Holstege, Mary. “Where Are All The Bugs? Introspection in XQuery.” Presented at Balisage: The Markup Conference 2013, Montréal, Canada, August 6 - 9, 2013. In Proceedings of Balisage: The Markup Conference 2013. Balisage Series on Markup Technologies, vol. 10 (2013). https://doi.org/10.4242/BalisageVol10.Holstege01.
Balisage: The Markup Conference 2013 August 6 - 9, 2013
Mary Holstege is Principal Engineer at MarkLogic
Corporation. She has over 20 years experience as a software engineer in and
around markup technologies and information extraction. She holds a Ph.D. from
Stanford University in Computer Science, for a thesis on document
representation.
In a large code and complex code base, it becomes unfeasible to
manually develop tests for every feature and combination of
features. The key to quality assurance in this context is automation and focus.
Automatic generation of tests creates its own problems, however, as the
execution of a complete cross-product of all interactions will take too long to
execute, and small defects can give rise to large numbers of regression
failures that must be manually analyzed. Manually identifying the interactions
is itself a challenging undertaking, as is automatically generating
meaningful test cases. It becomes important to make smart
choices about what to expend effort on so as to minimize the risk of undetected
code defects.
This paper reports on an attempt to find areas to focus testing on in a
large XQuery code base by performing XQuery introspection on that code base,
treating the set of functions and parameter and return types as vocabularies, and
computing TF-IDF scores over the terms in those vocabularies. To the extent
that function names and types follow classic Zipf distributions,
using TF-IDF scoring over those vocabularies makes mathematical sense.
Terms that score high will be those that are common enough to be important
(high term frequency) but not so ubiquitous that they tend not to be covered by
other tests (high inverse document frequency).
Ensuring that software works properly can be a difficult undertaking.
When a code base is small and worked on by a handful of people,
you can manually generate tests with good confidence that they cover the ground.
As the code base grows it develops more complex interactions,
includes more features, and is modified by more and more developers.
The code develops unused byways and tangles of dependencies.
It becomes unfeasible to
manually develop tests for every feature and combination of features.
Complete automated testing of all possibilities also becomes increasing less
feasible:
developing cases, executing them, and analyzing the results becomes more and
more time consuming. The sad truth about QA is that the difficulty of ensuring
that software works correctly does not scale linearly with the size of the code base.
Analysis of code usage patterns can help focus attention where testing can do
the most good. Code analysis can also provide a different perspective on the
code that can lead to uncovering potential issues as well. For example, a
function that is not called much probably doesn't need a lot of testing. Testing is
designed to limit risk, and the risk of a bug in a rarely used function is
commensurately low. On the other hand, a function that is widely called may
also not need a lot of additional testing on the grounds
that it is already tested in the process of testing its callers. So again, from
a risk perspective, the risk of not adding additional tests for that function
is also low. Beyond simple
testing, analysis of usage patterns can perhaps highlight areas where APIs can
be simplified by removing unnecessary options and alternatives.
The schema types and elements used in function argument and return types form
an important part of the API. Analysis of the usage patterns of declared types
and elements against the available pool exposed by the in scope schemas can
also provide insights into possible API simplification, or testing focus.
The idea explored here is that (a) functions and types form
vocabularies of sorts
and the distribution of usage of those vocabularies follows the well-established
laws for natural language vocabularies (i.e. Zipf's law) and as such
(b) TF-IDF score calculations over those vocabularies make mathematical
sense and (c) high scoring items make interesting and useful targets for
testing.
This paper describes a case study in analyzing a large XQuery code base
using XQuery and XML Schema introspection in an attempt to determine where to
focus testing efforts, based on this idea. For functions at least, there seems
to be some reason to conclude that the idea holds promise. Types, less so.
Several extensions to XQuery are required to perform this introspection:
a schema component API, functions to provide lists of available functions and
return types and argument types of functions. It is also convenient, in order
to implement the entire processing reasonably efficiently in XQuery, to have
map data types, a structured dump of the parse tree of XQuery modules,
filesystem access functions, and the ability to evaluated constructed XQuery
functions.
