This paper describes work in progress on the problem of discontinuous structures undertaken in the context of the project Markup Languages for Complex Documents (MLCD) at the University of Bergen. The first section describes the problem in simple terms. Subsequent sections describe the problem as it relates to other work of the MLCD project: the TexMecs notation for marked up documents in serial form, to the Goddag data structure, and to validation with rabbit/duck grammars.
We consider the problem of discontinuity in the light of a recent proposal to treat containment and dominance as distinct relations. We suggest that this proposal allows a solution (or dissolution) of the problem, at least for Goddag structures. In the context of validation, a number of problems remain for future work.
The problem of discontinuity
Consider the following familiar passage from Lewis Carroll's Alice in Wonderland:
Alice was beginning to get very tired of sitting by her sister on the bank, and of having nothing to do: once or twice she had peeped into the book her sister was reading, but it had no pictures or conversations in it,
and what is the use of a book,thought Alicewithout pictures or conversation?
In its most general form, the problem of discontinuity
is the question How can we represent this passage,
and others like it, in a satisfactory way?
This
general problem takes more specific forms in the
context of specific notations, data structures, and
validation tools.
We might mark this up using p (paragraph
)
and q (quotation
, for reported discourse)
elements in a straightforward way:
<p> Alice was beginning to get very tired of sitting by her sister on the bank, and of having nothing to do: once or twice she had peeped into the book her sister was reading, but it had no pictures or conversations in it, <q>and what is the use of a book,</q> thought Alice <q>without pictures or conversation?</q> </p>
This encoding satisfactorily distinguishes the narrative voice from that of the characters (although it does not capture the fact that the q elements are to be read as uttered by Alice), and it allows a formatting application to supply quotation marks in the right places.
It does not, however, capture the intuitive sense the reader may have that the reported thoughts of Alice form a single continuous unitary utterance, nor the interplay and alternation between the two voices. It would be desirable if the markup sufficed to allow some of the more obviously relevant inferences to be drawn, without losing any of the information provided in the original simple markup:
-
This paragraph contains one (one!) quotation from Alice.
-
The sentence
What is the use of a book, without pictures or conversation?
occurs in the text (and should in principle be retrievable by a phrase search looking for book adjacent to without).[1] -
That one quotation from Alice is interrupted by the narrator's attribution of the thought to Alice.
The problem encountered here is not new; it has been recognized for some years. We digress briefly here to review some earlier approaches to the problem, since they help illuminate the issues.
The 1990 version of the TEI Guidelines
[ACH/ACL/ALLC 1990] proposes specialized markup
for discontinuities in the reporting of direct discourse.
Interruptions of the quotation by a narrator may be
tagged with the tag
Using
this element, the example would read:
<in.quot>.
<p> Alice was beginning to get very tired ... but it had no pictures or conversations in it, <q>and what is the use of a book,<in.quot> thought Alice </in.quot>without pictures or conversation?</q> </p>The in.quot element did not survive the revision of the Guidelines. Some readers may find it awkward (although this can be debated back and forth) because they perceive the attribution
thought Aliceas an interruption or suspension of the quotation, and not as something embedded within (and thus in some sense forming part of) the quotation. The fact that a formatting application will emit a closing quotation mark for the start-tag of in.quot, and an opening quotation mark for its end-tag, may contribute to a feeling of unease. And in.quot does not in any case handle all forms of discontinuity.[2]
Later versions of the TEI Guidelines
[ACH/ACL/ALLC 1994]
define more powerful methods of encoding discontinuity.
For certain elements (specifically, verse lines
and text divisions), a part attribute
is defined, which takes the values
I (initial
),
M (medial
), and
F (final
) (as well as
Y and N for less informative encodings).
The unity of a discontinuous element
can be reconstructed by taking the fragment
with part="I", followed by the
zero or more fragments with part="M",
and concluding with part="F".
A second mechanism uses
next and prev attributes
of type IDREF to allow each fragment of a
whole to point at the next such fragment.
The next / prev mechanism
is more general than the part attribute
because it does not
require the fragments of a discontinuous whole to appear
in order in the larger document.
The next and prev attributes
are defined for every element type,
if the additional tag set for linking is selected.
Using next and prev,
our example might look like this:
<p> Alice was beginning to get very tired ... but it had no pictures or conversations in it, <q id="q1" next="q2">and what is the use of a book,</q> thought Alice <q id="q2" prev="q1">without pictures or conversation?</q> </p>A third mechanism, less convenient but more powerful, is the TEI's join element, which creates a virtual element by joining fragments together.[3] Assuming the same IDs as just shown, the unitary nature of Alice's utterance might be encoded thus:
<join result="q" targets="q1 q2" scope="branches"/>
TexMecs notation
Mechanisms like those defined by the TEI are not, of course,
understood or supported by generic XML tools; they require
vocabulary-specific support by a different
layer of code. One goal of
the TexMecs notation first specified in 2001 and revised in 2003
[Huitfeldt/Sperberg-McQueen 2003]
is to move such information about virtual elements
and element discontinuity out of the application level
and into the level of basic syntax.
