str>к<vowel stress="1">а</vowel>р<vowel stress="-1">и</vowel>й</str>
</word>
<!-- other words -->
</line>
<!-- other lines -->
</stanza>
<!-- other stanzas -->
</poem>So how, given the presence of 0
values in the dictionary lookup
results, do we do the following:
-
Determine the strong and weak positions in the poem, that is, the syllablic positions in each line that tend toward being stressed and the ones that tend toward being unstressed?
-
Determine whether the poem observes binary or ternary meter?
-
Determine, on the basis of the preceding, whether the binary meter is iambic or trochaic and whether the ternary meter is dactylic, anapest, or amphibrach?
-
Identify deviations from the ambient meter in individual lines?
-
Recognize and accommodate catalexis and hypermetrical syllables, the latter both at the end of the line and before a caesura?
Metrical valence
The dictionary report can be understood as a matrix of 1
,
-1
, and 0
values, where the rows are lines of the poem
and the columns are vowel positions (<vowel> elements) in the line
(ignoring all textual content). For example, an eight-line passage of iambic tetrameter
without catalexis or hypermetrical syllables will be represented by an 8 x 8 matrix.
Exploiting our strategy of targeting poetry that exhibits a strongly regular
syllabotonic organization, for each column in the matrix we calculate whether the
position should be considered metrically strong or weak (provisionally; this initial
evaluation is modified subsequently, as described below) by counting the number of
1
values and dividing that count by the sum of the counts of
1
and -1
values (ignoring 0
values). We
call this the metrical valence of the position, and it varies
between a low of 0 (all unambiguous syllables in that position are unstressed) and
a
high of 1 (all unambiguous syllables in that position are stressed). If there are
no
unambiguous syllables in that position, we provisionally return a metrical valence
of 0
(identical to the valence of a weak syllable). These values are calculated easily
in
XQuery, e.g.:
let $lines := $poem/descendant::line
let $maxVowels := max($lines/count(descendant::vowel))
let $valences :=
for $position in 1 to $maxVowels
let $positive := count($lines[descendant::vowel[position() eq $position][@stress eq '1']])
let $negative := count($lines[descendant::vowel[position() eq $position][@stress eq '-1']])
let $valence :=
if ($positive + $negative eq 0) then 0 else $positive div ($positive + $negative)
return string($valence)
return string-join($valences,' ')
The string() and string-join() functions are for human
legibility; for machine processing the $valences variable can be returned
as a sequence of doubles that range between 0 and 1. The following first four lines
of
Aleksandr Puškin’s “Prorok” (“The prophet”):[5]
<poem>
<stanza>
<line>
<word>
<orth>Духовной</orth>
<str>д<vowel stress="-1">у</vowel>х<vowel stress="1">о</vowel>вн<vowel stress="-1">о</vowel>й</str>
</word>
<word>
<orth>жаждою</orth>
<str>ж<vowel stress="1">а</vowel>жд<vowel stress="-1">о</vowel><vowel stress="-1">ю</vowel></str>
</word>
<word>
<orth>томим,</orth>
<str>т<vowel stress="-1">о</vowel>м<vowel stress="1">и</vowel>м</str>
</word>
</line>
<line>
<word>
<orth>В</orth>
<str>в</str>
</word>
<word>
<orth>пустыне</orth>
<str>п<vowel stress="-1">у</vowel>ст<vowel stress="1">ы</vowel>н<vowel stress="-1">е</vowel></str>
</word>
<word>
<orth>мрачной</orth>
<str>мр<vowel stress="1">а</vowel>чн<vowel stress="-1">о</vowel>й</str>
</word>
<word>
<orth>я</orth>
<str><vowel stress="0">я</vowel></str>
</word>
<word>
<orth>влачился,—</orth>
<str>вл<vowel stress="-1">а</vowel>ч<vowel stress="1">и</vowel>лс<vowel stress="-1">я</vowel></str>
</word>
</line>
<line>
<word>
<orth>И</orth>
<str><vowel stress="-1">и</vowel></str>
</word>
<word>
<orth>шестикрылый</orth>
<str>ш<vowel stress="-1">е</vowel>ст<vowel stress="-1">и</vowel>кр<vowel stress="1">ы</vowel>л<vowel stress="-1">ы</vowel>й</str>
</word>
<word>
<orth>серафим</orth>
<str>с<vowel stress="-1">е</vowel>р<vowel stress="-1">а</vowel>ф<vowel stress="1">и</vowel>м</str>
</word>
</line>
<line>
<word>
<orth>на</orth>
<str>н<vowel stress="-1">а</vowel></str>
</word>
<word>
<orth>перепутье</orth>
<str>п<vowel stress="-1">е</vowel>р<vowel stress="-1">е</vowel>п<vowel stress="1">у</vowel>ть<vowel stress="-1">е</vowel></str>
</word>
<word>
<orth>мне</orth>
<str>мн<vowel stress="0">е</vowel></str>
</word>
<word>
<orth>явился.</orth>
<str><vowel stress="-1">я</vowel>в<vowel stress="1">и</vowel>лс<vowel stress="-1">я</vowel></str>
</word>
</line>
</stanza>
</poem>
yields 0 0.5 0 1 0 0 0 1 0
Even generally regular and consistent syllabotonic poetry contains frequent divergences from the general metrical type, so that, for example, in iambic tetrameter verse some even-numbered syllables may be unstressed and some odd-numbered syllables may be stressed. As was shown most comprehensively by Taranovski 1953, the only absolute regularity is that the last metrically strong position (expected stress) of every line must be linguistically stressed; other metrically strong positions may be linguistically unstressed.[6] For that reason, we do not expect that all values will be exactly equal to either 0 (weak) or 1 (strong). To identify the strong and weak positions in a poem, we compare the metrical valence of each position in the matrix to its neighbors; positions with a higher valence than both neighors are presumed to be strong (which we represent as 1 and all others a presumed to be weak (which we represent as 0). This yields a vector of 1 and 0 values, which we must then reconcile with one of the five basic metrical line types (iambic, trochaic, anapest, amphibrach, dactylic) known in Russian verse.
Identifying metrical types
Taking the preceding sequence of 0 and 1 values as input, we calculate the percentage of matching values at a distance of two and at a distance of three, which we call the binary (resp. ternary) coefficient of the poem. We predict that there will be no ties in poetry that observes a reasonably regular and consistent syllabotonic structure.[7] To determine these coefficients, we start two (resp. three) syllables into the sequence and proceed item by item, calculating the absolute value of subtracting from each item in the sequence the one located two (resp. three) syllables before it. We then divide the sum of those values by the total number of sequences examined, returning the mean. For example, with the following unambiguous iambic tetrameter pattern:
0 1 0 1 0 1 0 1
the binary coefficient is determined by subtracting from the 0 at position 3 the 0 at position 1, then from the 1 at position 4 the 1 at position 2, etc. We sum the absolute values of those subtractions (all of which equal 0 in this example) and divide by the number of comparisons (6 in this example), so the binary coefficient of this line is 0. The ternary coefficient starts at position 4 and subtracts from it the value three positions before it, at position 1, and then proceeds until the end of the line, similarly to the binary calculation. The absolute values in this case are all equal to 1 and there are 5 comparisons, so the ternary coefficient is 5/5, or 1. Our system regards the lower of the two values as determinative, so we report correctly that this poem observes binary meter.
