Nordin, Brent. “Markup and Canada's National Model Building Codes.” Presented at Balisage: The Markup Conference 2013, Montréal, Canada, August 6 - 9, 2013. In Proceedings of Balisage: The Markup Conference 2013. Balisage Series on Markup Technologies, vol. 10 (2013). https://doi.org/10.4242/BalisageVol10.Nordin01.
Balisage: The Markup Conference 2013 August 6 - 9, 2013
Balisage Paper: Markup and Canada's National Model Building Codes
Brent Nordin
I've been playing with markup off and on since about 1990. I served as a Canadian
rep to JTC1/SC18/WG8 during the SGML revision days, developed an SGML DTD Viewer product
(released about 2 months before Near and Far, which ended my hopes for early retirement),
and have worked on markup projects for companies like Frame, Adobe, Boeing, Embraer,
National Research Council of Canada, and Schlumberger.
When I`m not playing in markup-land, I work on data-centric security, with as much
of an XML twist as I can manage.
The National Building Codes content shown in any examples accompanying this paper
are reproduced with the permission of the National Research Council of Canada, copyright
holder.
Abstract
This paper offers up a brief publishing oriented view of the Canadian National Building
Codes since their first release in 1941 and continues on to describe current work
in maintaining the Codes documents and their XML content.
I have been working as an independent contractor to the National Research Council
of Canada (NRC) Canadian Codes Centre (CCC) off and on for 8 years. I have no formal
affiliation with either the NRC or the CCC nor am I representing either organization
in this paper.
Acknowledgements
Guy Gosselin - Director, Building Regulations, NRC-CNRC Construction
Guyane Mougeot-Lemay - Building Regulations, Manager, Production & Marketing
Tarek Raafat - Building Regulations, Head, Information Systems
Helen Tikhonova - Building Regulations, Information Systems Specialist
David Taylor - Building Regulations, SGML/XML Specialist and CMS Administrator
Henning Heinemann - Building Regulations, Project Manager, Information Systems
The Building Codes content shown in any of the images or examples accompanying this
paper are copyright the National Research Council of Canada and used with permission.
Roadmap
This paper describes some of the work I've been doing on a project featuring large,
complex technical documents - The Canadian National Model Building Codes. I'll start
with a short intro to the organizations and processes that maintain and update the
Codes. From there I'll give a very selected time line of the Codes dating from a time
before computers to the present and on to some current work we are doing. Where the
time line intersects with my involvement I will be able to expand the level of detail.
Please assume that anything I describe would not have been possible without the help
and guidance of the people mentioned in the acknowledgements section. Guy Gosselin
gave me permission to write this paper, Guyane Mougeot-Lemay and Tarek Raafat have
provided excellent project management, Helen Tikhonova and David Taylor have provided
me with endless subject matter expertise and feedback at every stage of my work, and Henning Heinemann
has done wonders customizing the CMS and integrating my code.
The Canadian National Model Building Codes
Like many countries, Canada maintains building codes designed to ensure building and
occupant safety. Building codes necessarily change over time in order to address new
requirements.
Canada`s National Research Council operates the Canadian Codes Centre (CCC) to provide
both technical and administrative support to the Canadian Commission on Building and
Fire Codes (CCBFC). The CCBFC has nine technical standing committees whose members
may be drawn from "... building and fire officials, architects, engineers, contractors
and building owners, as well as members of the public".
While building codes are a provincial or territorial responsibility, the CCBFC helps
coordinate the work with input from the Provincial/Territorial Policy Advisory Committee
on Codes (PTPACC) to the extent that many jurisdictions adopt the Model Building Codes
directly, while others modify the model codes as appropriate for conditions in their
jurisdictions.
These codes currently maintained by the CCC are the following:
National Energy Code of Canada for Buildings 2011 (NECB)
National Building Code of Canada 2010 (NBC)
National Fire Code of Canada 2010 (NFC)
National Plumbing Code of Canada 2010 (NPC)
National Farm Building Code of Canada 1995 (NFBC)
A Look at the Building Codes
1941
Canada's building codes date back to 1941 when the first version of the National Building
Code was published. At that time, a typical page from the document looked like Figure 1.
Figure 1: Sample content from the 1941 Building Code
Markup and computer based publishing (and computers for that matter) were still off
in the future. To keep things moving along and relevant to this conference, I'll gloss
over the ensuing forty years of Building Codes development and publishing activity.
1990
By the late eighties, Codes production had shifted to desktop publishing (Pagemaker)
and a typical page looked like Figure 2.
Figure 2: Sample page from the 1990 Building Code
Even as the Building Codes were being converted to desktop publishing tools, markup
and, in particular, the notion of separating document content from document presentation,
especially for large technical publications, was becoming more common. So too were
the tools and expertise necessary to handle markup.
1995/6
Despite the claimed advantages of a markup based publishing approach, it was still
a leap of faith to go to the expense of converting data from proprietary formats to
SGML and retooling the publishing chain. Nonetheless, for the 1995 version of the
Codes, the content was converted to SGML with an accompanying DTD. Arbortext was selected
as the editing and page composition tool which also required that a FOSI be developed
to format the output. The SGML/Arbortext printed copy looked like Figure 3.
