Intro
Profiling is an often-used XML publishing technique where nodes are marked as conditional according to a set of profiles, identified using attribute values as filtering conditions. When publishing, the nodes are only included if the publishing conditions match the publishing context. The profiles are sometimes also used as variables in text content, including the attribute value in the publication.
While useful, these techniques have a number of problems. This paper takes a look at profiling, some of the common problems and suggest ways to solve those problems.
Definitions
Before I begin, let me briefly attempt to define the terminology used in this paper. Consider the following markup example:
<doc profile="B"> <p>Information common to products A, B, and C.</p> <p profile="A">Information about product A.</p> <p profile="B C">Information about products B and C.</p> <p profile="B C">Information about products B and C.</p> </doc>
The above is an example document that describes a product with the three product
variants A
, B
and C
; in other words,
it's the same basic product (imagine, for example, a diesel-engined car model with
three different-sized engines) but with three differing configurations.
I try to use the following terminology throughout the paper:
-
A profile is a set of conditions defining when a node is applicable. The
profile="A"attribute in the secondpelement, for example, says that this particularpelement is applicable for the variantA
. -
A profile's value is the human-readable condition for a specific profile, there to help a reader identify the condition in the text flow. For example, information that applies to the
D5
diesel engine might be marked up withprofile="D5". -
A profile's semantics, on the other hand, represent the underlying meaning behind the value. The
D5
diesel engine might be renamed to something very different without changing the semantics of a profile[1]. For example, a marketing department might decide to rename it without the engineering department changing a single engine component. -
A profiling context is the condition(s) applied to the document when publishing it. In my examples, I try to consistently set that profile in the root element; above, the publishing context is
B
, which means that only nodes either without any profiles or nodes including the context profile's value are included in the publication.
The Basic Example
Consider the following example:
<doc> <p>Information common to products A, B, and C.</p> <p profile="A">Information about product A.</p> <p profile="B">Information about product B.</p> <p profile="C">Information about product C.</p> </doc>
Three p elements are profiled for products A
,
B
, and C
, respectively. A fourth remains
unprofiled and is therefore always applicable. When publishing, the profile to be
used could be selected by adding an attribute to the root, like this:
<doc profile="A"> ... </doc>
The profile attribute in the root is used as a context for the publication. Processed, the document would
become:
<doc profile="A"> <p>Information common to products A, B, and C.</p> <p profile="A">Information about product A.</p> </doc>
Multiple profiles can be defined using this principle, of course, separating each value with a whitespace character:
<doc profile="B"> <p>Information common to products A, B, and C.</p> <p profile="A">Information about product A.</p> <p profile="B C">Information about products B and C.</p> <p profile="B C">Information about products B and C.</p> </doc>
Here, the last two p elements with B C
profiles match
the publishing context, B
, assuming OR logic.
Similarly, using B C
as context, profiles using B
,
C
, and B C
would be included, again assuming OR
processing.
Multiple Conditions
It is common to use different attributes for different profiling purposes. There
might be an attribute profile for processing product variants and an
attribute audience for processing content according to intended reader
category. Here's an example:
<doc profile="B" audience="default"> <p>Information common to products A, B, and C.</p> <p profile="A">Information about product A.</p> <p profile="B C" audience="default">Information about products B and C.</p> <p profile="B C" audience="admin">Information about products B and C.</p> </doc>
Here, the information is filtered in context B
and a
default
audience, so the last paragraph would be excluded because
the audience attribute doesn't match.
A third attribute might be required for processing the intended platform, a fourth for differences in diagnostic software, etc. Basically, different attributes would be used for differing semantics or when mixing them might prove messy for one reason or another.
Variable Text
Profiles can be used for variable text, like this:
<p>Information about product <phrase profile="A B C"/>.</p>
Ignoring the linguistic difficulties this construction tends to cause, the idea is
simple. When processed, the phrase element is replaced with the
context's profile value, A
, B
, or C
. In
the published document, a more generic text can be replaced with the exact product
variant.
Tools and Processing
A profile's allowed values are sometimes defined as in enumerated lists to avoid
user errors. In DITA, for example (see id-dita), an audience
type attribute includes the following values[2]:
<!ATTLIST audience
type (user | purchaser |
administrator | programmer |
executive | services | other |
-dita-use-conref-target) #IMPLIED
... >It follows that adding a new audience will cause problems. For that reason,
CDATA constructs are common, as are catch-alls like this:
othertype CDATA #IMPLIED
This allows for new audience types without having to change the DTD. Here, having the authoring software keep track of the allowed values in a database or such is a good idea, because someone will almost certainly misspell the new audience type, causing problems later. Here's an example from a CMS I sometimes use:
Figure 1
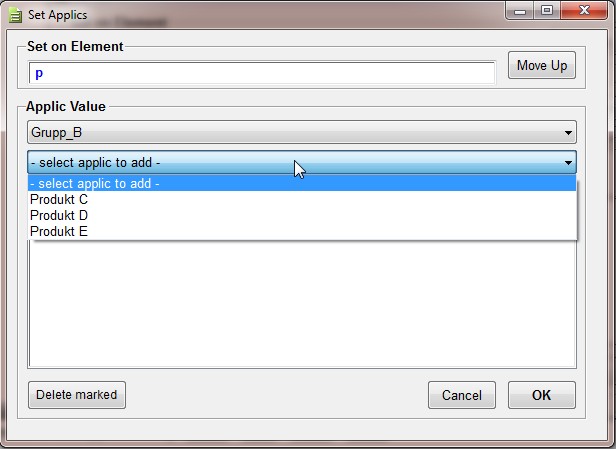
The values are fetched from a database. The profile uses two levels, a group
(Grupp_B
, above), and products C
,
D
, and E
that belong to the group[3].