A perfect ternary example is similarly clear:
0 1 0 0 1 0 0 1 0 0 1 0
The binary coefficient of the preceding perfect amphibrach tetrameter is 6/10 or 0.60. The ternary coefficient is 0/9, or 0, which identifies the type as ternary.
This value is easily determined with XQuery similar to the following (with
$valences set, for this illustrative example, to the values for the
Puškin poem):
let $valences := (0, 0.5, 0, 1, 0, 0, 0, 1, 0)
let $positions := count($valences)
let $binaries :=
for $position in 3 to $positions
return abs($valences[$position] - $valences[$position - 2])
let $binary := sum($binaries)
let $ternaries :=
for $position in 4 to $positions
return abs($valences[$position] - $valences[$position - 3])
let $ternary := sum($ternaries)
return
(concat('binary = ', $binary,'
'),
concat('ternary = ',$ternary,'
'),
concat('meter is: ', if ($binary lt $ternary) then 'binary' else if ($ternary lt $binary) then 'ternary' else 'tied'))
The output of the preceding is:
binary = 2.5 ternary = 3.5 meter is: binarywhich correct identifies the metrical type as binary. The output has been formatted for human legibility; what is important is that binary and ternary coefficients are doubles that can be compared, with the lower value determining the basic metrical type.
Once we have determined whether the basic type is binary or ternary, we can set all positions to 0 or 1, which we consider a representation of the ambient meter, that is, the distribution of strong and weak positions irrespective of whether they are filled by linguistically stressed or unstressed vowels.[8] We can then determine the subtype (iamb vs trochee for binary, anapest vs amphibrach vs dactyl for ternary) by identifying the rightmost strong position in the line. Exploiting the fact that the final strong position in Russian syllabotonic verse is the only one that must be stressed 100% of the time, we can distinguish among the binary resp. ternary meters by counting the syllables (i.e., vowels) before the final strong position. In binary meter, the final strong position is an odd-numbered syllable in trochaic verse and an even-numbered syllable in iambic verse. In ternary meter, the final strong position is evenly divisible by 3 in anapest verse, divisible by 3 with a remainder of 2 in amphibrach verse, and divisible by 3 with a remainder of 1 in dactylic verse. Since the final strong position in the Puškin example is the eighth syllable, we know that we are dealing with iambic verse, and specifically with iambic tetrameter. We can calculate this in XQuery (plugging in the values for the Puškin poem after resetting them all to 0 or 1, alternating as appropriate for binary meter) along the lines of[9]:
let $valences := (0, 1, 0, 1, 0, 1, 0, 1, 0) let $rightmostStrong := index-of($valences,1)[last()] return if ($rightmostStrong mod 2 eq 0) then 'iambic' else 'trochaic'
Finally, the number of feet per line can be determined by counting the number of strong position per line. XQuery such as the following can identify the number of feet (here preloaded with the values from the Puškin sample):
let $valences := (0, 1, 0, 1, 0, 1, 0, 1, 0)
let $countStrong := count($valences[. eq 1])
return
switch($countStrong)
case 1 return 'monometer'
case 2 return 'dimeter'
case 3 return 'trimeter'
case 4 return 'tetrameter'
case 5 return 'pentameter'
case 6 return 'hexameter'
case 7 return 'heptameter'
case 8 return 'octameter'
case 9 return 'nonameter'
case 10 return 'decameter'
default return 'other'
This correctly identifies the sample as tetrameter.
Overlapping hierarchies and the analysis of poetic texts
Poetic texts are often included among the poster children of overlapping hierarchies,
since the organization of poems into cantos, stanzas, lines, and feet is largely
independent of the sentences and words of the text. Yet although foot boundaries and
word boundaries are mutually independent, the implementation of caesura depends on
their
synchronization. Overlap is a well-understood challenge for XML systems because the
XML
data model regards documents as rooted directed acyclic graphs with single
parenthood and a total ordering on leaf node
(Marcoux, Sperberg-McQueen, and Huitfeldt 2013), which requires that every element
be fully nested within all of its ancestors. XML-compatible strategies for representing
overlapping reality are also well understood, and rely, whether implicitly or
explicitly, on prioritizing at most one hierarchy syntactically and flattening any
competing hierarchies by delimiting their conceptual elements as paired milestone
tags
or standoff pointers. And as the implementation of LMNL tools using XML technologies
has
shown, the XML toolkit is sufficient flexible to support a view of documents as
overlapping ranges, where hierarchy is not a fundamental organizational aspect of
the
data model. (Piez 2012, Piez 2014)
The present project is not using (and therefore not tagging) linguistic units other
than words, so the inherent overlap relationship between some aspects of verse structure
(e.g., cantos, stanzas, and lines) and some aspects of linguistic structure (e.g.,
sentences) is not an issue. But metrical foot boundaries and word boundaries commonly
exhibit an overlap relationship, and, as noted above, that relationship is important
for
identifying caesura. A caesura is a regular coincidence of foot and word boundaries,
as
in the following initial quatrain of Zinaida Gippius’s 1907 Neljubov′
(Non-love
):
Table III
Zinaida Gippius, Neljubov′
(Non-love
) (1907)[10]
| Text | Meter | Word group boundaries[11] |
|---|---|---|
| Как ве|тер мокрый, ‖ ты бьёшь|ся в ставни, | OX|OX(O)‖OX|OX(O) |
O X O|X O‖O X O|X O |
| Как ве|тер чёрный, ‖ поёшь: | ты мой! | OX|OX(O)‖OX|OX |
O X O|X O‖O X|O X |
| Я древ|ний хаос, ‖ я друг | твой давний, | OX|OX(O)‖OX|OX(O) |
O X O|X O‖O X O|X O |
| Твой друг | единый,— ‖ открой, | открой! | OX|OX(O)‖OX|OX |
O X|O X O‖O X|O X |
Caesura may be understood as the regular coincidence of metrical and word boundaries
at the same position in multiple lines in a poem, where the regularity creates an
expectation of potential pause in the ear of the listener.[12] The preceding quatrain (and the entire sixteen-line poem) is written in
strict iambic tetrameter with a hypermetrical caesura in all lines and a hypermetrical
clausula in the odd-numbered lines. The second column depicts the metrical structure:
stressed syllables are represented by an X
, unstressed syllables by an
O
, hypermetrical syllables are parenthesized, the boundary between
feet is marked with a pipe, and the caesura with a double pipe. The third column marks
the stressed and unstressed syllables and hypermetricality the same way, with
X
and O
and parentheses, respectively, but here the
pipe demarcates not metrical feet, but phonological words (the double pipe continues
to
represent the caesura). In the first column the foot boundaries are represented by
pipes
(mapped from the second column onto the first); word boundaries are represented by
white
space, except that here the white space has its normal orthographic property of
delimiting orthographic, rather than phonological words.
Comparison of these three parallel columnar views of properties of the same underlying data shows that the boundaries between metrical feet and phonological words frequently fail to coincide, but the transition between the fifth and sixth syllables of every line regularly separates both metrical feet and phonological words—that is, it represents a regular caesura. This synchronization of the overlapping metrical and phonological-lexical hierarchies is the essence of poetic caesura, and our challenge is to identify it automatically, so that our analysis can be scaled to a poetic corpus so large that manual individual analysis of all poems would be impractical.
