Introduction
The original aims of the web browser application was to retrieve, present and navigate information resources on the World wide Web (WWW). It started with static HTML documents, which can be seen as a text-based format standard for browsers required when rendering web pages. But it wasn't long before dynamic HTML and CSS came along, providing a richer interactive experience. Web browsers have come a long way in bundling complementary tools to provide interaction to the rendered HTML web pages, with CSS, JavaScript, JSON, AJAX, JQuery and more. Remarkably, the performance of these (largely interpreted) languages is highly satisfactory for most applications.
However, as successful as HTML as been to the browser, there exists an underlying problem, in that HTML is not best suited to representing document data. Such data we would expect to be stored on web servers or close to the browser on the client machine. XML was created to solve this problem, as a multi-purpose and platform-neutral text-base meta language, which could be used for storage, transmission and manipulation of data. It was a great way to represent data, but the question was what could we do with it on the browser? Given the introduction of XHTML as an application of XML with HTML, direct rendering of XML was not possible as browsers were designed for use with HTML. The need of program application to convert these special data documents written in XML to HTML became paramount.
The answer to this was XSLT. It was designed as a functional programming language for XML. It was now possible to convert XML documents into HTML documents which in turn could be rendered in the browsers. This was great for the 'Web 1.0' architecture, where we have static documents on the web, which needed to be rendered in the browser.
XSLT 1.0 was published in 1999 XSLT20. On the server it presented a way to convert XML data into HTML before it reached the browser. But the challenge was to get XSLT closer to the browser. Before the specification was finished Microsoft implemented XSLT 1.0 as an add-on to Internet Explorer (IE) 4, which became an integral part of IE5. (Microsoft made a false start by implementing a draft of the W3C specification that proved significantly different from the final Recommendation, which didn't help.) It then took a long time before XSLT processors with a sufficient level of conformance and performance were available across all common browsers. In the first couple of years the problem was old browsers that didn't have XSLT support; then the problem became new browsers that didn't have XSLT support. In the heady days while Firefox market share was growing exponentially, its XSLT support was very weak. More recently, some mobile browsers have appeared on the scene with similar problems. So there has never been a time when good XSLT 1.0 support was universal
By the time XSLT 1.0 conformance across browsers was substiantially achieved (say around 2009, if we exclude old browsers and newer mobile devices), other technologies had changed the goals for browser vendors. The emergence of XSLT 2.0 XSLT20, which made big strides over XSLT 1.0 in terms of developer productivity, never attracted any enthusiasm from the browser vendors — and the browser platforms were sufficiently closed that there appeared to be little scope for third-party implementations.
The 'Web 2.0' architecture within the browser sphere demonstrated the way forward for the user experience on the web. The web was no longer about producing pretty renditions of static documents, but was about interactions and event handling within web applications. These all came about with the introduction of CSS (a styling language for HTML/ XHTML web pages which can also do basic interactions), AJAX (acronym for asynchronous JavaScript and XML, which has been somewhat superseded now by less cumbersome tools), JavaScript (client-side scripting language, which has evolved into a powerful VM for the web browser platform). The introduction of JSON has made data interchange between client and server much more convenient, because of its good match to the JavaScript data model, but it doesn't help those whose applications are document-based, or whose data happens to be in XML.
A few years ago it seemed likely that XML would go no further for web applications, limited for ever to what could be achieved by server-side conversion to HTML. The browser vendors had no interest in developing it further, and the browser platform was so tightly closed that it wasn't feasible for a third party to develop the necessary tools. Plug-ins and applets as extension technologies were largely discredited, for good reasons. But paradoxically, the browser vendors' investment in Javascript provided the platform that could change this. Javascript was never designed as a system programming language, or as a target language for compilers to translate into, but that is what it has become, and it does the job surprisingly well. Above all else, it is astoundingly fast.
Google were one of the first to realise this, and responded by developing Google Web Toolkit (GWT) GWT as a Java-to-Javascript bridge technology. GWT allows web applications to be developed in Java (a language which in many ways is much better suited for the task than Javascript) and then cross-compiled to Javascript for execution on the browser. It provides most of the APIs familiar to Java programmers in other environments, and supplements these with APIs offering access to the more specific services available in the browser world, for example access to the HTML DOM, the Window object, and user interface events.