TexMecs includes a generic notation for discontinuous elements:
in addition to start- and end-tags of the form
<e| and |e>, TexMecs defines
suspend-
(|-e>)
and resume-
(<+e|) tags,
which can be used to signal discontinuity in the element.
Using this TexMecs notation, the passage from Alice in Wonderland can be encoded thus:
<p|Alice was beginning to get very tired of sitting by her sister on the bank, and of having nothing to do: once or twice she had peeped into the book her sister was reading, but it had no pictures or conversations in it, <q|and what is the use of a book,|-q> thought Alice <+q|without pictures or conversation?|q> |p>
This has the modest advantage over the next / prev mechanism of TEI P3 that it does not require that we generate unique identifiers for the fragments; it's also a bit more compact than the attribute-based notations. It shares with the other mechanisms mentioned the property of assuming some more abstract layer in which elements fragmented in the concrete syntax are treated as units, and of leaving the details of that more abstract layer to be specified elsewhere, while it focuses solely on the serialization layer.
In the MLCD project, efforts to define that more abstract layer have focused on the definition of generalized ordered-descendant directed acyclic graphs (Goddags).
Goddag structures
The Goddag structure is a directed acyclic graph structure developed by the MLCD project for the convenient representation of overlapping document structures [Sperberg-McQueen/Huitfeldt 2000].
Although in principle the goal of the MLCD project is to ensure that every TexMecs document be representable using a Goddag structure, and that every Goddag structure be serializable as a TexMecs document, nevertheless work to date on Goddag structures has not addressed the topic of discontinuous elements directly. The definition of Goddag structures antedated the specification of the TexMecs notation, and when the notation for discontinuous elements was added to TexMecs, we did not initially notice that it caused a problem for the existing rules for mapping documents into Goddag structures.
Our colleague Paul Meurer called our attention to
the problem, when he discovered that his program for
drawing diagrams of Goddag structures from TexMecs data
[Meurer 2001]
was producing output structurally different from the input
whenever it was asked to re-serialize TexMecs examples with discontinuous
elements. His
program maps the example into the Goddag
structure shown in Figure 1.
Figure 1: A Goddag for the Alice example Figure 2: A Goddag for the Alice example, without crossing lines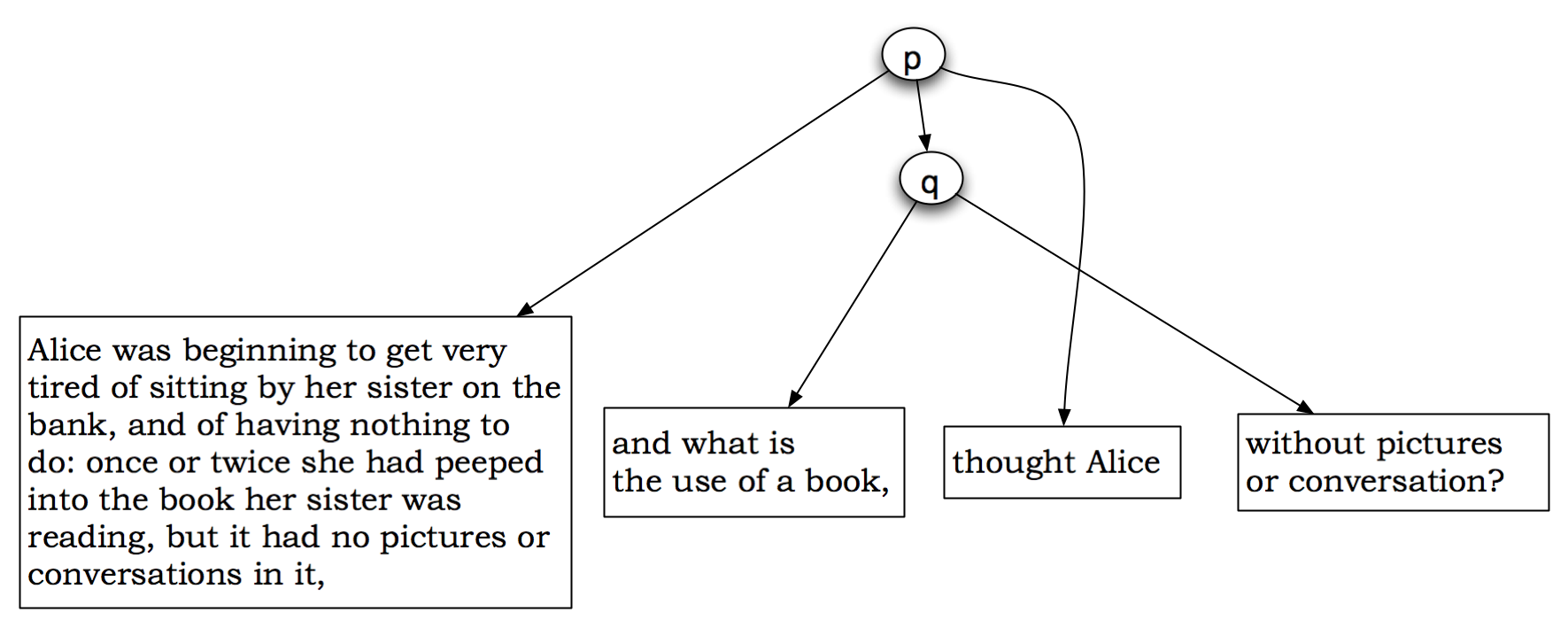
That is, the p has three children,
in the following order: a text node (Alice was beginning ... of a book
),
a q element, and a text node (thought Alice
);
the q element has two text-node children
(and what ...
