Piez, Wendell. “Hierarchies within range space: From LMNL to OHCO.” Presented at Balisage: The Markup Conference 2014, Washington, DC, August 5 - 8, 2014. In Proceedings of Balisage: The Markup Conference 2014. Balisage Series on Markup Technologies, vol. 13 (2014). https://doi.org/10.4242/BalisageVol13.Piez01.
Balisage: The Markup Conference 2014 August 5 - 8, 2014
Balisage Paper: Hierarchies within range space
From LMNL to OHCO
Wendell Piez
Wendell Piez is an independent consultant specializing in XML and XSLT, based in
Rockville MD.
LMNL provides a markup syntax for annotating arbitrary ranges, irrespective of
hierarchical relations, in text. A LMNL processor can parse this syntax (or any other
syntax,
if mapped) into a generalized data model, which can be queried and processed. Among
the
applications that LMNL supports readily is the creation of visual "sketches" of the
markup
on a document, e.g. using SVG. Such sketches can discover and depict any range relations
of
interest. It turns out the overlap is often less interesting than the hierarchies.
Examining texts showing overlapping hierarchies (MCH or multiple concurrent hierarchies)
suggests some interesting things about the evolution, purposes and uses of the OHCO
(ordered
hierarchy of content objects) as a concept applied to "documents" or literary artifacts
in
general— and by implication of any hierarchical data model such as XML.
As attendees of prior conferences in this series know, since 2002 I have been
experimenting with an unorthodox approach to document markup, LMNL (the Layered Markup
and
Annotation Language), conceived by Jeni Tennison and myself with significant contributions
and
support by others. LMNL is similar to XML in its conceptual architecture, distinguishing
between a markup syntax and a data model capturing an abstraction of text as it
is described by the syntax. Unlike XML, however, the LMNL data model represents arbitrary
ranges over text; in particular, ranges that have any or no hierarchical relation
to one
another are as easily handled as those that fall into the familiar nested element
structure of
XML documents.
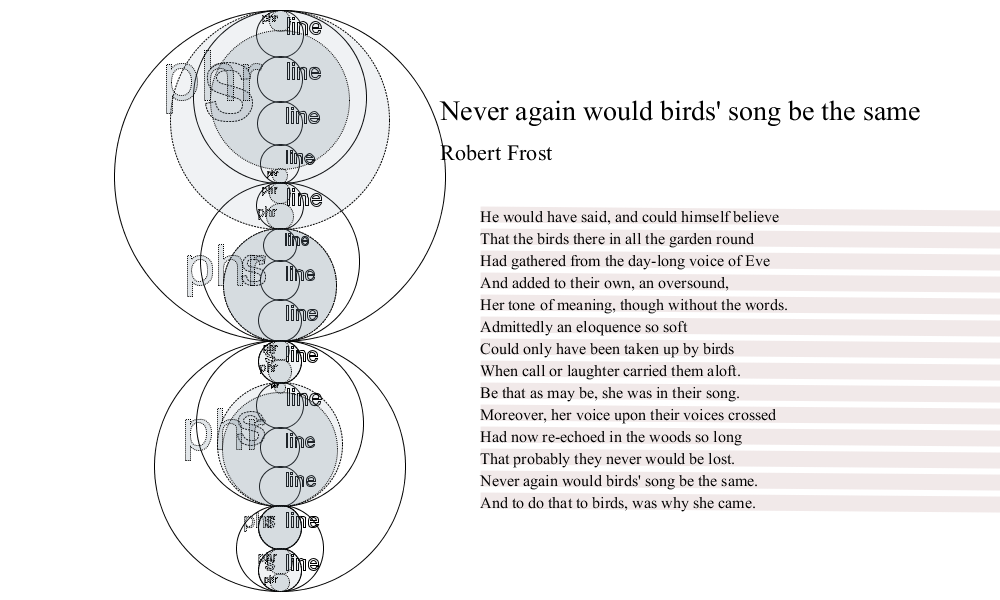
A simple example (five lines of a poem by Robert Frost) illustrates the syntax
Note
One reviewer recalls correctly that LMNL is defined as a data model, capable of
various syntactic representations. This is correct, but LMNL also has something we
called
LMNL syntax, defined separately from the model and implementable in its
own right (inasmuch as it was a text-based format). Not everyone who built a LMNL
application has had occasion to use the syntax much; but my experiments with Luminescent
(Piez 2012) show it is feasible in principle.
For those who wish for more formal references, I offer (with apologies) several
antiquated documents archived at http://www.lmnl-markup.org.
in its bare
form:
[sonnet}[octave}[s}[quatrain}[line}[phr}He would have said,{phr] [phr}and could himself believe{line]
[line}That the birds there in all the garden round{line]
[line}Had gathered from the day-long voice of Eve{line]
[line}And added to their own,{phr] [phr}an oversound,{phr]{line]{quatrain]
[quatrain}[line}[phr}Her tone of meaning,{phr] [phr}though without the words.{phr]{line]{s]
...{quatrain]...{octave]...{sonnet]
Interestingly, an approach to markup that permits arbitrary overlap, as does LMNL,
turns
out to be highly convenient for marking up multiple concurrent hierarchies (MCH),
albeit with
no built-in "awareness" of them in the model. (These hierarchies, that is, are entirely
implicit in the data model until they are resolved and processed as hierarchies by
a
processor.) So, in the example just given, two concurrent hierarchies may be discerned
in the
poem. One hierarchy constitutes the formal structure of the sonnet as an example of
English
verse, in which (as represented here) lines are combined into couplets, tercets, quatrains,
sestets, octaves—some of which may contain other such structures. (So an octave of
eight lines
may decompose into two quatrains of four lines each.) The other constitutes the structure
of
grammar and rhetoric (argument): phrases are joined to constitute sentences. Because
sentences
and indeed phrases may overlap verse structures, these two hierarchies do not align
at every
point. Yet they can nevertheless be discerned, separately or together, within the
range
space of the text.
MCH is readily visualized in a toolset able to process LMNL markup, build a range
model
from it, and generate an SVG diagram showing the ranges, as illustrated for this poem
in Figure 1. Such a toolset was demonstrated at Balisage 2012 (Piez 2012).
Note
In case you are wondering, no claim is made that anything can be done here that cannot
be done in XML without LMNL. LMNL just makes it really really easy because we don't
have
to support XML-based workarounds for dealing with ranges, multiple hierarchies or
overlap.
In XML, we are faced with an XML (engineering) task even before we can get on with
the
markup task.
Figure 1: A sonnet by Robert Frost
Of particular interest here is the overlap between ranges marked s and
phr (marking sentences and phrases) and ranges indicating the formal
structure of the first (line, quatrain etc.) Indicating how some
lines are end-stopped, while others enjamb (phrases break across them), these incidences
of
overlap between the two hierarchies—which are largely, but not entirely congruent—reveal
the
movement of the poem's language across its formal foundation.
