Why another XML search engine?
So first: why? There are a number of excellent XQuery databases available, both commercial and free ones, even open source. Some of our motivation was historical; for a variety of reasons we ended up with a number of applications built on top of a Solr/Lucene data store. We keep XML in these indexes, and we can define XPath indexes, but our query syntax is limited to Lucene's simple query languages, which are not at all XML aware. So we wanted to be able to use XQuery in an efficient way with these pre-existing data stores.
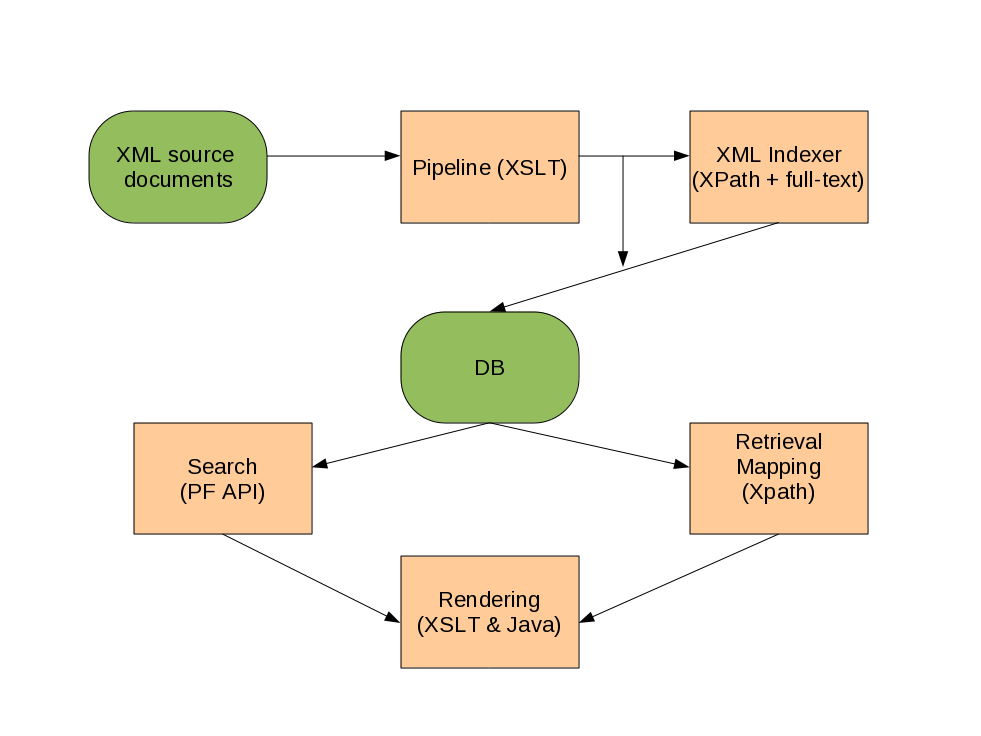
This system design has a lot of nice features: it enabled us to accomplish most of what we needed with a leaner technology stack, and we gained a degree of power and flexibility by doing so, since we had Java programmers on staff who could fill in the missing bits. But having done this we also had to grapple with some missing conveniences that those programmers were somewhat reliant on.
We knew from the beginning that we would miss the ad hoc query capabilities that both MarkLogic, and eXist, which we had been using, provided. We had come to rely on CQ and the eXist sandbox: what would take their place? The Solr admin query interface is a truly impoverished replacement for these. In fact it has recently gotten a facelift, but the query interface is essentially unchanged: you have no opportunity to operate on the results beyond selecting which fields are returned. Worse still, all of our indexes would have to be computed in advance. MarkLogic provides a great feature for ad hoc querying, which I think they call the "universal index." This index provides for lookup by word (ie full text search) and value (exact match) constrained by the name of containing elements and attributes.
So Lux was really born out of this need for an ad hoc query capability, something akin to what Micah Dubinko presented at Balisage last year in Exploring the Unknown. Our first thought was something like this: "Hey, Saxon provides an XQuery capability, and Solr provides indexing and storage: all we need to do is marry them, and presto! We'll have an indexed XQuery tool." It turned out though that there was a lot more work required to produce a usable version of that than it appeared at first blush. This is the story.