and without ...
).
This is equivalent, in turn, to the TexMecs document
<p|Alice was beginning to get very tired ... it had no pictures or conversations in it, <q|and what is the use of a book,|-q> <+q|without pictures or conversation?|q> thought Alice |p>And indeed a straightforward serialization of the Goddag structure into TexMecs notation is likely to produce this form of the document, or something similar.
These observations may be interpreted as indicating a problem in the serialization of Goddag structures, and we and our colleagues in the MLCD project have spent some time attempting to understand and solve the problem in those terms, without achieving results that we have found wholly satisfactory. This paper proposes that in fact the problem indicated by this example lies not in the serialization of Goddag structures, but in the mapping from TexMecs into Goddag structures and in the definition of Goddag structures.
We can formulate the problem as we now understand it in slightly more abstract terms.
A discontinuous element in TexMecs has a start-tag, an end-tag, one or more suspend-tag / resume-tag pairs. Any discontinuous element E with P suspend/resume pairs divides the material appearing between the start-tag and end-tag of E into 2×P+1 sequences:
-
s[1] is the sequence between the start-tag and the first suspend-tag,
-
s[2] between the first suspend-tag and the first resume-tag,
-
s[3] between the first resume- and the second suspend-tag
-
...
-
s[2×N] is the sequence between the Nth suspend-tag and the Nth resume-tag (for 1 ≤ N < P)
-
s[2×N+1] the sequence between the Nth resume-tag and the N+1th suspend-tag (for 1 ≤ N < P)
-
...
-
s[2×P+1] is the sequence between the last resume-tag and the end-tag
Without loss of generality, let us consider the TexMecs document D
<A|<B|x|-B>y<+B|z|B>|A>where sequence s[1] contains just the character
x, s[2] contains
y, and s[3] contains
z. Let us refer to s[1], s[2], and s[3] as x, y, and z.
TexMecs discontinuity is meaningful just on the assumption that there is some significance both to the sequence xz and to the sequence xyz. Otherwise, there is no need to make B be discontinuous; the material interrupting it (i.e., y) can be moved to one side or the other of B.
The sequence xyz can be preserved without difficulty in the data structure if the A node has three children, in order, which are or contain x, y, and z respectively. Similarly, the unity of B can be indicated, and its contents correctly represented, if the B node has the two children x and z, in that order. And the fact that B is wholly contained within A can be captured by having the A node dominate the B node.
It appears difficult to reconcile these different demands. The original description of Goddag structures [Sperberg-McQueen/Huitfeldt 2000, p. 151] specifies a rule we will call here R1:
|
R1 |
One node dominates a second if and only if the second node is completely contained within the first. |
|
R2 |
No node dominates another node both directly and indirectly. |
Containment and dominance
In recent work reported elsewhere [Sperberg-McQueen/Huitfeldt 2008], we have for other reasons begun to contemplate distinguishing more sharply than heretofore between dominance (regarded as the transitive closure of the parent/child relation). and containment (regarded as superset/subset relation on the leaf nodes reachable from a node by following parent-child arcs).