Background
About ten years ago, a handful of developers worked on a couple thousand
lines of XQuery code, and one person manually constructed the tests to add to
automatic regression suites. All was well. As time went by, the code grew and
became more complex, the number of people manually constructing tests
increased, with additional people to manually analyze regression failures. Some
tests are automatically generated, but such tests tend to raise analysis costs
when something does fail. The time has come to think about new approaches and
find ways to focus effort.
The Code Base
The code base consists of about 630 thousand lines of
XQuery code, divided roughly evenly between an old and much modified
schema-driven GUI
application for database configuration and management, more recent REST endpoint
implementations and web applications, and a collection of library modules
(including some main modules used in triggers). In total there are a little over
1500 XQuery module files, defining over 68 thousand functions. In addition, the
particular XQuery implementation associated with this collection of XQuery
modules also provides a little over 1800 built-in functions. XML schemas are
actively used to strongly type parameters: there are over 150 schema files
exposing over 12 thousand global element declarations, 26 thousand named simple
type definitions, and 7 thousand named complex type definitions. The bulk of
these schemas
relate to XHTML, however. Setting that aside there are over 50 schema files
exposing over 7 thousand global element declarations, almost 18 thousand named
simple type
definitions, and 3 thousand complex type definitions.
This is a live and
active body of code, ranging in age from code first written ten years ago to
functions still just being implemented today. A peculiar problem with this
particular code base is the range of syntax in play: The code ranges from
XQuery 1.0 compliant code to code using some XQuery 3.0 features or
anticipatory XQuery extensions (similar to although not necessarily identical
to proposed XQuery features) and some very old code still using some 2003 draft
syntax. Relying on the XQuery engine itself to analyze such diverse code is
helpful, because the engine already has to reconcile the syntactic differences
internally. This peculiarity does mean that third party code analysis tools
cannot be used.
Figure 1: Detailed statistics
XQuery code
Total
1559
363497
Group
Files
Lines of code
Admin GUI
740
116714
Libraries
333
137983
REST endpoints and applications
387
101322
Misc. other
99
7478
Schema Types
Count
Total
Non-XHTML Total
Files
158
56
Global element declarations
12324
7338
Named simple type definitions
26536
17866
Named complex type definitions
7038
3009
Functions
Group
Number of Functions
Built-in functions (C++)
1849
XQuery module functions
68191
Zipf's Law and TF-IDF Scoring
Zipf's law is an empirical observation Zipf49 that
in a natural language corpus, the distribution of word frequencies (number of
occurrences, that is) varies in
inverse proportion to the rank of the word in frequency order.
Mathematically, Frequency(R) = Frequency(1)/Rk where
Frequency(R) is the frequency of the word of rank
R and k is some constant.
If you graph the distribution on log-log axes, you get a straight line.
Such distributions are very common across various fields and
applications. This paper will consider sequence types used in function
parameters and return types as forming one vocabulary, and the names of
functions themselves forming another, and look at the frequency distribution of
these terms in the corpus of XQuery modules.
TF-IDF scoring has become a standard technique for computing relevance
of documents to full-text queries since it was introduced in 1972
Jones72. TF stands for "term frequency" and is a count of
how often a particular term occurs in a particular document. In the context
of full-text search a term is typically a single word, but other terms for
phrases or wildcards are possible. IDF stands for "inverse document
frequency" and is the number of documents a term occurs in, as a fraction of
the total number of documents in the corpus. The "inverse" part of IDF means
that this number is divided, so that higher document frequencies lead to
smaller scores.
When TF-IDF scores are used to compute relevance to a query, the term
and document frequencies of each query term are combined together.
The technique is based on a particular probabilistic model of documents,
but the intuition behind it is simple enough: more occurrences of a query
term makes a document more relevant, and occurrences of query terms that only
occur in a few documents makes a document more relevant.
Various modifications and extensions of the
technique are currently ubiquitous in modern search engines. It has also been put
to related purposes, such as computing document similarities and
clustering. In these applications there may not be a query per se, but the
set of terms is taken from the documents themselves.
Here, I will attempt to use TF-IDF scores of function calls and types as
a way of selecting "interesting" functions and types on which to focus QA attention.
In this model, the XQuery modules play the role of documents, function calls or types
play the role of terms, and the terms are taken from the documents
themselves, as one would see in a clustering or similarity application.
