Introduction
The XML and HTML standards and associated technologies have evolved (and continue to evolve) in different ways with very different goals. A good understanding of these differences is the key to the successful development of solutions that benefit from both XML and HTML.
DeltaXML solutions perform comparisons on an XML tree within an XML pipeline. This paper provides two practical examples of how we’ve been able to exploit the extensibility of our own solutions and the features of third party tools to provide a smooth integration between XML and HTML5. These examples can be summarised as:
|
HTML5 Compare |
A website providing an HTML5 comparison service. This demonstrates a comparison solution for HTML5 created by extending a system that processes XML using an XSLT transform pipeline; the main problems were handling parsing and serialization differences between XML and HTML5 and adapting XSLT filters originally designed for XHTML. |
|
XMLFlow |
A web app for reviewing and merging concurrent changes to DITA documents. In this client-side example, we show it's possible to exploit XSLT's powerful document transform capabilities and yet still provide the dynamic behaviours, responsive design and file-handling capabilities characteristic of HTML5 web applications. For this we use the client-side XSLT processor's interactive extensions and JavaScript interoperability. |
HTML5 Compare
Overview
The HTML5 Compare project was set up following an external enquiry to DeltaXML. The reported problem was about a number of difficulties encountered when comparing relatively large and complex HTML5 documents using tools then available. The documents in question were different drafts for the W3C HTML5 specification, and this naturally made a much more compelling case for us to come up with a solution.
HTML5 Compare is built using an XML comparison toolkit called DeltaXML Core. Core provides an XML processing pipeline with configurable input and output filter-chains and an XML comparator in the middle. Therefore, to work with HTML5, a parser and serializer is needed at the input and output of the pipeline.
Figure 1: The HTML5 Parser and Serializer sit at each end of an XML processing pipeline
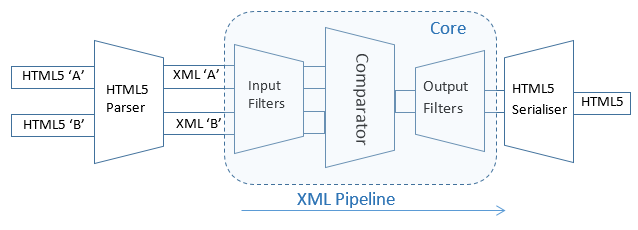
The HTML5 Parser
With HTML5, the W3C specification includes formal syntax and parsing rules[1] such that the same document model may be achieved using very different lexical HTML5 versions. Because these rules are more clearly specified in HTML5 than HTML4, better quality comparisons are possible as differences in HTML syntax that don't affect the DOM can be safely ignored when required.
An HTML5 parser determines where some elements must close if they have no close tag,
it also adds any missing wrapper elements where they are
implied and where the DOM requires them. The HTML5 syntax shown below is valid but
has a number of elements (such as the html element
itself) and element-tags that must be inferred correctly by the parser to make a valid
DOM.
<!DOCTYPE html> <title>The title</title> <p>Testing<br>paragraph <table><tr><td>First cell</td></tr></table>
After the HTML5 shown above is parsed the resulting document model can be processed as XML, the serialized form of this is shown below with the original content and tags in bold:
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<title>The title</title>
</head>
<body>
<p>Testing<br />paragraph</p>
<table>
<tbody>
<tr>
<td>First cell</td>
</tr>
</tbody>
</table>
</body>
</html>The XML serialization of the parsed HTML5 adds new elements: html, head, body and tbody, these wrapper elements are
required as part of the DOM and were therefore added by the parser. The p start tag now has a corresponding close tag, and the
br element made self-closing. The other key difference is that a meta element has been added with default values for
attributes to describe the Content-Type.
The use of a conformant HTML5 parser at the very start of the comparison pipeline allows non-significant differences in the lexical HTML5 to be ignored, the chosen parser for this project was the Validator.nu parser [2]. This Java-based parser provides a standard SAX interface and therefore interfaces well with the Java-coded Core comparator which exposes a Saxon-API based interface for integration with an internal Saxon XSLT processor instance. The code required to integrate the parser into the comparator is relatively straightforward:
public XdmNode compare(InputStream is1, String systemId1, InputStream is2,
String systemId2, OutputStream result){
HtmlParser htmlParser= new HtmlParser();
htmlParser.setErrorHandler(errorHandler);
org.xml.sax.XMLReader xmlReader= htmlParser;
Processor saxonProcessor= new Processor(true);
InputSource in1= new InputSource(is1);
InputSource in2= new InputSource(is2);
in1.setSystemId(sytemId1);
in2.setSystemId(systemId2);
DocumentBuilder db= saxonProcessor.newDocumentBuilder();
SAXSource saxSource1= new SAXSource(xmlReader, in1);
SAXSource saxSource2= new SAXSource(xmlReader, in2);
XdmNode inputNode1= db.build(saxSource1);
XdmNode inputNode2= db.build(saxSource2);
com.deltaxml.xhtml.XhtmlCompare xhtmlCompare= new XhtmlCompare();
return xhtmlCompare.compare(inputNode1, inputNode2);
}
The code above shows how the XMLReader interface of the HtmlParser instance is used to build XdmNode instances for each
HTML5 input, these then provide the input arguments, inputNode1 and inputNode2 for the compare() method
call.