Because the Saxon XSLT 2.0 processor is written in Java, this gave us the opportunity to create a browser-based XSLT 2.0 processor by cutting down Saxon to its essentials and cross-compiling using GWT. An inspiration that such a project was possible was the development of the XProc engine for the browser vojt2010, as it was implemented using GWT.
We realized early on that simply offering XSLT 2.0 was not enough. Sure, there was a core of people using XSLT 1.0 who would benefit from the extra capability and productivity of the 2.0 version of the language. But it was never going to succeed using the old architectural model: generate an HTML page, display it, and walk away, leaving all the interesting interactive parts of the application to be written in Javascript. We would like to use XML technologies throughout, and that means replacing Javascript not only for content rendition (much of which can be done with CSS anyway), but more importantly for user interaction, including event handling. And it just so happens that the standard processing model for handling user interaction is event-based programming, and XSLT is an event-based programming language, so the opportunities are obvious.
The first implementation of XSLT 2.0 for the browser we call Saxon-CE SAXONCE. In this short paper we investigate the underlying concepts of Saxon-CE. Specifically, how does one use XSLT 2.0, which is a purely functional language to manipulate a stateful interactive dialogue with the user to develop web applications.
Interaction with XSLT 2.0
XSLT as a declarative language was influenced by the ideas of functional programming, and by text-based pattern matching lnaguages. In essence, we have an input document, ideally written in XML, which would then go into the XSLT process and then produce output at the other end. The output would be some result document in a desired format, which would be in many cases XML, HTML or some other textual representation. The template rule structure of the XSLT stylesheet made it posssible to match XML documents and their sub-trees in a recursive rule-based process while generating the output.
Offering XSLT 2.0 in the browser is a benefit to those coding XSLT 1.0 in the web, as it presents many advances, in term of extra capability and productivity. Regular expression support, user-written functions, and grouping are the most obvious examples, familiar to anyone at this conference. But offering interaction via XSLT 2.0 in the browser allows us to start winning over those Web 2.0 developers in supporting interaction and event handling.
In Saxon-CE we have a true XSLT 2.0 processor for the browser with some key extensions. However, what is different from our traditional approach when developing in XSLT is what we consider as our input and output document. The input not only can be some text-based document, as in XML, but we have available the HTML DOM tree from the browser in the current instance of the web page loaded. This is important when we think of accessing the HTML as we see it on the browser. Likewise the output would typically be to the HTML DOM. The output in fact is typically some document fragment which can be attached to the HTML tree, ready for the next phase of processing, as discussed later in this paper.
The following features are standard in XSLT 2.0, but we extend their use to support interaction, either through language extensions or through an imaginative interpretation of the flexibility that the language specification gives to implementors:
-
Multiple result files: The instruction
xsl:result-documentin XSLT 2.0 allow us to create multiple result trees. In Saxon-CE we take advantage of this instruction in an innovative way: we allow the transformation to create many small sub-trees, each of which is written to a different part of the HTML page. This means that a transformation phase does not need to rewrite the whole HTML document, it only needs to write those parts that have changed as a result of the user interaction. This leads to a radically different programming approach from the way XSLT is conventionally used. Thexsl:result-documentinstruction uses a URI to define the destination of the result tree; Saxon-CE defines a URI syntax that allows addressing into the HTML document, so that the result tree can be written to any part of the page -
The XDM data model: XDM (the data model for XSLT 2.0) is an abstract data model with a close relationship to the XML infoset. But the XDM specification gives implementations freedom how to construct an XDM instance to represent information that might not have originated as XML. Saxon-CE takes advantage of this to provide a view of the HTML page as an input document. The mappings to the HTML DOM are for the most part straightforward and familiar to anyone who has used XPath 1.0 in the browser, though there are a few surprises because of the way HTML5 in particular normalizes case and handles namespaces. But Saxon-CE also goes beyond merely mapping the HTML DOM to XDM. A peculiarity of the Javascript environment is that nodes in the HTML DOM correspond to Javascript objects, but there is often information in the Javascript objects which is not directly or conveniently available as DOM elements and attributes. To avoid users having to constantly escape into Javascript to access this information, Saxon-CE therefore exposes many of the properties of these Javascript objects as "virtual" attributes. These appear in a separate namespace to avoid conflicts with real attributes. There are in fact two such namespaces, one for properties of the Javascript object itself, and one for properties of the CSS style associated with each element.
