Building the Untestable—and Documenting It
For more than sixty years, the Y-12 National Security Complex (Y-12) has made components for the nuclear arsenal of the United States. Unlike other industrial products, such as automobiles and computers, Y-12's finished work cannot be tested in use. Instead, we must assure our customers that the products we send them are made precisely according to specifications, using approved procedures. Not only can the products not be tested in use, they typically remain in the stockpile inventory for some decades, so assurance of what went into an individual unit and how all the components were assembled is important for continued customer assurance (no mere 5 years/50,000 mile warranty here). And when an individual unit comes back to us, either to be refurbished for life extension or to be dismantled at the end of its life, we need to know exactly what was in it and how the components were assembled.
Because we think in long product lifetimes for these products that are not easily opened for inspection (you can't just lift the hood and check the oil), each individual product is accompanied by extensive documentation. A typical component will undergo numerous certifications, including tests of the chemical and physical properties of its materials and inspections of the part itself for dimensions, surface finish, and contaminants. Each step in the assembly process is accompanied by more tests and X-rays for alignment of components, finished dimensions, and other properties. All the test results, checklists, instrument printouts, and other materials gradually accumulate into a bulky record that is kept until the individual device is dismantled, when it will be compared with a report of what is found in the dismantlement process.
Dealing with potentially long product life expectancy and therefore also archival retention of product documentation has made the Nuclear Weapons Complex (NWC) extremely conservative about introduction of new technology to documentation. The devices that Y-12 has recently refurbished were first built before the development of the personal computer, and their documentation is entirely in paper. It is only in the past decade that the NWC has begun to require that the measurement data from certification tests be captured in electronic form. In this same period, the NWC has also begun to look at formal standards for capturing metadata about the documents, if not the actual documents themselves, in electronic format [Mason 1997]. The actual process of certifying parts has for more than sixty years continued to be driven by paper procedures and checklists used on the shop floor.
As part of a project to move to an electronic process for product construction records, we have undertaken to develop an XML-based workflow for the Dimensional Certification Report (DCR) and the Nondestructive Test Report (NDT). Dimensional certification typically employs templates and instruments such as coordinate measuring machines (CMMs). The CMMs can perform exceedingly precise tracings of surface contours and generate electronic data. At some future phase of this project we hope to merge CMM data directly into the DCR, but for the present it will be entered into the report by the inspector at a terminal beside the machine. (Our CMMs are massive instruments: to achieve the necessary precision, their work tables and supporting beams are massive blocks of granite because steel I-beams are too flexible, Fig. 1.) Typical NDT tests include visual inspection and treatment with fluorescent dyes that can help make visible minute cracks in welds or metal parts. Figure 1
Figure 1

Fig. 1. Coordinate Measuring Machine
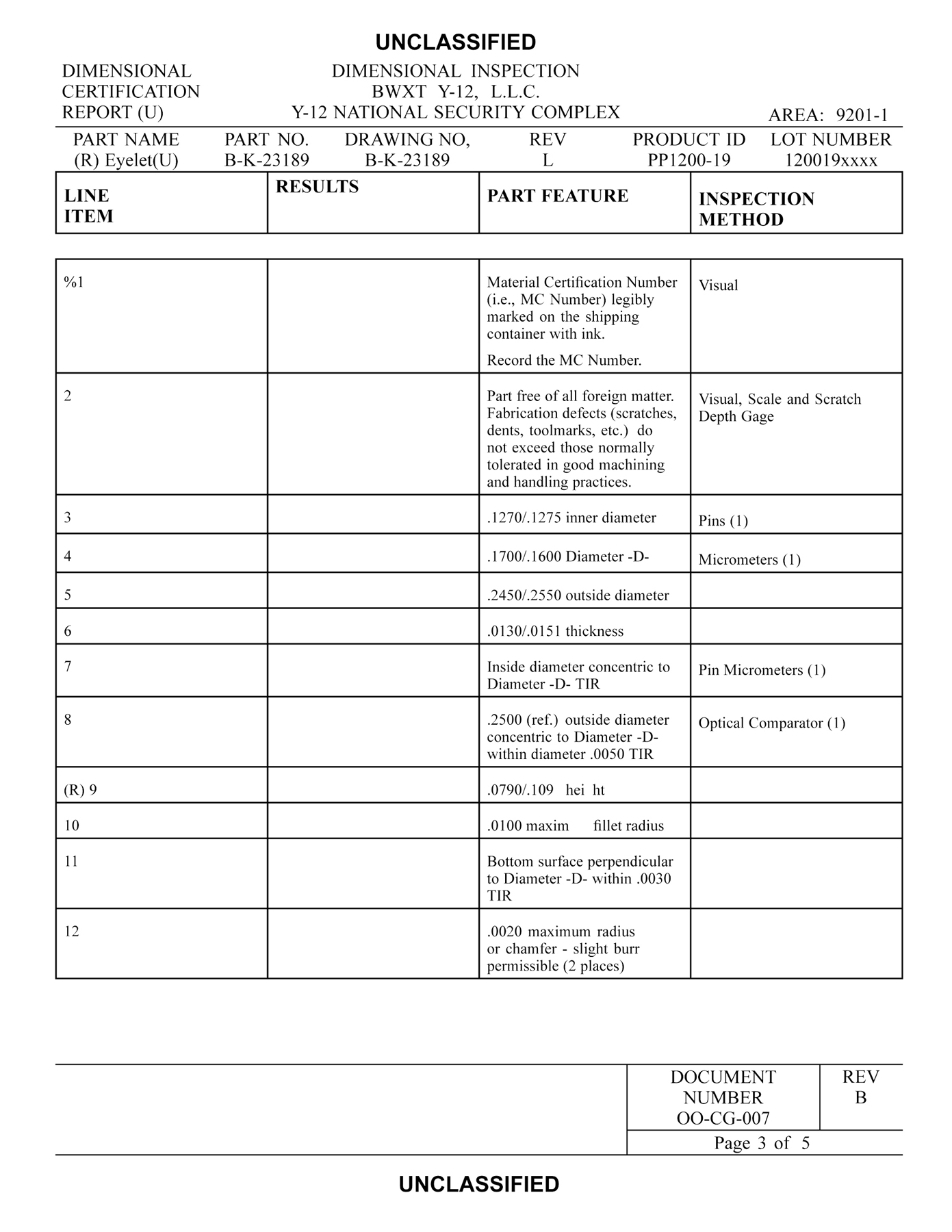