The HTML5 Serializer
The result from the comparison is an XML document that requires conversion back to
the HTML5 format for rendering. The latest versions of the Saxon
processor are capable of HTML5 serialization, however, it was decided instead to use
the HTML5 serializer included with the HTML5 parser solution as
this should reduce round-tripping issues. An example of this is that a single newline
character at the start of a pre element is removed by
the parser but always added by the serializer to assist readability.
The SAX ContentHandler interface of the serializer allowed it to be used as the destination of the final
XSLT transform in the pipeline
as shown in the Java code below:
public void serialize(XdmNode compareOutputNode, OutputStream result,
Processor saxonProcessor){
XsltCompiler comp= saxonProcessor.newXsltCompiler();
XsltExecutable execFilter= comp.compile(finalXslt);
XsltTransformer transformer= execFilter.load();
transformer.setInitialContextNode(compareOutputNode);
ContentHandler ch= new HtmlSerializer(result);
transformer.setDestination(new SAXDestination(ch));
transformer.transform();
}
A useful property of the serializer is that it will always produce valid HTML5, for example any attributes not in the ‘HTML5 namespace’ are removed – unless they are prefixed with ‘data-‘. Note that this behaviour contrasts with some browser-hosted XML serializers described later in this paper, which sometimes produce XML that is not well-formed.
Comparison Detail
The comparison process starts with the two HTML5 input documents being converted by
the HTML5 parser to an XML DOM instance. The next step is to
apply each DOM instance to the comparison pipeline that is managed within a Java DocumentComparator object. The
DocumentComparator's internal pipeline is extended using a set of pre-existing XHTML processing filters
modified specifically for HTML5.
Each filter is implemented either in Java or XSLT and is managed as a FilterStep object that is combined with other related
FilterSteps to build a FilterChain. The common pattern is that, for each comparison feature, there is a dedicated input
filter with a corresponding output filter. For example, for word-by-word granularity
(an internal DocumentComparator feature), word tokens
are converted to XML elements in the input filter and then recombined after comparison
in the corresponding output filter.
Each FilterChain instance is applied to a specific extension point within the input or output pipeline
by passing using a
setExtensionPoint method call. Configuration properties of the DocumentComparator can be used to control internal filters.
For example, in this case HTML table handling is enabled with the ProcessHtmlTables property and CALS table handling is disabled with the
ProcessCalsTables property.
Simplified code for setting up the properties and FilterChains at specific extension points is shown below:
private static DocumentComparator getConfiguredComparator(Processor saxonProcessor)
throws Exception {
DocumentComparator dc= new DocumentComparator(saxonProcessor);
dc.setLexicalPreservationMode(null);
dc.setProcessCalsTables(false);
dc.setProcessHtmlTables(true);
dc.setDebugFiles(true);
filterStepHelper = dc.newFilterStepHelper();
FilterChain inputFormatterFc = filterStepHelper.newFilterChain();
FilterChain outputFc1 = filterStepHelper.newFilterChain();
FilterChain outputFinalFc = filterStepHelper.newFilterChain();
