Writers just wanna write
The initial impetus for this research grew out of a facile observation many years ago that an author had to learn SGML in order to use an SGML editor.
This is a necessary requirement in many fields where the content is complex: for example encoding literary or historical documents in TEI, or writing computer systems documentation in DocBook. The author needs to understand what markup is available so that it can be used to describe the finely-detailed features accurately, but the naming and function of the markup is not always entirely obvious (Reid1980, Joloboff1989).
By contrast, to submit a paper to a conference, an article to a journal, or a book to a publisher, the conventional author uses a wordprocessor, or another standard like LaTeX. It is the author's responsibility to adhere to the sometimes arcane or inconsistent formatting instructions provided by the publisher, even when assisted by the publisher's style template.
Publishers have traditionally mistrusted authors who do their own formatting, even when using the publishers' specifications to provide final-format copy. Authors, for their part, are always encountering new reasons why their article, book, or paper has to be formatted differently. Where a stylesheet is provided, abusing or ignoring the styles is common, because it is sometimes the only way to get the formatting the author believes necessary, because they feel they should be in charge of the formatting (Piez2007, Ebel2005). In many cases the solution is for the production team to remove all the author's formatting and send the document to a typesetter to have the house style applied.
In wordprocessors, structure is largely non-existent in the markup, and only interpretable by human eyes through the formatting. Synchronous typographic (ST) editing (usually, if inaccurately, called WYSIWYG) has been the standard interface for some decades, but it hides the markup boundaries so effectively that accurate editing is sometimes impossible.[1] In XML and LaTeX editors, the adoption of ST editing was slower although it is now widespread.
Unless there has been some extensive (and expensive) customization, conventional use of a structured-document editor usually means learning the language, the specific markup required for the domain, and the logic or business rules that accompany it. Much of this is far beyond the comfort zone of those writers who have no exposure to markup but nevertheless still have cause to write a document under the constraint of producing a specific (structured) file format.
The objective of this research was to see how much of the cognitive, perceptual, and technical burden of creating a formally-structured document might be relieved by changing some of the ways in which the interface works.
In earlier work we found that most writers simply want to
write in what they perceive to be the easiest
way
(ST), adding what formatting they deem appropriate, without ever
seeing a pointy bracket or a backslash, and without having to
come to terms with the language of trees and graph theory,
predicate logic, or document engineering (Flynn2009). While this desire was generally
acknowledged by experts, it was felt possibly to be one of the
reasons for the failure of XML and LaTeX to be adopted as
general authoring formats outside their related technical
fields.[2]
Who writes what
The target population for this study was those writers who are required to write (or who wish to write) documents adhering to a well-defined structure, but whose professional area of expertise is not in computing science, markup, editing, typesetting, or technical documentation, where advanced knowledge of markup technology is more commonplace. There are three key features to the activity of this population:
-
it is very diverse: it includes people in the private sector, public sector, NGOS, research, and academia;
-
its members are writing or editing to a known structure (articles, books, reports, white papers, web pages, and similar documents) defined by their field or industry or organization;
-
the documents themselves are intended or expected to become a part of the permanent record; or to require access to the structure for the purposes of re-use.
Structured documents tend not to be created for ephemeral, transient, or inconsequential use. This means that structured document file formats tend to have a high degree of durability, system-independence, reusability, and freedom from exogenous or arbitrary change. XML and LaTeX supplied the use cases in this study.
Structure
for this purpose means a
hierarchy of enclosures whose implicit or explicit content is
a selection of repeatable objects holding text and other
text-bearing containers, whose identity and existence is
programmatically enforceable or verifiable. XML and LaTeX
were therefore candidates; wordprocessor and DTP formats were
generally not, except when they use named styles in a rigorous
manner which identifes their content.