First, we will look at the actual distributions of types and functions,
to see if computing scores makes sense at all. Where it makes sense to do so,
we will look at computed scores qualitatively and quantitatively to try to see
whether the high scoring items are indeed interesting targets for testing focus.
Distribution of Sequence Types
XQuery XQuery30 functions may have declared
sequence types for their parameters and their return values. XQuery sequence
types may be either simple type names XSD11.2 or node
tests of some kind. It is
possible to define sequence types that name a complex type without naming a
specific element. XQuery
3.0 F&O30 also allows for functions tests.
XQuery sequence
types also have cardinality indicators, with '?' meaning a sequence of 0 or 1
instances of the base type, '*' meaning any
number, '+' meaning 1 or more, and no indicator meaning exactly 1. When no
explicit sequence type declaration is given, the sequence type is the most
generic, matching anything: item()*.
Figure 2
declare function my:example($x, $y as xs:string?) as element(my:result)
The declaration of an example function. The parameter $x
has the (default) sequence type item()*, $y has the
sequence type xs:string?, and the returned value has the sequence
type element(my:result).
In this code base and the underlying XQuery engine associated with it,
the built-in functions return 196 distinct declared sequence types while the
XQuery modules use 629 distinct declared sequence types. In this particular
XQuery implementation, it is not possible to declare different named element
sequence types for parameters or return types of built-in functions.
That is, a built-in function may be declared as returning
element()
but not element(my:result).
If we consolidate all the element sequence
types for module functions, there are only 103 distinct declared sequence types.
Obviously, the sequence types used in the API form but a small part of
the total set exposed through the schemas. Only 3 named complex types are
explicitly used, from the complete set of 3 thousand (non-XHTML) named complex
types. Only 474 named elements are explicitly used, from the complete set of 7
thousand. Only 49 named simple types are explicitly used by module
functions. The overabundance of named schema components is partly because named
types and are used implicitly in the schema-driven configuration and
administration UI, and partly a matter of stylistic preference for global
element declarations and for declaring functions using generic element tests
(e.g. element()) rather than specific complex types
(element(*,my:example)). Regardless, it doesn't look like it would
be helpful to pay special attention to types or elements that are not
specifically referenced in function signatures.
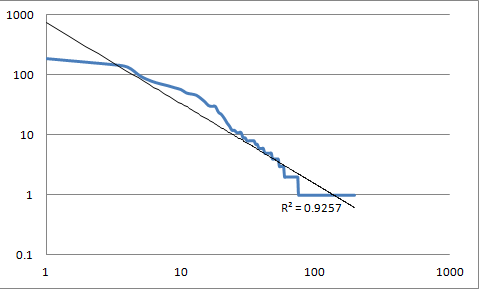
Figure 3: Sequence type distribution (return values)
The frequency distribution of return value sequence types
shown
on a double log scale. The horizontal axis is the rank and the vertical axis is
frequency. The top graph shows the distribution for built-in
functions; the bottom graph shows the distribution for module functions.
The return type frequency distribution curves in
Figure 3 do show that these return types mostly follow a
power law distribution, although for built-in functions there is
very substantial drop-off at ends, possibly as a consequence of the
relatively small vocabulary size.
The distribution of function parameter sequence types looks very
similar to that of function return value sequence types, including the
drop-offs at the extremes for built-in functions, as shown in Figure 4
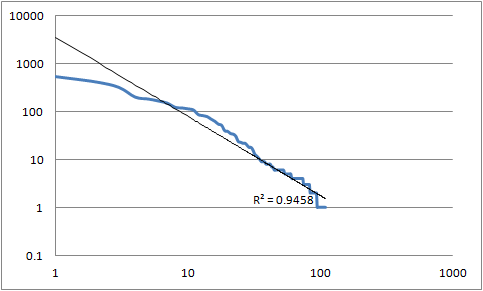
Figure 4: Sequence type distribution (parameters)
The frequency distribution of parameter sequence types
shown
on a double log scale. The horizontal axis is the rank and the vertical axis is
frequency. The top graph shows the distribution for built-in
functions; the bottom graph shows the distribution for module functions.
