1. Is XPath 1.0 a full programming language?
Does XPath 1.0[XPath1.0] have all necessary features to be used as a complete, self-sustained programming language?
The facts summarized in this table show that XPath 1.0 lacks many important features of a programming language.
Table I
| Capability | Presence | Remarks |
|---|---|---|
| Define variables | No. | Variables references can be part of XPath 1.0 expressions, but such variables must be defined by the host language (various PLs, DOM, or XSLT[XSLT1.0]). |
| Define and use range/outer-context variables. | No. | In an XSLT context the function current() provides a limited capability
of an outer-context variable.
|
| Define its own functions. | No. | Only XPath system functions or functions defined in the host-provided context
(such as generate-id() ) can be referenced.
|
| Work with sequences of items. | No. | Only the notion of a nodeset is defined. No support for sequences containing a non-node, or of nodes that can occur more than once and/or in any order. |
| Define own callable units. | No. | |
| Specify that a function should be executed on every selected node. | No. | |
| Strong typing. | No. | XPath 1.0 is a weakly-typed language. |
2. Is XPath 2.0 a full programming language?
Does XPath 2.0[XPath2.0] have all necessary features to be used as a complete, self-sustained programming language?
The facts summarized in this table show that XPath 2.0, while having strong typing, the capability to define its own variables and operations on sequences, still lacks some important features of a programming language, such as its own callable units of execution.
Table II
| Capability | Presence | Remarks |
|---|---|---|
| Define variables. | Yes, but limited. | Variables can be defined within an XPath 2.0 expression. It is impossible to define a variable whose value is a sequence. |
| Define and use range/outer-context variables. | Yes. | |
| Define its own functions. | No. | Only XPath system functions or functions defined in the host-provided context (such as functions defined in XSLT[XSLT2.0] or in XQuery[XQuery1.0]) can be referenced. |
| Work with sequences of items. | Yes. | XPath 2.0 supports sequences whose items can be non-nodes, or nodes that can occur more than once and/or in any order. |
| Define own callable units. | No. | |
| Specify that a function should be executed on every selected node. | Yes. | /a/b/c/string-length() is legal
|
| Specify that a function should be executed on every item in a sequence. | No. | While /a/b/c/string-length() is legal, it isn’t allowed to use:
('London', 'New York', 'Paris')/string-length()
|
| Strong typing. | Yes. | XSD type constructors, cast as, castable as, instance of
|
3. The Function Library Author’s Dilemma
There are examples of useful function libraries that have a separate version for XSLT2.0[XSLT2.0] and a separate version for XQuery[XQuery1.0]. There are other function libraries, written only for use in one of these two languages. A real-world example of a function library with both XSLT and XQuery versions is the FunctX library by Priscilla Walmsley[Walmsley].
While a function library author has the goal to produce his library for the widest possible audience, writing one separate version of the library for XSLT and another separate version for XQuery is problematic:
-
The time required to produce two versions of the library – for use from two different languages, may be significantly (up to twice) bigger than the time for producing a single version.
-
If the time necessary to produce two different versions of the library could be used for producing only one version, then more functions could be written and included in this library.
-
Having two versions for the same set of functions is redundant and results in all anomalies of redundancy.
-
Maintaining two different versions of the same set of functions is challenging – it is difficult to maintain the two versions in synch, and the required time to do so is significantly greater than maintaining a single library.
Due to these problems, some libraries would only have one single version. The libraries that have two versions could have included more useful functions, or could have become available sooner, if they had been written in a single version only.
“Copy and paste portability” has never been achieved with XPath 2.0 to the extent to be really useful, because the language lacks the ability to define its own callable units and because it cannot define its own variables that contain a sequence, and it isn’t possible to produce a new XML document / node by an XPath 2.0 expression.
4. New capabilities in XPath 3.0
The next table shows some of the significant new features of XPath 3.0[XPath3.0]:
Table III
| Capability | Presence | Remarks |
|---|---|---|
| Define variables | Yes. | In addition to the variable definition available in XPath 2.0, XPath 3.0 makes it possible to define in a “let clause” a variable whose value is a sequence. |
| Define and use range/outer-context variables. | Yes. | As in XPath 2.0. |
| Work with sequences of items. | Yes. | As in XPath 2.0. |
| Define own callable units. | Yes. | Inline function items. |
| Specify that a function should be executed on every selected node. | Yes. | As in XPath 2.0. |
| Specify that a function should be executed on every item in a sequence. | Yes. | The ! (simple mapping) operator.
|
| Strong typing. | Yes. | As in XPath 2.0. |
| Define its own functions. | Yes. | This is one of the most significant new features of XPath 3.0, based on the “function item” type as defined in the XDM[XDM3.0]. Only “inline function items” (anonymous functions) can be defined. Typically, these are defined as the content of a variable, which then can be used as a function. |
| Higher Order Functions (HOFs). | Yes. | A function item is a first class object. It can be passed as a parameter or returned as a result of calling a function. It is possible to express such well-known FP techniques as functional composition, partial function application, creation of closures. |
| Can recursive anonymous functions be specified within an XPath expression? | Yes. | Shown later in this paper. |
| Can robust recursion of anonymous functions be implemented? | Yes. | Shown later in this paper. |
| Can a new XML document or node be created within an XPath expression? | Yes. | Shown later in this paper. |
| Can new data types be created in an XPath expression? | Yes. | Shown later in this paper. |
In the next sections we give examples of using XPath 3.0 to specify functional composition, partial application, closures, anonymous function recursion and robust recursion. Then we provide an example of specifying a new data type – the Binary Search Tree. We show how a new XML document can be created with an XPath 3.0 expression. Finally, we provide an example of a complete XML processing application written entirely in XPath.
4.1 Creating and using an anonymous function in an XPath expression. HOFs.
In XPath 3.0 one can define inline (anonymous) functions and then provide arguments for their execution in a function call simply like this:
let $incr :=
function($n) {$n+1}
return $incr(2)
Or, as recommended alternative, define the same function in a strongly typed way:
let $incr :=
function($n as xs:integer) as xs:integer
{
$n +1
}
return
$incr(2)
When either of these two expressions is evaluated, the result is: 3.
The remaining examples in this paper use strong typing.
The ability to define a function as a pure XPath 3.0 expression is one of the most important additions to the XPath Data Model (XDM)[XDM3.0].
The function has no name and is the value of the $incr variable. The
function definition has a strongly typed argument and a strongly typed result – in
this case both the argument and the result must be of type xs:integer.
The body of the function is an XPath expression of type
xs:integer
The scope of the function is the let clause where it is defined and the
corresponding return clause.
Most importantly, in XPath 3.0 one can define Higher-Order Functions (HOFs)[HOF]. By definition, a higher order function has an argument which itself is a function, or produces a function as its result.
Here is a complete example of defining and calling a HOF within an XPath expression:
let $process :=
function($s as xs:string, $fun as function(xs:string) as xs:string)
as xs:string
{
$fun($s)
},
$lower :=
function($s as xs:string) as xs:string
{
lower-case($s)
}
,
$reverse :=
function($s as xs:string) as xs:string
{
codepoints-to-string(reverse(string-to-codepoints($s)))
}
return
('lower: ', $process('HELLO', $lower),
', reverse: ', $process('HELLO', $reverse))
The function $process()takes two arguments: a string, and a function
that takes a string and produces a string. The result returned by
$process()is a string.