Similarly, Saxon-CE also extends the XDM model to provide access to information beyond the scope of the HTML DOM, such as the properties of the browser window itself.
-
Template rules with mode setting: XSLT 2.0 allows a transformation to be initiated with a given context node, in a given mode. Saxon-CE takes advantage of this to process user interaction events in the browser, such as the user clicking a button. When an on-click event occurs on a button object, a transformation is initiated with the HTML element representing the button as the initial context node, and with the initial mode
ixsl:on-click(whereixslis a Saxon-CE defined namespace). Each such event starts a new transformation, which can produce one or more result trees. To preserve the purely functional semantics of XSLT, these result trees are not written back to the HTML DOM until the transformation has finished; a transformation cannot see its own updates. The approach used to achieve this is very similar to the use of pending update lists in XQuery Update (in fact the code is directly lifted from Saxon's implementation of XQuery updates). A beneficial effect of this has been high reliability; the product is largely insulated from the concurrency effects that otherwise occur when many events occur in quick succession, each modifying the same shared data.As well as handling user interaction events, Saxon-CE also allows a transformation to be triggered by a timer event, thus enabling animations.
-
Use of XSLT functions: XSLT 2.0 allows and encourages the development of function libraries by vendors and third parties, rather than requiring everything to be in the core language. Saxon-CE fully takes advantage of this flexibility and extensibility. Built in to the product is a small library of essential functions needed by anyone developing browser-based applications. These fall into two groups. The first group contains functions which access parts of the browser environment (
ixsl:pagegets the HTML document,ixsl:sourcegets the XML source document,ixsl:windowgets the browser window,ixsl:eventgets the current event). The second group provides interoperability between XSLT and Javascript code (ixsl:callcalls a Javascript function,ixsl:getgets a property of a Javascript object,ixsl:evalevaluates a Javascript expression supplied as a string.)These extensions enable the development of higher-level function libraries, which can provide access to the many rich Javascript libraries available to web developers. Developers choosing to take advantage of XSLT for writing their web applications do not need to forgo the joys of using these cool libraries available in the Javascript world.
HTML DOM Tree
In Figure 1 we illustrate that with Saxon-CE we can
manipulate the HTML DOM tree and handle events with the use of
xsl:result-document and xsl:template, respectively.
The code snippet below gives further detail of the use of the
xsl:result-document instruction. The hef attribute
contains a '#' symbol followed by the id value referencing the element
in the HTML DOM tree. This is where we would like to make modifications in the DOM
tree, for example we use the id attribute of the div
element. The method attribute has the value 'append-content' which
causes the result tree to be written as the last child of the div
element. Using the alternative 'replace-content' causes all its child nodes to be
replaced.
<xsl:result-document href="#x" method="append-content">
<p>text1</p>
</xsl:result-document>
As discussed before, in Saxon-CE we take advantage of modes in template instructions
to handle events which match the rule in the match attribute. This we show in the
code snippet below. Here we use the function matches with an regular
expression when matching a div element. We also show how we can set the
values of the JavaScript object properties from within he XSLT stylehsheet.