The top five return value and parameter sequence types share some
overlap between built-ins and module functions, although there are some
interesting differences. The atomic types map:map and
cts:query are special built-in types, the former anticipating
XQuery maps, and the latter in support of full-text queries. Given the
importance of full-text queries to this implementation, the strong showing
of cts:query is unsurprising. The strong showing of
map:map demonstrates the utility of this feature. In both
cases the distribution does suggest that these are important types and
should be the focus of some QA effort.
In this
code base it appears that developers use strong types on parameters more
often than on
function return values (as indicated by the higher prevalence of
item()* for function return values but not for parameters).
Simple types dominate the distribution for parameter types but less so for
return types. The high frequency of empty-sequence() in return
types is a consequence of the fact that the implementation supports
functions that update the data store, so many functions are called for
effect rather than for the return value.
Given that the distribution of types follows a classic
Zipf distribution, it is not unreasonable to apply the probabilistic
document model on which TF-IDF scoring is based.
The score of a particular term t that occurs at least
once in the corpus of N documents is given by the following
equation, where log is the natural logarithm,
TF(t) is the number of occurrences of t, and
DF(t) is the number of documents in which t
occurs.
Equation (a)
score(t) = log(1+TF(t)) / log(DF(t)/N)
The sequence types with the highest scores are almost all
distinctly named elements, typically those used as important API
elements. On the other hand, it must be said that there doesn't seem to
be any qualitative difference between distinctly named elements with high
scores and those with much lower scores. Various kinds of options
elements are scattered throughout the range of scores, for
example. element(xproc:xslt) has a much higher score than
element(xproc:xquery) but again, it is hard to see a difference in
the QA needs of these two sequence types. What are we to make of the fact that
xs:long has a much lower score than xs:integer? Not
much, I think. Perhaps the vocabulary of sequence types is too small to be
useful.
The scores for the top 10, bottom 10, and some selected sequence
types in between are shown, rounded to 2 decimal places.
Techniques
Type frequencies for built-in functions were computed using
some introspection APIs: a function to enumerate all the defined
functions, and accessor functions for the return type, the arity of the
function, and the parameter types. Function accessors defined by Holstege
Holstege and function introspection functions defined
in XQuery 3.0 F&O30 do not quite do the job. The
accessors defined by Holstege only give the atomic type names, not the
full sequence types, while the XQuery 3.0 functions only give access to
the function name and its arity. I used three additional
built-in extension functions, one to enumerate the set of functions, and
two to give the sequence types as string values.
Maps kept running totals of the usage of each sequence type.
Computing type frequencies for module functions requires a little
more. There are two approaches: (1) use an evaluation function that
imports a given module and uses the same approach as for built-ins, but
only considering functions in the proper namespace, (2) dump out the
module parse tree in a structured form and analyze it for the necessary
information. In this case, I used the second approach, using a built-in
extension function that dumped out the parse tree. The format of this
dump was not, alas, XML, so fishing information out of the text relied
heavily on the XQuery 3.0 function analyze-string.
Doing everything in XQuery was convenient. Doing so meant using
non-standard features such as maps and access to filesystem information.
The filesystem access gave me the equivalent of a recursive
find. It was handy, but not
strictly necessary: one could instead use shell scripts to gather up the
set of module names to process them, and then pass that to the analysis
module. Strictly speaking, maps are not necessary either, but they made
it much easier to write the analysis modules.
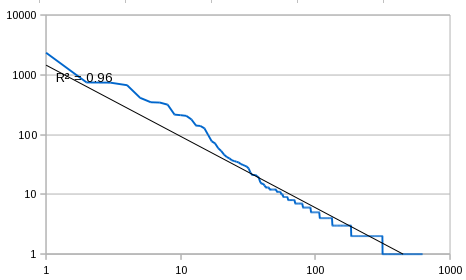
Distribution of Functions
Function call distributions show the same characteristic Zipf
distribution as types (see Figure 6, although with a
bit of a drop-off at the upper end of the curve. The majority of the top
10 functions are XQuery standard built-in functions, although map-related
functions occur at rank 8 and 9. The top 10 most frequently called
functions are:
string, concat, empty,
exists, xs:QName, error,
data, map:put, map:get,
and not.
Figure 6: Function call distribution
The frequency distribution of function calls
shown on a double log scale. The horizontal axis is the rank and the vertical axis
is
frequency.