addFilterStepToChain(inputFormatterFc, "xhtml-add-xml-base.xsl");
addFilterStepToChain(inputFormatterFc, "html5-preserve-space.xsl");
addFilterStepToChain(inputFormatterFc, "xhtml-infilter.xsl");
dc.setExtensionPoint(ExtensionPoint.FORMAT_MARKER, inputFormatterFc);
addFilterStepToChain(outputFc1, "xhtml-resolve-hrefs.xsl");
addFilterStepToChain(outputFc1, "xhtml-compare-images.xsl");
dc.setExtensionPoint(ExtensionPoint.OUTPUT_PRE_TABLE, outputFc1);
addFilterStepToChain(outputFinalFc, "xhtml-outfilter.xsl");
addFilterStepToChain(outputFinalFc, "xhtml-combine-deltatags.xsl");
dc.setExtensionPoint(ExtensionPoint.OUTPUT_FINAL, outputFinalFc);
return dc;
}
A visual representation of the FilterChain/ExtensionPoint configuration created in Java is shown below:
Figure 2: XSLT Filter chains are configured for specific extension points in the pipeline
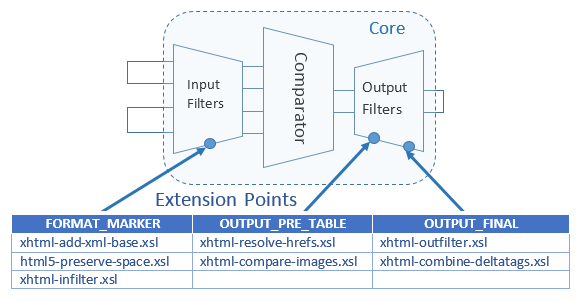
Whitespace Preservation in HTML5: When XHTML is parsed in an XML parser, xml:space attributes are
added for elements where whitespace preservation rules apply, however, this does not
happen in an HTML5 parser. To allow for this, a simple XSLT filter
html5-preserve-space.xsl is used to add the missing xml:space attributes so that filters further on in the pipeline
have the information they need for whitespace preservation:
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xhtml="http://www.w3.org/1999/xhtml" exclude-result-prefixes="#all" version="2.0">
<xsl:template match="node() | @*">
<xsl:copy>
<xsl:apply-templates select="@* | node()"/>
</xsl:copy>
</xsl:template>
<xsl:template match="xhtml:pre">
<xsl:copy>
<xsl:attribute name="xml:space" select="'preserve'"/>
<xsl:apply-templates select="@* | node()"/>
<xsl:copy>
</xsl:template>
</xsl:stylesheet>In addition to whitespace preservation, a number of other comparison features are included in HTML5 compare. No HTML5 specific problems were encountered with the corresponding XHTML filters for these features, but they are listed here for completeness:
-
Word-by-word granularity
-
Structural changes to HTML tables
-
Resolving relative URIs in each source
-
Handling of links to CSS stylesheets
-
Conversion of relative URIs to absolute URIs
-
Binary comparison of referenced images
-
Special processing of formatting elements
User interface
HTML5 Compare's user interface works as a conventional HTML web form presented to the user. The user is first asked to enter the URLs for the 'A' and 'B' documents of the comparison. The 'Run' button is then pressed to invoke the comparison.
Figure 3: Running the comparison
The compare request is sent to the server via the form using a HTTP Get, server-side code retrieves the HTML5 documents from the given URLs and invokes the compare method with these documents as arguments. Once a result is ready the current page is replaced with the comparison result page in typical client-server fashion. Note that the HTML, CSS and embedded JavaScript for the rendered result is generated in the final XSLT filter in the comparison pipeline.
Figure 4: The rendered comparison result in 'View Both' mode.
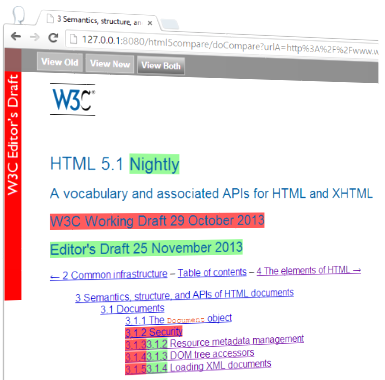
The header bar in the comparison result contains three buttons to allow switching between the ‘View A’ and ‘View B’ document views and a ‘View Both’ mode. In this last mode, the differences are highlighted with red and green background colours, effectively showing deletions and additions respectively.