The DCR is not simply the report of results of a certification process; it is also a procedure for carrying out the process, with the results captured in forms in the body of the procedure. Thus, a potential reader some years in the future can see not only that a product has been certified but the steps that were taken in the process to certify it. As an XML document, the DCR is not particularly exceptional; it has the typical components of technical documents: sections, titles, paragraphs, lists, tables, figures. Its most unusual feature is the tabular presentation of the steps in the procedure, intermixed with spaces to capture user input as the steps are carried out. The NDT is simpler than the DCR, but it, too, captures data on a form. The procedure for the NDT is a separate document, and the form is for data capture only. (Each DCR procedure is unique to an individual component, but NDT procedures are generic to many components.)
What is more interesting than the forms as examples of XML documents is the workflow associated with the creation and use of the these procedures/reports and its implications for configuration management. In their paper format, DCRs in particular have always been under many layers of configuration control. A typical DCR contains one or more “Picture Pages” that contain drawings of the component being certified, followed by the testing procedure. Both the Picture Page and the procedure require sign-offs by a Product Engineer and an Inspection Engineer, who are responsible for the manufacture and testing of the component, and a configuration control officer, who releases the procedure to the certification laboratory under a Product Engineering Transmittal (PET). The process of developing, approving, and releasing an individual DCR procedure is well established and governed by its own controlled procedures.
In developing an electronic workflow, we are constrained by the PET process. However, behind it we must develop additional layers of configuration control on the components of the XML processing. Even though SGML, XML, and related software have been evolving in the industrial documentation sector for more than a quarter of a century, they are still young in the eyes of those in the NWC. Our configuration control must not only account for the requirements of software development, they must also meet the requirements of our customers, most of whom are not computing specialists, much less XML experts. One consequence of the PET process is that we must closely mirror the process for paper documents, and the electronic document must capture the metadata associated with the paper one that has been accepted by the user community.
Behind that, however, we must also maintain a high level of configuration control for the XML and processing components. Because the potential lifetime of certification data for a product is longer than the past history of structured markup, we must attempt to anticipate what will be needed to recall certification data when an individual product returns for refurbishment or dismantlement some day in the future, when everyone who is working either on the current XML project or who participated in the certification on the shop floor has retired. Thus the files that record results of certifications must record audit trails not only of the certification process but also of the XML and its processing behind the creation of the files. Only when we are able to integrate all of these processes and data flows into an integrated archive will we be able to say that we have implemented an Electronic Build History (EBH).
The life cycle that we are incorporating into this project is only one of the possibilities we examined. We also looked at a system for scanning user input on paper forms and a manufacturing execution system that would place the entire process under electronic control. Scanning, we decided, was actually too difficult: intelligent character recognition systems, it seems, place too many constraints on their input forms. They fit best in environments where there are large volumes of a very few forms, which is the opposite of our situation. A manufacturing execution system (MES), we know from our own tests, could be programmed for our workflow. Because our current MES is very old and does not have good data collection capabilities, Y-12 is looking at replacing it. Although the replacement MES will take time to implement, it may have appropriate data collection capabilities. Thus a workflow built around an XML publishing system with extensive scripting and an attached Web server represents a middle path for capability and costs.
