McDonough, Jerome. “Some Assembly Required: Reflections on XML Semantics, Digital Preservation and the
Construction of Knowledge.” Presented at Balisage: The Markup Conference 2013, Montréal, Canada, August 6 - 9, 2013. In Proceedings of Balisage: The Markup Conference 2013. Balisage Series on Markup Technologies, vol. 10 (2013). https://doi.org/10.4242/BalisageVol10.McDonough01.
Balisage: The Markup Conference 2013 August 6 - 9, 2013
Balisage Paper: Some Assembly Required
Reflections on XML Semantics, Digital Preservation and the Construction of Knowledge
Jerome McDonough
Jerome McDonough is an associate professor in the Graduate School of Library & Information
Science at the University of Illinois. His research focuses on socio-technical aspects
of digital libraries, with a particular focus on issues of metadata and description
as well as digital preservation of complex media and software. Prior to joining the
faculty at GSLIS, Prof. McDonough served as the head of the Digital Library Development
Team for New York University.
The semantics of XML markup is a perennial topic of discussion among markup enthusiasts,
but these discussions often focus at the level of the meaning of a tag within a document,
or within a document collection. Such discussions also have an inherent assumption
of looking at the meaning of a tag at the moment. Employment of XML markup and machine
ontologies for long-term digital preservation raises question of how meaning of tags
may alter over time and how tags meaning may differ depending on the agent interpreting
the tag. This paper discusses the Preserving Virtual Worlds project on the preservation
of computer games and the semantic issues that arose in trying to use XML and OWL
ontologies for long-term digital preservation.
"You keep using that word. I do not think it means what you think it means."
— Inigo Montoya, The Princess Bride
Introduction
The issue of semantics has been of perenniel interest to those who study markup languages.
From Eliot Kimber's presentation on HyTime semantic groves Kimber, 1996 to Steven Newcomb's work on semantic integration Newcomb, 2003 through more recent work such as Dubin's and Birnbaum's Dubin & Birnbaum, 2008 comparison of markup technologies for knowledge representation and Karen Wickett's
Wickett, 2010 discussion of contextual aspects of semantic interoperability of markup langauges,
discussions of what exactly tagging structures and markup mean and the implications of semantics for dealing with issues of interoperability and
knowledge representation have consumed the time and energy of markup enthusiasts for
decades. In some sense, the entire literature on markup languages can be viewed as
a continuing conversation about semantics and the best means for their technical and
syntactical implementation in the realm of text.
For the past six years, participants in the Preserving Virtual Worlds projects have been investigating the preservation of computer games and interactive
fiction. A great deal of that work has focused on how to best employ XML and semantic
technologies in the packaging of content and metadata for preservation. XML metadata
standards such as METS McDonough, 2006, PREMIS PREMIS Editorial Committee, 2012 and Dublin Core Weibel, Kunze, Lagoze & Wolf, 1998, along with new ontologies created in OWL-DL, have been employed in conjunction with
data models such as FRBR IFLA Study Group, 1997 and the Open Archival Information System (OAIS) Reference Model CCSDS, 2012 to try to develop packaging mechanisms for long-term preservation of game software
as well as knowledge bases regarding file formats necessary for digital preservation
within the OAIS model. Our team has benefited from earlier work on XML semantics,
but as we endeavored to create XML mechanisms suitable for long-term preservation,
there has seemed to us to be a component missing in much of the discussions of semantics
and markup.
Ultimately, much of the discussion of XML semantics has focused on the question of
How is the meaning of a document augmented or otherwise affected by the presence of
markup?Marcoux, Sperberg-McQueen & Huitfeldt, 2009 This is a valid and important question, but in focusing at the document level, I
am afraid we may be focusing on the trees (and the groves) to the neglect of the larger
forest. By employing a mental model of markup semantics which focuses on meaning as
emerging from the interaction between a text, its markup and a reader, we may be missing
other influences on meaning that operate at a larger scale than a single document,
or even a collection. In many situations, such influences may be irrelevant and safely
ignored, but within the realm of digital preservation and, I suspect, many other enterprises
worried about large scale knowledge representation, focusing on meaning at the document
level may be problematic. In the remainder of this paper, I will describe some of
the problems we encountered in attempting to preserve computer games, XML's and OWL's
role in our solutions to those problems, and discuss a possible alternate formulation
of markup semantics based on social constructionist theory.