A caesura is a regular phenomenon that becomes
perceptible when and because it occurs throughout a
poem. Or almost throughout a poem: Gippius plays with
this expectation in her 1905 Ona
(She
), a sixteen-line
poem with a regular caesura except in the pivotal eighth line, at the end of the first
half of the poem. And she similarly plays with the hypermetricality of the dactylic
caesura on the second line of the poem, where the sixth syllable of this line, and
only
of this line, is most naturally read with a stress:
Table IV
Zinaida Gippius, Ona
(She
) (1905) [13]
| Text | Meter | Word group boundaries |
|---|---|---|
| В своей | бессо|вестной ‖ и жал|кой ни|зости, | OX|OX|(OO)‖OX|OX(OO) |
O X|O X O O‖O X O|X O O |
| Она | как пыль | сера, ‖ как прах | земной. | OX|OX| OX ‖OX|OX |
O X|O X|O X‖O X|O X |
| И у|мира|ю я ‖ от э|той бли|зости, | OO|OX|(OO)‖OX|OX(OO) |
O O O X O|X‖O X O|X O O |
| От не|разрыв|ности ‖ её | со мной. | OO|OX|(OO)‖OX|OX |
O O O X O O‖O X|O X |
| Она | шерша|вая, ‖ она | колю|чая, | OX|OX|(OO)‖OX|OX(OO) |
O X|O X O O‖O X|O X O O |
| Она | холод|ная, ‖ она | змея. | OX|OX|(OO)‖OX|OX |
O X|O X O O‖O X|O X |
| Меня | изра|нила ‖ против|но-жгу|чая | OX|OX|(OO)‖OX|OX(OO) |
O X|O X O O‖O X O|X O O |
| Её | колен|чата|я че|шуя. | OX|OX|(OO)|OO|OX |
O X|O X O O O|O O X |
| О, е|сли б о|строе ‖ почу|ял жа|ло я! | OX|OX|(OO)‖OX|OX(OO) |
O X O|X O O‖O X O|X O O |
| Непо|ворот|лива, ‖ тупа, | тиха. | OO|OX|(OO)‖OX|OX |
O O O X O O‖O X|O X |
| Така|я тяж|кая, ‖ така|я вя|лая, | OX|OX|(OO)‖OX|OX(OO) |
O X O|X O O‖O X O|X O O |
| И нет | к ней до|ступа — ‖ она | глуха. | OX|OX|(OO)‖OX|OX |
O X|O X O O‖O X|O X |
| Свои|ми коль|цами ‖ она, | упор|ная, | OX|OX|(OO)‖OX|OX(OO) |
O X O|X O O‖O X|O X O O |
| Ко мне | ласка|ется, ‖ меня | душа. | OX|OX|(OO)‖OX|OX |
O X|O X O O‖O X|O X |
| И э|та мёрт|вая, ‖ и э|та чёр|ная, | OX|OX|(OO)‖OX|OX(OO) |
O X O|X O O‖O X O|X O O |
| И э|та страш|ная — ‖ моя | душа! | OX|OX|(OO)‖OX|OX |
O X O|X O O‖O X|O X |
The identification of caesura requires the identification of both feet and words, which are not coextensive and which frequently overlap. The challenge, then, is to locate where foot and line boundaries coincide without employing markup in a way that would violate well-formedness overlap constraints.
Explicit and implicit markup
The markup community typically uses the term markup
to refer to the insertion of (angle-delimited in XML) tags into a stream of text as
a
way of making explicit information about its structure, semantics, or other properties.[14] It is also well known, however, that so-called plain
text is more than a sequence of informationally equivalent content units,
and that some characters may represent data content while others may represent
components of structure. As TEI P5 notes, A text is not an
undifferentiated sequence of words, much less of bytes.
In some cases the
same information may be represented in plain text by raw characters (e.g., quotation
marks to delimit quotations, space characters to delimit words, new line characters
to
delimit lines of poetry, multiple new line characters to delimit paragraphs of prose,
asterisks or underscores to delimit emphasized text, etc.) and in XML by markup. The
richness vs sparseness of a markup schema, at least in digital humanities projects,
typically represents a compromise between making structure and semantics explicit
through the use of markup, on the one hand, and not letting the markup overwhelm the
content in a way that compromises human legibility, on the other.[15] Furthermore, richer markup increases the risk of overlap, which is
prohibited syntactically in XML. For example, if in an XML representation of a poem
we
try to tag explicitly both metrical feet and words, the two hierarchies will typically
overlap because they are largely independent of each other structurally. But can we
use
a combination of explicit and implicit markup to represent the logically overlapping word and foot hierarchies needed for caesura
without violating the XML well-formedness constraint against syntactically overlapping tags?
Identifying elements without identifying their boundaries
In our use of the dictionary to identify lexical stress we tokenize the plain text
input on white space and pass each word into the dictionary web service, which
returns it with <word> and <str> wrapper tags.
This establishes <word> elements as constituting the fully
tesselated element content of <line> elements. Independently of
word tagging, the procedure described above to identify the strong and weak vowel
positions and the stressed and unstressed vowels in the text enables us to assign
every <vowel> element to a particular foot on the basis of its
position in the sequence of <vowel> descendants of the
<line>, but 1) where do the actual foot boundaries fall and
2) how do we represent them in the XML, given the prohibition against encoding fully
tesselated <foot> elements that would overlap with our fully
tesselated <word> hierarchy?