Publishing
Publishing is a simple XSLT transformation that filters the contents according
to context. If several conditions with differing semantics are used (such as
profile and audience, above), using one stylesheet
per profile type is easy to set up in an XProc pipeline used to preprocess the
document.
Essentially, filtering is about string matching. The publishing context value needs to match the node's profile for the node to be included[4].
Boolean Logic
The above examples all assume OR. A single profile value match is enough to include a node. Similarly, even with a multiple-value context, a single matching profile value is enough:
<doc profile="A B"> <p>Information common to products A, B, and C.</p> <p profile="A">Information about product A.</p> <p profile="B C">Information about products B and C.</p> <p profile="B C">Information about products B and C.</p> </doc>
Here, nothing is excluded from the output because the A
context
matches the first node and B
the second and the third.
Sometimes, Boolean AND is preferred[5]. Here is a simple (and limited) way to do it:
<doc profile="B"> <p>Information common to products A, B, and C.</p> <p profile="A">Information about product A.</p> <p profile="B C">Information about products B and C.</p> <p profile="B C" boolean="AND">Information about products B and C.</p> </doc>
Here, boolean="AND" in the last paragraph means that for it to be
included, every
profile value must match the context (B AND C
). In
this case, the last paragraph is therefore excluded from the output.
More advanced Boolean expressions might be useful, of course, but would almost certainly prove to be far more problematic to implement in an XSLT stylesheet:
<p profile="B AND C AND NOT(A OR D)">Some text.</p>
This is no longer mere XSLT territory; an external tool for parsing the attribute contents might prove necessary.
But There Are Problems
Renaming Values
Let's say you need to rename some of the profiles. It's not uncommon for a product to be renamed or even to possess multiple names, depending on, say, market requirements. Problems ensue:
-
If the values are from a schema, the schema must be updated with the new values, either by renaming the existing values or by adding new ones.
The first option means that legacy documents will no longer be valid and will have to be converted. The second means that the legacy documents will have to be converted anyway or there will be two unrelated values for what is essentially the same profile.
-
Converting the old profiles to new values in this manner usually results in that the old ones can no longer be supported. If a legacy document is republished, it must use the new values. In a best case, this might confuse the existing users; in a worst, it might render the documents unusable.
-
Very often, once the client is made aware of the basic problem, the decision is to keep the old document base, making them either incompatible or just very expensive to update, because of the doubled profiles.
Changing Scope
Changing the scope of a profile value means that
the semantics of that value is updated.
For
example, let's say that a car engine D5
is updated with new
components, perhaps as the result of updated specifications or new component
suppliers. To marketing, it's still the same engine; after a certain date, it is
simply manufactured using the new components instead of the old.
To engineers and mechanics, the changes are likely to be significant and require new assembly methods, diagnostics, spare parts, and so on. The documentation will have to reflect these changes. New content must be added, technical data updated, images and illustrations changed.
Keeping the old profile, D5
, would still make sense to marketing,
and the car itself would still leave the assembly line with a D5
batch on the boot lid, but cause problems for the technical writer:
-
When updating legacy documents with new information (for example, when correcting errors), the writer would not be able to tell if a new warning, seemingly profiled with the same value, was compatible or not with the new information.
-
When writing new
D5
content, reusing old modules profiled with that same value would be equally deceptive; there is no easy way to know if the information is compatible or not.
Changing the profile value might solve part of the problem but again cause problems; the resulting conversions of old values to new are much harder to do. Which existing modules are compatible with the new version of the engine and which aren't? Very frequently the decision is to create a new (internal) profile, keeping the two apart, but this results in added processing when publishing, and certainly a doubled profile even in cases when the information is, in fact, identical.
Text Content
If the D5
profile, above, is used as variable text (see section “Variable Text”), changing the value is not an
option. The product is still marketed as D5. The end user will
most likely not know or care about the updated components or the resulting updated
document content.
Here, again, some attempt to solve the problem by adding internal profiling
values. In the car industry, model years are not used for profiling; instead, the
vehicles are identified using manufacturing weeks. To someone in the know, the
manufacturing week will clearly identify changes to a component such as the
D5
engine, but this divides the readers into two categories: the
internal audience that knows the significance of weeks and the external that only
sees the model year. This may not seem as a big problem but any third-party
technical group (consider, for example, third-party car mechanics, car enthusiasts,
etc) will have problems unless they have knowledge about, and access to, the
internal profiling.