Formatting Elements: Special treatment is reserved for comparison of inline elements within HTML that
are primarily
associated with formatting, alignment of such elements prioritises text content over
structure; to achieve this, an input filter is used to identify and
mark formatting elements prior to comparison. The result is a common text stream enclosed
within two different hierarchies that potentially overlap. XML
fragmentation (see Modelling overlapping structures [3] ) is used to represent overlap cases internally. Here is a simple overlap
example, with HTML strong and em elements renamed as s and i respectively for illustration
purposes:
|
Input A |
<p>The quick <s>brown fox jumped</s> over the lazy dog.</p> |
|
Input B |
<p>The quick brown <i>fox jumped over the</i> lazy dog.</p> |
|
Result |
<p deltaxml:deltaV2="A!=B">The quick <s deltaxml:deltaV2="A!=B" deltaxml:deltaTagStart="A"> brown</s> <s deltaxml:deltaV2="A!=B" deltaxml:deltaTagEnd="A"> <i deltaxml:deltaV2="A!=B" deltaxml:deltaTagStart="B">fox jumped</i> </s> <i deltaxml:deltaV2="A!=B" deltaxml:deltaTagEnd="B"> over the</i> lazy dog. </p> |
With the comparison result in this format, each tree, A and B, can be extracted independently by using the
deltaxml:deltaTag attribute values to filter the unwanted trees from the fragmented XML in a multi-stage
XSLT transform. For generating
HTML for rendering, an alternative approach is also used: here milestone span elements are added to mark the extents of formatting
differences using an XSLT-coded recursive-descent parser. An XSLT 3.0 map is exploited to keep track of stack information for each tree,
for trace purposes, an xsl:message instruction is used to show the state of each stack for each recursion, this also
provides for a rough
pre-HTML visualisation of the trees:
node parent text overlap-stacks
{A+B}
[p p p
'The quick ' p The quick p {A}
{s s p - - s
' brown' s brown p - - s
s} p p - - s
{s s p - - s {B}
{i i p - - - s - - - i
'fox jumped' i fox jumped p - - - s - - - i
i} s p - - - s - - - i
s} p p - - - - i
'\n ' p p - - - - i
{i i p - - - - i
' over the' i over the p - - - - i
i} p p - -
' lazy dog.' p lazy dog. p - -
p]For the end-user, changes in formatting elements normally have a different significance
to changes in actual text content, it is therefore a
requirement that changes to formatting elements are rendered differently in the comparison
output. Figure 5 shows the result of an XSLT
transform on the raw comparison result representing overlapping elements. The result
is HTML with span elements that have class attributes
representing the A and B hierarchy. Corresponding CSS rules use the box-shadow property to style the span elements with underlines of
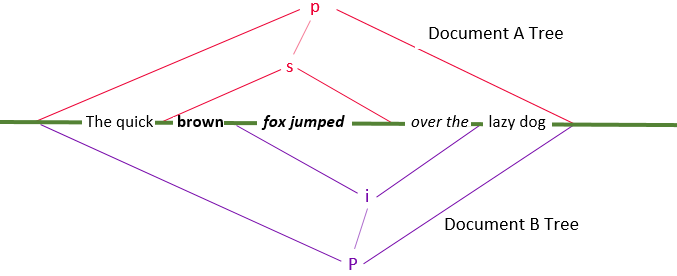
different colors to show the underlying structure. Below this is a diagram showing
an alternative diagrammatic view
Figure 5: Overlapping differences in elements used for formatting require special treatment

Figure 6: An alternative view of overlapping markup
A source view using underlines as shown in Figure 5 above should be easier to read than the raw fragmented XML markup which can be quite verbose, but will probably not suit many HTML users. Moreover, there is a performance issue associated with syntax-highlighting the source of large HTML documents due to the number of extra span elements required.
The alternative approach for viewing overlapping hierarchies, now used by HTML5 compare in the 'View Both' mode, is to show the WYSYWIG formatting view with the 'Document B' formatting shown. A subtle top/bottom border is used to highlight areas where the 'Document A' formatting differs. The user can then hover over the highlighted areas to see the 'Document A' formatting, a JavaScript event handler substitutes in the 'Document A' formatting elements to achieve this.
Figure 7: Formatting in the browser changes as the mouse hovers over a formatting change

Future Work
Performance
The extra complexity associated with producing more usable results means that HTML5 comparisons can take a significant amount of time, especially for large documents over 1MB in size with a significant number of changes. The amount of memory available for the comparison may also be a concern.
The current design could be improved by making comparison requests asynchronous and updating the user interface to notify the user of progress (or otherwise). The WebSocket API is available on our web system and would provide this capability without significant architectural changes server-side. Socket.IO, hosted by a Node.js server is another approach that has been suggested but this might be difficult to integrate with DeltaXML's existing server-side infrastructure. A further improvement would be to either increase resources available for a comparison or impose a restriction on the size of input files to ensure a reasonable response time.
Lexical Preservation
The use of an HTML5 parser prior to comparison means that we lose lexical differences
in the HTML5 source that are not significant in terms of
rendering the HTML but may be significant for authors who need to edit the result
of an HTML5 comparison in its lexical form. For example, character
entity references such as ½ are resolved to the unicode character '½' by the parser but are not converted back
to
references by the serializer. It's possible that in future the HTML5 parser and serializer
could be extended to preserve some of the lexical detail
that is currently lost.
