Mitchell, Tristan, and Nigel Whitaker. “Marking up changes to ISO standards: A case study.” Presented at Balisage: The Markup Conference 2013, Montréal, Canada, August 6 - 9, 2013. In Proceedings of Balisage: The Markup Conference 2013. Balisage Series on Markup Technologies, vol. 10 (2013). https://doi.org/10.4242/BalisageVol10.Mitchell01.
Balisage: The Markup Conference 2013 August 6 - 9, 2013
Balisage Paper: Marking up changes to ISO standards: A case study
Tristan joined DeltaXML after graduating with an MEng from Aberystwyth University
in 2004. Since then he has been involved in improving the performance of DeltaXML’s
comparison
software as well as developing new ways of representing change to XML.
Tristan lives in Salisbury, UK, with his wife and two young daughters. Outside of
work he enjoys reading about and watching movies and he is also a keen runner.
Nigel Whitaker is Chief Architect of DeltaXML and has driven the development of their
XML comparison and merge products, their APIs and products related to DITA and
DocBook.
The ISO Standards Tags Set (ISOSTS) is a customization of NISO’s Journal Article Tag
Suite (JATS) developed for the International Standards Organization for authoring
standards
documents.
As part of the authoring workflow used at ISO, they required the capability to produce
redline publications of a document in order to show
changes between different versions of a given standard. Alongside Typefi, who provided
the functionality for publishing the marked XML into PDF with redlining, we provided
our XML
comparison toolset to detect and mark the changes as required.
This paper discusses some of the issues we faced while completing this work, including
the representation of changes in the XML, comparison of tables, ignoring text formatting
changes, and the use of processing instructions. The paper also looks at the pros
and cons of various format design decisions that can have an impact on the suitability
of that
format to support good comparison.
The ISO Standards Tags Set (ISOSTS) [isosts] is a customization of NISO’s Journal Article Tag Suite (JATS) developed by Mulberry
Technologies
[mulberry] for the International Standards Organization for authoring standards documents. Documents
authored in this format can then be
converted into multiple publishing formats such as Adobe InDesign, PDF, HTML or EPUB,
using a solution from Typefi called Typefi Publish [typefi-publish]. As part of the authoring workflow used at ISO, there was a requirement to produce
documents in these published formats that displayed changes between
different versions of a standard using redlining. Redlining is a technique for marking
changes in a document, typically using text styling to highlight deleted and/or added
content.
For example, all deleted text could be highlighted by colouring it red and striking
through the text. Added content could be highlighted with an underline. It is also
common practice
to highlight only added content and mark the position of deleted content using a caret
such as ‸ or ⁁.
Typefi approached us and asked us to be involved in producing a proof of concept,
building on top of their existing solution for ISO. Our expertise in XML comparison
and change
representation matches perfectly with Typefi’s expertise in content layout and document
publishing to provide a solution to this new requirement for ISO. Our contribution
included
producing a tailored comparison of ISOSTS documents, ignoring certain types of change
that were not important to ISO. The result from this is fed into Typefi Publish which
handles the
DeltaXML change representation format, DeltaV2, to produce the redlined final output.
As an alternative, we also provided modifications to ISO XSLT stylesheets that convert
ISOSTS into
XHTML directly. These modifications used CSS to provide the redline change highlighting.
Document Comparison Overview
Comparison is a key component of any system that is dealing with documents that change
during their lifetime. Understanding the differences between different versions of
a document
is absolutely vital and, in some industries, can even be a legal requirement. It is
therefore important to understand the implications for document comparison when those
documents are
stored in an XML format such as ISOSTS.
Because of the structure and syntax of XML, line based comparison tools can often
produce incorrect comparison results. Line based tools are often unaware of XML syntax,
and
changes which can usually be ignored, such as indentation, namespace prefixes, and
attribute ordering can lead to false notification of changes. Consider the following
two XML
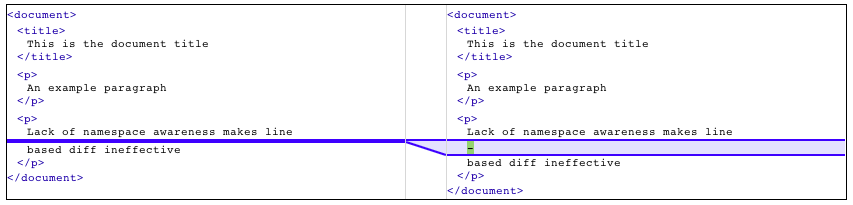
documents and the line-based comparison provided by a UNIX diff.