What they write with
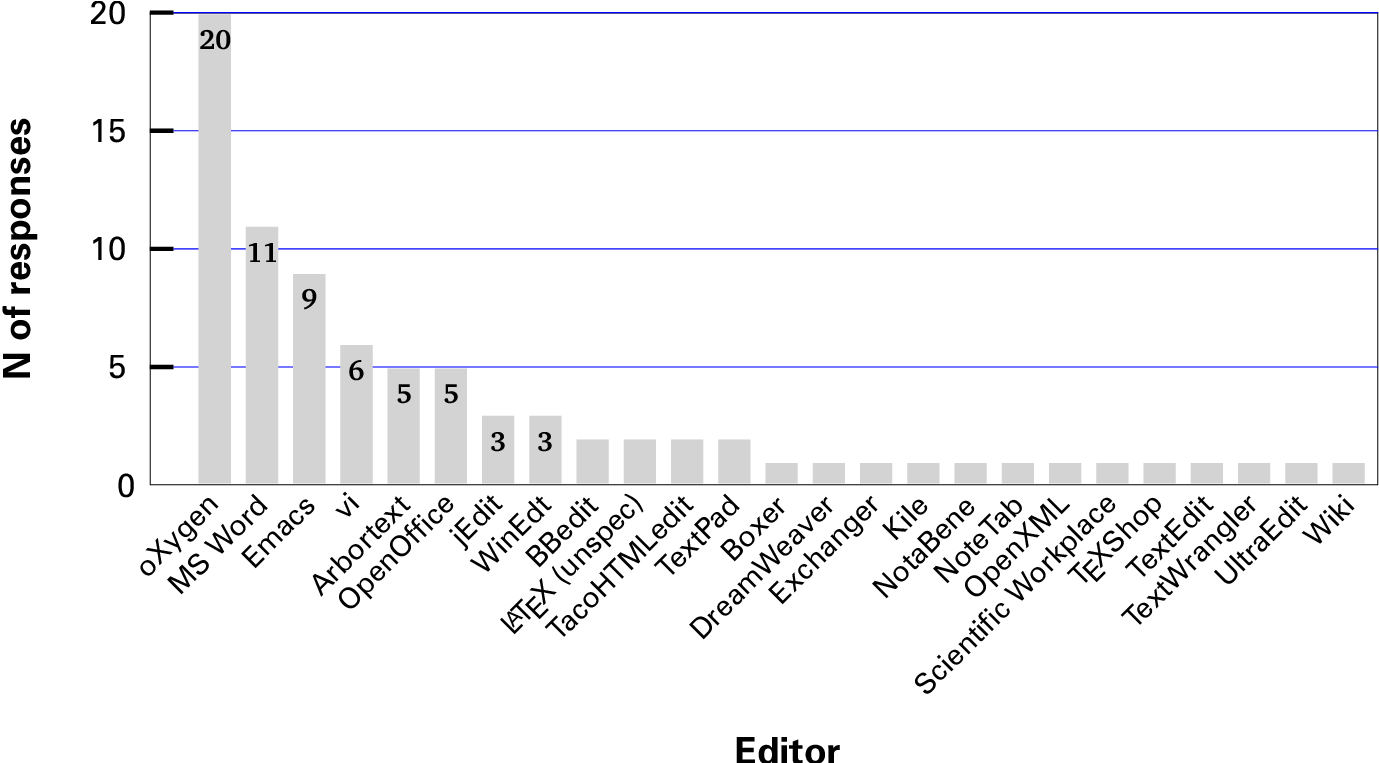
In the survey of existing markup systems users reported earlier (Flynn2009), we identified that the editors most respondents had experience of were oXygen (24%) followed by Word with styles (13%). LaTeX editors accounted for another 12%, and the Arbortext editor rated 6% along with OpenOffice. Emacs (11%) and vi (7%) were also reported, but the number of other editors was very large and diverse.
Figure 1: User Survey: Markup types used
Outside the markup field, the much-publicized figure of
500M people using Word
appears to have no
verifiable basis: the source most often cited for this (Schulz2009) just claims roughly half a
billion people use Office
. However, observation
would suggest that the penetration of Word is nevertheless
extremely high, possibly close to 100% in tightly-governed
environments, but more from organisational imperatives than
from end-user choice. There are also many areas where there
are legacy alternatives (eg Lotus, WordPerfect), or where
open-source or free-to-use competition is accessible
(OpenOffice, Libre Office, Google Docs). Recent, public,
independently-verifiable global figures do not appear to be
available from conventional sources (eg UN), although there
are claims that many organizations use Word out of habit,
familiarity, or legacy investment (McLeish2008). We therefore made the assumption
that users of systems other than XML and LaTeX will be
acquainted with Word or something very similar.
What can we change?
The earlier research also identified over 20 specific functions or tasks which the authors and editors surveyed found hard to use, misleading to identify, difficult to find, or non-functional in the structured editing systems they had used. A few of these (eg equation formatting) were outside the scope of the research; some were not specifically markup issues (opening and closing files, for example); and some were concerned with exogenous requirements (eg Unicode).
From these functions or tasks, six categories of direct concern were identified. Analysis showed that in many cases, users expected a specific behavior which not all editors provided, or the expected behavior required markup-related information that was not seen as relevant. The expectations were summarised in XML and XPath terminology for comparability, and are shown in an abbreviated form in Figure 2. Two supporting technologies were identified: Smart Insertion (SI) and Target Markup Adoption (TMA): see section “Additional mechanisms”. Some editors already implement some of the actions listed here.
Figure 2: Categories of interface action identified, with desired behavior
|
Keyboard controls |
For the first three, detect multiple successive keypresses and enter the appropriate formatting dialog.
|
|
Documents and metadata |
|
|
Insertions |
(Requires the use of SI and TMA.)
|
|
Formatting controls |
|
|
Moving blocks |
(Requires the use of SI and TMA.)
|
|
References |
|
How can we change it?
In addition to the actions listed in Figure 2, the survey identified specific requirements for actions not found in all editors, for example the joining and splitting of adjacent elements of the same type. With these additions, and the subsuming of keyboard-character usage into actions that were detected during a test (as opposed to being testable items themselves), a list of 12 tests was devised (see section “Testing”).
The requirements and expectations were compared with the list of editor functions reported in earlier work (Flynn2006), and a solution for each in interface terms devised. As these were model or outline solutions for testing, it was recognized that implementation in an editor would require adherence to the features and functions available.