The reign of the OHCO
The acronym OHCO, for Ordered Hierarchy of Content Objects, was coined in 1990 to
describe
a tree-shaped data model for texts, or documents (we set aside an examination
of what these terms should mean here), in a seminal discussion of text encoding presented
by
Allen Renear and colleagues at Brown University (Renear et al., 1990). The argument
presented in that paper makes two claims: first, that a hierarchical model is superior
to
alternatives then prevalent for purposes of electronic document production and application,
supporting necessary operations that are not so easily addressed by other data models
then prevalent;
Note
Certainly this point of view has been vindicated; if we do not today speak much of
OHCOs, in our DOMs, trees, and directed acyclic graphs, we have infrastructures for
OHCO
under other names.
and second, that this superiority is not merely pragmatic (an aspect of design and
functionality), but due to the fact that such a model accurately reflects what a document
actually is (as an abstraction, in the instance, or by
definition). In the years since this argument was first made, its authors qualified
and
prevaricated to a degree (see, for example, Renear et al., 1993[1]) in an effort to meet objections on several levels; but Renear, at least, has
never given up the core metaphysical claim (for example, see Renear 2004).
Nor has he really had to, because, despite many objections, the first argument made
by that
paper has clearly carried the day (at least on the web), as SGML, XML, the HTML DOM
and
numerous other technologies have all verified the usefulness and power of the recursive,
tree-shaped model.
The OHCO thesis attributes three fundamental properties to texts, interdependent but
distinct. First, a text is a hierarchy (the H in OHCO). Secondly, it is ordered (the
O): we
cannot simply take the constituent parts of a text (such as the lines in a sonnet
by Robert
Frost) and treat them as unordered, or re-order them, without altering (and thereby
in some
sense destroying) the text they make up together. Third (the CO), that these constituent
parts
all have thingness: they too may be complex (ordered hierarchies of smaller
objects); and in any case they have distinct properties or sets of properties—we might
say
they are typed. So, although a system is not free to rearrange the objects that
constitute a text, when it comes to objects of a given type (such as paragraphs, list
items,
or lists containing list items), we can treat them all alike. They are interchangeable,
if not
quite in the sense that one can be substituted for another, then at least insofar
as they
share essential properties that makes it both possible and correct to unify their
handling in
a system. This promises a satisfying power of generalization, since by this account,
all
sonnets can be handled alike, as can all their lines. Where there are exceptions to
this, the
system can and must account for them by subtyping or otherwise qualifying the types
(so in XML
we may assign attributes to elements to drive special handling) or by resolving differences
based on their ordered, hierarchical relations (their context). Thus, if some
lines in a poem appear with extra vertical white space on the page, this is not because
they
are different, as lines, from others, but because the poem as a whole (or perhaps
a
constituent stanza object) is displayed with extra spacing that belongs
properly to it, not to its pieces.
Note that from the point of view of today's technologies, this powerful and elegant
account of text as system and organization provides a rationale and justification for two things we have
learned (since the thesis was proposed in 1990) to separate. On the one hand, in data
models
for XML, we have the ordered hierarchy. On the other, in the idea of a regulation
and indeed a
grammar of element types, we have a rationale for schemas. XML's parent standard,
SGML,
assumed that both were necessary together (in fact in SGML, the document's hierarchical
form
is arguably a side effect of the fact that it is specified with a grammar of element
types).
XML disentangles this dependency—its more consistent syntax maps to a hierarchy irrespective
of element types and prescribed relations—and in doing so, acquires much greater flexibility
in application. (This is not to say that XML is more expressive or capable of any
application
than SGML; only that because the XML parse can happen without reference to any schema
or
element specification, XML tools become more lightweight, easier to use and easier
to build
with than SGML tools.) Defining exactly what our content objects are and how they
are to be
treated may now be performed late, forgoing processes such as validation or data binding
until
they are known to be useful. Yet irrespective of the semantics of particular element
types, an
XML parser knows about elements and attributes, and can always present the hierarchy
of
elements for processing. So the tree remains: always there, always dependable, always
addressable and processable using generic technologies designed for the purpose, such
as
XPath, XSLT and XQuery.
All of this was a very positive development for developers of publishing systems or
data
processing systems in general—and so, indirectly, for users and communities. Yet at
the same
time, handling overlap in its various forms has remained a complication (at
worst, a prohibitive one) for many applications of XML, especially applications whose
purpose
is not simply to create and process new texts or new versions of old texts (for example,
in
publishing activities), but to represent texts for scholarly or research purposes,
as they are
found, in all their complexity and nuance. The retrospective
encoding of texts (see Piez 2001) would offer encodings of documents that
trace what we see in them, irrespective of any prior commitments to how these texts
are (or
should be) defined and constituted as texts—the model of the text has the form of a
tree being such a prior commitment.
This hasn't stopped us from trying. To represent multiple concurrent hierarchies (MCH)
in
XML, or anything that doesn't fit into the hierarchy, we resort to one of several
well-understood and well-documented workarounds: milestone markers, chained
segments, standoff markup or what have you (see Barnard et al. 1995, TEI, chapter 20). These work by specifying handling for particular elements or
attributes, in order to represent, indirectly, things (not yet content objects)
that cut across the hierarchy. But this necessitates control of these elements'
properties—identifiers and pointers to them—which indeed entails prior commitments
to element
semantics, as well as cumbersome and opaque methods of processing that are able to
resolve
these relations according to the kind of representation intended. This inevitably
means we do
not benefit much from schema-free processing, and face significant tagging and validation
overhead just to represent the phenomena we seek to understand.
Thus a paradoxical consequence of XML's so-called overlap problem is that
it presents scholars and researchers with a special challenge precisely as we seek
to study
the place, nature and historical development of hierarchies in text. We who are most
fascinated by the OHCO thesis, and wish most to scrutinize the nature of hierarchies
in texts,
are the most hampered by a data model that imposes a single hierarchy, because we
have
questions not readily addressed when it must be assumed. Because document hierarchies
provide
XML tools with their frames of reference (literally), it is difficult to consider
the
hierarchy of a text, while using XML, as anything but given: using XML to consider
how the
OHCO thesis applies to text is like looking at a rose garden through rose-colored
glasses.
(The world may look nice, but we can only smell, not see, the roses.)
In particular, it becomes difficult to ask questions, using XML encoding, about texts
whose hierarchies that are not perfectly regular, or about the relation of multiple
hierarchies (views according to Renear et al., 1993) that appear
together. Are their relations incidental, or systematic and significant? What accounts
for the
structural regularity of texts? Does a single account serve for all texts, or do various
kinds, genres, or formats of text show different aspects (features, hierarchies) that
suggest
or demand different explanations? Accepting Renear's argument that the OHCO is a real
thing, where does it come from and how did it come about? Are texts produced before
the electronic age, as Renear and his colleagues argued, also always ordered hierarchies,
and
do they always have content objects? If so, of what nature are these? With their tree-shaped
document models, do XML and HTML represent a radical break from prior forms of text,
or are
they a continuity? And if they are a continuity, what do they continue?
One of the most fascinating things about this inquiry is that it is greatly facilitated
by
a technology, such as LMNL, that allows us to mark up and process text without imposing
hierarchy at all. Where we can have any hierarchy or none, hierarchy itself is immediately
open for study.