Figure 1: Document A
<document xmlns="demo-namespace">
<title>This is the document title</title>
<p>An example paragraph</p>
<p>Lack of namespace awareness makes line based diff ineffective</p>
</document>
Figure 2: Document B
<demo:document xmlns:demo="demo-namespace">
<demo:title>This is the document title</demo:title>
<demo:p>An example paragraph</demo:p>
<demo:p>Lack of namespace awareness makes line-based diff ineffective</demo:p>
</demo:document>
Figure 3: Result of comparing Figure 1 and Figure 2 with UNIX diff
1,5c1,5
< <document xmlns="demo-namespace">
< <title>This is the document title</title>
< <p>An example paragraph</p>
< <p>Lack of namespace awareness makes line based diff ineffective</p>
< </document>
---
> <demo:document xmlns:demo="demo-namespace">
> <demo:title>This is the document title</demo:title>
> <demo:p>An example paragraph</demo:p>
> <demo:p>Lack of namespace awareness makes line-based diff ineffective</demo:p>
> </demo:document>
The result of this particular line based comparison gives no advantage over visually
inspecting the two documents to detect the differences. The tool’s lack of understanding
of XML
syntax means that it detects far too much difference in the two documents.
It is possible to improve the results of a line based comparison by canonicalizing
the documents to be compared to ensure consistent use of namespace prefixes, defined
attribute
ordering, and consistent indentation. This will go some way to reducing the amount
of false differences identified by line based tools but there are still limitations
with what can be
achieved. Change identification at the word level is potentially still problematic
and if the documents reference a DTD for example, correct parsing of the documents
is necessary for a
comprehensive comparison since parsing may actually affect the content of the document
itself (this is covered in more detail in section “Infoset Augmentation”).
An XML aware tool has the advantage of being able to parse the document, taking into
account any references to external content (e.g. DTDs, XIncludes) where necessary.
As well as
parsing, it is then a simple task to add pre-processing of documents using various
XSLT steps to perform tasks such as segmenting sentences into individual words. If
we use an XML
aware tool such as DeltaXML Core to compare the two documents, we get a result more
like that shown in Figure 4. This is an HTML rendering of the underlying
result format produced by DeltaXML Core.
Figure 4: Result of comparing Figure 1 and Figure 2 with DeltaXML Core
Change representation
Identifying change to XML documents is just the first part of a solution. Once these
changes have been discovered, there needs to be a way of representing those changes.
This
does not necessarily need to be in a result document; in some use cases it may be
appropriate to produce a report on the changes that have been made. However, in the
context of
producing redline documents, it will be necessary to represent the changes within
the context of the documents themselves. In the case of ISOSTS, this marked document
is an
intermediate result file which can subsequently be rendered either as a redlined PDF,
using Typefi Publish, or as a redlined XHTML document, using the XSLT stylesheet extension
mentioned in section “HTML change visualization”.
There are several options for representing change within the document context, each
of which has its own benefits and drawbacks.
Tracked Changes
Although tracked change representations are usually intended to be generated during
live editing of a document, it is perfectly possible to generate the relevant syntax
from
changes identified during a comparison. The actual syntax varies depending on the
consuming application but many editors use processing instructions to mark changes.
The advantage of processing instructions as a representation is that they do not break
the validity of the content they are tracking and they do not require modification
to a
format to enable tracking of change. A major disadvantage is that there is no standard
syntax defined; each editor typically uses its own syntax to represent change. This
means
that, if visualisation of changes is required in multiple editors, changes identified
will need to be converted into multiple result formats. There is also the chance that
it is
not possible to represent specific types of change, e.g. attribute changes, using
the syntax provided by a specific editor.
This type of change representation was not appropriate in the ISO solution as the
final document needed to be a published document that was not viewed in an editing
application. In order for changes to be displayed in hard copies of a document, they
needed to be represented by styling of the text and, while it is technically possible
to
convert these processing instructions into styling as part of a publishing process,
other representations were deemed more suitable.
Format-specific syntax
Some document formats, e.g. DocBook, DITA, and OpenDocument, define elements and/or
attributes specifically for marking changes. DocBook, for example, includes a
revisionflag attribute on most elements that can take the values changed, added, deleted, and off. DITA includes
a CDATA rev attribute and a status attribute that can take the values changed, new, deleted, and
unchanged. These attributes can be used to represent change, and the relevant tools for publishing
documents to formats such as HTML and PDF can use them to add
styling for change highlighting.