Figure 3: Sample page from the 1995 Building Code
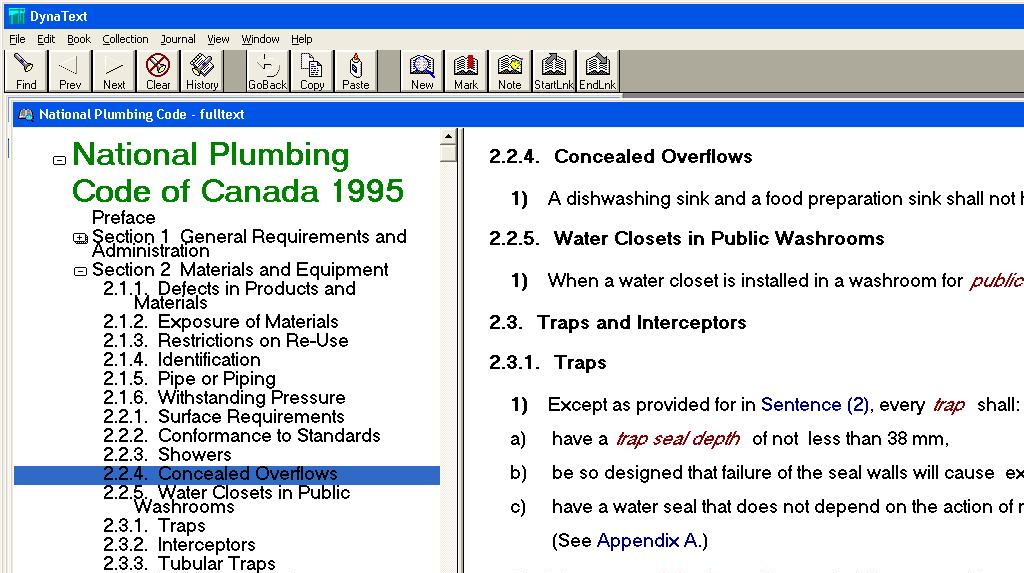
One year later, the Codes were issued in their first electronic version using Dynatext
from Electronic Book Technologies. Dynatext was a publishing system that allowed SGML
content to be combined with other media like vector and raster graphics and audio
and video clips into a book or book collection that could be shipped on a CD. The
Dynatext version of the Building Codes looked like Figure 4.
Figure 4: Sample page from the Dynatext electronic Building Code
The Dynatext release of the Building Codes was important for demonstrating:
The advantage of a non-proprietary data format that could be processed by different
tool chains to create very different output products - a particularly important message
given the cost of conversion to SGML and the retooling to support the conversion.
The added value of an electronic document over paper - search, hyper links, light
and compact (CD vs. paper), etc.
At the time however, a well-thumbed copy of a paper version of the Building Codes,
thrown into the cab of a pickup truck on a building site, or stored on a building
professional's desk, was a more realistic delivery scenario than a format that required
ready access to a laptop or desktop computer.
2005/6
It was 10 years before the next release of the Building Codes. As before, the paper
version of the Codes was edited and composed in Arbortext although by 2005 the DTD
and content had been converted from SGML to XML. The conversion was not difficult
as the original conversion from Pagemaker to SGML did not take significant advantage
of the SGML features that were dropped when XML was designed (although we have had
many opportunities to lament the loss of inclusions in the XML DTD - having to allow
for change-begin and change-end elements nearly everywhere in the XML DTD is much
messier than being able to specify their inclusion once). This sample page from the
2005 version of the Codes (Figure 5) shows a strong resemblance to the 1995 version (Figure 3), save for the change to a single column format.
Figure 5: Sample page from the 2005 Building Code
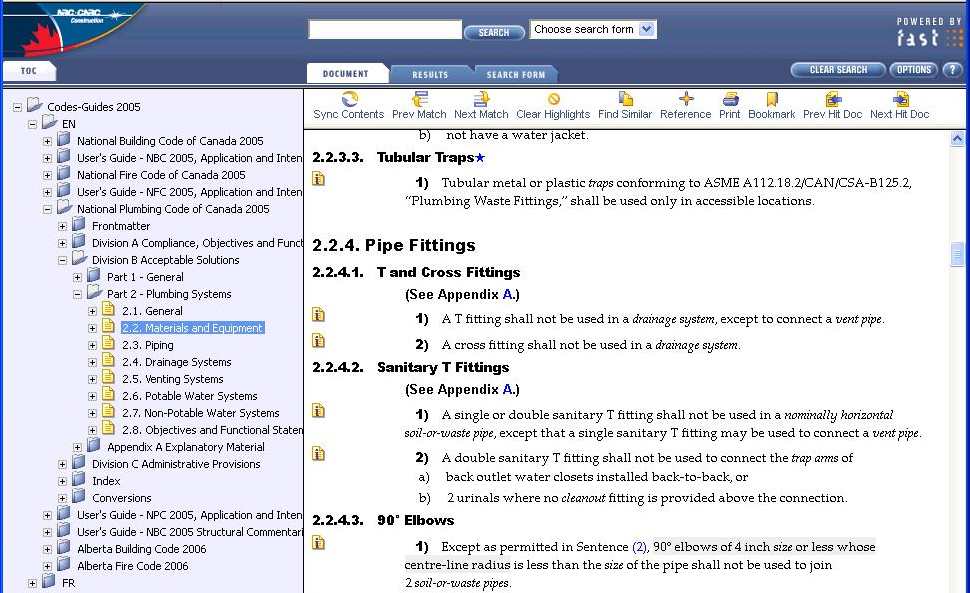
This is where I come in to the story. By 2005, Dynatext was no longer available and
the Canadian Codes Centre had selected the NXT CD publishing tool to create the next
electronic version of the Building Codes. My initial brief was to create HTML output
from the XML source suitable for import into NXT. As far as possible, the content
was to be formatted like the paper copy. The FOSI used for the printed Codes, being
a stylesheet itself, provided me with a useful leg up in creating the CSS.
