Sperberg-McQueen, C. M. “Representing concurrent document structures using Trojan Horse markup.” Presented at Balisage: The Markup Conference 2018, Washington, DC, July 31 - August 3, 2018. In Proceedings of Balisage: The Markup Conference 2018. Balisage Series on Markup Technologies, vol. 21 (2018). https://doi.org/10.4242/BalisageVol21.Sperberg-McQueen01.
Balisage: The Markup Conference 2018 July 31 - August 3, 2018
Balisage Paper: Representing concurrent document structures using Trojan Horse markup
C. M. Sperberg-McQueen
Founder and principal
Black Mesa Technologies LLC
C. M. Sperberg-McQueen is the founder and principal of
Black Mesa Technologies, a consultancy specializing in helping
memory institutions improve the long term preservation of and
access to the information for which they are
responsible.
He served as editor in chief of the TEI Guidelines from
1988 to 2000, and has also served as co-editor of the World
Wide Web Consortium's XML 1.0 and XML Schema 1.1
specifications.
The need for markup to handle multiple concurrent document
structures has been clear at least since SGML introduced the
CONCUR feature to support such markup. Few SGML users found
the use of CONCUR necessary, few products ever supported it,
and the designers of XML dropped it as an unnecessary
complication. But those who need concurrent markup really
need it. Fortunately, the functionality of CONCUR can be
recreated more or less successfully in XML: one document
structure can use conventional XML, while others use
Trojan-Horse markup (DeRose 2004). Rabbit/duck grammars can
be used to validate the document and to guide the creation of
conventional schemas for use in editing tools.
The project Annotated Turki Manuscripts from the
Jarring Collection Online (ATMO) is digitizing a number
of Central Asian manuscripts collected in the first half of the
twentieth century by the Swedish ethnographer and Turkic
philologist Gunnar Jarring.[1]
A number of previously undigitized documents have been scanned,
and the project has put digital facsimiles of them
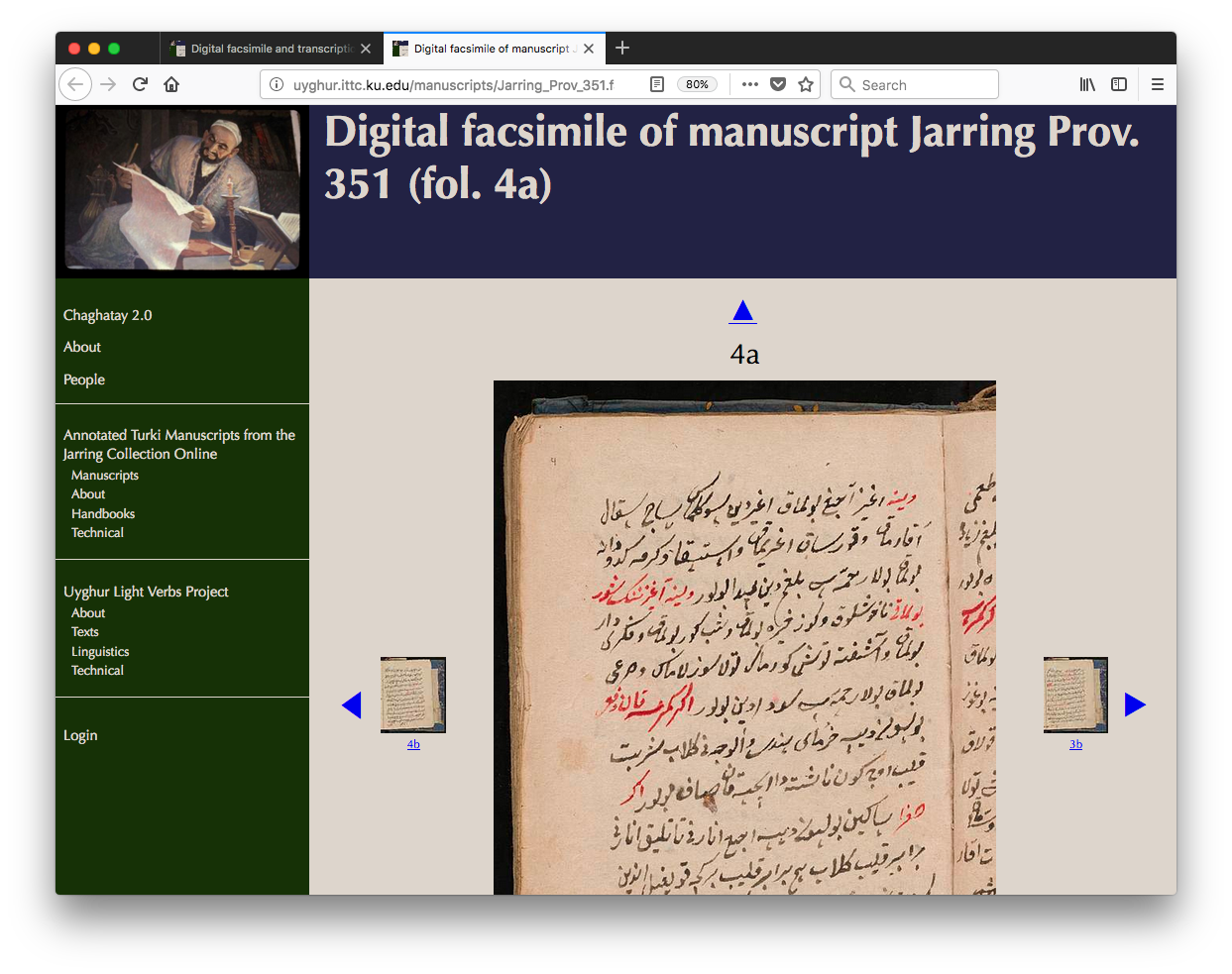
online. One is shown in Figure 1.
Figure 1: Digital facsimile
One page of a digital facsimile from the ATMO
project (Jarring Prov. 351, fol. 4a).
Further, the project is transcribing as many newly scanned
manuscripts as resources allow, and a number of transcriptions
are also available on the project's site. For as many of the
transcribed manuscripts as we can manage, the project is also
translating and providing word-by-word (or to be more precise,
morpheme-by-morpheme) linguistic annotation.
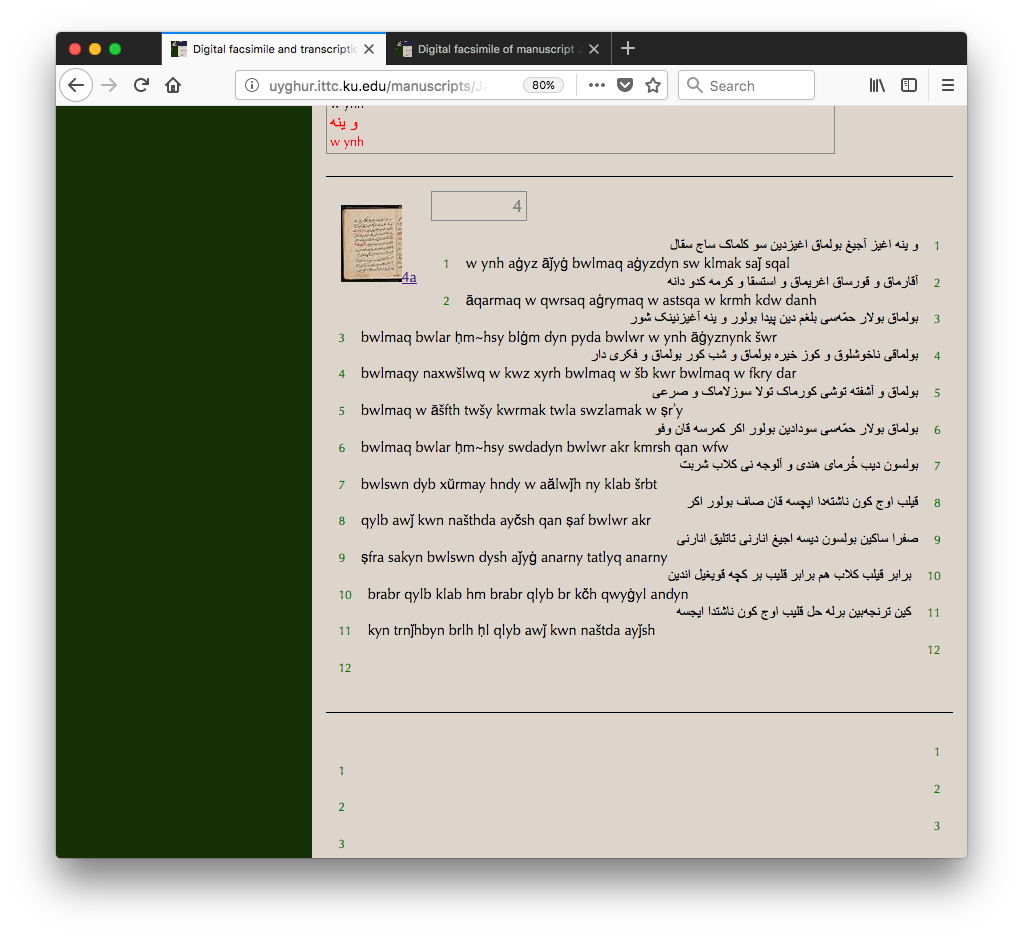
In order to simplify both the creation of the literatim
transcripts and their later comparison with the scanned images of
the originals, the transcriptions use the markup defined by the
Text Encoding Initiative (TEI P5) for close
transcriptions of physical sources, with elements for writing
surfaces (here mostly pages), zones (regions of the surface used
for writing), and lines. A line by line transcription of the
page shown in Figure 1 is shown in Figure 2.