The advantage of using this type of syntax is that it is built directly into the language
specification. This means that there is often support for making use of such syntax
in
existing publishing tools. Again, one disadvantage is that the syntax may not be valid
on every element that has been changed. In DocBook and DITA, it is not possible to
mark
attribute changes using the aforementioned syntax.
Of course, not all documentation formats include such syntax in their specification
and in this case, we must either amend the specification where possible, or use another
approach. This was the case for ISOSTS but as we were not able to edit the specification
we opted to use our own generic change representation.
Generic change representation
Both options listed above are specific to particular formats or editors and, while
they are useful ways of representing change, they do require the use of specific tools
or
languages. A generic way of representing change in XML is a more preferable solution
as it can be applied to any XML format, whether change marking is specified in the
language or
not and, with appropriate support, could be visualised in any editor.
A generic solution should be able to represent change to any part of an XML document
including addition/deletion/modification of attributes, and addition/deletion of elements
and text. Ideally, it should not cause the XML document to be invalid and it should
be simple to process the document to obtain the ‘latest’ version. To ensure consistency
across
different document formats and editors, such a solution lends itself well to becoming
a standard and the W3C has created a Change Tracking Markup Community Group [w3c-change] in order to discuss ideas that could potentially lead to a standard.
In the meantime, we continue to use our own generic markup format, DeltaV2 [deltav2], to represent changes to XML documents. This markup
uses elements and attributes in a separate namespace to show the input documents in
which each element occurred. In the case where an element occurs in both documents,
attributes
are used to show whether there have been modifications. It is possible to represent
attribute changes by converting an element’s changed attributes into an XML subtree
containing
the relevant information. Text changes are also represented by wrapping different
versions of text strings inside elements. An example result representing the changes
between the
documents defined above (Figure 1 and Figure 2) is shown below.
Figure 5: DeltaV2 Result
<document xmlns:deltaxml="http://www.deltaxml.com/ns/well-formed-delta-v1"
deltaxml:deltaV2="A!=B" deltaxml:version="2.0" deltaxml:content-type="full-context">
<title deltaxml:deltaV2="A=B">This is the document title</title>
<p deltaxml:deltaV2="A=B">An example paragraph</p>
<p deltaxml:deltaV2="A!=B">Lack of namespace awareness makes line
<deltaxml:textGroup deltaxml:deltaV2="A!=B">
<deltaxml:text deltaxml:deltaV2="A"> </deltaxml:text>
<deltaxml:text deltaxml:deltaV2="B">-</deltaxml:text>
</deltaxml:textGroup>
based diff ineffective</p>
</document>
Making use of DTDs and schema
We encountered issues with some of the ISO documents we tested as the use of DOCTYPE
instructions was not consistent. For a given pair of documents, for example, one included
a
DOCTYPE instruction but the other did not. This led to issues, particularly with infoset
augmentation, described below. The ISOSTS standard does not explicitly state the intended
use
of the DTD and whether it should be included in instance files in a DOCTYPE instruction.
This could lead to different behaviour for documents provided by different implementers.
Many
specifications, for example the XHTML specification [xhtml-spec], explicitly state that a conforming document MUST include a DOCTYPE
instruction.
While many XML authors will understand that a DOCTYPE instruction has “something to
do with validating” the XML they are writing, they will not always be clear about
the full
implications of this instruction. While it is true that a DTD provides validation
of the document being authored, it also has implications on the meaning of whitespace
in a document
and on the appearance and/or value of certain attributes.
Whitespace
Prior to comparison, it is recommended practice to ‘normalize’ whitespace within the
input documents. This is because differences in whitespace are not usually significant
to
authors and in fact cannot always be represented once a document has been rendered
in a publishing format. Whitespace normalization, in its simplest sense, converts
each whitespace
sequence into a single space character. This means that all indentation and occurrences
of multiple contiguous spaces are removed, being replaced by a single space. More
typically
though, normalization also involves the complete removal of inter-element whitespace. This is whitespace that is used purely for indentation and
readability and has no textual meaning at all. A simplistic approach to normalizing
this kind of whitespace is to remove all PCDATA nodes that contain only whitespace
characters.
This leads to problems in mixed content, as can be seen in the example below.
