Introduction
Parallelization and acceleration of XML parsing is a widely studied problem that has seen the development of a number of interesting research prototypes using both single-instruction multiple-data (SIMD) and multi-core parallelism. Most works have investigated data parallel solutions on multicore architectures using various strategies to break input documents into segments that can be allocated to different cores. For example, one possibility for data parallelization is to add a pre-parsing step to compute a skeleton tree structure of an XML document Lu and Chiu 2006. The parallelization of the pre-parsing stage itself can be tackled with state machines Pan and Zhang 2007, Pan and Zhang 2008b. Methods without pre-parsing have used speculation You and Wang 2011 or post-processing that combines the partial results Shah and Rao 2009. A hybrid technique that combines data and pipeline parallelism was proposed to hide the latency of a "job" that has to be done sequentially Pan and Zhang 2008a.
Fewer efforts have investigated SIMD parallelism, although this approach has the potential advantage of improving single core performance as well as offering savings in energy consumption Lin and Medforth 2012. Intel introduced specialized SIMD string processing instructions in the SSE 4.2 instruction set extension and showed how they can be used to improve the performance of XML parsing Lei 2008. The Parabix framework uses generic SIMD extensions and bit parallel methods to process hundreds of XML input characters simultaneously Balisage 2009 Parabix2 2011. Parabix prototypes have also combined SIMD methods with thread-level parallelism to achieve further acceleration on multicore systems Lin and Medforth 2012.
In this paper, we move beyond research prototypes to consider the detailed integration of both SIMD and multicore parallelism into the Xerces-C++ parser of the Apache Software Foundation, an existing standards-compliant open-source parser that is widely used in commercial practice. The challenge of this work is to parallelize the Xerces parser in such a way as to preserve the existing APIs as well as offering worthwhile end-to-end acceleration of XML processing. To achieve the best results possible, we undertook a nine-month comprehensive restructuring of the Xerces-C++ parser, seeking to expose as many critical aspects of XML parsing as possible for parallelization, the result of which we named icXML. Overall, we employed Parabix-style methods of transcoding, tokenization and tag parsing, parallel string comparison methods in symbol resolution, bit parallel methods in namespace processing, as well as staged processing using pipeline parallelism to take advantage of multiple cores.
The remainder of this paper is organized as follows. section “Background” discusses the structure of the Xerces and Parabix XML parsers and the fundamental differences between the two parsing models. section “Architecture” then presents the icXML design based on a restructured Xerces architecture to incorporate SIMD parallelism using Parabix methods. section “Multithreading with Pipeline Parallelism” moves on to consider the multithreading of the icXML architecture using the pipeline parallelism model. section “Performance” analyzes the performance of both the single-threaded and multi-threaded versions of icXML in comparison to original Xerces, demonstrating substantial end-to-end acceleration of a GML-to-SVG translation application written against the Xerces API. section “Conclusion and Future Work” concludes the paper with a discussion of future work and the potential for applying the techniques discussed herein in other application domains.
Background
Xerces C++ Structure
The Xerces C++ parser is a widely-used standards-conformant XML parser produced as open-source software by the Apache Software Foundation. It features comprehensive support for a variety of character encodings both commonplace (e.g., UTF-8, UTF-16) and rarely used (e.g., EBCDIC), support for multiple XML vocabularies through the XML namespace mechanism, as well as complete implementations of structure and data validation through multiple grammars declared using either legacy DTDs (document type definitions) or modern XML Schema facilities. Xerces also supports several APIs for accessing parser services, including event-based parsing using either pull parsing or SAX/SAX2 push-style parsing as well as a DOM tree-based parsing interface.
Xerces, like all traditional parsers, processes XML documents sequentially a byte-at-a-time from the first to the last byte of input data. Each byte passes through several processing layers and is classified and eventually validated within the context of the document state. This introduces implicit dependencies between the various tasks within the application that make it difficult to optimize for performance. As a complex software system, no one feature dominates the overall parsing performance. Table I shows the execution time profile of the top ten functions in a typical run. Even if it were possible, Amdahl's Law dictates that tackling any one of these functions for parallelization in isolation would only produce a minute improvement in performance. Unfortunately, early investigation into these functions found that incorporating speculation-free thread-level parallelization was impossible and they were already performing well in their given tasks; thus only trivial enhancements were attainable. In order to obtain a systematic acceleration of Xerces, it should be expected that a comprehensive restructuring is required, involving all aspects of the parser.
Table I
Execution Time of Top 10 Xerces Functions
| Time (%) | Function Name |
|---|---|
| 13.29 | XMLUTF8Transcoder::transcodeFrom |
| 7.45 | IGXMLScanner::scanCharData |
| 6.83 | memcpy |
| 5.83 | XMLReader::getNCName |
| 4.67 | IGXMLScanner::buildAttList |
| 4.54 | RefHashTableO<>::findBucketElem |
| 4.20 | IGXMLScanner::scanStartTagNS |
| 3.75 | ElemStack::mapPrefixToURI |
| 3.58 | ReaderMgr::getNextChar |
| 3.20 | IGXMLScanner::basicAttrValueScan |
The Parabix Framework
The Parabix (parallel bit stream) framework is a transformative approach to XML
parsing (and other forms of text processing.) The key idea is to exploit the
availability of wide SIMD registers (e.g., 128-bit) in commodity processors to represent
data from long blocks of input data by using one register bit per single input byte.
To
facilitate this, the input data is first transposed into a set of basis bit streams.
For example, Table II shows the ASCII bytes for the string "b7<A" with
the corresponding 8 basis bit streams, b0 through b7 shown in Table III.
The bits used to construct b7 have been highlighted in this example.
Boolean-logic operations (∧, ∨ and ¬ denote the
boolean AND, OR and NOT operators) are used to classify the input bits into
a set of
character-class bit streams, which identify key
characters (or groups of characters) with a 1. For example, one of the
fundamental characters in XML is a left-angle bracket. A character is an
'<' if and only if
¬(b0 ∨ b1)
∧ (b2 ∧ b3)
∧ (b4 ∧ b5)
∧ ¬ (b6 ∨
b7) = 1. Similarly, a character is numeric, [0-9]
if and only if ¬(b0 ∨
b1) ∧ (b2 ∧
b3) ∧ ¬(b4
∧ (b5 ∨
b6)). An important observation here is that ranges of
characters may require fewer operations than individual characters and
multiple
classes can share the classification cost.
Table II
XML Source Data
| String | b
|
7
|
<
|
A
|
| ASCII | 01100010
|
00110111 |
00111100 |
01000001 |
Table III
8-bit ASCII Basis Bit Streams
| b0 | b1 | b2 | b3 | b4 | b5 | b6 | b7 |
0
|
1
|
1
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
1
|
1
|
0
|
1
|
1
|
1
|
0
|
0
|
1
|
1
|
1
|
1
|
0
|
0
|
0
|
1
|
0
|
0
|
0
|
0
|
0
|
1
|
Consider, for example, the XML source data stream shown in the first line of Table IV.
The remaining lines of this figure show
several parallel bit streams that are computed in Parabix-style parsing, with each
bit
of each stream in one-to-one correspondence to the source character code units of
the
input stream. For clarity, 1 bits are denoted with 1 in each stream and 0 bits are
represented as underscores. The first bit stream shown is that for the opening angle
brackets that represent tag openers in XML. The second and third streams show a
partition of the tag openers into start tag marks and end tag marks depending on the
character immediately following the opener (i.e., "/") or
not. The remaining three lines show streams that can be computed in subsequent parsing
(using the technique of bitstream addition Parabix2 2011), namely streams
marking the element names, attribute names and attribute values of tags.