Lux Architecture
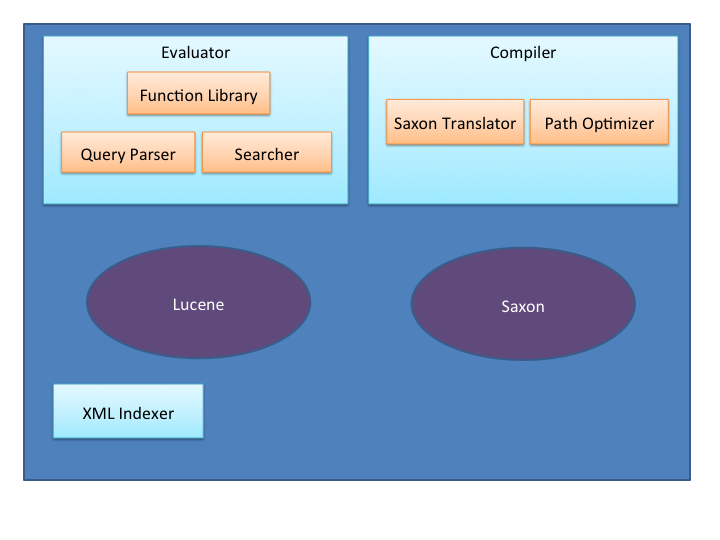
A quick overview of the Lux internal software design provides context for the XQuery indexing optimizations that are the main topic of this paper.
|
Evaluator |
the highest-level abstraction in Lux. It contains the other objects listed below (and the underlying Saxon objects) and provides a central access point for all Lux functionality, but in particular provides the evaluate(query) method. |
|
Compiler |
compiles XQuery expressions into an executable form |
|
SaxonTranslator |
translates expressions from Saxon's internal Expression tree structure to Lux's AbstractExpression tree structure. |
|
PathOptimizer |
rewrites AbstractExpression to make use of Lux indexes |
|
FunctionLibrary |
Provides index-aware XQuery functions |
|
XmlIndexer |
Indexes XML documents, generating Lucene field values |
|
Searcher |
Searches the Lucene index, returning matching documents stored there |
|
XML Highlighter |
Highlights terms in a document matching a search query |
|
Query Parser |
Parses queries in Lux's extended Lucene query language and its XML form |
Query optimization with indexes
When executing queries in a setting with a large amount of data,
indexes are critical. A properly indexed query may execute in less
than a millisecond while the same query, unoptimized, could easily
take so long that it would effectively never complete. In Lux,
queries are implicitly executed with the entire contents of the index
as their context: more precisely, wherever there is an absolute
expression (a path rooted at "/"), Lux inserts, conceptually, a call
to collection(), the function that returns all
documents. This approach has been adopted in other databases; we've
attempted to provide a familiar environment.
Sometimes users exercise control over the indexes that are generated and how they are used to resolve queries. XSLT's key functionality is an example of this. In other cases, like SQL databases, users specify the indexes and hope they've chosen the right ones that will nudge the optimizer to speed up their queries. And sometimes indexes are created and used with little or no user intervention at all. This is an ideal situation when it works, but nearly impossible to get right all the time in a general case where queries are expressed in a complex language such as XQuery. There are two main difficulties: knowing which indexes might be useful enough to justify the cost of creating them, and then actually applying those indexes to optimize queries.
Our philosophy is to provide as much automatic help as possible, so the user doesn't have to think, but to get out of the way when the user tells us they want manual control.
-
Provide basic indexes that can be applied automatically and relied on to provide value for a wide range of queries.
-
Give the user clear information about the output of the optimizer. Sometimes the optimizer can be tricked by otherwise insignificant syntactic constructs, like variables. If the user is made aware of this, they can often rectify the situation by rewriting their queries.
-
Allow the user to specify indexes explicitly: users can be relied on to know when there are especially interesting sequences to be indexed.
-
Provide users with query constructs that reference the indexes directly. This way users can take over when the optimizer fails.
It has become standard practice to index XML with the following kinds of indexes:
-
QName indexes
-
Path indexes
-
Full text indexes
-
QName value and/or text indexes
-
XPath indexes
Lux currently provides path, full text, element/attribute full text, and xpath indexes. We've done some work on an element/attribute value index as well. The optimizer generates search expressions using the path indexes, and in some cases, the full text indexes and XPath indexes. The user can make explicit use of all the indexes for search, optimized counting, and sorting by calling index-aware functions provided in the Lux function library.