In previous work, containment and dominance have been regarded as near synonyms, connected by the principles R3 and R4, which are a fuller and more precise statement of the same general idea as R1:
|
R3 |
If two nodes A and B each contain the other (i.e. they dominate the same set of leaves), then either A dominates B or B dominates A. |
|
R4 |
Given two nodes A and B which do not dominate the same set of leaves, A dominates B if and only if A contains B. |
The rationale for distinguishing more broadly between containment and dominance can be summarized here briefly. When a document contains several hierarchical structures, a purely containment-based method of deriving the Goddag structure leads to a confusing mixture of hierarchies: sometimes (for example) pages contain paragraphs, sometimes paragraphs contain pages, and sometimes pages and paragraphs simply share children without either containing the other. Similar things can be said about verse lines and speeches, in verse drama. This leads to a confusing account of the structure of the larger units of the document. It is convenient to be able to view a chapter either as a sequence of paragraphs (oversimplifying slightly for brevity) or a sequence of pages; it is somewhat less convenient to have to view it as containing a sequence of children some of whom are pages, others paragraphs. Such a mixed view offers little help in describing or understanding the nature of chapters, and still less in validating them against a document grammar.
We propose, then, to relax rules R3 and R4. We propose to replace them by stipulating that dominance (parent-child) relations in a Goddag structure entail containment, but not vice versa. In other words:
|
R5 |
Given two nodes A and B, if A dominates B, then A contains B. |
If we
replace R3 and R4 with R5,
then there are two Goddag structures that could
be used to describe the Alice example. In the first, we
adopt the rule that neither a discontinuous element (here the q)
nor any of its fragments is ever a child of any element
which directly dominates
any material between any of its suspend- / resume-tag pairs
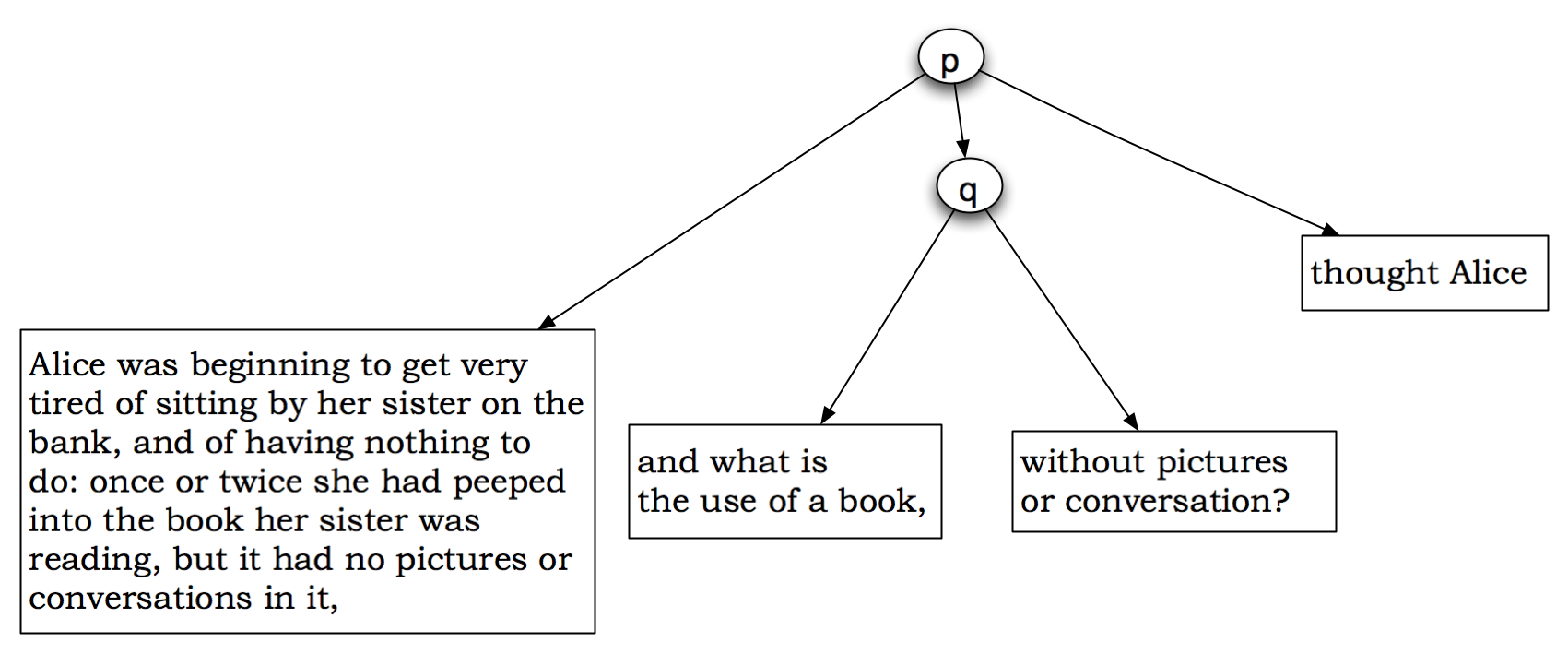
(here, the p). The result is shown in Figure 3
Figure 3: A Goddag in which P does not dominate Q
The Goddag shown in Figure 3, however,
does not reflect our intuition as readers that the
paragraph and the q element are not quite so unrelated.