Additional mechanisms
In order to express (and therefore test) the required changes, we identified two mechanisms which needed formalizing. Both have existed for some time in a few systems, but as far as is known, neither has been widely adopted. It should be borne in mind that these mechanisms, or their equivalent, are important when a writer cannot see any markup.
Some of the actions described require that the cursor position at an element boundary (start-tag, end-tag) dictate that tests for validity may be required both for a position inside and outside the boundary.
|
Smart Insertion (SI) |
When a whole element or sequence of elements has been cut or copied from elsewhere in the same document or another one of the same type, pasting must be possible even when the target location does not allow the fragment element types. This is based on the principle of operating in an environment where markup is not displayed, where rejection of a paste action is not acceptable unless it occurs at the boundaries of reason. Only when no solution can be identified should the user be informed that the material cannot be pasted at the target location, a suitable explanation provided, and pasting into the user's choice of possible elements allowed. To achieve this, the containing element type[s] of the fragment must be changed to one which is permitted at the target location, including the validity of any sub-element markup. Any algorithm to implement SI must take into account the possible changes to the containing element type as well as to the changes in location described below. This must include the possibility of demoting or promoting the clipboard container element type in the hierarchy, especially when the target location is within such a hierarchy (eg section/subsection/subsubsection, etc). Where no such element type can be identified, the test is repeated, starting with the original cut or copied element types, on successive axes from the target location, until a match is found, or a barrier reached (eg the root element on the way up, or character data on the way down). If a match is found, any required containing elements are created to preserve validity, and the user informed. |
|
Target Markup Adoption (TMA) |
When pasting a fragment from another document of a different type into mixed content, any containing element type from element content is first removed, so that the pasted material is all mixed content. If the target location is inside an element which does not permit subelements, and subelements are present in the clipboard material, the target location must be moved to a point where pasting subelements is permitted, or the nested markup must be removed and the exposed character data merged with the preceding and following text nodes. Where there is a mismatch between the subelements
and the element types available in the target mixed
content, a table of equivalences or some derived
heuristics must be used (eg All font-related markup, where identifiable, is stripped from the clipboard, except Bold, Italic, Underline, and Strikeout, and the resulting sequence normalized before pasting. |
Testing
For reasons of practicality, it had already been determined that writing an entirely new editor in full, just to test a dozen interface items, was not feasible. Two editor manufacturers did very generously offer a copy of their (completely undocumented) monolithic source code for experimental purposes, but these were declined with regrets as involving work beyond the time limits available. After examining the several usability testing methodologies available, the decision was made to use Paper Prototyping (Snyder2003), as this provided the levels of control required, with the ability to conduct the tests without committing to a specific operating environment, or predicating a specific editor.
Screenshots were prepared of the 12 test scenarios
developed from the foregoing list in the form of a simple
editing task to be completed (eg Highlight this word
because it's a product name
). A panel of testers was
recruited from local institutions, following the requirements
listed in the section “Who writes what” where possible. A
web-based questionnaire was used to gather information on
their work area, background, and professional experience in
order to eliminate those who fell outside the specifications,
resulting in 20 testers being asked to participate.
Testing was carried out in the Usability Testing Laboratory of the Human Factors Research Group (HFRG) in the School of Applied Psychology at University College Cork, during June and July 2013.
The test harness (some 200 generated screenshots with a script and protocol) was piloted both with colleagues in the HFRG experienced in usability testing, as well as with users from outside the institution who fitted the target user profile. Some logic choices, phrases and expressions, and changes to the rubrics were implemented as a result. The base screen used is shown in Figure 3.