Table IV
XML Source Data and Derived Parallel Bit Streams
| Source Data | <document>fee<element a1='fie' a2 = 'foe'></element>fum</document> |
| Tag Openers | 1____________1____________________________1____________1__________ |
| Start Tag Marks | _1____________1___________________________________________________ |
| End Tag Marks | ___________________________________________1____________1_________ |
| Empty Tag Marks | __________________________________________________________________ |
| Element Names | _11111111_____1111111_____________________________________________ |
| Attribute Names | ______________________11_______11_________________________________ |
| Attribute Values | __________________________111________111__________________________ |
Two intuitions may help explain how the Parabix approach can lead to improved XML parsing performance. The first is that the use of the full register width offers a considerable information advantage over sequential byte-at-a-time parsing. That is, sequential processing of bytes uses just 8 bits of each register, greatly limiting the processor resources that are effectively being used at any one time. The second is that byte-at-a-time loop scanning loops are actually often just computing a single bit of information per iteration: is the scan complete yet? Rather than computing these individual decision-bits, an approach that computes many of them in parallel (e.g., 128 bytes at a time using 128-bit registers) should provide substantial benefit.
Previous studies have shown that the Parabix approach improves many aspects of XML processing, including transcoding u8u16 2008, character classification and validation, tag parsing and well-formedness checking. The first Parabix parser used processor bit scan instructions to considerably accelerate sequential scanning loops for individual characters Parabix1 2008. Recent work has incorporated a method of parallel scanning using bitstream addition Parabix2 2011, as well as combining SIMD methods with 4-stage pipeline parallelism to further improve throughput Lin and Medforth 2012. Although these research prototypes handled the full syntax of schema-less XML documents, they lacked the functionality required by full XML parsers.
Commercial XML processors support transcoding of multiple character sets and can parse and validate against multiple document vocabularies. Additionally, they provide API facilities beyond those found in research prototypes, including the widely used SAX, SAX2 and DOM interfaces.
Sequential vs. Parallel Paradigm
Xerces—like all traditional XML parsers—processes XML documents
sequentially. Each character is examined to distinguish between the XML-specific markup,
such as a left angle bracket "<", and the content held within the
document. As the parser progresses through the document, it alternates between markup
scanning, validation and content processing modes.
In other words, Xerces belongs to an equivalence class of applications termed FSM applications.[1] Each state transition indicates the processing context of subsequent characters. Unfortunately, textual data tends to be unpredictable and any character could induce a state transition.
Parabix-style XML parsers utilize a concept of layered processing. A block of source text is transformed into a set of lexical bitstreams, which undergo a series of operations that can be grouped into logical layers, e.g., transposition, character classification, and lexical analysis. Each layer is pipeline parallel and require neither speculation nor pre-parsing stages Lin and Medforth 2012. To meet the API requirements of the document-ordered Xerces output, the results of the Parabix processing layers must be interleaved to produce the equivalent behaviour.
Architecture
Overview
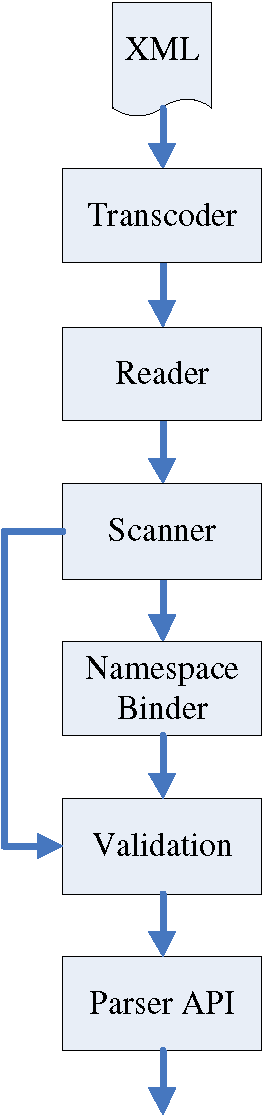
icXML is more than an optimized version of Xerces. Many components were grouped, restructured and rearchitected with pipeline parallelism in mind. In this section, we highlight the core differences between the two systems. As shown in Figure Figure 1, Xerces is comprised of five main modules: the transcoder, reader, scanner, namespace binder, and validator. The Transcoder converts source data into UTF-16 before Xerces parses it as XML; the majority of the character set encoding validation is performed as a byproduct of this process. The Reader is responsible for the streaming and buffering of all raw and transcoded (UTF-16) text. It tracks the current line/column position, performs line-break normalization and validates context-specific character set issues, such as tokenization of qualified-names. The Scanner pulls data through the reader and constructs the intermediate representation (IR) of the document; it deals with all issues related to entity expansion, validates the XML well-formedness constraints and any character set encoding issues that cannot be completely handled by the reader or transcoder (e.g., surrogate characters, validation and normalization of character references, etc.) The Namespace Binder is a core piece of the element stack. It handles namespace scoping issues between different XML vocabularies. This allows the scanner to properly select the correct schema grammar structures. The Validator takes the IR produced by the Scanner (and potentially annotated by the Namespace Binder) and assesses whether the final output matches the user-defined DTD and schema grammar(s) before passing it to the end-user.