It turns out, perhaps surprisingly, that we don’t need to care about the answers
to those questions; it is sufficient for the purpose of locating caesura to identify
only the two (resp. three) syllabic nuclei (vowels) of binary (resp. ternary) feet,
without locating the precise boundaries of the syllables or the feet and without
tagging them. Once we determine that, for example, a poem is written in iambic
tetrameter, we know that there are logical milestone foot boundaries somewhere between a strong vocalic position
(even-numbered <vowel> element, in the sequence of
<vowel> descendants of the <line>) to the
left and a weak vocalic position (odd-numbered <vowel> element)
immediately to its right (subject to adjustment for catalexis and hypermetricality),
and that is all that we need to know. If in two adjacent words
(<word> elements) the last vowel (<vowel>)
of the word to the left is in an even-numbered position and the first vowel of the
word to the right is in an odd-numbered position, we can infer that the foot
boundary coincides with the word boundary, which is already present explicitly in
our markup. Otherwise, we can infer that the foot boundary does not coincide with
a
word boundary, and in that case we do not need to care about its exact position. If
in every line of this hypothetical iambic tetrameter poem, then, the fourth
<vowel> descendant of each <line> element
is the final <vowel> in its containing <word>
element, we have a regular caesura.[16]
The insight here, then, is that we can privilege (fully mark up) the word-level
hierarchy and allow the position of <vowel> elements inside
containing <word> and <line> elements to
supply enough information to identify the presence or absence of caesura without our
needing to know anything more about syllable or foot boundaries in the poem. The
full system needs to adapt to lines of different length (including those with an odd
number of feet, where the simple arithmetic division below is not appropriate) and
needs to account for hypermetrical caesura, but the simplified XQuery below
illustrates the general strategy for locating caesura by targeting iambic tetrameter
without hypermetrical caesura (although with optional hypermetrical clausula) that
has been tagged for words but not for syllables or feet:[17]
let $vowelCount := min(//line/count(descendant::vowel))
let $midPoint := $vowelCount div 2
let $targets := //line/descendant::vowel[position() eq $midPoint]
return
if ($targets/following-sibling::vowel)
then
'no caesura'
else
'caesura'
Tokenizing mixed content
Above we illustrate how to identify the foot boundaries we care about for the
purpose of identifying caesura without having to tag syllables or feet, while
relying on the presence of <word> tags. In this project the
dictionary web service happens to tag words as a side-effect of locating the place
of stress, but what if the <word> tags were not there? For
example, how would we deal with input like:
<line>Дух<stress>о</stress>вной ж<stress>а</stress>ждою том<stress>и</stress>м</line>To a scholar of poetry, the task appears to involve separating words on white space when they happen to have stresses marked, but the XPath and XSLT resources that support tokenization (XPath
tokenize() and XSLT
<xsl:analyze-string>) atomize their contents, which means
that neither can be used directly on this content to achieve this end. This mismatch
between the human understanding of line(a unit of poetry) and the XML understanding of
<line> (an XML element) results from the
fact that humans naturally perceive the line as something that can be regarded as
words separated by white space, something that XML processing is unable to do
without atomization.[18]
The strategies for dealing with this mismatch between human and XML perspectives
are well known to XSLT programmers, although perhaps not intuitive to human readers
of poetry: either 1) convert the markup (in this case, <stress>
tags) to plain-text characters that do not otherwise occur, tokenize the resulting
plain text, and then convert the plain-text characters back to markup or 2) convert
the relevant plain-text characters to markup. The latter can be illustrated with the
following sample:
<poem>
<quatrain>
<line>"Мой д<stress>я</stress>дя с<stress>а</stress>мых ч<stress>е</stress>стных пр<stress>а</stress>вил</line>
<line>Когд<stress>а</stress> не в ш<stress>у</stress>тку занем<stress></stress>ог,</line>
<line>Он уваж<stress>а</stress>ть себ<stress>я</stress> заст<stress>а</stress>вил</line>
<line>И л<stress>у</stress>чше в<stress>ы</stress>думать не м<stress>о</stress>г.</line>
</quatrain>
</poem>
using a two-pass XSLT approach. First convert space characters in
text() node children of <line> to empty
milestone elements (such as <word/>):
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
exclude-result-prefixes="xs"
version="2.0">
<xsl:template match="node()|@*">
<xsl:copy>
<xsl:apply-templates select="node()|@*"/>
</xsl:copy>
</xsl:template>
<xsl:template match="line/text()">
<xsl:analyze-string select="." regex=" ">
<xsl:matching-substring><word/></xsl:matching-substring>
<xsl:non-matching-substring><xsl:sequence select="."/></xsl:non-matching-substring>
</xsl:analyze-string>
</xsl:template>
</xsl:stylesheet>
This produces:
<poem>
<quatrain>
<line>"Мой<word/>д<stress>я</stress>дя<word/>с<stress>а</stress>мых<word/>ч<stress>е</stress>стных<word/>пр<stress>а</stress>вил</line>
<line>Когд<stress>а</stress><word/>не<word/>в<word/>ш<stress>у</stress>тку<word/>занем<stress/>ог,</line>
<line>Он<word/>уваж<stress>а</stress>ть<word/>себ<stress>я</stress><word/>заст<stress>а</stress>вил</line>
<line>И<word/>л<stress>у</stress>чше<word/>в<stress>ы</stress>думать<word/>не<word/>м<stress>о</stress>г.</line>
</quatrain>
</poem>;
Then use <xsl:for-each-group> to convert the milestones to
wrappers:
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema" exclude-result-prefixes="xs" version="2.0">
<xsl:template match="node() | @*">
<xsl:copy>
<xsl:apply-templates select="node() | @*"/>
</xsl:copy>
</xsl:template>
<xsl:template match="line">
<line>
<xsl:for-each-group select="node()" group-starting-with="word">
<word>
<xsl:sequence select="current-group() except self::word"/>
</word>
</xsl:for-each-group>
</line>
</xsl:template>
</xsl:stylesheet>
This produces the following output:[19]
<poem>
<quatrain>
<line>
<word>"Мой</word>
<word>д<stress>я</stress>дя</word>
<word>с<stress>а</stress>мых</word>
<word>ч<stress>е</stress>стных</word>
<word>пр<stress>а</stress>вил</word>
</line>
<line>
<word>Когд<stress>а</stress></word>
<word>не</word>
<word>в</word>
<word>ш<stress>у</stress>тку</word>
<word>занем<stress/>ог,</word>
</line>
<line>
<word>Он</word>
<word>уваж<stress>а</stress>ть</word>
<word>себ<stress>я</stress></word>
<word>заст<stress>а</stress>вил</word>
</line>
<line>
<word>И</word>
<word>л<stress>у</stress>чше</word>
<word>в<stress>ы</stress>думать</word>
<word>не</word>
<word>м<stress>о</stress>г.</word>
</line>
</quatrain>
</poem>
The dictionary stress lookup obviates the need to tokenize mixed content for our
project, which means that the location of stressed vowels within words can be
encoded explicitly with markup, even though the location of those vowels within feet
is not encoded explicitly. The example above illustrates that this type of analysis
would also be possible even without explicit <word> tags in the
input markup. Although it happens not to be needed within our work flow, this type
of tokenization task is nonetheless common in digital humanities, at times in
situations where it would be impossible to tag words without creating overlapping
markup. For example, in Povestʹ vremennyx let it is necessary to tokenize not only
lines like:
<Aka>рѹ<sup>с</sup><problem>каꙗ</problem><lb/> землѧ кто в неи поча<sup>л</sup> первое кнѧжити.</Aka>where the
<sup> (superscription) tags are comparable to
<stress> or <vowel> tags at different
stages in our poetry project. In that project it is also necessary to flatten
elements that span multiple words to avoid stranding a start tag inside one
<word> element and its corresponding end tag inside another,
as in
<Ipa>съ грѣкы. ѿпусти слы ѡ<marginalia>даривъ. <lb/> ско</marginalia>рою</Ipa>Here the
<marginalia> start and end tags would have to be
tokenized with different words, which can be done by flattening them into
milestones, with or without Trojan pointers,[20] depending on whether the elements need to be re-erected and on whether
there might be problems with ambiguous associations involved in their
restoration.