The DCR Life Cycle
The certification process captured by the DCR is a late step in an overall manufacturing workflow that begins with a product specification issued by a Design Agency (DA, typically Los Alamos National Laboratory or Lawrence Livermore National Laboratory). At Y-12, that specification becomes the responsibility of a Product Engineer (PE), who oversees its interpretation into manufacturing processes on the shop floor and then certification procedures for validating the results of manufacturing. The manufacturing process for an individual component may be complex, involving many steps, each with its own associated tests. A casting, for example, may be turned to a rough shape, then gradually machined to a final shape before being submitted for final certification. At every step there are additional tests. Certification itself is often iterative: a part that is slightly off-tolerance will be returned to manufacturing for further refinement, perhaps several times, until it is able to meet all requirements of the certification. As each test is completed, the results and the reports are audited before the manufacturing step is certified. The various test reports, such as the DCR and NDT, will accumulate with each part and assembly, being accumulated into a build history that forms part of the certification documentation of a product.
The certification process is overseen by an Inspection Engineer (IE), who works with the PE to ensure that the tests are adequate to capture the specification of the component. Development of an inspection procedure is also iterative; when it is complete, the document must be signed by both the PE and the IE, as well as an engineer responsible for configuration control. The typical DCR, having both a part drawing and a testing procedure, has separate signature records for both.
Constructing a DCR in XML
Our current practice is for a DCR to be generated in Microsoft
Word and for the results to be printed. The testing procedure consists
of steps, each of which describes a test process and lists the tools
and instruments needed to carry it out. Each step, which appears as
a row in tabular form, also provides a space to record the results,
which may include pass/fail indicators, direct observations or measurements
from test equipment, and comments or even sketches from the inspector.
Fig. 2 shows sample pages from a typical DCR: a “Picture Page,” a
page of instructions, and a page from the combined certification procedure
and data-recording form.
Figure 2 Fig. 2a. Picture Page from a DCR Fig. 2b. Instruction Page from a DCR Fig. 2c. Procedure Page from a DCR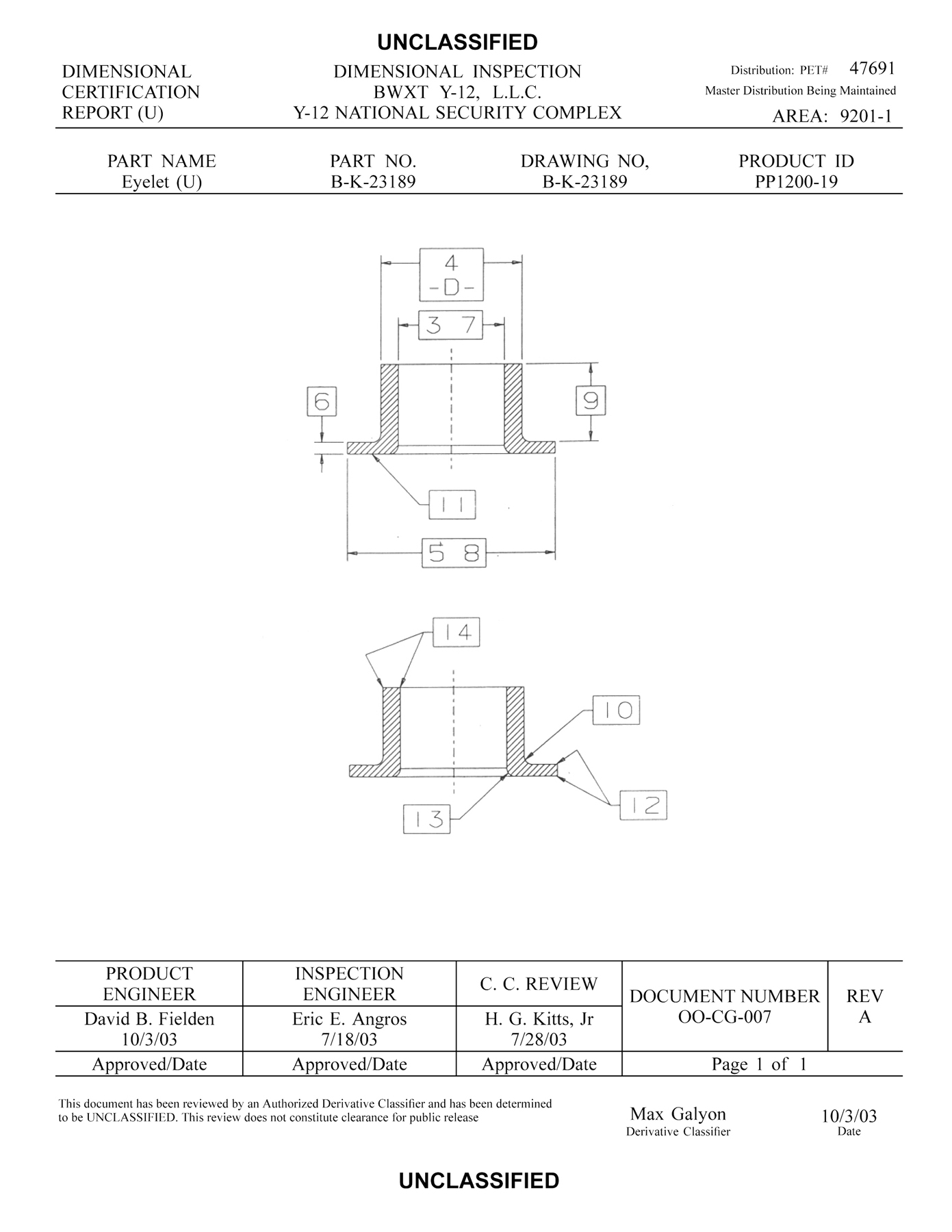

The workflow we envision for a DCR is based on our understanding of the workflow already used in Word. In Fig. 3, the development of a new procedure and its reporting form begins with the IE, guided by the PE, producing an XML document rather than a Word file. The resulting document goes through the conventional review process, ending with approval and the addition of appropriate signatures and other metadata to the XML file. Each dimensional inspection process for a given part requires such an XML template file that will guide the inspection, record the data collected in the inspection, and become the basis for the certification report that accompanies each part.