Figure 1: Xerces Architecture
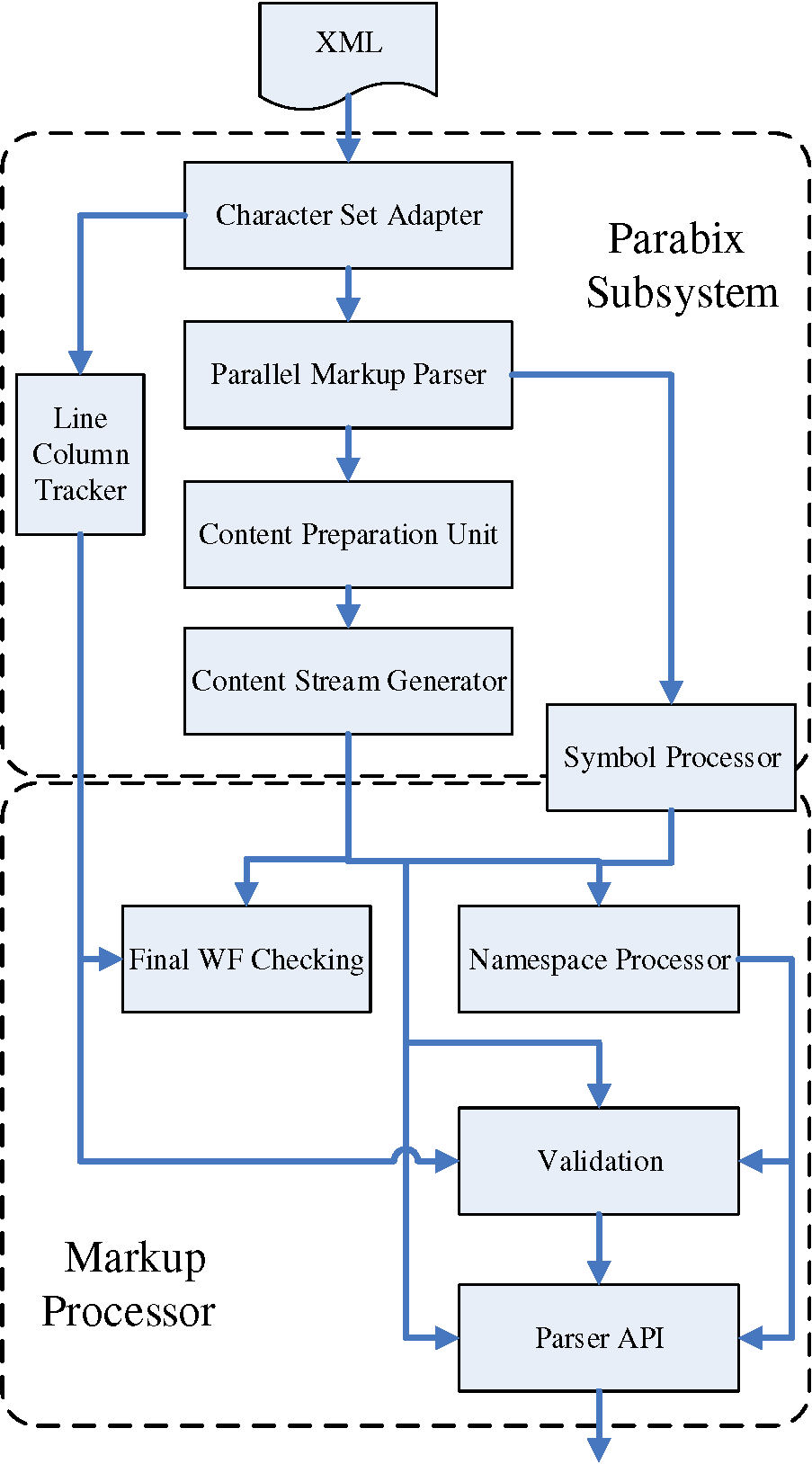
In icXML functions are grouped into logical components. As shown in Figure 1, two major categories exist: (1) the Parabix Subsystem and (2) the Markup Processor. All tasks in (1) use the Parabix Framework Lin and Medforth 2012, which represents data as a set of parallel bitstreams. The Character Set Adapter, discussed in section “Character Set Adapters”, mirrors Xerces's Transcoder duties; however instead of producing UTF-16 it produces a set of lexical bitstreams, similar to those shown in Parabix1 2008. These lexical bitstreams are later transformed into UTF-16 in the Content Stream Generator, after additional processing is performed. The first precursor to producing UTF-16 is the Parallel Markup Parser phase. It takes the lexical streams and produces a set of marker bitstreams in which a 1-bit identifies significant positions within the input data. One bitstream for each of the critical piece of information is created, such as the beginning and ending of start tags, end tags, element names, attribute names, attribute values and content. Intra-element well-formedness validation is performed as an artifact of this process. Like Xerces, icXML must provide the Line and Column position of each error. The Line-Column Tracker uses the lexical information to keep track of the document position(s) through the use of an optimized population count algorithm, described in section “Error Handling”. From here, two data-independent branches exist: the Symbol Resolver and Content Preparation Unit.
A typical XML file contains few unique element and attribute names—but each of them will occur frequently. icXML stores these as distinct data structures, called symbols, each with their own global identifier (GID). Using the symbol marker streams produced by the Parallel Markup Parser, the Symbol Resolver scans through the raw data to produce a sequence of GIDs, called the symbol stream.
The final components of the Parabix Subsystem are the Content Preparation Unit and Content Stream Generator. The former takes the (transposed) basis bitstreams and selectively filters them, according to the information provided by the Parallel Markup Parser, and the latter transforms the filtered streams into the tagged UTF-16 content stream, discussed in section “Content Stream”.
Combined, the symbol and content stream form icXML's compressed IR of the XML document. The Markup Processor parses the IR to validate and produce the sequential output for the end user. The Final WF checker performs inter-element well-formedness validation that would be too costly to perform in bit space, such as ensuring every start tag has a matching end tag. Xerces's namespace binding functionality is replaced by the Namespace Processor. Unlike Xerces, it is a discrete phase that produces a series of URI identifiers (URI IDs), the URI stream, which are associated with each symbol occurrence. This is discussed in section “Namespace Handling”. Finally, the Validation layer implements the Xerces's validator. However, preprocessing associated with each symbol greatly reduces the work of this stage.
Figure 2: icXML Architecture
Character Set Adapters
In Xerces, all input is transcoded into UTF-16 to simplify the parsing costs of Xerces itself and provide the end-consumer with a single encoding format. In the important case of UTF-8 to UTF-16 transcoding, the transcoding costs can be significant, because of the need to decode and classify each byte of input, mapping variable-length UTF-8 byte sequences into 16-bit UTF-16 code units with bit manipulation operations. In other cases, transcoding may involve table look-up operations for each byte of input. In any case, transcoding imposes at least a cost of buffer copying.
In icXML, however, the concept of Character Set Adapters (CSAs) is used to minimize transcoding costs. Given a specified input encoding, a CSA is responsible for checking that input code units represent valid characters, mapping the characters of the encoding into the appropriate bitstreams for XML parsing actions (i.e., producing the lexical item streams), as well as supporting ultimate transcoding requirements. All of this work is performed using the parallel bitstream representation of the source input.
An important observation is that many character sets are an extension to the legacy 7-bit ASCII character set. This includes the various ISO Latin character sets, UTF-8, UTF-16 and many others. Furthermore, all significant characters for parsing XML are confined to the ASCII repertoire. Thus, a single common set of lexical item calculations serves to compute lexical item streams for all such ASCII-based character sets.
A second observation is that—regardless of which character set is used—quite often all of the characters in a particular block of input will be within the ASCII range. This is a very simple test to perform using the bitstream representation, simply confirming that the bit 0 stream is zero for the entire block. For blocks satisfying this test, all logic dealing with non-ASCII characters can simply be skipped. Transcoding to UTF-16 becomes trivial as the high eight bitstreams of the UTF-16 form are each set to zero in this case.
A third observation is that repeated transcoding of the names of XML elements, attributes and so on can be avoided by using a look-up mechanism. That is, the first occurrence of each symbol is stored in a look-up table mapping the input encoding to a numeric symbol ID. Transcoding of the symbol is applied at this time. Subsequent look-up operations can avoid transcoding by simply retrieving the stored representation. As symbol look up is required to apply various XML validation rules, there is achieves the effect of transcoding each occurrence without additional cost.
The cost of individual character transcoding is avoided whenever a block of input is confined to the ASCII subset and for all but the first occurrence of any XML element or attribute name. Furthermore, when transcoding is required, the parallel bitstream representation supports efficient transcoding operations. In the important case of UTF-8 to UTF-16 transcoding, the corresponding UTF-16 bitstreams can be calculated in bit parallel fashion based on UTF-8 streams u8u16 2008, and all but the final bytes of multi-byte sequences can be marked for deletion as discussed in the following subsection. In other cases, transcoding within a block only need be applied for non-ASCII bytes, which are conveniently identified by iterating through the bit 0 stream using bit scan operations.