Then, in the same let clause two functions are defined, each taking
a string and producing a string: $lower() and $reverse().
In the return clause $process() is called twice, with “HELLO” as the
same first argument, and with the $lower() function as the second
argument in the first call to $process() and $reverse()
function as the second argument in the second call to $process().
When the above expression is evaluated, the result is:
lower: hello , reverse: OLLEH
4.2 Function composition
By definition, the functional composition[FuncComp] of two functions g(x) and h(y)
is a third function f(x) such that f(x) = h(g(x))
We can specify a function, which takes as its parameters two other functions, and produces as its result the functional composition of its two arguments:
$compose :=
function($f as function(), $g as function())
as function()
{
function($x as item()*)
{
$g($f($x))
}
}
And we can use the so defined function in the following expression:
let $compose :=
function($f as function(), $g as function())
as function()
{
function($x as item()*)
{
$g($f($x))
}
},
$lower :=
function($s as xs:string) as xs:string
{
lower-case($s)
}
,
$reverse :=
function($s as xs:string) as xs:string
{
codepoints-to-string(reverse(string-to-codepoints($s)))
}
return
$compose($reverse, $lower)('HELLO')
The result of evaluating this expression is:
olleh
4.3 Partial application of a function
One definition of partial application[PartApp] is the following:
“Partial function application is the ability to take a function of many parameters and apply arguments to some of the parameters to create a new function that needs only the application of the remaining arguments to produce the equivalent of applying all arguments to the original function.”
XPath 3.0 has a natural way of specifying partial application.
f(3, ?)is a new function
g(x), such that for all allowed values of x
the following holds:
g(x) = f(3, x)
Using partial application, we can re-define the increment() function
in the following way:
let $plus :=
function($m as xs:integer, $n as xs:integer) as xs:integer
{
$m + $n
},
$incr :=
function($n as xs:integer) as xs:integer
{
$plus(1, ?)($n)
}
return
$incr(2)
When this XPath 3.0 expression is evaluated, the result is 3.
In the above expression the partial application of $plus() on
binding its first argument to 1 is defined simply as:
$plus(1, ?)The ‘
?’ character is
called argument placeholder and is used to denote
free (still not bound) arguments.
4.4 Closures
By definition “a closure[Closure] is a function produced by another function and the produced function contains data from the producing function.”
Here is a complete example:
let $greet :=
function($greeting as xs:string)
as function(xs:string) as xs:string
{
function($name as xs:string) as xs:string
{
$greeting || $name || '! '
}
},
$hello := $greet('Hello: ')
return
($hello ('John'), $hello ('Peter') )
Note that the outer function $greet() returns as its result the inner
function and injects into the body of the inner function some of its own (outer
function’s) data – the value of its $greeting argument.
When the above expression is evaluated, the result is:
Hello: John! Hello: Peter!
Here is another example. Let’s have this XML document:
<Books>
<Book>
<Title>Six Great Ideas</Title>
<Author>Mortimer J. Adler</Author>
</Book>
<Book>
<Title>The Society of Mind</Title>
<Author>Marvin Minsky</Author>
</Book>
</Books>
We want to have a function that has only one argument – a book’s title and returns the author of the book with this title. Somehow this function should have the above XML document already injected in its definition:
let $lookup :=
function($books as element())
as function(xs:string) as xs:string?
{
function($bookTitle as xs:string) as xs:string?
{
$books/Book[Title eq $bookTitle]/Author
}
},
$author := $lookup(/Books)
return
$author('The Society of Mind')
The wanted function ($author()) is created by the function
$lookup() by injecting into it some of its own content – the top
element of the XML document to be searched. The result is:
Marvin Minsky
4.5 Can Anonymous functions be recursive?
Such a question seems odd – if a recursive function[Recurs] is one that calls itself by name, then how can an anonymous function be recursive, having no name?
This seems to be a stopping problem when trying to write XPath 3.0 inline function items that process long sequences or other, recursive data structures. So serious a problem, that some people[Snelson][Snelson2] even raised the question of amending the XPath Data Model and altering the XPath 3.0 syntax in order to allow an anonymous function to call itself.
As it turns out, a natural solution exists, without the need to change anything[Nova].
Let us take a concrete problem: Write an XPath 3.0 inline function, that given a
positive integer n, produces the value of n! (The
factorial of n).
As a first attempt, let us analyze this code:
let $f := function($n as xs:integer,
$f1 as function(xs:integer) as xs:integer
) as xs:integer
{
if($n eq 0)
then 1
else $n * $f1($n -1, $f1)
}
return
$f(5, $f)
What happens here?
An inline function cannot call itself by name, because it doesn’t have a name. What we still can do, though, is to pass the function as an argument to itself.
The only special thing to notice here is how the processing is initiated:
$f(5, $f)calling the function and passing it to itself.
Such initiation may seem weird to a caller and is also error-prone. This is why we need to further improve the solution so that no weirdness remains on the surface:
let $f := function($n as xs:integer,
$f1 as function(xs:integer,
function()) as xs:integer
) as xs:integer
{
if($n eq 0)
then 1
else $n * $f1($n -1, $f1)
},
$F := function($n as xs:integer) as xs:integer
{
$f($n, $f)
}
return
$F(5)
Thus we produced an inline, anonymous function $F, which given an
argument $n, produces $n!
4.6 Robust Recursion
While the described recursion technique works well with relatively small values
for n, we run into problems when n becomes bigger.
Let’s see this based on another example – calculating the sum of a sequence of numbers:
let $f := function($nums as xs:double*,
$f1 as function(xs:double*, function())
as xs:double
) as xs:double
{
if(not($nums[1]))
then 0
else $nums[1] + $f1(subsequence($nums,2), $f1)
},
$F := function($nums as xs:double*) as xs:double
{
$f($nums, $f)
}
return
$F(1 to 10)
This calculates correctly the sum of the numbers 1 to 10 –
the result is: 55However, if we try:
$F(1 to 100)the result is the following Saxon 9.4.6EE exception:
Error on line 22
Too many nested function calls. May be due to infinite recursion.
Transformation failed: Run-time errors were reported
So, what happens here? Most readers would have guessed by now — our old Stack Overflow (not the site) exception.
Is there any way to avoid this exception?
One could rely on the smartness of the XSLT processor to do this. A slight fraction of XSLT processors recognize a limited kind of tail recursion and implement it using iteration, thus avoiding recursion.
Let us refactor the above code into a tail-recursive one (the last thing the function does is invoke a function):
let $f := function($nums as xs:double*,
$accum as xs:double,
$f1 as
function(xs:double*, xs:double, function())
as xs:double
) as xs:double
{
if(not($nums[1]))
then $accum
else $f1(subsequence($nums,2), $accum+$nums[1], $f1)
},
$F := function($nums as xs:double*) as xs:double
{
$f($nums, 0, $f)
}
return
$F(1 to 100)
Saxon[Saxon] is well-known for carrying out tail-recursion optimization, however it still raises the stack-overflow exception for the above, tail-recursive code. Why?
Here is the Wikipedia definition[TailCall] of tail recursion:
“In computer science, a tail call is a subroutine call that happens inside another procedure as its final action; it may produce a return value which is then immediately returned by the calling procedure. The call site is then said to be in tail position, i.e. at the end of the calling procedure. If any call that a subroutine performs, such that it might eventually lead to this same subroutine being called again down the call chain, is in tail position, such a subroutine is said to be tail-recursive”
At present, the XSLT/XPath processors that do recognize some kind of tail recursion typically do so if a function/template calls itself by name.