Figure 3: Base screen showing generated interface
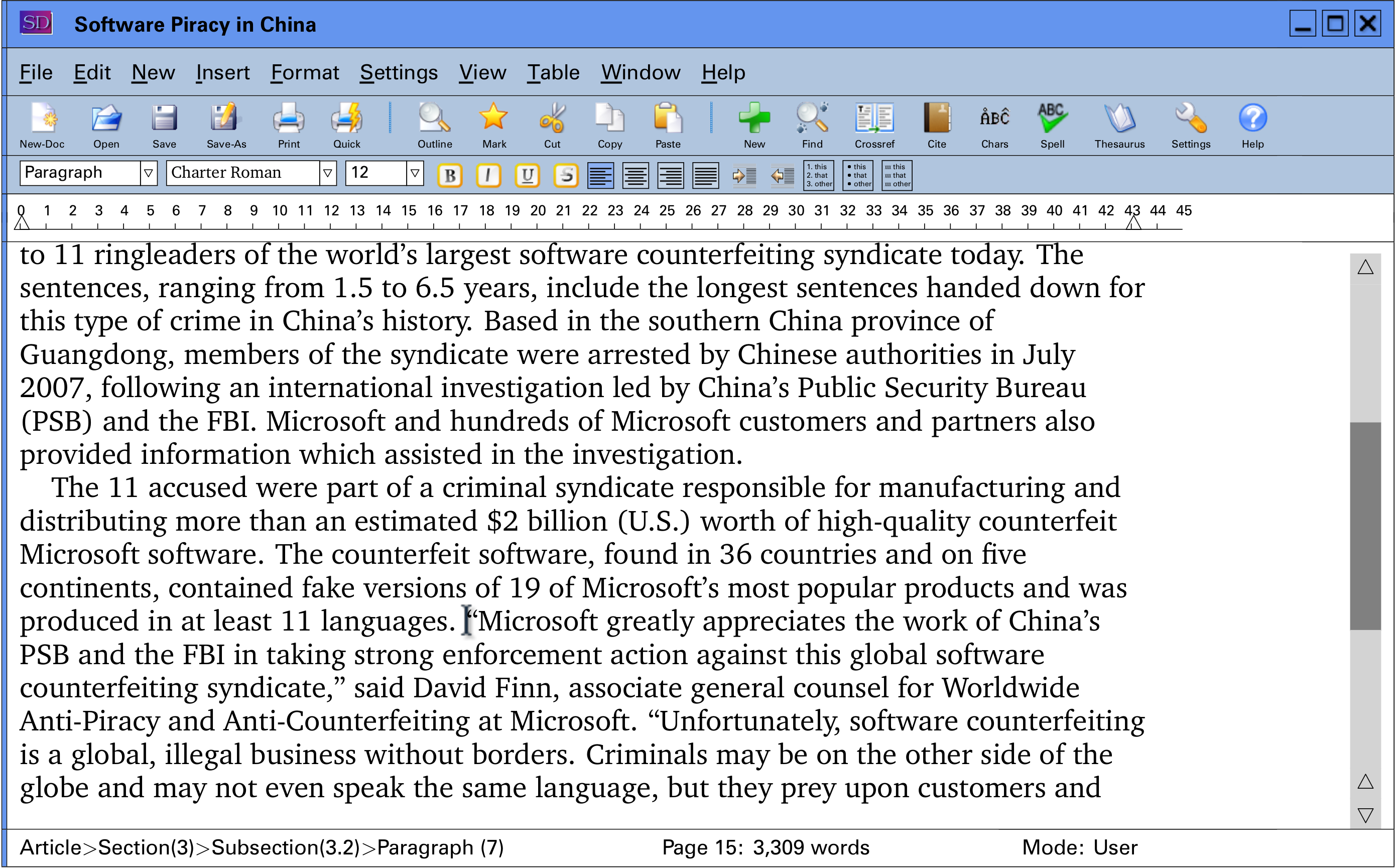
The additions and changes in the interface are:
-
a New menu item and toolbar button for adding new structural elements
-
a specific New-Doc toolbar button
-
an Outline toolbar button for access to the document structure for navigation
-
a Mark toolbar button for recursively selecting the current container
-
Crossref and Cite toolbar buttons
-
an additional List type toolbar button for description lists
Each tester was given time to study the interface screenshot before starting, and the additional buttons and menu items were explained. They were then presented with the 12 tests in sequence, and their clicks or keystrokes were recorded on paper for later analysis. After testing there was the opportunity to discuss the interface, and to identify if the tester felt that it was more or less efficient than their current system.
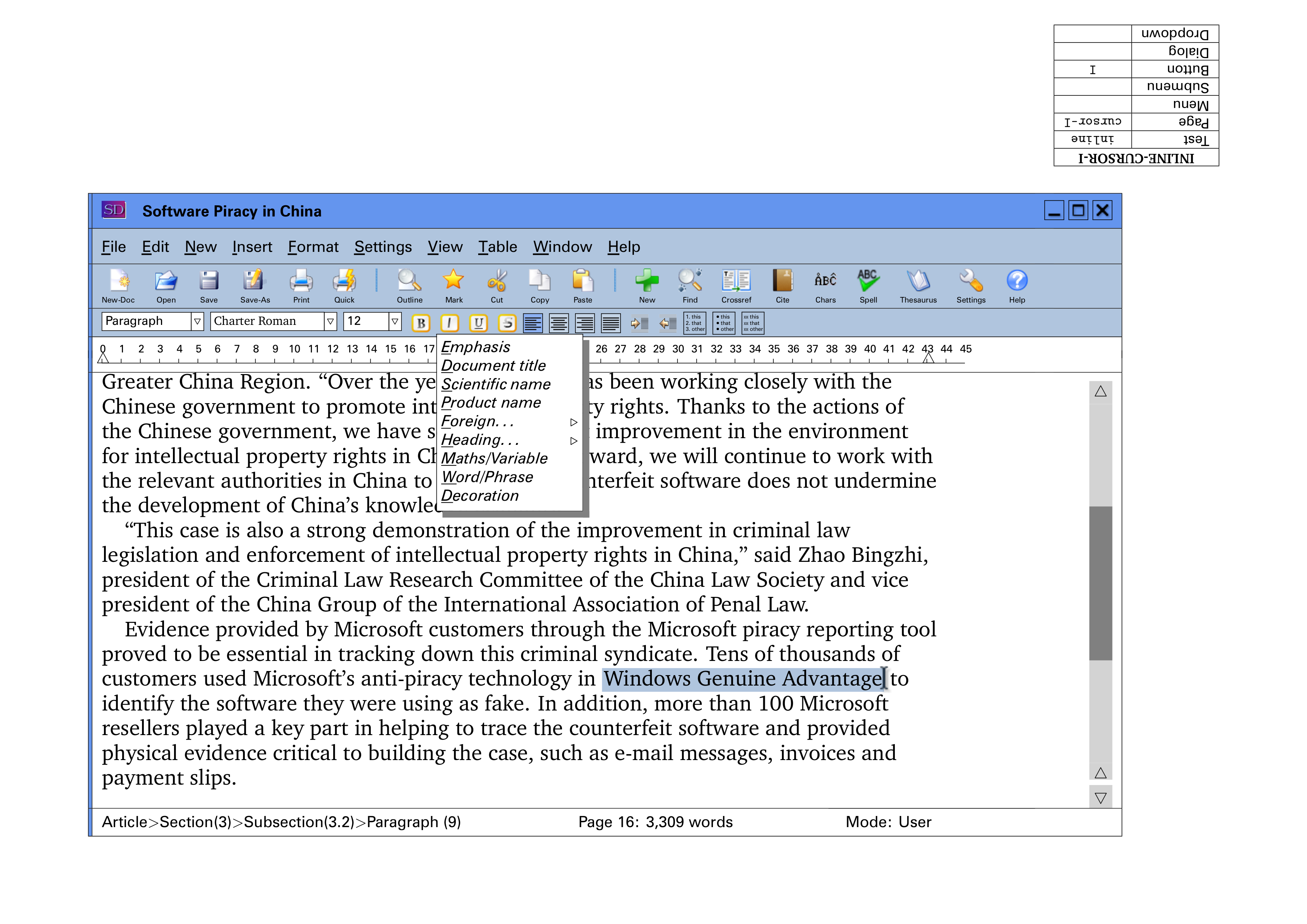
A sample screenshot
is shown in Figure 4. This shows the drop-down menu from clicking
the I button.
Figure 4: Paper-prototyping screenshot
showing
drop-down I button menu
The 12 tasks were:
-
Create a new document (a journal article)
-
Add a new paragraph after the current one
-
Split a paragraph into two
-
Join a paragraph to the preceding one
-
Join a paragraph to the following one
-
Add a new section to the article
-
Add a new (numbered) list
-
Move a block of text from one place to another
-
Highlight a product name (in italics)
-
Add a cross-reference to another section
-
Insert a citation and reference to a source
-
Insert a fragment from another document
A set of keystroke/mouseclick patterns was constructed for comparison with the testers' solutions, consisting of a sequence of mnemonics for the existing (traditional) ways of doing the tasks, and the new ways envisaged using the new affordances (buttons/menus).
Figure 5: Pattern examples
|
Add new list (task 7, rank 1, new method) |
|
|
Move a block of text (task 8, rank 7, old method) |
|
|
Add new section (task 6, rank 5, old method) |
|
Some of these (especially the list buttons) involved a change in behaviour which was explained before the test. The List buttons add a new list at the first available point after the cursor; they only make the current paragraph into a list item if the paragraph was selected.
Results
All testers completed all the tasks successfully, with one minor exception, although there were numerous divergences from the expected patterns en route. There were two principal axes of measurement:
-
how much use the testers made of the new functions in the interface; this was measured by a pattern rank value and an affordance class (old, new, or hybrid) for the pattern eventually followed in each task (Figure 6);
-
how much they diverged from the expected patterns; this was measured by the number of unexpected steps along the way to completing a task.
Using the affordances
The responses fell into two groups: those tasks solved by a preponderance of old or new methods, and those solved by a much wider mix.