When we started work converting the XML to HTML (using XSLT) for the NXT CD tool
we did not actually have the NXT software. Our initial conversion delivered a
2-frame HTML view of the output with a Table of Contents in the left frame and the
Codes content in the right. Figure 6 shows a sample.
Figure 6: Sample page from the 2006 electronic Building Code
Once the NXT software arrived, and as we learned its specific requirements, we
modified the conversion scripts to support both the original framed output and the
NXT output. In the next few sections I'll outline some of the more interesting
challenges we had to deal with.
Output Formatting
I have already mentioned that the plain HTML output and the NXT output were
different. The changes were mostly related to the Table of Contents (TOC) and
the format of hyper links. Setting up the conversion scripts to handle these
differences was fairly straightforward. Formatting was another thing entirely.
At the time, we were trying to support Firefox 3, Internet Explorer 6, and CSS 2
- it turned out that if we got that right, the NXT output would look OK too. We
wanted to have a single CSS style sheet to reduce long term maintenance
headaches. Effectively, we were trying to support 3 different rendering engines
with one set of HTML files and one style sheet. Our initial conversion scripts
tried to take advantage of HTML elements like <P> but the browsers attach
some amount of built-in formatting to the HTML elements. Of course the
formatting was different for each browser as were the interactions of the
predefined formatting with the linked CSS. We simplified the problem by mapping
the XML into DIV and SPAN elements for block and running text respectively. As I
learned at Balisage in 2011 over a beer one evening, DIV and SPAN were
introduced specifically to be unformatted so we were able to limit my hair
pulling to resolving differences between how the browsers interpreted CSS2. This
was entertaining enough - we had to tweak both the output HTML and the CSS to
achieve my goals. For example, one instance we had to wrap output in both DIV
and SPAN elements to get similar presentations in Firefox and Internet Explorer.
The CSS has a disturbing number of comments like:
IE and FF have different opinions about how to layout para-nmbrd caused by FF
not honoring sentnum width. Numbers in FF on para-nmbrd text will therefore be
shifted left by 1em plus the difference between the width of the number (including
its trailing ')') and the width of an 'm' character.
Tables
My claim in the previous section about using only DIV and SPAN elements was true to
a point. Tables were that point. Tabular output required engaging the table rendering
engines in the browsers and so my HTML output does include HTML table elements. Anyone
who has had to convert tables marked up using the Oasis Exchange Table Model into
HTML tables knows just how much work this can be. For example, an Oasis table can
have multiple TGROUP elements where each TGROUP can support a different number of
columns. There is no analog in HTML tables - each table can only have a single number
of columns. You therefore have 2 options:
Convert each TGROUP to support the number of columns in the least common multiple
of the columns in all TGROUPs.
Output each TGROUP as a separate table and rely on rendering the tables with no intervening
space to look like a single table.
The first option is unspeakably horrible as it involves setting up column spans or
converting existing column spans (named or positional) and all the references to the
span information in the table data amongst other nasties. The latter option is much,
much easier but had a dark side that was not apparent at the time. That dark side
showed up years later when we converted our output to be accessible. No longer could
we present a single logical table as multiple printed tables. We had to present the
logical table as a single HTML table with a CAPTION element. Fortunately, and after
an extensive review of our content, we found that, while we did have to support multiple
TRGOUPS, we did not have different numbers of columns or different types of presentational
attributes in each TGROUP.
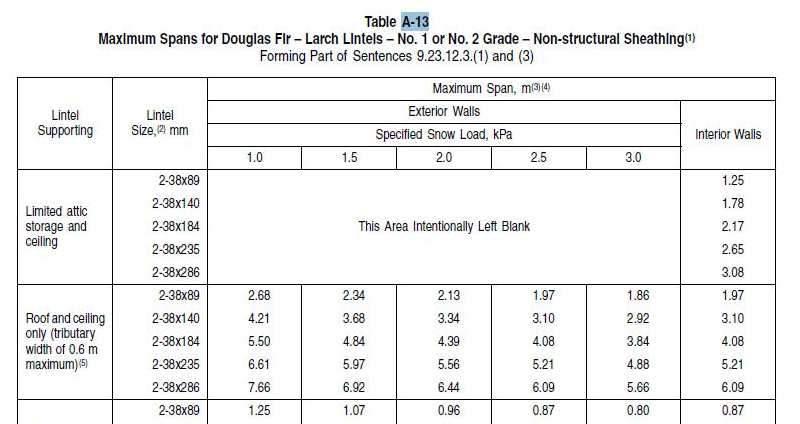
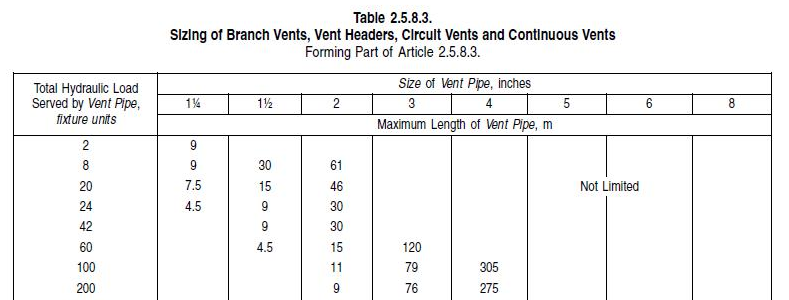
The tables in the Codes documents are both numerous and often complex. Even things
like figuring out which borders to render on a table cell required looking at all
the possible places cell borders could be specified starting at the Oasis TABLE element
and working down through TGROUP, COLSPEC, ROW, and ENTRY elements. Ultimately, the
results worked out well enough. The following table samples (Figure 7, Figure 8) give a feeling for the complexity of our tables.