No discussion of overlap would be complete without a nostalgic nod in the
direction of the optional CONCUR feature of SGML (Goldfarb 1990
177), but the ways in which SGML anticipated some of the issues discussed here go
beyond CONCUR. Because SGML was concerned with simplifying the markup process by
reducing typing, it allowed the developer to specify, as part of the SGML
declaration, several types of markup minimization. Our decision to treat space
characters as if they were milestone tags in the examples above gives us access to
an additional hierarchy at processing time without actually writing markup into the
document. That meaning of space characters is inherent in the popular, vernacular
understanding of spaces as delimiting words in normal Russian orthography, but from
an XML perspective a space is just a character, like any other, in a
text() node, and its interpretation as markup becomes part of the
processing model only when we choose to treat it as such during querying or
transformation. SGML, though, provides, through a combination of OMITTAG and
SHORTREF, the ability to create a map that encodes
the milestone function of space characters in the DTD, which is an obligatory part
of the SGML document, and therefore at the level of the document model itself, prior
to transformation or other processing (Goldfarb 1990 429–32, DeRose 1997 210). In this way SGML formalizes, as part of the
document syntax, a structure that in our XML implementation is only a human
interpretive convention at the document level, and that becomes part of the formal
structure only when processed in a way that applies that interpretation.
Mixed content as a type of overlap
The XML literature conceptualizes overlap in several ways; see, e.g., the overviews
in
DeRose 2004, Bauman 2005, the many articles listed
at Balisage Concurrent markup/overlap, and, from a TEI perspective, Bański 2010. None of these, though, mentions that mixed content of the
type described above, where words boundaries are represented by space characters,
rather
than by tags and without standoff pointers, is also an intellectual manifestation
of
overlap. This type of situation has not previously been identified as overlap because
from a syntactic perspective it isn’t, and the tesselated hierarchy instantiated by
the
space characters does not raise errors or compromise well-formedness in the presence
of
other (explicit) markup because from a strict XML perspective it is implicit, rather than overt. As is shown above, though, it
may nonetheless raise processing challenges comparable to those that arise with other
non-overlapping overlap strategies, such as Trojan milestones
or the
other syntactically licit expressions of overlap described in DeRose 2004 and Bauman 2005. In this example, white space characters are
milestones tags in disguise, and milestones of this type are surrogates for wrapper
tags, with the result that the space characters implement a tesselated hierarchy that
may overlap with others in ways that become overt only when it is necessary to address
that hierarchy explicitly during processing.
Mixed content and rhyme
The present report concentrates on the identification and analysis of meter, but some of the mixed-content issues mentioned above are also relevant for the identification and analysis of rhyme. The requirements for rhyme in Russian are close to those in English, and in both languages rhyme must be identified according to pronunciation, rather than orthography.[21] In Russian, however, it is possible to convert from orthography to a broad phonetic trancription algorithmically, with negligible need for lookup dictionary queries, as long as the place of stress is known. Since our system already enriches the orthographic representation of the text with information about stress as part of the process of determining meter, we can also leverage that information to identify rhyme.[22] An algorithm for mapping between Russian orthographic (enhanced by stress markup) and broad phonetic representations is given in Adams and Birnbaum 1997, and the principal challenges to regarding orthography as a direct surrogate for phonetics are that:
-
Most vowel letters are pronounced differently under stress than they are when they are not stressed. One effect of this process, commonly called vowel reduction, is that two letters may have different pronunciations when they are under stress but the same pronunciation when they are not stressed.
-
As noted above, certain small Russian orthographic words (prepositions, the negative particle не, and a few others) function as clitics, merging with adjacent head words to form a single phonological word, or stress group. This means that some properties of Russian pronunciation require looking beyond the domain of the orthographic word, although these larger domains are not part of the markup of the input text that is implied by white space.
-
Consonants may undergo assimilative changes in voicing and palatalization in certain environments. These assimilations may cross word boundaries, which means that they may involve consonants that might be understood by a human reader as phonetically adjacent even though they are not contiguous (or even siblings) from an XML perspective. For example, the type of regular expression processing one might use to say
pronounce т (phonetic [t]) as д (phonetic [d]) before д
(a voicing assimilation) becomes more than a simple regular expression pattern when the first consonant is at the end of one<word>element and the second at the beginning of the next. -
Several Russian letters (
soft
vowel letters, soft sign) have a diacritic function whereby they represent properties of preceding consonant letters. For example, in the Russian sequences та and тя, the initial consonant letters are the same and the final vowel letters are different. But the division of the sequence into segments phonetically differs from the division into letters: phonetically these syllables have different initial consonant sounds and the same final vowel sounds (see Adams and Birnbaum 1997 for discussion). Because vowels are all tagged as<vowel>elements in our representation and consonants are intext()node siblings of the<vowel>elements, here, as with some instances of consonant assimilation, the segments are adjacent from a human perspective but not from an XML perspective. Vowel reduction, introduced in the first point above, is also sensitive to consonants that are adjacent to the unstressed vowels from a human perspective, but not from an XML perspective.
We cannot analyze rhyme without access to information about the place of stress because, among other things, end rhyme in Russian verse is defined as a phonetic match that begins at the final stressed vowel and continues through the end of the line. We can, however, convert each line algorithmically to a plain text phonetic representation and then perform regular expression matching on the outputs of that conversion function.[23] For example, since our phonetic representation makes no other use of upper-case vowel letters, we can use those[24] to represent stressed vowels. We can then identify lines as rhyming by using a regular expression to isolate the rightmost upper-case vowel letter and everything that follows it from each line and to compare them with one another.[25]
At this stage of the project we identify only perfect rhyme, where all sounds in the rhyme domain correspond. We anticipate, though, extending this strategy to analyze patterns of slant (inexact) rhyme, that is, to identify whether a particular poet permits non-correspondence with respect to some phonetic features, but not others. Much as we rely on the notion of ambient meter to infer metrical consistency even where individual lines may deviate from it, so we might identify an ambient rhyme scheme based on unambiguous matches and extend that by inference to lines that deviate from it. We could then decompose phonetic inexact rhymes into distinctive features to determine whether, for example, a particular poem or a particular poet employs imperfect rhyme only of specific types, that is, by neutralizing specific phonetic distinctions but not others.
Conclusions
The strategies we employ to identify and analyze Russian meter and rhyme on the basis of plain text input in normal Russian orthography are useful not only because of what they tell us about Russian verse (the digital humanities questions), but also because of what they illustrate about structured text (the markup questions). The methods we employ for working around overlap constraints are well known, but in particular:
-
We have long known that plain text typically uses certain charaters, such as white space and punctuation, as a sort of pseudo-markup, and also that the extent to which structural and other features of XML texts are made explicit through tagging depends on the purposes and preferences of the researcher. What we have tried to emphasize and illustrate above is that conceptual overlap may exist not only where it has been discussed intensively before (e.g., where milestones are used to flatten a hierarchy or where standoff is employed), but also in at least two situations that have not previously played a role in the general overlap discourse:
-
The boundaries of an overlapping hierarchy are not encoded at all. This is illustrated by the identification of feet even when foot boundaries are not only untagged, but also completely unrepresented, and even unknown.
-
An overlapping hierarchy may be encoded through plain text pseudo-markup, but the avoidance of overlap is only apparent, and may vanish when the implicit hierarchy needs to be processed. This is illustrated by delimiting word boundaries with space characters, which is well known insofar as it is common in digital humanities projects not to tag all individual words explicitly. However, the consequences of needing nonetheless to treat words during processing as though they had been marked up individually has figured in discussions of overlap largely as a technical complication to be overcome. What has not played as significant a role in the discourse is the fact that this use of white space with a milestone function is ultimately an encoding of overlap.
