Introduction
The challenge of XML Parsing and Schema Validation
Extensible Markup Language (XML) has been playing crucial roles in web services, databases and document processing fields. However, it has been commonly perceived that the verbosity of XML incurs heavy processing overhead. Several academic and industry efforts have been made to accelerate the XML processing, trying to mitigate the performance pain point. [6-10]
XML parsing and schema validation are two major XML processing loads in most XML based applications. XML parsing provides the infoset and XML Schema validation determines type information for every node of the document. Beside use on the application perimeter to validate input XML messages [1][2], the schema-aware processing gains are significance inside application, using XML processing languages like XPath2.0/XSLT2.0, accessing XML database, or mapping to Java objects.
The schema validation adds extra significant overhead into XML parsing [5]. For example, the eBay Web services specification has a few thousand elements and hundreds of complex type definitions. Communicating with eBay via the SOAP protocol requires processing of large XML documents [2]. Benchmark analysis [3][4] shows that most implementations of Web services do not scale well as the size of XML document increases.
Parallel XML Processing and Multi-cores
On the hardware front, a recent trend in computer architecture is the rapid adoption of chip multiprocessors (CMPs), commonly referred as multi-core processors. Intel, as an example, has shipped several of multi-core processors from 2 cores to 8 cores and is even leading the trend from multi-core to many-core with their future-oriented 80-core chip research project[12]. It's no doubt that tomorrow's computers will have more cores rather than exponentially faster clock speeds. As more and more web services based applications are deploying on multi-core processors, the heavy XML processing in web services will need to take full advantage of multi-core processing.
In this paper, we present a hybrid parallel processing model for XML parsing and schema validation, which combines data-parallel and pipeline parallelization model to achieve high performance and good scalability. The parsing and schema validation are two major pipeline stages in this model and are both based on a novel chunk-based speculative parallel XML processing algorithm. The parallel algorithm first partitions the XML document by chunks and then apply data-parallel model to process each chunk in parallel.
Several efforts have been made in this field to parallelize XML parsing. Wei Lu first presented a pre-scanning based parallel parsing model, which consisted of an initial pre-scanning phase to determine the structure of the XML document, followed by a full, parallel parser [6]. The results of pre-scanning phase are used to help partition the XML document for data parallel processing. The research continued with an attempt to parallelize the pre-scanning stage to exploit more parallelism [8]. Michael R.Head also explored new techniques for parallelizing parsers for very large XML documents [7]. They did not focus on developing parallel XML parsing algorithm, but exposing the parallelism by dividing XML parsing process into several phases, such as XML data loading, XML parsing and result generation, and then scheduling working threads to execute each parsing phase in a pipeline model. The paper discussed a bunch of performance issues such as load imbalance and communication and synchronization overhead. Parabix uses parallel bitstream technology [10], in its XML parsing by exploiting the SSE vector instructions in the Intel architecture [9].
Compared to other approaches, our approach tries to avoid the pre-scanning overhead [6], as we discovered the pre-scanning overhead is considerable especially after we improved the parsing performance [9]. Our the algorithm is chunk-based and each parallel sub-task is to process a chunk, it helps processing a large document without loading it into the memory. The vectorization approach [10] can be used in the each parallel sub-task and therefore complementary to our approach. Moreover, our paper is the first one describing the parallel schema validation and the hybrid parallel model. The performance evaluation results show the performance benefits by this model and parallel XML parsing and schema validation.
The rest of the paper is organized as follows. Section 2 introduces hybrid parallel XML processing model. Sections 3 and 4 focus on parallel XML parsing and parallel schema validation algorithms. The last section gives the performance evaluation results and makes a performance comparison with an existed parallel XML parser model.
Hybrid Parallel XML Processing Model
The hybrid parallel XML processing model showing in figure 1 combines pipeline and data-parallel model to expose more parallelism and achieve better scalability.