Figure 7: Sample table
Figure 8: Sample table
Change Bars
One feature of the Codes documents is that each new version highlights significant
changes from the previous version using change bars in the page margins. This is a
very common technique in print, but HTML and CSS were not designed to support this
level of page fidelity. We settled on using shaded text to highlight the differences
(see Figure 9).
Figure 9: Version change highlighting
The interesting problem was that Arbortext encoded change bars in the XML as switches
(empty elements) that told the Arbortext page composition engine to start (or stop)
rendering a change bar. You can see the "change-begin" and "change-end" empty elements
in the sample below.
<sentence id="es007023"><intentref xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="ei000287.xml" xlink:title="Intent"/><text>Where hangers are used to support <term refid="nmnll-hr">nominally
horizontal</term> piping, they shall be</text>
<clause id="es007023a">
<text>metal rods of not less than</text>
<subclause id="es007023a1">
<text><change-begin/><meas>6 mm</meas> diam to support piping <meas>2 inches</meas> or
less in <term refid="z">size</term>,<change-end/></text>
</subclause>
<subclause id="es007023a2">
<text><change-begin/><meas>8 mm</meas> diam to support piping <meas>4 inches</meas> or
less in <term refid="z">size</term>, and<change-end/></text>
</subclause>
<subclause id="es007023a3">
<text><change-begin/><meas>13 mm</meas> diam to support piping over <meas>4
inches</meas> in <term refid="z">size</term>, or<change-end/></text>
</subclause>
</clause>
What we wanted to do was emit an element start tag when we encountered the
element that started the change bar and emit the corresponding end tag when we
hit the stop change bar element so that we could wrap content in a DIV or SPAN
element (with a CSS class). Of course XSLT does not normally allow a partial
element to be emitted in a template. We had to hide what we were doing from the
XSLT engine by outputting the start and end tags in different XSLT templates
using character entities like so:
<!-- CHANGE-BEGIN Any changes in this code should be mirrored in CHANGE-END. -->
<xsl:template match="change-begin">
<xsl:text><div class="change-begin"></xsl:text>
</xsl:template>
<!-- CHANGE-END Any changes in this code should be mirrored in CHANGE-BEGIN. -->
<xsl:template match="change-end">
<xsl:text></div></xsl:text>
</xsl:template>
The XSLT output serializer then converted the character entities back into regular
< > characters where they would be interpreted as markup (and therefore as a DIV or
SPAN wrapping content) by the browsers. Codes text that included < and > characters
and that we did not want interpreted as markup had to be hidden by doubly encoding
them as &lt; and &gt;.
Of course converting singleton elements functioning as switches to an element wrapping
content did not initially produce reliably well-formed output in every case. Subsequent
stages of our rendering pipeline choked on the output. Our solution was to manually
relocate the offending change singletons in the source XML. In most cases this was
as simple as moving a change-begin singleton from preceding a start tag to immediately
following the start tag (for example) which left well-formed output that had the same
effect as the original change markup.
Ultimately, the NXT output (and interface) looked like Figure 10.
Figure 10: NXT output
The NXT output preserves the look of the printed Codes text (in the right pane) and
also offers a number of advantages over print:
Active hyper linking within and between Codes documents
Full text search
More complete (the electronic output included the intent statements which were not
released on paper). These are accessed through the links at the left of each sentence.
Much more portable
2010
Between the time we published the Codes on CD using NXT and the time we had to start
preparing for the next release of the Codes in 2010, changes on the NXT side suggested
strongly that we have a plan B for releasing an electronic copy of the Codes in 2010.
Plan B turned out to rely on Arbortext for both the print and electronic copies of
the Codes using Arbortext PDF output. The electronic PDF output, like the SGML and
HTML electronic version before it offers active hyper links, a TOC, and search capabilities.
As you can imagine, with PDF as the output for both the print and electronic versions
of the Codes, the presentation was nearly identical and the entire production process
was greatly streamlined. The output looks very much like the 2005 Codes so I haven't
included an example here.
