Context
INSEE (http://www.insee.fr/) is France's National Statistical Institute. Like every statistical organization, it conducts many surveys on households or enterprises. Forms, whether on paper or electronic, are therefore key business objects.
For a long time, forms have been designed and managed independently and in a rather ad hoc fashion, but today statistical offices face new challenges (growing demand, data deluge, resource constraints, etc., see HLG-BAS Vision) that urge them to rationalize and industrialize all their business processes.
In the case of survey forms, or data acquisition in general, we also have to adapt to a growing diversification in the modes of collection: paper, telephone, various web devices, etc.
How should we organize the data collection processes to adapt to this new situation? The statistical community has identified some principles to guide the work in that respect:
-
rely on standard and shared definitions for the concepts measured, codification, etc.
-
share questions or question blocs across surveys
-
automate the production of the forms, and the retrieval of response data
This paper describes the application of these ideas to the generation of XForms questionnaires for a real business survey (CIS). We first explain in greater detail the motivations and the design choices made, then we give the details of the techniques employed. As a conclusion, we present some of the lessons learned from this operation and evoke some future directions.
The case for generating XForms
The need of a model
In this perspective of rationalization of its business process, INSEE launched a number of projects, two of which are of particular importance for the subject treated here:
The operation described in the present paper sits at the crossroads between these two projects, and it has been conducted as a collaboration of the two project teams.
The Coltrane project aims to industrialize the collection processes in a variety of domains like contact management or authentication methods, but one of its primary objectives is to build a single platform for collecting survey data, which would replace the different systems in use today. This platform needs to be able to collect data in different ways, even within the same survey:
This requirement leads naturally to the idea of creating these different manifestations of a given questionnaire from a common representation of the content and the logic flow, in the most automated fashion possible. This common representation is in fact based on metadata.
Statistical metadata come in different kinds: concept schemes, code lists and classifications, but also quality or methodological metadata, process descriptions, etc. The availability of harmonized and good-quality metadata has been identified as a major factor of progress for statistical offices.
Since metadata provide for the structuring and documentation of the statistical data, we need metadata standardization in order to be able to understand and compare data or to make them interoperable. Different standards exist on the international level for statistical metadata, for example SDMX [5] (SDMX), an ISO standard focused on the exchange of dimensional data (tables, cubes...) and associated metadata, the Neuchâtel Model (NEUCHATEL), a de facto standard representation of statistical classifications or the GSBPM [6] (GSBPM), a common high-level representation of the statistical process.
An important goal of the RMéS project is to align INSEE's metadata models on international standards. But storing or even managing metadata is not enough: we know from experience that metadata is not used when it is just after-the-fact documentation, for example because the informations are not up-to-date. What is expected from the RMéS project is the emergence of a metadata-driven information system, in which the meta-information is actively leveraged in the production process. This means that we build on these metadata: for example a code list generates controls in a data editing activity, or a questionnaire description in a specific meta-model is used to produce the actual survey instrument.
We see that Coltrane and RMéS have a convergent interest: the automatic generation of collection instruments from standard metadata-based models of questionnaires.
Figure 1: Generation of collection instruments
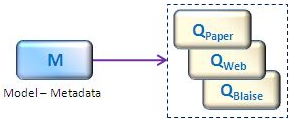
The studies carried out by both projects concluded that DDI [7] was the best metadata standard to use for their common purpose.
DDI is an international standard for describing data from the social, behavioral, and economic
sciences
(http://www.ddialliance.org/what). It is a
well-established standard for researchers and data archives, and its “Lifecycle” version
(DDI 3.2) has more recently attracted attention within the official statistics
community.
As shown in the following picture, DDI is based on a model of the whole data and metadata lifecycle during the statistical production process and provides – by design – the possibility to convey business information all along this process.