XMLFlow
XMLFlow is a single-page web application designed for the tablet or desktop. It provides a document review capability for concurrent changes made by two or more authors to a document derived from the same common ancestor. An important priority is the effective handling of the conflicts that can often occur when changes are made concurrently. The fundamental problem is about representing and modifying the state of an XML document within the browser using HTML, CSS and JavaScript. A key second-level problem is about how to load and save the XML from within the browser.
Inception
Our DITA Merge product combines multiple versions of a DITA XML document and outputs a single DITA XML document with DeltaXML annotations (namespaced elements and attributes) that describe the origin of differences in a compact format termed 'DeltaV2', a sample extract is shown below:
<section deltaxml:deltaV2="anna!=ben!=chris">
<title deltaxml:deltaV2="anna=chris!=ben">
<deltaxml:textGroup deltaxml:deltaV2="anna=chris!=ben">
<deltaxml:text deltaxml:deltaV2="anna=chris">Introduction</deltaxml:text>
<deltaxml:text deltaxml:deltaV2="ben">Preliminaries</deltaxml:text>
</deltaxml:textGroup>
</title>
<p deltaxml:deltaV2="anna!=chris">Anna <deltaxml:textGroup deltaxml:deltaV2="chris">
<deltaxml:text deltaxml:deltaV2="chris">and Chris </deltaxml:text>
</deltaxml:textGroup>likes to do things properly and have introductions.
</p>
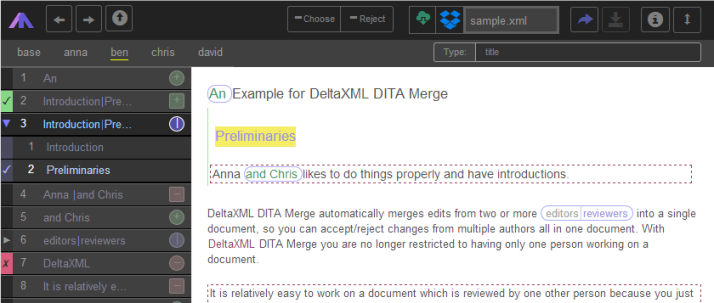
</section>XMLFlow is being developed informally as a study of a way to handle this 'raw' DeltaV2 XML output from DITA Merge. It is designed to present to the end-user DITA document changes made concurrently by multiple contributors in a comprehensible and interactive way.
Figure 8: Screenshot showing the review of changes in XMLFlow after an n-way merge.
High-level Design
Whilst the main priority for this design is to provide an effective user interface, the study is helped considerably by making the app fully functional by providing features for loading and saving the XML documents being reviewed by the user. These features are currently:
-
Load XML from the desktop file system (does not apply when hosted on a tablet)
-
Load XML from a users Dropbox cloud-based file system
-
Load XML from a user-supplied URL (on any domain)
-
Save XML locally between sessions
-
Save XML to web server file store
-
Permit copy of XML from web server file store - to file system or to Dropbox
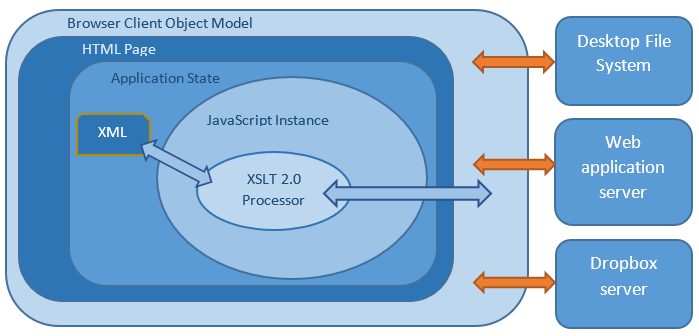
A ‘top-down’ design approach is used for XMLFlow to allow a more flexible study of the user interface. the functionality and interfaces of services provided by the web server are driven by the needs of the client-side components. A high-level design view of the web app and the back-end systems it interacts with is shown below:
Figure 9: A high-level design view of XMLFlow
The implementation exploits a number of internal compenents and third party open source frameworks, APIs and systems, the table below outlines the key components used.