Figure 6: Number of testers by task showing affordance class
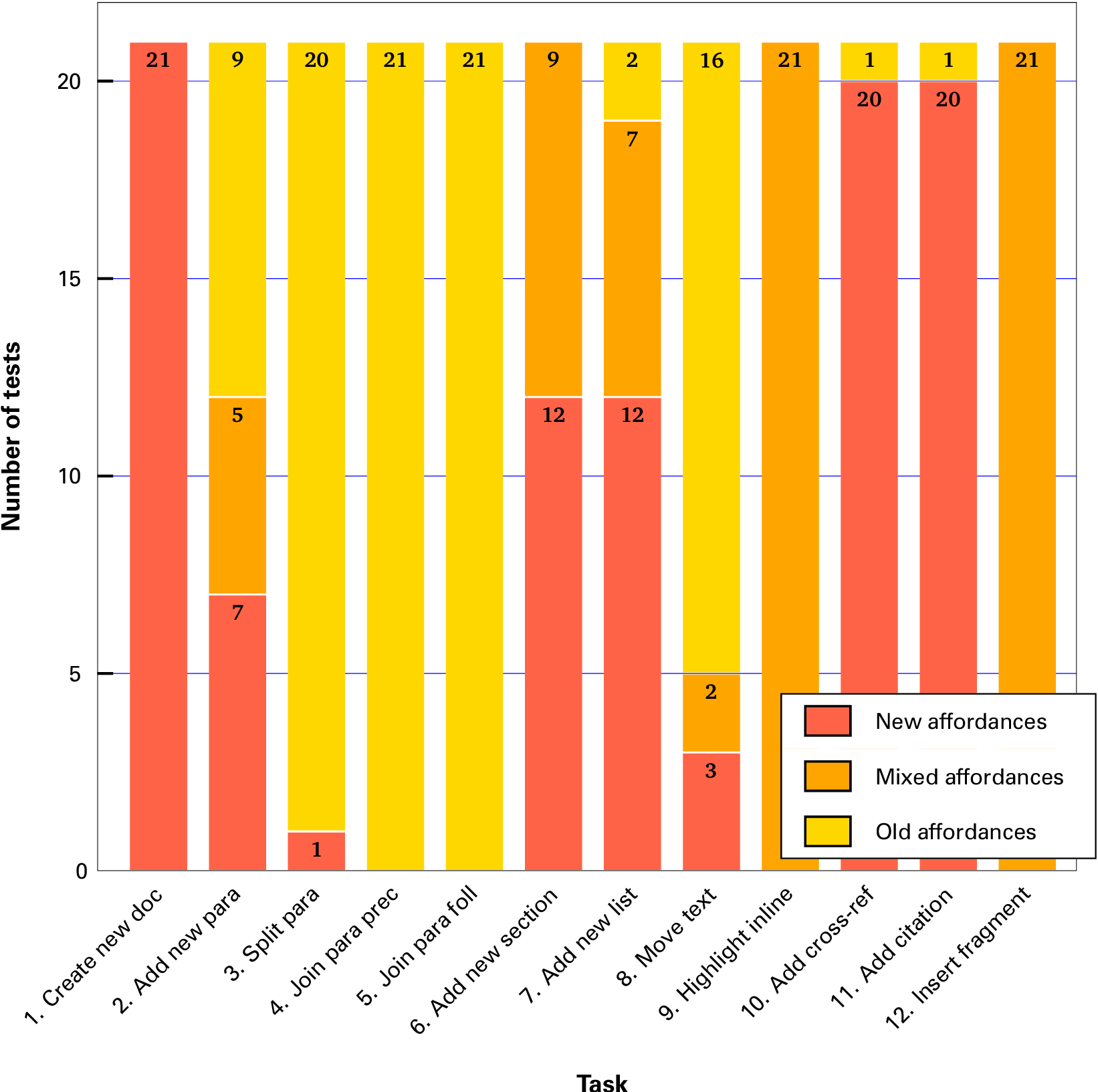
-
Three of the twelve tasks (create new document, insert cross-reference, and insert citation) were solved almost entirely using the new affordances; two more were solved using a hybrid approach (highlight product and insert fragment); and two were solved entirely using the traditional method (both join paragraph tests);
-
The remaining five showed an unrelated mix of old and new methods, showing a wide variety of approaches by the testers, although in two (adding new section and adding list), 12 out of 21 testers used the new affordances;
A preference for editing methods using existing, known, keystrokes or mouseclicks appears to be strong in the longest and most complex task (moving a block of text), and in the least understood task (splitting a paragraph: some testers had to ask what this meant).
Question 8 (highlighting in italics) has also been successfully tested independently by a project in the Netherlands examining a related but different aspect of text editing (Geers2010).
Divergences from the expected patterns
Thirty-five out of the 252 task solutions (12×21) included dvergences from the expected patterns: keystrokes or mouseclicks which were out of sequence, exploratory, unintended, or otherwise abnormal.
An outlier was eight divergent steps to solve Task 12
(Insert a fragment of another document
) using
the traditional steps of opening the external document,
finding, marking, and copying the required text, closing the
document, and pasting the text into position. This was an
extreme case, and perhaps indicates that the anecdotal
perception of user reluctance to adopt new methods may not be
entirely correct.