The Problem of Meaning in Digital Preservation
The Preserving Virtual World project McDonough et al., 2010 was an investigation into the preservation of computer and video games and interactive
fiction. As part of this project, the research team investigated the application
of various XML technologies to the problem of packaging these complex media objects
for long-term preservation. Of critical importance was trying to develop a means
of packaging games which complied with the OAIS Reference Model.
Compliance with the OAIS Reference Model imposed some difficult requirements on the
project team. Of particular note is one aspect of the information model employed by
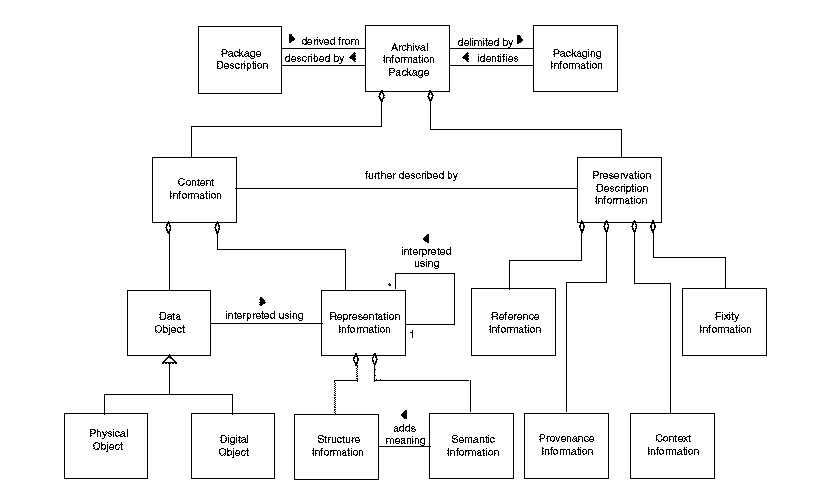
the OAIS Reference model shown in Figure 1.
Figure 1: OAIS Archival Information Package Model
The information model depicted here sets out what OAIS calls the Archival Information
Package, the body of information which an archive needs to preserve to insure the
longevity of the data object, which is the original target of preservation. As shown,
an archival information package for a preserved digital object should contain not
only the object itself, but a variety of additional information, of which one of the
most important types is Representation Information, the information that allows
someone to take the sequences of bits which comprise the data object and
interpret them as meaningful information. Representation information can be either
structural or semantic in nature. Structure information maps bit sequences into basic
data types (e.g., character data, integers, floats); the Unicode standard Unicode Consortium, 2012, for example, allows one to map a series of zeros and ones into
a particular character set, while IEEE Standard 754-1985 IEEE, 1985
defines a mapping from bit sequences into floating point numbers. Semantic information,
on the other hand, provides someone who is using the data with additional information
they need to fully interpret it. Knowing that a particular string of 32 bits represents
two short integers requires structure information; knowing that those integers represent
the X and Y map coordinates of an object in a DOOM game map requires semantic
information.
As can also be seen in Figure 1, representation information can be recursive in nature. If structure or semantic
representation information is itself in digital form, the archive should additionally
store the representation information needed to decode the other representation information.
Ultimately, this recursive chain can only be broken by storing representation information
in a form that does not require the technological assistance of computer to display
that information in readable form to a human being (e.g., on paper).
Conformance with this information model means that a digital archive will store not
only the original data object, but also the associated standards and documentation
defining the data format in which the object is written. Within the realm of space
science data preservation for which the OAIS Reference Model was originally intended,
this is a relatively straightforward and unproblematic endeavor. Standards for codebook
documentation of scientific data sets such as the Data Documentation Initiative Codebook
Data Documentation Initiative, 2012 and the Data Format Definition Language (DFDL) Powell, Beckerle & Hanson, 2011 provide relatively concise definitions of data formats used for scientific data.
While they have some degree on reliance on additional standards for the definition
of fundamental data types (e.g., DFDL assumes the use of W3C XML Schema data type
definitions), the complete set of representation information required for data such
as a social science survey is small and fairly well-bounded.