Using profiles as variable text also results in language-related problems:
-
A single profile, say
A
, is uncomplicated to use in a variable:A is the latest-generation diesel engine for the environmentally conscious driver.
-
A variable that might result from possibly multiple matching profiles is more difficult:
B and C are high-performance turbo engines for the demanding racing driver.
For the writer, variable text resulting form single or multiple profiles are ultimately manageable only if they are known in advance.
Localisation
A related problem is about localisation[6]. If the target market requires different profiling values (perhaps the product is sold under a different name), the values must be handled either when translating or when publishing for that market. This is doable, of course, but will add to the complexity. If the localised value or scope needs to be changed at some point, as described above, further problems will arise.
A Basic Solution
Why Do We Have Problems?
The naming problems (that is, keeping the semantics of a profile unchanged but changing the displayed value) have a fairly obvious basic cause: Values are handled directly, instead of addressing the basic semantics of the profile. They inevitable change over time, but a simple product name change may be just that, a mere name change, meaning that the semantics remain unchanged. Yet, the profiling information that is available does not reflect this.
As with any changing content, any profile value should be version handled, yet they can't be when handled directly as strings.
The scoping problems offer further revelations:
-
We confuse semantics with values. Changed semantics may or may not result in a changed value; filtering should be based on semantics rather than representations.
-
The semantics evolve over time, as do the values, but the values are only there to represent the semantics.
In the car example,
D5
is used for both scopes because for the manufacturer's aftersales organisation, the engine variant is the same, regardless of the components used. In other words, we happen to have two different versions of the basic semantics but the same value to represent them. -
Because we confuse semantics and presentation, we can either describe the changes in presentation or describe the changes in semantics, but not both.
-
A change in a profile's semantics should mean a new version of the profile but not necessarily new values.
Or, in so many words, we confuse semantics and current values, using them interchangeably and frequently changing the wrong one. We need to separate the two.
Abstraction Layers
The solution is to separate semantics from presentation, like this:
Table I
|
Semantics |
Presentation |
|
D5 old |
D5 |
|
D5 new |
D5 |
Or, if changing profiles according to localisation, like this:
Table II
|
Semantics |
Presentation |
|
Platform X, GB |
Vauxhall |
|
Platform X, DE |
Opel Saab |
|
Platform X, SE |
Opel Saab |
And so on. In the former example, we have a basic name for the semantics
(D5
) and two versions, both represented by
the same value. In the latter, we have three localisations of
the basic platform name (X
), GB, DE and SE. Interestingly, the
localisations of the platform use three different values, Vauxhall, Opel and Saab.
In this case, this represents the fact that the same basic platform is used to
create three separate vehicle brands.
Obviously, all may be required to completely describe the correlation between the semantics and every intended representation of the profile[7], like so:
PROFILE-VERSION-LOCALISATION
The different versions and localisations could then be assigned values:
Table III
|
Profile |
Values |
|
D5.1-GB D5.1-DE D5.1-SE |
D5 |
|
D5.2-GB D5.2-DE D5.2-SE |
D5 |
|
X.1-GB |
Vauxhall |
|
X.1-DE |
Saab Opel |
|
X.1-SE |
Saab Opel |
Note that the table represents incomplete semantics rather than a real-life problem. More is required to determine which value to use and when.
If the core semantics change, the corresponding values may or may not change[8]; if changed values are desired, the corresponding semantics must change[9].
The core
profile, the intended semantics of the filtering
condition, should be uniquely and persistently named. That name should be version
handled and localised as needed. So, I wonder, is there a convenient way to separate
semantics from presentation?
Use URNs to Name Filters
I'm partial to URNs when it comes to uniquely identifying things. I'd have used URNs to name my kids, had I been allowed to.
It's easy to define a URN namespace for unique names. And if you control the scope, they can also be persistent. For URN-based profiling, something like this should do:
PROFILE:LANG-COUNTRY:VERSION
PROFILE, of course, is the core profile, the semantic filter concept,
LANG-COUNTRY the localisation and VERSION a specific
milestone. Combined, they should describe the examples above, but
PROFILE can be further broken down if needed. For example,
Platform X in the above table could solve the
semantic problems: X:OPEL, X:SAAB, etc.
A semantically identical profile used for different markets requiring different presentation (values) is solved like so:
Table IV
|
URN |
Values |
|
URN-X:sv-SE:12 |
V1 |
|
URN-X:en-GB:12 |
V2 |
The values (V1
for Sweden, V2
for the UK) are
different because the target localisation varies, but the core profile
(URN-X
) is the same, as is the version (12
). The
values V1
and V2
are therefore equivalent with each
other.