There are a variety of optimizations using indexes we could imagine applying in order to make a query go faster: Filtering the input collection to include only "relevant" documents is the main one, and it sounds simple enough, but there are a lot of specific cases to be considered, and there is a real danger of over-optimizing and getting incorrect results. Optimizations tend to have a patchwork character, and in order to stay on top of things, it's important to have a formal framework we can use to prove to ourselves that the optimizations are correct; that they preserve the correct results.
Formal setting
Because XQuery is a functional language, it's natural to think of queries as functions, and to apply the formalisms of functional logic. In this light, query optimizations can be described formally as a special kind of homomorphism [1] over the space of all queries. A function is generally defined as a mapping from one set to another: in this case from sequences of documents to sequences of items. So in this terminology, two queries are homomorphic if they represent the same mapping from documents to items. We won't take this formal setup very far, but we note that homomorphism is preserved by composition. In other words if two optimizations are "correct" independently, applying both of them will still be "correct", in the sense of preserving correct results, and we can apply them in whichever order we choose. This is important because it enables us to work on query transformations independently, without worrying that making changes in one place will suddenly cause problems to crop up somewhere completely different.
Defining optimization as a mapping from queries to queries has another nice property: it means we can fairly easily show the user what the optimized query is: it's just a different (hopefully faster) query that returns the same result. This is different from the situation in some systems, where optimizations are completely opaque to the user, or are presented as a kind of abstract "query plan" that bears little or no resemblance to an actual query. Of course the user needs to be able to understand the optimized XQuery form, but given that they wrote the original XQuery, it shouldn't be too much of a stretch for them.
Filtering the context
It is often the case that query expressions return an empty sequence
when evaluated in the context of a given document. For example, the
query //chapter[.//videoobject]/title returns the titles
of all (DocBook) chapters containing references to videos. Suppose
our database contains 1000 books broken into a document for every
chapter. Only a small fraction of these may actually contain videos,
but a naïve unoptimized implementation might have to load every one
of those documents into memory, parse them, evaluate the query on
them, only to return nothing. One of the main goals of the optimizer
is to filter the context early in the process, using indexes, so that
all this unnecessary work can be avoided.
We said that we operate on the whole database by replacing "/" with collection(). We can think of every query to be optimized then as some function whose single argument is the sequence of all documents. What we'd like to be able to do is to filter out all documents from that sequence that have no chance of contributing to the query results. Intuitively we know that the result of
collection()//chapter[.//videoobject]/title
collection('chapters with videos (and titles)')//chapter[.//videoobject]/title
f(s1,s2,s3,...) === (f(s1), f(s2), f(s3), ...)
f(S) === f(s∈S | f(s) is not empty)
This is very useful. What it means is that if we can come up with some index query that selects only those documents that return results for a given XQuery, then we can use that to filter the documents "up front," and save a lot of processing. Actually it's OK to retrieve more documents than we need, but the game is to retrieve as few as possible without missing any important ones.
So that's goal #1 of the optimizer: for any XQuery, produce an
index query that minimizes the number of documents required to be
retrieved. How do we do that? The strategy is to devise indexes,
and queries, that match XQuery primitives like QNames and simple
comparisons, and then to combine those primitive queries when they
appear as part of more complex, composite expressions, like
sequences, boolean operators, set operators, FLWOR expressions and
so on. In particular what the Lux optimizer does is to perform a
depth-first walk of the syntax tree of a query, pushing, popping,
and combining index queries on a stack as it goes. The
pseudo-logic of optimize(xquery) goes something like
this:
if (xquery has no children)
push a corresponding primitive index query
else
let current-query = match-all
for each child expression
pop the child-query
if (child is absolute (contains a Root sub-expression: /))
replace the Root with search(child-query)
else
let current query = combine (current-query, child-query)
push current-query
Path Indexes
Let's look more closely at optimizing queries with path expressions in them, since these expressions are uniquely characteristic of querying tree-structured data like XML. We've implemented different kinds of structure-related indexes, and it's interesting to compare what each one buys, and what it costs.
The most basic approach that captures some document structure is just to index all the names of all the elements and attributes (the QNames) in each document. If we do that, we can easily make sure not to go looking for videos in documents that don't have them.