<xsl:template match="div[matches(@id, '\w\d')]" mode="ixsl:onclick">
<xsl:variable name="initial-square" select="@id"/>
<ixsl:set-property name="value" object="ixsl:page()//input[@id='inputBx']"
select="concat($initial-square, '-')"/>
</xsl:template>
Figure 1: HTML DOM Tree Saxon-CE interaction presented in the HTML DOM tree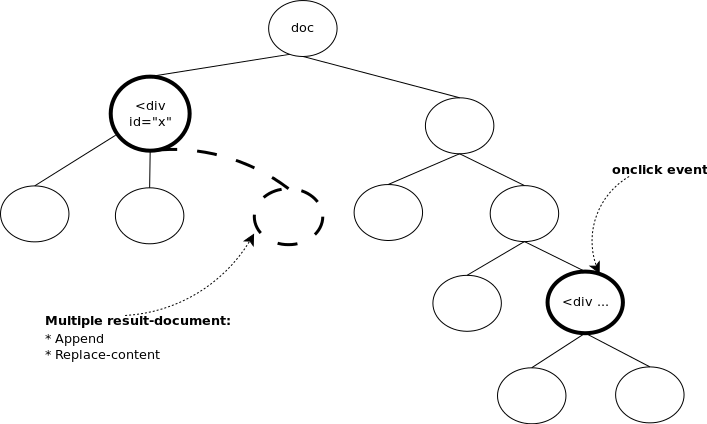
Saxon-CE implementation
As already mentioned, Saxon-CE is implemented using the Google Web Toolkit, which cross-compiles Java to Javascript for execution in the browser, and provides access to many aspects of the browser environment including the HTML DOM.
GWT does not offer the full range of class libraries available on the standard Java-SE
platform,
but it provides 90% of the interfaces that Saxon needs. Filling the gaps was not difficult.
Some of the
gaps are a little surprising, for example there is no java.net.URI class; but there
are plenty of open-source alternatives that provide the functionality Saxon uses.
In a few cases Saxon supplements the services GWT provides with native code written in Javascript, but the total amount is very small. For example, GWT's DOM interface provides no way of enumerating the attributes of an element, which is clearly needed to implement XPath; Saxon therefore handles this itself, using code that varies from one browser to another (in one case, it has to resort to re-parsing the source HTML).
Javascript notoriously provides only floating-point arithmetic, and GWT therefore
maps Java's integer
and long types to double-precision floating point. In view of this, we decided in
Saxon to implement the
XDM xs:integer and xs:decimal data types using the Java BigDecimal class, which is available
in GWT and appears to perform quite adequately.
One of the few areas we chose to compromise on XSLT and XPath conformance was in the code for converting floating-point numbers to strings. The mainstream Saxon product implements this logic itself, because the XPath rules are not aligned with the Java rules. But in the interests of code size and speed, we decided on the Saxon-CE platform to use GWT's toString() method for this, which maps directly to the Javascript implementation, and produces results that are perfectly acceptable to users, but not 100% conformant with the XPath specification.
By contrast, for regular expression handling we chose to use Saxon's regular expression engine (a fork of the open-source Jakarta engine from Apache) rather than the GWT regular expression library, which is a wrapper over the Javascript routines. The main reason is for Unicode support, which is very weak in the Javascript libraries.
The Saxon-EE product is over 250,000 lines of code. Key to Saxon-CE performance is
the size of the code
that needs to be downloaded, and so an early imperative was to cut this down. There
was no shortage of opportunities:
the schema processor and the query processor were obvious candidates. Less obvious
was the decision to drop the
highly-efficient TinyTree implementation of the XDM model, and rely on the much slower DOM. The final
code size is around 80K lines of Java, which compiles to around 900Kb of Javascript:
this results in a visible
delay when starting a Saxon-CE application, typically a couple of seconds — not a
long enough delay to deter most users.
And of course the code is cached, so this happens only on first access. There is scope
to reduce the code size
more than this — aggressive pruning could probably bring it down to half this, but
there is a law of diminishing
returns. Some of the bulkier parts of the code are already paged in on demand (for
example the data tables needed
to support Unicode normalization) and this technique could be extended.
Key to the practical utility of the product is the availability of developer tools. Hopefully in time third-party vendors will see the benefits of adding to the tooling available, but the product already comes with a very useful starter set of capabilities for tracing and debugging, fully integrated with the browser's developer console.
Saxon-CE applications
Some of the Saxon-CE applications that have been developed by users are showcased on Saxonica's web site SAXONDEMO. Inevitably, many of them were written to explore the capability of the technology rather than to meet a real business need. Games and puzzles feature strongly: and one can see why — creating a simple game in XSLT 2.0 is so much easier than writing it in Javascript. Another class of applications can be categorized as "data visualization": the idea of taking some complex data and generating a dynamic SVG animation is very appealing. Similarly, reports allowing arbitrary drilling-down into detail can involve creation of thousands of pages of static HTML if published in the conventional way on the server, but can deliver a better user experience while also saving on network bandwidth if delivered to the browser as raw XML.