There is no record that any of them handles the case when the tail call is to another function (Michael Kay, author of Saxon[Saxon], shared on the Saxon mailing list that Saxon correctly handles any type of tail calls (not only calls to the same named template) for templates, but doesn’t do so in the case of functions).
So, what can we do in this situation? One decision is to wait until some processor starts handling any type of tail call inside functions.
Fortunately, there is another option: use the DVC (Divide and Conquer) technique[DivConq] for minimizing the maximum depth of nested recursion calls.
The idea is to split the sequence into subsequences (usually two) of roughly the same length, recursively process each subsequence, and then combine the results of processing each individual subsequence.
Here is the above code, re-written [Nova2] to use DVC:
let $f := function($nums as xs:double*,
$f1 as function(xs:double*, function())
as xs:double
) as xs:double
{if(not($nums[1]))
then 0
else if(not($nums[2]))
then $nums[1]
else
let $half := count($nums) idiv 2
return
$f1(subsequence($nums,1, $half), $f1)
+
$f1(subsequence($nums, $half+1), $f1)
},
$F := function($nums as xs:double*) as xs:double
{
$f($nums, $f)
}
return
$F(1 to 10000)
Sure enough, this time we get the result without any exception being thrown:
5.0005E7
Using this technique, the maximum recursion depth is Log2(N) — thus
for processing a sequence with 1M (one million elements) the maximum
recursion depth is just 19.
Thus, the DVC technique is a tool that can be immediately used to circumvent the lack of intelligence of current XPath 3.0 processors when dealing with tail-call optimization.
4.7 Producing a new XML document or element
Can an XPath expression produce a new XML document? Say, from the Books XML document used before, can an XPath expression produce this XML document:
<Person>Marvin Minsky</Person>“No way!” will tell you any XPath specialist. And they would be right for XPath 1.0 or 2.0.
Remarkably, we can produce the above new XML document with the following XPath 3.0 expression:
parse-xml(concat('<Person>', (//Author)[last()], '</Person>'))
When this XPath 3.0 expression is evaluated, the result is:
<Person>Marvin Minsky</Person>
To see that we have really produced a new document we evaluate this expression:
parse-xml(concat('<Person>', (//Author)[last()], '</Person>'))/*/text()
and sure enough, the result is: Marvin Minsky
5. Complete XPath 3.0 modules and applications
We now have the necessary knowledge to produce a complete module or XML processing application within a single XPath 3.0 expression.
The problem we are solving in this chapter is to define a new data-type – the Binary Search Tree (BST). The code is implemented entirely in XPath. An advantage of an “XPath-only” definition is that it can be used (hosted) in many programs—it can be hosted in XSLT programs, in XQuery programs, and in any other programming language that hosts XPath. Thus “XPath-only” data-type definitions or, more generally, libraries of XPath functions, are highly portable and reusable.
A BST[BST] as defined here can process an XML document and represent its data as a binary search tree. A BST can implement “find/insert/delete a node” operations much more efficiently (with logarithmic time complexity) than in the case when the nodes are processed in a linear fashion.
Table IV
Brief efficiency analysis
|
It is a well-known, proven fact that find/insert/delete operations in a
balanced binary tree can be implemented with time complexity of
When processing in a linear fashion two sequences of data items:
Compare this to having two balanced binary search trees |
In the rest of this paper we are solving this real-world problem: Find all bank transactions within a given range of dates.
Example: the following XML document contains a list of bank transactions (withdrawals and deposits). Each transaction is stamped with a date. The transactions are in no particular chronological order:
<Transactions>
<transaction date="2012-03-01">
<withdrawal>100</withdrawal>
</transaction>
<transaction date="2012-01-15">
<deposit>200</deposit>
</transaction>
<transaction date="2012-05-01">
<deposit>100</deposit>
</transaction>
<transaction date="2012-02-01">
<withdrawal>50</withdrawal>
</transaction>
<transaction date="2012-06-01">
<deposit>100</deposit>
</transaction>
<transaction date="2012-04-01">
<deposit>100</deposit>
</transaction>
<transaction date="2012-01-01">
<deposit>25</deposit>
</transaction>
</Transactions> If we could represent the above XML document as a
binary search tree where for each node (transaction), the date of its left child
(transaction) node is less than the (parent) node’s date and the date of its right
child
(transaction) node is greater than the (parent) node’s date. Then such a binary search
tree be graphically represented as below: 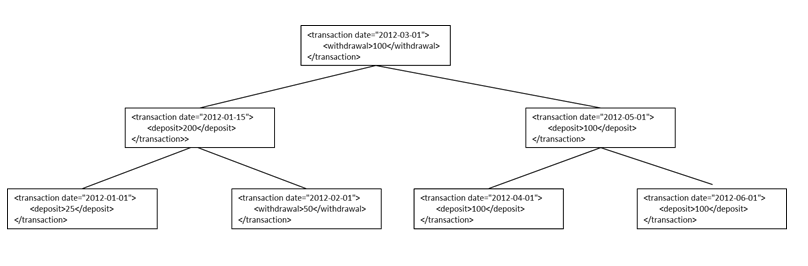
Problem: Find all the transactions in the range 2012-03-15 to 2012-05-15.
This problem can be solved efficiently now that the transactions are stored in a binary tree. (The more balanced the binary search tree is, the more efficient is a BST-based solution.)
The following pseudo-code (an initial version of which and the code below was first
produced by
Roger Costello [Costello]) that shows how to find the wanted transactions
(start date >= 2012-03-15, end date <= 2012-05-15):
Return a sequence of the following nodes:
If the value of the root node equals the start date, then:
-
The root node.
-
The result of recursing on the right subtree.
If the value of the root node equals the end date, then:
-
The result of recursing on the left subtree.
-
The root node.
If the value of the root node is between the start and end date, then:
-
The result of recursing on the left subtree.
-
The root node.
-
The result of recursing on the right subtree.
If the value of the root node is less than the start date, then:
-
The result of recursing on the right subtree,
If the value of the root node is greater than the end date, then:
-
The result of recursing on the left subtree.