But the simple QName index doesn't really capture anything about
relationships of nodes within a document. It feels like it ought
to be possible to search chapter titles independently from
searching book titles or section titles, for example, even if they
are all tagged with <title>, as in DocBook. A natural thing
to do is to index the complete path of every named node. We've done
this by treating each path as a kind of "sentence" in which each
node name is a single word or token. Then using phrase queries and
similar queries based on token-proximity, we can express
constraints like a/child::b, a//b (and
others) much more precisely. With the simple QName index, it isn't
possible to write a query even for //a//b that won't
match other irrelevant documents as well (such as
<b><a/></b>).
Here's a concrete example:
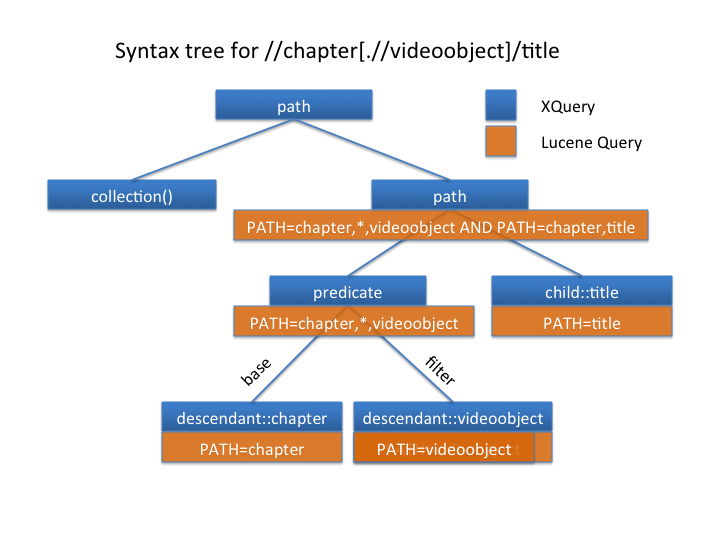
The figure shows a syntax tree for the example expression roughly as it would be expressed by the Saxon parser, in blue rectangles, and in orange it shows the corresponding Lucene pseudo-query that is generated by Lux. Parent queries are formed by joining together child queries using the recursive process described above. The combine() method alluded to there is somewhat complex for path queries. Its job is to characterize the relationship between two child expressions and to generate as precisely as possible (ie matching as few documents as possible, without missing any) a query corresponding to the parent expression. For the simple boolean queries that are generated when only QName indexes are in use, this is generally just a matter of deciding whether the children should be AND-ed together or OR-ed together. The choice is typically dictated by the character of the parent expression: most are restrictive and generate AND-queries, but some, like "or", "|", and "union" conjoin their child expressions and generate OR-queries.
Joining path queries also requires computing a distance between two subexpressions. The optimizer computes this distance when visiting path expressions (a/b) and predicates (a[b]), translating non-adjacent path axes like descendant, and intervening wildcard steps like /*/*/ into corresponding phrase distances in the Lucene proximity query.
Once the optimizer has generated a Lucene query corresponding to an XQuery expression, it replaces the collection() (or /) expression with a call to Lux's search function, passing it the generated query as its argument.
One benefit of the Lux architecture is that it optimizes expression trees that have already been optimized to some extent by Saxon. Saxon reduces a number of equivalent expressions to a simpler canonical form, making it easier to perform the analysis needed for optimization. There are some drawbacks to this approach as well: Saxon converts some expressions (like atomized sequences) into internal forms that have no direct correspondence with XQuery expressions, so some clever inferencing is required in those cases to create an equivalent XQuery.
Of course we can keep on devising more and more precise indexes.
Consider indexing every occurrence of every path, so that we keep a
count of each path as well: that should give us a handle on queries
involving positional predicates like //title[2]. We
often want to know if there is a second same-named element since it
might violate a schema that requires a singleton. Indexing paths
as phrases in Lucene doesn't really lend itself well to maintaining
this kind of statistic since the tokens in that case are QNames.
But if we index each complete path as a token (i.e. "/a/b/c" as a
single token, rather than "a b c" as three tokens associated by
position-proximity), then the index will maintain a term count for
us.
