Intro
Modularised XML Example
Let's say we have a modularised XML document. It consists of a number of linked resources, XML or otherwise:
Figure 1: Document Tree
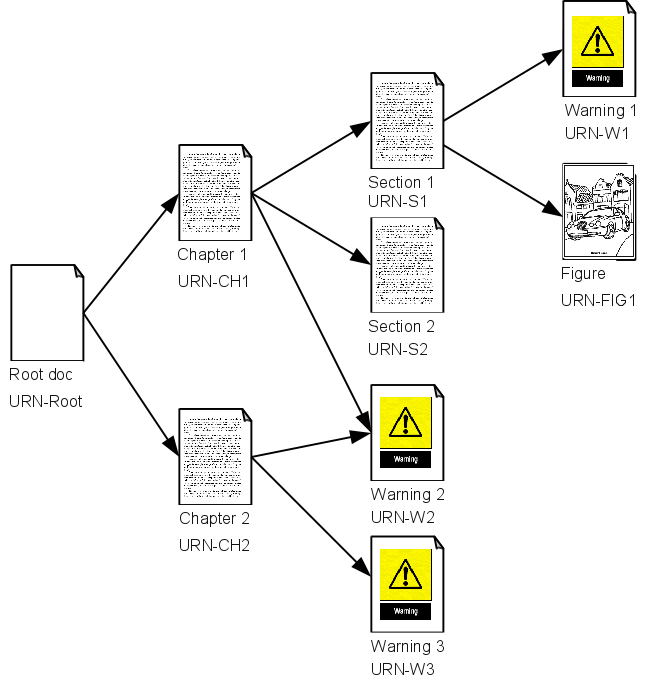
Each resource is version handled separately, and every significant change to a resource will result in a new version of that resource[1]. Many of the resources are reused in other documents as well. For example, the three warnings are used in many documents and might be edited by a separate legal team.
Furthermore, each link includes not only the resource's name but also its exact version. This means that while the document pictured above may use version 12 of Warning 3, another document may have linked to a later version of that same warning, say version 18. This means that, in a version handling system, any modularised document such as the one above can be precisely recreated later, using the right versions of each participating resource, as every link includes both name and version.
The Versioning Module in eXist
I've implemented the above modularisation and version handling in a document management system based on an XML editor coupled with a SQL database and a document management layer, but I'd very much like to implement something like that in an XML-based database. Something like eXist.
I love eXist. It's extremely powerful: it supports handling and storing XML as XML using XML technologies from XSLT to XQuery, XProc to XForms, and more, which means that geeks such as yours truly who are markup-centric rather than code-centric[2] can do a lot of cool stuff in eXist using those technologies and nothing else.
There is a simple versioning module available for eXist. It allows you to version handle your stored resources, basically adding a new version whenever you hit Save. It works quite well for what it is intended, well but there are problems:
-
You get a lot of versions, most of which are irrelevant.
-
It is therefore difficult to identify the relevant versions.
-
There's no concept of a workflow beyond that save operation, no check-outs or check-ins.
-
Addressing the stored versions is somewhat difficult.
-
The version number itself is just an integer number, with a single counter for everything version handled.
A more code-centric markup geek would probably write a better versioning module using Java or some such language, adding basic functionality for check-outs and check-ins, metadata for versions, etc. I'm not one of them, unfortunately, so I need to make do with what I have, which is XML and the XML-based technologies available to me in eXist.
The Use Latest
Problem
There are problems when updating a modularised document such as the one above:
Let's say, for example, that the link to Warning 3 needs to be updated from the old version 12 to the latest version, 18. It should be a simple matter of checking out Chapter 2, updating the link, and checking in the updated chapter again.
But this means that the root document's (Root doc's) link to Chapter 2 needs to be updated as well, which entails checking out the root, updating the link, and checking in the root again.
This causes several potential problems:
-
Since Chapter 2might have been used elsewhere, what if it had been edited elsewhere? What if that edit was more recent, meaning that Chapter 2 had been updated after our example document was first put together, with Warning 3 in version 12 inserted into Chapter 2? This would mean that Chapter 2 might contain incompatible changes.
-
The problem is the same for any ancestor module, of course. They might have been edited and updated since the document at hand was published and could therefore include incompatible content.
-
That later version of Chapter 2 might, of course, now also include new links in addition to in-module content.
-
It would then not be possible to update Chapter 2 to include a new version of the Warning 3 link without immediately creating a problem for the other documents using Chapter 2 once someone needed to update them.
So, with all this in mind, what if one always wanted to use the latest versions of some of the resources but not others?
Leaf nodes such as images are an obvious choice; it's perfectly reasonable to, say, always require the latest approved versions of warnings. In our example, the warnings are authored by a separate legal team, so it makes sense that the latest version approved is always the one to be used. It would then also make sense to automate the handling of links, automatically updating such a link to the latest version when editing the rest of the document.
Which means that we'll run into the problems outlined above, that is, how to (automatically) update the ancestor's link versions, considering that their contents (links) have potentially been updated with incompatible content. A change in contents means that a new version must result.
The problem here is, in the words of Eliot Kimber, bad configurations
management
[3]. The document link tree is allowed to be updated freely and
uncontrollably, creating a situation that is next to impossible to handle. More
specifically, the idea of always using the latest version does not play well with
the version management; every resource is updated separately and independently.
From a configuration management point of view, all of the resource versions above
are equal; no single version is more important than another. There are no workflow
statuses (editing
, reviewing
, approved
,
etc) for the participating resources. Nothing indicates what
version, if any, is approved. In other words, is updating from version 12 to version
18 OK in the first place? There is no scope, so always wanting the latest warning
(or image or some other resource) is a matter of safeguarding against change.
You want version handling so you can recreate the exact version of your
modularised document later, but at the same time, you want to be able to easily
update links to certain leaf nodes without the hassle of updating every parent link,
all the way up to the root. Preferably, you want the system to do the updating for
you, automatically, but the stupid
version handling that handles
every resource separately gets in the way, because the
resources are reused everywhere.
This, basically, is what I call the use latest
problem.
Better Version Management for eXist
To introduce version handling that is a bit more advanced than the versioning module in eXist, I propose the following:
Split the versioning of resources into different areas[4], where a stable
area will only ever contain approved versions
of documents, that is, the resources that make up a modularised document. This area
I
rather appropriately call Stable. When a stable document is
updated, it is first copied, or checked out, into an area intended for editing. I
call
this area Stage 1.
Figure 2: Versioning Split Into Two Areas
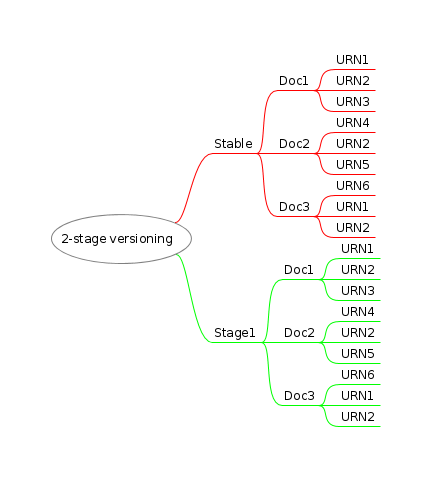
Versioning, then, is represented using a tree structure with two main areas:
-
Stable is exactly what it sounds like: stable. It contains the
major
versions of resources anddocuments
, that is, groups of resources. -
Stage 1 is intended for editing. An author can check out an individual resource from Stable to Stage 1 to work on the resource. He may also be allowed to check out a whole document.