-
-
Like other strategies for avoiding syntactic overlap, the methods discussed here raise no well-formedness errors, but they may pose similar processing challenges as soon as the researcher needs to engage with them explicitly.
-
To a human reader of poetry, consonants, stressed vowels, and unstressed vowels are all part of a continuous stream of phonetic material. Stressed vowel sounds are phonetic units in that stream, just like unstressed vowel sounds and consonant sounds; that is, they exist on the same (phonetic and conceptual) level. Meanwhile, the XML representation of stressed vowels as
<stress>elements puts the stressed vowel letter itself on a different level of the hierarchy than the rest of the letters that represent the text of the poem.[26]
For these reasons, it is useful to recognize that both situations described above represent a type of overlap that has not traditionally been identified and discussed as such explicitly.
References
[Adams and Birnbaum 1997] Adams, Lawrence
D. and David J. Birnbaum. 1997. Perspectives on computer programming for the
humanities.
Originally published in Text
technology 7, 1: 1–17 with an updated version available at
http://poetry.obdurodon.org/reports/adams-birnbaum.xhtml. [cited 14
June 2015]
[Balisage Concurrent markup/overlap] Balisage series on markup technologies. Topic: Concurrent
markup/overlap.
Inventory of links on line at
http://www.balisage.net/Proceedings/topics/Concurrent_Markup~Overlap.html
[cited 14 July 2015]
[Bański 2010] Bański, Piotr. Why TEI
stand-off annotation doesn't quite work: and why you might want to use it
nevertheless.
Presented at Balisage: The Markup Conference 2010, Montréal,
Canada, August 3 - 6, 2010. In Proceedings of Balisage: The Markup
Conference 2010. Balisage Series on Markup Technologies, vol. 5 (2010).
doi:https://doi.org/10.4242/BalisageVol5.Banski01. Available on line at
http://www.balisage.net/Proceedings/vol5/html/Banski01/BalisageVol5-Banski01.html
[Bauman 2005] Syd Bauman. TEI HORSEing
around. [cited 27 July 2015]
Proceedings of Extreme Markup Languages 2005. Available
on line at
http://conferences.idealliance.org/extreme/html/2005/Bauman01/EML2005Bauman01.html.
[cited 14 July 2015]
[Belyj 1910] Belyj, Andrej. 1910. Simvolizm. Moscow: Musaget. Repr. Moscow, 2010. Available on line at http://az.lib.ru/b/belyj_a/index.shtml#gr7 (HTML) and http://dlib.rsl.ru/viewer/01003765268#?page=3 (images). [cited 14 June 2015]
[DeRose 1997] DeRose, Steven. The SGML FAQ book. Boston: Kluwer.
[DeRose 2004] DeRose, Steven. Markup
overlap: A review and a horse.
Proceedings of Extreme Markup Languages 2004. Available
on line at
http://conferences.idealliance.org/extreme/html/2004/DeRose01/EML2004DeRose01.html.
[eXist-db] eXist XML database. eXist-db [cited 14 June 2015]
[FEB] Fundamental′naja èlektronnaja biblioteka
Russkaja literatura i fol′klor
http://www.feb-web.ru/ [cited 19 July 2015]
[Friedberg 2009] Friedberg, Nila. The
Russian Auden and the Russianness of Auden.
In: Aroui, Jean-Louis, and A.
Arleo, ed. 2009. Towards a typology of poetic forms: From language
to metrics and beyond. Language faculty and beyond: Internal and external
variation in linguistics 2. Amsterdam; Philadelphia: John Benjamins Pub. Company.
229–45.
[Friedberg 2011] Friedberg, Nila. 2011. English rhythms in Russian verse: On the experiment of Joseph Brodsky. Trends in linguistics. Studies and monographs 232. Berlin: Mouton de Gruyter.
[Gasparov 1984] Gasparov, Mixail Leonovič. 1984. Očerk istorii russkogo stixa. Metrika, ritmika, rifma, strofika. Moscow: Nauka. Selections available on line at http://www.infoliolib.info/philol/gasparov/gsprsfr.html. [cited 14 June 2015]
[Goldfarb 1990] Goldfarb, Charles. 1990. The SGML handbook. Oxford: Clarendon.
[Marcoux, Sperberg-McQueen, and Huitfeldt 2013] Marcoux, Yves, Michael
Sperberg-McQueen and Claus Huitfeldt. Modeling overlapping structures: Graphs and
serializability.
Presented at Balisage: The Markup
Conference 2013, Montréal, Canada, August 6–9, 2013. In Proceedings of Balisage: The Markup Conference 2013. Balisage
Series on Markup Technologies, vol. 10 (2013). doi:https://doi.org/10.4242/BalisageVol10.Marcoux01.
[Piez 2012] Piez, Wendell. Luminescent:
Parsing LMNL by XSLT upconversion.
Presented at Balisage: The Markup Conference 2012, Montréal, Canada, August 7–10,
2012. In Proceedings of Balisage: The Markup Conference
2012. Balisage Series on Markup Technologies, vol. 8 (2012). doi:https://doi.org/10.4242/BalisageVol8.Piez01.
[Piez 2014] Piez, Wendell. Hierarchies
within range space: From LMNL to OHCO.
Presented at Balisage: The Markup Conference 2014, Washington, DC, August 5–8, 2014.
In Proceedings of Balisage: The Markup Conference 2014.
Balisage Series on Markup Technologies, vol. 13 (2014). doi:https://doi.org/10.4242/BalisageVol13.Piez01.
[Povestʹ vremennyx let] Povestʹ vremennyx let. http://pvl.obdurodon.org/ [cited 19 July 2015]
[Scherr 1986] Scherr, Barry P. 1986. Russian poetry: Meter, rhythm, and rhyme. Berkeley: University of California Press.
[RNC poetry] Poetry subcorpus, Russian National Corpus. http://ruscorpora.ru/search-poetic.html [cited 19 July 2015]
[Shaw 1993] Shaw, J. Thomas. 1993. Pushkin’s poetics of the unexpected: The nonrhymed lines in the rhymed poetry and the rhymed lines in the nonrhymed poetry. Columbus, OH: Slavica.
[Taranovski 1953] Taranovski, Kiril. 1953. Ruski dvodelni ritmovi. Posebna izdanja, knjiga CCXVII. Odelenije literature i jezika, knjiga 5. Belgrade: Srpska akademija nauka.
[TEI P5] Text Encoding Initiative. P5: Guidelines for Electronic Text Encoding and Interchangehttp://www.tei-c.org/release/doc/tei-p5-doc/en/html/SG.html#SG12 Version 2.8.0. Last updated on 6th April 2015, revision 13197. [cited 16 July 2015]
[Trans-historical Poetry Project] Trans-historical Poetry Project. Developed at the Stanford University Literary Lab by Ryan Heuser, Mark Algee-Hewitt, Maria Kraxenberger, J. D. Porter, Jonny Sensenbaugh, and Justin Tackett. https://github.com/quadrismegistus/litlab-poetry, and especially the slides from their DH2014 Lausanne presentation at http://tinyurl.com/ou3gr5o [cited 19 July 2015]
[Tsur 2012] Tsur, Reuven. Poetic rhythm: Structure and performance. An empirical study in cognitive poetics. Second edition, revised. Eastbourne, UK and Portland, OR: Sussex Academic Press.