Here's the introductory XML example using URNs as profiles:
<doc profile="urn:x-profile:a:sv-SE:12"> <p>Information common to products A, B, and C.</p> <p profile="urn:x-profile:a:sv-SE:12">Information about product A.</p> <p profile="urn:x-profile:b:sv-SE:7">Information about product B.</p> <p profile="urn:x-profile:c:sv-SE:3">Information about product C.</p> </doc>
A variable might be included like so:
<p>Information about product <phrase profile="urn:x-profile:a:sv-SE:12"/>.</p>
As the phrase element is a placeholder for variable content, the URN
needs to be processed accordingly so that the right values are used when publishing.
This construct, of course, can still result in a linguistic nightmare.
Can representing profiles with URNs solve the problems we've outlined?
-
If a profile is updated, either when changing the values or their scope, a system that can fully resolve the URNs will support both the old and new profiles. A new document can use the new values because it uses a later URN version while a legacy document can keep on using the old values because it uses the older URN version.
-
As a consequence, no processing of legacy documents beyond resolving URNs is necessary.
-
It is still easy to string match profiles when publishing, even if localisation is required.
-
It is also easy to publish a legacy document that uses old URNs with new values by preprocessing the old URNs[10].
Processing
Editor
To make URNs practical, the writer will need help to identify and insert a profile (while URNs are unique, they are not necessarily human-readable). Similarly, when editing existing profiled nodes, the profiles must be easily identifiable.
The problem, of course, is that a string like
urn:x-cassis:r1:cos:xplatform:000359:sv-SE:0.12
is not very
descriptive. Identifying it requires asking the CMS, which might prove
cumbersome if one ever wanted to work offline.
A cop-out solution is to use strictly human-readable URNs, but problems such
as identifying the variations in scope in the D5
example above
(see section “Changing Scope”) require
more.
Perhaps better and certainly easier to process is to insert descriptive
throwaway attributes containing current profile values when checking out or
opening a document in the editor. Such an attribute, say, values,
would be for convenience only and be stripped from the document at
check-in:
<p profile="urn:x-profile:a:sv-SE:12" values="A">Information about product A.</p>
An more powerful alternative requiring a bit more processing is to use a mapping document listing any required profile-and-value pairs for any checked out or open documents, like so:
<maps> ... <pair> <profile>urn:x-profile:a:sv-SE:12</profile> <values>A</values> </pair> <pair> <profile>urn:x-profile:a:en-GB:12</profile> <values>B</values> </pair> ... </maps>
Or some variation thereof. A mapping document might also provide the basis for a profiling GUI, listing the available profiles and their versions in some human-readable form, an immediate advantage being that once populated, the mapping document would give access to the available profiles without requiring a server connection.
I've used a similar approach with a mapping document when matching URNs for checked-out or open documents with their temporary URLs in the editor:
<Repository>
<RepositoryName>CosTI</RepositoryName>
<Map>
<UrnUrlPair>
<Urn>urn:x-cassis:r1:cos:00002730:sv-SE:0.7</Urn>
<Url>C:\Users\arin\Documents\condesign\cassis\ti\xmetal\2880321bb5d24b08a95e2854bccf859b\prox-för-cassis.xml</Url>
<Writable>false</Writable>
<EditUrl />
</UrnUrlPair>
</Map>
<ShowMetadataDialog>true</ShowMetadataDialog>
</Repository>Expanding this to include profiling would be relatively easy[11].
Variable Text and Localisation
Variable text in the editor can be inserted using both techniques above: a
throwaway values attribute or a separate mapping document both do
the trick. The former alternative requires less processing while the latter
gives access to more features. Localised values, for example, would require the
mapping document.
Combining Profiles
URNs (and indeed any type of abstraction layer) can help simplify complex profiles, such as the logical expressions mentioned in section “Boolean Logic”. Instead of having to process the expression in an attribute, the expression can be represented using another URN, like so (with apologies for the pseudo-code):
URN-EXPRESSION = URN1 AND URN2 AND NOT(URN3 OR URN4)
The replacement URN represents the expression and is used instead of it when
processing. Of course, to be more than a theoretical exercise in neat ways of
doing the unneeded, the situations in which boolean expressions can occur must
be clearly defined. Such situations are common when describing complex modular
products and their many variants; such products are frequently sold as
individuals, requiring individualised documentation. A closer look of those
situations is outside the scope of this document, but the point I want to make
here is nevertheless an important one: rather than processing
2*(3+2)
, process 10
. An abstraction layer is
simply some suitable representation of semantics.
Thus, a writer might use a shortcut URN to represent a group of profiles
comprising several URNs. Such a user-defined URN
could be paired
with descriptive metadata to help identify it and other URNs created for similar
purposes. The right systems support could easily provide the user with a listing
of the underlying profiles.
Base Profiles
A complete profile includes localisation and version information, but sometimes it is useful to process the base profile regardless of language, country or version. This is easily done by defining wildcard behaviour:
URN:*:*
This basically ignores the wildcards; it matches every single one. With the URN semantics well defined (I use EBNF for mine) this should be easy.
Other useful variations here might define processing for, say, the latest
version of a profile. A stylesheet treating URN:sv-SE:* as the
latest is not hard to do but will, of course, require access to the
corresponding values, either at runtime or when populating a mapping
document.