Both areas are actual collections in the system, version handled using eXist's versioning extension module. In other words, every Save in respective collection results in a new version of the old one (offsetting each save using a diff against a first, base, version).
Each area, then, is versioned independently from the other. They are designed to be used together, however:
-
Stable implies integer versions: 1, 2, 3, etc.
-
Stage 1 implies decimal versions: 1.1, 1.2, 1.3, etc; 2.1, 2.2, 2.3, etc.
Save, Check-in and Check-out
Direct Save operations are only allowed in Stage 1. In other words, they are edited, saved and versioned there, and need to be checked in to Stable to cause a new Stable. Stable resources cannot be edited directly.
Stable resources can be checked out to Stage 1 to be edited, however, in which case they are locked in Stable while awaiting a check-in from Stage 1. A check-in from Stage 1 to Stable means that the Stage 1 resource is locked from further edits.
Note
The locking of files merits a discussion. See section “Locking”.
Check-out and check-in operations are as follows:
-
Check-out from Stable is a copy to Stage 1. The check-out causes a new file version of the resource in Stage 1.
-
Check-in from Stage 1 is a copy to Stable, locking the resource in Stage 1 and causing a new file version of the resource in Stable.
Version Abstraction
While both areas are version handled using the standard versioning system in the respective collection, they are connected to each other only implicitly. There is therefore a need to create version abstractions for the resources being copied, logically connecting the two areas. A basic URN namespace such as the following should be enough:
urn:x-resource:r1:<doc-number>:<lang>:<stable>:<stage1>
where <stable> is the integer version
in
Stable and <stage1> the decimal
version
in Stage1
[5]. <lang> is a four-position[6] language-and-country code for the resources that require one. For
example, version 2.1 of a British English document 123456 might be identified like
so:
urn:x-resource:r1:123456:en-GB:2:1
The URNs can be kept track of using an XML-based URN/URL map document, like so:
<resources>
<resource>
<urn></urn>
<url></url>
</resource>
...
</resources>A resource mapping document is useful, as links can be made to resource names (and specific versions) rather than addresses. In a reasonably well-indexed XML database, looking up a URN to find its corresponding URL should be quick, even with many resources and a large map.
Version Mapping XML
The resource maps need to do more than just map a name to an address, however. Every version, integer or decimal, of every URN needs to not only be mapped to a URL, but also to be given a context, indicating a relation between the two staging areas and, thus, between the different versions of the same resource.
The URN schema implies a structure for each resource version. Something like this[7]:
<?xml version="1.0" encoding="UTF-8"?>
<resource>
<!-- Base URN -->
<base></base>
<!-- Stable version 1 -->
<version>
<rev></rev>
<url></url>
<!-- Stage 1 (decimal versions) -->
<version>
<rev></rev>
<url></url>
</version>
<version>
<rev></rev>
<url></url>
</version>
</version>
<!-- Stable version 2 -->
<version>
<rev></rev>
<url></url>
<!-- Stage 1 (decimal versions) -->
<version>
<rev></rev>
<url></url>
</version>
<version>
<rev></rev>
<url></url>
</version>
</version>
</resource>I've included two Stable versions, each of them inside a
version tag, and two Stage 1 or decimal
versions for each Stable version. This is a nice, recursive
version structure (and yes, there is a reason for it; read
on).
Each rev identifies an actual stored version (integer or decimal) of
a resource, with the resource's URL in url. On
Stable level, there's only a single rev inside
version, but it may contain an unlimited number of decimal
versions.
A save operation in Stage 1 causes a new version of the
resource to be stored in that area. A new decimal-level version
structure is added to the mapping document, with a new rev (counted up
a notch) and a URL to the decimal-level resource file.
When a Stage 1, or decimal-level, resource is checked in, the
resource is copied into the Stable area, causing a new (eXist)
version of the resource to be stored in that area. A new integer-level
version is added to the mapping document, with a new
rev (counted up a notch) and a URL to the integer-level resource
file.
Using the mapping document and a simple XPath, any version of the base URN can easily be retrieved later.
Translations
Resources, of course, are translated to other languages all the time, so a versioning system needs to be able to keep track of the translations, clearly identifying which translation is based on which original, etc.
Translations As Renditions
A document management system will frequently require writing the actual
content in one language (the master language
) only and then
translating that content into whatever target languages that are needed. This is
mostly a design decision, based partly on the authors' preferences and location,
but also around the notion that a single language will be used to drive the
contents (and versions) forwards, thus minimising problems arising from allowing
different languages to take turns
in developing the content[8].
Such a system will regard the master-language document as the original bearer of content and the translations simply as renditions of that original. A typical workflow might be as follows:
-
Update the master-language document through a couple of versions, then lock an approved version.
-
Translate the approved version to any required target languages. These translations are seen as renditions of that particular master-language version.
-
Update the master-language document again, based on the approved and translated version from step 1, going through the required number of versions until done. Lock the approved version.
-
Retranslate the new approved version to any required target languages.
Note
Typically, there is no way to know what differences there are between this new approved version and the old one. In modularised documents, however, some modules may not need updates and will have their versions and any translations unchanged.
This works well in some contexts but there are some rather well-defined problems:
-
In a large, decentralised organisation, it might be difficult to always author in a single master language. Market-specific requirements frequently drive documentation forwards, and often in a market where the available writers would much prefer their own language.
-
When translating to certain languages, an intermediate language is often desired to keep costs to a minimum due to the availability of translators. It is, for example, much easier to find a good translator working from English to Simplified Chinese than from Swedish to Simplified Chinese.
Which brings us back to the URN schema representing a resource:
urn:x-resource:r1:<doc-number>:<lang>:<stable>:<stage1>
I use a similar URN schema to identify originals and their translations in a
system that requires the authors to write using a predefined master language and
then translating an approved version to any required target languages. So if
urn:x-resource:123456:en-GB:18 is the original, all of these
are renditions of that original:
-
urn:x-resource:123456:sv-SE:18 -
urn:x-resource:123456:es-ES:18 -
urn:x-resource:123456:pl-PL:18 -
urn:x-resource:123456:fi-FI:18 -
urn:x-resource:123456:en-US:18
Etc. But here's the kicker: there's nothing here to identify one as the master and the others as translations, other than my introductory sentence. We shouldn't have to define a master language, not if the versioning system can keep track of a series of URNs, so rather than actually defining one, it should be better to define a semantic resource:
urn:x-resource:123456
Then add a language to render the base content
with:
urn:x-resource:123456:en-GB
And versioning to identify changes over time:
urn:x-resource:123456:en-GB:18
If we accept that the underlying semantic resource can be updated using any rendering language, then this one is a perfectly acceptable updated version to version 18:
urn:x-resource:123456:fi-FI:19
It happens to be rendered in Finnish, but 19
is the next
version of the semantic resource according to the URN schema, above.