Ironies of alignment
As illustrated above, it is perfectly possible to discern more than one hierarchy
in, say,
an example of poetry, where we have both formal organization (stanza and line) and
grammatical
structure (sentences and phrases) together. By definition, by distinguishing more
than one
hierarchy, we admit the potential for them to conflict or overlap. (If they were never
in
conflict, then we should be able to accommodate them together within a single hierarchy.)
And
indeed examples of poetry are not hard to find in which there is not perfect alignment
between
these hierarchies.
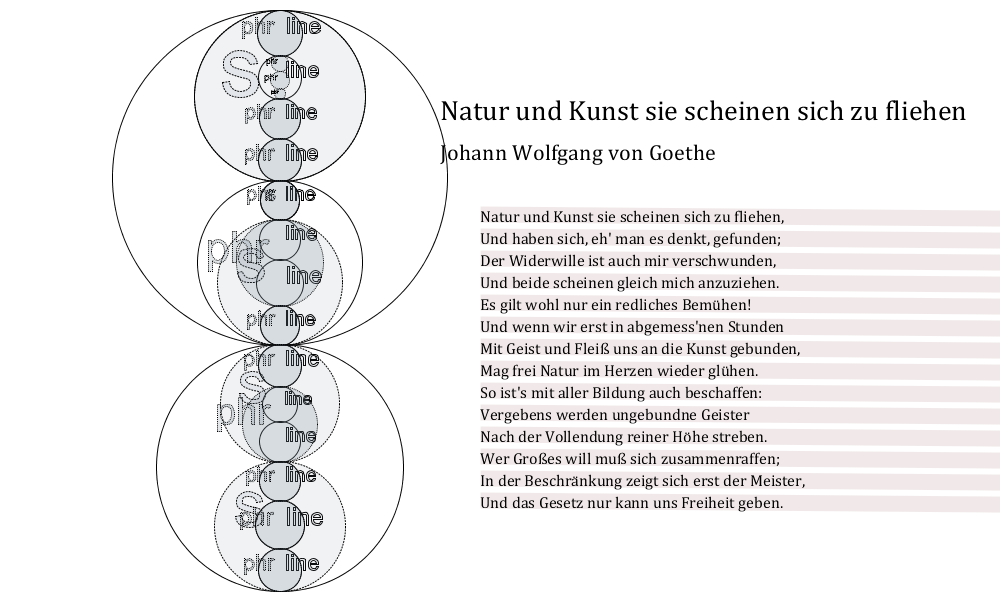
Figure 2: Natur und Kunst sie scheinen sich zu fliehen, by J. W. Goethe (ca.
1800)
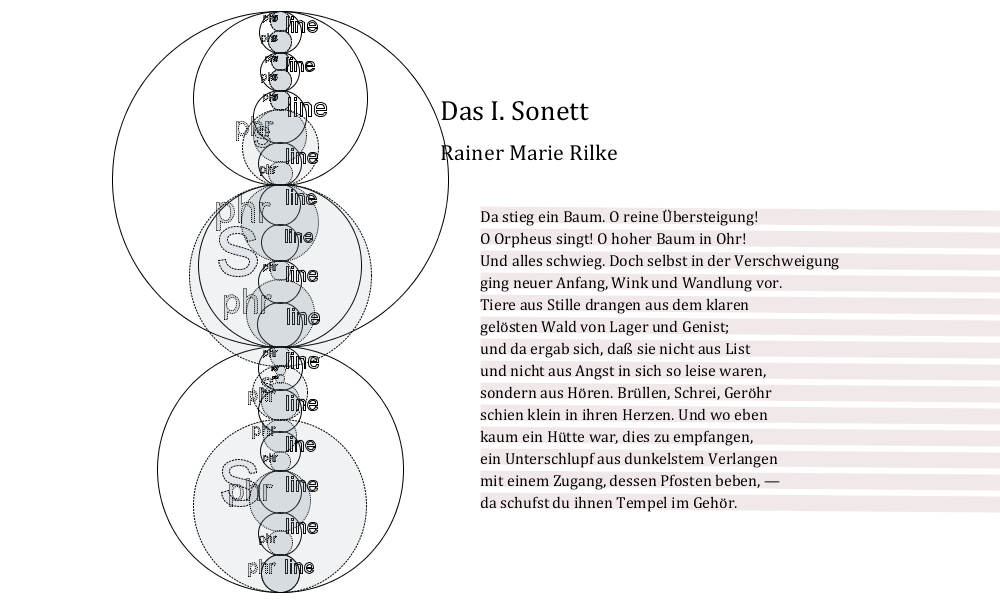
Figure 3: Sonnet I, from Sonnets to Orpheus, by R. M. Rilke
(1922)
Consider two more sonnets: Goethe's Natur and Kunst sie scheinen sich zu
fliehen (ca. 1800; shown in Figure 2), and Rilke's Sonett I
from Sonnets to Orpheus (1922, Figure 3).
The notworthy thing about these examples in this context is the contrast between them.
The
earlier, more classical example shows a perfect alignment between meter and
grammatical structure (one does not need to be a reader of German to see this); the
latter
poem, anything but.
In each poem, the degree of alignment between these two hierarchies is significant,
and
thematic. Indeed, in each poem, this aspect (especially when we take grammatical structure
as
a proxy for phrasing when read aloud) is integral to the sense of the poem itself,
reflecting
and reinforcing its denotation. Both these sonnets, like many sonnets, are about sonnets.
Goethe's is a reflection on the art of crafting verse, among other arts, while in
Rilke's,
both the tree of the first line, and the temple it has become in the last, represent
the
singing of Orpheus and thus poetry itself. Goethe's poem might be described as
rectilinear and balanced throughout, while Rilke's shows a kind of eddying
movement that enacts a transition (weaves a spell, we might say) like the one it describes.
In
other words, we have here a kind of signification: in both cases, whether, how much
and where
the sentence structure aligns with the verse, and where it fails to, is part of the
poetry
itself. It says something. Nor are these two examples at all unusual in this, as a
consideration of a broader selection can show.
We might generalize from this to consider what happens when multiple concurrent
hierarchies align, or fail to. I believe the proper term for the latter situation—where
two
simultaneous arrangements might coincide, but do not—is irony. Of course, irony designates a rhetorical trope (a figure of
speech or signification) in which the meaning being overtly represented is not the
same as the
meaning being communicated.
Note
One reviewer asked whether this definition of irony wasn’t too
broad (so weak as not to disinguish irony from other tropes), and I admit that for
me
almost any trope has ironic potential or capability. But I would contrast irony with
metaphor (for example) in indicating how irony works by a deliberate failure of alignment, whereas metaphor works through the alignment itself.
In any case, these are excellent questions.
More generally, it is a signal, by means of a kind of misalignment or variance from
expectation, that a meaning should not be taken (at least by a knowing audience) at
face
value; the representation must not only be looked at, but also looked
through, with the understanding that what is seen at the different levels may
not correspond (and that this failure to correspond can itself tell us something).
By this
account, Goethe is not being ironic in his assertion that only law can give us
freedom, and he demonstrates the principle he enunciates.