Figure 3
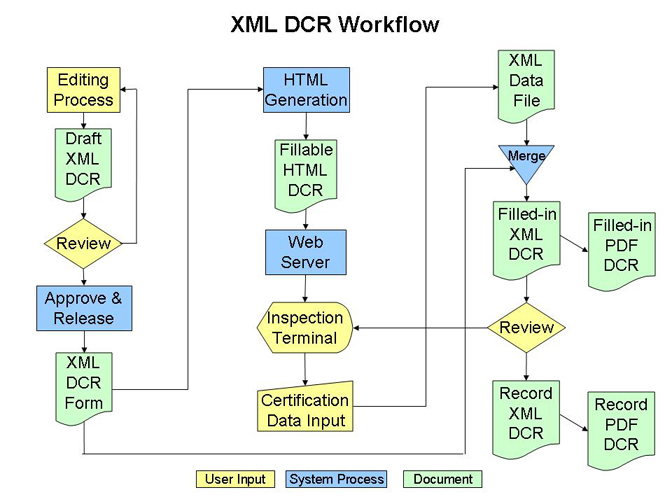
Fig. 3. DCR Workflow
Once the base document is approved, the workflow diverges from past practice, because the information flow forks: The XML document is converted to an HTML (actually JSP) procedure and form for online delivery to the inspector, while a copy of the file is reserved for population with data later in the process. The inspector on the shop floor uses a Web browser to enter data into a new instance of the online form. At the end of the inspection, the data is collected in another XML file that is then merged with the empty copy of the procedure to produce the actual certification report. At that point the completed procedure is audited. If the part is not approved, it is returned to manufacturing for further work, followed by more inspections, until the part is either finally approved for this stage or it is “killed” and its materials perhaps recycled. If the part is approved, based on the data collected, the completed XML report is archived. Our current view is that there will actually be at least three objects archived: the first is the XML data file collected from the online process, the second a merged XML file containing the DCR in the form of the template populated with the collected data, and the third a PDF file of the completed DCR report created by merging the data file with the form. Moreover, until the EBH has been certified as a valid process, the DCR report must be produced in paper. For this reason, as well as for the comfort of our customers, we have taken special care to produce the DCR in a format that closely approximates that of the current Word documents. Using a form that looks like their current form also makes it easier to meet Y-12's conduct-of-operations requirements.
This workflow contains most of the expected components associated with XML-based publishing. Behind the XML documents there are, of course, DTDs. (We use DTDs and not some other form of schema largely for consistency with other local applications.) Conversion to HTML forms and merging data collected online back into the XML record is handled by XSLT. Because we use the Arbortext publishing system, both screen presentation and formatting for PDF are handled by Arbortext's proprietary stylesheets, which are, at least, also XML documents.
When we started on the project, our early goal was to find out whether we could recreate the DCR document in an XML publishing system. Having done the document analysis, written a DTD, and created a stylesheet, we concluded that the basic document was within our capabilities. Then the process expanded into the scripts that create the HTML form pages, collect the data from the forms, and populate a completed XML document. That being done, and a parallel process for the NDT form likewise undertaken, we could have considered our project complete. However, these reporting forms do not exist in a vacuum. The data recorded on a DCR, in particular, does not all come from human observation; it may come from test equipment, though it currently must be entered manually. In many cases the component being tested may also be undergoing a surface contour trace on a CMM, and the CMM is producing a data file. For some years, DOE has been requiring that such data become part of an “Electronic Data Capture” (EDC) record. Heretofore, the EDC file has probably been in a proprietary format or in a record format that does not involve XML. CMM measurements and reports are not entered in or handled as DCRs, and current CMM reports have their own defined paper and electronic formats. CMM paper reports are placed in the build history and electronic versions are saved in the plant EDC system. Now, however, we are beginning to look at the potential for merging data entered by the inspector with EDC data from test gear and creating a complete XML record of the certification process. DCRs are used for many kinds of measurements not performed using CMMs and for which EDC is not currently performed. Future development of an EBH may cause rethinking of the kinds of reports generated, the formats of the data, and the relationship between the reports and the results of EDC.