Version Mapping With Translations
Keeping the basics of the (semantic) resource and the URN schema representing it in mind, here's a mapping document updated with language handling:
<?xml version="1.0" encoding="UTF-8"?>
<resource>
<!-- Base URN -->
<base></base>
<!-- Stable version 1 -->
<version>
<rev></rev>
<url lang="en-GB"></url>
<!-- 1st decimal version -->
<version>
<rev></rev>
<url></url>
</version>
<!-- 2d decimal version -->
<version>
<rev></rev>
<url lang="en-GB"></url>
<url lang="sv-SE"></url>
<url lang="fi-FI"></url>
</version>
</version>
<!-- Stable version 2 -->
<version>
<rev></rev>
<url lang="en-GB"></url>
<url lang="sv-SE"></url>
<url lang="fi-FI"></url>
<!-- Stage 1 (decimal versions) -->
<version>
...
</version>
</version>
</resource>Let's walk through this. The first Stable version happens to be authored in English (UK):
<?xml version="1.0" encoding="UTF-8"?>
<resource>
<!-- Base URN -->
<base></base>
<!-- Stable version 1 -->
<version>
<rev></rev>
<url lang="en-GB"></url>
<!-- 1st decimal version -->
...
</version>
...
</resource>
Then follow two decimal versions. Translations are made based on the second saved iteration because the original language version is considered to be ready:
<?xml version="1.0" encoding="UTF-8"?>
<resource>
...
<!-- Stable version 1 -->
<version>
...
<!-- 1st decimal version -->
<version>
...
</version>
<!-- 2d decimal version -->
<version>
<rev></rev>
<url lang="en-GB"></url>
<url lang="sv-SE"></url>
<url lang="fi-FI"></url>
</version>
</version>
<!-- Stable version 2 -->
...
</resource>
The translations (and original) are then checked in (copied to Stable) to form a new stable version:
<?xml version="1.0" encoding="UTF-8"?>
<resource>
...
<!-- Stable version 1 -->
<version>
...
<!-- 2d decimal version -->
<version>
<rev></rev>
<url lang="en-GB"></url>
<url lang="sv-SE"></url>
<url lang="fi-FI"></url>
</version>
</version>
<!-- Stable version 2 -->
<version>
<rev></rev>
<url lang="en-GB"></url>
<url lang="sv-SE"></url>
<url lang="fi-FI"></url>
...
</version>
</resource>The concept of the semantic resource means that while translations (or rather, renditions) are bound to specific versions, all that is required to identify them uniquely is to add the URLs to the actual physical translated files; everything else remains the same.
Note
There's nothing above to suggest that the original (as in first
written
) language is always carried over from one stable version
to the next; a first decimal version based on a stable version might entail
translating the original-language document to a new language that is then
used to update the contents with.
Multiple Level Versioning
While the versioning system outlined in section “Better Version Management for eXist” is, in my mind, better than the basic versioning offered, there are problems:
-
It does not solve the
use latest
problem, outlined in section “TheUse Latest
Problem”. In all fairness, it doesn't attempt to; it simply provides a better abstraction for versioning. -
There will still be a lot of versions in Stage 1. This happens because basically, every new version is a save when working on a resource in that area.
-
Also, it is noteworthy that while too many versions are still being saved, overall, too few of them can easily be used to identify significant versions[9] of the works in progress.
So what can be done to identify all significant versions in a resource's version history?
One solution is to add markup to the version mapping XML to identify significant saves. This requires (author) access to the version map, so that suitable markup can be added to some saves but not others, but also additions to the save operation itself. It means supporting a special case of save.
This, of course, is the general case of adding workflow handling to the markup. The problem with workflow markup, apart from the access needed to the versioning markup and the additions to the save operation, is that not every check-in comprises a change in a workflow. Most, in fact, are simply versions that an author considers to be of interest for some reason.
Another is to check in the resource more often, but that would defeat one of the purposes of the Stable area, namely to identify stable versions only.
But there is a simpler, third option.
Adding a Second Stage
In my mind, it's far easier, and more logical, and better suited for the versioning logic as described by the URN schema and the version map markup, to add a second (or third, if you consider Stable to be one) stage, like so:
Figure 3: Versioning Split Into Three Areas
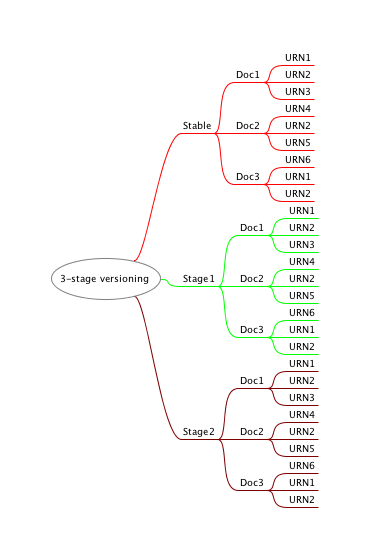
So, what's the use of a third area?
-
The Stable branch is still just that, stable.
-
Now, however, Stage 1 is the
project checkout level
, used for checking out projects, groups of documents, from the stable branch, but the participating resources cannot be directly edited there. Stage 1 is used to storesignificant
versions, but also to enable updating links in a controlled fashion. More on this last bit later. -
An author can check out an individual resource from Stage 1 to Stage 2 to edit the resource.
All three areas are still actual collections (and subcollections) in the system, still versioned using eXist's versioning module. In other words, every Save results in a new version.
Each area still implies an integer-based versioning system:
-
Stable implies integer versions: 1, 2, 3, etc.
-
Stage 1 implies decimal versions: 1.1, 1.2, 1.3, etc; 2.1, 2.2, 2.3, etc.
-
Stage 2 implies centecimal versions: 1.1.1, 1.1.2, 1.1.3, etc; 2.1.1, 2.1.2, 2.1.3, etc.
Save, Check-in and Check-out Revised
The basic idea is largely unchanged, but an added stage offers better control.
Direct Save operations are now only allowed in
Stage 2, that is, resources must be checked out from
Stage 1 to Stage 2 to be edited, and
any edits are saved and versioned there. When sufficiently edited (that is, when a
significant
version is at hand, it can be checked in to
Stage 1 to cause a new Stage 1 version
of the resource. Stage 1 resources cannot be edited directly
but mark those significant
versions that are not (yet?)
stable.
Sufficiently significant
[10]
Stage 1 resources can then be checked in from Stage
1 to Stable, causing a new
Stable version to be added.
Check-out operations, then, are as follows:
-
A check-out from Stable is a copy to Stage 1. A direct Save is not allowed. The check-out causes a new file version of the resource in Stage 1.
-
A check-out from Stage 1 is a copy to Stage 2. A direct Save is not allowed.
-
There is no check-out from Stage 2, as it would mean a third stage. A direct Save is allowed and will result in a new file version in Stage 2.
Check-in operations are as follows:
-
A check-in from Stage 2 is a copy to Stage 1, locking the resource in Stage 2 and causing a new file version of the resource in Stage 1.
-
A check-in from Stage 1 is a copy to Stable, locking the resource in Stage 1 and causing a new file version of the resource in Stable.
Note
It might be prudent to make the check-out/in operations permission-based, requiring special permissions to check in a new Stable version, for example, while allowing a writer to check out from (and in to) Stage 1.