Note
At least one reviewer appeared to be under a misconception that I am disparaging what
is not ironic in favor of the ironic, that Goethe’s work somehow suffers in comparison
to
Rilke's. Nothing could be further from the truth, and to say Goethe’s sonnet is not
ironic
(at least with respect to this particular kind of internal structural alignment between
sound and form) is not to say that it is not self-conscious (as it certainly is) in
other
ways, for example metaphorically or metonymically. Indeed it might be said that Goethe’s
synecdoche here (synecdoche being the part for
whole trope) is deliberately and consciously not ironic—and that Rilke’s irony would have been impossible without
it.
But Rilke's verse is ironic: this poem also follows all applicable rules of
versification, while at the same time it threatens (or pretends to threaten) to transgress
the
sonnet's strict boundaries in its act of creation. The poem speaks with two voices
at once, in
tension until its end, exuberantly about to burst out of itself at any moment. As
readers, we
are invited to notice this.
Figure 4: A set of sonnets
I believe that instances like this have much to teach us about the way texts communicate
and indeed about the ways in which literary and documentary forms of text serve their
purposes. Even to characterize it this way gives us an opportunity to see an important
distinction, if we can generalize to say that literary texts are characterized
by the capacity for this kind of irony (an irony that may confirm or deepen evident
senses
even while it may superficially undermine them), while documentary may describe
that class of texts in which this kind of variance does not happen or is not supposed
to. (We
do not want aircraft maintenance manuals, scientific reports, or maybe even conference
papers
to present such problems for their readers. This is to say nothing in disparagement
of texts
that show little or no ironic transgression of their own forms: they have their own
strengths
and virtues.) If so, this might help explain why an OHCO model is so well suited for
so much
work in publishing and data processing (in which such misalignments within organizations
of
text must be erased or elided lest their complications destabilize regular operations),
especially for born-digital materials (which can be made to conform to these
constraints in their creation)—while at the same time, a model that imposes a single
hierarchy
can be so frustratingly inept for other purposes, even including the study and representation
of (something called) text.
What is text, really?
Other examples of overlap in literary texts give rise to similar questions, while
continuing to suggest that such ironies and misalignments are not always bugs, but
features,
indeed essential ones. Of particular interest to students of literature, for example,
are the
structures of formal narrative. Necessarily, as soon as these conflict with logical
and
presentational arrangements (such as chapters and paragraphs, which may normally fail
to align
with narrative and dialogue), a model such as XML's, which reflects a simple OHCO,
forces us
to foreground one or the other hierarchy, while likewise inhibiting our ability to
see how
they work together despite (and because of) their tensions, because whichever hierarchy
we
push into the background is not easily or immediately recognizable as a hierarchy.
One vivid example of such a text is Mary Shelley's novel of 1818, Frankenstein, or, the Modern Prometheus (revised 1831). A canonical example of
the Gothic genre, it shows a set of anomalies that are both interestingly illustrative
for
this text, and yet also suggestive of issues for any such text.
We will follow the lead of the 1993 revised statement regarding OHCO (Renear et al., 1993) in suggesting that any adequate accounting for what the text
is must correspond at least generally with our intuitions. A very simple
intuition is that a text (at any rate, a text of the nineteenth century) is going
to be a
sequence of printed (or manuscript) pages; and indeed, one of the first things we
find we can
do using LMNL is mark, as ranges named page, the extents of pages of the novel in
whatever edition(s) we choose (in this case, the revised edition of 1831, which is
the version
known to most readers), and not only (as is more usual in XML) their starting points.
The fact
that pages may overlap with paragraphs and chapters is not a problem when using a
markup
regime that imposes no containment. And if such a concept of text is evidently too
unsophisticated to take us far, that's okay too: since the markup technology permits
it, we
can proceed to mark the pages as ranges (not only insert markers for the page breaks)
If the
page hierarchy is interesting (as it may be to students of printed media and their
history),
that is enough. Or even only useful, because it allows us readily to retrieve pages
in the
edition (see Appendix C). In any case, marking up pages in addition
to anything else is easy and straightforward, without concern for whether hierarchies
will
inhibit the markup of other features we expect to see on a closer look. We don't have
to
invent, then test and enforce, any special schemes or implicit processing logic to
accomplish
this, resolving the actual pages, with their content, and not just breaks
between them.
Of course the ordered hierarchy we will usually prefer will be that of of chapters
and
paragraphs. Yet in this novel, these are not quite adequate for a comprehensive account.
Not
only are there an Introduction and a Preface (assuming we consider them to be part
of
the text, we can think of them to be specialized chapters if we like), but
also, we find the chapters of the novel do not account for its entirety. (See Figure 5). Before the chapters begin we are presented with a framing
narrative, consisting of letters, one of which (the last) contains several entries,
in the
midst of one of which, the sequence of chapters begins. So the logical view is
deeper than most modern novels, having an epistolary form wrapped around the primary
narrative—the sort of complication that is not unusual in the Gothic genre. A
map of the novel showing all this structure is presented in Figure 6.
Note
In RNC notation
novel = element novel {
element letter {
element entry {
( content |
transcription )+
}
}
}
transcription = chapter+
chapter = element chapter { content }
content = ( element p { text }+ )
Shelley's Frankenstein does not, quite, fit this model (due to overlap), unless we are willing to make a
significant editorial adjustment.
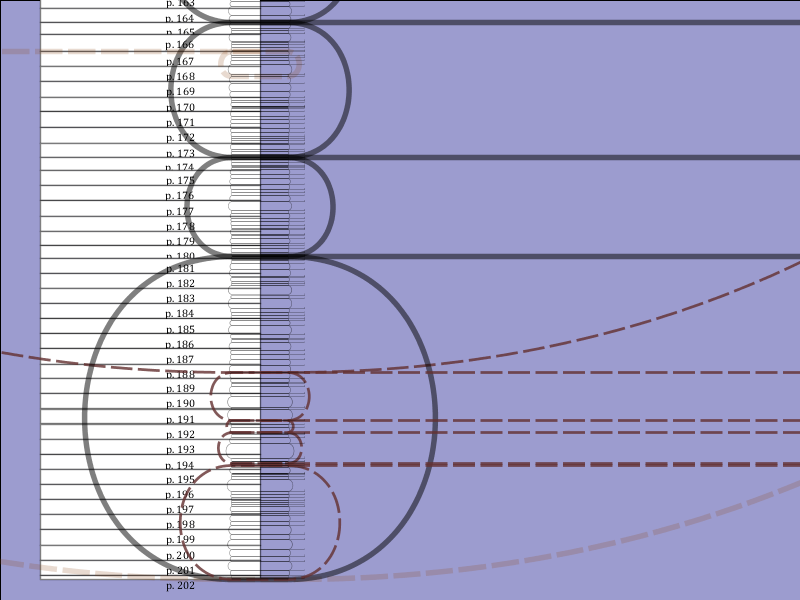
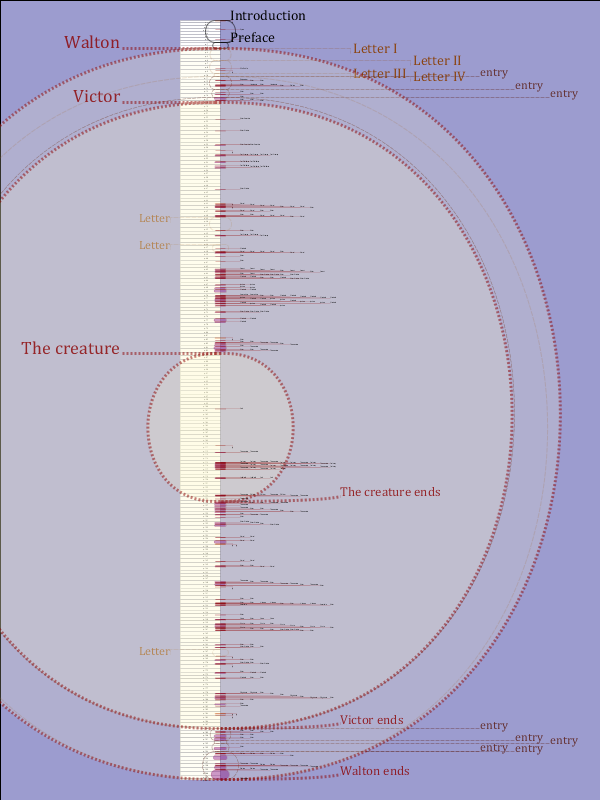
Figure 5: Chapter and page hierarchies overlapping (with a gap)
Since the chapters of the book begin only on page 18, there is a gap that must be
accounted for. The contents of the gap constitute the framing narrative, which resumes
again at the end of the book (not shown in this closeup).