Building the XML environment for EDC is in only the very earliest investigatory stages. We know that some data, such as series of coordinates from CMMs, could be recorded as simple XML records. Other data, such as signal output from a vibration analyzer, will probably need to remain in binary format. Our challenge, then, will be to create a layered data/metadata environment that will accommodate a variety of test equipment as well as a variety of users and uses for the data over the long life span of the product. We are investigating this environment with other users of such test equipment, most of them outside the NWC. At the innermost layers of the metadata onion, next to the core of data from the test gear, will need to be metadata about the equipment in use, such as the identification of the device and its calibration record. Around that will be layers that describe the specific test environment, such as the time, date, and environmental conditions in the test shop. Another layer will include the identification of the component under test and link the specific test to the record being created in the DCR.
Tracking the Workflow
Much of the problem of assembling an EBH is a result of the need to track both the actual certification data and the metadata about the data-collection process and to keep all of this information in synchronization. Furthermore, the process must continue to support the workflow that has been built up—and certified—around the paper-based process. The layers of configuration management that have accumulated around the PET process are concerned with tracking paper documents. Now we need to embed configuration management into the documents themselves and make them as self-documenting as possible. This seems to suggest that at each stage of processing the document should accumulate additional metadata, so that when the report, which represents the procedure completely populated with certification data, is finished, it is also fully populated with an audit trail of the processes that allowed it to be completed. Thus the metadata will accumulate in layers, one of which captures the traditional PET and audit processes and the others which track the XML environment.
Files, Locations, and Management
In a conventional XML document-management environment, the goal is frequently to get to a final document. In that case, it is the document instance that will be archived. It may be of interest to archive the DTD or other schema if that will help in further interpretation of the document, but for many applications a well-formed document may, as some have argued, be sufficient. If a document, such as a maintenance manual, is revised iteratively, then continued maintenance of its DTD and other supporting structures like stylesheets becomes more significant than in cases where the document is a final product. In our case, however, the entire processing stack becomes a structure subject to audit and thus to archiving. When we face the possibility that a generation from now it will be necessary to verify that an electronic document is what was intended originally, we need not only the document and its graphics but many of the process files that supported them.
The document-management system for our process is not yet established because it will have to be coordinated with other systems outside our current scope. Currently a DCR template is created on a local PC. For the interim, document processing and storage are on a Web server (see below, Table 1). Even after primary storage systems are established, copies of the files will continue to appear on that system. Processing of a new DCR form begins with loading the DTD, template, composition stylesheet, and XSLT stylesheets to the server. The server then establishes links for starting certifications using that template. The inspector can call forth an online form, enter metadata about the part being tested, and walk through the procedure, entering data as required. When the procedure is completed, the results can be saved. The individual certification run can be reopened for further editing, or the results can be composed as a report and sent for auditing and approval.
At the current stage in the development of the process, we are not completely certain of all the items that will be tracked, but our current analysis suggests that we have a complex of items in the stack. Since our analysis is more advanced for the DCR than for the NDT, this list reflects the components required for it.
-
End-user objects
-
Blank Procedures/Forms
Each DCR procedure/form, which represents an individual certification step for a particular component, is represented by this single configuration control item:
-
Form XML file, the template for constructing reports on individual components
-
-
Form Graphics and Supplemental Material
The graphics and supplemental material can be specific to a single form or shared among forms.
The “Picture Page” of a DCR procedure contains at least one reference drawing for the certification process. Such graphics are under configuration control with the related forms:
-
Part graphics and supplemental material
-
Common part graphics and supplemental material
-
Common process graphics and supplemental material
-
Form graphics used to improve form appearance and operation
-
-
In-Process Form Data
In-process form data represent forms that have data entered but have not yet been assigned a disposition. These data must be managed using an iterative model with all iterations saved:
-
XML data file, collected from Web form
-
PDF file showing data entered in original form, displayed for review, auditing, and certification
-
-
Record Data
Forms that are complete become record data and must be stored in a system that complies with records management requirements:
-
XML data file
-
Completed XML DCR with data merged into template
-
PDF file rendering the XML DCR with entered data in original blank form
-
-
-
XML control structures
-
DCR Procedure and Report Form Template
Each type of form is represented by a DTD that controls its structure and data content:
-
DCR XML DTD, which represents all the components of a generic procedure, along with the framework for data collection to create a report and the frameworks for metadata
-
Data-collection DTD, which defines the structure of the data collected online during the execution of the certification process
-
-
-
Supporting software
-
Form Web Page
The Web artifacts are displayed to the end users during the execution of the procedure and the collecting of certification data. Because they are secondary documents generated by software, they may be stored and managed separately from their original sources. End users may interact with pages on the Web server, but they have no interaction with the files as files, any more than they interact with the XSLT or Java source code.