Table V
XSLT/XQuery or XPath?
|
The code in this chapter can be implemented using XSLT or XQuery -defined functions. One would favor an XPath-only solution because:
|
$find-range-of-transactions :=
function( $tree as function()*,
$start-date as xs:date,
$end-date as xs:date
)
{
$find-range-of-transactions-helper
( $tree,
$start-date,
$end-date,
$find-range-of-transactions-helper)
}
The function’s name is find-range-of-transactions. This is a recursive
function. As shown previously, implementing recursion using anonymous functions requires
a “helper” function. Here is the helper function
find-range-of-transactions-helper():
$find-range-of-transactions-helper :=
function( $tree as function()*,
$start-date as xs:date,
$end-date as xs:date,
$find-range-of-transactions-helper
)
as element(transaction)*
{
if (empty($tree)) then ()
else
if (xs:date($root($tree)/@date) eq $start-date)
then
(
$root($tree),
$find-range-of-transactions-helper
( $right($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper)
)
else if (xs:date($root($tree)/@date) eq $end-date)
then
(
$find-range-of-transactions-helper
( $left($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper),
$root($tree)
)
else
if ((xs:date($root($tree)/@date) gt $start-date)
and
(xs:date($root($tree)/@date) lt $end-date)) then
(
$find-range-of-transactions-helper
( $left($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper),
$root($tree),
$find-range-of-transactions-helper
( $right($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper)
)
else
if (xs:date($root($tree)/@date) lt $start-date) then
(
$find-range-of-transactions-helper
( $right($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper)
)
else
if (xs:date($root($tree)/@date) gt $end-date) then
(
$find-range-of-transactions-helper
( $left($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper)
)
else ()
}
As tree-nodes are inserted into the binary tree, a comparison is made between the tree-node being inserted and the tree’s root node. How should the comparison be done? That depends on the data-type of the items stored in a tree. Consequently, the “insert function” must be provided an appropriate “comparator function.” For our bank transactions example, the comparison is done based on the date attribute. Here is an appropriate comparator function:
$transaction-less-than-comparator :=
function($arg1 as element(transaction),
$arg2 as element(transaction)
) as xs:boolean
{
xs:date($arg1/@date) lt xs:date($arg2/@date)
}
The value of the variable is an anonymous function. The function takes two arguments – both transaction elements – and returns true if the date of the first transaction is less than the date of the second transaction.
In this paper we define a binary search tree is a set of these functions:
-
create: create an empty tree.
-
root: return the value of the root node.
-
left: return the left subtree.
-
right: return the right subtree.
-
empty: return true if the tree is empty, false otherwise.
-
insert: insert an item into the tree, with comparison done using a comparator (see above).
-
print: serialize the tree as XML document.
-
populate: create a BST from a sequence of items.
Below is the complete XPath code for both the BST type definition and the functions that use this data-type to actually solve the problem of finding all the bank transactions between a given start date and a given end date.
let
(:
The purpose of create is to return an empty tree.
It returns a sequence of functions,
- the first function represents the root of a tree,
- the second function represents the left subtree,
- and the third function represents the right subtree.
The value of each function is an empty sequence.
:)
$create := (
function() { () } (: root :),
function() { () } (: left :),
function() { () } (: right :)
),
(:
empty() returns a boolean value,
indicating whether $tree is empty.
$tree is empty in either of these two cases:
1. $tree is the empty sequence (it doesn't contain any functions).
2. $tree contains a sequence of three functions, but the first
function - representing the root - is empty (i.e., if you invoke the
first function it returns the empty sequence).
:)
$empty := function($tree as function()*)
{
empty($tree) or empty($tree[1]())
},
(:
root()returns the value of the root node.
This function takes one argument, $tree. Since $tree
is represented by a sequence of functions, returning the
value of the root node actually means returning the value of
the function that corresponds to the root node.
If $tree is empty then the empty sequence is returned. Otherwise
the *value* of executing the first function in $tree is returned (recall
that a tree is represented by a sequence of functions, the first
function representing the root of the tree).
Note: $tree[1] is the first function whereas
$tree[1]() is the *value* of executing the first function.
:)
$root := function($tree as function()*)
{
if ($empty($tree))
then ()
else $tree[1]()
},
(:
left()returns the left subtree.
This function takes one argument, $tree. Since $tree is represented
by a sequence of functions, returning the left subtree
actually means returning the value of executing the function that corresponds
to the left subtree.
If $tree is empty then the empty sequence is returned. Otherwise
the *value* of executing the second function in $tree is returned (recall
that a tree is represented by a sequence of functions, the second
function representing the left subtree).
Note: $tree[2] is the second function whereas
$tree[2]() is the *value* of executing the second function.
:)
$left := function($tree as function()*)
{
if ($empty($tree)) then ()
else
if ($empty($tree[2])) then ()
else $tree[2]()
},
(:
right() returns the right subtree.
This function takes one argument, $tree. Since $tree is represented
by a sequence of functions, returning the right subtree actually
means returning the value of executing the function that corresponds to the
right subtree.
If $tree is empty then the empty sequence is returned. Otherwise
the *value* of executing the third function in $tree is returned (recall
that a tree is represented by a sequence of functions, the third
function representing the right subtree).
:)
$right := function($tree as function()*)
{
if ($empty($tree)) then ()
else
if ($empty($tree[3])) then ()
else $tree[3]()
},
(:
As tree-nodes are inserted into a BST, a comparison is made between
the value being inserted and the value in the tree's root node. How should
the comparison be done? That depends on the type of the data contained in a tree-node.
Comparing two integers is different than comparing two tree fragments.
So, the insert function must be provided with an appropriate comparator. For
the case of bank transactions, a date comparison is needed.
Here is an appropriate comparator function:
:)
$transaction-less-than-comparator :=
function( $arg1 as element(transaction),
$arg2 as element(transaction)
) as xs:boolean
{
xs:date($arg1/@date) lt xs:date($arg2/@date)
},
$numeric-less-than-comparator :=
function( $arg1 as xs:decimal,
$arg2 as xs:decimal
) as xs:boolean
{
$arg1 lt $arg2
},
(:
insert() takes a $tree (BST) and a $item and produces a new BST that is the result
of inserting $item as a tree-node in $tree. A BST is a persistent (functional) data-type.
Insertions or deletions are never done “in place” – instead a new BST is produced.
The new node is inserted at:
- if $tree is empty then as root node.
- if the value of $item is less than the value of the root node then
the new tree-node is inserted into the left subtree (note the recursive definition)
- else the new tree-node is inserted into the right subtree (again note the recursive
definition)
Here are the steps taken if $tree is empty:
- $item specified to be the result of the root function. That is, the root function,
if invoked, it returns $item.
- A left function is created such that, if invoked, will return an empty subtree.
- A right function is created such that, if invoked, will return an empty subtree.
The insert function is recursive. Recursion with anonymous functions requires
a helper function as discussed before.
:)
$insert-helper :=
function( $tree as function()*,
$item as item(),
$less-than-comparator as function(item(), item()) as xs:boolean,
$insert-helper
)
{
if ($empty($tree)) then
(
function() {$item} (: root :),
function() {()} (: left :),
function() {()} (: right :)
)
else if ($less-than-comparator($item, $root($tree))) then
(
function() {$root($tree)} (: root :),
function() {$insert-helper( $left($tree),
$item,
$less-than-comparator,
$insert-helper)
} (: left :),
function() {$right($tree)} (: right :)
)
else
(
function() {$root($tree)} (: root :),
function() {$left($tree)} (: left :),
function() {$insert-helper( $right($tree),
$item,
$less-than-comparator,
$insert-helper)
} (: right :)
)
},
$insert :=
function ( $tree as function()*,
$item as item(),
$less-than-comparator as function(item(), item()) as xs:boolean
)
{
$insert-helper($tree, $item, $less-than-comparator, $insert-helper)
},
(:
print() produces an XML document that represents the BST $tree.
The XML document produced by print() consists of:
1. A root element that represents the value of executing the root function.
2. A left element that represents the value of print() on the left subtree
(note the recursive definition).
3. A right element that represents the value of print() on the right subtree
(note the recursive definition).
The $print-helper function produces the markup
as a string and then the $printer function converts
this string into an XML document by calling the parse-xml() function.
:)
$print-helper :=
function ( $tree as function()*,
$print-helper
)
as xs:string?