From a narrative point of view, the paragraph does not
contain just four text nodes in sequence; the
paragraph contains text in the narrative voice
interspersed with text in Alice's voice. It may be
more satisfactory, then, to treat the fragments of the
q as themselves nodes in the Goddag structure and
allow them, though not the discontinuous q
itself, to be dominated by the p.
Figure 4: A Goddag in which P dominates the Q fragments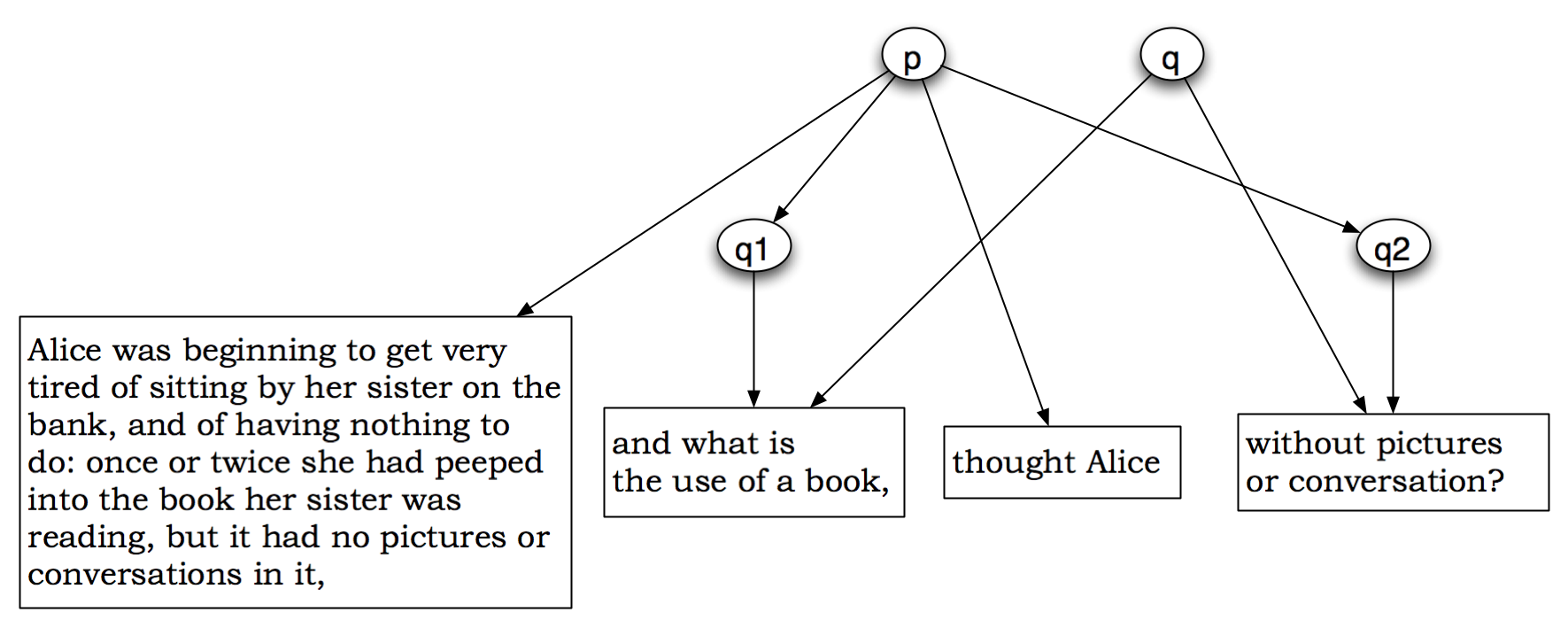
Figure 4 conveys accurately that from one point of view the paragraph has four children: two text nodes and two fragmentary q elements.
It is not immediately obvious whether the right thing to
do with the q element is to make it dominate the two
text nodes directly (as shown) or to make it dominate
the two fragmentary q elements which are its
representation in the TexMecs markup. At the moment,
we lean toward the solution shown, on the grounds that
if we want to treat the q element as a unitary object
(which was, after all, the starting point of our
discussion), no good purpose is served by making
it structurally anomalous. A normal q element
recording the sentence What is the use of a
book without pictures or conversations?
will
contain textual data, not fragmentary sub-elements.[4] If it is desirable to make
some connection between the nodes q, q1, and q2
explicit in the Goddag structure, it had better take
some other form.