Table I
Summary of the most significant client-side components
| Type | Component | Description |
| HTML5 | Bespoke JavaScript functions | Low-level processing and interaction with JS APIs |
| HTML5 | Custom CSS | App-specific styling of user interface buttons and popups |
| HTML5 | DITA CSS | Styling of span elements representing the DITA XML document |
| HTML5 | Bootstrap CSS [4] | Underlying styles for main user interface |
| HTML5 | Dropbox Chooser [5] and Saver [6] APIs | Features for saving and opening documents to and from Dropbox |
| XML | Saxon-CE [7] | XSLT 2.0 processor from Saxonica (a JavaScript library) |
| XML | DITA Body XSLT | Transform of DITA XML to HTML spans |
| XML | Change List XSLT | Generation of HTML div elements for each change |
| HTTP | CORS [8] | Cross-Origin Resource Sharing - retreival of XML from Dropbox |
| HTTP | FormData API [9] | Asynchronous HTTP for posting data - including files. |
| HTML5 | File API [10] | File-handling - for file drag and drop and blobs for HTTP. |
| HTTP | Apache Tomcat [11] and FileUpload [12] libraries. | Java servlet application server and file upload features. |
| HTTP | Apache HTTPClient [13] and HTTPCore [14] libraries. | Server-side processing of HTTP GET and POST requests. |
The Saxon-CE XSLT 2.0 client-side processor lies at the centre of the design. The 'host' HTML page was developed first to provide a skeleton structure with components that can then be updated dynamically and independently by XSLT. The main HTML body element structure updated by XSLT is shown below - style associated attributes have been removed for readability purposes:
<body>
<div class="navbar navbar-inverse navbar-fixed-top" role="navigation">
<div class="container-fluid">
<div>
<ul id="members">
<!-- update dynamic list of document versions -->
</ul>
<div id="x-download">
<div class="input-group">
<!-- show status type -->
<span id="status-label">Status:</span>
<!-- show status message -->
<input id="status" type="text" class="form-control" placeholder="">
</div>
</div>
</div>
</div>
</div>
<div class="scrollbody">
<!-- update document body -->
<div id="docbody" data-visibility="hidden"></div>
</div>
<div>
<div class="row">
<div class="col-sm-3 col-md-2 sidebar">
<ul class="nav nav-sidebar" id="changes">
<!-- update list of document changes -->
</ul>
</div>
</div>
</div>
</body>Interactive XSLT extensions (IXSL) for the mode and href attribute of the xsl:result-document instruction
allow this to be used to update specific HTML elements by an 'append' or 'replace'
operation.
An initial XSLT transform showbody.xsl is invoked from JavaScript and used to convert the DITA Merge output
(standard DITA XML with DeltaXML annotations) to HTML span elements with attributes
added that match CSS rules used for styling purposes. An
xsl:result-document instruction with an href attribute value of #docbody is used to populate the div element
(with an id attribute value of docbody) with the result of this transform to provide the 'Document View'. Another
xsl:result-document instruction populates a ul element with li elements that show a label for each of the
document versions represented in the merged document.
Figure 10: Span elements in the Document View are styled with CSS rules to represent DITA tables etc.
A secondary XSLT transform setchanges.xsl invoked from JavaScript creates a vertically stacked list of changes with
id attributes that correspond with similar id attributes on elements in the Document View to allow easy interaction. The
entry template for this transform is shown below. Here the #changes value of the href attribute in the
xsl:result-document instruction selects the target element for the transform with an id attribute value of changes.
The XPath expression in the select attribute ensures one and only one node for each change is processed, allowing the
the
position() function to be used to determine the change number. The js:getV2Members() function call is a call to JavaScript
that returns the sequence of strings representing each document version, used to allow
the count() function determine the number of
members.
<xsl:template match="/">
<xsl:variable name="deltav2" as="attribute()?" select="/*/@deltaxml:deltaV2"/>
<xsl:choose>
<xsl:when test="$deltav2">
<xsl:variable name="member-count" as="xs:integer"
select="count(js:getV2Members(string($deltav2)))"/>
<xsl:result-document href="#changes" method="replace-content">
<xsl:apply-templates
select="//deltaxml:textGroup | //*[not(self::deltaxml:*)]
[exists(@deltaxml:deltaV2) and not(contains(@deltaxml:deltaV2, '!='))
and count(tokenize(@deltaxml:deltaV2, '=')) ne $member-count
and not(parent::deltaxml:attributes)
or (exists(@deltaxml:deltaV2) and count(tokenize(@deltaxml:deltaV2, '='))
ne count(tokenize(parent::*/@deltaxml:deltaV2, '='))
and not(parent::deltaxml:attributes))
and exists(parent::*)]" mode="setchange"/>
</xsl:result-document>
</xsl:when>
<xsl:otherwise>
<xsl:result-document href="#changes" method="replace-content">
</xsl:result-document>
</xsl:otherwise>
</xsl:choose>
</xsl:template>
Event handling in XSLT
All dynamic behaviour of the app is controlled using XSLT templates for specific events
on elements selected by the XPath pattern in the
match attribute. A dedicated stylesheet, main.xsl, was used for event handling and all processing
associated with user events.