This proved not to be the case for the vast majority of the computer games that the
Preserving Virtual Worlds project examined. There were a number of problems involved
in identifying and collecting a set of representation information documenting the
data formats used in a particular game, but one stood out as being particularly problematic.
Unlike scientific data, which is often quite intentionally recorded in a manner to
facilitate its exchange and use across a variety of computing platforms using standards
such as NetCDF or HDF5, executable software is tightly bound to a particular platform.
The representation information set for a computer game thus often becomes equivalent
to the information necessary to completely document its operating platform.
Consider a game like Blizzard Entertainment's Warcraft III: Reign of Chaos for OS X, and let us ignore the large number of different files and file formats
employed by the game and focus solely on its main executable. This is a file in the
Mach-O format. Structure information needed to interpret the Mach-O format begins
with the OS X ABI Mach-O File Format ReferenceApple, Inc., 2009. However, this work, while providing the basic format definition for Mach-O, is not
a complete specification of the format in that it makes specific reference to another
document, Mach-O Programming Topics. This document in turn references other documentation necessary to understand its
content, including System V Application Binary Interface AMD64 Architecture Processor Supplement, the OS X ABI Dynamic Loader Reference, Plug-in Programming Topics, etc. Moreover, the ability to understand the OS X ABI Mach-O File Format Reference involves more than simply having the set of additional reference documentation available.
A section of text such as this:
is readily interpreted by anyone with experience in the C programming language, but
a good deal less so if you lack that experience. It is easy enough to include documentation
on the C programming language in the representation information set for the Mach-O
format but understanding that it is actually a C language data structure (and hence
that the representation information set should include documentation on C) requires
a relatively deep knowledge of computer software design and implementation.
This problem is exacerbated when we move beyond considering structure information
to considering the semantic information necessary to interpret a Mach-O binary executable.
Binary executables contain platform-specific machine code; in the case of the version
of Warcraft III on my desktop, the executing platform is based on the Intel 64 architecture.
We should, therefore, add the seven volume Intel® 64 and IA-32 Architectures Software Developer's Manual documenting the machine code for Intel systems to our representation information,
plus the set of additional documents referenced by those volumes as well as the additional
technical library necessary to achieve the level of knowledge necessary to comprehend
the Intel® 64 and IA-32 Architectures Software Developer's Manual. In short, understanding a single file requires the equivalent of a small, specialized
engineering library.
We found this problem recurring in our examination of computer game files. Even something
that on its face would seem relatively unproblematic, Adobe's Portable Document Format
specification, proved to have a truly remarkable representation information set, for
it references a large number of additional standards documents from ISO, IEEE, the
World Wide Web Consortium and others. Understanding the specification also requires
knowledge of the mathematics of Bézier curves, color theory, audio encoding techniques,
and principles of font design. For any number of file formats employed by computer
games, representation information sets are both large and poorly defined.
The OAIS Reference Model recognizes this as a potential problem for those administering digital archives,
and states that an archive may limit the amount of representation information it stores
to the minimum which the community it serves requires in order to decipher a particular
format. If your archive serves a community of computer scientists, you presumably
do not need to store a copy of Kernighan & Ritchie's C Programming Language to allow them to understand the Mach-O format; similarly, if you serve a community
of Middle English scholars, your representation information set for William Langland's
Piers Plowman need not include a Middle English dictionary and grammar. Unfortunately, our project
was focused on preserving games within the context of academic research libraries,
where detailed technical knowledge cannot be assumed for all users, and where even
those users who possess advanced techical knowledge of existing platforms may have little knowledge of or experience with previous platforms. I
would expect any computer scientist today to have a reasonable working knowledge of
modern disk operating systems and disk formatting operations, but the exact form of
an Apple II disk image file or the instruction set for the Apple II's MOS 6502 microprocessor
is something for which I would expect many would need to consult a manual.