The following exemplifies a document that is updated from Stable version 1 to 2. The numbers inside the circles represent an ordered list of check-out and check-in operations.
Figure 4: Updating from Stable Version 1 to Stable Version 2
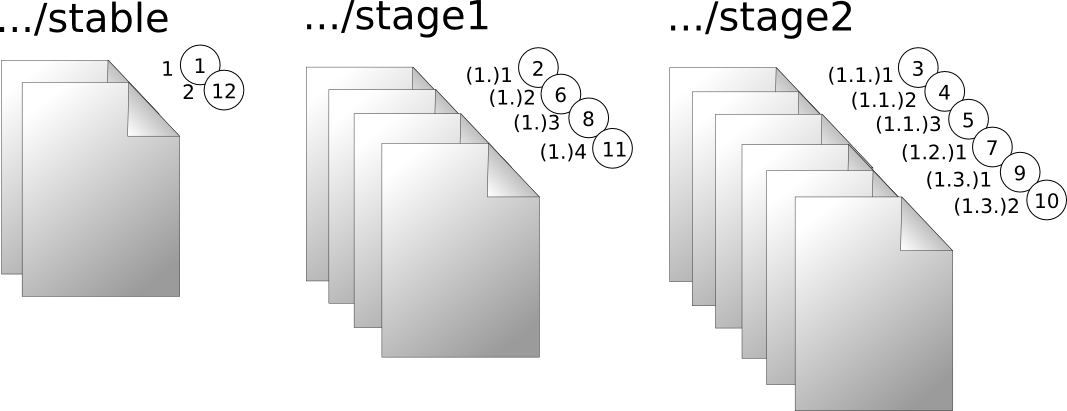
While only the Stable versions might need to be
published
, the Stage 1 could be seen as
significant, perhaps for traceability, and as such be saved. As we can see, the
number of these versions is comparatively small. Stage 2, on
the other hand, is simply the document as a work in progress, and while there may
be
a significant number of new versions produced in that area, none of them is seen as
significant.
Adding to the Abstraction
The URN schema identifying the resources (see section “Version Abstraction”) can easily be expanded, of course:
urn:x-resource:r1:<doc-number>:<lang>:<stable>:<stage1>:<stage2>
Version Map Additions
The version map markup was already recursive, so adding a second stage is uncomplicated:
<?xml version="1.0" encoding="UTF-8"?>
<resource>
<!-- Base URN -->
<base></base>
<!-- Stable version 1 -->
<version>
<rev></rev>
<url lang="en-GB"></url>
<!-- 1st Stage 1 (decimal) version -->
<version>
<rev></rev>
<url></url>
<!-- Stage 2 (centecimal) versions -->
<version>
<rev></rev>
<url></url>
</version>
<version>
<rev></rev>
<url></url>
</version>
<!-- Translations added -->
<version>
<rev></rev>
<url lang="en-GB"></url>
<url lang="sv-SE"></url>
<url lang="fi-FI"></url>
</version>
</version>
<!-- 2d Stage 1 (decimal) version -->
<!-- Translations checked in from last Stage 2 -->
<version>
<rev></rev>
<url lang="en-GB"></url>
<url lang="sv-SE"></url>
<url lang="fi-FI"></url>
</version>
</version>
<!-- Stable version 2 -->
<version>
<rev></rev>
<url lang="en-GB"></url>
<url lang="sv-SE"></url>
<url lang="fi-FI"></url>
<!-- Stage 1 (decimal versions) -->
<version>
<rev></rev>
<url></url>
<!-- Stage 2 (centecimal) versions -->
<version>
<rev></rev>
<url></url>
</version>
<version>
<rev></rev>
<url></url>
</version>
</version>
<version>
<rev></rev>
<url></url>
<!-- Stage 2 (centecimal) versions -->
<version>
<rev></rev>
<url></url>
</version>
<version>
<rev></rev>
<url></url>
</version>
</version>
</version>
</resource>The differences here consist mostly of an added recursive version,
listing centecimal versions for each decimal version. Notable is how translations
are added to the last centecimal iteration following the first decimal version and
then checked in to Stage 1, causing a new decimal
version:
<?xml version="1.0" encoding="UTF-8"?>
<resource>
<!-- Base URN -->
<base></base>
<!-- Stable version 1 -->
<version>
<rev></rev>
<url lang="en-GB"></url>
<!-- 1st Stage 1 (decimal) version -->
<version>
<rev></rev>
<url></url>
<!-- Stage 2 (centecimal) versions -->
<version>
<rev></rev>
<url></url>
</version>
<version>
<rev></rev>
<url></url>
</version>
<!-- Translations added -->
<version>
<rev></rev>
<url lang="en-GB"></url>
<url lang="sv-SE"></url>
<url lang="fi-FI"></url>
</version>
</version>
<!-- 2d Stage 1 (decimal) version -->
<!-- Translations checked in from last Stage 2 -->
<version>
<rev></rev>
<url lang="en-GB"></url>
<url lang="sv-SE"></url>
<url lang="fi-FI"></url>
</version>
</version>
...
</resource>This new decimal version is then immediately checked in to Stable, causing a new stable, integer version.
Metadata
While adding markup to identify significant check-ins (see the beginning of this chapter, at section “Multiple Level Versioning”) is, in my humble opinion, not a good idea, markup to handle metadata for every check-in probably is, as it will help locate a specific version later. The versioning module provided by eXist will add a timestamp and the user for a save, but other metadata, such as a comment field or a list of relevant keywords, need to be added.
The version map hints at several useful locations for the metadata:
-
For a resource, regardless of version.
-
For a whole version, be it integer, decimal or centecimal.
-
For specific content, as identified by the mapped URL.
Markup-wise, one solution might be something like this:
Figure 5: Metadata
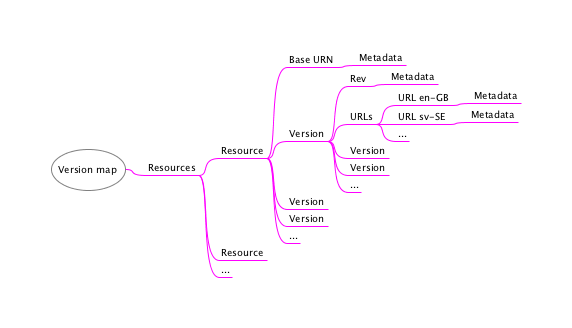
The structure and contents of the metadata element are beyond the
scope of this paper, as they concern themselves with metadata for each specific
version rather than the progression of versions as described here; they simply
provide human-readable metadata[11] for a specific version (as identified by the node).
Scope and Additional Stages
Adding a second stage allows us to keep track of significant checked-in versions beyond the Stable branch. Additional stages might be considered to add further semantics to versioning.
For example, if the versioning was used to handle the documentation of a large software project (everything from Microsoft Office to the Linux kernel springs to mind), the Stable branch could list major releases in the project's lifecycle, Stage 1 mark updates within those releases and Stage 2 any hotfixes, all of which should be considered to identify significant versions aimed at an end user. A Stage 3 and perhaps a Stage 4 might be needed to handle the versioning required for content production, where most versions would never reach the end user and only help ease a content author's life.