Figure 2: Literatim transcript
Portion of line by line transcription from the
ATMO project (Jarring Prov. 351, fol. 4a). For the
convenience of some readers, a transliteration into Latin
characters with diacritics is shown as well as the original
Perso-Arabic script.
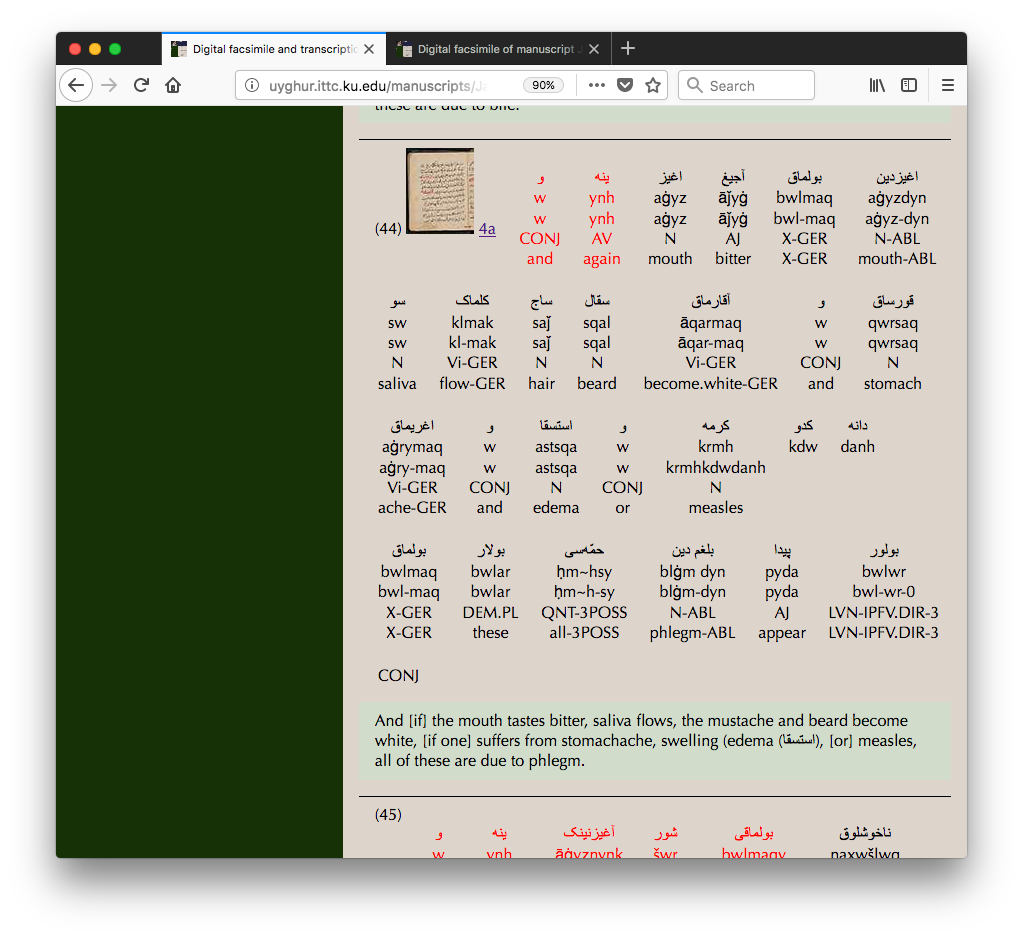
The linguistic annotation, however, is based on the linguistic
structure of the texts and requires elements for sentences (or
sentence-like units), words, and morphemes. As may be seen in
Figure 3, the text is displayed sentence by
sentence, with Latin transliteration, segmentation into
morphemes, part of speech for each morpheme, and interlinear
gloss for each morpheme shown immediately below each word, and a
prose gloss for the entire sentence shown below the sentence,
followed by any notes applicable to the sentence.
Figure 3: Linguistic annotation
Portion of a linguistically annotated text from
the ATMO project (Sentence 44 of Jarring Prov. 351). The
material in red is written in red ink in the manuscript. Note
that because most of the material is in Latin script, words
are displayed left to right, not right to
left.
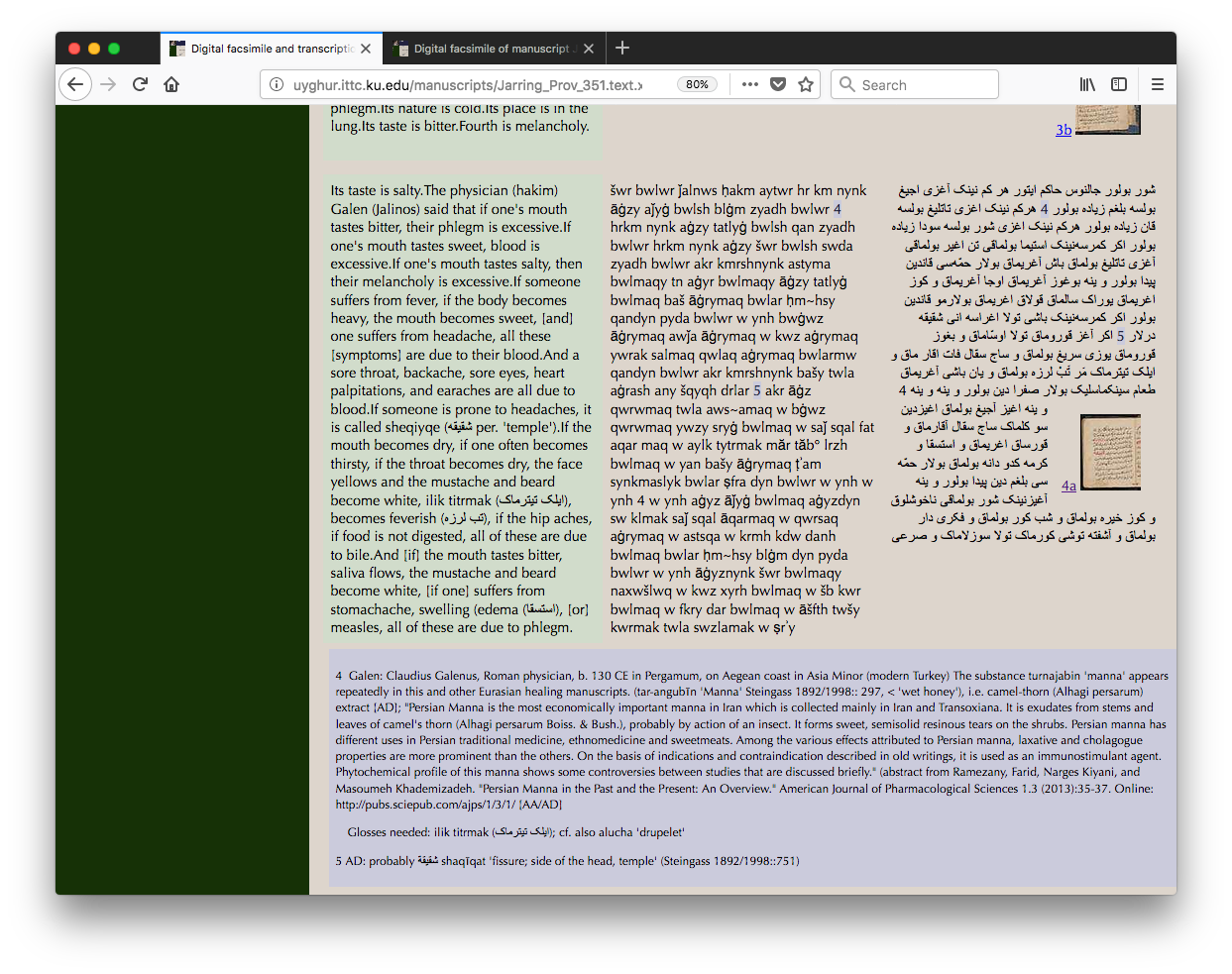
A display of the material oriented to speakers of
Uyghur or to area specialists with non-linguistic interests
(e.g. historians of religion or folklore) will require (or at least
benefit from) markup for a third set of textual structures, with
elements for texts (some manuscripts contain anthologies of
multiple texts), headings, paragraphs, verse stanzas, verse lines,
etc. Figure 4 shows a sample text-oriented
display, with the original Perso-Arabic script on the right,
the English sentence-by-sentence translation on the left, and
the Latin transliteration between the two.