Rabbit/duck grammars
The MLCD project has proposed rabbit/duck grammars as a possible mechanism for validating overlapping structures [Sperberg-McQueen 2006].
Previous work on rabbit/duck grammars has not dealt with the validation of discontinuous elements; many questions remain open, and we can do nothing here but sketch some possible avenues of attack.
It seems clear that if we specify that the discontinuous
element (q or B in our examples) matches a normal
(first-class
) token in a content
model, then the usual rules for interpreting right-hand
sides in the production rules of context-free grammars
do not apply: the usual interpretation is that the
right-hand side specifies a sequence of children for
the left-hand side, but as described at some length
above (section section “Goddag structures”)
the discontinuous element itself cannot
be part of any sequence which also contains the material which
interrupts it. We postulate, therefore, that discontinuous
elements, taken as wholes, do not match first-class
tokens in content models. If then the content model for p is
(#PCDATA | q)*and no further adjustments are made to the rules for rabbit/duck grammars, then the example from Alice in Wonderland cannot be valid.
There seem to be two obvious alternatives, each of which would make the example valid. We could introduce a new kind of content-model token for fragmentary elements, allowing us to write the content model for p as
(#PCDATA | q | #frag(q))*meaning that a p element can contain
PCDATA,
entire q elements, or fragmentary q elements,
intermixed in any order. This would allow
the example to be valid.
It might be simpler, however, to allow fragments of a first-class element to match content model tokens for that element type. When validating the p element in the example, each fragmentary q element would match the q token in the content model, so the example would be valid against the first content model given. This amounts to saying: for purposes of validating the parent, the plusses and minus-signs in the suspend- and resume-tags are ignored, and they are treated as if they were end- and start-tags; only for validation of the discontinuous element itself does the difference between fragmentary element and entire element matter.
The content model for q itself, however, should probably be validated against the whole discontinuous q element, not against the individual fragments. Since conventional content models for quotations are likely to take a form like
(#PCDATA | %phrase.mix;)*this distinction doesn't matter for q. But if we imagine a stricter content model with a sequence of required sub-elements, the difference will matter. For example, take a conventional content model for text:
(front, body, back?)and imagine a text embedded in a larger text which interrupts it:
<doc|
<p|...|p>
<p|...
<text|
<front| ... |front>
<body|...
...
|-body>|-text>
<p|Just then, we were interrupted.
...
|p>
<+text|<+body|
...
|body>
|text>
...|p>
|doc>
As regards the discontinuous text element,
this document should probably be valid, not invalid.
Validating each fragmentary text element
separately, however, would
make the second text
fragment invalid, as it has no
front matter.
Integrating this idea more firmly into the definition of validation using rabbit/duck grammars remains work for the future.
Another pressing task will be modifying the parsing algorithm for rabbit/duck grammars to integrate support for discontinuity. The published algorithm uses Brzozowski derivatives, and it is not at all clear how to suspend the validation of an element while it is interrupted, and return when it is resumed. The validation of discontinuous elements would be easier using the graph data structure, but the only known algorithms for validating with rabbit/duck grammars rely on an event stream created by parsing TexMecs documents, and cannot be used on Goddag structures. The current working assumption is that Goddag structures contain no nodes for start- or end-tags (or any other form of tags, in languages with multiple forms of tags); if this assumption were abandoned, validation could work from the Goddag structure (but the structures themselves would be harder to define and work with).
It is possible that the treatment of interleave in Creole [Tennison 2007] will indicate a solution. Further study of the problem remains a task for future work.
Relation to other proposals
A few remarks may be in order on how discontinuity, and the proposal to distinguish between containment and dominance, relate to other proposals for handling overlapping structures.
LMNL, the layered markup and annotation language [Tennison/Piez 2002], cannot readily make a distinction between containment and dominance (we are indebted to a reviewer of this paper for this observation), and so seems unlikely to satisfy the competing demands which suggest to us that both concepts are needed. On the other hand, there is a sense in which LMNL does not need to make the distinction. Elements in a LMNL document are in any case just ranges with annotations; containment relations follow from the arithmetic of the range start and end points, but no dominance relations are ever postulated except by some application logic. The same applies for the unity of discontinuous elements: such a unity may be asserted by the application layer (that is, by the definition of a LMNL vocabulary), but it is not visible on the LMNL level, and thus need not be accounted for at the level of LMNL itself.
The design of LMNL thus seems to require that any account of dominance (as distinct from containment), and any account of discontinuous elements, be handled in the application layer. LMNL itself achieves a degree of simplicity and regularity as a result, at the expense of complexity in the application.