This has meant that for computer games, identifying and collecting representation
information is not simply an issue of documenting a particular file format. It is
an exercise in knowledge representation and management. If highly complex, multimedia
objects such as game software are going to survive in the long-term, archivists will
need to collect, organize and preserve a large body of additional information necessary
to interpret those objects. Or perhaps more precisely, they need to collect, organize
and preserve the information necessary to allow an individual to acquire the knowledge
to interpret those objects. The problem the game preservationist confronts is that
they do not need to merely preserve the game; they need to preserve people's ability
to be able to understand the game, from the level of individual 0's and 1's on up.
This problem has dimensions other than the purely technical one we have been discussing.
On the technical side, if we are to preserve the seminal interactive fiction game
Adventure in its original form, we need to preserve the ability to understand DEC's version
of Fortran IV from the mid-1970s. If we wish to preserve people's ability to understand
the importance of Adventure in computing history, however, there is other information that we might wish to preserve,
documentation such as Dennis Jerz's historical examination of the game's development
Jerz, 2007. The OAIS reference model recognizes that all data objects have this form of contextualizing
information, and recommends that an archival information package include information
on "why the Content Information was created and hot it relates to other Content Information
Objects."CCSDS, 2012 For scientific data collections, this will typically involve documentation on the
reasons why a study was conducted, links to associated data sets, and in some cases
links to publications based on the scientific data in question (metadata standards
such as the previously mentioned Data Documentation Initiative provide XML facilities
for recording these links). Attempting to apply the OAIS reference model outside the
realm of scientific data quickly led our research team to the conclusion that digital
preservation of computer games was more complicated. A cultural artifact such as a
game has links to a much wider range of related materials. Documentation for the MIT
game SpaceWar!, for example, would not really be complete without including reference to it being
a tribute to E.E. "Doc" Smith's Lensmen novels as well as its information on its impact on later vector graphic games such
as Atari's Tempest and Star Wars arcade games.
Ultimately, digital preservation is devoted to insuring users' ability to interpret
the preserved material in both a specific technical and more general historical sense.
Essentially, the goal of a preservationist is to allow users of libraries and archives
to make sense of the information in a collection, whether their interests are technological,
historical or cultural. In the next section, I will discuss the role that XML and
OWL played in trying to pursue these goals, and then discuss the implications of this
for larger discussions of XML semantics.
Problems in Using XML for Preservation: Trying to Make Sense of Sense-Making
Recognizing the need to incorporate significant amounts of representation information
and contextual information about a game as part of a package used to preserve a game
in the long term, and recognizing that this in turn meant preserving a great deal
of information about the relationships between the digital files we would include
in an archival package for a game, the Preserving Virtual Worlds team turned to XML
and OWL as mechanisms to tackle this problem in knowledge representation and management.
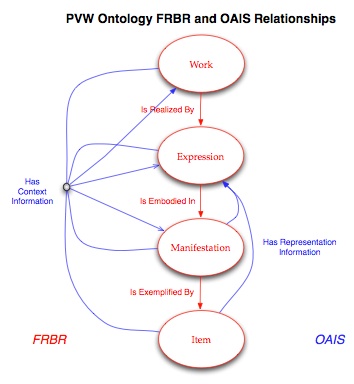
OWL-DL was used to create an ontology in which the major entities from the FRBR entity-relationship
model were defined as OWL classes, and relationships from FRBR were defined as properties.
Relationships between various information entities in the OAIS reference model were
further defined as properties in the ontology relating different FRBR classes. A partial
representation of the OWL class and property relationships in the Preserving Virtual
Worlds ontology is shown in Figure 2.
Figure 2: Preserving Virtual Worlds Ontology
By using the OWL ontology in conjunction with XML standards from the digital library
community intended for packaging bodies of content and metadata together (e.g., METS
and OAI-ORE), we could organize the various materials we need to preserve a game over
time. An OAI-ORE file, for example, could provide URLs for the files comprising a
game along with all of the files containing representation information and contextual
information. The OAI-ORE file could also be used to indicate that files represented
instances of FRBR classes (e.g., file 'advf4.77-03-31' is a FRBR Item) and that different
entities participated in relationships defined within the OAIS Reference Model (e.g.,
file 'advf4.77-03-31' (a Fortran IV source code file) has representation information
in the form of the FRBR Expression of DEC's Programmer's Reference Manual for Fortran
IV, which in turn has a physical manifestation and an item exemplifying that manifestation
in the file 'DEC_FORTRANIV_1968.pdf').