Figure 6: A more complete map, showing chapters inside Letter IV
A more complete accounting for the content objects of the novel shows
four letters, one of which (Letter IV) contains several entries, in the midst of which
the sequence of chapters begins. Letters also appear embedded in the chapters.
There is, however, another problem. Chapter 24 (the last) starts inside one entry
(dated
August 19) in the last of four letters, but it continues on after this entry ends,
to include
four more (dated August 26 and September 2, 5, 7 and 12). In other words, there is
apparently
an overlap between the hierarchy of chapters, and the hierarchy of letters containing
entries.
This is not a well ordered hierarchy. (See Figure 7 for a closeup
view)
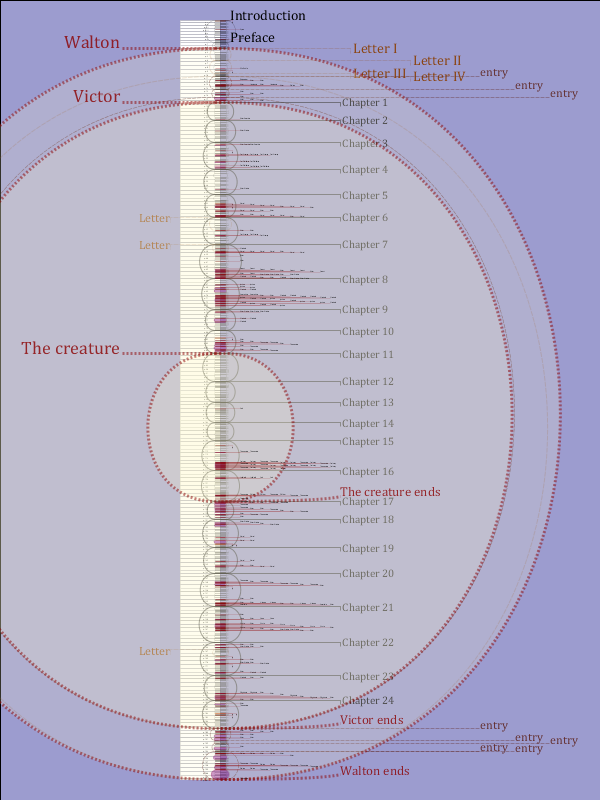
Figure 7: Overlap in Chapter 24
This closeup of the map of the novel shows where Chapter 24 overlaps with the framing
structures (the four letters from the main narrator, Walton, to his sister) and the
entries in Letter IV.
Yet there is another accounting for this problem. Maybe this overlap is only apparent,
if
the chapter hierarchy is not the real hierarchy of the book, but merely
overlaid on top it, like the pages. Maybe the chapter hierarchy and the hierarchy
of letters
and their entries are in fact two different views. Indeed there is another set of
ranges we
might think about, namely the narrative structure as such. The story appears within
a story,
and within the main story are subordinate narratives: three letters and a long narration
by
Frankenstein's creature himself. This hierarchy can be traced, tagged and mapped as
well. In
fact it should include also direct discourse (that is, spans of dialogue) and other
attributions and sources, which may overlap and conflict with both paragraph and page
boundaries. A map of the novel showing this hierarchy is shown in Figure 8
Figure 8: The narrative structure of the novel
In this variant, chapters are not shown, and we see only the narrative structure of
nested stories (letters, stories, dialogue) that constitutes the
substance of the book. Direct discourse is noted. Of course, this
hierarchy still overlaps with the page sequence.
Mapping out narrative boundaries has always been one of the challenges of OHCO-based
models, if not because narrative fails at being well structured (typically it does
not), then
because they so often conflict with the logical structures of paragraphs and
sections or chapters—the published view. As long as the range space was
occupied by one and one hierarchy only (that is, as long as the data model recognized
only a
single hierarchy), and as long as the (so-called) logical hierarchy of the published
view was
given pride of place, it has been more or less prohibitively difficult to use XML
to mark up
any hierarchy (or indeed any phenomena at all) that overlapped chapters and paragraphs.
Paradoxically, the ideology that descriptive markup should serve multiple
purposes, and not be limited to presentation (see Coombs et al. 1987, Renear 2004), may have hindered this also, since there is at least a presumption
that one should be able to mark up paragraphs and chapters, and yet also mark up everything
else one might wish to describe. (Because text, by definition, is an OHCO, there will
ipso facto never be a conflict between the so-called
logical structure and anything else that is really there.) In
other words, the XML data model interferes with the realization of a regime of descriptive
markup that is fully adequate to the principle's potential. The range model offered
by LMNL
presents no such difficulties: using LMNL syntax, marking these hierarchies together
is only
as difficult as marking each separately.
Yet at the same time, there does seem to be a stress between these hierarchies that
we do
not feel, for example, from the misalignment of either of them with the pagination.
We do not
expect pagination to align with anything, regarding it as an incidental consequence
of
typesetting, not a reflection of the text. Accordingly, we are tempted to set
aside the pagination structure as merely incidental to anything else (at least until
it turns
out there is some sort of echoing or consonance). Yet between the narrative and the
published
view (the chapters and paragraphs)—most particularly, since the published view must
include
(for this novel) the letters and entries that wrap the chapter sequence (except
where they don't)—the reader faces a similar kind of phenomenogical stress as we have
observed
in poetry. Is there an irony here, serving any sort of purpose (or creating any sort
of
effect) like the effect of sentences and phrases in poetry pushing and pulling against
verse
lines? Apparently there is, if we consider how our attention hardly shifts, as readers,
across
the boundary in Chapter 24, back out to the framing narrative in which it is embedded,
like
waking up from a nightmare—only to discover it is not a dream, when the monstrous
creature at
the center of the tale next appears on the scene, no longer only hearsay, but breathing,
speaking, imprecating. (Or so the story says.)