The example includes three types of whitespace nodes: inter-element whitespace within
a PCDATA node that contains only whitespace (marked with a •) that can safely be removed
entirely, whitespace within a PCDATA node that also contains non-whitespace characters
(marked with a ◦) that can be normalized to a single space character but should not
be removed,
and whitespace within a PCDATA node that contains purely whitespace (marked with a
*) that should NOT be removed. The difference between the whitespace marked * and
that marked • is
not obvious when subsequently processing the XML but the use of a DOCTYPE instruction
will cause the different types of whitespace to be reported differently by an XML
parser.
Consider a possible DTD for this document, shown below.
Figure 7
<!ELEMENT document (p)* >
<!ELEMENT p (#PCDATA | b | i)* >
<!ELEMENT b (#PCDATA) >
<!ELEMENT i (#PCDATA) >
With the inclusion of this DTD, the parser can now differentiate between the different
types of whitespace. Whitespace marked in the previous example as • can now be reported
as
ignorable whitespace as the DTD states that no PCDATA can be present as a child of the document element. All other whitespace is
reported using the characters event and should be treated as ‘normal’ PCDATA. It could still be normalized to a
single space character but should not
be removed entirely.
Infoset Augmentation
Another important implication of DTD or schema use is infoset augmentation. Infoset
augmentation means adding data from the DTD or schema to the resulting parsed representation.
It is often used to specify values of attributes, for example that a table by default
will have a 1 pixel border.
If DOCTYPE instructions are not used consistently in documents to be compared, it
is quite possible that one of the inputs will undergo infoset augmentation while the
other one
does not. This causes misleading comparison results to appear because attributes that
were added during parsing in one document but not in the other appear as added or
deleted in the
result. Such problems can be avoided by consistent use of DOCTYPE instructions.
Table Comparison
The ISOSTS specification uses the XHTML table model to define how tables are declared.
While not as complex as the CALS table model, there are still significant issues with
this
model if tables are compared as ‘plain’ XML, without knowledge of the table structure.
One example of this is adding row spanning to a cell.
Rendered result table, using bold italics to show deletion
Cell 1
Cell 2
Cell 3
Cell 4
Cell 5
Cell 6
As can be seen, the resultant table does not render well as the second row now includes
too many cells, thus pushing Cell 4 too far to the right. A better result would be
to handle
the change to row spanning by including the problematic rows from the original table,
marked as deleted, followed by the matching rows from the modified table, marked as
added. This
can be seen in the example below.
Rendered result table, using bold italics to show deletion and underline to show addition
Cell 1
Cell 2
Cell 3
Cell 4
Cell 1
Cell 2
Cell 4
Cell 5
Cell 6
This is one example of the way that tables are handled intelligently during the comparison
phase. As mentioned above, the XHTML table model is simpler than the CALS table model
leading to fewer potential issues during comparison, but there were still a number
of problems that needed to be solved.
Text formatting changes
Changing the format of specific pieces of text, e.g. highlighting a word by making
it bold or italic, is common during text editing but should this constitute a change
in a redline
document? The answer will depend on the context of the change, whether the subject
domain places meaning on such formatting, and whether or not there is a requirement
to see these kind
of changes in the redline document. In the case that it should be highlighted, there
may be different ways of doing so. The document reviewer may wish to see the text
with its old
formatting marked as deleted and the text with its new formatting marked as added
so that a complete view of the change is present. In other situations, it may be sufficient
to mark
the text with some other kind of highlighting to show that there has been a formatting
change but not include details of how the formatting has changed.
Many content authors may not even understand that there is an XML structure underlying
their document and that a format change actually constitutes a structural change.
Thus, when
they make a word bold and the resultant comparison result shows the word deleted and
then added again, they see this as a mistake.
Figure 12: A result file showing a formatting change
In order to have the ability of marking formatting changes in a different way, or
in fact ignoring them completely, we need to have some way of detecting the structural
change
without having to mark the underlying text as changed as well. One technique we have
utilised for this is to pre-process the documents to flatten the structure of formatting
elements.
The following example shows a document with a bold word that has had its formatting
flattened.
Figure 13: A pre-processed input with flattened formatting
<p xmlns:deltaxml="...">
The addition of
<deltaxml:format-start>
<deltaxml:element><b/></deltaxml:element>
</deltaxml:format-start>
bold
<deltaxml:format-end/>
formatting.
</p>
This flattened structure can handle formatting elements that are a simple tag, e.g.