Combined Parallel Filtering
As just mentioned, UTF-8 to UTF-16 transcoding involves marking all but the last
bytes of multi-byte UTF-8 sequences as positions for deletion. For example, the two
Chinese characters 你好 are represented as two
three-byte UTF-8 sequences E4 BD A0 and E5 A5 BD while the
UTF-16 representation must be compressed down to the two code units 4F60
and 597D. In the bit parallel representation, this corresponds to a
reduction from six bit positions representing UTF-8 code units (bytes) down to just
two
bit positions representing UTF-16 code units (double bytes). This compression may
be
achieved by arranging to calculate the correct UTF-16 bits at the final position of
each
sequence and creating a deletion mask to mark the first two bytes of each 3-byte
sequence for deletion. In this case, the portion of the mask corresponding to these
input bytes is the bit sequence 110110. Using this approach, transcoding
may then be completed by applying parallel deletion and inverse transposition of the
UTF-16 bitstreams u8u16 2008.
Rather than immediately paying the costs of deletion and transposition just for
transcoding, however, icXML defers these steps so that the deletion masks for several
stages of processing may be combined. In particular, this includes core XML requirements
to normalize line breaks and to replace character reference and entity references
by
their corresponding text. In the case of line break normalization, all forms of line
breaks, including bare carriage returns (CR), line feeds (LF) and CR-LF combinations
must be normalized to a single LF character in each case. In icXML, this is achieved
by
first marking CR positions, performing two bit parallel operations to transform the
marked CRs into LFs, and then marking for deletion any LF that is found immediately
after the marked CR as shown by the Pablo source code in
Figure 3.
Figure 3: Line Break Normalization Logic
# XML 1.0 line-break normalization rules.
if lex.CR:
# Modify CR (#x0D) to LF (#x0A)
u16lo.bit_5 ^= lex.CR
u16lo.bit_6 ^= lex.CR
u16lo.bit_7 ^= lex.CR
CRLF = pablo.Advance(lex.CR) & lex.LF
callouts.delmask |= CRLF
# Adjust LF streams for line/column tracker
lex.LF |= lex.CR
lex.LF ^= CRLF
In essence, the deletion masks for transcoding and for line break normalization each represent a bitwise filter; these filters can be combined using bitwise-or so that the parallel deletion algorithm need only be applied once.
A further application of combined filtering is the processing of XML character and
entity references. Consider, for example, the references & or
< which must be replaced in XML processing with the single
& and < characters, respectively. The
approach in icXML is to mark all but the first character positions of each reference
for
deletion, leaving a single character position unmodified. Thus, for the references
& or < the masks 01111 and
011111 are formed and combined into the overall deletion mask. After the
deletion and inverse transposition operations are finally applied, a post-processing
step inserts the proper character at these positions. One note about this process
is
that it is speculative; references are assumed to generally be replaced by a single
UTF-16 code unit. In the case, that this is not true, it is addressed in
post-processing.
The final step of combined filtering occurs during the process of reducing markup data to tag bytes preceding each significant XML transition as described in section “Content Stream”. Overall, icXML avoids separate buffer copying operations for each of the these filtering steps, paying the cost of parallel deletion and inverse transposition only once. Currently, icXML employs the parallel-prefix compress algorithm of Steele Warren 2002. Performance is independent of the number of positions deleted. Future versions of icXML are expected to take advantage of the parallel extract operation Hilewitz and Lee 2006 that Intel is now providing in its Haswell architecture.
Content Stream
A relatively-unique concept for icXML is the use of a filtered content stream.
Rather that parsing an XML document in its original format, the input is transformed
into one that is easier for the parser to iterate through and produce the sequential
output. In Table V, the source data
<document>fee<element a1='fie' a2 = 'foe'></element>fum</document>
is transformed into
0fee0=fie0=foe0>0/fum0/
through the parallel filtering algorithm, described in section “Combined Parallel Filtering”.
Table V
XML Source Data and Derived Parallel Bit Streams
| Source Data |
<document>fee<element a1='fie' a2 = 'foe'></element>fum</document> |
| String Ends | 1____________1_______________1__________1_1____________1__________ |
| Markup Identifiers | _________1______________1_________1______1_1____________1_________ |
| Deletion Mask | _11111111_____1111111111_1____1111_11_______11111111_____111111111 |
| Undeleted Data | 0________>fee0__________=_fie0____=__foe0>0/________fum0/_________
|
Combined with the symbol stream, the parser traverses the content stream to
effectively reconstructs the input document in its output form. The initial 0 indicates an empty content string. The following
> indicates that a start tag without any attributes is the first
element in this text and the first unused symbol, document, is the element
name. Succeeding that is the content string fee, which is null-terminated
in accordance with the Xerces API specification. Unlike Xerces, no memory-copy
operations are required to produce these strings, which as
Table I shows accounts for 6.83% of Xerces's execution time.
Additionally, it is cheap to locate the terminal character of each string: using the
String End bitstream, the Parabix Subsystem can effectively calculate the offset of
each
null character in the content stream in parallel, which in turn means the parser can
directly jump to the end of every string without scanning for it.
Following 'fee' is a =, which marks the
existence of an attribute. Because all of the intra-element was performed in the Parabix
Subsystem, this must be a legal attribute. Since attributes can only occur within
start
tags and must be accompanied by a textual value, the next symbol in the symbol stream
must be the element name of a start tag, and the following one must be the name of
the
attribute and the string that follows the = must be its value. However, the
subsequent = is not treated as an independent attribute because the parser
has yet to read a >, which marks the end of a start tag. Thus only
one symbol is taken from the symbol stream and it (along with the string value) is
added
to the element. Eventually the parser reaches a /, which marks the
existence of an end tag. Every end tag requires an element name, which means they
require a symbol. Inter-element validation whenever an empty tag is detected to ensure
that the appropriate scope-nesting rules have been applied.
Namespace Handling
In XML, namespaces prevents naming conflicts when multiple vocabularies are used
together. It is especially important when a vocabulary application-dependant meaning,
such as when XML or SVG documents are embedded within XHTML files. Namespaces are
bound
to uniform resource identifiers (URIs), which are strings used to identify specific
names or resources. On line 1 in Table VI, the xmlns
attribute instructs the XML processor to bind the prefix p to the URI
'pub.net' and the default (empty) prefix to
book.org. Thus to the XML processor, the title on line 2
and price on line 4 both read as
"book.org":title and
"book.org":price respectively, whereas on line 3 and
5, p:name and price are seen as
"pub.net":name and
"pub.net":price. Even though the actual element name
price, due to namespace scoping rules they are viewed as two
uniquely-named items because the current vocabulary is determined by the namespace(s)
that are in-scope.
Table VI
XML Namespace Example
| 1. | <book xmlns:p="pub.net" xmlns="book.org"> |
| 2. | <title>BOOK NAME</title> |
| 3. | <p:name>PUBLISHER NAME</p:name> |
| 4. | <price>X</price> |
| 5. | <price xmlns="publisher.net">Y</price> |
| 6. | </book> |
In both Xerces and icXML, every URI has a one-to-one mapping to a URI ID. These persist for the lifetime of the application through the use of a global URI pool. Xerces maintains a stack of namespace scopes that is pushed (popped) every time a start tag (end tag) occurs in the document. Because a namespace declaration affects the entire element, it must be processed prior to grammar validation. This is a costly process considering that a typical namespaced XML document only comes in one of two forms: (1) those that declare a set of namespaces upfront and never change them, and (2) those that repeatedly modify the namespaces in predictable patterns.