While the specific terms employed by our project as an effort in digital preservation
differ from those employed elsewhere in the digital library community, this use of
XML for packaging digital library materials is hardly a novel application of markup
technologies (see, for example, Morrissey et al., 2010 and Bekaert, Hochstenbach and Van de Sompel, 2003). We were able to employ our ontology with a variety of XML packaging languages
for digital library objects and capture the requisite content and metadata we believed
formed the backbone of a digital preservation effort for game software. But examining
our work more closely in retrospect, certain aspects of our ontology and its application
strike me as troubling.
The first problem we encountered was that the OAIS relationships between information
objects that appeared relatively clear semantically as described in the Reference
Model turned out be somewhat more polysemous in actual application. If we examine
the full network of representation information necessary to interpret a file in Adobe
PDF format, for example, we find a great deal of subtle variation in the roles performed
by representation information necessary to interpret the Adobe PDF specification itself.
IEEE-754 obviously constitutes representation information for the Adobe PDF specification,
and of a type clearly defined within the OAIS Reference Model: structure information.
IEEE-754 defines the underlying bit patterns used to represent floating point numbers
in Adobe PDF. A specification like CIE L*a*b* ISO, 2008 also constitutes representation information necessary for a complete interpretation
of PDF, as L*a*b* is one of the standard color spaces referenced within the PDF specification
and the specification is necessary for understanding the semantics of color information
embedded within some PDF documents. But other documents referenced within the Adobe
PDF specification, while of assistance in interpreting information in a PDF file,
are not representation in the same way that IEEE-754 or CIE L*a*b* are, which is to
say, the Adobe PDF specification does not have a technical dependency on those specific documents. Graphics Gems IIArvo, 1994 and Graphics Gems IIIKirk, 1994 are both valuable texts for achieving an understanding of the Bézier curves used
within the PDF specification, but no more so than a variety of other texts on that
topic. They do provide semantic information that allows someone to make sense of a
PDF document, and hence qualify as representation information, but their relationship
to the PDF specification is not the same as the standards documents identified as
normative by Adobe. The Graphics Gems series books could be replaced by substitutes and still leave the PDF specification
interpretable in a way that is not true if IEEE-754 vanished from the Earth and all
knowledge of it was lost. All of these texts, however, are at least referenced by
the PDF specification itself. Their status as representation information is therefore
at least subtly different than, say,Visual Color and Color MixtureCohen, 2001, which while it provides the semantic information necessary to understand the matrix
algebra operations for color space transformation employed within the PDF specification,
is not referenced by that document at all. All of these ancillary texts might be considered
representation information for the PDF specification; but their status as such is
varied, and the application of a common ontological predicate (http://people.lis.uiuc.edu/~jmcdonou/PVW2.owl#hasRepresentationInformation)
to link them all to the PDF specfication hides a great deal of semantic nuance.
Also somewhat disturbing in our examination of the XML preservation packages we were
developing was the realization of the situationally-determined nature of the truth
of assertions regarding representation information and context information. Consider
a PDF instruction manual that comes with a game; while the PDF specification allows
for embedding of JPEG image data within a PDF file, this particular file does not
use JPEG data for its images. If we ask, 'does this particular file have the ISO/IEC
10918-1:1994 ISO, 1994 standard which defines the JPEG data format as part of its representation information
network,' the answer is clearly 'no.' You do not need ISO/IEC 10918-1:1994 to decode
the manual. However, if we ask instead, does the representation information network
for the PDF specification include ISO/IEC 10918-1:1994,' the answer is 'yes.' ISO/IEC
10918-1:1994 is cited as a normative reference by the PDF specification, "indispensable"
for the application of the PDF specification itself.
The OAIS Reference Model discussion of representation information seems to imply that
representation information networks are specific to a data file, so for PDF files
as a class, there can be no a priori determination of the representation network necessary for decoding a file. Identification
of a representation information network has to be conducted on a file-by-file basis,
significantly increasing the knowledge management burden on digital preservationists.