We have made some experiments with these "path occurrence" queries. The path queries become token queries, possibly involving wildcards, rather than phrase queries. The performance of the resulting queries is roughly the same as the phrase-like queries described before. The promise of indexing positional predicates proves difficult to realize, though. In Lucene, the primary function of term frequency counts is to compute relevance-ranking scores: using them to filter queries is much more involved, requiring some deeper spelunking into Lucene's internals, but this is a promising avenue for future work.
Other optimizations
The optimizer knows a few other tricks, beyond simply ignoring irrelevant documents.
Special Functions
In general, function calls are opaque to the optimizer, but it
does apply special optimizations for a few built-in XPath
functions: root(), exists(),
empty(), count() and
subsequence().
count(), exists(), and
empty() can be evaluated using indexes only, without
loading documents, when it can be determined that their arguments
are faithfully modeled by an appropriate query. When this
inference can be made, the speedup is are often dramatic, so we
go to some lengths to track a few properties that characterize
the precision of the Lucene query that the optimizer generates.
If we can prove that a given Lucene query retrieves *only* the
documents that produce XQuery results, no more and no fewer, then
we call the query minimal. A minimal query
is the best we can do in terms of filtering the context set for
the query. When their arguments' queries are minimal,
exists() and empty() are replaced by an
index-aware analogue, lux:exists(), which simply
checks whether any documents match a (Lucene) query (or its
negation, in the case of empty()).
Another useful property that some queries have is that they only
return one result per document. We call these
singular. It's useful to track singularity
since a minimal, singular query can be counted efficiently, using
indexes only. It's not always possible to tell whether a query's
result will be singular, but in some cases it is. In particular,
if a query returns only documents (or root element nodes), then
it will be singular. Lux recognizes that the root()
function is singular, and counts paths ending with
/root() in an efficient manner.
The subsequence($seq,$start,$length) function provides
a fixed window into a larger sequence. We can rely on the XQuery
processor's lazy evaluation to avoid retrieving documents beyond
the right edge of the window. When the windowed sequence is
singular, we can also avoid loading the documents to the left of
the window by telling the Lucene searcher to skip the number of
documents indicated by subsequence's second argument. Also note
that Saxon does us the favor of translating numeric predicates
($sequence[10]) into subsequence function calls, so the same
optimization applies to those.
Sorting
Sorting a sequence using an XQuery "order by" clause typically requires the entire sequence to be loaded into memory in order to evaluate the ordering expression for use in sorting, even if only a subset of the documents will eventually contribute to the overall query result (they may be filtered by subsequence() for example). We can do better when the ordering expression has been indexed.
Lux can populate a Lucene field for any user-supplied XPath
expression, and exposes these fields in XQuery via the
lux:key (formerly lux:field-values)
function. When the optimizer finds a
lux:key($field) call used as an ordering expression,
the field argument is used to order the Lucene query result. In
general results can be ordered much more quickly this way. Such
optimizations are applicable for single-valued fields with string
and numeric values. They support empty least/greatest, and can
handle multiple fields.
Range Comparisons
Lux optimizes range comparisons (=, !=, <, <=, >, >=, eq,
ne, gt, ge, le, lt) when one of the operands is a constant, and
the other is a call to lux:key() or can be proven to match an
indexed expression. For example, if there is a string-valued
index called "book-id" on //book/@id, the expression
//book[@id="isbn9780123456789"] would be optimized
into something like:
lux:search("book-id:isbn9780123456789"), and
evaluated using indexed lookup. There will be additional clauses
to the generated query, such as path constraints. Also, equality
tests may be optimized using the built-in full text indexes. In
the example above, a word-based query such as:
<@id:isbn9780123456789 would be generated, which
would find the given isbn, ignoring text normalizations such as
case, in any id attribute. These text queries are less selective
than the query based on the XPath index, but can often be
selective enough, depending on the structure of the documents.
FLWOR expressions and variables
There are no special optimizations related to these constructs, but they do present special problems. Lux doesn't make any attempt to apply constraints from where clauses, but since Saxon converts most where clauses to predicates, this isn't a significant drawback. Variables are handled by keeping track of variable bindings while the try is being optimized, and applying any query constraints from a variable's bound expression to its containing expression as if it were simply expanded in place.