Pipeline Execution in XML Processing
XML processing can be executed as pipeline. Figure 1 shows two pipeline stages, parsing and validation. The two stages can execute as a pipeline based on chunks, which means, the parsing stages inputs the XML document by chunks and outputs parsed chunks while validation stage inputs the parsed chunk from previous stage and do validation against each parsed chunk if it's necessary. After that, it either associates PSVI information with each node in the chunk or produce a simple Boolean to indicate whether the document is valid.
However, the common challenge for a pipeline model is how to maintain load balance among pipeline stages. As the speed of producing the parsed chunk can be different than the consumption speed of the validator and the difference may vary for different chunks. The parsed chunk pool acts as a cushion to absorb these differences. The more detailed discussion about how to assure load balance in pipeline model is out of the scope of this paper.
Apply Data-parallel Model
Both the parsing and validation stages can apply chunk based data-parallel model respectively to exploit more parallelism.
As shown in figure 1, parsing stage contains a number of XML parsers. At first, the input XML document is partitioned into chunks and put into a chunk pool. All of XML parsers can start speculative parsing once an input chunk in the chunk pool is available even though not receiving the whole input XML document. Any parser may perform chunk partition when the chunk number in the pool is less than a given threshold. After finishing parsing a chunk, the information for the chunk is not complete, the parallel parser must carry out post processing for the chunk after all preceding chunks are parsed. After that, the parsed chunks hold the complete infoset information for the corresponding input chunk and can be put into parsed chunk pool to be processed by next stage.
Similarly, the validation stage contains multiple parallel validators, each of which can perform partial validation once a parsed chunk is available. The parallel validator reads the parsed chunk from the pool directly. After validating one chunk, the post processing should be executed for all of preceding chunks to produce final validation result.
hybrid
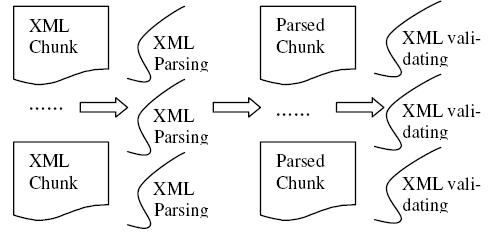
Hybrid parallel XML processing model
Parallel XML Parsing
Parallel XML parsing scans an XML document in parallel as well as checking the well-formedness and generates the parsing result. The XML document is divided into chunks so that each parser works on a chunk independently and generates its own partial result that is merged in document order during the post processing step to produce the final result.
The key to the parallel XML parsing algorithm is how to parse a chunk as a part of an XML document without seeing the whole document. A chunk may start in the middle of some string whose context and grammatical role is unknown. For example, a chunk may start as a part of element name or attribute or text value. Without this information, the parser does not know how to parse a chunk.
We present speculative XML parsing to address this issue. Speculative parsing can produce partial result for each chunk and delegate uncompleted work to post processing.
To support the speculative processing, we use a simple DOM-like XML tree(S-TREE) as our internal representation and the final parsing result. The node in S-TREE only has parent and first children link and all of sibling nodes are organized as document order, which is very memory efficient. S-TREE can be partially generated in the initial parsing step with the rest of the information completed in the later post processing step. We use the term of partial S-TREE to refer a partially generated S-TREE by speculative parsing for one chunk and all of partial S-TREEs can be linked together to be a completed one after post processing.
Figure 2 provides a detailed look at the parser. The speculative parsing based algorithm brings additional overhead: the chunk partition and the post processing. However, the overhead is much smaller than the pre-scanning overhead [6] and it can be amortized as the task can be done in parallel with speculative parsing. As shown in the figure, typically the chunk partition and the post processing are carried out only once although each parallel parser may perform the function. Comparably, the pre-scanning based algorithm [6] requires a pre-scanning over the whole document to get the skeleton of an XML document before parallel parsing can start.