Given that tools for automating the identification of representation networks for
a file at this level of detail are non-existent, this is an unhappy realization for
a digital preservationist. Equally unhappy, however, was the realization that the
semantic interpretation we had been applying to our "hasRepresentationInformation"
term was somewhat at odds with how the OAIS Reference Model describes representation
information as a concept. Our understanding aligned with asking the question of "in
the abstract, does Document A have Document B as representation information" and not
"in the case of this specific file, does Document A require Document B as representation
information." This is clearly problematic at a variety of levels, not the least of
which is 'how is a user in 100 years, seeing our ontology applied in a preservation
environment, going to know that our interpretation of representation information is
at variance with the original standards document which proposed the concept?'
One final problematic arose in applying our ontology in packaging of computer games,
with respect to the idea of context information in the OAIS Reference Model. The OAIS
Reference Model defines context information as "the information that documents the
relationships of the Content Information to its environment. This includes why the
Content Information was created and how it relates to other Content Information objects."
The problem with this definition with respect to games is that the task of documenting
a game's relationship to its environment and identifying how it relates to any and
all other content information objects is a nigh-infinite task. If I take a game like
the original DOOM, do I need to document it's relationship to predecessor and successor
games that employed similar themes (e.g., MindScape's The Colony and Valve's Half-Life),
to alternative media presentations of the story (ab Hugh and Linaweaver, 1995 and Bartkowiak, 2005)), to other games from its manufacturer, id Software, to legal documents in a lawsuit
filed by relatives of the survivors of the Columbine shootings against id Software?
To archives of speedrun competitions using the game? To fan websites? To the approximately
4,000 journal articles retrieved from Google Scholar in response to a search for "doom
'computer game'"? Completely specifying context is an impossible task, and for any
given user, much of that context will be irrelevant.
This leads to a problem similar to the representation information problem. A given
user will consider some documents as valuable context information and others as irrelevant,
but those judgements will vary from user to user. Given this, any record I make as
preservationist of context information is going to have an implied semantic connotation
beyond simply 'this is context information' of 'this is what we believe is the important
context information.' And implicit in that relative value judgment will be a number
of assumptions about what sort of scholarly activity is important (and what is necessary
to support that scholarly activity). Scholars will interpret the application of a
'hasContextInformation' predicate to information they need for their work as an endorsement
of the significance of their field of study; similarly, finding that information they
need doesn't receive recognition as context information (and information they consider
irrelevant has) will also speak to the significance (or lack thereof) of their work.
Languages, including ontological languages are not written or read in a vacuum, and
a seemingly simple predicate such as 'hasContextInformation' can easily acquire additional
layers of meaning in use.
A common thread running through all of these problems is the relationship between
terms' meanings and the contexts in which they're applied. Each application of an
ontological term such as 'hasRepresentationInformation' or 'hasContextInformation'
can reinforce or redefine that term's meaning. Our research team had lengthy discussions
on issues such as whether something was really representation information or whether it was something else. Should documentation
of the architecture of an Intel processor-based personal computer be considered representation
information for a binary executable (for surely apprehension of the full system architecture
is necessary to completely understand how an op code will be interpreted) or is it
contextual information (for surely historians of tomorrow will want to understand
the complex interplays between game design and computer architectures)? Or is it both?
Or neither? These discussions were the beginning of a process by which the meaning
of our ontology's terms were defined and refined by our somewhat localized community
of practice, but they were not the end of that process. Like any other language development
process, the application of our ontology will be a process in which our community
negotiates to achieve a shared, if imperfect, common understanding of the ontology's
terms' meaning.
Viewing the semantics of an OWL ontology as an example of language activity in which
meaning of terms is socially constructed and variable is fine if you are a linguist
interested in pragmatics, but somewhat problematic from the point of view of a preservationist;
if the meaning of ontological terms is socially constructed, I cannot assume that
this process will magically end when the ontology is published; it is more likely
that the meaning derived from these terms by humans will continue to be redefined
and reinterpreted. What if the meaning of the ontological terms I have created suffer
linguistic drift over the next 100 or 500 years? If I'm employing an ontological language
to convey to users what documents they need to obtain to decipher a bit stream, how
can I help insure that they understand the language I'm using to express those thoughts
today, when I cannot be assured they will be interpreting the terms in the same way
I am?