The application we will demonstrate at the conference is perhaps one area where the benefits of XSLT in the browser are easiest to appreciate. It is also a live production application SAXONDOC. Both the "mainstream" Saxon and the Saxon-CE documentation are now delivered using this application, which provides an interactive browser/reader for the technical documentation.
We chose to maintain the documentation on the server in HTML5, rather than using a richer vocabulary such as DocBook or DITA. However, it's HTML5 containing logical structure only, with no presentation information; if displayed directly on the browser it would be readable, but very plain. Excluding the Javadoc API specifications, it's delivered as about 20 files totalling around 8Mb of text. The application is written entirely as a single XSLT stylesheet, plus a tiny amount of Javascript mainly to handle highlighting of search terms.
There's a catalog file on the server containing a top-level table of contents, which enables the contents menu to be displayed without downloading all 20 files; the rest of the content is downloaded on demand. It's a single page application, which presents a page-oriented hyperlinked view of the documentation in which each page has its own "hash-bang" URI which can be written down, bookmarked, and exchanged by email: all navigation functions within the application update this URI in the browser window, so the back button works as expected and generally, the experience of regular web browsing is faithfully reproduced, but with much better responsiveness.
The most obvious added-value that the application brings to the content over regular static HTML browsing is the ability to search the whole 8Mb of text for keywords, without returning to the server. But there are many other navigation aids such as table of contents, hyperlinks, breadcrumbs, and forward and backward navigation, all implemented directly in the XSLT 2.0 code. All of this could of course have been written in Javascript, but it would have required far more code and almost certainly, far more debugging.
The benefits of the approach are particularly noticeable for the Javadoc API browser. Saxon is a big product and the static Javadoc was becoming extremely unwieldy, as well as delivering a very old-fashioned image. The sheer bulk of the HTML files (each containing reams of identical presentation information, as well as highly redundant content) made it difficult to manage, discouraging incremental updates and corrections, or maintenance of multiple versions. For the new approach, we found and adapted a Javadoc plug-in (or "doclet") to generate XML instead of HTML, and then do a modest amount of server-side XSLT processing on this XML prior to publication; the rest of the job is done by the XSLT 2.0 stylesheet on the browser. The result for the user is much slicker navigation around the information; for the publisher (ourselves) it's a much lighter-weight publication workflow.
Conclusion
In this paper we have presented a number of innovative ideas of Saxon-CE and a plethora of possible use case applications. We have not only demonstrated how one can bring XSLT 2.0 into the web browser, with the help of Google's GWT technology, but that it is possible to extend XSLT 2.0 into a feature rich Web '2.0' architecture tool. We can now develop interactive client-side applications in XSLT 2.0, which has the HTML DOM tree and XML documents as its core data model. It is also possible for Saxon-CE to interoperate with JavaScript or even be used as its replacement.
References
[XSLT10] Clark, James. XSL Transformations (XSLT) Version 1.0, 16 November 1999. W3C Recommendation. http://www.w3.org/TR/xslt
[XSLT20] Kay, Michael. XSL Transformations (XSLT) Version 2.0, 23 January 2007. W3C Recommendation. http://www.w3.org/TR/xslt20
[vojt2010] Vojtěch, Toman. XML Pipeline Processing in the Browser. Presented at Balisage: The Markup Conference 2010, Montréal, Canada, August 3 - 6, 2010. In Proceedings of Balisage: The Markup Conference 2010. Balisage Series on Markup Technologies, vol. 5 (2010). doi:https://doi.org/10.4242/BalisageVol5.Toman01.
[GWT] Google Web Toolkit (GWT). Google. http://code.google.com/webtoolkit/
[SAXONCE] Saxon-CE. Saxonica. https://github.com/Saxonica/Saxon-CE
[SAXONDOC] Saxon Documentation driven by Saxon-CE. Saxonica. http://www.saxonica.com/documentation/index.html
[SAXONDEMO] Saxon-CE Demonstrations. Saxonica. http://www.saxonica.com/ce/user-doc/1.1/index.html#!demonstrations