Thus we are brought back to the text. (Really.) Examining the boundaries between chapters
(the published view) and the entries in the letters that contain them shows us how
we get into
this trouble in the first place—because the rendering of these transitions in this
edition (as
seen in Figure 9) leaves it somewhat doubtful that the reader will easily
construe exactly how things are set up—at least as long as she or he is shaking herself
awake.
Indeed, we are inclined to ask, shouldn't Chapter 24 really end on page 188, with
Walton, in continuation? The reader must be the judge. Interestingly, to the
extent I have been able to determine the question by looking at various editions of
this
frequently-reprinted novel, the 1831 revision by Mary Shelley is actually ambiguous
on this
point, there being no page headers or other indicators to suggest that we are still
inside
Chapter 24 as the framing narrative resumes. Yet in almost every subsequent edition
I have
been able to find, Chapter 24 page headers continue through to the end.[2]
Figure 9: Structural boundaries on two pages from the 1831 edition
A few pages later, Frankenstein comes to the end of his narration, and Walton (the
author of the letters) resumes. In this edition, we might be forgiven for thinking
of this
as tucked within, rather than ending, Chapter 24.
Almost every edition of Frankenstein I have checked ends Chapter 24 not here, with
Walton, in continuation, but only at the end of the novel as a whole. This
isn't the case everywhere: indeed, to the extent that they appear to have thought
about it at
all, editors have sometimes been able to correct it. In effect, these editions
make the claim at least implicitly that the rendering of the final passages of Walton's
letter
inside Chapter 24 is an error or lapse, and that the correct form of the
novel is, in fact, more like an ordered hierarchy of content objects. Chapter 1 begins,
and
Chapter 24 ends, the manuscript that Walton transcribes from Victor.
Note
Since this paper was first drafted, I have learned more about the textual transmission
of Frankenstein, which complicates this picture significantly, without substantially
challenging the argument here. In the original 1818 edition, indeed, the chapters
(along
with the framing narrative) are grouped into volumes. Yet the same question arises
as to
whether the final passages (entries in Walton's letter from August 26 - September
12)
should be included within the last chapter (Chapter VII) of Volume III. Considering
them
as external to it does regularize the shape of the novel along similar
lines to what I have discussed as applying to the structure of 1831—indeed with an
added
dimension, since the tripartite division into volumes reflects the tripartite division
of
Victor's narrative (while it does not entirely correspond with, inasmuch as it must
also
comprise the leading and trailing sections). Moreover, manuscript evidence that a
two-volume structure was subsequently recast into three volumes suggests that the
eventual
three-volume structure (which neatly corresponds to the clean nesting of a
corrected 1831 text) was a design decision on the part of the author. See
Robinson (email) 2014, Robinson 1996, SGA [date], and Hindle 1992. Additionally, a
set of
invaluable resources for studying the textual history of the novel is at the Shelley
Godwin Archive (http://shelleygodwinarchive.org/
In this reading, the hierarchy of the chapters as published is really subordinate
to the
hierarchy of entries of letters with their contents. (See Figure 10 for
such a rectified view.) This would indeed have the effect of reconciling the
form of the novel—its internal form, even if its external form (the chapters as typeset)
is
somewhat misleading—into a single ordered hierarchy. The novel is comprised of four
letters,
one of which has several entries; of these, one contains a transcription of a long
narrative
presented in a sequence of chapters. Chapters (or the contents of letters and entries
outside
the chapters) contain paragraphs or other things such as letters and quotations.
Figure 10: A rectified view of the narrative and chapter hierarchies
together
Thus corrected, the narrative view has the interesting property of aligning with the
chapter view to a very great extent, if not entirely. The incidences of alignment
(or the lack
thereof) with other factors such as pagination, or quoted dialogue, turn out also
to be rather
interesting, once one starts examining them closely. One can learn a great deal by
executing
queries such as are depicted in Appendix C. (For example, there is
the remarkable fact that chapters starting at Chapter 19 all start on new pages, as
if they
had been copy fit: coincidence, or evidence of something?)[3] In particular, there is the striking alignment between the story that occurs at
the center of the novel (the narration told by the creature to Victor, who tells it
to Walton)
and the chapter structure, inasmuch as it contains exactly six chapters, and starts
and ends
with them.
Note
This is especially interesting in light of the observations of Mary Douglas regarding
ring structures in her amazing treatment of such structures in oral and
written literature (Douglas 2007). However Mary Shelley came to define
this structure for the first published edition of Frankenstein—only to revise it or
see it
revised in the subsequent edition of 1831—it certainly appears to matter that the resulting structure is one that is attested
elsewhere in imaginative literature.
One is left with the inescapable conclusion that the ordered hierarchy of content
objects
is a real thing—but also that it is contingent, not necessary, and the result
of an evolution in media and forms of expression, and in this case only imperfectly
realized
or expressed in the printed medium. We do not have to regard the relation between
the
narrative structure and the formal chapter/paragraph organization as ironic;
instead perhaps other tropes come to mind, perhaps metaphor in this case. Note that
here we
are not speaking of a metaphorical relation between any two levels of any hierarchy,
such as
between Walton's narrative and Victor's contained narrative—which we might also see.
Rather,
it is in the alignment of the structure of the narrative as a set of attested
documents (including Walton's letters and his transcript of Victor's story
Note
And, intriguingly, perhaps of physical attestation of Victor's veracity in the form
of
transcripts of letters made by the creature and given by him to Victor, who in turn
shows
them to Walton.
), and the structure of the novel as a published work in conventional
(chapter/paragraph) form.
Yet to argue that the correct reading is that these must be aligned, with no possibility
of intentional misarrangement, as a consequence of what it is to be a text, because ...
OHCO (which is not, mind you, what was ever proposed for OHCO ... it’s just that
somehow this coincided with the push for SGML, then to be wired into XML), is to suppose
we
know the answer before we have pondered the question. Instead, alerted to the possibility
that
this novel (and others) might well perturb, if not altogether defy, its own well-ordered
arrangement—the possibility, that is, of an ironic stress between two or more of its
internal
and presented structures—the fact that we can reconcile them here becomes important.
If this
novel is an ordered hierarchy, an arrangement of nested narratives (that happens incidentally
to be segmented, in part, into chapters), it is a particular
ordered hierarchy of particular content objects. Even the possibility of this reading,
that
is, vindicates the idea that such a model (which indeed is satisfyingly symmetrical
in this
case) was indeed part of the concept of the novel itself. The novel is structured
as it is not
because of some prior rule that texts are always hierarchies, but because Mary Shelley
designed it like this. (She put the hierarchy there much in the way an XML schema
designer
would have. Except that typesetters subsequently failed to understand her full intent,
or the
implication of it.) At the same time, were the typographer to do a better job representing
the
shift back to the framing story when Frankenstein's narrative ends, it would make
it no less
startling (indeed, maybe more so) when the creature himself appears on the scene—by
this
reading, outside the chapters of the book. A boundary is
transgressed in either case; indeed in this reading even more strongly, since the
separation
of the framing narrative indicated by a clean ending to Chapter 24 is suddenly broken,
and we,
with the narrator, are brought face to face with something we would prefer never to
have
met.Likewise we can see how our vindication of an OHCO here is only provisional: it
applies to
this novel alone (as long as we take the paginated structure to be incidental, and
leave aside
the occasional misalignment of dialogue speeches with paragraphs), and is liable to
slip with
any new example of a narrative that violates it.