Figure 4: Reading text
Portion of a bilingual text display from
the ATMO project (part of Jarring Prov. 351). As in the
linguistic analysis, the English gloss is shown on a green
background and notes on a blue background.
No two of these views nest neatly with each other.
The ATMO project thus exhibits in a particularly
straightforward and striking form the problem of
overlapping hierarchies which the SGML and XML
communities have been discussing since the 1980s.[2]
This paper first describes the specific requirements to be met
by the markup for the ATMO project; the following sections
describe how the project is going about meeting those
requirements. Sections are devoted to the abstract structure
assumed for documents, the serialization forms used to
represent that structure in XML, and the mechanisms employed
for well-formedness checking and (very briefly) validation;
these are all based on those of XML, but require some
description of the application conventions employed and how
they deal with multiplicity of document structures.
The paper concludes with some indications of further work
to be done and/or to be reported on in other papers.
Requirements
For transcription (and for the presentation of transcripts for
those interested in the physical organization of the
manuscript), the ATMO project uses markup whose elements
identify important units in the topography of the manuscript
exemplar: pages, regions on the page (header area including
folio numbers and page numbers, right margin, main writing area,
left margin, footer including catch-words), lines, and
highlighted areas within the lines. For tabular material,
extensive use is made of TEI's rend attribute, to
allow the display stylesheets to approximate the layout of the
exemplar.[3]
For linguistic annotation and for presentation of
annotated material for readers with linguistic interests, a
close reproduction of the physical organization of the
manuscript is not helpful; the key units of organization are
sentences, words, and morphemes. Like many documentary
linguistic projects, ATMO segments words to identify
inflectional (but not derivational) morphemes and annotates each
segment.
For presentation of the texts in regularized spelling and
for readers interested primarily in the cultural, ethnographic,
anthropological, religious, or historical import of the
material, neither the close reproduction of the physical
organization of the manuscript nor an exclusive focus on
sentences would be helpful; the kind of logical
structure typically captured in document-oriented SGML
and XML vocabularies is more useful: texts or works, paragraphs
or other blocks, phrases of various kinds should be
identified.
In prose, where sentences normally nest within paragraphs
or similar units, the text-oriented and
sentence-oriented structures are often compatible and can be
combined in a single tree structure. In verse, however, the two
structures do not nest.
It may be noted in passing that in the ATMO project these
three structures compete with or overlay each other only in the
main part of the document; the TEI header will be the same in
all views. In XML terms, the competing structures all occur
only within a container element; in the
case of ATMO the container is the tei:text or
tei:sourceDoc element. Within the container, again
some elements may be common to all structures.
From these observations several requirements arise, which
in turn entail or suggest others:
Any of the three structures (which I will call page,
sentence, and paragraph) should be visible and processable
when needed.
Because we do not have the resources needed to re-create
the XML software stack from the ground up, a second
requirement is that if possible, all document representations
used in the project should be XML.
Taken together, the two requirements just mentioned
seem to suggest that we use XML representations in which one
of the structures (I'll call it the dominant structure) is represented
more or less conventionally, representing each structural
unit of the dominant structure with one XML element (and
vice versa), and the other two structures (the recessive structures) are represented
in some other way (with milestone elements, fragmentations,
stand-off markup, or some other technique).
Terminological note: for brevity, I will sometimes refer
to elements or nodes appearing in a recessive structure as
recessive elements, and to the markup
delimiting such elements as recessive
markup, and similarly for dominant
elements and dominant
markup.
We meet this requirement using Trojan-Horse markup
(DeRose 2004) for the recessive
structures.
Because we do not wish to privilege any one structure by
making it permanently dominant, we would like to be able to
view and process any document with any of the three structures
as the dominant one.
Because we do not wish to have to perform triple
maintenance on documents, we do not want to have three
parallel static representations for each document which must
be maintained in parallel; instead, we want to be able to
translate from any of the three forms to either of the other
two (changing from one dominant structure to another),
without information loss.[4]
We meet this requirement with XSLT transformations which
accept a document with one dominant and any number of
recessive structures and write out an equivalent document with
a dominant structure identified by a run-time
parameter.[5]
Because each of the three structures is reasonably
simple and well understood, we would like to be able to
validate the markup for each structure using a conventional
grammar-based schema language.
We meet this requirement by translating a set of
document grammars defining the individual views into a set of
related schemas (one for each dominant structure).
Because most of the uses we imagine for the project's
data involve one or the other of these views, but not more
than one, it is probably not an absolute requirement, for the
ATMO project, that multiple structures be visible and
processable at the same time. But neither is it an absolute
requirement that recessive structures be invisible to
processing: A requirement to see all structures at once can
in principle easily arise whenever multiple structures are
of interest: all it takes is beginning to wonder whether any
two structures are completely orthogonal to each other or
not. So we would tentatively like if possible both to be
able to perform tasks that require taking more than one
hierarchical structure into account and to completely ignore
the recessive structures.
We believe we have met this requirement but do not
have space to demonstrate how; we hope to report on
processing techniques for concurrent documents in later
work.
Related work
A full account of the last thirty years' work on
non-hierarchical document structures would require more space
and time than are currently available; there are reasonably
good surveys of older literature in DeRose 2004
and Witt 2004.
The possibility of marking up multiple concurrent document
structures was built into ISO 8879:1986. The
potential use of CONCUR in a digital-humanities context was
discussed by Sperberg-McQueen / Huitfeldt 1999. The work described here
resembles the CONCUR feature of SGML in describing multiple
trees over the same sequence of text nodes; it differs in
guaranteeing that recessive structures are visible even to
software processing the dominant structure. (ISO 8879 can be
read as allowing or requiring only the dominant structure to be
visible; see Barnard et al. 1988.)
In the early years of the century, Patrick Durusau and
Matthew Brook O'Donnell brought forward a series of proposals
for dealing with multiple hierarchies in an XML context.
Bottom up virtual hierarchies (Durusau / O'Donnell 2001) are represented by
dividing a document into atomic pieces none of which spans any
element boundaries in any concurrent structure, and supplying an
XPath expression for each atom and each hierarchy, indicating
the position of the atom in that hierarchy (e.g. /pages
/page[1][@id='p1'] /line[2][@id="l2"] /w[1] to indicate
the first word on the second line of the first page and (for the
same word) /text /para[1][@id='p1'] /w[16] to
indicate that it is the sixteenth word of the first paragraph of
the text. This representation makes possible certain kinds of
cross-hierarchy searches, but the notation is verbose and
it is not completely trivial to reconstruct a conventional XML
representation for any of the hierarchies, nor to detect errors
in the XPath expressions.