Figure 2: The statistical process in DDI-Lifecycle
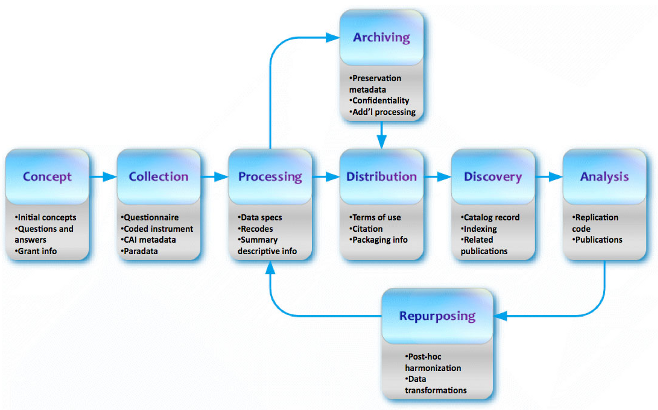
Copyright © 2013, DDI Alliance
DDI's “Data collection” module delivers great support for describing survey instruments, in particular questionnaires, with their structure and logical flow. This explains the choice made by the two projects, with RMéS focusing on the elaboration of the DDI models and Coltrane on the generation of the survey instruments.
Why XForms?
The different ways to administer a questionnaire do not have the same possibilities. Except for visual presentation, paper forms have rather poor functionalities, but but statistical offices have long since developed processes that allow them to be used efficiently. Software packages like Blaise are highly specialized and can easily handle complex content or logic, with rich interfaces for exchanging data. In both cases, business objectives are fulfilled, either through the organization or the software features. Web forms or electronic documents, on the other hand, leverage powerful and versatile technologies that must be tailored to the business needs.
In order to take the full advantage of web forms, the following requirements were selected:
-
The possibility to implement the logical flow of the questionnaire
-
The possibility to formalize and execute controls on the client or server side
-
The possibility to inject initialization data (for example for questionnaire personalization)
-
The possibility to produce different variants of a questionnaire depending on the respondent
-
The possibility to easily retrieve the response data
-
The possibility to style user interface elements according to business characteristics of the underlying questionnaire
These requirements combine some aspects that are defined in the abstract model and others that depend on the web implementation chosen, so we felt that we needed an intermediary technical model suited for the web, allowing us a step for processing and additional fine-tuning operations on the final questionnaire. We chose to express this technical model in XForms.
XForms is a powerful tool for the distribution of complex forms over the Internet. First of all, its design offers an easy way to initialize and capture data and to support complex dynamic treatments through its Model-View-Controller architecture.
Another decisive aspect of our choice is that XForms is the first X of the XRX architecture. XRX is XForms-REST-XQuery [http://en.wikipedia.org/wiki/XRX_(web_application_architecture)], an elegant software architecture which, amongst others, promotes a zero-impedance model in which data and code are members of the XML family, thus providing a coherent set of technologies. Since DDI is also expressed as XML schemas, we had the opportunity to build a completely homogenous solution.
Finally, the XForms implementations offer both client-side and server-side execution: hence we can imagine different balances of both depending on needs.
As to the last requirement above, it is easy to include in the XForms technical model some CSS references depending on the underlying questionnaire model.
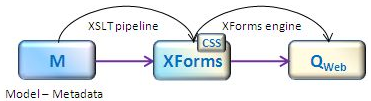
Our web forms generation pipeline now looks like this:
Figure 3: Generation of web forms – principle

It is worth noting that although XForms provides a great solution for complex web forms, it is a generic design format and so misses information relevant to our activity. It would not be adequate to use the XForms meta model to store our business information: we need a specific model through which we could express our core domain activity, and store and reuse components. XForms is envisioned as a target model, not a source model.
While our primary motivation to generate XForms rather than manually edit them has been the need of a generic model, we've found out that this process is a good workaround against two XForms weaknesses:
-
XForms is based on a pure MVC paradigm which can be an issue when controls or groups of controls are repeated in different contexts in the same form or in different forms (see Eric van der Vlist's “When MVC becomes a burden for XForms”). When editing XForms by hand this leads to a number of “copy & paste” which become a nightmare to maintain. When generating XForms these repetitions are not an issue any longer.
-
The current version of XForms (XForms 1.1) is limited and the use of non standard extensions is often necessary to perform complex tasks. These extensions are implementation dependent and non interoperable. When generating XForms from a model, these differences can be seen as minor templates adaptations.
We see from this last point that the XForms generation process must be easily adaptable to the target implementation. This idea is at the heart of our generic transformation engine.