For that reason, icXML contains an independent namespace stack and utilizes bit
vectors to cheaply perform
When a prefix is
declared (e.g., xmlns:p="pub.net"), a namespace binding
is created that maps the prefix (which are assigned Prefix IDs in the symbol resolution
process) to the URI. Each unique namespace binding has a unique namespace id (NSID)
and
every prefix contains a bit vector marking every NSID that has ever been associated
with
it within the document. For example, in Table VI, the prefix binding
set of p and xmlns would be 01 and
11 respectively. To resolve the in-scope namespace binding for each prefix,
a bit vector of the currently visible namespaces is maintained by the system. By ANDing
the prefix bit vector with the currently visible namespaces, the in-scope NSID can
be
found using a bit-scan intrinsic. A namespace binding table, similar to
Table VII, provides the actual URI ID.
Table VII
Namespace Binding Table Example
| NSID | Prefix | URI | Prefix ID | URI ID |
|---|---|---|---|---|
| 0 | p
|
pub.net
|
0 | 0 |
| 1 | xmlns
|
books.org
|
1 | 1 |
| 2 | xmlns
|
pub.net
|
1 | 0 |
To ensure that scoping rules are adhered to, whenever a start tag is encountered, any modification to the currently visible namespaces is calculated and stored within a stack of bit vectors denoting the locally modified namespace bindings. When an end tag is found, the currently visible namespaces is XORed with the vector at the top of the stack. This allows any number of changes to be performed at each scope-level with a constant time.
Error Handling
Xerces outputs error messages in two ways: through the programmer API and as thrown objects for fatal errors. As Xerces parses a file, it uses context-dependant logic to assess whether the next character is legal; if not, the current state determines the type and severity of the error. icXML emits errors in the similar manner—but how it discovers them is substantially different. Recall that in Figure Figure 2, icXML is divided into two sections: the Parabix Subsystem and Markup Processor, each with its own system for detecting and producing error messages.
Within the Parabix Subsystem, all computations are performed in parallel, a block at a time. Errors are derived as artifacts of bitstream calculations, with a 1-bit marking the byte-position of an error within a block, and the type of error is determined by the equation that discovered it. The difficulty of error processing in this section is that in Xerces the line and column number must be given with every error production. Two major issues exist because of this: (1) line position adheres to XML white-normalization rules; as such, some sequences of characters, e.g., a carriage return followed by a line feed, are counted as a single new line character. (2) column position is counted in characters, not bytes or code units; thus multi-code-unit code-points and surrogate character pairs are all counted as a single column position. Note that typical XML documents are error-free but the calculation of the line/column position is a constant overhead in Xerces. To reduce this, icXML pushes the bulk cost of the line/column calculation to the occurrence of the error and performs the minimal amount of book-keeping necessary to facilitate it. icXML leverages the byproducts of the Character Set Adapter (CSA) module and amalgamates the information within the Line Column Tracker (LCT). One of the CSA's major responsibilities is transcoding an input text. During this process, white-space normalization rules are applied and multi-code-unit and surrogate characters are detected and validated. A line-feed bitstream, which marks the positions of the normalized new lines characters, is a natural derivative of this process. Using an optimized population count algorithm, the line count can be summarized cheaply for each valid block of text. Column position is more difficult to calculate. It is possible to scan backwards through the bitstream of new line characters to determine the distance (in code-units) between the position between which an error was detected and the last line feed. However, this distance may exceed than the actual character position for the reasons discussed in (2). To handle this, the CSA generates a skip mask bitstream by ORing together many relevant bitstreams, such as all trailing multi-code-unit and surrogate characters, and any characters that were removed during the normalization process. When an error is detected, the sum of those skipped positions is subtracted from the distance to determine the actual column number.
The Markup Processor is a state-driven machine. As such, error detection within it is very similar to Xerces. However, reporting the correct line/column is a much more difficult problem. The Markup Processor parses the content stream, which is a series of tagged UTF-16 strings. Each string is normalized in accordance with the XML specification. All symbol data and unnecessary whitespace is eliminated from the stream; thus its impossible to derive the current location using only the content stream. To calculate the location, the Markup Processor borrows three additional pieces of information from the Parabix Subsystem: the line-feed, skip mask, and a deletion mask stream, which is a bitstream denoting the (code-unit) position of every datum that was suppressed from the source during the production of the content stream. Armed with these, it is possible to calculate the actual line/column using the same system as the Parabix Subsystem until the sum of the negated deletion mask stream is equal to the current position.
Multithreading with Pipeline Parallelism
As discussed in section section “Xerces C++ Structure”, Xerces can be considered a FSM application. These are "embarrassingly sequential."Asanovic et al. 2006 and notoriously difficult to parallelize. However, icXML is designed to organize processing into logical layers. In particular, layers within the Parabix Subsystem are designed to operate over significant segments of input data before passing their outputs on for subsequent processing. This fits well into the general model of pipeline parallelism, in which each thread is in charge of a single module or group of modules.
The most straightforward division of work in icXML is to separate the Parabix Subsystem
and the Markup Processor into distinct logical layers into two separate stages. The
resultant application, icXML-p, is a course-grained
software-pipeline application. In this case, the Parabix Subsystem thread
T1 reads 16k of XML input I at a
time and produces the content, symbol and URI streams, then stores them in a pre-allocated
shared data structure S. The Markup Processor thread
T2 consumes S, performs well-formedness
and grammar-based validation, and the provides parsed XML data to the application
through
the Xerces API. The shared data structure is implemented using a ring buffer, where
every
entry contains an independent set of data streams. In the examples of
Figure 4, the ring buffer has four entries. A
lock-free mechanism is applied to ensure that each entry can only be read or written
by one
thread at the same time. In Figure 4 the processing time of
T1 is longer than
T2; thus T2 always
waits for T1 to write to the shared memory.
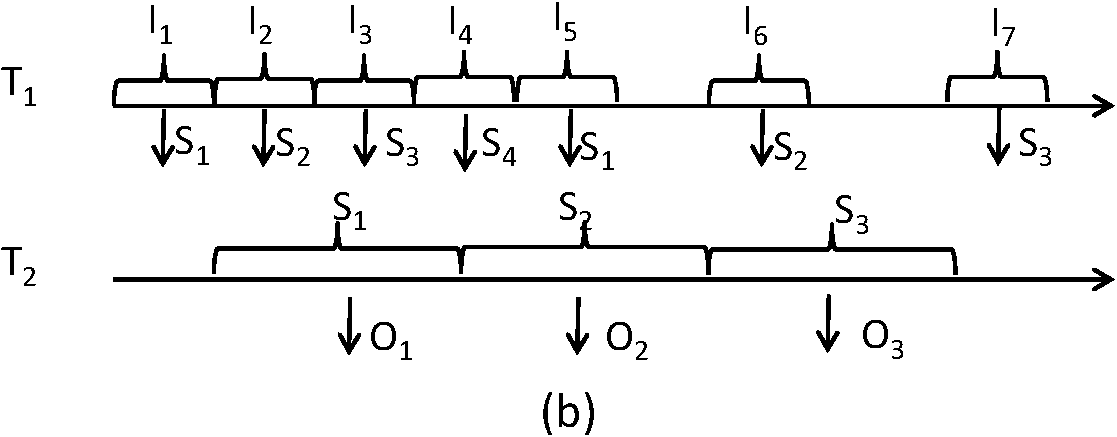
Figure 5 illustrates the scenario in which
T1 is faster and must wait for
T2 to finish reading the shared data before it can
reuse the memory space.