Just-in-time trees (Durusau / O'Donnell 2002a,
Durusau / O'Donnell 2002b) are represented
with a kind of tag-salad of XML tags used without regard to
XML's nesting constraints; a specialized scanner can read the
document under the control of a document grammar, identify
the tags relevant to that grammar, and pass them to a
SAX-based validator as start- and end-tag events; other
tags can be suppressed or treated as character data.[6]
This technique allows multiple hierarchies to be marked up in a
single source, but the fact that the document in its raw form is
not well-formed and requires a special-purpose parsing setup
makes it awkward. In later work (Durusau / O'Donnell 2003, Durusau / O'Donnell 2004), Durusau and
O'Donnell's examples show the use of well-formed XML input using
a form of Trojan Horse markup (on which see below), and return
to the idea of annotating each atomic piece of the document with
information on its structural locations, with sample table
structures that could be managed in any relational database
system. This final form of Durusau and O'Donnell's work is very
similar to that proposed here, as regards the serialization of
the document (especially to the shallow form
described below [section “All-recessive form”]). There are
differences in processing and philosophical viewpoint. Durusau
and O'Donnell propose search mechanisms based on relational
databases rather than XQuery (not then completed), and they
argue that it is best to regard hierarchical structures as
things imposed on documents during processing and not intrinsic
to the documents. In contrast, the work reported here starts
from the belief that the multiple hierarchies are immanent in
the document and made explicit by markup, not imposed
externally.
Trojan Horse markup was described by DeRose 2004, generalizing and improving on the idea
of using empty elements to mark boundaries for logical units
which do not fit into the dominant hierarchy (for which see
i.a. Barnard et al. 1995 and the TEI). The work
described here differs in using Trojan Horse markup not for
single logical units which do not fit the dominant hierarchy,
but for a complete recessive structure. The attributes used for
coreference are also placed in a th namespace to
eliminate the risk of conflict with user-defined
attributes.
Wendell Piez has described using XML infrastructure for
processing non-hierarchical (LMNL) data (Piez 2012, Piez 2014); our work
resembles his in exploiting the XML software ecology. The data
model used here, however, is not LMNL but concurrent trees, and
it is defined in terms of XML and XDM representations.
Document structure
ISO 8879 introduced the notion that a markup language can
not only be defined as a set of character sequences but can also
be associated naturally both with an abstract data type which
represents the structure of the marked up document and with a
mechanism for validating marked up documents. The following
sections follow this pattern in describing explicitly the abstract
data type for document structure, the serial form, and the
mechanisms for well-formedness checking for the markup used by the
ATMO project. It is hoped that later work will have space for
fuller discussion of validation against schemas and the challenges
of processing data with concurrent structures.
CONCUR has sometimes been described (by the current author
and by others) as involving multiple element trees drawn over
the same frontier of text nodes, comments, and processing
instructions. This is a reasonable first approximation, but in
fact the data structure implied by ISO 8879 is slightly more
complicated: when CONCUR is used, it is not guaranteed or
required that each document type have exactly the same character
data.[7] There are two sources of variation. First, SGML's
rules for record-end suppression depend crucially on the
relative location of the record-end in question and the nearest
markup. Since in a document marked up with CONCUR, some markup
is applicable to (visible in) only one document type; record
ends affected by that markup will be suppressed in that document
type and visible in others. Second, there is no requirement
that a given general entity name be given the same declaration
in different document types; if the replacement text for entity
E differs in different DTDs,
then the concurrent trees will have different frontiers at any
point where entity E is
referred to.
It would thus be more precise to say that concurrent
markup describes multiple element trees over a frontier of text
nodes, comments, and processing instructions which is shared
in whole or in part. In any one
tree, all leaf nodes (indeed, all nodes, if we assume an
XDM-like data model) are totally ordered, and any leaf nodes
shared among trees have the same relative ordering in all trees.
(I.e., if N1 and N2 are present both in document type
X and in document type
Y, and N1 << N2 in X,
then N1 << N2 in Y.)
It is not obvious at first glance that the ATMO project
needs to allow different structures to cover different sets of
leaf nodes; we defined the abstract model as allowing that
possibility just in case that requirement showed up in later
work. It did: when words are broken across line breaks, and
even more obviously when broken across page breaks (so that the
first part of the word and its ending may be separated by a
catchword, a page number, a folio number, and other material in
the top margin of the new page), the page view requires that
each word fragment appear on the page where it is written in the
manuscript, while the text and sentence views need the word to
appear as an undivided whole. Annotations applicable only to a
single view of the document would also be a use case for
different views having slightly different character-data
content.
Variations in whitespace, on the other hand, we hope to
succeed in ignoring permanently.
Sharing of internal nodes (elements)
ISO 8879 can (as already noted above) be read as allowing an
SGML processor to make just one of the available document types
available for processing; it can also be read as allowing a
processor to make multiple document types available. Since 8879
does not constrain the interface offered by an SGML parser to its
consumer (or even require that there be such an interface —
the standard does not require that an SGML application be
divisible into an SGML parser and a
consumer), it is unspecified whether markup shared between
document types is treated by the interface as being the
same in all applicable document types or not. It is
similarly unspecified whether the nodes that might appear in a
data structure representing the document are shared between
document types or not.
For purposes of the ATMO project, we do want some nodes to
be shared across views: we wish to regard elements representing
individual texts (in a manuscript which contains several
distinct texts), paragraphs, headings, tables, and notes as
occurring in all views: the text and sentence views should not
have distinct but similar sets of paragraphs, but the same set of paragraphs. (Of course, such
identity of elements across views is not readily detectable by
inspection of the markup or by validation; node identity arises
as an issue only in the context of processing with the XDM or
some other object model. And even there, there is no way at the
XDM level to express the identity of elements across different
XDM documents representing different views of the manuscript: no
XDM node occurs in more than one document.
Illustration of concurrent trees with shared elements
An example may be helpful as an illustration of the data
model. Consider the following haiku by Bashō as translated
by Harold G. Henderson (Henderson 1958, p. 48), marked up
with its metrical structure (line group, line):
<text xmlns="http://www.tei-c.org/ns/1.0">
<body xml:id="body">
<head xml:id="h1">The Village Without Bells</head>
<lg xml:id="lg1">
<l xml:id="L1">A village where they ring</l>
<l xml:id="L2">no bells! — Oh, what do they do</l>
<l xml:id="L3">at dusk in spring?</l>
</lg>
</body>
</text>
If instead we mark up the sentences, we will have something
like this:
<text xmlns:tei="http://www.tei-c.org/ns/1.0">
<body xml:id="body">
<head xml:id="h1">The Village Without Bells</head>
<ab xml:id="ab1">
<s xml:id="s1">A village where they ring no bells! — </s>
<s xml:id="s2">Oh, what do they do at dusk in spring?</s>
</ab>
</body>
</text>
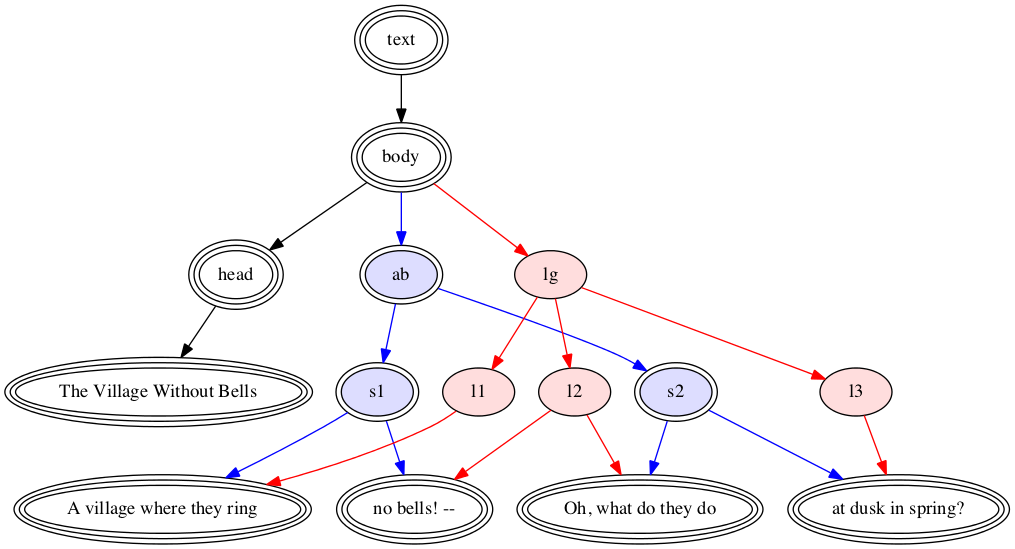
The metrical and the sentence structures of the document
relate to each other as shown in Figure 5 below.
Figure 5: Two concurrent structures
Circle-and-arrow diagram showing the metrical and sentence
structures of the Basho haiku.
Nodes in the metrical structure have single ovals and are shaded
pink, those in the sentence structure have two and are shaded
blue, and nodes appearing in both structures have three (and are
unshaded).