-
Java Server Pages: Web page form displayed on the inspector's browser in the certification shop or laboratory
-
Web page graphics and supplemental material, generally drawn from the graphics associated with the XML form template
-
-
Form Transforms and Style Sheets
These form transforms can be specific to a single form or shared by several forms; in general, they are specific to a single DTD, such as the DCR:
-
XSLT from form XML to JSP
-
XSLT for merging data XML and form XML into a completed report
-
Arbortext style sheet for rendering XML into PDF
-
-
Form Web Page Software
The Web server software can be specific to a single form but more likely will be shared among forms generated from a single DTD:
-
Java Server Faces backing bean that transfers data between the Web page and the data model
-
-
Data File
Data file configuration control items consist of:
-
Data File Model, a software representation of the data file that maps form entries to data file entries
-
-
Another way of looking at the complex of files and programs is to consider what roles the components play and where they appear both during processing and in storage (Table 1).
Table I
DCR form system file types and locations
| File Type | Component file role | File storage locations | |||||
|---|---|---|---|---|---|---|---|
| Form Creation Template | Form Package | Data Package | Content-management System | Web Server | Arbortext Publishing Engine Server | Data Repository | |
| Form DTD | X | X | X | X | X | ||
| Form XML instance | X | X | X | X | |||
| Form graphics instances | X | X | X | X | |||
| Form PDF stylesheet | X | X | X | X | X | ||
| Form PDF | X | X | |||||
| Form-to-JSP XSL transform | X | X | X | X | |||
| Form JSP instance | X | X | |||||
| Data-collection DTD | X | X | X | X | X | ||
| Data-collection XML instance | X | X | X | ||||
| Form-and-data merge XSL transformation | X | X | X | X | X | ||
| Form XML with merged data | X | X | X | ||||
| Completed report with data merged and rendered to PDF | X | X | X | ||||
What Table 1 shows is that, just looking at files and not at the software behind them, we start with a small number of control files, build a form package, and then collect a data package. Source files are to be archived in a content-management system and final results will be passed to a data repository. Almost all the files pass through the Web server, where source XML is rendered into HTML/JSP forms, data is collected through the forms, and results are assembled in XML and PDF. One auxiliary server hosting composition software is called in to manage PDF rendition of XML files. Software source code, such as the backing bean module and DOM-based interpreter of JSP output, will also be managed, probably on a content-management system.
Some files in the system are, in effect, transient and so do not require archiving. The JSP version of a procedure and form is created when an IE creates a new or revised procedure and loads it to the Web server. It is displayed to guide the inspector through the certification process and collect input from the process, but it is not saved with data in place. Creation of a new XML data file from what is entered in the online form is hidden from the user until that data is merged with the XML form template and displayed as a PDF rendition.
Metadata Flow
Because the EBH project builds on legacy processes and incorporates metadata from both the legacy and the new processes, it incorporates a dual flow of metadata.
The XML component of the EBH study began with a pilot project to capture a DCR as an XML document rather than as a Word file. One of the first decisions in the document design was to create specific elements to capture metadata already in the paper-based workflow. So there are individual elements to both information about the component being certified and the engineers involved in developing and approving the certification and reporting procedure. The component itself is identified on the template form by its part number and name. When the certification procedure is executed, the inspector will add to these the lot number and serial number of the part. The Picture Page also includes the governing drawing number. The approvals include elements for the PE, IE, and configuration engineer, along with the dates of their approvals and the PET governing the procedure. There are separate approvals for the Picture Page and the body of the procedure. These elements of the template are simply passed through the entire process to the final certification report unchanged. They are rendered in both HTML and PDF, but appear in the XML version of the report just as they appeared in the template XML created by the IE.
The IE will recognize that the new workflow calls out this legacy metadata as explicit items for input, rather than finding it simply as locations in a Word table to fill in. (We are still developing the user interface to be used in the Arbortext editor.) But beyond that, these items will not be recognized as metadata by users of the process. The information will, for all practical purposes, continue to look as it did in the paper-based process. Because the information is wrapped in XML, however, it will be available to future processes that for the most part have not yet been created.