In this respect Frankenstein is not singular among works of literature. Meanwhile,
the
OHCO is alive and well, but not because it is inevitable or the only correct
and possible way of representing texts. Its power is not in any generalization regarding
texts or some set of artifacts we regard as being text, as
much as it is in its own act of fiat, its description,
rationalization and legitimization of hierarchical models in systems as we are building
them.
Appendix A. More sonnets
All these diagrams are generated from poems encoded in LMNL.
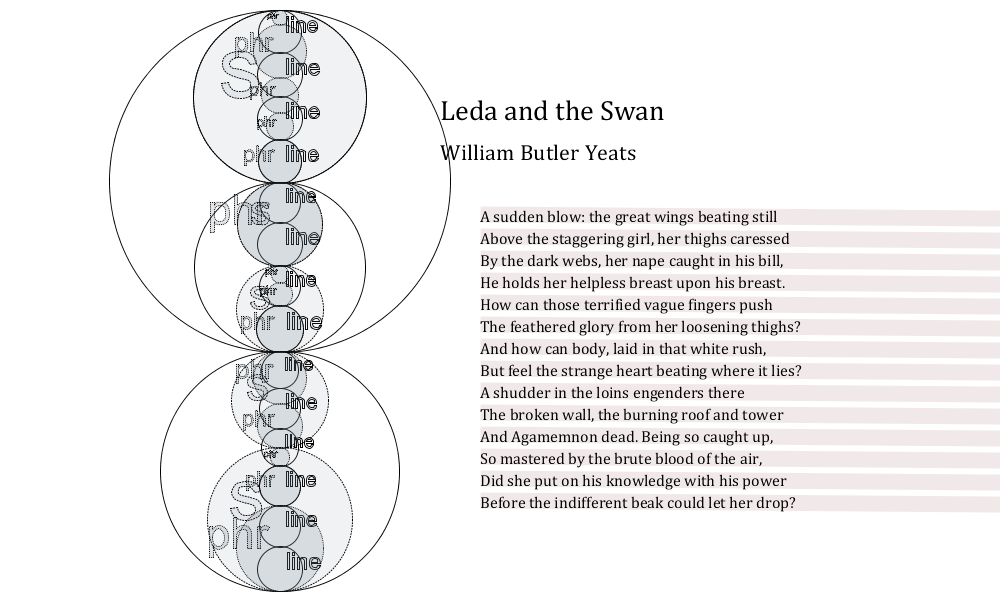
Figure 11: Leda and the Swan by W. B. Yeats (1924)
This example shows phrases overlapping lines (enjambment) in the first quatrain, and
again at the beginning of the sestet.
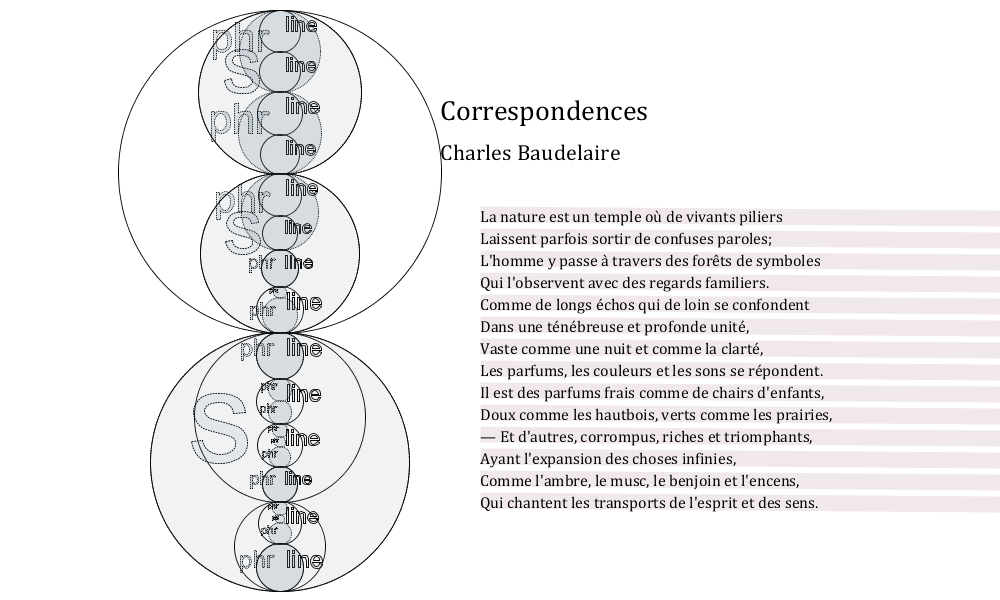
Figure 12: Correspondences by Charles Baudelaire (1924)
In this example, each major division (quatrains and sestet) constitutes a sentence,
and phrases nest perfectly inside lines, with no overlap.
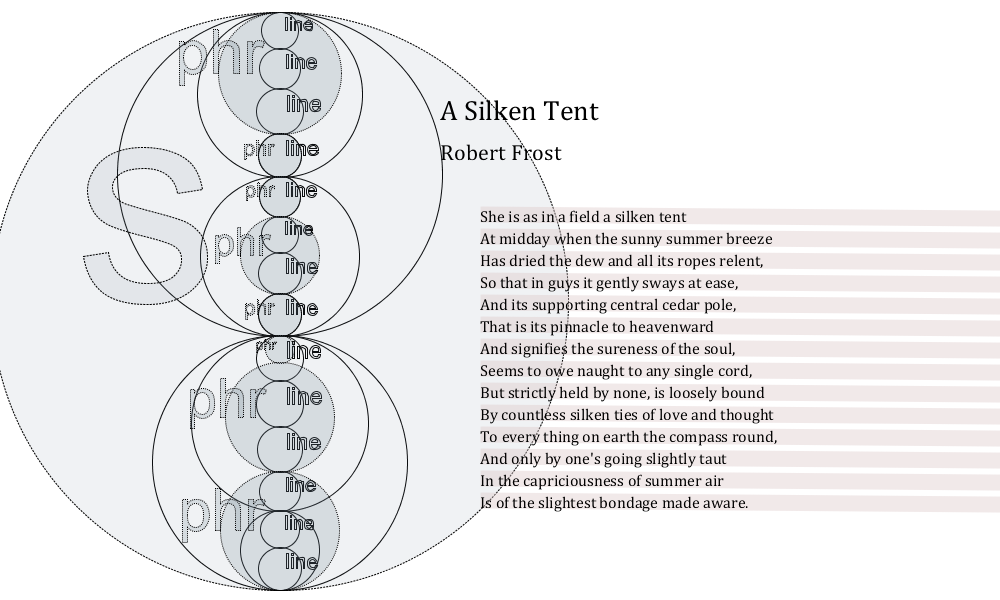
Figure 13: The Silken Tent by Robert Frost (1942)
This example shows almost no overlap, except at the beginning of the sestet (i.e.,
at
the center), where the language briefly tugs on the verse.