Note
The additional stages should, of course, be added to the URN schema.
Stages, then, are ultimately about scoping and define situations where the checked-in versions apply.
Projects
In addition to adding staging levels, the resources frequently need to be grouped when version handled. For example, if checking out a resource, it is often a good idea to check out the document or documents using them. Furthermore, check-outs as discussed here would benefit from defining projects, that is, groups of resources that are related for some other reason (resources commonly reused; documents belonging to the same product; all system administration guides; etc).
As a resource is frequently reused by several documents, a useful (and easy) way of identifying such resources in the version map is something like this:
<map>
<resources>
<resource>
...
</resource>
...
</resources>
<projects>
<project>
<urn></urn>
<urn></urn>
<urn></urn>
</project>
<project>
<urn></urn>
<urn></urn>
</project>
</projects>
</map>A project is an arbitrary group listing resources and project
metadata, useful when handling the resources together. Obvious features here
include check-out and check-in operations for the project, but I can think of
several other uses, most of which are beyond the scope of this paper.
Note
There are several ways of listing the URNs included in the project,
depending on their use. If the project's aim is to handle every decimal
version and language of a resource, a wildcard-based shorthand might be
preferable (say, urn:x-resources:123456:*:1:*).
Projects should, of course, be version handled too, as they will almost
certainly change over time. For example, one might handle them as any other
resource in the version map and always store project documents in
separate files (which requires a way to easily identify them when
authoring).
Use Latest Revisited
The use latest problem[12] is largely a scoping issue and happens because modules are reused everywhere, without defining rules for when and where reuse is allowed[13].
Better is to add one or more stages and clearly define a scope where using (and perhaps automatically updating links to) the latest approved versions is allowed. For example, if Stage 1 handles the releases of a product and its documentation within a major release, it might be reasonable to allow at least some of the reused modules to be automatically updated to their latest versions within that major version.
Let's say, for example, that Module A in version 3.1 (Stage 1) needs a link to a warning inside a warnings document authored by the legal team. The warnings document is also in Stage 1 and has version 1.19. Module A is checked out to Stage 2 and a link to the warning is added to it, including a fragment ID pinpointing the warning, like so:
<link xlink:href="URN:1:19#id-warning"/>
First of all, it is easy to define a business rule that updates the link to the latest available Stage 1 (decimal) version when Module A is published, triggered by the fact that the version linked to is a decimal version. It would be easy to look up the latest version in the version map and use that during preprocessing. If such a generic business rule feels a bit too risky, adding markup that further scopes the link is equally easy if somewhat crude:
<link xlink:href="URN:1:19#id-warning" use-latest="yes"/>
The logic here is use latest decimal version
. An editor feature
that checks the available versions of the warnings document, including new
Stable versions, and alerts the author if newer ones
are available than the one used in Module A should be useful and relatively
uncomplicated to implement.
More refined, but perhaps a bit complex to handle without a style guide and a
good user interface, might be to use the version level as the
use-latest value[14].
<link xlink:href="URN:1:19#id-warning" use-latest="1"/>
This would include every update to the target checked in to Stage 1 in the scope. An additional dimension of reuse might be to limit the scope to specific project or projects only.
Linking
This paper is about versioning rather than linking, but since the former will only be truly useful if there is at least some of the latter, I wish to make a few points regarding linking.
Using URNs in Links
My preferences for URNs stem from my day-to-day work but any other abstraction would probably do, as long as there is a way to separate the version component(s)[15] from the name. Using a name is important, however, assuming that the name is persistent and unique where used. Addresses change because resources are frequently moved around. Indeed, here, using an address would be very difficult in itself.
Be as it may, there is little point to the multilevel versioning abstraction if it
is only ever used for checking in and out monolithic XML documents that never
include a multilevel version link to anything else. In section “Use Latest Revisited”,
I do just that, though: the link element uses a name-based
xlink:href rather than an address-based one.
Using a URN in a link should be a simple matter of referencing resources in the
version map, using the base URN and as many levels of versions as needed (and
allowed by the business rules and their implementation). For example, an
implementation might use all version levels available when creating the link
(resulting in a pointer such as URN:en-GB:2:19:4:3#some-id) but then
update that link when publishing to the latest version in scope, based on the
business rules in effect.
The Case for XLink and Linkbases
Until now, I've made few assumptions about the link mechanisms themselves. The
link tag above, for example, is an inline reference using XLink
mostly because I rather prefer XLink and use Simple XLinks all the time, but I think
the example would be equally valid using, say, XInclude.
I do think, however, that XLink(id-xlink-spec) might prove to be very powerful, especially if the links were placed out of line, in a linkbase. There are several points to be made here:
-
Out-of-line links, of course, would not require updating the resource itself, only the linkbase arc, which would certainly change the specifics of a
use latest
implementation and conceivably result in easier-to-maintain business rules. -
Extended XLink does also suggest a standardised way for much, if not most, of the version map markup. The URNs listed in a project, for example, would probably benefit from being handled as XLink locator-type elements.
It would be sort of cool to add the linkbase to the version map directly:
Figure 6: Linkbase Added
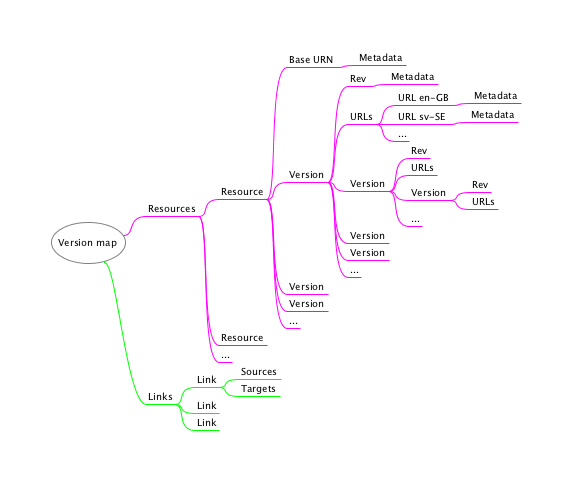
The Links
branch above list the XLink arcs.
There is, to my inner markup geek, something very appealing about this kind of all-purpose markup. I get all excited, thinking about how easy it would be to create, edit and publish XML with a few XPaths pointing to things across the version map XML, but the more practically-minded me questions the feasibility and, above all, necessity of including everything in the same, big file when it does not matter all that much in a well-indexed XML database where you actually put the markup you need to look up later.
All of which neatly brings me to the last big topic in this paper.
Implementation Notes
Now, I know that there is nothing quite so practical as a good theory, but I would still like to include a few implementation notes in my limited capacity as a non-programmer. I do believe that most if not everything of what's suggested in this paper can be implemented using XML technologies only, without having to learn Java, even though I'll readily admit that Java would help[16].
URN Generation and Parsing
The URN schema (see section “Version Abstraction” and section “Adding to the Abstraction”) requires a unique base URN that should be generated and handled by the system. At its simplest, the base URN is little more than a sequential number, bumped up a notch for every new resource, but allowing for different types of base URNs to identify different types of resources might be useful.
There is also a need to parse the URN, for example, when locating base URNs, handling wildcards, updating links, etc.