{
if (not($empty($tree))) then
concat('<tree>',
'<root>',
$root($tree),
'</root>',
'<left>',
$print-helper($left($tree),$print-helper),
'</left>',
'<right>',
$print-helper($right($tree),$print-helper),
'</right>',
'</tree>'
)
else ()
},
$print := function ($tree as function()*)
{parse-xml($print-helper($tree, $print-helper))/*},
(:
populate() produces a new tree from its BST argument $tree by inserting
the value of the head() of the sequence $items onto $tree and then inserting
the tail() of the sequence $items onto the result.
:)
$populate-helper :=
function ( $tree as function()*,
$items as item()*,
$less-than-comparator as function(item(), item()) as xs:boolean,
$populate-helper
)
{
if (empty($items)) then $tree
else
$populate-helper( $insert($tree, $items[1], $less-than-comparator),
$items[position() gt 1],
$less-than-comparator,
$populate-helper
)
},
$populate :=
function( $tree as function()*,
$items as item()*,
$less-than-comparator as function(item(), item()) as xs:boolean
)
{$populate-helper($tree, $items, $less-than-comparator, $populate-helper)},
(:
Finally, the solution of the original problem.
Task: find all the bank transactions in the range 2012-03-15 to 2012-05-15.
:)
$find-range-of-transactions-helper :=
function( $tree as function()*,
$start-date as xs:date,
$end-date as xs:date,
$find-range-of-transactions-helper
)
as element(transaction)*
{
if (empty($tree)) then ()
else
if (xs:date($root($tree)/@date) eq $start-date) then
(
$root($tree),
$find-range-of-transactions-helper
( $right($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper)
)
else
if (xs:date($root($tree)/@date) eq $end-date) then
(
$find-range-of-transactions-helper
( $left($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper),
$root($tree)
)
else
if ((xs:date($root($tree)/@date) gt $start-date)
and
(xs:date($root($tree)/@date) lt $end-date)) then
(
$find-range-of-transactions-helper
( $left($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper),
$root($tree),
$find-range-of-transactions-helper
( $right($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper)
)
else
if (xs:date($root($tree)/@date) lt $start-date) then
(
$find-range-of-transactions-helper
( $right($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper)
)
else
if (xs:date($root($tree)/@date) gt $end-date) then
(
$find-range-of-transactions-helper
( $left($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper)
)
else ()
},
$find-range-of-transactions :=
function($tree as function()*,
$start-date as xs:date,
$end-date as xs:date
)
{
$find-range-of-transactions-helper
( $tree,
$start-date,
$end-date,
$find-range-of-transactions-helper)
}
(: At last, we finalize this big, outermost *let* clause with a *return* clause
that expresses the intent of the users of the BST data-type.
We want to get all transactions in the period:
15th March 2012 to 15th May 2012.
:)
return (
$find-range-of-transactions
( $populate((), //transaction, $transaction-less-than-comparator),
xs:date('2012-03-15'),
xs:date('2012-05-15')
)
)
6. Analysis
This example shows how a new data-type, or generally a library of functions can be defined in an XPath 3.0 expression and then used by a client in the same XPath expression:
-
The definitions of the library functions are in the “let clause”.
-
The expressions that use these library functions are in the “return clause”.
We also experienced some inconvenience and that helped us specify a wish-list for a future version of XPath:
-
Our example contains one huge let-return expression. For better modularity it would have been nice to place all the binary search tree functions (create, left, right, insert, etc.) into their own “module” which could then be “imported” by the bank transaction functions. Unfortunately, XPath does not support this. Recommendation for a future XPath version: Support XPath expression files and an import clause to collect such expressions from files in a desired new, client XPath program.
-
Our example implemented binary search trees as a sequence of functions. While this works okay, it would be much more precise and elegant if XPath had a “tuple type” so that a tree could be simply defined as a tuple: tree is a tuple (root, left, right). Recommendation for a future XPath version: Support a tuple type, so that the result type of various functions (such as the creation of a tree) can be more precisely specified than just a sequence of function items.
-
The Map data-type could further boost the expressiveness of XPath, making the language even more convenient. The Map data-type is already part of the latest published working draft of XSLT 3.0 [XSLT3.0] and has been warmly accepted by the XML developers community.
-
Introducing generics would further strengthen the expressive power and preciseness of XPath.
7. Consuming an XPath function library from XSLT 3.0 and XQuery 3.1
It is possible in XSLT 3.0 to conveniently consume an XPath function library directly from a text file.
Here is an example:
A simple function library (file SimpleLibraryAsMap.xpath):
let
$incr := function($n as xs:integer)
{$n +1},
$mult := function($m as xs:integer, $n as xs:integer)
{$m * $n},
$decr := function($n as xs:integer)
{$n -1},
$idiv := function($m as xs:integer, $n as xs:integer)
{$m idiv $n}
(: Provide the function libary as a map:)
return
map {
'incr' := $incr,
'mult' := $mult,
'decr' := $decr,
'idiv' := $idiv
}
XSLT transformation that uses this function library:
<xsl:stylesheet version="3.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xsl:output omit-xml-declaration="yes" indent="yes"/>
<xsl:template match="/">
<!-- The Function Library -->
<xsl:variable name="vMath" as="map(*)">
<xsl:evaluate xpath="unparsed-text('SimpleLibraryAsMap.xpath')"/>
</xsl:variable>
<xsl:sequence select="'incr(3) = ', $vMath('incr')(3)"/>
</xsl:template>
</xsl:stylesheet>
The result is: "incr(3) = 4"
The "importing" of the library is done via the simple and powerful combination of the standard XPath 3.0 function unparsed-text() and the new XSLT 3.0 instruction <xsl:evaluate>
Consuming the function library from a map-cognizant XQuery processor is even simpler -- we just need to wrap the library as/into an XQuery module and then import this module in the consuming XQuery.
Conclusion
The powerful new capabilities in XPath 3.0 such as HOFs, inline functions, functional composition, partial application and closures, indirect and robust anonymous function recursion, own sequence-type variables and the ability to create new XML documents / nodes, turn XPath into a full-pledged, complete, modern XML programming language: the first to truly implement useful copy-paste code portability between XSLT and XQuery.
This gives the XML programmer the ability to write an application once and reuse it many times – standalone or included into code written in many other languages.
Function library author’s productivity is significantly increased, redundancy is eliminated, maintenance of dual sets of functions is no longer a problem.
A few finishing touches are needed such as adding tuples, generics and modularity support – either by the W3C or by proactive programmers.
Acknowledgement
Many thanks to Roger Costello, without whose work this paper would hardly be possible.
Appendix: The BST data type defined and consumed as a map
Here we show an easy way to consume from both XSLT and XQuery the BST function library residing at its own file
The BST XPath code (XPathFunctionLibrary.xpath) -- see how a map is created in the return clause:
let
(:
The purpose of create is to return an empty tree.
It returns a sequence of functions,
- the first function represents the root of a tree,
- the second function represents the left subtree,
- and the third function represents the right subtree.
The value of each function is an empty sequence.
:)
$create := (
function() { () } (: root :),
function() { () } (: left :),
function() { () } (: right :)
),
(:
empty() returns a boolean value,
indicating whether $tree is empty.
$tree is empty in either of these two cases:
1. $tree is the empty sequence (it doesn't contain any functions).