pxp
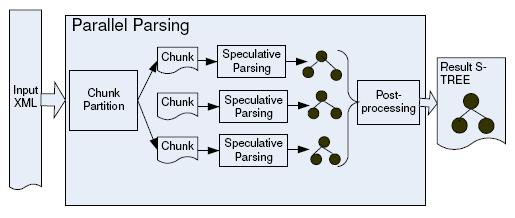
Parallel XML Parsing Algorithm
Chunk Partition
Chunk partition divides the whole or part of XML document into several of approximately equal-sized chunks and puts them into the chunk pool. The chunk size can be decided at run time to assure 1) each chunk should be big enough to minimize the number of chucks and reduce the post processing workload. 2) each parsing thread has one chunk to be processed at least, that is, the number of chunks should be larger than the number of working threads.
An issue for chunk partition is that a chunk may start in the middle of some string as we have discussed before. To make use of speculative parsing, we force each chunk must start with left angle bracket "<" by forward searching in XML during partition. By this way, each chunk can be regarded as a new XML document though it may not be well-formed.
Speculative Parsing
This step parses each chunk and generates partial S-TREE.
Because each chunk always begins with left angle bracket "<", our parser works the same way as a single threaded or traditional parser does. However, a traditional parser may throw an exception if a chunk is not well-formed. For example, figure 3-a is a possible chunk partition for a sample XML document, we can find the chunk 3 is not well-formed for it starts with an end element.
Speculative parsing deals with this issue by catching and classifying all of ill-formed exceptions. We have identified that there are three types of ill-formed exceptions. Each exception implies there is an unresolved element. All of unresolved elements can be further processed in post processing step.
1) Unresolved Start Element; which means the start element has no corresponding end element in current chunk. The unresolved start elements include "catalog", "book", and "title" in the first chunk of figure 3-a.
2) Unresolved End Element; which means the end element appeared when there is no matched start element in current chunk. Like the element "title" in the second chunk of figure 3-a.
3) Unresolved Prefix; which means the prefix has no associated namespace definition in current chunk. Like the prefix "bw" in the second chunk of figure 3-a.
sample

Figure3-a A sample XML includes three chunks
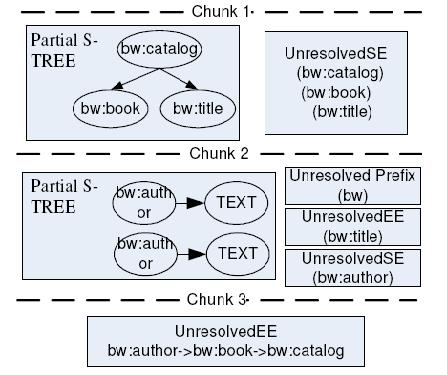
Figure3-b Speculative Parsing Result of sample XML
The unresolved start and end elements of a chunk are added to UnresolvedEE queue and UnresolvedSE queue respectively. For each unresolved start element, it also records the context information like namespace definition. In addition, the Qname of the start element and end element are recorded to help the well-formedness check in the post processing. The unresolved prefixes are recorded and later on resolved in the post processing step. Figure 3-b gives the speculative parsing result for each chunk of figure 3-a, which contains generated partial S-TREEs and unresolved elements.
Speculative parsing of a chunk may produce a number of partial S-TREEs. A new S-TREE is produced whenever the element has no parent in the current chunk. For example, the chunk 2 generates two partial S-TREEs as shown in figure 3-b. For each S-TREE, a relative depth is recorded to indicate his distance between the current tree and the tree with lowest level.
Post-Processing
The post processing propagates the context information and performs residual processing including checking well-formedness across chunks, resolving unresolved prefix and linking partial S-TREEs. As post processing has to be sequentially executed in one parallel parser, the algorithm is designed to be highly efficient.
Context information
The post processing propagates context information from the first chunk to the succeeding chunks. The context information is used in the residual processing to complete the parsing of a partial processed chunk. The context information has to include QName, namespace definition and node reference of each unresolved start element in the UnresolvedSE queue to support well-formedness checking, unresolved prefix resolving and partial S-TREEs linking. The context information has to be prepared beforehand at the partial processing as long as the UnresolvedSE queues are formed.