Figure 7: Total number of occasions of divergence by test
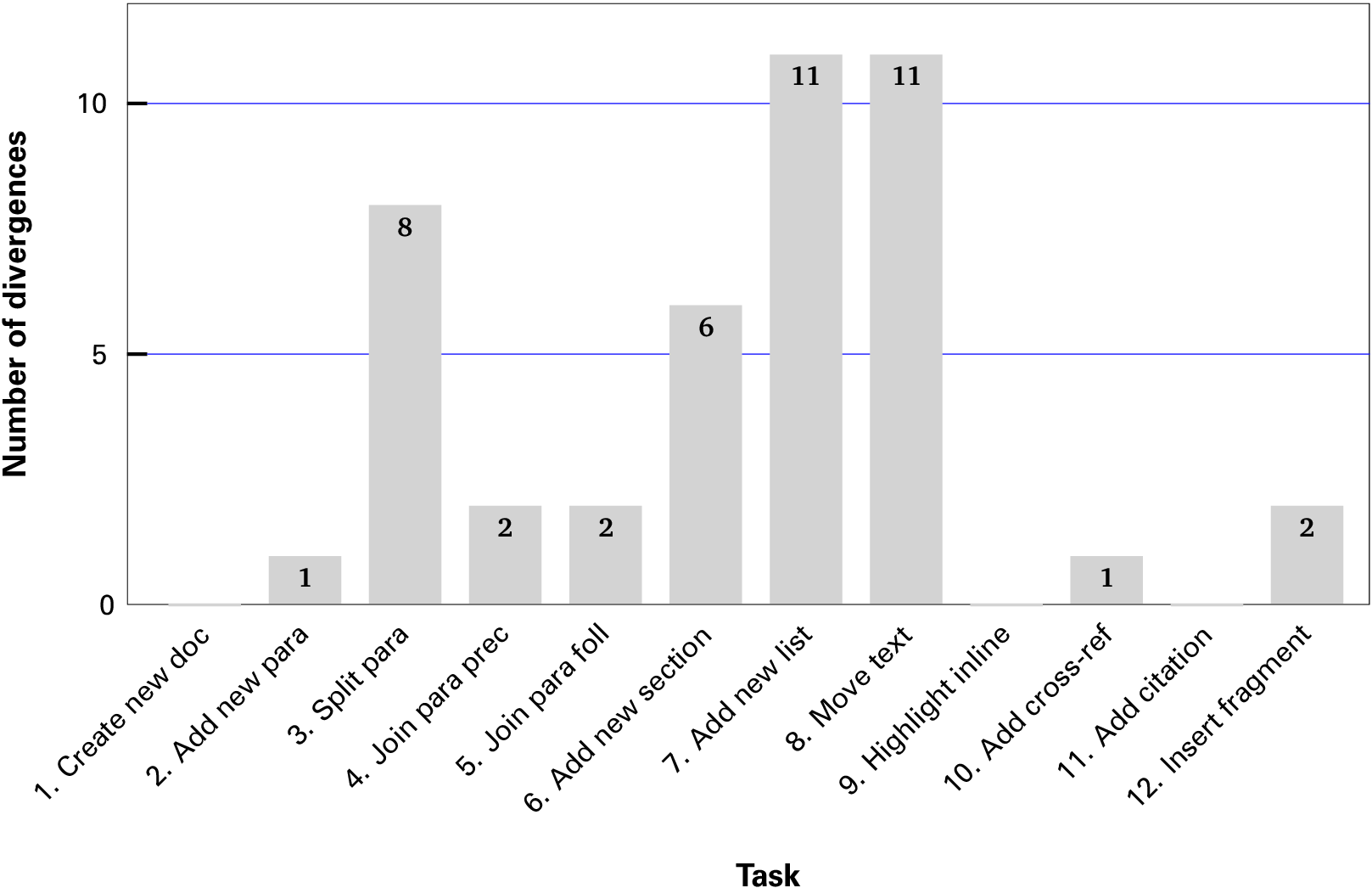
A measure of divergence was taken by by multiplying the number of divergences by the number of testers who diverged (a form of weighting) as shown by Figure 7.
Three tasks (create document, highlight product, and insert citation) were completed with no divergences at all, and five more (add paragraph, join paragraph [both], insert cross-reference, and insert document fragment) with only one or two.
The greater numbers of divergences were in task for which there are traditionally several different ways of achieving them, all equally valid. This may indicate that not all users stick to a single, canonical way of performing a task:
-
#3, Split paragraph; as noted earlier, some uncertainty clearly existed in the testers' mental model of a paragraph. In all these cases except the last, the first move (position the cursor) was correct, but three of them (four if we include the last) then exercised the New menu or button, believing the task to require the introduction of a new paragraph. It is not known if this is due to a fault in the rubric, although as the majority of testers succeeded with no problem, this is regarded as unlikely.
-
#6, Add new section; these are minor, as they are almost all the introduction of [unnecessary] vertical white-space before finally using the new affordances to add the new section.
-
#7, Add new list; as with test 3 above, the initial cursor movement was unexceptional (although unnecessary), but as with test 6, the extra white-space reveals the inheritance of the wordprocessor model, where the list buttons operate on the current paragraph.
-
#8, Move text; these were slightly more varied divergences: some do indeed use the same model as above (of adding white-space, in this case before pasting), but they included an experimental excursion into vi keystroke (shortcut) mode, and a use of the Find function to locate the end of the required section.
None of these would appear to affect the thesis that the
new affordances provide an alternative means to completing the
tasks, but they do perhaps reveal the change of mind-set
required for efficient use of a structured editor. In
discussion, several testers said they were unaware that an
editing interface could do so much
; that is,
automate so much of the task as this one implies.
Comment and discussion
Three questions were asked after each test session was completed:
-
How obvious was it what to click on?
-
Did you feel it needed more or fewer clicks than your current system?
-
Do you feel that the program is
doing it right
(that is,as you would expect
)?