2. $tree contains a sequence of three functions, but the first
function - representing the root - is empty (i.e., if you invoke the
first function it returns the empty sequence).
:)
$empty := function($tree as function(*)*)
{
empty($tree) or empty($tree[1]())
},
(:
root()returns the value of the root node.
This function takes one argument, $tree. Since $tree
is represented by a sequence of functions, returning the
value of the root node actually means returning the value of
the function that corresponds to the root node.
If $tree is empty then the empty sequence is returned. Otherwise
the *value* of executing the first function in $tree is returned (recall
that a tree is represented by a sequence of functions, the first
function representing the root of the tree).
Note: $tree[1] is the first function whereas
$tree[1]() is the *value* of executing the first function.
:)
$root := function($tree as function(*)*)
{
if ($empty($tree))
then ()
else $tree[1]()
},
(:
left()returns the left subtree.
This function takes one argument, $tree. Since $tree is represented
by a sequence of functions, returning the left subtree
actually means returning the value of executing the function that corresponds
to the left subtree.
If $tree is empty then the empty sequence is returned. Otherwise
the *value* of executing the second function in $tree is returned (recall
that a tree is represented by a sequence of functions, the second
function representing the left subtree).
Note: $tree[2] is the second function whereas
$tree[2]() is the *value* of executing the second function.
:)
$left := function($tree as function(*)*)
{
if ($empty($tree)) then ()
else
if ($empty($tree[2])) then ()
else $tree[2]()
},
(:
right() returns the right subtree.
This function takes one argument, $tree. Since $tree is represented
by a sequence of functions, returning the right subtree actually
means returning the value of executing the function that corresponds to the
right subtree.
If $tree is empty then the empty sequence is returned. Otherwise
the *value* of executing the third function in $tree is returned (recall
that a tree is represented by a sequence of functions, the third
function representing the right subtree).
:)
$right := function($tree as function(*)*)
{
if ($empty($tree)) then ()
else
if ($empty($tree[3])) then ()
else $tree[3]()
},
$numeric-less-than-comparator :=
function( $arg1 as xs:decimal,
$arg2 as xs:decimal
) as xs:boolean
{
$arg1 lt $arg2
},
(:
insert() takes a $tree (BST) and a $item and produces a new BST that is the result
of inserting $item as a tree-node in $tree. A BST is a persistent (functional) data-type.
Insertions or deletions are never done “in place” – instead a new BST is produced.
The new node is inserted at:
- if $tree is empty then as root node.
- if the value of $item is less than the value of the root node then
the new tree-node is inserted into the left subtree (note the recursive definition)
- else the new tree-node is inserted into the right subtree (again note the recursive
definition)
Here are the steps taken if $tree is empty:
- $item specified to be the result of the root function. That is, the root function,
if invoked, it returns $item.
- A left function is created such that, if invoked, will return an empty subtree.
- A right function is created such that, if invoked, will return an empty subtree.
The insert function is recursive. Recursion with anonymous functions requires
a helper function as discussed before.
:)
$insert-helper :=
function( $tree as function(*)*,
$item as item(),
$less-than-comparator as function(item(), item()) as xs:boolean,
$insert-helper
)
{
if ($empty($tree)) then
(
function() {$item} (: root :),
function() {()} (: left :),
function() {()} (: right :)
)
else if ($less-than-comparator($item, $root($tree))) then
(
function() {$root($tree)} (: root :),
function() {$insert-helper( $left($tree),
$item,
$less-than-comparator,
$insert-helper)
} (: left :),
function() {$right($tree)} (: right :)
)
else
(
function() {$root($tree)} (: root :),
function() {$left($tree)} (: left :),
function() {$insert-helper( $right($tree),
$item,
$less-than-comparator,
$insert-helper)
} (: right :)
)
},
$insert :=
function ( $tree as function(*)*,
$item as item(),
$less-than-comparator as function(item(), item()) as xs:boolean
)
{
$insert-helper($tree, $item, $less-than-comparator, $insert-helper)
},
(:
print() produces an XML document that represents the BST $tree.
The XML document produced by print() consists of:
1. A root element that represents the value of executing the root function.
2. A left element that represents the value of print() on the left subtree
(note the recursive definition).
3. A right element that represents the value of print() on the right subtree
(note the recursive definition).
The $print-helper function produces the markup
as a string and then the $printer function converts
this string into an XML document by calling the parse-xml() function.
:)
$print-helper :=
function ( $tree as function(*)*,
$print-helper
)
as xs:string?
{
if (not($empty($tree))) then
concat('<tree>',
'<root>',
$root($tree),
'</root>',
'<left>',
$print-helper($left($tree),$print-helper),
'</left>',
'<right>',
$print-helper($right($tree),$print-helper),
'</right>',
'</tree>'
)
else ()
},
$print := function ($tree as function(*)*)
{parse-xml($print-helper($tree, $print-helper))/*},
(:
populate() produces a new tree from its BST argument $tree by inserting
the value of the head() of the sequence $items onto $tree and then inserting
the tail() of the sequence $items onto the result.
:)
$populate-helper :=
function ( $tree as function(*)*,
$items as item()*,
$less-than-comparator as function(item(), item()) as xs:boolean,
$populate-helper
)
{
if (empty($items)) then $tree
else
$populate-helper( $insert($tree, $items[1], $less-than-comparator),
$items[position() gt 1],
$less-than-comparator,
$populate-helper
)
},
$populate :=
function( $tree as function(*)*,
$items as item()*,
$less-than-comparator as function(item(), item()) as xs:boolean
)
{$populate-helper($tree, $items, $less-than-comparator, $populate-helper)}
(: Finally, make the function libary :)
return
map {'create' := $create,
'empty' := $empty,
'root' := $root,
'left' := $left,
'right' := $right,
'insert' := $insert,
'populate' := $populate,
'print' := $print,
'numeric-less-than-comparator' := $numeric-less-than-comparator
}
Here is the XSLT consuming code, that solves the bank transactions problem:
<xsl:stylesheet version="3.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xsl:output omit-xml-declaration="yes" indent="yes"/>
<xsl:template match="node()|@*">
<!-- The Tree Function Library -->
<xsl:variable name="vTree" as="map(*)">
<xsl:evaluate xpath="unparsed-text('XPathFunctionLibrary.xpath')"/>
</xsl:variable>
<xsl:sequence select=
"
(:
Finally, the solution of the original problem.
Task: find all the bank transactions in the range 2012-03-15 to 2012-05-15.
:)
let $find-range-of-transactions-helper :=
function( $tree as function(*)*,
$start-date as xs:date,
$end-date as xs:date,
$find-range-of-transactions-helper
)
as element(transaction)*
{
if (empty($tree)) then ()
else
if (xs:date($vTree('root')($tree)/@date) eq $start-date) then
(
$vTree('root')($tree),
$find-range-of-transactions-helper
($vTree('right')($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper)
)
else
if (xs:date($vTree('root')($tree)/@date) eq $end-date) then
(
$find-range-of-transactions-helper
($vTree('left')($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper),
$vTree('root')($tree)
)
else
if (
(xs:date($vTree('root')($tree)/@date) gt $start-date)
and
(xs:date($vTree('root')($tree)/@date) lt $end-date)) then
(
$find-range-of-transactions-helper
($vTree('left')($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper),
$vTree('root')($tree),
$find-range-of-transactions-helper
($vTree('right')($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper)
)
else
if (xs:date($vTree('root')($tree)/@date) lt $start-date) then
(
$find-range-of-transactions-helper
($vTree('right')($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper)
)
else
if (xs:date($vTree('root')($tree)/@date) gt $end-date) then
(
$find-range-of-transactions-helper
($vTree('left')($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper)
)
else ()
},
$find-range-of-transactions :=
function($tree as function(*)*,
$start-date as xs:date,
$end-date as xs:date
)
{
$find-range-of-transactions-helper
( $tree,
$start-date,
$end-date,
$find-range-of-transactions-helper)
},
(:
As tree-nodes are inserted into a BST, a comparison is made between
the value being inserted and the value in the tree's root node. How should
the comparison be done? That depends on the type of the data contained in a tree-node.