Well-formedness Checking
Parallel XML parsing uses two steps to check the well-formedness against an XML document. First, speculative parsing checks the well-formedness inside a chunk and post processing checks unresolved start and end element with a simple and efficient algorithm illustrated in figure 4. In this algorithm, N indicates the number of parsed chunks.
wellform

Well-formedness checking algorithm
This algorithm maintains the global context stack and matches its unresolved start element with the unresolved end elements in the UnresolvedEE queue for each chunk consecutively. After the last chunk has been processed, the global context stack and the UnresolvedEE queue of the chunk should be empty, which indicates all of start elements have matched all of end elements. Then the whole XML document is well-formed; otherwise it throws ill-formed exception.
Resolving Unresolved Prefix
In a well-formed XML document, any prefix must bind to a determined namespace. Speculative parsing can't bind an unresolved prefix to any namespace because its namespace may be defined in a preceding chunk.
To resolve unresolved prefixes, the post processing treats the namespace as context information and propagates the namespace information when maintaining the global context stack. It looks up all the ancestors of the element from its direct parent to the root element of XML document in global context stack to find the first matched namespace definition. If successful, all elements with the prefix associate the matched namespace; otherwise it throws unrecognized prefix exception.
However, there is an exception for resolving default namespace. If there is no matched default namespace definition for a default prefix, it should not report any error. Because XML specification has specified a pre-defined default namespace, it's not necessary to define a new default namespace in an XML document.
Linking Partial S-TREEs
This step links partial S-TREEs together to be a complete S-TREE representing the original XML document. The key to this step is finding the correct parent for the root node of each partial S-TREE. So element's depth is introduced to indicate the relevant depth for the element in its own chunk, which is equal to number of unresolved end element appearing before the element in current chunk. The figure 5 shows how a partial S-TREE is linked to the trunk tree. In this algorithm, N stands for the total number of chunks.
dommerge

Partial S-TREE Linking algorithm
After this step, a chunk of XML data can be represented by a number of partial S-TREEs whose information is complete enough that it can be processed by another application, for example, parallel schema validator can start validation based on partial S-TREEs to expose more data-parallel opportunity.
Parallel Schema Validation
Like parallel XML parsing, the basic idea of parallel schema validation is dividing the whole validation task into a set of subtasks, where each subtask validates a chunk of the document. Schema validation can work on partial S-TREE directly rather than the raw XML data. The validation stage has two phases, partial validation and residual validation, corresponding to speculative parsing and post processing in section 3. The figure 6 provides a more detailed look at the parallel validation.
psv
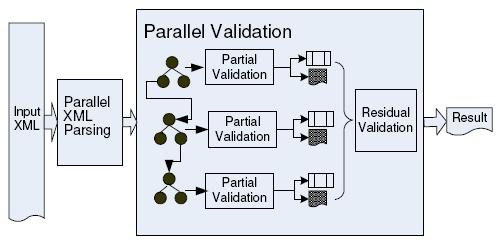
Parallel Schema Validating
Partial Validation
Partial validation starts with schema validation on the partial S-TREEs, which can be regarded as a subtask of the whole validation process starting from one of generated partial S-TREE so that partial validation can be executed in parallel based on having multiple partial S-TREEs. Usually, a finite state machine is used to describe the validation process. To validate a partial S-TREE, we must determine the schema type for the root element of a partial tree to initialize start of the start of the finite state machine.