Results
Correctness
It's critical to ensure that an "optimized" query returns the same results as the original, but it's not always so easy to prove that a given optimization is homomorphic. Sometimes we think we've done so, but a counterexample arises. If we were better mathematicians, perhaps we wouldn't need to, but as engineers, we take a pragmatic approach and build lots of tests.
XQTS was a great help, in resolving query translation issues, and somewhat helpful in testing the optimizer. But it isn't targeted at testing queries to be run over large numbers of documents, so we created our own test suite to ensure that our optimizations do in fact improve query speed. In the course of doing this, we uncovered numerous bugs, even though we had a nearly 100% pass rate on XQTS. You just can't have enough unit tests.
Indexing Performance
Of course the whole point of this exercise is to improve query performance. No paper about optimization would be complete without some measurements. And we have been able to make improvements. In some ways it's uninteresting to look at specific performance comparisons with and without index optimizations, since the improvement (when there is one) can usually be made arbitrarily large simply by adding more documents to the database. There are a few inferences to be drawn from the numbers, though.
Note on the test data: we used Jon Bosak's hamlet.xml (courtesy of ibiblio.org) to generate a set of 6636 documents, one for each element in the play's markup. So there are a single PLAY document, five ACT documents, and so on, in our test set.
We evaluated the cost, in bytes, of enabling various indexing options. The size of the indexes is an important consideration since it has an effect on memory consumption and on the amount of disk I/O the system will need to perform when updating and merging. For the Hamlet test set, the relative sizes of the index fields are given in the following table, in bytes, and as a percentage of the size required to store the XML documents.
| Index Option | Size (in bytes) | % of xml |
| XML Storage | 1,346,560 | 100% |
| Full Text | 1,765,376 | 100% |
| Node Text | 1,770,496 | 100% |
| Paths | 122,880 | 100% |
| QNames | 88,064 | 100% |
The Full Text index includes all of the text, but no node name information. The Node Text index indexes each text token together with its element (or attribute) context. Note that the sizes of the QName and Path indexes are fairly low relative to the size of the documents themselves (also: the QName index isn't needed if we have a Path index). The next section shows the effect of these indexes on query performance.
Query Performance
The table below shows the time, in milliseconds, to evaluate a certain query with different indexes enabled. The queries were repeated 500 times in order to smooth out the noise in the measurements. The column labeled baseline represents an unfiltered baseline where every query is evaluated against every document. The qname column filtered documents using qname indexes, and the path shows results for path indexes. The %change and difference columns show the difference between qname and path indexing; positive values indicate greater times for qname indexes. The queries have been sorted in descending order by this difference.
| query | baseline | qname | path | %change | difference |
| /LINE | 444 | 262 | 185 | 29.19 | 76.48 |
| //ACT/TITLE/root()//SCENE/TITLE/root()//SPEECH/TITLE/root() | 338 | 31 | 2 | 92.01 | 28.52 |