Figure 4: Thread Balance in Two-Stage Pipelines: Stage 1 Dominant Figure 5: Thread Balance in Two-Stage Pipelines: Stage 2 Dominant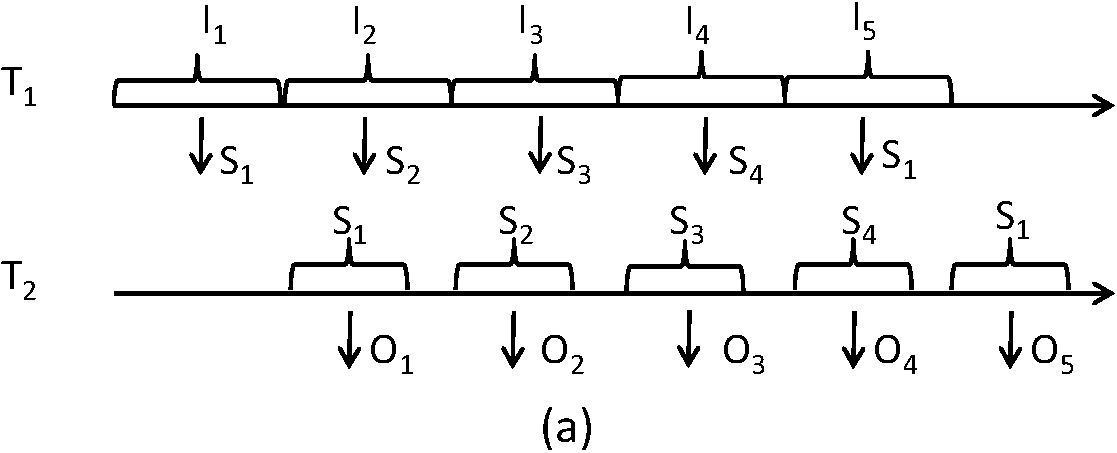
Overall, our design is intended to benefit a range of applications. Conceptually, we consider two design points. The first, the parsing performed by the Parabix Subsystem dominates at 67% of the overall cost, with the cost of application processing (including the driver logic within the Markup Processor) at 33%. The second is almost the opposite scenario, the cost of application processing dominates at 60%, while the cost of XML parsing represents an overhead of 40%.
Our design is predicated on a goal of using the Parabix framework to achieve a 50% to 100% improvement in the parsing engine itself. In a best case scenario, a 100% improvement of the Parabix Subsystem for the design point in which XML parsing dominates at 67% of the total application cost. In this case, the single-threaded icXML should achieve a 1.5x speedup over Xerces so that the total application cost reduces to 67% of the original. However, in icXML-p, our ideal scenario gives us two well-balanced threads each performing about 33% of the original work. In this case, Amdahl's law predicts that we could expect up to a 3x speedup at best.
At the other extreme of our design range, we consider an application in which core parsing cost is 40%. Assuming the 2x speedup of the Parabix Subsystem over the corresponding Xerces core, single-threaded icXML delivers a 25% speedup. However, the most significant aspect of our two-stage multi-threaded design then becomes the ability to hide the entire latency of parsing within the serial time required by the application. In this case, we achieve an overall speedup in processing time by 1.67x.
Although the structure of the Parabix Subsystem allows division of the work into several pipeline stages and has been demonstrated to be effective for four pipeline stages in a research prototype Lin and Medforth 2012, our analysis here suggests that the further pipelining of work within the Parabix Subsystem is not worthwhile if the cost of application logic is little as 33% of the end-to-end cost using Xerces. To achieve benefits of further parallelization with multi-core technology, there would need to be reductions in the cost of application logic that could match reductions in core parsing cost.
Performance
We evaluate Xerces-C++ 3.1.1, icXML, icXML-p against two benchmarking applications: the Xerces C++ SAXCount sample application, and a real world GML to SVG transformation application. We investigated XML parser performance using an Intel Core i7 quad-core (Sandy Bridge) processor (3.40GHz, 4 physical cores, 8 threads (2 per core), 32+32 kB (per core) L1 cache, 256 kB (per core) L2 cache, 8 MB L3 cache) running the 64-bit version of Ubuntu 12.04 (Linux).
We analyzed the execution profiles of each XML parser using the performance counters found in the processor. We chose several key hardware events that provide insight into the profile of each application and indicate if the processor is doing useful work. The set of events included in our study are: processor cycles, branch instructions, branch mispredictions, and cache misses. The Performance Application Programming Interface (PAPI) Version 5.5.0 PAPI toolkit was installed on the test system to facilitate the collection of hardware performance monitoring statistics. In addition, we used the Linux perf perf utility to collect per core hardware events.
Xerces C++ SAXCount
Xerces comes with sample applications that demonstrate salient features of the parser. SAXCount is the simplest such application: it counts the elements, attributes and characters of a given XML file using the (event based) SAX API and prints out the totals.
Table VIII shows the document characteristics of the XML input files selected for the Xerces C++ SAXCount benchmark. The jaw.xml represents document-oriented XML inputs and contains the three-byte and four-byte UTF-8 sequence required for the UTF-8 encoding of Japanese characters. The remaining data files are data-oriented XML documents and consist entirely of single byte encoded ASCII characters.
Table VIII
XML Document Characteristics
| File Name | jaw.xml | road.gml | po.xml | soap.xml |
| File Type | document | data | data | data |
| File Size (kB) | 7343 | 11584 | 76450 | 2717 |
| Markup Item Count | 74882 | 280724 | 4634110 | 18004 |
| Markup Density | 0.13 | 0.57 | 0.76 | 0.87 |
A key predictor of the overall parsing performance of an XML file is markup density[2]. This metric has substantial influence on the performance of traditional recursive descent XML parsers because it directly corresponds to the number of state transitions that occur when parsing a document. We use a mixture of document-oriented and data-oriented XML files to analyze performance over a spectrum of markup densities.
Figure 6 compares the performance of Xerces, icXML and pipelined icXML in terms of CPU cycles per byte for the SAXCount application. The speedup for icXML over Xerces is 1.3x to 1.8x. With two threads on the multicore machine, icXML-p can achieve speedup up to 2.7x. Xerces is substantially slowed by dense markup but icXML is less affected through a reduction in branches and the use of parallel-processing techniques. icXML-p performs better as markup-density increases because the work performed by each stage is well balanced in this application.
Figure 6: SAXCount Performance Comparison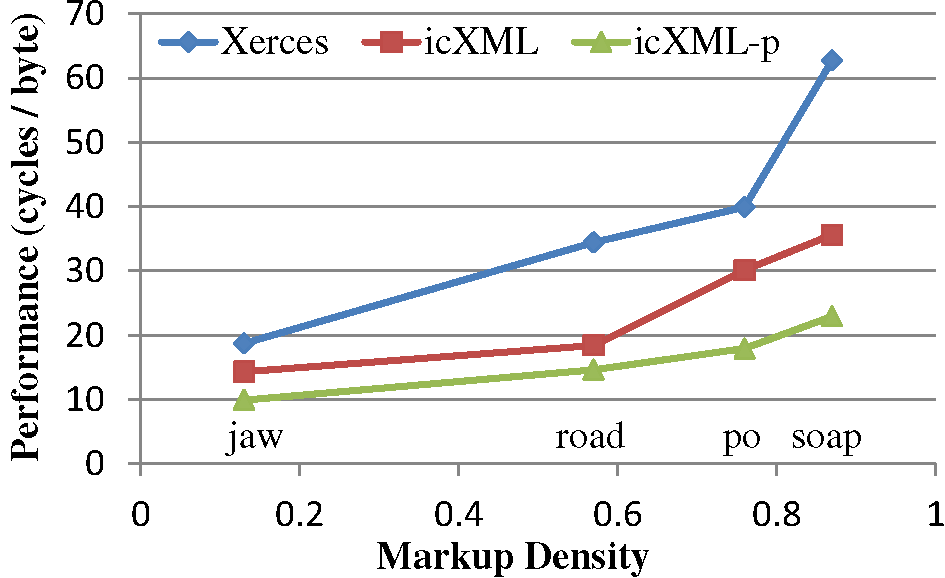
GML2SVG
As a more substantial application of XML processing, the GML-to-SVG (GML2SVG) application was chosen. This application transforms geospatially encoded data represented using an XML representation in the form of Geography Markup Language (GML) Lake and Burggraf 2004 into a different XML format suitable for displayable maps: Scalable Vector Graphics (SVG) format Lu and Dos Santos 2007. In the GML2SVG benchmark, GML feature elements and GML geometry elements tags are matched. GML coordinate data are then extracted and transformed to the corresponding SVG path data encodings. Equivalent SVG path elements are generated and output to the destination SVG document. The GML2SVG application is thus considered typical of a broad class of XML applications that parse and extract information from a known XML format for the purpose of analysis and restructuring to meet the requirements of an alternative format.