Quite a few functions are not used within the code base at
all. A total of 497 built-in functions are unused, although only 16
module functions are unused. Given that there is a much larger number of
declared module functions, the disproportionate nature of this result
demands comment. It turns out that the unused built-in functions include a
number of accessor functions for special types (defined for API
completeness), some specialized functions that just happen not to be used
in the applications in this code base (geospatial functions, for
example), and the
constructor functions for some built-in types including some relatively
uncommon types such as xs:NOTATION. Figure
Figure 7 gives a rough break down.
Figure 7
Table II
Characterization of the built-in functions unused in any
module in the code base.
Group
Percent
Accessors and constructors for special built-in types
30.6
System management and operations
16.3
Advanced specialized functions
14.7
Assorted standard functions
13.8
Mathematical functions
9.5
Assorted standard XQuery functions
6.4
Debugging/profiling
5.4
In active development
2.4
The fact that certain specialized functions are not called
anywhere in the code base is not a problem, per se, but the fact that
out of an assortment of special built-in types of a particular class
(geospatial, for example) only a couple are not represented at all
may warrant further investigation. It may be a sign of missing
functionality in higher level APIs.
The situation with the unused module functions is better: all but
one of the
unused functions have to do with features under active development or
testing/debugging code. The remaining unused function, however, looks
like it does represent a genuine oversight.
Function Scores
Again, since the function call distribution follows a classic
Zipf distribution, it is not unreasonable to apply the probabilistic
document model on which TF-IDF scoring is based.
The scores for top 10 and bottom 10 functions are
shown, rounded to 2 decimal places. Function namespaces have been abbreviated
to prefixes.
A look at the functions with the highest scores was encouraging:
the number one
function, called navItem, is in a notorious part of the code
that has been subject to much revision and bug fixes. The function with
the third highest score was its companion function
navItemClosed. Other functions in the top ten were
service functions used within administrative API. These service
functions are called from many places, but only from within that one
module. However, that one module is very large. Document size
normalization is a common modification to TF-IDF scoring. Perhaps a similar
normalization here would be useful.
Most of the top 50 functions are other service functions for
other modules that have similar calling patterns. Are these good
functions to focus extra testing effort on? Perhaps. Directed testing of
such functions is likely to expose important bugs, but
probably normal API testing would have accomplished the same thing.
The fact that only one or two modules uses these functions does increase
the risk that fewer developers are calling them and therefore they are more
likely to be making (possibly unwarranted) assumptions about how they
will be used.
At the other end of the
scale, with very low scores, are widely used functions with names like
buildHTTPServer2 (widely used throughout the Admin UI) and
do-parse (a key function for the search APIs) and rarely
used functions such as call-calais and
create-server. Are these good functions to avoid expending
extra testing effort on? Perhaps. Certainly the very widely used functions
would have been exercised many times in many different contexts through normal
API testing. The rare functions have demonstrably few interactions with the
rest of the code, so presumably the risk of not expending a lot of effort on
testing them is low.
Quantifying the usefulness of this approach is difficult. Getting a
concrete measure for the bugginess of a particular function is hard
as bug reports are linked only weakly to particular files, much less
individual functions within those files. Here we will take the number of
source control revisions within the scope of a particular function as a
measure of how likely it is to need fixing. This is obviously an
imperfect measure, as source changes may reflect new functionality, or
trivial formatting changes. It is also a manually intensive measure to
obtain. The following graph shows statistics for functions that were used
more than once in the corpus that were defined in
the same module as the top scoring function.
It is an admittedly very small data set.
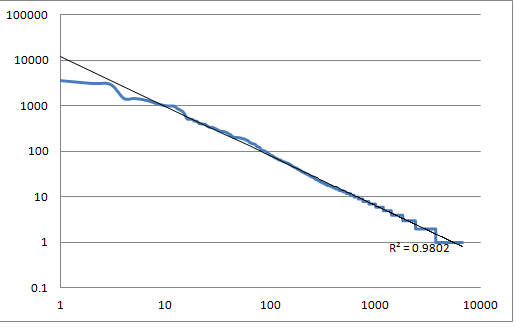
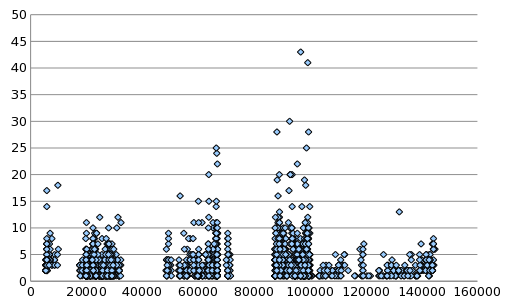
Figure 9: Revisions as a function of score
The number of revisions made to functions as a function
of score.