Comparing two integers is different than comparing two tree fragments.
So, the insert function must be provided with an appropriate comparator. For
the case of bank transactions, a date comparison is needed.
Here is an appropriate comparator function:
:)
$transaction-less-than-comparator :=
function( $arg1 as element(transaction),
$arg2 as element(transaction)
) as xs:boolean
{
xs:date($arg1/@date) lt xs:date($arg2/@date)
}
(: At last, we finalize this big, outermost *let* clause with a *return* clause
that expresses the intent of the users of the BST data-type.
We want to get all transactions in the period:
15th March 2012 to 15th May 2012.
:)
return (
$find-range-of-transactions
($vTree('populate')
((), //transaction, $transaction-less-than-comparator),
xs:date('2012-03-15'),
xs:date('2012-05-15')
)
) "/>
</xsl:template>
</xsl:stylesheet>
The BST XPath code -- as an XQuery module (XPathFunctionLibrary.xpath) -- see how a map is created in the return clause:
module namespace BST = "BST";
declare variable $BST:vTree :=
let
(:
The purpose of create is to return an empty tree.
It returns a sequence of functions,
- the first function represents the root of a tree,
- the second function represents the left subtree,
- and the third function represents the right subtree.
The value of each function is an empty sequence.
:)
$create := (
function() { () } (: root :),
function() { () } (: left :),
function() { () } (: right :)
),
(:
empty() returns a boolean value,
indicating whether $tree is empty.
$tree is empty in either of these two cases:
1. $tree is the empty sequence (it doesn't contain any functions).
2. $tree contains a sequence of three functions, but the first
function - representing the root - is empty (i.e., if you invoke the
first function it returns the empty sequence).
:)
$empty := function($tree as function(*)*)
{
empty($tree) or empty($tree[1]())
},
(:
root()returns the value of the root node.
This function takes one argument, $tree. Since $tree
is represented by a sequence of functions, returning the
value of the root node actually means returning the value of
the function that corresponds to the root node.
If $tree is empty then the empty sequence is returned. Otherwise
the *value* of executing the first function in $tree is returned (recall
that a tree is represented by a sequence of functions, the first
function representing the root of the tree).
Note: $tree[1] is the first function whereas
$tree[1]() is the *value* of executing the first function.
:)
$root := function($tree as function(*)*)
{
if ($empty($tree))
then ()
else $tree[1]()
},
(:
left()returns the left subtree.
This function takes one argument, $tree. Since $tree is represented
by a sequence of functions, returning the left subtree
actually means returning the value of executing the function that corresponds
to the left subtree.
If $tree is empty then the empty sequence is returned. Otherwise
the *value* of executing the second function in $tree is returned (recall
that a tree is represented by a sequence of functions, the second
function representing the left subtree).
Note: $tree[2] is the second function whereas
$tree[2]() is the *value* of executing the second function.
:)
$left := function($tree as function(*)*)
{
if ($empty($tree)) then ()
else
if ($empty($tree[2])) then ()
else $tree[2]()
},
(:
right() returns the right subtree.
This function takes one argument, $tree. Since $tree is represented
by a sequence of functions, returning the right subtree actually
means returning the value of executing the function that corresponds to the
right subtree.
If $tree is empty then the empty sequence is returned. Otherwise
the *value* of executing the third function in $tree is returned (recall
that a tree is represented by a sequence of functions, the third
function representing the right subtree).
:)
$right := function($tree as function(*)*)
{
if ($empty($tree)) then ()
else
if ($empty($tree[3])) then ()
else $tree[3]()
},
$numeric-less-than-comparator :=
function( $arg1 as xs:decimal,
$arg2 as xs:decimal
) as xs:boolean
{
$arg1 lt $arg2
},
(:
insert() takes a $tree (BST) and a $item and produces a new BST that is the result
of inserting $item as a tree-node in $tree. A BST is a persistent (functional) data-type.
Insertions or deletions are never done “in place” – instead a new BST is produced.
The new node is inserted at:
- if $tree is empty then as root node.
- if the value of $item is less than the value of the root node then
the new tree-node is inserted into the left subtree (note the recursive definition)
- else the new tree-node is inserted into the right subtree (again note the recursive
definition)
Here are the steps taken if $tree is empty:
- $item specified to be the result of the root function. That is, the root function,
if invoked, it returns $item.
- A left function is created such that, if invoked, will return an empty subtree.
- A right function is created such that, if invoked, will return an empty subtree.
The insert function is recursive. Recursion with anonymous functions requires
a helper function as discussed before.
:)
$insert-helper :=
function( $tree as function(*)*,
$item as item(),
$less-than-comparator as function(item(), item()) as xs:boolean,
$insert-helper
)
{
if ($empty($tree)) then
(
function() {$item} (: root :),
function() {()} (: left :),
function() {()} (: right :)
)
else if ($less-than-comparator($item, $root($tree))) then
(
function() {$root($tree)} (: root :),
function() {$insert-helper( $left($tree),
$item,
$less-than-comparator,
$insert-helper)
} (: left :),
function() {$right($tree)} (: right :)
)
else
(
function() {$root($tree)} (: root :),
function() {$left($tree)} (: left :),
function() {$insert-helper( $right($tree),
$item,
$less-than-comparator,
$insert-helper)
} (: right :)
)
},
$insert :=
function ( $tree as function(*)*,
$item as item(),
$less-than-comparator as function(item(), item()) as xs:boolean
)
{
$insert-helper($tree, $item, $less-than-comparator, $insert-helper)
},
(:
print() produces an XML document that represents the BST $tree.
The XML document produced by print() consists of:
1. A root element that represents the value of executing the root function.
2. A left element that represents the value of print() on the left subtree
(note the recursive definition).
3. A right element that represents the value of print() on the right subtree
(note the recursive definition).
The $print-helper function produces the markup
as a string and then the $printer function converts
this string into an XML document by calling the parse-xml() function.
:)
$print-helper :=
function ( $tree as function(*)*,
$print-helper
)
as xs:string?
{
if (not($empty($tree))) then
concat('<tree>',
'<root>',
$root($tree),
'</root>',
'<left>',
$print-helper($left($tree),$print-helper),
'</left>',
'<right>',
$print-helper($right($tree),$print-helper),
'</right>',
'</tree>'
)
else ()
},
$print := function ($tree as function(*)*)
{parse-xml($print-helper($tree, $print-helper))/*},
(:
populate() produces a new tree from its BST argument $tree by inserting
the value of the head() of the sequence $items onto $tree and then inserting
the tail() of the sequence $items onto the result.