<DCRbody>
<DCRInformation>
<DCRHeader>
<DCRPET>47691</DCRPET>
<DCRArea>9201-1</DCRArea>
<DCRtitleblock>
<DCRPartName>Eyelet</DCRPartName>
<DCRPartNumber>B-K-23189</DCRPartNumber>
<DCRDrawingNumber>B-K-23189</DCRDrawingNumber>
<DCRDrawingRev>L</DCRDrawingRev>
<DCRProductID>PP1200-19</DCRProductID>
<DCRLotNumber>120019xxxx</DCRLotNumber>
</DCRtitleblock>
</DCRHeader>
<DCRFooter1>
<DCRdisposition>
<Disposition>pending</Disposition>
<DispositionedBy>mxm</DispositionedBy>
<InspectionDate>
<date>200801281628</date>
</InspectionDate>
</DCRdisposition>
</DCRFooter1>
<DCRFooter2>
<DCRApproval>
<DCRPEapproval>
<ProductEngineer>David B. Engineer</ProductEngineer>
<date>10/2/03</date>
</DCRPEapproval>
<DCRIEapproval>
<InspectionEngineer>Eric E. Inspectionguru </InspectionEngineer>
<date>10/1/03</date>
</DCRIEapproval>
<DCRCCapproval>
<CCReview>I. M. Incontrol</CCReview>
<date>10/2/03</date>
</DCRCCapproval>
<DCRDocumentNumber>OO-CG-007</DCRDocumentNumber>
<DCRRevision>B</DCRRevision>
</DCRApproval>
</DCRFooter2>There is a similar block of data for the Picture Page. The information collected in this metadata appears in the PDF rendition of the DCR in the blocks at the top and bottom of the Picture Page and the first page of the DCR body (Figs. 2a and 2b).
As we have created a workflow that processes the DCR template, we have added the other metadata in ways that are transparent to the user. It is not necessary even to display this information, since it is not expected on the paper forms we are emulating. Nonetheless, we are currently appending it to the merged DCR and rendering it in the PDF output, largely as a convenience to ourselves in testing. This metadata falls into two categories: information about the version of the process and information tracking the application of the process.
Information about the process begins with the versions of the DTDs and XSLT stylesheets employed.
In the case of the DTDs, version information begins as a parameter entity and is carried by an attribute of the document element. As a result, the DCR procedure created by an IE carries its version data, and this is in turn recorded in the merged DCRs that result from execution of the procedure.
<DCR doc_class_level="U" DTD_version="0.9" status="draft">
The corresponding version data about the data-collection DTD similarly appears in the XML data generated by the online process. In the merged DCR, this latter version data can be copied by the XSLT into the metadata section appended to the original DCR.
Version information about the XSLT begins as variables in the stylesheets, and this is written by the transforms into “meta” elements in the HTML/JSP files and attributes on the metadata appendix of the merged XML DCR. Because the HTML/JSP files are transient generated objects and not archival artifacts, their metadata is less important than that of the XML files. Nonetheless, we have the information available in case we need it. We do write the name of the Web form into the data-collection file and copy that into the DCR.
In addition to version information, we also capture data about each “inspection event.” In traditional processing, each inspection of a part is a unique event. If the part passes the inspection (or is granted a “deviation” waiver from some portion of the specification being tested), a report is completed and sent to auditing. If the part fails, it is either “killed” or sent for rework, and the form being completed is discarded without becoming a report. Because the overall process for electronic histories is still in early phases of investigation, we have not constrained ourselves to this model. Instead, our process allows for checkpointing a version of the collected data and reopening the form for revision, starting with the saved inspection data. Even if the future workflow continues the current model of each inspection being unique, the ability to reopen a file allows the inspector or auditor to correct errors in data entry. In any event, we record data from each time the file is opened, including the person opening the file, a timestamp, and the disposition of the inspection (whether the part has been accepted or has failed). This data, together with other metadata from the process flow, is accumulated in the “Inspection Record” appended to the DCR.
<LotInspection>
<InspectionData>
<FormID formNumber="OO-CG-007" formRevision="A" formType="DCR"/>
<InspectionID iteration="1" lotNumber="1200-19-0000"
number="4" time="2008-01-10 07:17:24.015-0500" user="george"/>
<FormPage>pp1200-19.jspx</FormPage>
</InspectionData>
<InspectionHistory>
<InspectionEvent iteration="1" lotNumber="1200-19-0000"
number="1" time="2008-01-10 07:17:24.015-0500" user="george"/>
<InspectionEvent iteration="1" lotNumber="1200-19-0000"
number="2" time="2008-01-10 07:17:24.015-0500" user="george"/>
<InspectionEvent iteration="1" lotNumber="1200-19-0000"
number="3" time="2008-01-10 07:17:24.015-0500" user="george"/>
<InspectionEvent iteration="1" lotNumber="1200-19-0000"
number="4" time="2008-01-10 07:17:24.015-0500" user="george"/>
</InspectionHistory>
<LotNumber>1200-19-0000</LotNumber>
<InspectionDisposition state="pending" time="200801281628" user="jake"/>
</LotInspection>The result of this metadata flow is flexible: a completed DCR
contains a history of its creation, and all the metadata, whether
from the old or new workflows, can be printed and is accessible to
further XML processing. Information flows from both the traditional
approval system and all the steps in online processing, being accumulated
in a merged XML file and rendered in PDF for paper records (Fig. 4).