<b/> or <i/> and also more complex formatting such as
<span style="font-size:14; font-weight:bold;"/>. Processing the input documents in this way then allows the text to be compared more
intuitively, as it is all at the
same level in the XML structure. Format changes are detected as changes to the <deltaxml:format-start/> and <deltaxml:format-end/> elements and the
structured formatting can be reconstructed after comparison. There is the potential
for overlapping structures in the result when formatting is flattened; to solve this
problem, the
formatting from one of the input documents, typically the latest or ‘B’ document,
is given priority when reconstructing.
ISO’s requirement was to ignore formatting changes completely and, for content that
was in both input documents, to include the formatting from the latest or ‘B’ document.
This
makes reconstructing the formatting elements a lot simpler because in the case where
formatting has changed it is possible to ignore all of the elements marked as being
only in
document ‘A’.
ID and IDREF attributes
ID attributes and their associated IDREFs are typically used for internal cross-referencing
in documents. It is important that the target of a cross-reference is declared as
an
attribute having type ID in order to ensure uniqueness within the document. Unfortunately,
this uniqueness constraint can cause problems in the result file, which must be overcome.
Imagine the situation where an image, e.g. an <img/> element, is used to display a diagram and defines an ID, e.g. <img xml:id="widget"/>. An editor of
the document decides that this should have been defined using a figure element but,
to avoid having to update references to the diagram, uses the same id: <fig
xml:id="widget"/>. This is all perfectly valid because each document maintains uniqueness of its IDs.
However, the comparison result file will contain the following content
because of the requirement to view both added and deleted content in the same document.
The document now contains two elements with the same ID value, which makes it invalid.
This situation can be resolved by renaming the IDs on any deleted, or ‘A’ document
elements
and also updating any references to that element (these will be elements in the ‘A’
document only, that contain an IDREF whose value is the ID in question). The following
figure shows
an example of a fixed result file.
Figure 15: An example fixed result file
<document deltaxml:deltaV2="A!=B" ... >
<img deltaxml:deltaV2="A" xml:id="widget_deleted_1" />
<fig deltaxml:deltaV2="B" xml:id="widget" />
<p deltaxml:deltaV2="A">This reference to the img will be deleted <xref linkend="widget_deleted_1" /></p>
<p deltaxml:deltaV2="A=B">This reference will be kept in the new document <xref linkend="widget" /></p>
</document>
This document is now valid in respect of its ID uniqueness. The deleted first paragraph
contains a reference to the old diagram as that is what it was referencing. The remaining
second paragraph now points to the new version of the diagram. The naming scheme for
updating deleted ID attributes can ensure uniqueness by using a number suffix that
does not exist
in the document. This can be checked against all existing IDs in the document.
Another potential use of ID values is to use them during comparison to align elements
of the same type with matching IDs. This can improve comparison results, particularly
for
documents that include repeated sentences and phrases as can be typical in legal documents
for example. For this technique to work, an element must maintain its ID value across
different versions of the document so that its identity is consistent. Many XML documents
are auto-generated from some other format and part of this process will involve the
generation
of ID values. If these are randomly generated, they will not be suitable for this
use as equivalent elements in different versions of a document will not have the same
ID. Even if they
are not random and use a naming scheme, e.g. fig1, fig2, fig3 etc., removal of an
element in this sequence could have a ripple effect on the ID values for all subsequent
elements,
again making them unsuitable for use during comparison. This was the case for the
ISO documents and the ripple effect of ID values changing caused a large amount of
change to ID
attributes that had to be handled using the technique above.
Processing Instructions
Processing instructions are used to supply a consuming application with information.
One thing they are increasingly used for is to insert data and/or content into a document
format that does not allow for that content in its model. This is a way of providing
a customized extension to a document format but is often used as a quick fix when
a more
appropriate solution would be to add the required functionality to the language specification.
An example of this is the use of a processing instruction to specify the size at which
a
table should be rendered on a page. In the ISOSTS documents we tested, we saw the
use of processing instructions to specify an external image location that could have been included as an attribute, e.g. <img><?img-id D09291AZ.PNG?></img> instead of <img href="D09291Az.PNG"/>.
One of the problems this causes is that if you compare documents containing such processing
instructions and you want the result file to include the processing instructions,
there
is no sensible way of representing change to them as they are not XML elements. It
is possible to preserve processing instructions, and even detect change in them by
first converting
them into an XML structure, comparing documents, and then converting the XML structure
back into processing instructions. A potential solution to representing change is
to duplicate
the containing element whenever a change is detected in a processing instruction.