Assertions
Sometimes, filtering profiled content causes structural problems in the resulting document, with required elements missing. Consider this admittedly simplistic example:
<doc profile="A">
...
<warning>
<p profile="A">Some content.</p>
</warning>
...
</doc>If a warning must always contain at least one p, the
above will result in an invalid warning if published in context
B
rather than A
. This is an easy mistake to
make, and more complex nodes could easily end up being invalid without the user
noticing, especially in modularised documents, resulting in the problem
remaining undiscovered until the document is published.
As these problems will only appear later[12], they can be difficult to spot. This can be solved using schematron (ISO standard; see id-idso-sch)
assertions and validation on a document to check for problems and missing
content after applying profiles. Such tests can be automated and used to
validate the profiled nodes only. Here's a schematron fragment for checking if
the warning contents match the publishing context:
<!-- Profiling status for node -->
<pattern>
<rule context="warning">
<assert test="p/@profile">No profiling information.</assert>
<report test="p/@profile">Profiling present.</report>
</rule>
</pattern>
<!-- Match -->
<pattern>
<rule context="warning">
<report test="contains(/*/@profile,p/@profile)">Profile matches
publishing context.</report>
</rule>
</pattern>
<!-- No match -->
<pattern>
<rule context="warning">
<assert test="contains(/*/@profile,p/@profile)">Profile does not
match publishing context.</assert>
</rule>
</pattern>Note that complex schematron documents can be automatically generated if the possible profiles are known and the possible changes are defined in a schema.
It might be possible to use XML Schema 1.1 assertions but since an assertion on an element cannot refer to siblings or ancestors (id-xsdassertions), the assertion would have to be made on descendants only, like so:
<xs:schema
xmlns:xs="http://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified">
<xs:element name="doc">
<xs:complexType>
<xs:sequence
maxOccurs="unbounded">
<xs:element
name="warning">
<xs:complexType>
<xs:sequence
maxOccurs="unbounded">
<xs:element
name="p">
<xs:complexType
mixed="true">
<xs:attribute
name="profile"/>
</xs:complexType>
</xs:element>
</xs:sequence>
<xs:attribute
name="profile"/>
</xs:complexType>
</xs:element>
</xs:sequence>
<xs:attribute
name="profile"/>
<xs:assert
test="contains(@profile,.//*/@profile)"/>
</xs:complexType>
</xs:element>
</xs:schema>This might result in some rather complex expressions, if the assertion required needed to go beyond the basics as illustrated above. I have not further explored this at the time of this writing.
Publishing
Publishing documents that include URN profiles remains easy; the URNs can be processed as strings, using string matching, so the filtering of nodes should not be a problem. Processing a translated document that uses untranslated profiles might prove tricky, however. Here is an example of a document originally profiled in Swedish but now translated to English:
<doc profile="urn:x-profile:a:en-GB:12"> <p>Information common to products A, B, and C.</p> <p profile="urn:x-profile:a:sv-SE:12">Information about product A.</p> <p profile="urn:x-profile:b:sv-SE:7">Information about product B.</p> <p profile="urn:x-profile:c:sv-SE:3">Information about product C.</p> </doc>
None of the profiled p elements is
included in the resulting publication. This, of course, could be the desired
result, but more likely is that the profiles need to be preprocessed. One way
could be to prep the file going to translation, replacing any language/country
information in the URNs before translation. More flexible is to define the exact
preprocess according to need. For one thing, if the profiled node is not
relevant in the target localisation, the profile should remain unchanged[13].
Note
It might be better to include every applicable profile localisation
directly in the above example, rather than replacing the original one during
preprocessing, as suggested by a reviewer of this paper. Or, if the profile
was always applicable, leave out the localisation altogether by using a
wildcard convention ( such as profile="urn:x-profile:a:*:12")
with suitable assertions when preprocessing. More complex localisation
requirements could be similarly handled (sv-SE
and de-DE, but not
en-GB
, etc) using more complex
assertions.
Also, the translators should be made aware of any processing requiring exact
values (most notably when using profiles for variable text in content); the
profile values in a localisation are far more important to
the translator than their corresponding URNs. The latter, then, need to be
mapped to any relevant values, including values resulting from localisation or
from some special processing (i.e. if the latest version of a profile is
preferred), before the original document is translated. The values can be placed
in a mapping document[14], provided to the translators but they'd almost certainly prefer
preprocessed documents where text variables such as the phrase
element in section “Variable Text” include their values rather
than the URNs:
<p>Information about product <phrase profile="A B C">A, B and C</>.</p>
Note
This will not solve the grammatical problem. It simply helps translators by showing the actual values rather than the URNs.
The Grammatical Problem Solved
The following sentence using a text variable will potentially cause problems if the number of applicable profiles varies:
-
A single profile, say
A
, is uncomplicated to use in a variable:A is the latest-generation diesel engine for the environmentally conscious driver.
-
A variable that might result from possibly multiple matching profiles is more difficult:
B and C are high-performance turbo engines for the demanding racing driver.