The correlation of score to the numbers of revisions is positive,
although not strong (R2=0.3048).
There are other associations we might expect to have stronger or more
meaningful correlations. For example, one might think that the number
of revisions would correlate with the age of a function, so that older
functions would tend to have more revisions associated with them. This
seems to be the case. For this little data set, the number of revisions
does have a stronger relationship to age, using a power
function (R2=0.6777),
as shown in Figure 10.
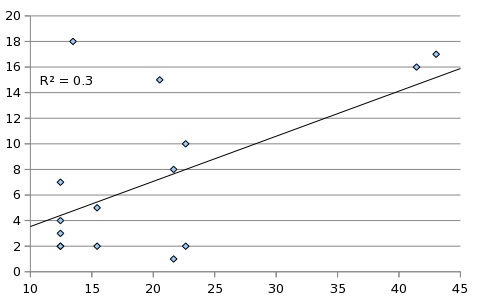
Figure 10: Revisions as a function of age
The number of revisions made to functions as a function of
the age (minimum revision number) of the function. A power curve gives
the best fit.
Similar relationships held for functions in the hand-generated data
for a couple of other modules as well, with scores showing a weak direct
relationship with R2 values
around 0.3 and age showing an inverse relationship with
R2 values about double that.
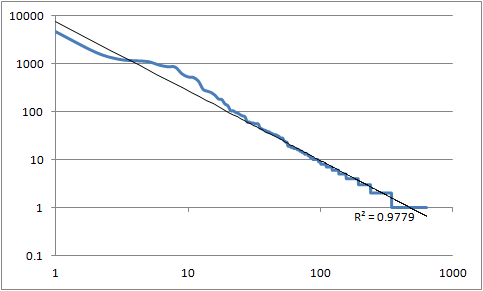
However, neither of these correlations holds up well on a larger data set
across modules, as you can see in
Figure 11 and
Figure 12. The best fit line in
both cases has R2 of essentially
zero, virtually indistinguishable from the mean value line. The data
behind these numbers is much messier than the hand-generated set, as
the automated detection of function boundaries is much more error-prone
and tends to pull in large comment blocks and non-function declarations.
Nevertheless, it is implausible to suggest that such factors
overwhelm what would otherwise be an interesting correlation. A manual
check of the statistics for a particular module from the automated
data set showed only small deviations from the statistics from the
manual procedure.
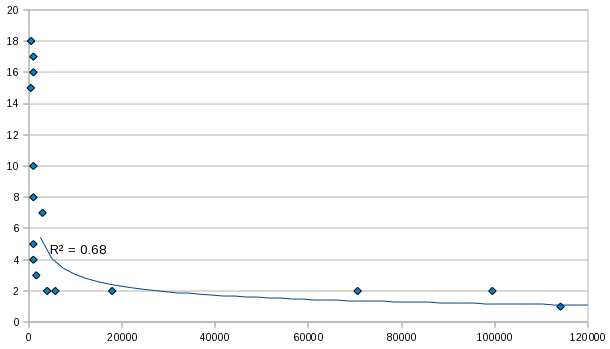
Figure 11: Revisions as a function of score
The number of revisions made to functions as a function of
the score, using a larger but messier data set.
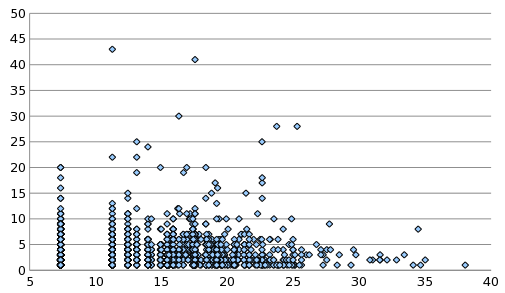
Figure 12: Revisions as a function of age
The number of revisions made to functions as a function of
the age (minimum revision number), using a larger but messier data set.