For the foreseeable future, Arbortext will be the composition engine for both the
print and electronic copies and so this part of my tale ends. The next part of this
paper describes a different aspect of the work I've been involved with at the Canadian
Codes Centre.
Maintaining and Developing the Building Codes
As we saw at the start of this paper, the Codes have an extensive set of stakeholders
all of whom both contribute to and must be kept apprised of development work on the
Codes. In addition, once the Codes are adopted by a jurisdiction (province, territory),
they acquire legal standing. Until recently, the tracking of each proposed change
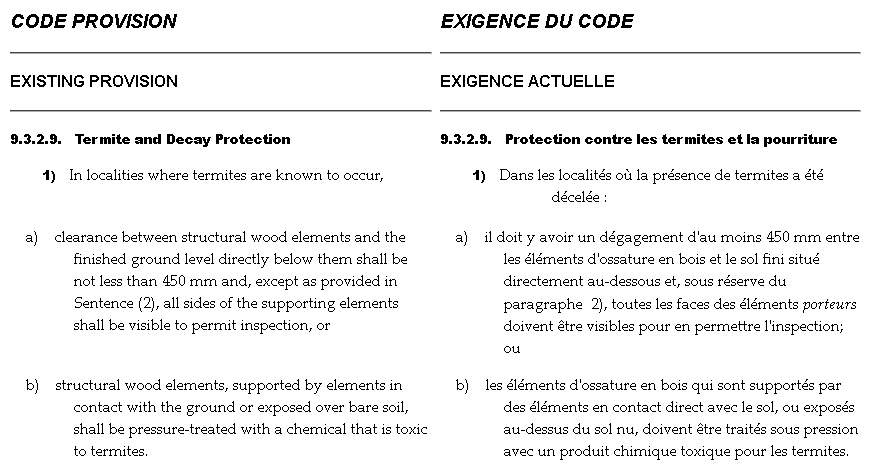
to the Codes was managed with a MS-Word template like Figure 11. The template shows the original Code text, the proposed change, the rationale for
the change, and a variety of administrative and tracking details.
Keeping the Word templates up to date required a lot of manual work and discipline
on the part of the technical committee chairs. In order to provide better process
traceability and accountability and to help manage the increased number of documents
in production the Canadian Codes Centre implemented a Content Management System (CMS).
The CMS we are using is Interwoven Teamsite. In the CMS, the Word template was replaced
with a proper electronic form (the Proposed Change Form or PCF) with work flow, versioning,
fielded searching, reporting, and centralized administration - all typical characteristics
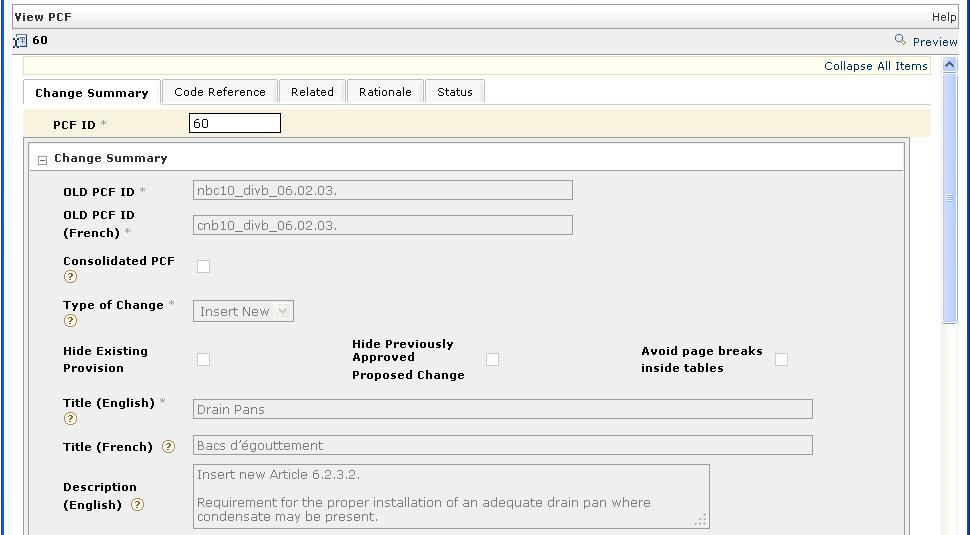
of a CMS. The new form looks like Figure 12.
Figure 12: Teamsite Proposed Change Form
This paper is not about the CMS though or even the PCF (which is itself an XML document
behind the scenes). I instead want to focus on one aspect of the PCF - the part of
the form that contains the text under consideration for change. This corresponds to
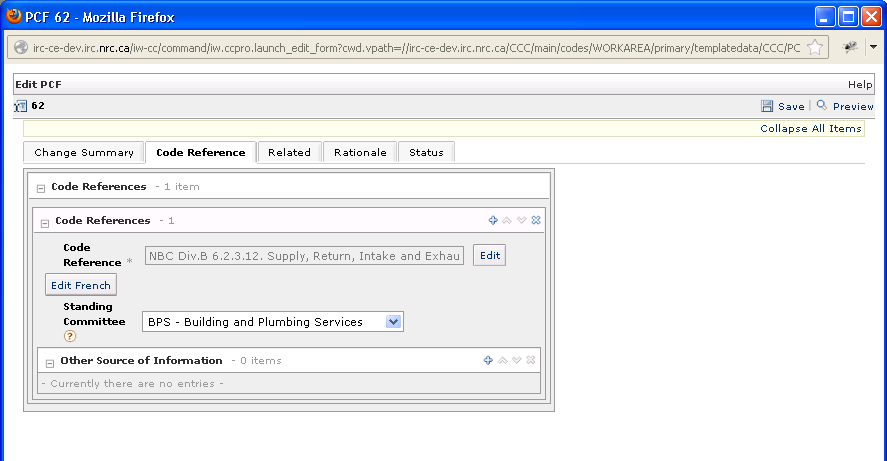
the second tab in the PCF form: Figure 13.