Figure 4 Fig. 4. Information Flow in document processing. Figure 5 Fig. 5. An Onion of Documents and Metadata: a part certified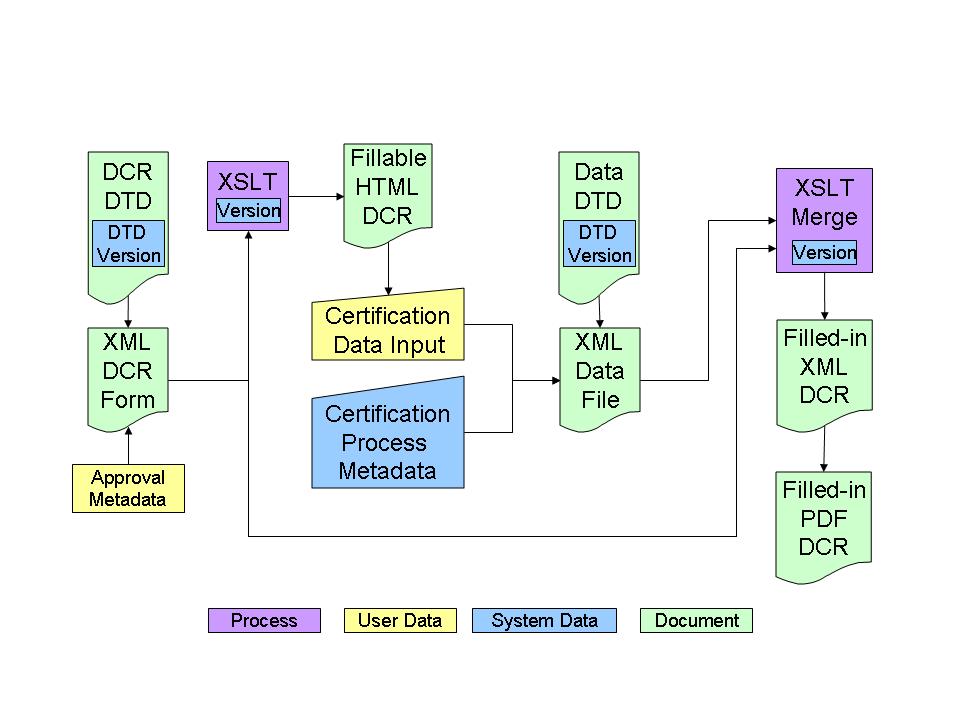

The NDT Report is a much simpler document than the DCR. It is usually a single page with form metadata at the top and bottom. Onto this form several different kinds of body can be put for a variety of tests, such as visual inspection of welds, tests with fluorescent dyes to reveal cracks, and X-rays. The body information is generally simple, to capture the identifiers of the parts being tested and whether the parts pass or fail the test. The general workflow mirrors that for the DCR, though there is less collecting of approval metadata. The flow of metadata through the processing system is nonetheless similar to that for the DCR.
Workflows to Come
The DCR and NDT are only two of many tests done in the overall certification process for Y-12's products. Materials may be sent for chemical, isotopic, and metallographic tests. Large assemblies undergo extensive X-ray analysis. (We have just installed a 9–MeV linear accelerator for examination of large structures.) DOE has mandated that many tests perform “electronic data capture” (EDC), though what that means is in some cases still evolving. In the case of radiography, we are being pushed to new electronic technology simply because of the dwindling supply of suitable X-ray film. Early EDC was done in stand-alone processes, with data captured in conventional databases. Essentially all machine-measured data is now collected in a central plant electronic data collection system. The proposed data packaging project will look at storing these data in XML-based packages. After years of hesitancy, there is a growing awareness that XML will probably turn out to be a way of binding together all the disparate processes and collections of data in the certification of our processes.
We are just now beginning to look at the problems of aligning the metadata about XML documents and processes with actual metadata about test conditions and pointers to test data from instruments. We are looking at HDF (Hierarchical Data Format, http://www.hdfgroup.org/why_hdf/index.html) as a means for managing instrument data, and we are looking at extracting HDF metadata into XML.
This project is still in an early state. We have created XML applications for both DCR and NDT, but the planning for the metadata is incomplete, particularly metadata about test results. We are just beginning to move the applications into the hands of the end users. By the time of the Balisage conference, however, we expect to have moved our environment from the test system to one that will be available in a few actual production areas. At that point, we shall begin working with IEs to create pilot inspection forms to be used in parallel with paper processing early in the coming fiscal year. If this project is successful, we shall expand it to more certification and report types, and we hope to move towards fully electronic records of Y-12's products.
References
[Mason 1997] Mason, James David. “SGML Metadata for Nuclear Weapons Information,” presented at SGML 1997, Washington, DC, December 8, 1997.