Check-in, Check-out and Updating the Version Map
Check-in and check-out are both copy operations from one location to another. In eXist, they are handled using XQuery functions for copying resources and, if permissions are used, eXist Security Manager functions for checking the appropriate permissions and possibly the group of the resource. eXist also provides UNIX-style functions for changing permissions, group, etc, for the file that is copied to protect it from unwanted changes[17].
Updating the map is a matter of adding to the resource's versions list. A
check-out means adding a new version to the next stage further down (from
Stage 1 to Stage 2, for example) and
starting up the next level revisions in the rev tag. A check-in does
pretty much the same thing but in the other direction, and needs to check the
existing revisions on that level before adding a new one.
For example, let's say that this resource in Stage 1, revision 2, is checked out:
<version>
<rev>2</rev>
<url>xmldb:exist:///...</url>
</version>A new version is added, like so:
<version>
<rev>2</rev>
<url>xmldb:exist:///...</url>
<!-- Stage 2 (centecimal) versions -->
<version>
<rev>1</rev>
<url>xmldb:exist:///...</url>
</version>
</version>Even though this example discusses stages 1 and 2, there's actually nothing apart from the comment that places them there. The operation here is the same, regardless.
Checking in is slightly more complicated, but only slightly. Here, the Stage 1 revision 2 will be checked in:
<resource>
<!-- Base URN -->
<base>123456</base>
<!-- Stable version 1 -->
<version>
<rev>1</rev>
<url>xmldb:exist:///...</url>
<!-- 1st Stage 1 (decimal) versions -->
<version>
<rev>1</rev>
<url>xmldb:exist:///...</url>
<!-- Stage 2 (centecimal) versions -->
...
</version>
<!-- 2d Stage 1 (decimal) version -->
<version>
<rev>2</rev>
<url>xmldb:exist:///...</url>
</version>
</version>
</resource>A new version, revision 2, is added:
<resource>
<!-- Base URN -->
<base>123456</base>
<!-- Stable version 1 -->
<version>
<rev>1</rev>
<url>xmldb:exist:///...</url>
<!-- 1st Stage 1 (decimal) versions -->
<version>
<rev>1</rev>
<url>xmldb:exist:///...</url>
<!-- Stage 2 (centecimal) versions -->
...
</version>
<!-- 2d Stage 1 (decimal) version -->
<version>
<rev>2</rev>
<url>xmldb:exist:///...</url>
</version>
</version>
<!-- Stable version 2 -->
<version>
<rev>2</rev>
<url>xmldb:exist:///...</url>
</version>
</resource>Both check-out and check-in should be able to use the same basic function for
adding a new version, as long as there is something to check which
operation has been selected so that the new version and the appropriate
rev can be added either up or down in the structure.
Note
If there is no further level down from Stage 2, in this example, there should be a little something to disable the check-out function on that level in the editor.
Locking
The versioning in this paper suggests that resources that are checked in or out from a stage are to be locked in that stage. While this paper does not attempt to solve every problem created by locking, there are a number of points to be made:
-
A lock, here, primarily signifies that the locked resource is being handled in another stage, not that it is checked out exclusively by a writer (who then leaves the company and causes problems for those remaining behind, etc).
-
Allowing a document in the editing stage to be edited by two or more writers simultaneously causes various merging problems, all of which are manageable, but the important question is (and please remember that we are discussing content rather than code): why are they editing the same content in the first place? This, to me, hints at an organisational problem.
-
Not locking a resource that is being handled in another stage is entirely feasible, of course. Easiest would be to implement an
optimistic check-out
, never locking anything but having the system notify the writer if the resource was already being edited by someone, encouraging communication and collaboration.The author's experience, drawn primarily from developing document content rather than code, is that alone, this approach works best within the same time zone, preferably the same building, but is made easier by adding merging tools and means to easily modularising content that is becoming too large to handle.
Business Rules and Linking
As mentioned in section “Using URNs in Links”, while the link implementation might use an exact
URN version in the pointer, business rules used when publishing might be used to
update that link to the latest version within scope. That scope might include
defining a versioning level, but also further limit the use latest
function to URNs listed in projects (see section “Projects”). Let's say
that we created this link:
<link xlink:href="urn:x-resources:r1:123456:en-GB:2:2:4" use-latest="1"/>
At the time the link was created, the very latest available version was
2.2.4
. However, later, when the document with the link is
published, the target resource has gone through a number of revisions and the
version tree now looks like this (leaving out the URLs):
<?xml version="1.0" encoding="UTF-8"?>
<map xmlns="http://www.sgmlguru.org/ns/versions">
<resources>
<resource>
<!-- Base URN -->
<base>123456</base>
<!-- Stable version 1 -->
<version>
<rev>1</rev>
<url lang="en-GB"></url>
<!-- 1st Stage 1 (decimal) version -->
<version>
...
</version>
<!-- 2d Stage 1 (decimal) version -->
<version>
...
</version>
</version>
<!-- Stable version 2 -->
<version>
<rev>2</rev>
<url lang="en-GB"></url>
<!-- Stage 1 (decimal versions) -->
<version>
<rev>1</rev>
<url></url>
<!-- Stage 2 (centecimal) versions -->
...
</version>
<version>
<rev>2</rev>
<url></url>
<!-- Stage 2 (centecimal) versions -->
<version>
<rev>1</rev>
<url></url>
</version>
<version>
<rev>2</rev>
<url></url>
</version>
<version>
<rev>3</rev>
<url></url>
</version>
<!-- Target at the time of link creation -->
<version>
<rev>4</rev>
<url></url>
</version>
<version>
<rev>5</rev>
<url></url>
</version>
</version>
<!-- New decimal version -->
<version>
<rev>3</rev>
<url></url>
<version>
<rev>1</rev>
<url></url>
</version>
<version>
<rev>2</rev>
<url></url>
</version>
<version>
<rev>3</rev>
<url></url>
</version>
</version>
<!-- New decimal version -->
<version>
<rev>4</rev>
<url></url>
</version>
</version>
<!-- New stable version -->
<version>
<rev>3</rev>
<url></url>
<!-- New decimal version from v3 -->
<version>
<rev>1</rev>
<url></url>
</version>
</version>
</resource>
...
</resources>
</map>We can see that two new Stage 1, decimal, versions have been
added to Stable version 2., but also, there is now a
Stable version 3, based on version 2.4. Since version 2.4
is the latest Stage 1 version at the time of publishing and
it's the level defined by use-latest="1" in the link, it is the one
used as a target. Version 3.1 is outside the defined scope.
We could, of course, add a project structure to the version map and further limit the scope. The business rules would state that the link update was only updated if both source and target were part of the same project. Let's say the projects look like this:
<?xml version="1.0" encoding="UTF-8"?>
<map xmlns="http://www.sgmlguru.org/ns/versions">
<resources>
...
</resources>
<projects>
<project>
<urn>123456</urn>
<urn>111111</urn>
<urn>222222</urn>
</project>
<project>
<urn>333333</urn>
<urn>111111</urn>
</project>
</projects>
</map>If the link source document was URN 111111 and the target URN
222222, the use latest
update when publishing would
be allowed. If the target was 333333, however, it wouldn't.