Our GML to SVG data translations are executed on GML source data modelling the city of Vancouver, British Columbia, Canada. The GML source document set consists of 46 distinct GML feature layers ranging in size from approximately 9 KB to 125.2 MB and with an average document size of 18.6 MB. Markup density ranges from approximately 0.045 to 0.719 and with an average markup density of 0.519. In this performance study, 213.4 MB of source GML data generates 91.9 MB of target SVG data.
Figure 7: Performance Comparison for GML2SVG
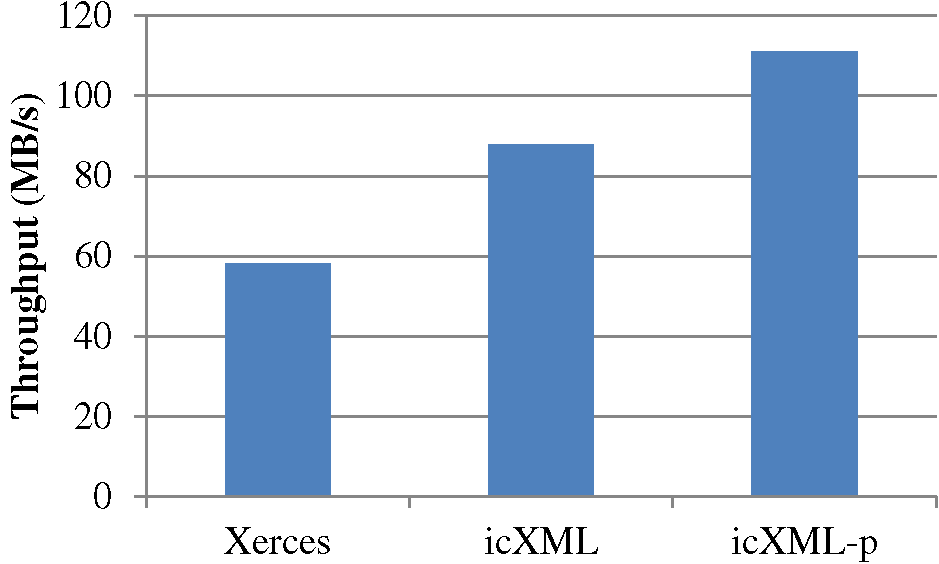
Figure 7 compares the performance of the GML2SVG application linked against the Xerces, icXML and icXML-p. On the GML workload with this application, single-thread icXML achieved about a 50% acceleration over Xerces, increasing throughput on our test machine from 58.3 MB/sec to 87.9 MB/sec. Using icXML-p, a further throughput increase to 111 MB/sec was recorded, approximately a 2X speedup.
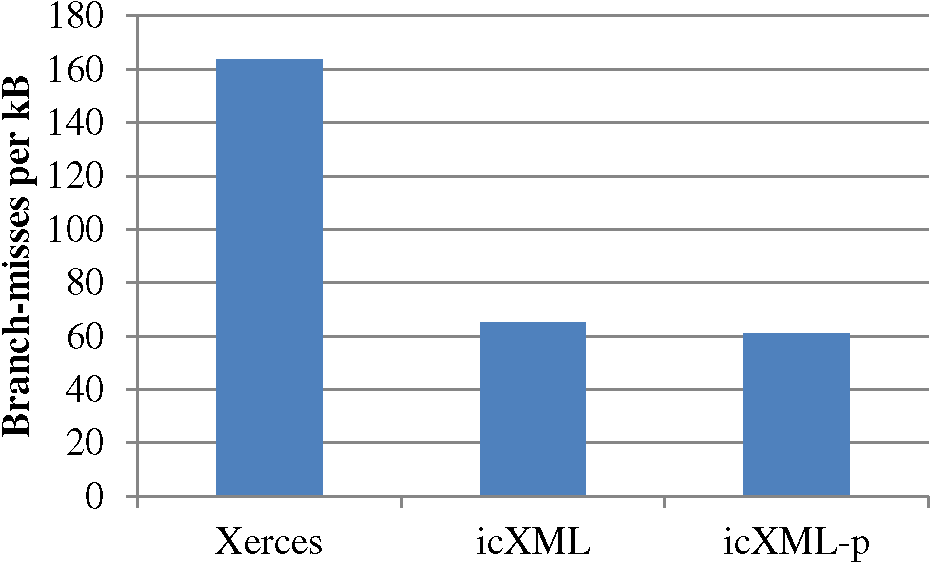
An important aspect of icXML is the replacement of much branch-laden sequential code inside Xerces with straight-line SIMD code using far fewer branches. Figure 8 shows the corresponding improvement in branching behaviour, with a dramatic reduction in branch misses per kB. It is also interesting to note that icXML-p goes even further. In essence, in using pipeline parallelism to split the instruction stream onto separate cores, the branch target buffers on each core are less overloaded and able to increase the successful branch prediction rate.
Figure 8: Comparative Branch Misprediction Rate
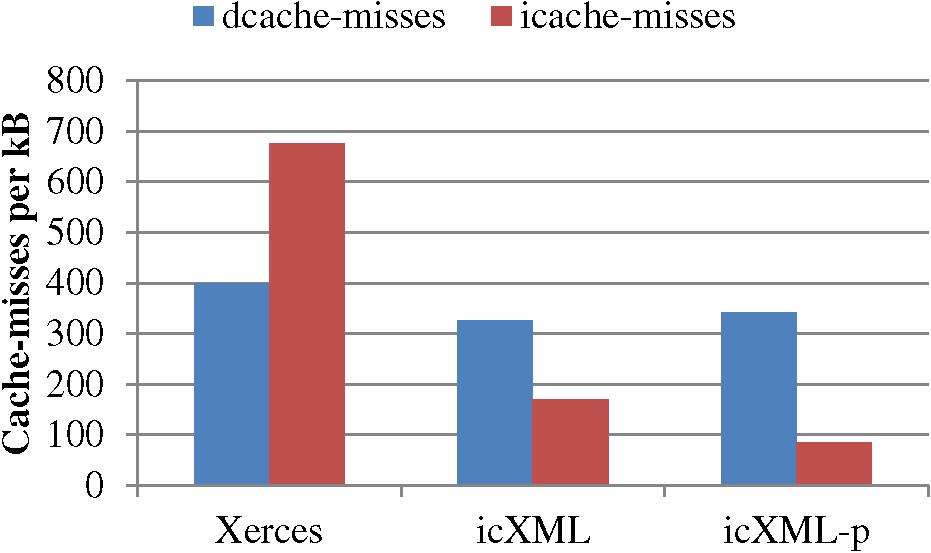
The behaviour of the three versions with respect to L1 cache misses per kB is shown in Figure 9. Improvements are shown in both instruction- and data-cache performance with the improvements in instruction-cache behaviour the most dramatic. Single-threaded icXML shows substantially improved performance over Xerces on both measures. Although icXML-p is slightly worse with respect to data-cache performance, this is more than offset by a further dramatic reduction in instruction-cache miss rate. Again partitioning the instruction stream through the pipeline parallelism model has significant benefit.