[1] Introductory information about the poetic motivation for this research is reproduced here from presentations by the authors at the April 2015 Russian formalism and the digital humanities conference at Stanford University (https://digitalhumanities.stanford.edu/russian-formalism-digital-humanities), the June 2015 Computational approaches to poetry: A day of workshops event at the University of Helsinki ( http://www.helsinki.fi/collegium/events/computationalpoetry/Computational_Poetry_Helsinki.html), and the June–July 2015 ADHO DH2015: Global digital humanities conference at the University of Western Sydney (http://dh2015.org/). The authors are grateful to Erin Harrington and Sam Depretis for their contributions to creating the stress dictionary.
[2] For comparative information about English on this and other points, see the challenges faced by the Stanford Literary Lab in their automated analysis of English verse, discussed in Trans-historical Poetry Project.
[3] We can illustrate the strong syllabotonic organization of Russian verse practice and the more tonic organization of contemporaneous English verse practice by comparing Robert Southey’s (1774–1842) “The old woman of Berkeley” (1799) with Vasilij Andreevič Žukovskij’s (1783–1852) 1814 (first published in 1831) translation of Southey’s text. Here are the first four lines of Southey’s original:
Table I
| Text | Syllables per foot | Rhyme |
|---|---|---|
| The ra|ven croaked | as she sate | at her meal, | 2 2 3 3 | a |
| And the Old | Woman knew | what he said; | 3 3 3 | b |
| And she | grew pale | at the Ra|ven’s tale, | 2 2 3 2 | c |
| And sick|ened, and went | to her bed. | 2 3 3 | b |
Table II
| Text | Syllables per foot | Rhyme |
|---|---|---|
| На кро|вле во|рон ди|ко про|кричал — | 2 2 2 2 2 | a |
| Стару|шка слы|шит и | бледнеет. | 2 2 2 2+ | B |
| Понят|но ей, | что во|рон тот | сказал: | 2 2 2 2 2 | a |
| Слегла | в постель, | дрожит, | хладеет. | 2 2 2 2+ | B |
We are grateful to Elisa Beshero-Bondar for bringing this example to our attention, and for her many insightful observations about Southey’s ballad practice.
[4] Metrical variation, that is, deviation from the predominant meter, is used by poets for a variety of reasons and purposes. It preserves meter, while preventing poetry from becoming “sing-song”; it establishes associations among words and lines; it modulates the tempo; it draws attention to important moments; and it adapts international meter to local linguistic properties (e.g., stress system, word length). For example, English has a lot of monosyllables and Russian has a lot of words with three or more syllables, which means that neither language is a perfect fit for completely regular binary or ternary meter. Metrical variation allows the predominant meter to emerge clearly without undermining the pronunciation of the poetic text in ways that are generally consistent with natural speech rhythms.
Scholars of versification sometimes refer to the syllables where we expect stress according to the ambient metrical cadence as strong (vs. weak) and to syllables that are pronunced more emphatically than their neighbors as stressed (vs. unstressed). Metrical variation means that not all strong syllables are stressed and not all weak syllables are unstressed, but linguistic stress and metrically strong position nonetheless coincide with sufficient consistency to impart a clear and regular general rhythm to the poetic text. Part of the challenge of machine-assisted metrical analysis is dealing with both this regularity and the deviations from it.
Some scholars (e.g., Friedberg 2009, adopting terminology advanced in the 1970s by Morris Halle and Paul Kiparsky) employ the term meter for what we call ambient or dominant meter and rhythm for what we refer to as the actual line-level meter.
[5] As Friedberg 2011 explains, many monosyllables in Russian,
including the pronominal forms я (1sg personal
pronoun, nominative case, line 2) and мне (1sg
personal pronoun, dative case, line 4), are read with stress in strong metrical
position and without stress in weak metrical position. The dictionary returns
these as stressed (1
), but we reset them (based on a lookup list
of words subject to this treatment) to 0
(ambiguous stress)
before calculating the metrical valence.
[6] The probability that a metrically strong position will be occupied by a vowel
that carries linguistic stress follows an alternating pattern that has comes to
be known as the Figure 2: Aleksandr Sergeevič Puškin, law of regressive accentual dissimilation
.
According to this principle, the penultimate strong position is the one that is
most likely to be filled with an unstressed vowel, the antepenult is the one
most likely to be stressed after the last, etc. For Puškin’s
Prorok
, the frequency with which linguistic stress actually
coincides with specific syllabic positions in the line may be illustrated as
follows:
Prorok
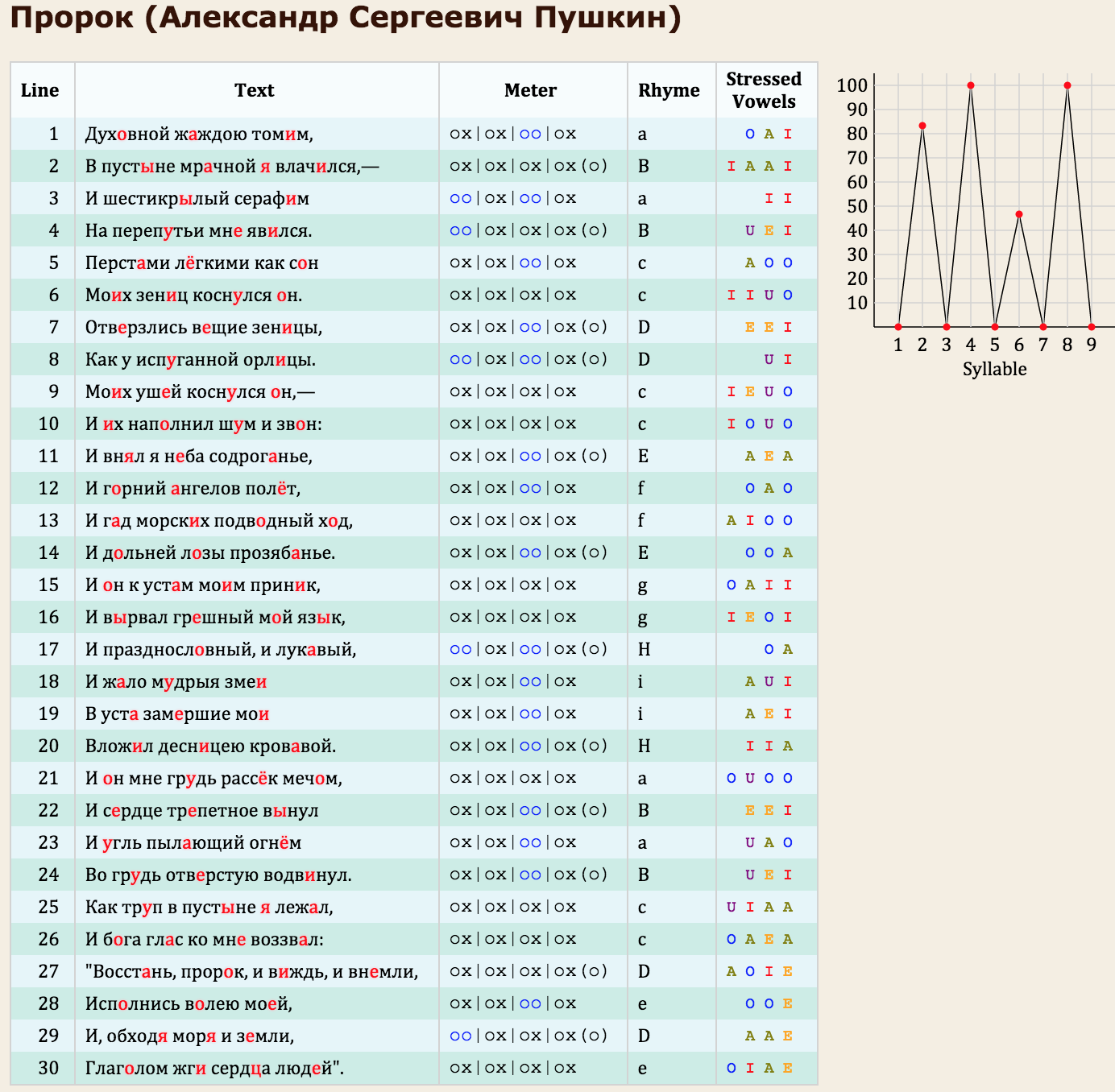
[7] Hypermetrical caesura must be identified and handled specially.