Implementation-wise, both scoping techniques should be easy to handle in XSLT stylesheets used by publishing pipelines.
Permissions
When implementing the more advanced versioning described in section “Multiple Level Versioning”, I think it is a good idea to consider requiring different permissions for check-out and check-in, depending on the versioning level. For example, it might be a good idea to limit check-outs from Stable and Stage 1 to a project management role to further control scoping and reuse, especially when handling larger documentation projects, while allowing authors and project managers alike to check out resources to stages 2 and below.
Handling eXist Versions
eXist stores versioning information in /db/system/versions/db/...,
mirroring the database's collection structure and including diffed resource versions
in the mirrored collections. The diffed XML files use names that include the eXist
revision numbers:
Figure 7: Versions in eXist
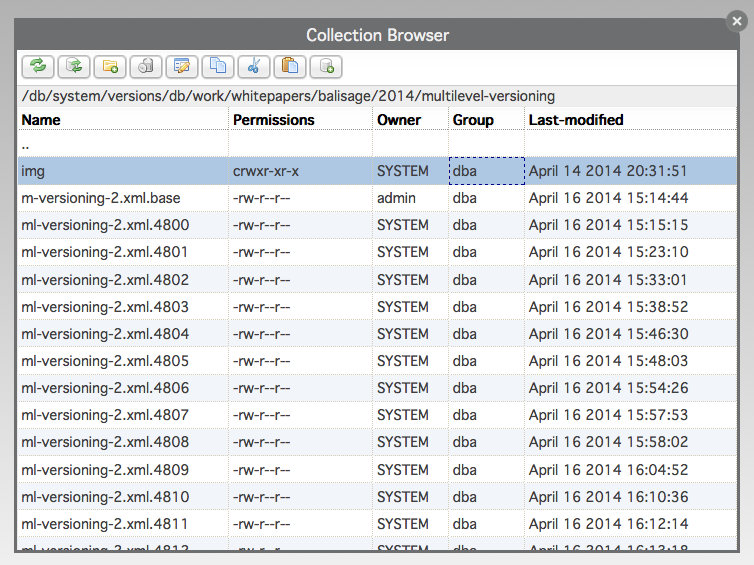
The eXist version-specific metadata is always included, first in the XML diff file (for example, ml-versioning-2.xml.4854), which makes it easy to retrieve when needed:
<v:version xmlns:v="http://exist-db.org/versioning">
<v:properties>
<v:document>ml-versioning-2.xml</v:document>
<v:user>admin</v:user>
<v:date>2014-04-17T09:29:14.085+02:00</v:date>
<v:revision>4854</v:revision>
</v:properties>
...
</v:version>Binary files are also tracked, but accessing them seems to be more difficult as the diffing mechanism (obviously) does not work.
eXist revisions are recorded in the
v:revision element (see above). A specific version can be retrieved
using the v:doc($doc,$rev) XQuery function, so
the
url element in the version mapping markup will need both the base
URL to the resource and the revision of the version to be retrieved:
<url>
<base>xmldb:exist:///db/work/whitepapers/balisage/2014/multilevel-versioning/ml-versioning-2.xml</base>
<rev>4854</rev>
</url>Identifying eXist version 4854 of ml-versioning-2.xml.
Note
The base URL, above, denotes the latest
version of the document rather than eXist's base
version, which
is the first version stored and on which the later versions are based.
A version update must be triggered in eXist whenever copying the file from one
area to another - both check-in and check-out are copy operations. eXist provides
versioning triggers for copy events so capturing the new eXist revision number is
a
matter of inserting the v:history function after the copy:
v:history(doc("/db/path/to/xml"))//v:revision[last()] This returns a v:revision element, with the eXist revision given in
@rev:
<v:revision xmlns:v="http://exist-db.org/versioning" rev="5029">
<v:date>2014-04-18T18:11:19.211+02:00</v:date>
<v:user>admin</v:user>
</v:revision>It is then a simple matter to bump up the URN rev and add the
URL
to the new version in the version map.
The eXist User Interface
At its simplest, the user interface needed in eXist is just what's needed to display the version map in a browser, easily produced with an XSLT stylesheet and some CSS, plus something to trigger the page with.
The map will probably grow to be quite large, so including a filtering mechanism is necessary to show only selected parts of the map (i.e., parts of or the complete version history of a specified resource). Functionality to show various metadata for specified versions, provide links to physical resources, include map icons to indicate the language(s) used, and so on, are other examples of useful additions.
eXist provides several XForms implementations[18], as well as a powerful XQuery (3.0) implementation, to help add these.
The Editor
Here's where I'm currently really out of my depth, as adding check-out and check-in functions to an editor will involve programming. Nevertheless, editor GUI considerations apart, the versioning additions should consist mainly of calling the XQuery doing the copying, including a flag indicating what operation is used, and making the editor aware of what versioning level the resource is at and disabling the check-out operation, if there are no further levels to copy to.
There should also be a permissions check that disables both operations if the author lacks the necessary permissions to run the operation(s).
Also, the editor needs linking functionality using the multilevel versioning abstraction (URNs rather than addresses in links). This entails opening the target so that the user can identify the target (including a node inside the target document); easiest should be to map the target's URN and URL locally rather than accessing the version map XML from the database.
Rather than opening the targets one by one, it might be a good idea to retrieve a URN/URL map for the whole project, if using the project concept (see section “Projects”).
Afterword
The versioning system suggested here came to be partly because I really want a more
advanced version handling for eXist, but mostly because the more primitive
straight
versioning system that introduces this paper was prominently
figured in my paper from last year's Balisage (id-semantic-profiling) and
Eliot Kimber promptly dismissed the problems with updating the document link tree
as the
results of bad configuration management. He was right, too, and I hope this is better.
Thank you, Eliot.
A Few Notes
Disclaimer
I am in no way claiming originality in terms of a versioning scheme that
includes multilevel numbering (1.1.1
, 1.1.2
, etc)
or the idea of different (and arbitrary) levels of versions defining version
significance and version structure. A number of software systems already use
such versioning schemes (for example, see id-windchill-multilevel).
Somewhat original (having not been able to find anything similar) is my
implementation, in the context of an XML database and using an XML-based version
mapping format defining an arbitrary level of versions. In particular, my goal
here was to define a way to add a versioning layer to an existing,
straight
, versioning system, one that differentiates between
significant versions and simple saves
by providing multiple
levels of check-outs and check-ins while leaving the definition of the
significance of each level to the end user.
git and Other VCSs
The version mapping document is, of course, by no means unique as a concept. As a reviewer pointed out, part of it is equivalent with the git index file (see id-git-index-format). After all, a lot if it is simply about mapping the names of resources and their versions to URIs. It is XML because XML is easy to handle in eXist, however, and there is a recursive hierarchy because such hierarchies (in my mind) neatly represent the relations between any number of versioning levels, which is not the case with a git index[19].
The point is that it should be straight-forward in eXist to implement the versioning represented by the XML. I'm sure it is possible to implement multilevel versioning in eXist based on git or some other VCS[20], with whatever advantages that they might bring to the table, but the point with this one is to do it in XML with a minimum of non-XML involvement[21].