Mutual visibility of different views
ISO 8879 seems clearly to expect that even if multiple
document types are processed at the same time, any nodes not
shared (and the tags which mark their boundaries) will be
visible only in the document types to which they belong.
Concretely, this means that in the example given above, the
nodes for tei:body and tei:head are
shared between the sentence and meter structures, and the
boundary markers for the end of sentence 1 and the beginning of
sentence 2 are not children of the tei:l element
for line 2. That is a convenient arrangement for many kinds of
processing, but it is also sometimes convenient for a process to
know not only about one dominant view but also about the other
recessive views of the document as well.
For the ATMO project, the initial expectation was that we
would prefer that each view know nothing about the others, so
that any tags relevant only for recessive views would be
invisible, as would any text nodes not part of the dominant
view. As will be seen below, however, the XML representation we
have chosen entails the opposite: all text nodes and all tags
are visible whether they are dominant or recessive. Once we got
over the embarrassment of having failed to implement the
intended design fully, however, experience taught us that this
is often helpful in ways not anticipated at first. In the web
display of any view, for example, the recessive markup can be
used to provide hyperlinks to alternative views of the location
being displayed; this would be much less convenient if recessive
markup were invisible. Nor does the presence of recessive
markup typically present any serious convenience: if it did, we
could write general-purpose filters to strip out recessive
markup from a document before processing it, but in practice it
has proven to be just as simple for the process to have its own
code to ignore explicitly those recessive tags it is not
interested in.
Serial form
The serial form of the project's documents is XML, in which
one dominant hierarchical
structure is represented by XML elements in the straightforward
conventional way (one XML element per node in the logical
structure) and other recessive
structures are represented by Trojan Horse elements, using
essentially the notation proposed by DeRose 2004
and used in OSIS (Durusau 2005).
Trojan Horse markup
Trojan Horse markup is a systematic application of an idea that
was current in markup folklore no later than the 1980s and
instantiated by a number of element types defined in the TEI
Guidelines.[8] The TEI, for example, defines empty elements to
mark boundaries of specific kinds: pb,
cb, and lb mark page, column, and line
breaks, and the more general milestone element
marks boundaries of arbitrary kinds. These elements are
designed for marking boundaries in a complete tesselation of the
data (when a page break occurs, one page ends and another
begins); they do not provide clean methods of marking the start
and end of a region which is not immediately preceded and
succeeded by other regions of the same kind. Nor do they have
good ways of providing values for all the attributes which could
appear on the logical element being represented. Like the
element types just mentioned, Trojan Horse markup uses empty
elements to mark the start and end of regions which cannot be
represented as XML content elements, but does not define special
element types for the purpose. Instead, it uses empty instances
of the normal element type for the kind of textual feature being
recorded, and marks them as special by using the attributes
sID and eID to signal that the empty
element in question marks the start or the end of a virtual
element rather than a content element. Matching start- and
end-markers will have the same value for these attributes, which
allows reliable identification of pairs.
OSIS defines twelve element types as
milestoneable (representable using Trojan Horse
markup). It uses the mechanism, for example, to represent
verses which cross paragraph boundaries:
<p> ...
<verse sID="Esth.2.8" osisID="Esth.2.8"/>
When the king ordered the search for beautiful women,
many were taken to the king's palace in Susa, and Esther
was one of them.
</p>
<p>Hegai was put in charge of all the women,
<verse eID="Esth.2.8"/>
<verse sID="Esth.2.9" osisID="Esth.2.9"/>
and from the first day, Esther was his favorite. He began
her beauty treatments at once. He also gave her plenty
of food and seven special maids from the king's palace,
and they had the best rooms.
<verse eID="Esth.2.9"/>
</p>
We make several small changes to the notation described by
DeRose and used in OSIS:
We place the sID and
eID attributes in a namespace (here conventionally
bound to the prefix th).
We add a soleID attribute for use
on empty recessive elements which we wish to represent
with sole tags rather than start/end pairs.
We add an attribute named th:doc to each
Trojan-Horse empty element, which contains a set of tokens
identifying the structures of which the virtual element is
part (in the ATMO project, we use the abbreviations P, T,
and S for the page, text, and sentence views). The
th:doc attribute simplifies the XSLT transform
to change dominant hierarchies. Any elements with more than
one name in the value of their th:doc attribute
are logically shared across those document types.
It should be noted that other XML-based serializations are
also possible (and many appear to have been invented more or less
ad hoc). The Trojan-Horse empty elements can be replaced by
elements in the Trojan Horse namespace named
th:start, th:end, and
th:sole, or by processing instructions with the
target th (i.e. Trojan Horse). These have the
advantage that they require little or no change (respectively) to
any pre-existing schemas for the various hierarchies. They have
the disadvantage that to eyes accustomed to scanning conventional
XML, they are less legible. As Derose pointed out when introducing
the notation, The advantage that (unlike generic
milestones) Trojan milestones look like element tags (that is,
they have the same GI) should not be underestimated (DeRose 2004).
In what follows, I refer to Trojan Horse elements which
mark the start of an element in a recessive structure as
start-markers, those which mark
the end of an element in a recessive structure as end-markers, and elements so marked as
logical or virtual elements. Elements
conventionally marked up with XML start- and end-tags I will
refer to as content elements
(even if in some particular cases they are empty).
Illustration
Using Trojan Horse markup, we can represent both the
metrical structure and the sentence structure in the example shown
above. When the metrical structure is dominant, the document
might look like this:[9]
<text xmlns:tei="http://www.tei-c.org/ns/1.0"
xmlns:th="http://www.blackmesatech.com/2017/nss/trojan-horse"
th:doc="meter sentence">
<body th:doc="meter sentence" xml:id="body">
<head th:doc="meter sentence" xml:id="h1"
>The Village Without Bells </head>
<lg th:doc="meter" xml:id="lg1">
<ab th:doc="sentence" th:sID="ab1" xml:id="ab1"/>
<l th:doc="meter" xml:id="L1">
<s th:doc="sentence" th:sID="s1" xml:id="s1"/>
A village where they ring
</l>
<l th:doc="meter" xml:id="L2">
no bells! —
<s th:doc="sentence" th:eID="s1"/>
<s th:doc="sentence" th:sID="s2" xml:id="s2"/>
Oh, what do they do
</l>
<l th:doc="meter" xml:id="L3">
at dusk in spring?
</l>
</lg>
<s th:doc="sentence" th:eID="s2"/>
<ab th:doc="sentence" th:eID="ab1"/>
</body>
</text>
When the sentence-structure is dominant:
<text xmlns:tei="http://www.tei-c.org/ns/1.0"
xmlns:th="http://www.blackmesatech.com/2017/nss/trojan-horse"
th:doc="meter sentence">
<body th:doc="meter sentence" xml:id="body">
<head th:doc="meter sentence" xml:id="h1"
>The Village Without Bells </head>
<lg th:doc="meter" th:sID="lg1" xml:id="lg1"/>
<ab th:doc="sentence" xml:id="ab1">
<l th:doc="meter" th:sID="L1" xml:id="L1"/>
<s th:doc="sentence" xml:id="s1">
A village where they ring
<l th:doc="meter" th:eID="L1"/>
<l th:doc="meter" th:sID="L2" xml:id="L2"/>
no bells! —
</s>
<s th:doc="sentence" xml:id="s2">
Oh, what do they do
<l th:doc="meter" th:eID="L2"/>
<l th:doc="meter" th:sID="L3" xml:id="L3"/>
at dusk in spring?
<l th:doc="meter" th:eID="L3"/>
<lg th:doc="meter" th:eID="lg1"/>
</s>
</ab>
</body>
</text>
Interpretation of tags in the input
Each tag in the document is either
dominant markup: an XML
start-, end-, or sole-tag used
conventionally and representing the
beginning, end, or location of a node in the dominant
structure, or
recessive markup: a
empty Trojan-Horse element representing (or
corresponding to) a start-, end-, or sole-tag in a
recessive structure.
The difference between them is visible on an examination of
the tag in question, without reference to context:[10]
Start- and sole-tags with th:sID or
th:eID attributes are Trojan-Horse markup and
relate to the recessive structures identified by the
th:doc attribute.
Start- and sole-tags with neither
th:sID nor th:eID attributes
relate to the dominant structure.