<p>The <phrase profile="A B C">is the latest generation diesel engine for the environmentally conscious driver.</>.</p>
Brute force solutions involving marking up inline content to identify
grammatical constructs might be manageable if only two need to be handled, if
Boolean constructs are accepted, for example, by using expressions such as
profile="(A AND NOT(B)) OR (B AND NOT(A))" for singular and
profile="A AND B" for plural form, but even this will quickly
become unmanageable for the writer.
Far more useful is to add an abstraction layer that defines the
types of profiles, for example, diesel
engines
or turbo engines
. A mapping document might
define a group of profiles for the purpose, like so:
<group> <profile>urn:x-profile:abc</profile> <included> <profile>urn:x-profile:a</profile> <profile>urn:x-profile:b</profile> <values>D5</values> </included> ... </group>
Here, all variants are called D5
but the value could just as
well be D Series Diesel Engine
or something else. The point is
that the abstraction is needed to a) group the participating profiles into a
meaningful semantic group while b) keeping either singular
or plural form, but not both, regardless of the number of exact profiles
used.
A different but useful way to solve the problem is to count the context
profiles in the root (one or more) and include markup to handle only the
grammatically relevant differences. Singular might be marked up as
<wrap context="s">is</wrap> and plural as
<wrap context="p">are</wrap> or similar.
Out-of-line Profiling
The profiling abstraction layer described above provides the basic ideas but more fun can be had. What if, for example, you needed to profile XML following a schema that you don't control? There are ID attributes but no profiling semantics. You can't change the schema directly and processing for local needs would be too expensive[15]?
My immediate reaction when thinking about this was extended XLink
.
XLink (id-xlink) is an
all-purpose linking standard that never really reached the level of acceptance I feel
it
deserves [16]. Among other things, the spec describes out-of-line
links, that is, links that are described outside the resources they use,
in linkbases
. The linkbase lists locators that identify the start and end points of the links, and
arcs that connect those points with each other. The
spec allows for multi-ended
links, which basically means that the link
ends can be connected with each other in any combinations, as many times as
needed.
Figure 2
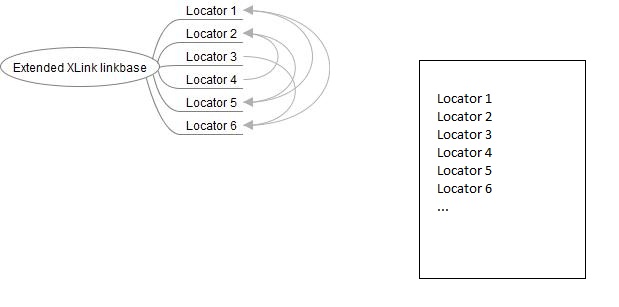
A linkbase (the blob to the left) lists locators and arcs that identify nodes and their relations in the document to the right. What's cool with extended XLink is that the link ends that participate in a link have no idea they are part of one. We can describe document semantics outside it.
Extended Profiling
Just as I can describe links outside the participant resources, I should be able to profile nodes in resources in a linkbase-like construct, like this:
<linkbase> <locator href="doc.xml#id1" profile="URN1"/> <locator href="doc.xml#id1" profile="URN2"/> <locator href="doc.xml#id2" profile="URN1"/> ... </linkbase>
Two separate locators identify the two profiles for the node with
id1 in doc.xml, URN1
and
URN2
, respectively. A third locator identifies a second node,
id2, with the profile URN1
. This, essentially, is
the mapping document I described above (see section “Editor”), so throwaway values could
easily be included, like so:
<linkbase> <locator href="doc.xml#id1" profile="URN1" values="A B"/> <locator href="doc.xml#id1" profile="URN2" values="C"/> <locator href="doc.xml#id2" profile="URN1" values="A B"/> ... </linkbase>
With URNs identifying the document(s), it is easy to include proper version handling and match localisation values with their URNs, like so (this is not directly equivalent with the above):
<linkbase> <locator href="URN-DOC:sv-SE:1#id1" profile="URN1:sv-SE:1" values="A"/> <locator href="URN-DOC:en-GB:1#id1" profile="URN1:en-GB:1" values="B"/> ... <locator href="URN-DOC:sv-SE:2#id1" profile="URN1:sv-SE:2" values="A C"/> ... </linkbase>
The first two locators describe version 1 of the document in Swedish and English
containing the id1 node profiled with URN1, version 1, with localised
values in Swedish (A
) and English (B
), respectively.
The third locator describes the Swedish version 2 of the same document, profiled
with version 2 of URN1 and updated values localised for Swedish (A
and C
).
As with the inline profiling (see section “A Basic Solution”), the URN profiles here can represent expressions.
Basic Requirements for the Document
Some requirements for that third-party document structure emerge:
-
The document must be XML.
-
Any relevant node should be identified with IDs or some other way to uniquely identify profiled nodes.
-
For variable text, there should be a placeholder to replace.