[8] As noted above, the pattern may be complicated by hypermetrical caesura, the identification of which requires special handling.
[9] Here and in many other listings, we use XQuery or XSLT for legibility, but the heavy lifting is being done by XPath, and the same functionality could be implemented a single XPath expressions. In this case, for example:
if (index-of((0, 1, 0, 1, 0, 1, 0, 1, 0),1)[last()] mod 2 eq 0) then 'iambic' else 'trochaic'
Like the damp wind you beat at the shutters, Like the black wind you sing: You are mine! I am primordial Chaos, I am your friend of old, Your only friend, Open! Open![Our translation]
[11] In Russian, phonological words (characterized by a single stress)
are not always coextensive with orthographic words (separated by
spaces), and the definition of word
that matters for
versification is the phonological word, or stress group.
Specifically, Russian clitic particles, such as prepositions and the
negative particle ne (no;
not
) form a single phonological word (characterized by a
single stress) with their head words. Additionally, the stress of
many categories of monosyllabic words that are not phonological
clitics in normal spoken Russian is determined in poetry by the
ambient meter, so that the words are pronounced with a stress during
reading when they fall in a metrically strong position (one where
stress is expected according to the ambient meter) and without a
stress in a metrically weak position (Friedberg 2011). For that reason, the boundaries in this column identify
transitions not between orthographic words, but between phonological
words, that is, stress groups.
[12] Whether there must be a pause during performance is a separate question. See
the review of the literature in chapter 4, Caesura
of Tsur 2012.
In her shameless and pathetic baseness, Like dust, she is gray, like mortal remains. And I am dying of this fatal closeness, Because she cannot be dissolved from me. She is rough and she is thorny; She is cold—she is a snake. I am wounded all over by her sickly-burning, Elbow-shaped scales. Oh, to feel her sharpened sting! Sluggish, dull, and silent. She’s such a grave and such a faded thing, And there is no reaching her—she’s deaf. Obstinately, with her coiling rings She snuggles up to me, strangling me whole. And this most dead, most black of things, Most terrifying she—she is my soul!(Translation by James McGavran from https://tropicsofmeta.wordpress.com/2013/07/29/3-poems-by-zinaida-gippius/, reproduced here with the permission of the translator.)
[14] Standoff markup may also be used for this purpose. In both cases the markup is distinguished syntactically from the textual content.
[15] In some cases markup may be used to add information that is not otherwise easily accessible in plain text; common cases in a digital humanities context include named entity and anaphor identification or disambiguation. In other cases markup that duplicates information that is accessible in plain text is nonetheless used for ease in retrieval and analysis; a common case in a digital humanities context might involve tagging words that are otherwise fully delimited by white space. In other instances markup attributes might be used to duplicate information already encoded through element structure; a common case involves numbering acts or scenes in a play or chapters in a novel when the section or division hierarchy already fully encodes and represents that ordering information in an alternative way.
Human legibility of tagged source files is not a requirement for all digital text projects, but it is a factor that digital humanists often consider when designing their markup schemas.
[16] Identifying the syllable boundaries needed to locate foot boundaries within an orthographic word is complex because in some cases variation is possible. The pipe characters that represent foot boundaries within words in the examples above were added by hand to simplify reading, and they are not an integral part of our analysis. It is possible to identify syllable boundaries in text in natural orthography algorithmically if we are willing to make arbitrary decisions in situations that permit variation, but because that level of precision is not relevant to our analysis, we have not prioritized implementing that functionality at this time.
[17] As was noted above, the XQuery is for human legibility, and the actual analysis can be expressed purely in XPath.
[18] The usual subordination of words to lines may be violated, often for the
comic effect that comes from the unexpected, as in Tom Lehrer’s
Smut
:
As the judge remarked the day that he acquitted my Aunt Hortense, “To be smut It must be ut- Terly without redeeming social importance.”
[19] We have not tagged unstressed vowels in order to preserve legibility, but
should that additional markup be needed, it is easily implemented with
<xsl:for-each-group> and a @regex
attribute value that matches vowel letters.
[20] For an explanation of this term see DeRose 2004.
[21] The phonetics that correspond to the orthographic sequence ough
in English is notorious in this respect. See, for example, A
rough-coated, dough-faced, thoughtful ploughman strode through the streets
of Scarborough; after falling into a slough, he coughed and
hiccoughed.
, cited at
https://www.englishclub.com/ref/esl/Power_of_7/7_Ways_to_Say_ough__2924.htm
[cited 19 July 2015].
[22] The same is true for other phonetic patterning, such as more generalized instances of consonance and assonance. The identification of line-internal rhyme of some types might require attention to word boundaries, and we have not made that a goal of the project at the present time.
[23] This two-step process (1. convert orthography to phonetics and then 2. compare the phonetic representations) reenacts the human experience of seeing letters on the printed page and recognizing rhyme on the basis of the sounds represented (often not on a one-to-one basis) by those letters.
[24] Or any other Unicode characters that do not otherwise occur in the phonetic surrogate of the line, but repurposing case is probably the most legible option.
[25] Open masculine rhyme also requires that the supporting
consonants before the final stressed vowels match. This feature distinguishes
Russian from English rhyme; see
and tree
rhyme in
English, but the Russian equivalents would not rhyme because of the absence of a
supporting consonant.
[26] From the perspective of the continuous stream of sound, that stressed vowel sounds are located on a lower level of the hierarchy than other phonetic material is an XML side-effect. It is not structurally different from many other inline markup situations (e.g., emphasis), except perhaps in degree, in that stress tagging almost always (except in the case of words consisting of a single stressed vowel, and then only within the individual word) creates mixed content.
The contradiction between the XML modeling and the human
understanding of poetic utterances is not obviated by encoding
stress as a textual diacritic or by encoding stressed vowels as
different textual characters than their unstressed counterparts,
which are possible syntactic alternatives to the markup employed
here. Each of those alternatives contradicts the human understanding
of the content of the line differently but not less than our use of
a <stress> wrapper element.