Note that strictly speaking some of the information recorded
is redundant and could be omitted: because the Trojan-Horse
elements correspond 1:1 to tags in a well-formed XML document with
a different dominant structure, each Trojan-Horse element marking
the end of a region closes the most recently begun matching
region; we could thus omit the th:sID and
th:eID attributes if we wished. We could similarly
omit th:doc on end-tag elements. These omissions
would not, however, save as many characters as one might think:
without th:sID and th:eID we would need
to add some other simple signal to distinguish Trojan-Horse
elements from conventional elements. In practice, the redundant
co-indexing of th:sID and th:eID is
convenient for processing software, as it makes it easy to find
the matching tag in a pair. The redundant specification of
th:doc on end-tag elements similarly makes processing
slightly simpler in the transforms which switch from one dominant
structure to another.
All-recessive form
It can sometimes be convenient to have no dominant
hierarchy at all, and to represent all three hierarchies as
recessive using Trojan Horse elements. The haiku example
looks like this in this shallow form:
<tei:text xmlns:tei="http://www.tei-c.org/ns/1.0"
xmlns:th="http://www.blackmesatech.com/2017/nss/trojan-horse"
th:doc="meter sentence">
<tei:body th:doc="meter sentence" th:sID="body" xml:id="body"/>
<tei:head th:doc="meter sentence" th:sID="h1" xml:id="h1"/>
The Village Without Bells
<tei:head th:doc="meter sentence" th:eID="h1"/>
<tei:lg th:doc="meter" th:sID="lg1" xml:id="lg1"/>
<tei:ab th:doc="sentence" th:sID="ab1" xml:id="ab1"/>
<tei:l th:doc="meter" th:sID="L1" xml:id="L1"/>
<tei:s th:doc="sentence" th:sID="s1" xml:id="s1"/>
A village where they ring
<tei:l th:doc="meter" th:eID="L1"/>
<tei:l th:doc="meter" th:sID="L2" xml:id="L2"/>
no bells! —
<tei:s th:doc="sentence" th:eID="s1"/>
<tei:s th:doc="sentence" th:sID="s2" xml:id="s2"/>
Oh, what do they do
<tei:l th:doc="meter" th:eID="L2"/>
<tei:l th:doc="meter" th:sID="L3" xml:id="L3"/>
at dusk in spring?
<tei:l th:doc="meter" th:eID="L3"/>
<tei:lg th:doc="meter" th:eID="lg1"/>
<tei:s th:doc="sentence" th:eID="s2"/>
<tei:ab th:doc="sentence" th:eID="ab1"/>
<tei:body th:doc="meter sentence" th:eID="body"/>
</tei:text>
As may be observed, in this form the container element
(here tei:text) contains a flat sequence of empty
elements and text nodes, with no further nesting; for this
reason we call this the shallow
form of the document. (It is called a
flattened form in Birnbaum et al. 2018.)
Translation from one dominant hierarchy to another is
conveniently achieved by a two-step translation first into
shallow form and then into the new dominant hierarchy.
Well-formedness checking and simple validation
Logical well-formedness checking
One immediate consequence of the syntax used here is that
it is possible to construct well-formed XML documents which are
not logically well formed. A
document is logically well formed if the markup for each
hierarchy (dominant or recessive) is well formed: each
start-marker has exactly one corresponding end-marker, and vice
versa, and start- / end-marker pairs nest properly, and the same
is true for start- and end-tags. A document that is not
logically well formed is logically ill formed. Logical
ill-formedness will be manifest as XML ill-formedness if the
markup for the dominant hierarchy is made recessive and the
markup for some recessive hierarchy is made dominant.
Unfortunately, neither XML editors nor XML parsers will
detect logical ill-formedness in a recessive hierarchy. And we
cannot simply make each recessive hierarchy dominant in turn in
order to check well-formedness using an XML parser: our
transformations are written in XSLT, which normally produces no
ill-formed output: if the recessive hierarchy is logically ill
formed in the input, the transformation will either fail or
(worse) succeed with erroneous output.
It is imperative, therefore, to develop tools for checking
the well-formedness of documents in this format. As the examples
above show, even in simple cases the density of markup can be very
high, and without the aid of an editor in maintaining well
formedness, it is very easy to make the kind of errors familiar to
anyone who has had to deal with attempts to edit XML documents in
editors without sufficient XML awareness.[11]
The current state of our well-formedness checking
is represented by an XSLT stylesheet whose core is given by the
following template:
As can be seen, it generates an XML document with a report
on the well-formedness of the input. Initially it reports on
its input and parameters: $doctype requests
well-formedness checking for one particular document type
(default is all), and $nesting determines whether
each content element in the input with Trojan Horse children is
checked independently for well-formedness; documents in shallow
form set $nesting to respect and those
with a dominant hierarchy set it to ignore.
Separate named templates[12]
then check the start- and
end-markers of the document to confirm that:
Each th:sID value is unique among start-
or sole-markers; each th:eID value is unique
among end-markers.
Each start-, sole-, or end-marker is empty.
No element has more than one of th:sID,
th:eID, th:soleID among its
attributes.
Each th:sID matches at least one th:eID.
Each th:eID matches at least one th:sID.
Each th:sID matches at most one th:eID.
Each th:eID matches at most one th:sID.
When th:sID and th:eID
match, the two markers have the same generic identifier,
the th:sID precedes the th:eID,
and the th:doc attributes match.
Another named template then checks to see that the
sequence of start- and end-markers for a given document type
form nesting elements: it progresses through the sequence of
markers, pushing th:sID values onto a stack
and checking, when it encounters an end-marker, that the
th:eID attribute on the end-marker
matches the value at the top of the stack. It can thus report
on errors of nesting in the recessive views.
Simple validation
It is straightforward (or more precisely: it is as
straightforward as document design ever gets) to specify a basic
document grammar for each structural view of the document, in
which the elements of that structure (including any common
elements) are defined and elements of other structures are
ignored. In the discussion that follows, we assume that such
grammars are available. For purpose of the discussion it does
not matter whether the grammars are expressed in DTD notation,
Relax NG, or XSD.
Given such basic grammars, validation of the markup
described above can be achieved in any of several ways.
The simplest approach is to validate each view separately.
For each structure S marked up
in the document:
First, translate the document into a form where
S is dominant.
Then use a simple transformation to omit all recessive
markup (or translate it into processing
instructions).
Finally, validate against the basic document grammar for
S.
For example, the basic grammar for the metrical
structure of the haiku example might be (in DTD
notation):
<!ELEMENT text (body) >
<!ELEMENT body (head?, lg+) >
<!ELEMENT head (#PCDATA) >
<!ELEMENT lg (l+) >
<!ELEMENT l (#PCDATA) >
The basic grammar for the sentence structure might be:
<!ELEMENT text (body) >
<!ELEMENT body (head?, ab) >
<!ELEMENT head (#PCDATA) >
<!ELEMENT ab (s+) >
<!ELEMENT s (#PCDATA) >
This approach has the advantage of simplicity in the
grammars: each basic grammar can essentially ignore the other
grammars. It has the disadvantage that XML editors can no
longer validate the document usefully, because there is no
document grammar that actually describes even approximately
the set of acceptable documents.
A more convenient validation process can be achieved by
making an augmented document
grammar for each structural view, which accounts for both the
dominant structure and the Trojan-Horse markup for recessive
structures. Because the augmented grammar includes
declarations for recessive markup, it can be applied without
pre-processing the document to strip recessive markup. This
makes it possible to use the augmented grammar in schema-aware
XML editors.
The set of base grammars satisfies the definition in
Sperberg-McQueen 2006 for a set of rabbit/duck grammars. All
common elements and elements in the dominant structure are
first-class elements, and all other elements are third-class.
We achieve a single augmented schema by making all recessive
elements second-class and accounting for their start- and
end-tags in the content models of the dominant structure.
For each structure S, make a list of all element types
present in other structures, for which recessive markup
may appear in view S (and
declarations for which thus need to appear in the
augmented schema). Call this list R (for
recessive).
Note that some element types may be present as
content elements in all structures: for the ATMO project,
the TEI header and the TEI note element (with
all its possible descendants) are such elements. Note,
however, that some instances of such element types may be
present in some structures but not all: the main
paragraphs of the text (not inside notes) will be content
elements in the text and sentence views, but virtual
elements marked by Trojan Horse markup in the page view.
The p element and its descendants, therefore,
must appear in the list R
constructed for the page view.