| /ACT['content'=SCENE] | 318 | 32 | 8 | 75.12 | 24.04 |
| /ACT//SCENE | 366 | 40 | 18 | 55.62 | 22.25 |
| /ACT[SCENE='content'] | 372 | 29 | 8 | 70.46 | 20.43 |
| /ACT[.='content'] | 360 | 30 | 9 | 68.08 | 20.42 |
| /ACT/SCENE[.='content'] | 333 | 29 | 9 | 67.47 | 19.57 |
| /ACT/SCENE | 359 | 35 | 15 | 55.61 | 19.46 |
| count(//ACT/SCENE/ancestor::document-node()) | 151 | 20 | 0 | 95.59 | 19.12 |
| number((/ACT/SCENE)[1]) | 17 | 23 | 5 | 74.62 | 17.16 |
| /ACT/text() | 379 | 18 | 8 | 56.25 | 10.13 |
| /*[self::ACT/SCENE/self::*='content'] | 366 | 16 | 6 | 60.85 | 9.74 |
| /ACT//* | 323 | 20 | 10 | 47.62 | 9.52 |
| /ACT | 342 | 17 | 9 | 46.84 | 7.96 |
| /*[self::ACT/SCENE='content'] | 321 | 13 | 5 | 60.95 | 7.92 |
| //ACT|//SCENE | 497 | 37 | 35 | 7.69 | 2.85 |
| //ACT | 334 | 24 | 21 | 11.47 | 2.75 |
| //ACT[exists(SCENE)] | 334 | 21 | 18 | 11.97 | 2.51 |
| (/)[.//ACT] | 390 | 35 | 33 | 7.07 | 2.47 |
| //ACT[empty(SCENE)] | 521 | 27 | 24 | 8.86 | 2.39 |
| for $doc in //ACT order by lux:field-values('sortkey', $doc) return $doc | 385 | 39 | 37 | 5.27 | 2.06 |
| for $doc in //ACT order by $doc/lux:field-values('sortkey'), $doc/lux:field-values('sk2') return $doc | 525 | 26 | 24 | 7 | 1.82 |
| //ACT[.//SCENE] | 328 | 37 | 36 | 4.17 | 1.54 |
| //ACT/@* | 265 | 21 | 20 | 6.27 | 1.32 |
| subsequence (//ACT, 1, 10) | 275 | 18 | 17 | 5.96 | 1.07 |
| (//ACT)[1] | 8 | 14 | 13 | 7.54 | 1.06 |
| //ACT[not(SCENE)] | 291 | 19 | 18 | 4.51 | 0.86 |
| not(//ACT/root()//SCENE) | 169 | 1 | 0 | 50.89 | 0.51 |
| (for $doc in collection() return string ($doc/*/TITLE))[2] | 8 | 10 | 10 | 3.9 | 0.39 |
| //ACT/SCENE[1] | 416 | 22 | 21 | 1.08 | 0.24 |
| for $doc in //ACT order by $doc/lux:field-values('sortkey') return $doc | 280 | 24 | 24 | 0.84 | 0.20 |
| not(//ACT) | 16 | 1 | 1 | 18.88 | 0.19 |
| /node() | 236 | 157 | 157 | 0.1 | 0.16 |
| /*/ACT | 314 | 22 | 21 | 0.15 | 0.03 |
| (/)[.//*/@attr] | 459 | 0 | 0 | -180.29 | 0.00 |
| //*[@attr] | 414 | 0 | 0 | -6.53 | 0.00 |
| //*/@attr | 322 | 0 | 0 | 53.42 | 0.00 |
| //ACT/@id | 338 | 0 | 0 | 27.49 | 0.00 |
| //AND | 382 | 0 | 0 | -18.86 | 0.00 |
| //lux:foo | 455 | 0 | 0 | 75.42 | 0.00 |
| //node()/@attr | 322 | 0 | 0 | 32.51 | 0.00 |
| /ACT[@id=123] | 435 | 0 | 1 | -135.83 | 0.00 |
| /ACT[SCENE/@id=123] | 452 | 0 | 0 | -24.56 | 0.00 |
| count(/) | 287 | 0 | 1 | -197.15 | 0.00 |
| count(//ACT/ancestor::document-node()) | 152 | 0 | 0 | 66.07 | 0.00 |
| count(//ACT/root()) | 165 | 0 | 0 | -49.56 | 0.00 |
| empty((/)[.//ACT and .//SCENE]) | 15 | 0 | 0 | 67.55 | 0.00 |
| empty(/) | 13 | 0 | 0 | -176.63 | 0.00 |
| empty(//ACT) | 14 | 0 | 0 | -377.25 | 0.00 |
| empty(//ACT) and empty(//SCENE) | 14 | 0 | 0 | -67.5 | 0.00 |
| empty(//ACT/root()) | 470 | 0 | 0 | 37.91 | 0.00 |
| empty(//ACT/root()//SCENE) | 448 | 0 | 0 | -78.32 | 0.00 |
| exists((/)[.//ACT and .//SCENE]) | 10 | 0 | 0 | -185.37 | 0.00 |
| exists(/) | 13 | 0 | 0 | 69.54 | 0.00 |
| exists(//ACT) | 10 | 0 | 0 | -53.78 | 0.00 |
| exists(//ACT) and exists(//SCENE) | 11 | 0 | 0 | 64.64 | 0.00 |
| exists(//ACT/root()) | 363 | 0 | 0 | 0.86 | 0.00 |
| exists(//ACT/root()//SCENE) | 377 | 0 | 0 | 79.15 | 0.00 |
| not((/)[.//ACT and .//SCENE]) | 4 | 0 | 0 | 4.59 | 0.00 |
| not(//ACT) and empty(//SCENE) | 5 | 0 | 1 | -205.65 | 0.00 |
| not(//ACT/root()) | 352 | 0 | 0 | -17.33 | 0.00 |
| (for $doc in collection() return data($doc//TITLE))[2] | 15 | 9 | 9 | -0.69 | -0.06 |
| subsequence (//ACT, 1, 1) | 13 | 11 | 11 | -1.52 | -0.17 |
| //ACT[exists(.//SCENE)] | 347 | 34 | 35 | -0.9 | -0.31 |