XLink Roles and Titles Put to Use
The XLink spec describes roles that can be applied to other XLink semantics:
The value of the role or arcrole attribute must be a URI reference as
defined in [IETF RFC 2396], except that if the URI scheme used is allowed to
have absolute and relative forms, the URI portion must be absolute. The URI
reference identifies some resource that describes the intended
property.
Sound familiar? A URN, of course, is a type of URI, so roles in XLink can do
more or less exactly what I have described above, except, of course, that there
can only be one URN per locator. That means that either a set of URN profiles is
described in a set of locators, with one URN per locator, or the URNs are
combined to other URNs as hinted in section “Combining Profiles”. Of course, that
resulting URN is just a reference [that] identifies some resource that
describes the intended property
, so we seem to be well within the
intentions of the spec.
The spec also describes titles:
The title attribute is used to describe the meaning of a link or resource
in a human-readable fashion, along the same lines as the role or arcrole
attribute.
So, here's an XLink version of the above example (stripping namespace stuff and such):
<linkbase> <locator href="URN-DOC:sv-SE:1#id1" role="URN1:sv-SE:1" title="A"/> <locator href="URN-DOC:en-GB:1#id1" role="URN1:en-GB:1" title="B"/> ... <locator href="URN-DOC:sv-SE:2#id1" role="URN1:sv-SE:2" title="A C"/> ... </linkbase>
This, of course, is exactly what we need, and in processable form.
Out-of-line Processing
A lot of the required processing for out-of-line profiles is unchanged from the inline version (see section “Processing”). Out-of-line links, whether they are done in linkbases or in overlay documents, add some processing and may present practical difficulties, but also hint at a different approach when creating or editing the profiles in the editor.
Editor
When profiling a document out-of-line, we are essentially editing a linkbase, that is, a separate document. That document does not need to be edited using full XML editing capabilities, only what's needed for locating the nodes and profiling them. This suggests a DITA map-like approach. In quite a few XML editors out there, there is a separate window or pane for editing DITA maps. It is specialised and only needed to handle editing topicrefs and such.
Similarly, a linkbase editor needs only include the necessary profiling handling, adding locators to the linkbase using a function in the main editor and then adding profiles in the linkbase editor. For editing existing locators, it should be enough to click on them to locate the corresponding nodes in the editor but remain in the specialised window when editing them.
The remaining problem is a practical one: how does one visualise a profile in the main editor window so that the user can easily spot any profiled content. Here, a processing instruction might suffice if the editor has trouble populating the document tree from more than one source.
Schematron Uses
Schematron can be used to validate the resulting profiled content and to generate PIs in the target document to indicate profiles, but also to generate the linkbase itself, if the rules describing what can be profiled and how are formalised. If the target document doesn't contain IDs, a schematron-like reporting function implemented in the specialised editor can be used to identify nodes using XPath expressions.
Variable Text
Variable text is more difficult to implement properly out-of-line, not because of the out-of-line approach itself but because we don't necessarily control the document. The language must be such that the profile value naturally fits into the text flow.
If profiling content we don't control, the problem is mostly beyond our control. If there are placeholders, the problem can be solved, but if not, while we can pinpoint a location using a variety of means (anything from a PI to XPointer comes to mind) variable text when profiling out-of-line should probably not be attempted if we don't control the content.
The Grammatical Problem Revisited
The grammatical solution suggested in section “The Grammatical Problem Solved” is even easier to handle in a linkbase, as the profiles are all in one place, regardless of how many modules they are used in. They can easily be preprocessed by wrapping selected groups in abstractions (grouping profiles under a single label), counting them, and otherwise producing any relevant information about them when publishing a document.
A reviewer of this paper commented: Instead of storing the variable
text only and using additional wrap element for the grammatical relevant
differences, why not store the whole grammatical phrase as variable text?
This is perhaps an easier solution for an author to handle than the one I started out with, but one that will cause the duplication of any surrounding grammatical phrases and likely reintroduce copy-paste editing when authors include the complete phrases with the variant information, rather than only the product variants themselves. Applying this on the sentence from section “The Grammatical Problem Solved”, we might end up with a number of variants, almost but not quite copies of each other:
-
A is the latest-generation diesel engine for the environmentally conscious driver.
-
B is the latest-generation diesel engine for the environmentally conscious driver.
-
C is the latest-generation diesel engine for the environmentally conscious driver.
-
A and B are the latest-generation diesel engines for the environmentally conscious driver.
-
B and C are the latest-generation diesel engines for the environmentally conscious driver.
-
A, B and C are the latest-generation diesel engines for the environmentally conscious driver.
And so on, for any permutations that may arise. The conclusion, in my mind, is
obvious: any more complex sentences involving named
variants in this manner should probably be avoided in favour of a more generic
label (say, diesel engine
or D
, in this case) in
any real-world document.
End Notes
In Or Out Of Line?
Inline (meaning placed in the physical XML file
) profiles can be
messy. If new profiles need to be added to an otherwise unchanged XML file, it must
nevertheless be edited to include those new profiles. In a system with version
handling and modularisation, this frequently means that a profile change will result
in that any module referring to the edited XML file must also be updated.