According to schema definition, we can look up all of ancestors for a specific element to determine its schema type. As described in last section, each partial S-TREE must be linked into the preceding parsed chunks before being validated. So the ancestor link for the root element of a partial S-TREE is available. As long as the schema type of the root element is determined, the whole partial S-TREE can be validated. After finishing validating all of partial S-TREEs in a chunk it generates schema context information for all of unresolved start elements in current chunk, and summaries the type information in validation summary, which can be used in residual processing. The algorithm detail is shown in figure 7.
pval

Partial Validation Algorithm
Residual Validation
Residual validation merges the partial validation result in document order. In fact, it just resumes to validate the unresolved start elements in a chunk which has been suspended due to its child nodes are not available in that chunk. The only difference of residual validation from traditional validation process is that it will use the information kept in validation summary to do the validation work other than retrieving from original XML document. Figure 8 describes the algorithm.
reval

Residual Validation Algorithm
Performance Evaluation
This section gives the performance evaluation result. In our experiment, we use the high performance XML parser in the Intel® XML Software Suite as the baseline, which offers 80M/sec throughput single-thread performance on the 2.66G Xeon test machine [9]. We first analyzed the performance breakdown for our hybrid parallel processing model for XML parsing and schema validation. Then we measured performance of our standalone parallel parser, which only parsing and try to analyze its speedup and overhead for documents with different size. Then we make a comparison between speculative parsing based XML parser and the pre-scanning based approach, using our prototype parallel parsers with the two approaches. At last, we show the performance improvement on schema validating parser which integrates parallel parsing and schema validation.
These performance measurements were taken on a Dual Intel Xeon 5300 processor machine (2.66GHz, Quad Core, Shared 8M L2 cache) with 4G RAM. The underlying operating system for these tests was Redhat Linux EL4 (kernel 2.6.9). The test cases are taken from Intel's XML Parsing Benchmark [11], whose cases are all from real customer and varied in XML size, number of elements and element nesting depth. For example, the size of test cases is in ranging from 5K to 20M and the element nesting depth is from zero to six.
To minimize external system effects on our results, we had exclusive access to the machine during testing. Every test ran ten times, to get the average time the first time was discard, so as to measure performance with the XML document data already cached rather than being read from disk.
Performance Breakdown
Our parallel XML processing model performs the pipeline stages as described, and thus we can measure the time of each stage. The sequential stages include chunk partition, post processing in XML parsing and residual validation in schema validation. The speculative parsing and partial validation can be done in parallel. Figure 9 shows the average time consuming percentage of each stage from two threads to eight threads.
First, we find the percentage of effort related to chunk partition is nearly zero. The main reason is that speculative parsing algorithm can start parsing any part of XML as long as it starts with left angle bracket "<", which simplifies the chunk partition algorithm.
As thread number increases up to eight, we observe the percentage for another two sequential stages, post processing and residual validation grows from 10% to 35%. If excluding the overhead caused by lock contention, the time consumed by the two stages is in direct ratio to chunk number and average element depth of an XML document. For example, the worst situation is that the first chunk only has start element while the second one only contains end element, which hints the XML document has very high depth. We also measure the performance breakdown for such worst XML case. The result shows the percentage taking by post processing and residual validation is less than 50% in 8 threads, which is acceptable because such worst XML case is rare exception.
Pbreak
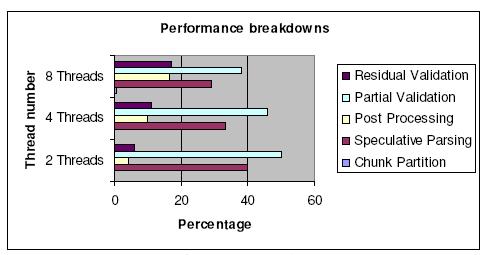
Performance Breakdowns
Standalone Parallel Parser Performance
Standalone parallel parser only parses the XML document in parallel and generate DOM-like tree. We use the term speedup to measure how well the parallel algorithm scales and evaluate the efficiency of parallel algorithms. Speedup is calculated by dividing sequential time by the parallel execution time. We use the XML parser in Intel® XML Software Suite as the baseline to get the sequential execution time. The parallel time is the time our parallel XML parser spends on build the same DOM-like tree. Figure 10 shows how the parallel algorithm scales with the number of threads when parsing the XML document with different document size.