XCONCUR and similar mechanisms ([Hilbert / Schonefeld / Witt 2005], [Schonefeld / Witt 2006]) already incorporate the containment/dominance distinction to a certain degree. The usual rules for hierarchical markup ensure that in a set of concurrent trees, dominance entails containment, but the fact that two elements in a containment relation may be in different trees ensures that in systems with concurrent markup, the relations of containment and dominance are systematically separate and distinct. For elements in the same tree, containment and dominance are essentially equivalent (except for elements with identical character data content), and elements in different trees never have dominance relations. But these are the only two choices: either two elements are both in the same tree, or they are not. The complex network of factors in examples like the q and p elements in the Alice example, however, lead us to wish both that the p element should dominate the q fragments and that it should not dominate the q element as a whole. In cases like this, the either/or choice of concurrent markup can seem unsatisfactory. And like non-concurrent XML, XCONCUR has no conception of discontinuous elements.
Mechanisms like Trojan Horse markup ([DeRose 2004], [Bauman 2005]) can be used to serialize discontinuous elements, provided the empty XML elements used to mark the boundaries of virtual elements have ways to signal that they record a resumption, rather than only a beginning or end, of the virtual element. Trojan Horse markup can be used to encode data models which make a distinction between containment and dominance, but it does not require such a distinction; its inclination is to leave details of the abstract model for elaboration by the user. Indeed, the treatment above of discontinuity, dominance, and containment may be regarded as an attempt to make more explicit what Trojan Horse markup hints at without making explicit.
Conclusion
We have illustrated the problem of discontinuity, in particular the problems it raises for data structures intended to represent documents.
We have proposed that a graph structure which more nearly reflects our intuitions about the document can be constructed if we retain the principle that parent/child and ancestor/descendant relations imply that the ancestor contain the descendant, but jettison the converse principle that any element properly contained by another element is necessarily a descendant of (dominated by) that other element.
A number of questions remain open and will require further work:
-
Can a principled set of criteria be found for assigning parent/child relations to node pairs? What are they? Do the criteria apply at the meta-language level, or are they a function of how document type designers specify the document types they are working with?
-
Can discontinuous elements be integreated into the notion of validity associated with rabbit/duck grammars?
-
Can the algorithms for validation with rabbit/duck grammars be extended to handle discontinuous elements?
-
Can the ideas of multi-colored trees be applied successfully to Goddag structures?
References
[ACH/ACL/ALLC 1990] Association for Computers and the Humanities, Association for Computational Linguistics, and Association for Literary and Linguistic Computing. 1990. Guidelines for the Encoding and Interchange of Machine-Readable Texts (TEI P1). Ed. C. M. Sperberg-McQueen and Lou Burnard. Chicago, Oxford: Text Encoding Initiative, 1990.
[ACH/ACL/ALLC 1994] Association for Computers and the Humanities, Association for Computational Linguistics, and Association for Literary and Linguistic Computing. 1994. Guidelines for Electronic Text Encoding and Interchange (TEI P3). Ed. C. M. Sperberg-McQueen and Lou Burnard. Chicago, Oxford: Text Encoding Initiative, 1994.
[Bauman 2005]
Bauman, Syd.
2005.
TEI HORSEing around.
In Proceedings of Extreme Markup Languages 2005.
On the Web at
http://www.idealliance.org/papers/extreme/proceedings/html/2005/Bauman01/EML2005Bauman01.html
[DeRose 2004]
DeRose, Steven J.
2004.
Markup overlap: A review and a horse.
In Proceedings of Extreme Markup Languages 2004.
On the Web at
http://www.idealliance.org/papers/extreme/proceedings/html/2004/DeRose01/EML2004DeRose01.html
[Hilbert / Schonefeld / Witt 2005]
Hilbert, Mirco, Oliver Schonefeld, and Andreas Witt.
2005.
Making CONCUR work.
In Proceedings of Extreme Markup Languages 2005.
On the Web at
http://www.idealliance.org/papers/extreme/proceedings/html/2005/Witt01/EML2005Witt01.xml
[Huitfeldt/Sperberg-McQueen 2003]
Huitfeldt, Claus, and C. M. Sperberg-McQueen.
2003.
TexMECS:
An experimental markup meta-language for complex documents
.
Working paper of the project Markup Languages for Complex
Documents (MLCD), University of Bergen.
January 2001, rev. October 2003.
Available on the Web at
http://decentius.aksis.uib.no/mlcd/2003/Papers/texmecs.html
[Jagadish et al. 2004]
Jagadish, H. V.,
Laks V. S. Lakshmanan,
Monica Scannapieco,
Divesh Srivastava,
and
Nuwee Wiwatwattana.
2004.
Colorful XML: One hierarchy isn't enough
.
Proceedings of the 2004 ACM SIGMOD International
conference on management of data, Paris,
sponsored by the Association
for Computing Machinery Special Interest Group on Management of Data.