| not(/) | 15 | 1 | 2 | -35.76 | -0.36 |
| //ACT[not(empty(.//SCENE))] | 340 | 23 | 23 | -1.84 | -0.42 |
| //*/ACT/SCENE | 396 | 35 | 35 | -1.4 | -0.49 |
| (/)[.//ACT][.//SCENE] | 340 | 24 | 24 | -2.89 | -0.69 |
| count(//ACT/root()//SCENE) | 315 | 34 | 35 | -3.99 | -1.36 |
| //ACT[SCENE='content'] | 324 | 32 | 33 | -4.3 | -1.38 |
| //SCENE[last()] | 623 | 45 | 46 | -3.24 | -1.46 |
| //SCENE[1] | 626 | 37 | 39 | -4.57 | -1.69 |
| /ancestor-or-self::node() | 285 | 239 | 241 | -0.77 | -1.84 |
| //ACT/TITLE | //SCENE/TITLE| //SPEECH/TITLE | 425 | 55 | 57 | -3.87 | -2.13 |
| /PLAY/(ACT|PERSONAE)/TITLE | 342 | 19 | 21 | -11.31 | -2.15 |
| /* | 288 | 310 | 312 | -0.73 | -2.26 |
| count(//ACT) | 222 | 19 | 21 | -12.14 | -2.31 |
| //SCENE[2] | 571 | 57 | 60 | -4.65 | -2.65 |
| //ACT[count(SCENE) = 0] | 253 | 18 | 21 | -17.2 | -3.10 |
| /descendant-or-self::SCENE[1] | 452 | 26 | 30 | -13.43 | -3.49 |
| //ACT[.='content'] | 368 | 27 | 31 | -13.13 | -3.55 |
| /self::node() | 292 | 309 | 314 | -1.58 | -4.88 |
| number((/descendant-or-self::ACT)[1]) | 364 | 19 | 25 | -30.09 | -5.72 |
| / | 312 | 347 | 362 | -4.45 | -15.44 |
| 288.23 | 34.52 | 31.15 | 9.76 |
It is clear that the path index is providing some benefit when the queries contain paths with multiple named steps. In other cases there is sometimes some increase in query time - it's not entirely clear why, but the absolute value of this increase tends to be small. It may be that there is some further improvement possible by avoiding the use of positional queries when there are not any useful path constraints in the query.
Note on benchmarking
Some reviewers expressed the desire for comparative performance benchmarks with other database systems. We've known since at least 1440 that "comparisons are odious," or, according to Dogberry, in a later gloss, "odorous." One would like the data, but we don't feel well-placed to provide an objective benchmark comparing our system against others. The best I can offer is that we observe comparable performance with other indexed XQuery systems, and simply note that the key factor for performance is to extend the cases where indexes can be applied.
Conclusions
We described an XML search engine, Lux, based on Saxon and Lucene. We gave an overview of how it optimizes queries, and we explored its Path indexes in more depth. Measurements show a substantial benefit from using these indexes. For many queries the Path index can provide additional benefit beyond what the QName index does, with a small additional cost in terms of index size. We also described some other index-based optimizations that Lux applies.
The indexing techniques described here are not unique to Lux. Although we're not aware of any existing use of proximity queries to match path constraints, it's a natural enough idea and is almost certainly in use in other systems as well. The main innovation here is the application of XML-unaware indexing technology to accelerate XML-aware queries, and the new combination of existing open source software packages to provide a reliable and powerful indexing and query system. Leveraging existing technology decreases the amount of code that needs to be maintained and tested, and leads to a high quality product with less effort than might otherwise be required.
References
Exploring the Unknown, Micah Dubinko, 2012 Balisage conference proceedings, doi:https://doi.org/10.4242/BalisageVol8.Dubinko01.
SQL Server XML index documentation
Oracle XML index documentation