Knowledge Scaffolding: XML as a Tool in the Social Construction of Knowledge
Dervin, 2003 proposed that information design "is, in effect, metadesign: design about design,
design to assist people to make and unmake their own informations, their own sense."
Our efforts to employ XML and OWL technologies as the basis for long-term knowledge
preservation and management conform to Dervin's definition of information design.
We are trying to assist others in the future make sense of bit streams from the present
day, both at the basic technical level of learning how to decode a particular bit
stream and at the higher intellectual level of understanding a game's role and value
within our culture. Enabling this, however, requires that those in the future be able
to make sense of our knowledge management framework. How do we approach the problem
of enabling people to make sense of digital information when the frameworks we use
for managing that information involve terminology that are problematic to interpret
even for a contemporary user, with meanings that appear to be far less stable than
we might hope?
I cannot claim to have the solution to these problems, but the nature of the problems
we experienced with Preserving Virtual Worlds I believe points to at least a few parameters
that need to be part of our solution. The first is to develop an account of meaning
in XML and other markup technologies that more adequately handle the issue of meaning
in context. Work on relevance theory (see, for example, Wilson and Dan Sperber, 2004 and various other theoretical takes on pragmatics and sociolinguistics (Barron and Schneider, 2009, Linell, 2006) offer what may be a more productive account of semantics for several reasons:
they abandon the simplistic encode/transmit/decode model of communication set forth
by Shannon and Weaver,1949 in favor of a model that allows for linguistic inputs as one of multiple inputs to
a message's recipient;
in so doing, they explicitly account for an individual's context (social and otherwise)
as part of the process of inferring meaning from linguistic inputs; and
they are founded on a model in which, as Linell observes, "knowledge of language is
emergent [emph. original] from practice" and practice is inherently social, which is to say
meaning is constructed through a variety of communicative interplays in society, and
is not innate or static.
These characteristics of much modern work on pragmatics align nicely with our observations
of ontology use in the Preserving Virtual Worlds project. Specific ontological terms
in our project originated within the Open Archival Information System Reference Model,
but as we applied our ontology and packaging standards, we found that our practice
was somewhat at odds with the original formal definition, which is to say, our team
constructed a somewhat different meaning for the terms than they originally had. Linguistic
theory which accounts for and explains these linguistic practices in a manner more
sophisticated manner than labeling them 'noise' or 'transmission error' is necessary
to plan for preservation systems which mitigate misunderstandings caused by linguistic
change over time.
For some, this may sound perilously close to an endorsement of tag abuse. I would
argue that tag abuse is simply another name for language praxis, and that if XML systems
are to be useful in information systems designed for extended use, we need to account
for that activity in knowledge management systems design. Failure to do so will lead
to brittle systems which do not perform well outside of a very limited setting.
[1]
An account of pragmatics sufficient to at least begin thinking about the concept of
a pragmatics of XML is, then, part of the solution we need. Another part is a better
understanding of how to take that knowledge and apply it in information systems design.
Alan Rector's piece on problems in the development of medical terminology provides
an interesting example of failure analysis in this domain, and similar interesting
work on classification systems has been done by Bowker and Star, 1999 and others, but we need more work on how to account for terminological fluidity in
information systems design.
Within the domain of digital preservation, I believe our experience with OWL and XML
packaging does make one thing clear: the users of the future cannot and will not be
able to decipher the meaning of our ontological terms separate from seeing their application
in practice, and if semantic variation and change over time is going to be made visible
and explicit to our users, then a fundamental aspect of digital preservation systems
must become preserving information about the preservation system itself, including
the XML languages used within the system. And given the social nature of language
use, such preservation cannot take the form of simply saving versions of specific
vocabularies as they are changed over time. We will need to preserve records of the
actual use of markup languages over time so that if necessary users can examine the
historical record of our markup languages' development.