For example, and <img/> containing a processing instruction as above with a change to
the external location of that image could be represented as an image deletion and
addition e.g.
This solution is not as good as being able to represent change to an href attribute as it is not as easily processed but it provides a reasonable result. This
can,
however, be problematic if the element containing the processing instruction is very
large, e.g. a table containing a processing instruction that gives information on
how it should be
rendered. Including two versions of the whole table in order to represent the processing
instruction change does not give a sensible result.
Word Capitalization
Word capitalization, like formatting change, is often viewed as an insignificant change
that should not be highlighted in a redline document. This was indeed the case with
ISO’s
requirements. Like formatting, the result document needed to include the version of
the text that was in the latest, or ‘B’ document.
A potential solution to this problem is to pre-process the input documents to ensure
that all text uses only lower case. For documents whose text is mainly prose, this
is not
appropriate as upper case letters are an important feature of the text and should
be preserved during comparison. Because pre-processing the inputs in this way does
not make sense for
the ISOSTS documents, the solution was to post-process the result file to detect those
text changes where the only difference between the two versions was letter case. The
following
figure gives an example of the kind of change that can be detected.
Figure 17: An example of a text change involving capitalization
<p deltaxml:deltaV2="A!=B" ... >
Word capitalization is often seen as an
<deltaxml:textGroup deltaxml:deltaV2="A!=B">
<deltaxml:text deltaxml:deltaV2="A">insignificant</deltaxml:text>
<deltaxml:text deltaxml:deltaV2="B">Insignificant</deltaxml:text>
</deltaxml:textGroup>
change.
</p>
A text-based comparison of the ‘A’ and ‘B’ branches of the <deltaxml:textGroup/> element after converting both strings to all lower-case, shows that there is no
change. In this situation, we can remove the marked changes and include only the text
from the ‘B’ document.
This technique works well for the cases where a text change is purely a capitalization
change. More complex changes that involve capitalization in conjunction with addition
and/or
deletion of surrounding words will still include the capitalization change in the
final output. As the capitalization is part of a larger change which will need to
be reviewed anyway,
this is not likely to be a significant inconvenience.
HTML change visualization
As well as the ISOSTS specification, ISO provide XSLT stylesheets that convert an
ISOSTS document into standalone XHTML. These stylesheets provide a useful and simple
way of
producing a published version of standards documents for previewing during authoring.
They can also be used to publish an online version of a standard.
As well as providing the intermediate change representation for input into Typefi
Publish, we were able to extend the XSLT stylesheets to provide some redline functionality
in the
XHTML output. In the simplest cases, this involved first categorizing the elements
in ISOSTS as either block-level or inline elements and then extending the output templates
to wrap
block-level elements in a <div/> and inline elements in a <span/> with these wrappers defining a class attribute containing the value of
the intermediate result’s deltaV2 attribute where it was ‘A’ or ‘B’. These classes were then styled using CSS to highlight
deletions with a red background and additions
with a green background.
Other cases were more complicated and involved the overriding of whole processing
templates in the original XSLT but the final result was a useful rendering of redlining
in
XHTML.
Results
The following figures show an excerpt from each of the different types of redline
result that were produced. The PDF result was produced using the intermediate result
delta,
published through Typefi Publish and the HTML result was produced by transforming
the intermediate delta file using our XSLT extension to the ISO stylesheets. Unfortunately,
images
were not available for the HTML output at the time of writing.
Figure 18: A PDF rendering of the redline result
Figure 19: An HTML rendering of the redline result
Summary
Document comparison is a key part of any workflow involving changing documents and,
with more and more documents being stored as XML, it is important to provide tools
that
understand the XML structure and the implications that it has on comparison results.
As we have demonstrated, there are many subtle areas to consider when looking at XML
comparison and
change representation and many of the problems we have encountered could have been
made simpler by designing the document formats with comparison and change representation
in mind.
This case study shows that the problems arising during comparison of structured content
are not insurmountable and those considering moving to an XML representation for their
document
storage should not be reluctant to do so based on any of issues seen here.
Structured content offers huge benefits, not least of which is the processability
of content to multiple published formats. This case study has shown that the production
of an
intermediate document containing change representation can be used to produce redline
documents in both PDF and XHTML. This intermediate file can quite easily be further
processed to
select the types of change which should be highlighted and those which should be ignored.
Coupling this technology with Typefi Publish, which provides the flexibility of multiple
output formats and professional layout and design capabilities provided ISO with a
comprehensive solution to their requirements for published redline documents.