:)
$populate-helper :=
function ( $tree as function(*)*,
$items as item()*,
$less-than-comparator as function(item(), item()) as xs:boolean,
$populate-helper
)
{
if (empty($items)) then $tree
else
$populate-helper( $insert($tree, $items[1], $less-than-comparator),
$items[position() gt 1],
$less-than-comparator,
$populate-helper
)
},
$populate :=
function( $tree as function(*)*,
$items as item()*,
$less-than-comparator as function(item(), item()) as xs:boolean
)
{$populate-helper($tree, $items, $less-than-comparator, $populate-helper)}
(: Finally, make the function libary :)
return
map {'create' := $create,
'empty' := $empty,
'root' := $root,
'left' := $left,
'right' := $right,
'insert' := $insert,
'populate' := $populate,
'print' := $print,
'numeric-less-than-comparator' := $numeric-less-than-comparator
}
;
Here is the XQuery consuming code, that solves the bank transactions problem:
import module namespace bst="BST" at "XPathFunctionLibrary.xpath";
declare variable $vDoc := doc('transactions.xml');
(: The Tree Function Library :)
(:
Finally, the solution of the original problem.
Task: find all the bank transactions in the range 2012-03-15 to 2012-05-15.
:)
let $find-range-of-transactions-helper :=
function( $tree as function(*)*,
$start-date as xs:date,
$end-date as xs:date,
$find-range-of-transactions-helper
)
as element(transaction)*
{
if (empty($tree)) then ()
else
if (xs:date($bst:vTree('root')($tree)/@date) eq $start-date) then
(
$bst:vTree('root')($tree),
$find-range-of-transactions-helper
($bst:vTree('right')($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper)
)
else
if (xs:date($bst:vTree('root')($tree)/@date) eq $end-date) then
(
$find-range-of-transactions-helper
($bst:vTree('left')($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper),
$bst:vTree('root')($tree)
)
else
if (
(xs:date($bst:vTree('root')($tree)/@date) gt $start-date)
and
(xs:date($bst:vTree('root')($tree)/@date) lt $end-date)) then
(
$find-range-of-transactions-helper
($bst:vTree('left')($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper),
$bst:vTree('root')($tree),
$find-range-of-transactions-helper
($bst:vTree('right')($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper)
)
else
if (xs:date($bst:vTree('root')($tree)/@date) lt $start-date) then
(
$find-range-of-transactions-helper
($bst:vTree('right')($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper)
)
else
if (xs:date($bst:vTree('root')($tree)/@date) gt $end-date) then
(
$find-range-of-transactions-helper
($bst:vTree('left')($tree),
$start-date,
$end-date,
$find-range-of-transactions-helper)
)
else ()
},
$find-range-of-transactions :=
function($tree as function(*)*,
$start-date as xs:date,
$end-date as xs:date
)
{
$find-range-of-transactions-helper
( $tree,
$start-date,
$end-date,
$find-range-of-transactions-helper)
},
(:
As tree-nodes are inserted into a BST, a comparison is made between
the value being inserted and the value in the tree's root node. How should
the comparison be done? That depends on the type of the data contained in a tree-node.
Comparing two integers is different than comparing two tree fragments.
So, the insert function must be provided with an appropriate comparator. For
the case of bank transactions, a date comparison is needed.
Here is an appropriate comparator function:
:)
$transaction-less-than-comparator :=
function( $arg1 as element(transaction),
$arg2 as element(transaction)
) as xs:boolean
{
xs:date($arg1/@date) lt xs:date($arg2/@date)
}
(: At last, we finalize this big, outermost *let* clause with a *return* clause
that expresses the intent of the users of the BST data-type.
We want to get all transactions in the period:
15th March 2012 to 15th May 2012.
:)
return (
$find-range-of-transactions
($bst:vTree('populate')
((), $vDoc//transaction, $transaction-less-than-comparator),
xs:date('2012-03-15'),
xs:date('2012-05-15')
)
)
References
[BST] Binary Search Tree as defined by Wikipedia, at: http://en.wikipedia.org/wiki/Binary_search_tree
[Closure] Closure (computer science) -- Wikipedia, at: http://en.wikipedia.org/wiki/Binary_search_tree
[Costello] Pearls of XSLT and XPath 3.0 Design, at: http://www.xfront.com/Pearls-of-XSLT-and-XPath-3-0-Design.pdf
[DivConq] Divide and conquer algorithm -- Wikipedia, at: http://en.wikipedia.org/wiki/Divide_and_conquer_algorithm
[FuncComp] Function composition -- Wikipedia, at: http://en.wikipedia.org/wiki/Function_composition
[Nova] Recursion with anonymous (inline) functions in XPath 3.0, at: http://dnovatchev.wordpress.com/2012/10/15/recursion-with-anonymous-inline-functions-in-xpath-3-0-2/
[HOF] Higher-order function -- Wikipedia, at: http://en.wikipedia.org/wiki/Higher-order_function
[Nova2] Recursion with anonymous (inline) functions in XPath 3.0 — Part II, at: http://dnovatchev.wordpress.com/2013/04/08/recursion-with-anonymous-inline-functions-in-xpath-3-0-part-ii/
[Nova3] The Binary Search Tree Data Structure–having fun with XPath 3.0, at: http://dnovatchev.wordpress.com/2012/01/09/the-binary-search-tree-data-structurehaving-fun-with-xpath-3-0/
[PartApp] Partial function application -- Wikipedia, at: http://rosettacode.org/wiki/Partial_function_application
[Recurs] Recursion (computer science) -- Wikipedia, at: http://en.wikipedia.org/wiki/Recursion_(computer_science)#Recursive_functions_and_algorithms
[Saxon] The Saxon XSLT/XQuery/XPath Processor, at: http://www.saxonica.com
[Snelson] Adding Recursive Inline Functions to XQuery 1.1 and XPath 2.1, at: http://john.snelson.org.uk/adding-recursive-inline-function-to-xquery-11
[Snelson2] W3C Bugzilla: Bug 8662 - [XQ31ReqUC] Requirement: Recursive inline functions , at: https://www.w3.org/Bugs/Public/show_bug.cgi?id=8662
[TailCall] Tail call -- Wikipedia, at: http://en.wikipedia.org/wiki/Tail_call
[Walmsley] FunctX XSLT 2.0 and XQuery 1.0 Function Libraries, at: http://www.functx.com/
[XDM3.0] XQuery and XPath Data Model 3.0, at: http://www.w3.org/TR/xpath-datamodel-30/
[XPath1.0] XML Path Language (XPath) Version 1.0, at: http://www.w3.org/TR/xpath/
[XPath2.0] XML Path Language (XPath) 2.0 (Second Edition), at: http://www.w3.org/TR/xpath20/
[XPath3.0] XML Path Language (XPath) 3.0, at: http://www.w3.org/TR/xpath-30/
[XSLT1.0] XSL Transformations (XSLT) Version 1.0, at: http://www.w3.org/TR/xslt
[XSLT2.0] XSL Transformations (XSLT) Version 2.0, at: http://www.w3.org/TR/xslt20/
[XSLT3.0] XSL Transformations (XSLT) Version 3.0, at: http://www.w3.org/TR/xslt-30/
[XQuery1.0] XQuery 1.0: An XML Query Language (Second Edition), at: http://www.w3.org/TR/xquery/