Technical description
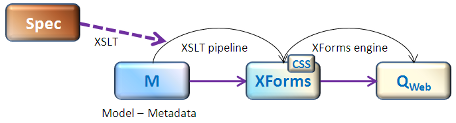
The next figure shows the technologies chosen to implement the generation process described in the previous section.
Figure 4: Generation of web forms – technologies
For the first transformation chain, the input is a questionnaire specification expressed in the DDI XML metamodel and the output is an XHTML5 + XForms document representing the final web form.
Since we were transforming XML documents into XML documents, XSLT was of course the natural choice. The functional approach and template-matching design of XSLT correspond very well with our intent to attach a specific web representation to each of our questionnaire metadata (questions, data to collect, instructions). We thus designed a base transformation engine using chained XSLT stylesheets.
A notable challenge was to cope with the complexity of the DDI metamodel, which maximizes the reusability of metadata elements like questions, code lists, or even texts, and also implements a very detailed versioning mechanism. As a consequence, DDI documents use a lot of chained references to bind logical elements together, and can be quite complex and difficult to process with XSLT which is more efficient with hierarchical document architecture than with relational structures.
Therefore, it was easier to design a series of separate steps producing simpler intermediate formats of the inputs or outputs, instead of a big and complex transformation.
The first step is a DDI compilation, resolving all references and providing a hierarchical view of the metadata. Then DDI elements are matched with generic behaviours, as TextInput (to figure a field designed to collect text), NumericInput, and so on. This is what we called the input steps. In the output steps, the behaviours are implemented to generate XForms components on the fly. At the end, finalization transformations are used to reorganize the outputs and render well-formed XForms documents.
The overall scripting of the XSLT chain was done with Ant, mainly because it is our corporate standard. For a next version of the engine, we are considering using XProc.
We've seen that DDI models are focused on describing data rather than surveys (you will not find, for example, any information in DDI to say if a data should be entered by a drop down menu or check boxes). DDI includes extension mechanisms which can be used to convey information which can be used to generate surveys but we prefer to rely on conventions to drive the transformation. In practice these conventions are project dependent and you need to add customization features to the XSLT engine to ensure its flexibility.
We added customization stylesheets using xsl:import (as often and in accord with the design patterns on overloading). In order to ensure quality and maintainability of our XSLT code, a careful design of the granularity and naming conventions was required. We defined default behaviours – implemented in the default engine – and customized behaviours attached to questionnaire elements – implemented in the customization stylesheets – when customized representations were needed.
We chose to specify these customized behaviours with spreadsheets, and more specifically ODF spreadsheets (ODS files), thereby preserving the XML homogeneity of our solution. The XML root structure of these spreadsheets is used as XML input of “configuration XSLT transformations” which produce the XSLT customization stylesheets (which, themselves, override some of the default behaviours of the default engine during the transformation to XHTML5 + XForms).
Figure 5: Generation of web forms – specification
This “spreadsheet-driven architecture” permits business experts to customize their questionnaires themselves with tools that they master, without knowing anything about XSLT. At this point, they still need to be somewhat comfortable with the DDI XML metamodel, but we're considering providing a guided interface to reduce, as much as possible, the technical IT requirements to design questionnaires.
Lessons learned
Our first goal was to be able to generate questionnaires using metadata definitions. It was not obvious for us that with a metamodel handling only statistical semantics we would be able to automatically generate all the features needed by our questionnaires. Moreover, we were not sure that DDI would support all these features. So, first of all, this realization is a good proof of concept for us, proof of technical feasibility to drive questionnaire generation with metadata. A concrete example of metadata-driven architecture for INSEE and the official statistics community.
Our goal to design a generic engine to industrialize the production of forms customized by domain experts has been really challenging and led us to define XSLT design patterns such as:
-
Use
xsl:apply-templates/xsl:templaterather thanxsl:chooseas much as possible. -
Decouple templates and functions related to the source documents from those in charge of the output tree generation.
-
Implement the “spreadsheet-driven mechanism” using a functional programming paradigm inspired by Dimitre Novatchev's FXSL (we've ruled out XSLT 3.0 features until they are more commonly implemented).
The first bullet point is one of the basics of sane XSLT programming but the two others – which are closely related – go against common XSLT programming.