Figure 9: Comparative Cache Miss Rate
One caveat with this study is that the GML2SVG application did not exhibit a relative balance of processing between application code and Xerces library code reaching the 33% figure. This suggests that for this application and possibly others, further separating the logical layers of the icXML engine into different pipeline stages could well offer significant benefit. This remains an area of ongoing work.
Conclusion and Future Work
This paper is the first case study documenting the significant performance benefits that may be realized through the integration of parallel bitstream technology into existing widely-used software libraries. In the case of the Xerces-C++ XML parser, the combined integration of SIMD and multicore parallelism was shown capable of dramatic producing dramatic increases in throughput and reductions in branch mispredictions and cache misses. The modified parser, going under the name icXML is designed to provide the full functionality of the original Xerces library with complete compatibility of APIs. Although substantial re-engineering was required to realize the performance potential of parallel technologies, this is an important case study demonstrating the general feasibility of these techniques.
The further development of icXML to move beyond 2-stage pipeline parallelism is ongoing, with realistic prospects for four reasonably balanced stages within the library. For applications such as GML2SVG which are dominated by time spent on XML parsing, such a multistage pipelined parsing library should offer substantial benefits.
The example of XML parsing may be considered prototypical of finite-state machines applications which have sometimes been considered "embarassingly sequential" and so difficult to parallelize that "nothing works." So the case study presented here should be considered an important data point in making the case that parallelization can indeed be helpful across a broad array of application types.
To overcome the software engineering challenges in applying parallel bitstream technology to existing software systems, it is clear that better library and tool support is needed. The techniques used in the implementation of icXML and documented in this paper could well be generalized for applications in other contexts and automated through the creation of compiler technology specifically supporting parallel bitstream programming.
Given the success of the icXML development, there is a strong case for continued development of the Parabix framework as well as for the application of Parabix to other important XML technology stacks. In particular, an important area for further work is to extend the benefits of SIMD and multicore parallelism to the acceleration of Java-based XML processors.
References
[Parabix1 2008] Cameron, Robert D., Herdy, Kenneth S. and Lin, Dan. High performance XML parsing using parallel bit stream technology. CASCON'08: Proc. 2008 conference of the center for advanced studies on collaborative research. Richmond Hill, Ontario, Canada. 2008.
[PAPI] Innovative Computing Laboratory, University of Texas. Performance Application Programming Interface. http://icl.cs.utk.edu/papi/
[perf] Eranian, Stephane, Gouriou, Eric, Moseley, Tipp and Bruijn, Willem de. Linux kernel profiling with perf. https://perf.wiki.kernel.org/index.php/Tutorial
[u8u16 2008] Cameron, Robert D.. A case study in SIMD text processing with parallel bit streams: UTF-8 to UTF-16 transcoding. Proc. 13th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. Salt Lake City, USA. 2008. doi:https://doi.org/10.1145/1345206.1345222.
[Shah and Rao 2009] Shah, Bhavik, Rao, Praveen, Moon, Bongki and Rajagopalan, Mohan. A Data Parallel Algorithm for XML DOM Parsing. Database and XML Technologies. 2009.
[Lei 2008] Lei, Zhai. XML Parsing Accelerator with Intel Streaming SIMD Extensions 4 (Intel SSE4). Intel Software Network. 2008.
[Balisage 2009] Cameron, Rob, Herdy, Ken and Amiri, Ehsan Amiri. Parallel Bit Stream Technology as a Foundation for XML Parsing Performance. Int'l Symposium on Processing XML Efficiently: Overcoming Limits on Space, Time, or Bandwidth. Montreal, Quebec, Canada. 2009. doi:https://doi.org/10.4242/BalisageVol4.Cameron01.
[Hilewitz and Lee 2006] Hilewitz, Yedidya and Lee, Ruby B.. Fast Bit Compression and Expansion with Parallel Extract and Parallel Deposit Instructions. ASAP '06: Proc. IEEE 17th Int'l Conference on Application-specific Systems, Architectures and Processors. Steamboat Springs, Colorado, USA. 2006.
[Asanovic et al. 2006] Asanovic, Krste and others. The Landscape of Parallel Computing Research: A View from Berkeley. EECS Department, University of California, Berkeley. 2006.
[Lu and Chiu 2006] Lu, Wei, Chiu, Kenneth and Pan, Yinfei. A Parallel Approach to XML Parsing. Proceedings of the 7th IEEE/ACM International Conference on Grid Computing. Barcelona, Spain. 2006.
[Parabix2 2011] Cameron, Robert D., Amiri, Ehsan, Herdy, Kenneth S., Lin, Dan, Shermer, Thomas C. and Popowich, Fred P.. Parallel Scanning with Bitstream Addition: An XML Case Study. Euro-Par 2011, LNCS 6853, Part II. Bordeaux, Frane. 2011.
[Lin and Medforth 2012] Lin, Dan, Medforth, Nigel, Herdy, Kenneth S., Shriraman, Arrvindh and Cameron, Rob. Parabix: Boosting the efficiency of text processing on commodity processors. International Symposium on High-Performance Computer Architecture. New Orleans, LA. 2012. doi:https://doi.org/10.1109/HPCA.2012.6169041.
[You and Wang 2011] You, Cheng-Han and Wang, Sheng-De. A Data Parallel Approach to XML Parsing and Query. 10th IEEE International Conference on High Performance Computing and Communications. Banff, Alberta, Canada. 2011.
[Pan and Zhang 2007] Pan, Yinfei, Zhang, Ying, Chiu, Kenneth and Lu, Wei. Parallel XML Parsing Using Meta-DFAs. International Conference on e-Science and Grid Computing. Bangalore, India. 2007.
[Pan and Zhang 2008a] Pan, Yinfei, Zhang, Ying and Chiu, Kenneth. Hybrid Parallelism for XML SAX Parsing. IEEE International Conference on Web Services. Beijing, China. 2008.
[Pan and Zhang 2008b] Pan, Yinfei, Zhang, Ying and Chiu, Kenneth. Simultaneous transducers for data-parallel XML parsing. International Parallel and Distributed Processing Symposium. Miami, Florida, USA. 2008.
[Warren 2002] Warren, Henry S.. Hacker's Delight. Addison-Wesley Professional. 2003.
[Lu and Dos Santos 2007] Lu, C.T., Dos Santos, R.F., Sripada, L.N. and Kou, Y.. Advances in GML for geospatial applications. Geoinformatica 11:131-157. 2007. doi:https://doi.org/10.1007/s10707-006-0013-9.
[Lake and Burggraf 2004] Lake, R., Burggraf, D.S., Trninic, M. and Rae, L.. Geography mark-up language (GML) [foundation for the geo-web]. Wiley. Chichester. 2004.