Figure 11: User events and handled by 'Interactive' XSLT Templates
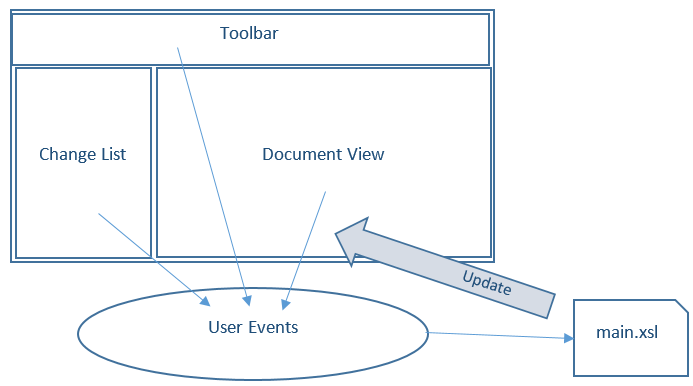
In Saxon-CE, event-handling templates exploit an IXSL extension for the mode attribute
that identify the type of event to be processed. For example,
ixsl:onclick is used to handle mouse click events. A simple JavaScript fix was required to handle
touch events on the IPad, this was required to determine if they were the equivalent of
a tap and not a move or scroll and then create a new click event that could then be handled on the XSLT side in the usual way. An example of
an event handling template is shown below:
<xsl:template match="div[contains(@class,'changebutton')]" mode="ixsl:onclick">
<xsl:call-template name="x-options"/>
<xsl:variable name="isOption" as="xs:boolean" select="../@class eq 'changeoptions'"/>
<xsl:variable name="id" select="if($isOption) then ../preceding-sibling::*[1]/@id else @id"/>
<xsl:variable name="bodyChange" as="element()" select="id(concat('deltaCount',substring($id,12)))"/>
<xsl:variable name="optionPos" as="xs:integer" select="count(preceding-sibling::*) + 1"/>
<xsl:for-each select="if($isOption) then
$bodyChange/*[@data-name eq 'deltaxml:text'][$optionPos]
else $bodyChange">
<xsl:sequence select="js:setDisableWScroll(true())"/>
<xsl:call-template name="selectResultRow">
<xsl:with-param name="temp-disabled" select="true()"/>
</xsl:call-template>
</xsl:for-each>
</xsl:template>Within the XSLT event template, the context node is the element corresponding to the
template's match pattern. This could theoretically be an
ancestor of the event target, so the target would have to be found from the JavaScript
event object (by using ixsl:event()), but for this
project it was simpler to structure the HTML and match pattern so that the context
node was always the node on which the event occurred.
The above example shows how the JavaScript function js:setDisableWScroll() is called from the XSLT. This particular call sets a
JavaScript boolean that is checked later to ensure no scrolling occurs even if the
template call updates the HTML asynchronously.
Sending XML to the Server
The method used for fetching XML files asynchronously from the server will be familiar
to most web developers. However, there is a relatively new
method for sending XML to the server in a way that can be coded simply on both the
client and server side. The resolveDocument() JavaScript
function is called by the main.xsl XSLT stylesheet and is used to first update the XML using the resolvechanges.xsl stylesheet and then send the result asynchronously to the server via a HTTP post.
var resolveDocument = function () {
setStatus("Preparing export...");
exportButton.setAttribute('data-enabled', 'no');
if (!xslResolveChanges) {
xslResolveChanges = Saxon.newXSLT20Processor(Saxon.requestXML("xsl/resolvechanges.xsl"));
}
var dfilename = dropZone.innerHTML;
dzFilename = "rsv-" + dfilename;
xslResolveChanges.transformToDocument(getCurrentXmlDom());
var result = xslResolveChanges.getResultDocuments(0);
console.log("result " + result);
var resolvedXML = xslResolveChanges.getResultDocument(xslResolveChanges.getResultDocuments(0));
var form = new FormData();
var blob = new Blob([Saxon.serializeXML(resolvedXML)], { type: "text/xml" });
form.append("objname", blob, dfilename);
console.log(reqhttp);
setStatus("Uploading XML...");
var oReq = new XMLHttpRequest();
oReq.open("POST", reqhttp, true);
oReq.send(form);
oReq.onreadystatechange = handleStateChange(oReq);
};The HTML5 FormData API, as used in the code above, provides the capability to post the XML to a server in such a way that the server can treat the posted XML as a file with a given name.