I also realise that git (and other) VCSs have variants of the use latest problem, as pointed out by that same reviewer. While the problem here is similar, it is not the same. As a technical writer with some insight into developing code, I am struck by some subtle differences:
First of all, in theory at least, it should be possible to avoid using an incompatible later version of a piece of code by writing automated tests. This is not possible in the use latest problem as described here. An incompatible change is only possible to detect by an author who can manually spot the differences, provided that s/he has sufficient knowledge in the subject of both the old version [of whatever that is being described] and any forks that happened along the way.
The scoping as provided by the stages, then, are simply an agreed-upon, but untestable, convention.
Second, while there are similarities between versioned code and versioned content, a major difference is that the documents as described here effectively need to include links addressing arbitrary versions of other resources in the VCS. As far as I understand git, a check-in in git represents a snapshot where any such links will point to a current file in that snapshot, not an historic one.
Notations for Related Content
Regarding the notion of translations as renderings of an original, a reviewer kindly linked to the Akoma Ntoso XML vocabulary for legal documents, specifically its URI namespace conventions for handling related content (see id-akomantoso).
Using URN abstractions (see section “Version Abstraction” and section “Adding to the Abstraction”) provides me with a useful way to describe the relationships I had in mind, namely versions of original-language resources and their translations, and how they relate to each other. Akoma Ntoso provides a fascinating and complex alternative, going well beyond my relatively uncomplicated naming conventions. I mention them here for comparison, but do not intend to implement them as naming conventions.
There are, of course, many other naming conventions in use for XML document management. Worth mentioning is the S1000D standard's Data Module Code, used to identify reusable content in an S1000D system. It is of particular interest because it provides a physical location of the component being described, in addition to mere document handling formalia.
My point here is that both of these conventions, as well as many others, are feasible, but none, including my simple URN scheme, is necessarily more right than the other. The idea here is to provide a suitable identifier that includes a version and localisation information, used when uniquely identifying resources.
Terminology
The terms stage
and staging
are, perhaps,
unfortunate, as they are in no way unique to what I propose in this paper. Git,
for example, uses the term staging area
, which may cause some
confusion (for more, see id-git-staging and id-git-index).
The git staging area, however, is an indexing area for a commit to which you
can add the files you wish to commit in any way you want to, before they are
committed, while every stage discussed here, regardless of
level, is intended to be a recorded next step after a
commit. The point here is to enable any number of levels of usable versions;
git's staging area should not be regarded as a recorded level
other than in terms of determining versioned content.
Future Work
There are several things I want to do with all this:
-
Doing a basic eXist implementation of the version handling itself is rather obvious, of course. I don't know if it is a case of chronic naïvety or something else, but I think it really shouldn't be all that hard to do in XQuery and an XSLT stylesheet or two. I'm not entirely sure of the parts that involve addressing eXist versions, but I remain hopeful.
-
Handling the first save and subsequent first check-in. A new document should start in the
save
stage and be checked in to the next stage and finally the first stable stage[22]. -
I want to test Extended XLink for the version map and project markup, because I think it would be a good fit.
-
Also, I think doing a basic Extended XLink implementation for linking inside eXist would be both interesting and fun, as well as make it easier to use standard markup languages such as DocBook or DITA in such an implementation, without changing either of them but helping implement the version handling that is the topic of this paper.
References
[id-existdb-versioning] "eXist Versioning Extensions". Part of the eXist DB documentation. http://www.exist-db.org/exist/apps/doc/versioning.xml
[id-db-triggers] "Configuring Database Triggers". Part of the eXist DB documentation. http://exist-db.org/exist/apps/doc/triggers.xml
[id-xlink-spec] XML Linking Language (XLink) Version 1.1
,
editors Steve DeRose, Eve Maler, David Orchard and Norman Walsh. http://www.w3.org/TR/xlink11/
[id-semantic-profiling] Nordström, Ari. Semantic Profiling Using
Indirection
. Presented at Balisage: The Markup Conference 2013, Montréal,
Canada, August 6 - 9, 2013. In Proceedings of Balisage: The Markup Conference 2013.
Balisage Series on Markup Technologies, vol. 10 (2013).
doi:https://doi.org/10.4242/BalisageVol10.Nordstrom01. http://www.balisage.net/Proceedings/vol10/html/Nordstrom01/BalisageVol10-Nordstrom01.html
[id-git-index-format] The Git Index
. http://schacon.github.io/gitbook/7_the_git_index.html
[id-windchill-multilevel] PTC Windchill Multi-Level Versioning
Labels
. https://firstrobotics.ptc.com/Windchill-WHC/index.jspx?id=ViewVersionConvertUtilAbout&action=show
[id-git-staging] The Staging Area
(a git
ready
blog post on January 9 2009. http://gitready.com/beginner/2009/01/18/the-staging-area.html
[id-git-index] What’s The Deal With The Git Index?
http://www.gitguys.com/topics/whats-the-deal-with-the-git-index/
[id-akomantoso] The Akoma Ntoso Naming Convention
. http://www.akomantoso.org/release-notes/akoma-ntoso-3.0-schema/naming-conventions-1
[1] Using a check-out/check-in procedure that bumps up the version with every check-in.
[2] A nicer way of grouping together those of us who think Java
is really a drink.
[3] His comment was given at Balisage 2013, in response to a description of the problems involved in updating a document link tree such as the one in Figure 1. It's an insightful comment, and one that directly caused this paper to come into being. Incidentally, the paper presented, Semantic Profiling (id-semantic-profiling), also used URNs.
[4] Collections, in eXist.
[5] Both are integers from 1
and up.
[6] Plus a position for the hyphen.
[7] Leaving, for the moment, out the lang attribute and element
content examples.
[8] This is a common occurrence in traditional, desktop-based authoring. Without systems support, a few translations and new versions of the documentation are enough for the writers to lose track of which version that contains the latest information.
[9] The problem is that every new version in Stage 1 is basically the same; they are all the result of a save.
[10] Finished and approved, that is.
[11] For example, a free-text comment.
[12] Where the latest (approved) version of a leaf node in a document link tree is always preferred and should therefore always be linked to, but where the module doing the linking may have been updated elsewhere, with incompatible changes, and therefore not be possible to update with a new link for the document at hand.
[13] As mentioned earlier, one (non-) solution is to update the link anyway and create a new (stable) version. This will pass on the problem to someone else and eventually come back to bite you, but nevertheless, you might be tempted to refine it by using merge software and such. Basically, however, it would always result in a situation where a new version could not be assumed to be a development of the last one, but rather an incompatible change.
[14] I've considered renaming the Stable level Stage 0, for this reason and others.
[15] And the language/country components.
[16] Java would probably be especially helpful when constructing suitable versioning triggers in eXist.
[17] For example, checked-out files might simply be have their group changed to a checked-out group.
[18] XSLTForms and Better Forms are both configured and ready for use, and Orbeon is easy to add.
[19] The git index file is used when staging resources to be committed, creating a single tree object to be stored in the database.
[20] There is, for example, a Subversion module for eXist.
[21] The reasons for which are that a) I am a poor programmer, and b) eXist is an XML database and well suited for that approach.
[22] If that version is 0
or 1
is probably
a matter of agreed-upon conventions.