Those of us working in digital preservation need to remember that our job is to support
individuals in making sense of the historical record of digital materials, that such
sense-making is fundamentally social in nature and involves drawing upon a number
of sources, and that making sense of the historical record requires making sense of
what preservationists have done with the historical record. What I am arguing for
here is an effort to preserve information about our preservation systems that extends
well beyond traditional archival notions of provenance. We need a record of not only
the specific actions we have taken with a historical object, but documentation of
the larger socio-technical systems in which an object has been housed, categorized,
discussed, reformatted, linked and disseminated. Making sense of the past will require
making sense of the preservation systems, and without a record of those systems and
their use, including markup technologies, such a sense-making project is inconceivable.
Acknowledgements
The research described in this paper was made possible by the Institute of Museum
& Library Services' Grant LG-06-10-0160-10.
References
[ab Hugh and Linaweaver, 1995] ab Hugh, Dafydd and Brad Linaweaver (1995). Knee-Deep in the Dead (Doom, Book 1). New York: Pocket Books.
[Bowker and Star, 1999] Bowker, Geoffrey C. and Susan Leigh Star (1999). Sorting Things Out: Classification and its Consequences. Cambridge, MA: The MIT Press.
[Cohen, 2001] Cohen, Jozef B. (2001). Visual Color and Color Mixture: The Fundamental Color Space. Chicago: University of Illinois Press.
[Dervin, 2003] Dervin, Brenda (2003). Chaos, Order, and Sense-Making: A Proposed Theory for Information
Design. In B. Dervin and L. Foreman-Wernet (with E. Lauterback) (Eds.) Sense-Making Methodology Reader: Selected Writings of Brenda Dervin. Cresskill, JN: Hampmton Press.
[ISO, 1994] ISO/IEC 10918-1:1994. Digital Compression and Coding of Continuous-Tone Still Images. International Organization for Standardization, Geneva, Switzerland.
[ISO, 2008] ISO 11664-4:2008 (CIE S 014-4/E:2007). Colorimetry -- Part 4 (CIE 1976 L*a*b* Colour space). International Organization for Standardization, Geneva, Switzerland.
[Kirk, 1994] Kirk, David (1994). Graphics Gems III. Cambridge, MA: Academic Press.
[Linell, 2006] Linell, Per (2006). Towards a Dialogical Linguistics. Mika Lähteenmäki, Hannele Dufva, Sirpa Leppänen & Piia Varis (Eds). Proceedings of the XII International Bakhtin Conference, Jyväskylä, Finland, 18–22
July, 2005.
[McDonough et al., 2010] McDonough, Jerome P., Robert Olendorf, Matthew Kirschenbaum, Kari Kraus, Doug Reside,
Rachel Donahue, Andrew Phelps, Christopher Egert, Henry Lowood and Susan Rojo (Aug.
31, 2010). Preserving Virtual Worlds Final Report. Champaign, IL: University of Illinois.
Dervin, Brenda (2003). Chaos, Order, and Sense-Making: A Proposed Theory for Information
Design. In B. Dervin and L. Foreman-Wernet (with E. Lauterback) (Eds.) Sense-Making Methodology Reader: Selected Writings of Brenda Dervin. Cresskill, JN: Hampmton Press.
IFLA Study Group on the Functional Requirements for Bibliographic Records (Sept. 1997,
as amended and corrected through Feb. 2009). Functional Requirements for Bibliographic Records: Final Report. The Hague: International Federation of Library Associations and Institutions.
ISO/IEC 10918-1:1994. Digital Compression and Coding of Continuous-Tone Still Images. International Organization for Standardization, Geneva, Switzerland.
ISO 11664-4:2008 (CIE S 014-4/E:2007). Colorimetry -- Part 4 (CIE 1976 L*a*b* Colour space). International Organization for Standardization, Geneva, Switzerland.
Linell, Per (2006). Towards a Dialogical Linguistics. Mika Lähteenmäki, Hannele Dufva, Sirpa Leppänen & Piia Varis (Eds). Proceedings of the XII International Bakhtin Conference, Jyväskylä, Finland, 18–22
July, 2005.
McDonough, Jerome P., Robert Olendorf, Matthew Kirschenbaum, Kari Kraus, Doug Reside,
Rachel Donahue, Andrew Phelps, Christopher Egert, Henry Lowood and Susan Rojo (Aug.
31, 2010). Preserving Virtual Worlds Final Report. Champaign, IL: University of Illinois.