Figure 13: PCF Code Reference Tab
In Figure 13, the reference is to an entire article.
As has been hinted at in the sample output shown so far, the Codes documents are highly
structured documents following a deep hierarchical model: division/part/section/subsection/article/sentence/clause/subclause
in the normative portions of the Codes and a different model for non-normative appendices.
A proposed change might include one or more sentences or higher level constructs (article,
subsection, etc.). In the past, the Code text under consideration was cut from a PDF
version of the Code document and pasted into the MS-Word PCF template. As anyone who
has done this knows, the results can be ugly, especially if the cut text spans a page
boundary in the PDF. Quite apart from that problem, the source for the Codes content
is maintained as fragments of XML. Converting the source to PDF (for publication),
then to Word (the PCF), and then back to XML (for our fragment library including regenerating
all the meta data in the XML - IDs, IDREFs, etc.) once changes had been made was largely
manual, time-consuming and error-prone. We wanted to try linking the source XML to
the Codes revision process somehow so that we could improve the overall throughput,
reliability, and integrity of the revision process, at least as far as the content
was concerned.
The CMS allows files to be attached to forms so rather than inserting Code text into
the form (much like the old Word templates), we decided to attach portions of the
XML source to the form. Before I describe our solution, I'll take a short diversion
into the XML library that contains the source for the Building Codes document.
XML Fragment Library
The XML source for the Codes documents are maintained as a single tree of XML fragments.
The leaves contain the bulk of the Codes text (sentences, tables, appendix notes,
intent analysis). Higher levels in the tree contain structural information fragments.
Tables, appendix notes, and intent analysis fragments are referenced from sentence
fragments.
A sample structural fragment looks like:
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE article PUBLIC "-//NRC-IRC//DTD Code_2010//EN"
"code_2010.dtd" [
<!ENTITY ES000432 SYSTEM "../../../sentence/es/000/es000432.xml">
<!ENTITY ES000433 SYSTEM "../../../sentence/es/000/es000433.xml">
]>
<article id="ea000274">
<title>Group A, Division 2, up to 6 Storeys, Any Area, Sprinklered</title>
&ES000432;
&ES000433;
</article>
You can see that the article fragment is little more than a title element followed
by entity references to the sentence fragments that make up the article (you can see
the SGML heritage here).
One of the sentence fragments in the above article looks like:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE sentence PUBLIC "-//NRC-IRC//DTD Code_2010//EN"
"code_2010.dtd">
<sentence id="es000432">
<ref.intent xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="ei002082.xml" xlink:title="Intent"/>
<text>A <term refid="bldng">building </term> classified as Group A, Division 2, that is
not limited by <term refid="bldng-r">building area</term>, is permitted
to conform to <ref.int refid="es000433" type="short"/> provided</text>
<clause id="es000432a">
<text>except as permitted by <ref.int pretext="Sentences"
refid="es000398"/> <ref.int pretext="and" refid="es000422"/>, the <term
refid="bldng">building</term> is <term refid="prnklrd">sprinklered</term
> throughout.</text>
</clause>
</sentence>
Each sentence has a corresponding intent analysis which describes why a sentence is
important based on a number of objectives and functional requirements. The XLink information
points to intent analysis fragments. Appendix notes can be included at any level in
the document hierarchy and contain explanatory text, figures, examples, and equations.
All content includes many cross-references to other parts of the document (see the
ref.int elements above).
The XML fragment library is a directory. The leaf filenames are the same as the ID
attribute on that fragment and the IDs capture the semantics of the directory structure.
This will be important later.
Linking the XML Library to the CMS
Clearly, the technical committee chairs could not be expected to know the XML fragment
ID of a block of content that they needed to attach to a form. We needed some sort
of selection process to allow for easier content selection. Apart from allowing a
more useful selection process, we also wanted to ensure that the content we built
to attach to the form included everything that a technical committee might need to
know about that content in order to amend it. This meant that we not only needed the
Code text, but also the intent analysis for each sentence and any appendix notes that
applied to the attached text. The old Word forms did not impose any such discipline
and so portions of the Codes document were sometimes overlooked during the revision
cycle. We called the content blobs composite fragments (CFs). A special version of
the main Codes DTD allows for the structure of the composite fragments.
The CMS form editor supports changes to the PCF form made by the committee chairs
directly or a side effect of a work flow process. The composite fragments though have
to be edited separately as the Teamsite CMS does not understand XML at the level we
need. We added a feature to the PCF form that put an "edit" button beside each attached
composite fragment. Clicking "edit" will cause the CMS to push the composite fragment
down to a local workstation from the CMS server and start up Arbortext on that composite
fragment. When an editing session is complete, the edited composite fragment is copied
back up to the server.