These were not intended as formal survey questions, but more designed to elicit a conversational response, although time was limited as sessions were targeted at 45 minutes, and 30 of those were nominally assigned to the tests. They do nevertheless contribute an indication of potential user satisfaction, which is overall positive.
|
Obviousness |
Eight testers felt the interface was
|
|
More or fewer clicks? |
12 testers thought such an interface would take
fewer clicks than their current system (mainly
Word); six thought it would
take about the same number or |
|
Does it right? |
18 felt the interface |
The overall impression was of slight surprise that there even existed ways different from Word of doing everyday editing and writing tasks.
The additional comments made in answer to the questions indicate that some aspects of the interface as tested would need revising, or that a different way of expressing the intent (the affordance) should be investigated:
-
the term
document fragment
was a poor choice, as it uses a term not commonly understood.Paragraph
or (in the context),signature block
would have been better, even though the concept being tested was actually generalisable to other element types. -
the distinction between New (additional structural material) and Insert (new material inside existing text within a paragraph) was imperfectly understood. Despite the extensive misunderstandings created by the application of the term in the concept of document trees, perhaps it is already too well-entrenched to change.
-
the idea is interesting that more clicks would even be acceptable if the resulting document quality is improved or the reason for the clicks is made clear.
-
the breadcrumb should have been clickable.
Conclusions
We conclude that changes along these lines are likely to contribute to making a structured-document editor more usable by the target population.
In addition, a number of unexplored techniques were identified which could contribute to lower user frustration, among them Target Markup Adoption and Smart Insertion.
The benefits likely to accrue from these changes are greater user satisfaction and less training, leading to increased productivity and greater accuracy in document construction.
We did not directly test whether these benefits would lead to lower costs within an organisation, as there are many other factors which affect this, including the organisational change which may be required to move to a new system. However, as several of them have recently been implemented in interfaces, including Word and Xopus, there appears to be a willingness among manufacturers as well as users to use them.
References
[Ebel2005] Ebel, Hans Friedrich; Bliefert,
Claus; and Russey, William E. The Art of Scientific
Writing: From Student Reports to Professional Publications in
Chemistry and Related Fields.
Wiley-VCH, Weinheim,
Germany, 2nd ed. 2005. ISBN 9783527298297.
[Flynn2002] Flynn, Peter. Formatting
Information.
Special issue of TUGboat 23:2, 2002.
TeX Users Group, Portland, OR. http://www.ctan.org/tex-archive/info/beginlatex/,
§8.2.5, p.158.
[Flynn2006] Flynn, Peter. If XML is so
easy, how come it’s so hard?: The usability of editing
software for structured documents.
Presented at the
Extreme Markup Languages Conference 2006, Montréal, Canada,
August 7–11, 2006. http://research.ucc.ie/articles/extreme06
[Flynn2009] Flynn, Peter. Why writers
don't use XML: The usability of editing software for
structured documents.
Presented at Balisage: The
Markup Conference 2009, Montréal, Canada, August 11–14, 2009. In
Proceedings of Balisage: The Markup Conference 2009. Balisage
Series on Markup Technologies, vol. 3 (2009). doi:https://doi.org/10.4242/BalisageVol3.Flynn01.
[Geers2010] Geers, Frederik.
User-friendly structured document editing: removing
barriers for author acceptance.
Masters Thesis,
Content and Knowledge Engineering, University of
Utrecht.
[Joloboff1989] Joloboff, Vania.
Document Representation: Concepts and standards.
In Andre, J; Furuta, R; and Quint, V: Structured
Documents, CUP, Cambridge UK, 1989,
pp.75–105.
[McLeish2008] McLeish, Sheri; McNabb, Kyle;
Tsang, Keith. Breaking Up Is Hard To Do: The Microsoft
Word Love Story.
Forrester Research Inc, Cambridge MA,
Report 46409, December 2008. http://www.forrester.com/home?docid=46409#/Breaking+Up+Is+Hard+To+Do+The+Microsoft+Word+Love+Story/fulltext/-/E-RES46409
[Piez2007] Piez, Wendell and Usdin, Tommie.
Separating Mapping from Coding in Transformation
Tasks.
Presented at the XML Conference, Boston, MA,
December 3–5, 2007.
[Reid1980] Reid, Brian. Scribe: A
Document Specification Language and its Compiler.
PhD
Thesis, Carnegie-Mellon University, 1980.
[Schulz2009] Schultz, Michael.
Microsoft Office Is Right at Home.
Microsoft
Corporation, 8 Jan 2009. http://www.microsoft.com/en-us/news/features/2009/jan09/01-08cesofficeqaschultz.aspx
[Snyder2003] Snyder, Carolyn. Paper
Prototyping.
Morgan Kaufmann (Elsevier Science), San
Francisco, 2003. ISBN 1558608702.
[1] One editor, compiling chapters from different authors, unwittingly pasted all but the first chapter into the final footnote of the first chapter, because the cursor appeared to be at the end of the chapter, and OpenOffice permitted the footnote to hold eleven chapters' worth of text!
[2] Although both Word and OpenOffice/Libre Office now XML as a file storage format to represent the (unstructured) content of documents, we are concerned here with the use of semantic markup.