Augment the document grammar for S (call the augmented grammar
S′) by allowing
start- or end-tags for all elements in R at any location in any content
model.[13]
This is equivalent to adding all the elements of
R as inclusion
exceptions on the SGML content model for the container
element(s). In Relax NG, the desired effect can be
achieved using the interleave operator (except when
RNG's ambiguity rules mean that it cannot). In other
schema languages (XML DTDs, XSD), systematic changes
will need to be made to content models.[14]
Validation against the modified document grammar
S′ is possible without
a prior transformation to strip out recessive markup, and thus
S′ can be used to
guide a validating XML editor.
An SGML DTD with an augmented form of the metrical
grammar might be:
<!ELEMENT text (body) +(ab | s)>
<!ELEMENT body (head?, lg+) >
<!ELEMENT head (#PCDATA) >
<!ELEMENT lg (l+) >
<!ELEMENT l (#PCDATA) >
An XML DTD will require more changes:
<!ENTITY % R "ab | s" >
<!ELEMENT text (body)>
<!ELEMENT body ((%R;)*, (head, (%R;)*)?, (lg, (%R;)*)+) >
<!ELEMENT head (#PCDATA | %R;)* >
<!ELEMENT lg (l, (%R;)*)+ >
<!ELEMENT l (#PCDATA | %R;)* >
Our current validation practice uses augmented grammars,
but our method of generating them is slightly less systematic
that could be desired and has run into a number of snags. We
continue to seek improvements, but resource constraints may
limit our ability to refine the process.
For project participants, it would perhaps be simplest
and most convenient to use a validator built to understand
rabbit/duck grammars and Trojan-Horse markup, capable of
validating multiple document grammars in parallel. A
prototype of such a validator was described in Sperberg-McQueen 2006, but it is not deployable on the ATMO server.
In any case, for editing an augmented grammar appears to be
the best approach that is currently feasible.
Conclusions and future work
The paper has presented an account of one technique for
representing multiple hierarchies systematically in XML and
processing documents so marked up using an XML tool
chain.
Within the project, it remains to make full use of the
technique, and in particular to create a search interface
that allows the user to exploit the presence of multiple
overlapping tagged structures in the documents.
It would also be helpful to automate the creation
of schemas more fully.
More generally, and beyond the confines of the ATMO
project, several topics invite further examination. The ability
to validate documents with concurrent hierarchies marked up in
this way in a single pass would be helpful; even more helpful
would be techniques for writing schemas in conventional schema
languages to enforce validity or at least well-formedness with
respect to recessive views, so that XML-aware editors could be
warned against changes that destroy logical well-formedness. If
such schemas could be generated by deterministic processes
operating on simple base schemas, so much the better.
The ability to query richly marked up documents with
multiple concurrent hierarchies is of interest not only to the
ATMO project but to others. It seems clear that such queries
can be supported in principle, but it is less clear how to make
such queries convenient and intuitive to the end user, or how to
make XPath / XQuery / XSLT formulations of cross-hierarchy
searches convenient and intuitive to the XML programmer. In
particular, providing tools for XPath-style navigation in the
presence of multiple hierarchies would be challenging and
interesting.
We can perhaps take query as a bellwether for the general
problem of processing concurrent structures, but it is possible
that other forms of processing may turn up requirements not
visible in search and retrieval applications. Peter Sharpe of
SoftQuad pointed out a number of years ago that even standard
operations like cut and paste take on new complications in the
presence of concurrent structures; there may be other operations
we take for granted in the conventional XML context that
similarly become more complicated in documents like those
described here.
[Barnard et al. 1995] Barnard, David,
Lou Burnard,
Jean-Pierre Gaspart,
Lynne A. Price,
C. M. Sperberg-McQueen,
and
Giovanni Battista Varile.
Hierarchical encoding of text: Technical problems and SGML solutions.
Computers and the Humanities
29 (1995): 211-231. doi:https://doi.org/10.1007/BF01830617.
[Birnbaum et al. 2018]
Birnbaum David J.,
Elisa E. Beshero-Bondar,
and
C. M. Sperberg-McQueen.
Flattening and unflattening XML markup: a Zen garden of XSLT and other tools.
To be
presented at Balisage: The Markup Conference 2018,
Washington, DC.
On the Web in the preliminary proceedings.
[Haentjens Dekker / Birnbaum 2017]
Haentjens Dekker, Ronald, and
David J. Birnbaum.
It's more than just overlap: Text As Graph.
Presented at Balisage: The Markup Conference 2017,
Washington, DC, August 1 - 4, 2017.
In
Proceedings of Balisage: The Markup Conference 2017.
Balisage Series on Markup Technologies, vol. 19 (2017).
doi:https://doi.org/10.4242/BalisageVol19.Dekker01.
[Henderson 1958]
Henderson, Harold G.
An introduction to haiku.
(Garden City, New York: Doubleday, 1958).
[ISO 8879:1986]
International Organization for Standardization (ISO).
1986.
ISO 8879-1986
(E). Information processing — Text and Office Systems —
Standard Generalized Markup Language (SGML). International
Organization for Standardization, Geneva, 1986.
[Jagadish et al. 2004]
Jagadish, H. V.,
Laks V. S. Lakshmanan,
Monica Scannapieco,
Divesh Srivastava,
and
Nuwee Wiwatwattana.
2004.
Colorful XML: One hierarchy isn't enough.
Proceedings of the 2004 ACM SIGMOD International
conference on management of data, Paris,
sponsored by the Association
for Computing Machinery Special Interest Group on Management of Data.
New York: ACM Press.
doi:https://doi.org/10.1145/1007568.1007598.
[Piez 2012]
Piez, Wendell.
Luminescent: parsing LMNL by XSLT
upconversion.
Presented at Balisage: The Markup Conference 2012,
Montréal, Canada, August 7 - 10, 2012.
In
Proceedings of Balisage:
The Markup Conference 2012.
Balisage Series on Markup
Technologies, vol. 8 (2012).
doi:https://doi.org/10.4242/BalisageVol8.Piez01.
[Piez 2014]
Piez, Wendell.
Hierarchies within range space:
From LMNL to OHCO.
Presented at Balisage: The Markup Conference 2014,
Washington, DC, August 5 - 8, 2014.
In
Proceedings of Balisage:
The Markup Conference 2014.
Balisage Series on Markup
Technologies,
vol. 13 (2014).
doi:https://doi.org/10.4242/BalisageVol13.Piez01.
[Schonefeld 2007]
Schonefeld, Oliver.
2007.
XCONCUR and XCONCUR-CL:
A constraint-based approach for the validation of concurrent markup.
In Datenstrukturen für linguistische Ressourcen
und ihre Anwendungen /
Data structures for linguistic resources and applications:
Proceedings of the Biennial GLDV Conference 2007,
ed. Georg Rehm, Andreas Witt, Lothar Lemnitzer.
Tübingen: Gunter Narr Verlag.
Pp. 347-356.
[Schonefeld / Witt 2006]
Schonefeld, Oliver,
and
Andreas Witt.
2006.
Towards validation of concurrent markup.
Extreme Markup Languages 2006.
[1] Many of the manuscripts in the Jarring Collection were
acquired during Jarring's 1929-1930 stay in Kashgar, a city on
the Silk Road in what is now the Xinjiang Uyghur Autonomous
Region in the far western portion of the People's Republic of
China. Some of the manuscripts are in Persian, Arabic, or other
languages, but most are in the language of Kashgar's main
indigenous population, the Uyghurs, which Jarring called Eastern
Turki or just Turki. It is a matter of some interest whether the
language of these manuscripts should be identified as modern
standard Uyghur (ISO language code uig) or as Chaghatay, the
language of the Chaghatay Khanate, the latest common ancestor of
modern standard Uyghur and of modern Uzbek. For what it's worth,
the linguists in the ATMO project lean on linguistic grounds
toward the latter classification.
Jarring later had a distinguished career in the Swedish
foreign service and at the United Nations. Near the end of his
career he donated his collection of manuscripts to the
University Library in Lund, Sweden, where they now form the
nucleus of the Jarring Collection.
The ATMO project has received funding from the Henry Luce
Foundation. The author thanks the Luce Foundation for their
financial support and my collaborators in the project
(especially Prof. Arienne M. Dwyer, Dr. Alexandre Papas, Akbar
Amat, and Gulnar Eziz) for the intellectual challenges of the
collaboration.