pureperf
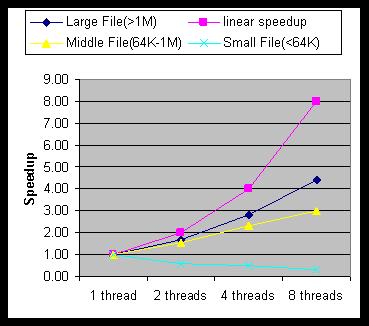
Speedup of standalone parallel parser on XML document with different size
From the figure 10, we can see that the bigger the XML document size, the higher speedup of parallel parser can achieve. Because bigger XML document can be split into more subtasks to be parsed in parallel and can maximize the utilization of multi-processors. This algorithm has very good speedup for large XML documents. It is even nearly three times faster than sequential parsing with four threads. The speedup for large documents is also nearly 4.5 with eight threads. But the overhead of thread communication and lock contention is becoming significant when the total sequential parsing time is very short for small XML documents. That's the reason why there is no performance gain for small XML documents less than 64K. But parallel parser can filter these cases at run time by setting a threshold of minimum XML document size. It still makes sense because parallel parser is designed for speeding up the parsing of large XML documents.
Besides, we made a performance comparison analysis against an alternative parallel parser prototype presented in paper [6]. Before we use the speculative execution based approach, we have developed a prototype using the pre-scanning approach. Figure 11 gives the performance comparison result for the two parallel XML parsing algorithms on large XML document. The result shows the performance of our speculative parsing based parser has significantly higher speed-up. Also, the pre-scanning based parsing approach doesn't scale very well when we use 8 threads on 8-core machine.
comperf
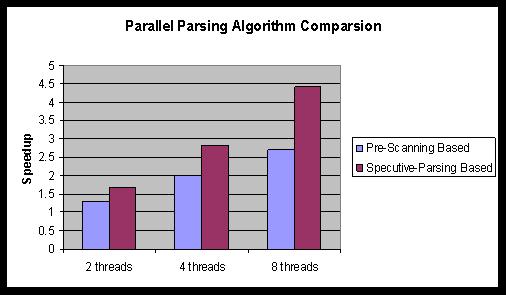
Performance Comparison for two Algorithms
Speculative parsing based parser avoids the pre-scanning process and reduces the sequential execution time as much as possible. An initial evaluation result shows that the average overhead of pre-scanning is hundreds times slower than the overhead introduced by the sequential execution time of our parallel algorithm, which explains the reason that speculative execution based parallel parser performs better than the pre-scanning based parallel parser.
Parallel validated parser performance
A validating parser performs validation during parsing. Our parallel validating parser is an integration of parallel parsing and parallel schema validation with a pipeline model. Schema validating parser has two usual usage models. The first, named parallel validator only validates the XML document and gives the validation result against a given schema. The other also outputs a DOM-like tree with type information at the same time, named parallel validating DOM parser.
Figure 12 gives the speedup for pure parallel parsing, standalone parallel validation and parallel validated DOM parser respectively on large XML documents, using XML schema validator in Intel® XML Software Suite as our baseline. The speedup of parallel validating DOM parser reaches above 5 on the 8-core test machine. The speedup of parallel validator is slightly slower as the baseline uses a faster mode which avoids generating the intermediate DOM-like tree. The better speedup of parallel validator than that of standalone parallel parser demonstrate the former exposes more parallelism by integrating parallel XML parsing and schema validation while has lower overhead of parallel validation by using the information summary in the residual processing
threeperf
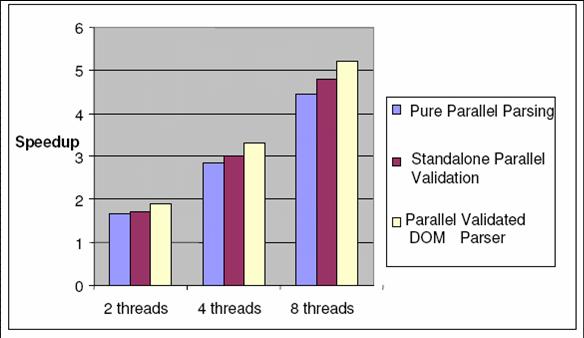
Speedup of Three Parallel Parsers
Conclusion
In this parser, we describe a new parallel XML parsing algorithm with great performance and that scales well for up to eight cores by means of speculative based parsing. Then we develop a novel parallel schema validation algorithm which can validate partial DOM-like trees generated by parallel XML parsers. Based on the two parallel algorithms, a hybrid parallel processing model is presented. This model organizes XML parsing and schema validation as a two stages execution pipeline and then apply data-parallel for each stage to expose more parallelism. Our results have shown this hybrid parallel XML processing model is effective and very efficient.