The mechanism that supports the creation of the composite fragments is
interesting. Our CMS is a web server based application. Custom Javascript and
server-side CGI scripts can be used to extend the basic CMS functionality. However,
we took a different route to integrate our XML fragment library with the CMS. We
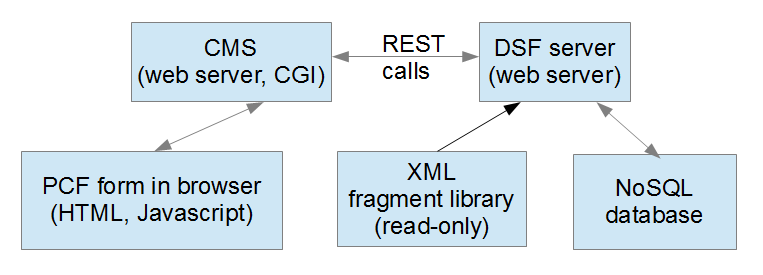
built a separate web server (the DSF Server) to sit between the CMS and the XML
fragment library. The following diagram shows the main moving parts in our system
(Figure 14):
Figure 14: System Architecture
The DSF Server follows the REST architecture. Javascript or CGI scripts on the CMS
send URLs to the DSF Server which responds with documents or pointers to documents.
So, for example, if a technical committee chair wanted to attach a sentence from the
National Plumbing Code to an open PCF, the CMS sends a URL to our DSF server, the
server creates the composite fragment and returns it to the CMS. The PCF form then
gets updated with a link to the composite fragment file.
The DSF Server relies on a custom NoSQL database to resolve which XML fragments should
be used to populate the composite fragment. This initial content is then parsed for
references to other material that must be included in the composite fragment until
we have a complete package of content, appendix notes, and intent statements.
A useful side-effect of our DSF Server architecture is that it isolates the XML fragment
library and all our fragment processing from the CMS itself. If the CMS is upgraded
or even replaced, we retain all the composite fragment functionality unchanged.
PCF Rendering
The PCF form (and the composite fragment editing) is useful but we also need to render
the forms so that the technical committees can see all the information presented in
context from both the PCF form and the attached composite fragments. We render to
HTML, PDF and MHT depending on the downstream use. Most of the rendering code comes
from the code that was developed to render our Codes to HTML for the NXT CD deliverable
in 2006. A small amount of rendering code was added to support the material in the
PCF form itself. A rendered PCF form (edited for presentation) looks like Figure 15.
Figure 15: Rendered Proposed Change Form
The existing provision section shows that the referenced appendix note has been added
to the composite fragment to ensure that a technical committee will consider it in
their deliberations. The appendix note does not render in the proposed change section
as no changes have been made (yet) and so we suppress its display (more on this below).
Of no small interest, Arbortext supports change tracking while editing, like all good
editors. The technical committees wanted to preserve the change tracking in the composite
fragments attached to the PCF and display the changes in the rendered PCF. Arbortext
change tracking causes new elements to be added to the XML file being edited. The
elements are embedded in the edited XML file until such time as a document editor
accepts the changes. The change tracking elements are not part of the document model
(DTD, Schema) for the XML document - Arbortext deals with them appropriately. However,
since the added elements change the element hierarchy in the XML document, any processing
that is based on an assumption about the element hierarchy as modeled in the DTD (or
Schema) will no longer work. In fact, Arbortext does not recommend working directly
with XML files containing change tracking elements.
Our solution to handle change tracking display, developed after several false
starts, was to introduce a rendering preprocessing step that converted the Arbortext
change tracking elements into change tracking attributes on every element wrapped
by
the change tracking element. We then strip out the change tracking elements,
restoring the document to its model conformant state, so we can render it correctly.
A composite fragment with change tracking like this (clause 'b' in Figure 16):
<atict:add user="U2">
<clause id="es001725b" cnum="b*">
<text>
<atict:del user="U1">comply with Sentence 6.3.1.1.(2)-2015 and</atict:del>
<atict:add user="U1">they are separated a minimum distance from sources
of contaminants in accordance with </atict:add>Table 6.2.3.12<atict:adduser="U1">.</atict:add>
<atict:del user="U1"> for minimum distances.</atict:del>
</text>
</clause>
</atict:add>
Will ultimately display like Figure 16 (a more complete example of change tracking output).
Figure 16: Change Tracking
There are two sets of sequence numbers in the generated PCF output. The rightmost
set are the sequence numbers that the content had when it was published and the left
most set are generated on the fly as the PCF is rendered. The former set helps tie
discussions back to the original published documents and the latter provide context
for discussions about changes. Note that the two clauses shown in Figure 16 are new and therefore have no original numbers (shown as "--)"). The new numbers
are critical in situations like this.
We preserve the "user" attributes from the Arbortext change tracking elements as classes
in the HTML output. This has allowed us to experiment with presenting the change tracking
output differently for each user or class of users so that we can distinguish changes
made by an editor from those made by a technical committee for example. If you look
carefully at Figure 16 you can see this in the shaded content. This represents changed material altered
by one of the Codes editors. The unshaded changed material was altered by a technical
committee chair.