New York: ACM Press.
[Meurer 2001] Meurer, Paul. 2001. TexMECS tester. Web-accessible program for drawing Goddags from TexMecs data. Available on the Web at http://decentius.aksis.uib.no/cl/mlcd/texmecs-tester.html
[Schonefeld / Witt 2006]
Schonefeld, Oliver, and Andreas Witt.
2006.
Towards validation of concurrent markup.
In Proceedings of Extreme Markup Languages 2006.
On the Web at
http://www.idealliance.org/papers/extreme/proceedings/html/2006/Schonefeld01/EML2006Schonefeld01.html
[Sperberg-McQueen 2006]
Sperberg-McQueen, C. M.
2006.
Rabbit/duck grammars:
a validation method for overlapping structures.
In Proceedings of Extreme Markup Languages 2006.
On the Web at
http://www.idealliance.org/papers/extreme/proceedings/html/2006/SperbergMcQueen01/EML2006SperbergMcQueen01.html
[Sperberg-McQueen/Huitfeldt 2000]
Sperberg-McQueen, C. M., and Claus Huitfeldt.
2000.
GODDAG: A Data Structure for Overlapping Hierarchies
,
paper given at Digital Documents: Systems and Principles. 8th
International Conference on Digital Documents and Electronic
Publishing, DDEP 2000, 5th International Workshop on the Principles of
Digital Document Processing, PODDP 2000, Munich, Germany, September
13-15, 2000. Published in
DDEP-PODDP 2000, ed. P. King and E.V. Munson.
Lecture Notes in Computer Science 2023.
Berlin: Springer, 2004, pp. 139-160.
Available on the Web at
http://www.w3.org/People/cmsmcq/2000/poddp2000.html
[Sperberg-McQueen/Huitfeldt 2008]
Sperberg-McQueen, C. M., and Claus Huitfeldt.
2008.
Containment and dominance in Goddag structures
,
paper given at the conference
Processing text-technological resources,
Bielefeld, March 13-15, 2008,
organized by the Zentrum für interdisziplinäre Forschung
der Universität Bielefeld.
Slides (but not full text) available on the Web at
http://www.w3.org/People/cmsmcq/2008/bielefeld/slides.html
[Tennison/Piez 2002]
Tennison, Jeni, and Wendell Piez.
2002.
The layered markup and annotation language (LMNL).
Late-breaking talk given at Extreme Markup Languages 2002 (not in proceedings).
Slides on the Web at
http://www.idealliance.org/papers/extreme/proceedings/author-pkg/2002/Tennison02/EML2002Tennison02.zip
[Tennison 2007]
Tennison, Jeni.
2007.
Creole: Validating Overlapping Markup
.
In Proceedings of XTech 2007,
Paris, 2007.
Available on the Web at
http://www.lmnl.org/wiki/images/8/86/Creole.zip
[W3C 2008]
World Wide Web Consortium (W3C).
2008.
XQuery 1.0 and XPath 2.0 Full-Text 1.0
,
ed. Sihem Amer-Yahia et al.
W3C Candidate Recommendation 16 May 2008.
[Cambridge, Sophia-Antipolis, Tokyo]: W3C, 2007.
Available on the Web at
http://www.w3.org/TR/xpath-full-text-10/
[1]
An anonymous reviewer points out that the XQuery and XPath
Full Text specification
[W3C 2008]
provides at least a partial solution to this problem.
That is, it provides the concept of a full-text window
which one could use to express the adjacency of
book and without.
It does not, as far as we can tell, define a way to
specify that book should for
some purposes be treated as adjacent to thought,
and for other purposes as adjacent to without.
It is of course not alone in this lack. (The TauRo system
now being developed at the Scuola Normale Superiore in Pisa
is unusual, in our experience, in providing for declarations
which specify that particular element types (jump tags
)
create a context switch for purposes of full-text retrieval
and proximity measures. See
http://tauro.signum.sns.it/index.php.)
[2] In verse drama, for example, speaker attributions interrupt the verse structure and are not generally regarded as embedded in the verse; in the latter way, they differ from stage directions.
[3] We describe join as more powerful because unlike the next / prev mechanism it is not limited to gluing together fragments which are tagged as elements with the same generic identifier. It also has the ability to specify that the target elements should be treated as children, or that the target elements should be disregarded and their children treated as children of the virtual element, which is lacking in the other mechanisms described here (including TexMecs).
[4] That the q element has two text-node children rather than one is already an artifact of the encoding. But like many such artifacts, this one dissolves if instead of positing text nodes we instead posit individual characters as children of the element. Conceptually, individual character children are probably the preferable approach. We adopt the text-node approach for drawing pictures, however, since it simplifies the drawing task.