LEGAL INFORMATION
This paper is for informational purposes only. THIS DOCUMENT IS PROVIDED "AS IS" WITH NO WARRANTIES WHATSOEVER, INCLUDING ANY WARRANTY OF MERCHANTABILITY, NONINFRINGEMENT, FITNESS FOR ANY PARTICULAR PURPOSE, OR ANY WARRANTY OTHERWISE ARISING OUT OF ANY PROPOSAL, SPECIFICATION OR SAMPLE. Intel disclaims all liability, including liability for infringement of any proprietary rights, relating to use of information in this specification. No license, express or implied, by estoppel or otherwise, to any intellectual property rights is granted herein.
Intel, the Intel logo, Intel leap ahead, Intel leap ahead logo, Intel Core, are trademarks of Intel Corporation in the United States and other countries.
*Other names and brands may be claimed as the property of others.
References
[Singh2003] G. Singh, S. Bharathi, A. Chervenak, E. Deelman, C. Kesselman, M.Manohar, S. Patil, and L. Pearlman. "A Metadata Catalog Service for Data Intensive Applications" In SC'03: Proceedings of the 2003 ACM/IEEE conference on Supercomputing, page 33
[eBay] eBay. eBay Developers Program http://developer.ebay.com/developercenter/soap
[Head2005] M. R. Head, M. Govindaraju, A. Slominski, P. Liu, N. Abu-Ghazaleh, R. van Engelen, K. Chiu, and M. J. Lewis. "A Benchmark Suite for SOAP-based Communication in Grid Web Services." In SC'05: Proceedings of the 2005 ACM/IEEE conference on Supercomputing, page 19, Washington, DC, USA, 2005. IEEE Computer Society
[Head2006] M. R. Head, M. Govindaraju, R. van Engelen, and W. Zhang. "Benchmarking XML Processors for Applications in Grid Web Services". In SC'06: Proceedings of the 2006 ACM/IEEE conference on Supercomputing, page 121, New York, NY, USA, 2006. ACM Press.
[Nicola2003] Nicola, M. and John, J., "XML Parsing: a Threat to Database Performance" International Conference on Information and Knowledge Management, 2003, pp. 175-178.
[WeiLu2006] W. Lu, K. Chiu, and Y. Pan "A parallel approach to XML parsing". In The 7th IEEE/ACM International Conference on Grid Computing, Barcelona, September 2006
[Michael] Michael R. Head and Madhusudhan Govindaraju. "Approaching a Parallelized XML Parser Optimizedfor Multi-Core Processor"
[Yinfei] Yinfei Pan, Ying Zhang, Kenneth Chiu, Wei Lu, "Parallel XML Parsing Using Meta-DFA", Proceedings of the Third IEEE International Conference on e-Science and Grid Computing
[Intel] Intel ® XML Software Suite http://www.intel.com/cd/software/products/asmo-na/eng/366637.htm
[parabix] parabix, http://parabix.costar.sfu.ca
[Intel] Intel ® XML Software Suite Performance Paper http://softwarecommunity.intel.com/isn/downloads/softwareproducts/pdfs/XSSPerformancePaper.pdf
[Intel] Intel Multi-core Architecture Briefing.http://www.intel.com/pressroom/archive/releases/20080317fact.html