Aside from rendering the change tracking visually, the rendering code exploits the
change tracking attributes to suppress content in the output. In general we try to
suppress content that is unchanged so that technical committees, editors, and
translators can focus on material that has changed. For example, if an article has
no changes, we will render just the article title to provide some context while
allowing the technical committees to focus on more relevant material. We are still
in the early stages of content suppression based on change tracking and we are
trying to avoid having to deal with requests like "Show me only what I want to see
at the moment."
Bursting
Once a Code change has been approved, the XML in the composite fragment attached to
the PCF must be returned to the XML library. Since the composite fragment is a single
document, we need to burst the composite fragment back into its component pieces (sentences,
tables, structural fragments, appendix notes, etc.). The ID attribute semantics tells
us what filenames and file paths we need to create for the burst output. For example
an ID on a sentence like:
es000001
indicates that this is an English ('e') sentence ('s') with a filename of 'es000001.xml'
stored in the XML fragment tree at
library/sentence/es/000/es000001.xml
Bursting also recreates the structural fragments as necessary.
Our bursting process exploits the semantics of the IDs in the composite fragment not
only to burst the composite fragment, but also to do a number of internal consistency
checks on the composite fragment to help ensure that the burst fragments will be properly
linked together. We do not burst the composite fragments directly back into the XML
fragment library to allow for final validity and consistency checking on the burst
pieces.
Bonus Features
In order to help sell the CMS and in particular the necessity of using an XML editor
for the Codes content attached to the PCF form we came up with a couple of interesting
(and we hoped addictive) outputs that would have been nearly impossible to do from
an MS-Word input. The two features that we built are side-by-side rendering and something
we call consolidated print.
Side by Side Output
The Codes documents are issued in French and English (Canada is officially bilingual).
The primary language for Codes development is English, but anything that is made available
during the Codes development cycle to the public must be translated. In order to check
translations, it is very useful to be able to line up French and English versions
beside each other. French text is often longer than English text so simply printing
French and English documents side by side will not help.
We developed code that takes our rendered PCF output, in French and English, and pours
the parts of the two documents into a two-column HTML table. Our rendered HTML contains
sufficient semantic information about what each part of the document is (via CSS classes)
that we can easily match the French and English text and output appropriate bits
into each table row. The browser table layout algorithms then do all the heavy lifting
for us by lining up each row in the output table. The side-by-side output looks like
Figure 17.
Figure 17: Side by Side
Consolidated Print
During the course of a (typically) 5 year development cycle, there can be several
hundred proposed changes to the Codes in play. Often a group of changes will affect
the same part of the Code document. The fine granularity of the proposed changes mean
that it can be difficult to see the overall picture of what a Codes document would
look like while it is under development. It is also possible for different technical
committees to be working in the same area of the Codes. There is potential for changes
to be made that are inconsistent.
We developed some code called consolidated print that allows for any portion of a
Codes document to be rendered including any proposed changes that are open against
that portion of the document. The code was built into the DSF Server as a new REST
URL call. The following is an example of what the consolidated output looks like (see
Figure 18).
Figure 18: Consolidated Print
The non-shaded text is the original Codes text. There are 3 proposed changes in
play against the original article (PCFs 663, 670 and 702). PCF 663 is proposing a
change to the article title, adding a reference to an appendix note and introducing
a new sentence 1. PCF 670 preserves the original title and PCF 702 duplicates the
title change but omits the appendix note reference. The consolidated output
interleaves the original text with all outstanding proposed changes at the sentence
level which offers a very clear view of the state of the document at any
time.
Tools
The main tools that we have in our toolbox are:
XSLT - Saxon and libxslt
Python - The DSF server and composite fragment bursting code is implemented in Python
CherryPy - This framework provides an excellent web server template for Python programs
lxml - A Python wrapper for the Gnome project libxml2 and libxslt libraries
libxml2 - The Gnome project XML parser
libxslt - The Gnome project XSLT and XPath library
Interwoven Teamsite - The CMS
Perl - The extension language of choice for the CMS
PrinceXML - To handle HTML to PDF conversion
HTML Tidy - To convert XHTML to backwards compatible HTML
Final Thoughts
I hope this has been an interesting markup focused tour through the Canadian Building
Codes. I have tried to capture breadth rather than depth in my discussions. If anything
I have mentioned seems lacking in detail or simply piques your curiousity, please
feel
free to follow up with me. Similarly, if things as presented seem the product of
unusually prescient designers, I would be more than happy to explain the role played
by
luck and hard work in our efforts.
Since the Codes content was converted to SGML in 1995 we have been able to produce
a range of output products without having to migrate the data or lose any data fidelity.
We are also finding new ways to process the content to support content maintenance.
Along the way, we have been able to make use of current software notions like REST,
and NoSQL databases - we are teaching old data new tricks.
All of our processing relies on complex markup that captures the semantics of the
data. Our processing also makes heavy use of transient metadata (embedded as attributes
on elements or as processing instructions) with varying lifetimes. A data format,
like
XML, that allows us to easily distinguish metadata from content has been critical
to
much of our work.
The Canadian Building Codes started life well before me and will live on long after
I'm gone. This makes aircraft documentation (with which I have a more than passing
acquaintance) look fleeting in comparison. It is a great adventure to work in such
an environment.