Techniques
Some of the same introspective functions for computing
the distribution of sequence types in modules were used to compute the
distribution of function calls in modules. The key technique
involved analyzing the structured dump of the module parse tree for
function calls, using maps to store running totals, and using
filesystem access functions to recursively find and process all modules
in the code base.
Computing the revisions within a particular function involved
using the source control system's ability to produce the source code
annotated with revision numbers. The resulting output was
chopped up into individual functions manually, with a little help from
Emacs keyboard macros. A shell script counted up the number of distinct
revision numbers as well as the minimum revision number for the
function using standard Unix tools such as awk,
sort, uniq, head, and
wc.
The larger data set began with a file containing the annotated
source files concatenated together. The XQuery function
tokenize was used to chop up the file first into subfiles
(by looking for the xquery version declaration) and then into
functions (by looking for declare function, and finally into
individual lines of code, from which the revision number was obtained.
Maps were used to collect minimum, maximum, and
counts of revision number.
Summary and Conclusions
XQuery introspection can be used to provide a fresh slant on a code
base, even a fairly large one. An analysis of unused schema components
(elements and types) proved largely uninteresting because stylistic
considerations for schema writing dominated actual usage requirements in the
APIs. The fact that certain extension types (in particular maps) were so common
suggests that there is a real need for providing such types as part of standard
XQuery. TF-IDF scores of sequence types did not produce any interesting
information.
The analysis of function usage points in a different direction.
A look at unused functions can highlight some interesting problems, but the
most frequently used functions are mainly basic standard XQuery functions.
Looking at a combination of frequency of use and rarity across modules using
TF-IDF scoring can pinpoint some interesting functions that warrant more QA
attention. This is a qualitative judgement. Attempts to quantify the
correlation of score to quality failed, using the number of revisions applied
to the function as a proxy for quality. Relationships within one module at a
time hold up better, but are still weak.
One common
modification to TF-IDF scoring is to normalize the TF values by the size of the
document. Since the high scoring functions included many that were only found in
a very large module, perhaps applying a similar normalization here would lead
to better results.
To perform introspection of XQuery from within XQuery, a number of
extension functions are useful:
Function accessors
list available functions as function items
return name of function item (XQuery 3.0 function-name)
return arity of function item (XQuery 3.0 function-arity)
return sequence type of return value of a function item
return sequence type of specific parameter of a function item
get type name from sequence type
Type accessors
list global element declarations for a particular schema
list named simple type definitions for a particular schema
list named complex type definitions for a particular schema
Parse tree accessors
return the parse tree for a particular module in structured form, preferably XQuery
OR:
list the functions declared in a particular module as function items
list the functions called in a particular module
File system accessors
list contents of a particular directory
determine whether a particular file is a directory
Maps
Provide a convenient means of keeping running totals
keyed to function names, for example
[XSD11.2]
W3C: David Peterson, Shudi (Sandy) Gao 高殊镝, Ashok Malhotra,
C.M. Sperberg-McQueen, and Henry S. Thompson, editors.
W3C XML Schema Definition Language (XSD) 1.1 Part 2: Datatypes.
W3C. April 2012.
http://www.w3.org/TR/xmlschema11-2/
[XQuery30]
W3C: Jonathan Robie, Don Chamberlin, Michael Dyck, John Snelson, editors.
XQuery 3.0: An XML Query Language
Candidate Recommendation. W3C, January 2013.
http://www.w3.org/TR/xquery-30/
[Zipf49]
Zipf, George Kingsley.
Human Behaviour and the Principles of Least Effort.
Addison-Wesley, 1949.
W3C: David Peterson, Shudi (Sandy) Gao 高殊镝, Ashok Malhotra,
C.M. Sperberg-McQueen, and Henry S. Thompson, editors.
W3C XML Schema Definition Language (XSD) 1.1 Part 2: Datatypes.
W3C. April 2012.
http://www.w3.org/TR/xmlschema11-2/
W3C: Jonathan Robie, Don Chamberlin, Michael Dyck, John Snelson, editors.
XQuery 3.0: An XML Query Language
Candidate Recommendation. W3C, January 2013.
http://www.w3.org/TR/xquery-30/