[2]
The earliest discussion I am aware of in a scholarly journal
is that of Barnard et al. 1988, though there is
earlier work in a master's thesis written under David
Barnard's supervision. The discussion of the problem and
potential solutions continues; see for example [Haentjens Dekker / Birnbaum 2017].
[3]
The use of rend to distinguish things for which
standard XML practice would prescribe different element types
is suboptimal; it has unavoidable similarities to the practice
sometimes described as a kind of thought experiment: could we
use a vocabulary with just one element type e,
distinguishing different kinds of structure only by use of a
type, class, or role
attribute? The answer turns out to be yes, but you
won't enjoy it very much.
The awkwardness can probably be taken as a sign of flaws in
the original document analysis within the ATMO project; one of
the challenges in tagging hitherto unavailable material,
however, is that the material one is going to tag may not be
conveniently accessible. For the ATMO project, a systematic
survey of the topographic structures found in the manuscripts
would have required an extended visit to Sweden.
A retrospective redesign of the markup and retagging of the
transcripts would probably be desirable but is unlikely to be
feasible. The most recent revision of the page-view schema
does, however, fix the most egregious problem of the initial
schema by allowing tables to appear within zones of writing.
[4] There is a certain potential for confusion in having
documents in three formats, any one of which may be the most
recently edited master copy, with changes
that must promptly be propagated to the other two copies.
To reduce this confusion, we have in fact chosen as a matter
of policy to identify one or other other form as the
standard master (or just default) format; any
changes most easily made with a different dominant hierarchy
should be followed immediately by automatically re-updating
the default master form. The goal of the markup design
described here is to allow decisions about master form and
maintenance rules to be made on other grounds, and not to be
foreclosed by by limitations of the markup design.
[5] On the topic of such transformations and their
algorithms see now the paper Birnbaum et al. 2018
elsewhere in this year's Balisage conference.
[6] They could also be treated as sole tags, in which
case the stream seen by the SAX-based consumer would
be very similar to that in the proposal made here. But
this possibility was not mooted explicitly by Durusau and
O'Donnell.
[7] The author is grateful to Lynne A. Price for patient
explication of these details in conversations spanning a number
of years.
[8] The name Trojan Horse markup is a jocular
reference to Troy Griffitts, a participant in the development of
the Open Scripture Information Standard, whom DeRose credits
with the basic idea.
[9] N.B. I have inserted line breaks and indentation here and
in other examples for ease of reading. If the details of
whitespace may be meaningful at the application level, less
convenient indentation may be needed.
[10] I apologize if I appear to belabor this point, but
experience has shown that even normally acute observers have
objected to Trojan-Horse markup on the erroneous supposition
that it introduces ambiguity. The claim is based on a
fundamental misunderstanding.
[11] This is true even for experienced XML users. Early in the
process of deploying the format described in this paper, the
author was obliged to make some relatively simple, mechanical
edits in a recessive hierarchy. Because the inter-format
transformations were not yet all ready, it was not feasible to
transform that recessive hierarchy to make it dominant, so he
edited the elements in the recessive hierarchy by hand. The
process involved splitting each tei:surface element
in two and supplying new hyperlinks to point to a new set of
page images to replace the old set of images of two pages at a
time. Although the process was essentially mechanical and was
executed using a simple editor macro, the end result had two
errors in its logical well formedness, which cost a full day and
half in debugging time, and which were found only after the
well-formedness checker described in this section had been
written.
[13]
In this simple approach, the dominant grammar will not
distinguish between start- and end-tags for recessive
elements; in the notation defined by Sperberg-McQueen 2006, this amounts to saying
tag(x) can be used, but not
stag(x) or etag(x).
[14]
The simplest approach is to replace every primitive
content token T
with the expression (T, (%R;)*), where
%R; is an or-group containing every
element in R.
Additionally, replace every content model M thus modified with the
expression ((%R;)*, M).
Barnard, David;
Ron Hayter;
Maria Karababa;
George Logan and
John McFadden.
SGML Markup for Literary Texts.
Computers and the Humanities
22 (1988): 265-276. doi:https://doi.org/10.1007/BF00118602.
Barnard, David,
Lou Burnard,
Jean-Pierre Gaspart,
Lynne A. Price,
C. M. Sperberg-McQueen,
and
Giovanni Battista Varile.
Hierarchical encoding of text: Technical problems and SGML solutions.
Computers and the Humanities
29 (1995): 211-231. doi:https://doi.org/10.1007/BF01830617.
Birnbaum David J.,
Elisa E. Beshero-Bondar,
and
C. M. Sperberg-McQueen.
Flattening and unflattening XML markup: a Zen garden of XSLT and other tools.
To be
presented at Balisage: The Markup Conference 2018,
Washington, DC.
On the Web in the preliminary proceedings.
Dekhtyar, Alex,
and
Ionut Emil Iacob.
2005.
A Framework For Management of Concurrent XML Markup.
Data and Knowledge Engineering
52.2: 185-215. doi:https://doi.org/10.1016/j.datak.2004.05.005.
Durusau, Patrick, and
Matthew Brook O'Donnell.
2001.
Implementing concurrent markup in XML.
Paper given at Extreme Markup Languages 2001,
Montréal, sponsored by IDEAlliance.
Slides on the Web at
http://www.durusau.net/publications/Implementing_concur.pdf.
Durusau, Patrick, and
Matthew Brook O'Donnell.
2002.
JITTS (Just-In-Time-Trees).
Talk given at New York XML Special Interest Group, January
2002.
Slides on the Web at
http://www.durusau.net/publications/NY_xml_sig.pdf.
Durusau, Patrick, and
Matthew Brook O'Donnell.
2002.
Coming down from the trees: Next step in the evolution of markup?
Late-breaking paper given at Extreme Markup Languages 2002,
Montréal, sponsored by IDEAlliance.
Slides on the Web at
http://www.durusau.net/publications/Down_from_the_trees.pdf.
Haentjens Dekker, Ronald, and
David J. Birnbaum.
It's more than just overlap: Text As Graph.
Presented at Balisage: The Markup Conference 2017,
Washington, DC, August 1 - 4, 2017.
In
Proceedings of Balisage: The Markup Conference 2017.
Balisage Series on Markup Technologies, vol. 19 (2017).
doi:https://doi.org/10.4242/BalisageVol19.Dekker01.
International Organization for Standardization (ISO).
1986.
ISO 8879-1986
(E). Information processing — Text and Office Systems —
Standard Generalized Markup Language (SGML). International
Organization for Standardization, Geneva, 1986.
Jagadish, H. V.,
Laks V. S. Lakshmanan,
Monica Scannapieco,
Divesh Srivastava,
and
Nuwee Wiwatwattana.
2004.
Colorful XML: One hierarchy isn't enough.
Proceedings of the 2004 ACM SIGMOD International
conference on management of data, Paris,
sponsored by the Association
for Computing Machinery Special Interest Group on Management of Data.
New York: ACM Press.
doi:https://doi.org/10.1145/1007568.1007598.
Piez, Wendell.
Luminescent: parsing LMNL by XSLT
upconversion.
Presented at Balisage: The Markup Conference 2012,
Montréal, Canada, August 7 - 10, 2012.
In
Proceedings of Balisage:
The Markup Conference 2012.
Balisage Series on Markup
Technologies, vol. 8 (2012).
doi:https://doi.org/10.4242/BalisageVol8.Piez01.
Piez, Wendell.
Hierarchies within range space:
From LMNL to OHCO.
Presented at Balisage: The Markup Conference 2014,
Washington, DC, August 5 - 8, 2014.
In
Proceedings of Balisage:
The Markup Conference 2014.
Balisage Series on Markup
Technologies,
vol. 13 (2014).
doi:https://doi.org/10.4242/BalisageVol13.Piez01.
Schonefeld, Oliver.
2007.
XCONCUR and XCONCUR-CL:
A constraint-based approach for the validation of concurrent markup.
In Datenstrukturen für linguistische Ressourcen
und ihre Anwendungen /
Data structures for linguistic resources and applications:
Proceedings of the Biennial GLDV Conference 2007,
ed. Georg Rehm, Andreas Witt, Lothar Lemnitzer.
Tübingen: Gunter Narr Verlag.
Pp. 347-356.
Sperberg-McQueen, C. M.,
and
Claus Huitfeldt.
1999.
Concurrent document hierarchies in MECS and SGML.
Literary & Linguistic Computing
14.1: 29-42. doi:https://doi.org/10.1093/llc/14.1.29.