Appendix B. Using LMNL to mark up narrative
Reflecting the lifting, in the LMNL model, of the prohibition against overlap, it
becomes
a comparatively simple exercise to provide a LMNL-syntax description of purely narrative
structures, aside even from paragraphs. Higher-level narrative structures are marked
up as
story ranges (start or end tags for page ranges may also
appear):
[page [n}86{] [ed}1831{]}or denial of this opinion. For the first
time, also, I felt what the duties of a creator towards his creature were, and
that I ought to render him happy before I complained of his wickedness. These
motives urged me to comply with his demand. We crossed the ice, therefore, and
ascended the opposite rock. The air was cold, and the rain again began to
descend; we entered the hut, the fiend with an air of exultation, I with a
heavy heart and depressed spirits. But I consented to listen, and seating
myself by the fire which my odious companion had lighted, he thus began his
tale.{p]{chapter]
[story [who}The creature{]}[chapter [n}11{]}
[head}Chapter 11{head]
[p}It is with considerable difficulty that I remember the original era of my
being...
Similarly, dialogue may be marked up as said, as per TEI, without worrying
about boundaries of paragraphs (which conflict rarely but not never) or pages (conflicting
frequently):
[p}[said [who}Prof Waldman{]}I am happy,{said] said M. Waldman,
[said [who}Prof Waldman{]}to have gained a disciple; and if your application
equals your ability, I have no doubt of your success. Chemistry is that branch
of natural philosophy in which the greatest improvements have been and may be
made; it is on that account that I have made it my peculiar study; but at the
same time, I have not neglected the other branches of science. A man would make
but a very sorry chemist if he attended to that department of human knowledge
alone. If your wish is to become really a man of science and not merely a petty
experimentalist,{page]
[page [n}36{n] [ed}1831{ed]}I should advise you to apply to every
branch of natural philosophy, including mathematics.{said]{p]
Appendix C. Querying LMNL
One of the capabilities of Luminescent (a LMNL processing framework) is querying over
an
XML compiled version of a LMNL document. (Luminescent is described in Piez 2012). For example, here is an XQuery expression that returns the number of
the page (in the 1831 edition) on which Volney is mentioned. (Functions named
with the lm prefix are defined by
Luminescent.)
let $novel := db:open('LMNL-library','Frankenstein.xlmnl')/*
return lm:ranges('page',$novel)[contains(lm:range-value(.),'Volney')]
/lm:annotations('n',.)/lm:annotation-value(.)
This
returns 102. (If Volney were mentioned more than once, more than one page
number would be returned.)
Here is a query for distinct values of annotations indicating speakers (who
annotations on said
ranges):
let $novel := db:open('LMNL-library','Frankenstein.xlmnl')/*
return distinct-values(
lm:ranges('said',$novel)/
lm:annotations('who',.)/lm:annotation-value(.) )
26
strings are returned, includingthe Creature.
Here is a query that returns all the speeches attributed to the Creature (or substitute
any
character):
let $novel := db:open('LMNL-library','Frankenstein.xlmnl')/*
let $who := 'The creature'
return lm:ranges('said',$novel)[lm:annotations('who',.) = $who]
/lm:range-value-ws-trim(.)
48
speeches are returned.
Count the ranges overlapping said ranges, excluding page
ranges:
let $novel := db:open('LMNL-library','Frankenstein.xlmnl')/*
return count(
lm:ranges('said',$novel)/lm:overlapping-ranges(.)[not(lm:named('page',.))] )
We
get 4. (Another query shows they are all p ranges.)
References
[Barnard et al. 1995] Barnard, David, Lou Burnard,
Jean-Pierre Gaspart, Lynne A. Price, C. M. Sperberg-McQueen and Giovanni Battista
Varile.
1995. Hierarchical Encoding of Text: Technical Problems and SGML Solutions. Computers
and the
Humanities, Vol. 29, No. 3, The Text Encoding Initiative: Background and Context (1995),
pp.
211-231. doi:https://doi.org/10.1007/BF01830617.
[Coombs et al. 1987] James H. Coombs, Allen H.
Renear, and Steven J. DeRose. 1987. “Markup Systems and The Future of Scholarly Text
Processing.” Communications of the ACM, 30:11 933-947 (1987). doi:https://doi.org/10.1145/32206.32209.
[Douglas 2007] Douglas, Mary. Thinking in
Circles: An Essay in Ring Composition. New Haven: Yale University Press, 2007.
[Renear et al., 1990] DeRose, Stephen J., David
Durand, Elli Mylonas, and Allen Renear. “What is Text, Really?” Journal of Computing
in Higher
Education. Winter 1990, Vol. I (2), 3-26. doi:https://doi.org/10.1007/BF02941632.
[Renear 2004] Renear, Allen. “Text Encoding”. In A Companion to Digital Humanities, ed. Susan Schreibman,
Ray Siemens, John Unsworth. Oxford: Blackwell, 2004.
http://www.digitalhumanities.org/companion/
[1] Indeed, the 1993 consideration (Renear et al., 1993) of all the problems that
come with an overly-exclusive OHCO remains an excellent overview of the issues, twenty
years later. With apologies to DeRose, Durand and Mylonas, in this paper I may sometimes
refer to them mistakenly under the name Renear.
[2] The only exceptions I have found are the online edition from Romantic Circles (see
http://www.rc.umd.edu/editions/frankenstein) and a 1934 edition edited by
Harrison Smith and Robert Haas (with memorable engravings by Lynd Ward), which has
no page
headers, and does promote the Walton, in continuation header on the entry
of August 26 to the level of a chapter heading (thus implicitly ending Chapter 24).
[3] On four occasions, dialogue overlaps with paragraphs, but this is not many considering
there are also 304 marked ranges of directly quoted discourse that do not. Given markup
in
LMNL syntax, a LMNL processor can be used to find these instances (see Appendix C).
Barnard, David, Lou Burnard,
Jean-Pierre Gaspart, Lynne A. Price, C. M. Sperberg-McQueen and Giovanni Battista
Varile.
1995. Hierarchical Encoding of Text: Technical Problems and SGML Solutions. Computers
and the
Humanities, Vol. 29, No. 3, The Text Encoding Initiative: Background and Context (1995),
pp.
211-231. doi:https://doi.org/10.1007/BF01830617.
James H. Coombs, Allen H.
Renear, and Steven J. DeRose. 1987. “Markup Systems and The Future of Scholarly Text
Processing.” Communications of the ACM, 30:11 933-947 (1987). doi:https://doi.org/10.1145/32206.32209.
DeRose, Stephen J., David
Durand, Elli Mylonas, and Allen Renear. “What is Text, Really?” Journal of Computing
in Higher
Education. Winter 1990, Vol. I (2), 3-26. doi:https://doi.org/10.1007/BF02941632.
Renear, Allen. “Text Encoding”. In A Companion to Digital Humanities, ed. Susan Schreibman,
Ray Siemens, John Unsworth. Oxford: Blackwell, 2004.
http://www.digitalhumanities.org/companion/