To write or even just to read and understand most XSLT transformation one must understand three different domain specific vocabularies:
-
XSLT and XPath themselves
-
The knowledge of the vocabulary used by the source document is required to understand most XPath expressions
-
The knowledge of the vocabulary used by the result document is necessary to understand the production of literals and the general structure of the transformation.
For this project the team was spread over multiple departments, profiles and geographical locations and composed of:
-
Business experts whose job is to design surveys and DDI experts who create the DDI model for these surveys
-
XSLT developers who speak fluently DDI and have a basic knowledge of XForms
-
XForms experts who are also fluent XSLT developers but are puzzled by the complexity of DDI.
The use of spreadsheets to generate XSLT templates has been a first step in the separation of concerns between design and implementation and we've gone a step further and separated as much as possible the concerns between DDI and XForms expertise so that in this loosely coupled team each profile could work as independently as possible.
This second step has been achieved by defining, like we would have done in any other programming language, an interface between everything related to DDI and anything related to XForms, the challenge being to define how this interface should be organized to take advantage of the template oriented nature of XSLT while performing this separation of concerns between source and result vocabularies.
The separation of concerns being materialized by splitting XSLT stylesheets between anything related to the source document and anything related to the result tree, the source related templates which are generated from the spreadsheet build a dynamic document, called the "driver" because its role is to drive the generation of the result tree and apply the templates on driver's nodes.
Result oriented templates match driver nodes to create the result tree and use a set of accessors functions implemented by the source oriented stylesheets to get any additional info they may need. An additional interface function implemented by source stylesheets returns the nodeset considered as the logical children of the context node from the source document.
This can be seen as a dialog between source and result stylesheets:
-
Source: Hmmm, my context node should be translated into this XForms control. I append the element identifying this control to the driver and apply the templates in result mode on this element in the driver.
-
Result: I see in the driver that I need to generate this XForms control. Please give me (using accessor functions) these information.
-
Result: I am done with this control, tell me which are the logical children of your context node so that I can apply the templates in source mode on these children.
We have found this design pattern very effective during our implementation.
To develop the result stylesheets which generate Orbeon Form Builder forms, we've written a set of source stylesheets implementing this interface on source documents which are... Form Builder forms! The combination gave us an identity transformation which has been very handy to debug the result stylesheets.
Different flavors of the result stylesheets are also being developed to generate "pure" XForms forms for different implementations (Orbeon, XSLTForms and betterFORM) and this separation of concerns greatly facilitates this development. The main difficulties met so far are related to the lack of interoperability of the different XForms implementations.
The deployment of a first survey in production on Orbeon Form Runner has not shown any performance issue despite the size of the form (15,000 lines, 10,000 elements, 1.1 Mo).
The development described in this paper has validated our approach of generating surveys instruments from questionnaire descriptions. This approach had previously been applied to the generation of electronic documents (ODF), but targeting XForms led us to a much more flexible and configurable solution. We now envision with confidence the possibility of generating entirely new formats like Blaise.
References
[HLG-BAS Vision] UNECE, Strategic vision of the High-Level Group for the Modernisation of Statistical Production
and Services
,
http://www1.unece.org/stat/platform/display/hlgbas/Strategic+vision+of+the+HLG
[CIS] CIS, Community Innovation Statistics
. http://epp.eurostat.ec.europa.eu/portal/page/portal/microdata/cis
[DDI 3.2] DDI Alliance, DDI 3.2 (Public Review Version)
.
http://www.ddialliance.org/Specification/DDI-Lifecycle/3.2/
[SDMX] SDMX Sponsors, Statistical Data and Metadata Exchange
, http://sdmx.org/
[NEUCHATEL] UNECE, Neuchâtel Terminology Model for classifications
,
http://www1.unece.org/stat/platform/pages/viewpage.action?pageId=14319930
[GSBPM] UNECE, The Generic Statistical Business Process Model
,
http://www1.unece.org/stat/platform/display/metis/The+Generic+Statistical+Business+Process+Model
[1] Référentiel de métadonnées statistiques
[2] Collecte transversale d'enquêtes
[3] Open Document Format for Office Applications (http://en.wikipedia.org/wiki/OpenDocument)
[5] Statistical Data and Metadata Exchange
[6] Generic Statistical Business Process Model
[7] Data Documentation Initiative (http://www.ddialliance.org/)