Moving the profiles out of line, to a linkbase, immediately solves this problem. With the profiles stored outside the physical XML files, the files only need to be edited if their contents (beyond the profiling information) are changed. Adding or editing profiles requires changing the linkbase, not the XML modules.
On the other hand, inline profiles are easy to display and highlight in an editor simply by adding some CSS. Out of line, there needs to be some kind of interaction between the editor and the linkbase. This may or may not be practical for an author, depending on the situation, and may be difficult to implement.
So which one is better? Leaving aside the implementation considerations for a moment, in a highly modularised[17] document management environment where each module is individually version handled for full traceability, moving the profiles out of line should be considered, especially if editing a module always means that it must be checked out and its version updated. A simple profile update inline could require updating not only the current module and its translations, but also any module that links to the current module, plus their translations.
I'm Not Alone
The techniques used when profiling and filtering, of course, are quite common.
I've mentioned DITA as an example, but the same principles are found everywhere.
DocBook's profiling attributes (arch, os, etc) come to
mind, as do the more generic role attribute found in many
schemas.
Indirection techniques to handle renaming are, of course, not uncommon, and are
used in both XML-based systems and outside them. For a comprehensive, and, in many
ways, different, profiling mechanism, have a look at the S1000D technical
documentation specification's applicability model
(see id-s1000d-applic-model
for an introduction, or download the S1000D spec itself at id-s1000d-home).
The S1000D applicability model is frequently implemented by S1000D vendors in the so-called S1000D Common Source Database (CSDB) using a certain level of indirection. There is a product lookup database that is set up to manage and map product semantics with values (such as aircraft manufacturer names, product serial numbers and so on), including versioning. S1000D also includes an assertion mechanism, implemented to varying degrees by vendors.
Finally, it should be noted that the S1000D applicability model may use out-of-line profiling, for example, to manage inline filtering conditions.
Thank You
My sincerest thanks must go to the reviewers of this paper. I have attempted to update the paper accordingly, trying to clarify, expand and remove content as suggested by the many helpful comments. Any mistakes, omissions and misunderstandings are solely mine, however.
A far better title than the one originally supplied by me was kindly provided by the Balisage program committee. My original title, I feel, is best left unmentioned, but for the new one, my heartfelt (and relieved) thanks must go to Tommie & Co.
References
[id-dita] DITA audience Attribute http://docs.oasis-open.org/dita/v1.2/os/spec/langref/audience.html#audience
[id-urn] Uniform Resource Names (URN) Namespace Definition Mechanisms http://www.ietf.org/rfc/rfc3406.txt
[id-idso-sch] Schematron ISO standard http://standards.iso.org/ittf/PubliclyAvailableStandards/index.html
[id-xsdassertions] XML Schema 1.1 Structures (Assertions) http://www.w3.org/TR/xmlschema11-1/#cAssertions
[id-xlink] XML Linking Language (XLink) Version 1.1 http://www.w3.org/TR/xlink11/
[id-prescod] XLink: behavior must go! http://www.biglist.com/lists/xsl-list/archives/199905/msg00218.html
[id-s1000d-home] The S1000D Web Site http://public.s1000d.org/Pages/Home.aspx
[id-s1000d-applic-model] S1000D Applicability Model http://www.ataebiz.org/forum/2008_ata_e-biz_forum_agenda/Applicability_vanRotterdam.pdf
[1] This is one of the basic problems with profiling that this paper attempts to address.
[2] The audience construct is more complex than that, but this suffices as an example.
[3] The resulting attribute value is a string, for example,
Grupp_B_Produkt_C
.
[4] With unprofiled content always being included.
[5] For example, the node might be an illustration showing a product
variant (A
) configured with a specific accessory
(B
), so it would only make sense to include the
illustration in the published document if the publishing context
included both A
and B
.
[6] For a moment ignoring the differing grammatical requirements imposed in variable text.
[7] Quite possibly, there might be other parameters to alter the basic profile in some way.
[8] A product may be partly or completely revised, yet retain its product name. Consider, for example, Apple's product naming strategy for tablets and laptops.
[9] Even though the product may be unchanged and the marketing department decide on a new name, without changing the basic semantic profile, there is no way of knowing when the name change occurred.
[10] Although it would result in having to check what exact semantics the later version represents. On the other hand, if profile semantics are versioned, it should be easy to bind specific versions to specific functionality.
[11] An added bonus is that in this case, the URN handling APIs are already in place.
[12] The document that is profiled remains valid, of course.
[13] Or the node removed; translators should not have to see it.
[14] Or in values throwaway attributes, depending on the
situation.
[15] Agreed, this is a contrived example. I never really bought that classic
namespacing argument, what if you need to import a foreign namespace into
yours?
[16] The lack of a processing model while including behavioural attributes is a
frequent criticism and arguably pertains to my suggested use, here. See, for
example, Paul Prescod's XLink: behavior must go!
(id-prescod).
[17] With multiple reuse levels or significant numbers of reusable modules, or both.