The last line of code assigns the handleStateChange() callback function to the onreadystatechange event of the HTTP
request. In this case the response handler simply updates the status box in the app
and enables the download button to show when the XML has been sent
successfully.
One disappointment with using the XML DOM in the browser is that serialization of
the DOM can produce invalid results depending on the browser.
Saxon-CE provides a serializeXML() method, but this simply wraps the browsers built-in method to allow compatibility
with older versions of
Internet Explorer. As one might expect, most serializaton issues are associated with
namespace declarations, to fix this issue, a simple XML serializer,
coded in JavaScript, is used that can declare known namespaces in the global document
scope. Though not suitable for cases where locally scoped
namespace declarations are required in the XML, this serializer is good enough for
the XML output of the final XSLT transform.
Server Side Processing
For this user-interface focussed project, server-side processing has been kept very simple. Here, Java servlets are used for handling the HTTP requests and Apache Tomcat is used as the web applicaton server. A simplified version of the Java used to upload files in response to a HTTP Post request is presented below:
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
DiskFileItemFactory factory = new DiskFileItemFactory();
ServletFileUpload upload = new ServletFileUpload(factory);
response.setContentType("text/xml;charset=UTF-8");
PrintWriter writer = response.getWriter();
writer.append("<?xml version=\"1.0\" encoding=\"UTF-8\"?>");
writer.append("<response>");
try {
List<FileItem> items = upload.parseRequest(request);
Iterator<FileItem> iter = items.iterator();
while (iter.hasNext()) {
FileItem item = iter.next();
if (item.isFormField()) {
processFormField(item, writer);
} else {
processUploadedFile(item, writer);
}
}
} catch (Exception e) {
writer.append("<error>" + "Upload exception " + e.getMessage() + "</error>");
e.printStackTrace();
} finally {
writer.append("</response>");
writer.close();
}
}In addition to Tomcat, the Apache commons libraries HTTPClient, HTTPCore and FileUpload significantly simplified the server-side development effort.
Conclusion
This paper demonstrates two very different examples on how projects can work effectively with XML and HTML5. The first project is XML oriented but successfully processes HTML5 by using a standards-based parser and serializer. The second project is browser-based and consequently HTML5 oriented but effectively retrieves, renders, updates and saves XML by using a collection of client-side technologies, including the Saxon-CE XSLT processor, Bootstrap CSS and a collection of utility JavaScript functions exploiting HTML5 APIs.
From our experience, as presented in this paper, the ability to exploit the combined resources of the XML and HTML5 technologies can significantly reduce development effort and provides for more flexible solutions.
References
[1] A vocabulary and associated APIs for HTML and XHTML: Parsing HTML documents http://www.w3.org/TR/html5/syntax.html#parsing
[2] Validator.nu http://about.validator.nu/htmlparser/
[3] Marcoux, Yves, Michael Sperberg-McQueen and Claus Huitfeldt. “Modeling overlapping structures: Graphs and serializability.” Presented at Balisage: The Markup Conference 2013, Montréal, Canada, August 6 - 9, 2013. In Proceedings of Balisage: The Markup Conference 2013. Balisage Series on Markup Technologies, vol. 10 (2013). doi:10.4242/BalisageVol10.Marcoux01. http://www.balisage.net/Proceedings/vol10/html/Marcoux01/BalisageVol10-Marcoux01.html. doi:https://doi.org/10.4242/BalisageVol10.Marcoux01
[4] Bootstrap CSS http://getbootstrap.com/css/
[5] Dropbox Chooser API https://www.dropbox.com/developers/dropins/chooser/js
[6] Dropbox Saver API https://www.dropbox.com/developers/dropins/saver
[7] Saxon-CE XSLT 2.0 Processor http://saxonica.com
[8] Cross-Origin Resource Sharing http://www.w3.org/TR/cors/
[9] FormData API http://www.w3.org/TR/XMLHttpRequest2/#interface-formdata
[10] FILE API: W3C Last Call Working Draft 12 September 2013 http://www.w3.org/TR/FileAPI/
[11] Apache Tomcat http://tomcat.apache.org/index.html
[12] Apache Commons FileUpload http://commons.apache.org/proper/commons-fileupload/
[13] Apache HTTPComponents HTTPClient http://hc.apache.org/httpcomponents-client-ga/index.html
[14] Apache HTTPComponents HTTPCore http://hc.apache.org/httpcomponents-core-ga/index.html